CentOS7下的Flink 集群部署
一、Flink 核心架构与应用场景
1.1 流处理引擎的核心优势
Flink 是 Apache 开源的分布式流处理框架,设计目标是提供低延迟、高吞吐的实时计算能力,核心特性包括:
- 真正的流处理:支持事件时间语义(Event Time)和精确一次语义(Exactly-Once),确保数据一致性(文档段落:2-818)。
- 内存计算优化:基于中间结果缓存和增量计算,迭代计算性能提升 10 倍以上。
- 多场景支持:同时支持流处理(Stream Processing)、批处理(Batch Processing)和机器学习(Flink ML)。
- 高可用性:通过 Checkpoint 机制实现故障恢复,秒级恢复时间目标(RTO)。
典型应用场景:
- 实时数据分析(如电商实时推荐、金融交易监控)。
- 物联网数据处理(设备状态实时监测与预警)。
- 日志流处理(分布式系统日志聚合与分析)。
二、集群环境规划与前置准备
2.1 集群节点规划(3 节点方案)
| 节点名称 | IP 地址 | 角色分配 | 内存配置 | 数据目录 |
|---|---|---|---|---|
| flink-node1 | 192.168.88.130 | JobManager、TaskManager | 16GB | /data/flink/data |
| flink-node2 | 192.168.88.131 | TaskManager | 16GB | /data/flink/data |
| flink-node3 | 192.168.88.132 | TaskManager | 16GB | /data/flink/data |
2.2 前置依赖安装(所有节点)
- JDK 环境(需 1.8+,文档段落:2-248):
bash
yum install -y java-1.8.0-openjdk-devel java -version # 验证版本 - Hadoop 集群(已部署 HDFS 和 YARN,文档段落:2-633):
确保 HDFS 服务正常,Flink 将使用 HDFS 作为 Checkpoint 存储。 - SSH 免密登录(文档段落:2-523):
bash
ssh-keygen -t rsa -b 4096 -N "" ssh-copy-id flink-node2 && ssh-copy-id flink-node3
三、Flink 单机安装与配置
3.1 下载与解压安装包
bash
# 下载Flink 1.10.0(文档段落:2-824)
wget https://archive.apache.org/dist/flink/flink-1.10.0/flink-1.10.0-bin-scala_2.11.tgz# 解压到指定目录
tar -zxvf flink-1.10.0-bin-scala_2.11.tgz -C /export/server/
ln -s /export/server/flink-1.10.0 /export/server/flink # 创建软链接
3.2 核心配置文件修改
3.2.1 flink-conf.yaml(文档段落:2-827)
bash
vim /export/server/flink/conf/flink-conf.yaml
# 修改以下核心配置
jobmanager.rpc.address: flink-node1 # JobManager地址
jobmanager.rpc.port: 6123 # JobManager RPC端口
jobmanager.heap.size: 1024m # JobManager堆内存
taskmanager.heap.size: 4096m # TaskManager堆内存
taskmanager.numberOfTaskSlots: 4 # 每个TaskManager的槽位数
parallelism.default: 12 # 默认并行度
jobmanager.web.port: 8081 # Web UI端口
3.2.2 slaves(文档段落:2-829)
bash
vim /export/server/flink/conf/slaves
# 添加以下内容(每行一个节点)
flink-node1
flink-node2
flink-node3
3.2.3 hadoop-conf-dir配置(集成 Hadoop)
bash
# 确保Flink能找到Hadoop配置
export HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
export YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
四、集群化部署:节点间配置同步
4.1 分发安装目录到其他节点
bash
# 在flink-node1执行,复制到node2/node3
scp -r /export/server/flink flink-node2:/export/server/
scp -r /export/server/flink flink-node3:/export/server/
4.2 配置文件一致性验证
检查所有节点的flink-conf.yaml和slaves文件内容一致,确保:
jobmanager.rpc.address指向正确的 JobManager 节点。slaves文件包含所有 TaskManager 节点主机名。taskmanager.numberOfTaskSlots与节点 CPU 核心数匹配(建议为核心数的 1-2 倍)。
