阿里云MaxCompute入门
ODPS入门
阿里云大数据开发治理平台-DataWorks

阿里云大数据计算服务-MaxCompute

数据仓库的概念
数据仓库定义(Data Warehouse),是为企业所有决策制定过程,提供所有系统数据支持的战略集合
数据仓库VS传统数据库存储
三大优势
- 体量大,效率高
- 历史追查,时光回溯
- 数据可用性强
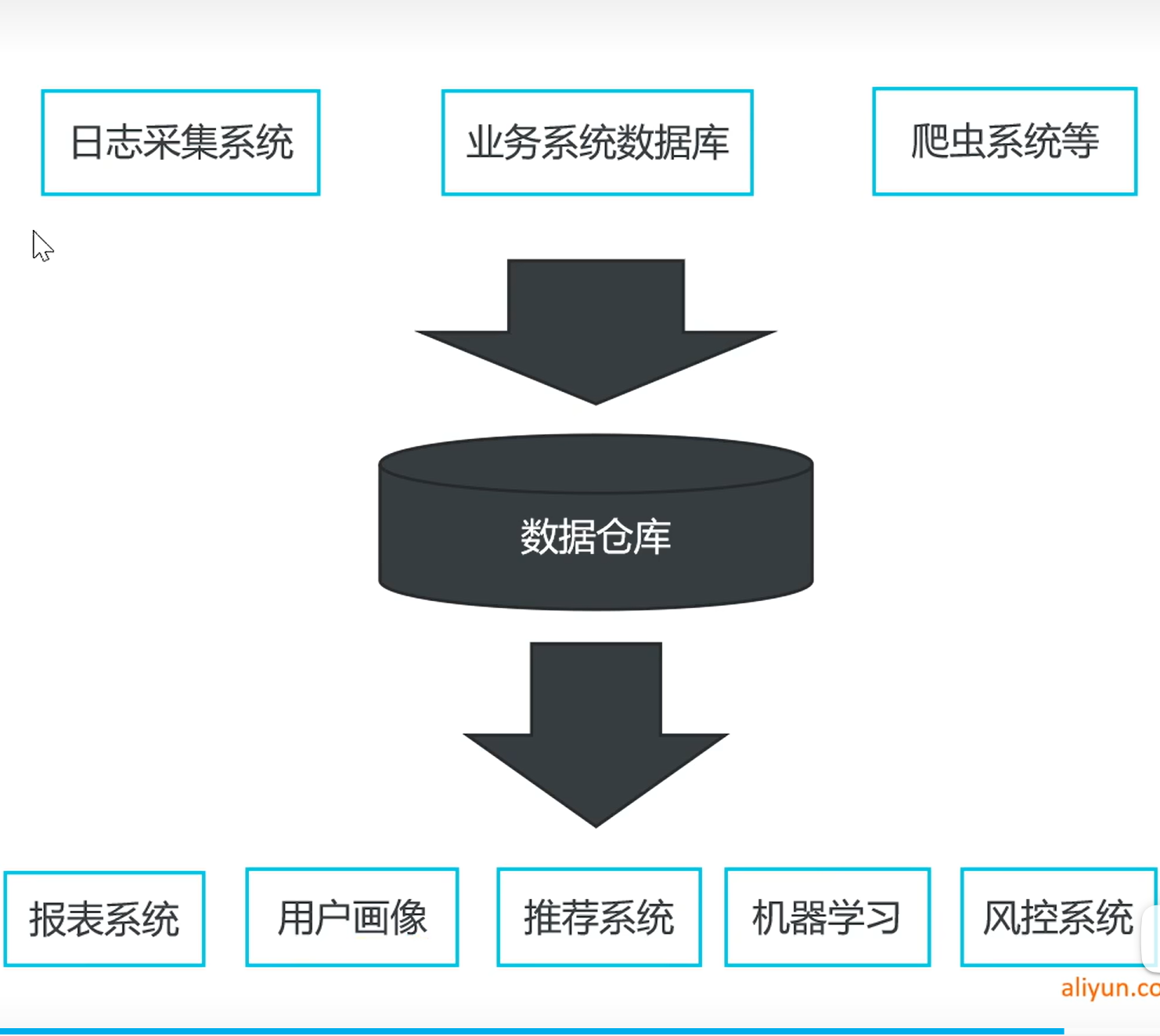
下面使用一个demo来入门
- 采集业务数据库中的数据
- 数据仓库的搭建
- 分析统计业务指标
- 对结果进行可视化展示