五、集群启动与状态验证
5.1 启动 Flink 集群
5.1.1 单节点启动(flink-node1 执行)
bash
# 启动JobManager和TaskManager
/export/server/flink/bin/start-cluster.sh
5.1.2 后台启动(生产环境推荐)
bash
nohup /export/server/flink/bin/start-cluster.sh &
tail -f /export/server/flink/log/flink-*-jobmanager.log # 查看启动日志
5.2 验证集群状态
5.2.1 进程检查(所有节点执行)
bash
jps | grep -E "JobManager|TaskManager"
# flink-node1应显示JobManager和TaskManager进程
# flink-node2/node3应显示TaskManager进程
5.2.2 网页管理界面
- JobManager 状态:访问
http://flink-node1:8081,查看集群概述、TaskManager 列表、作业运行情况(文档段落:2-837)。 - TaskManager 状态:在管理界面中点击节点名称,查看 CPU、内存、磁盘使用情况及 Slot 分配。
5.2.3 命令行验证(文档段落:2-840)
bash
# 提交WordCount示例作业
/export/server/flink/bin/flink run \
/export/server/flink/examples/batch/WordCount.jar \
--input hdfs://flink-node1:8020/README.txt \
--output hdfs://flink-node1:8020/wordcount-result# 查看作业状态
/export/server/flink/bin/flink list
六、核心功能测试与性能调优
6.1 流处理测试
6.1.1 实时单词计数(Socket 源)
bash
# 启动Socket服务器(flink-node1执行)
nc -lk 9999# 提交流处理作业
/export/server/flink/bin/flink run \
/export/server/flink/examples/streaming/SocketWindowWordCount.jar \
--hostname flink-node1 --port 9999# 在Socket中输入文本,查看实时统计结果
6.1.2 Kafka 流处理(文档段落:2-819)
java
// 示例代码:Flink对接Kafka
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "kafka-node1:9092,kafka-node2:9092");
properties.setProperty("group.id", "flink-kafka-group");FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("test-topic",new SimpleStringSchema(),properties
);DataStream<String> stream = env.addSource(consumer);
stream.flatMap((String line, Collector<String> out) -> {for (String word : line.split(" ")) {out.collect(word);}
}).keyBy(word -> word).timeWindow(Time.seconds(5)).countWindow(10).sum(1).print();
6.2 性能优化策略
6.2.1 资源分配优化
- TaskSlot 分配:根据任务类型调整 Slot 数量(文档段落:2-827):
yaml
taskmanager.numberOfTaskSlots: 4 # 每个TaskManager分配4个Slot - 作业提交参数:
bash
/export/server/flink/bin/flink run \ --parallelism 12 \ --jobmanager-memory 2g \ --taskmanager-memory 4g \ --withWebUI true \ my-job.jar
6.2.2 内存优化
- 调整堆内存比例:
yaml
jobmanager.heap.size: 2048m # JobManager堆内存2GB taskmanager.heap.size: 8192m # TaskManager堆内存8GB taskmanager.memory.framework.off-heap.size: 1024m # 框架堆外内存1GB - 启用堆外内存:
yaml
taskmanager.memory.off-heap.size: 2048m taskmanager.memory.off-heap.enabled: true
6.2.3 检查点优化
- 配置 Checkpoint:
yaml
execution.checkpointing.interval: 5000ms # 5秒 checkpoint execution.checkpointing.timeout: 10000ms # 10秒超时 execution.checkpointing.min-pause: 200ms # 最小暂停时间 - 指定 Checkpoint 存储位置:
yaml
state.backend: filesystem state.checkpoints.dir: hdfs://flink-node1:8020/flink-checkpoints
七、常见故障排查与解决方案
7.1 集群无法启动
可能原因:
- SSH 免密失败:检查节点间 SSH 连接是否正常,
~/.ssh/authorized_keys是否包含所有节点公钥(文档段落:2-523)。 - 端口冲突:确保 JobManager 端口(8081)、RPC 端口(6123)未被占用。
- 配置文件错误:检查
flink-conf.yaml中jobmanager.rpc.address是否指向正确主机名。
解决方法:
bash
# 示例:修复SSH免密问题
ssh flink-node2 "echo 'hello' > /tmp/test" # 验证连接
netstat -anp | grep 8081 # 检查端口占用
7.2 作业执行失败
可能原因:
- 资源不足:TaskManager 内存或 Slot 数量不足,导致作业无法分配资源。
- 数据倾斜:某个分区数据量过大,导致 TaskManager 过载。
- Checkpoint 失败:HDFS 存储异常或 Checkpoint 间隔过短。
解决方法:
- 增加 TaskManager 数量或内存,调整
taskmanager.numberOfTaskSlots。 - 对倾斜数据进行重分区:
java
dataStream.rebalance() // 重新平衡分区 - 延长 Checkpoint 间隔或增加超时时间:
yaml
execution.checkpointing.interval: 10000ms execution.checkpointing.timeout: 30000ms
7.3 TaskManager 掉线
可能原因:
- 内存溢出:TaskManager 内存不足导致 JVM 崩溃。
- 网络分区:节点间网络延迟过高或断开。
- 磁盘故障:数据目录所在磁盘损坏,导致 Checkpoint 失败。
解决方法:
- 增加
taskmanager.heap.size配置,降低单个 Task 内存占用。 - 检查网络连接,确保节点间延迟 < 1ms,带宽≥1Gbps。
- 更换故障磁盘,重启 TaskManager 进程:
bash
/export/server/flink/bin/stop-taskmanager.sh flink-node2:6121 # 修复磁盘后重新启动 /export/server/flink/bin/start-taskmanager.sh
八、生产环境最佳实践
8.1 高可用性配置
8.1.1 多 JobManager 部署(HA 模式)
通过 Zookeeper 实现 JobManager 自动故障转移(文档段落:2-815):
yaml
# 修改flink-conf.yaml
high-availability: zookeeper
high-availability.zookeeper.quorum: zk-node1:2181,zk-node2:2181,zk-node3:2181
high-availability.zookeeper.path: /flink
high-availability.jobmanager.port: 6124# 启动多个JobManager
/export/server/flink/bin/start-cluster.sh --jobmanager flink-node1
/export/server/flink/bin/start-cluster.sh --jobmanager flink-node2
8.1.2 持久化作业状态
- 配置 Checkpoint:对长时间运行的流作业设置定期 Checkpoint:
java
env.enableCheckpointing(5000); // 5秒 checkpoint env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); - 作业历史服务器:配置 HistoryServer 记录作业历史:
bash
# 修改flink-conf.yaml historyserver.web.port: 8082 historyserver.archive.fs.dir: hdfs://flink-node1:8020/flink-job-history /export/server/flink/bin/start-historyserver.sh
8.2 安全与资源管理
8.2.1 启用 Kerberos 认证
bash
# 配置flink-env.sh
export HADOOP_USER_NAME=flink-user
export KERBEROS_KEYTAB=/etc/kerberos/keytabs/flink.keytab
export KERBEROS_PRINCIPAL=flink-user@EXAMPLE.COM# 提交作业时认证
kinit -kt flink.keytab flink-user@EXAMPLE.COM
/export/server/flink/bin/flink run --master yarn-cluster ...
8.2.2 YARN 资源队列管理
通过 YARN 队列管理不同作业资源(需提前配置 YARN 队列):
bash
/export/server/flink/bin/flink run \
--master yarn-cluster \
--yarnqueue production \
--yarnapplication.name "Flink Production Job" \
--yarncontainer_memory 4096 \
--class com.example.MyApp my-app.jar
九、总结:Flink 集群部署核心流程
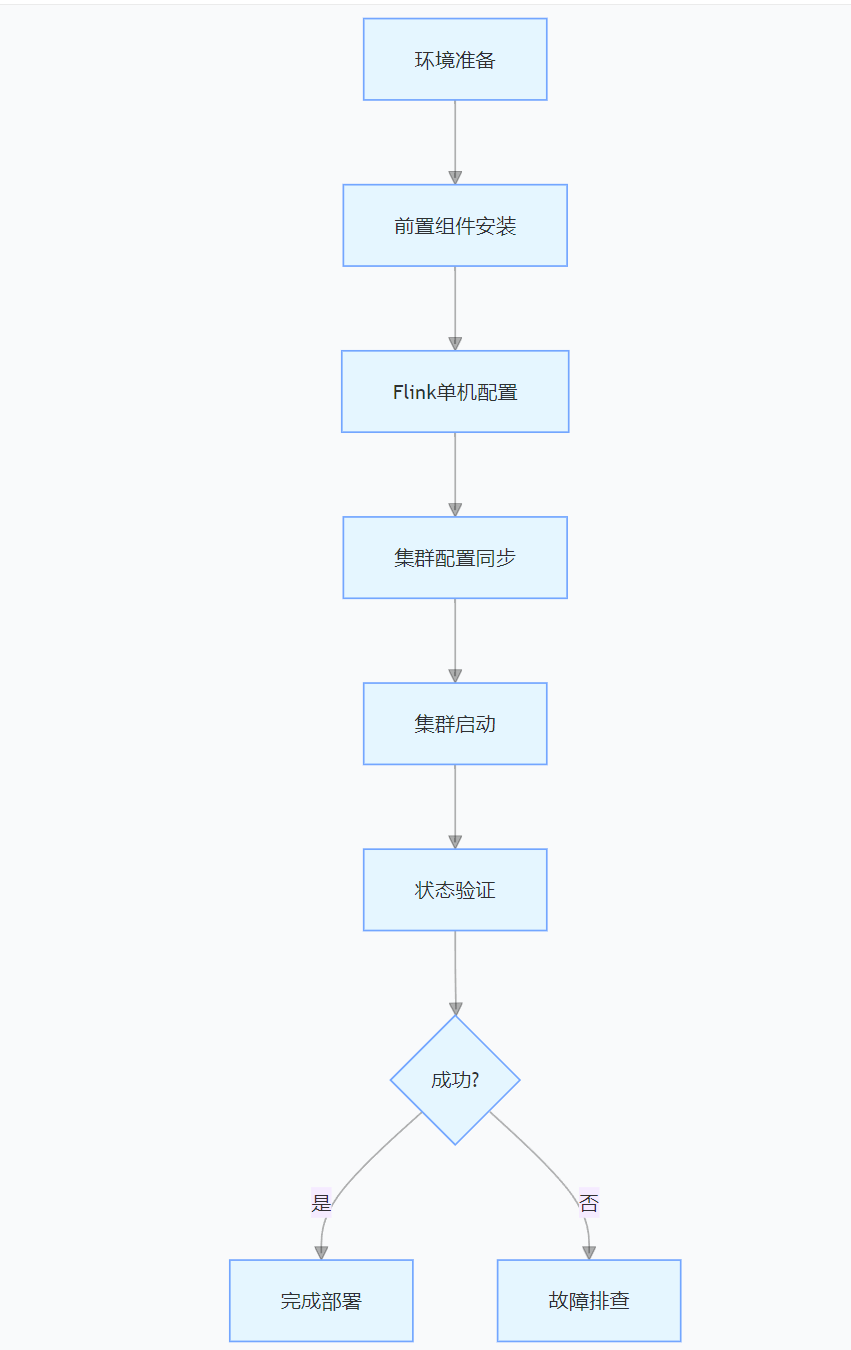
通过以上步骤,可构建一个高可用、高性能的 Flink 分布式流处理集群,支撑实时数据处理与分析任务。生产环境中需结合业务场景优化资源分配、内存使用及 Checkpoint 策略,并利用 Flink 生态工具(如 Flink SQL、Table API)提升开发效率。参考官方文档(Flink Documentation)可进一步学习流处理语义、机器学习集成等高级特性及性能调优技巧。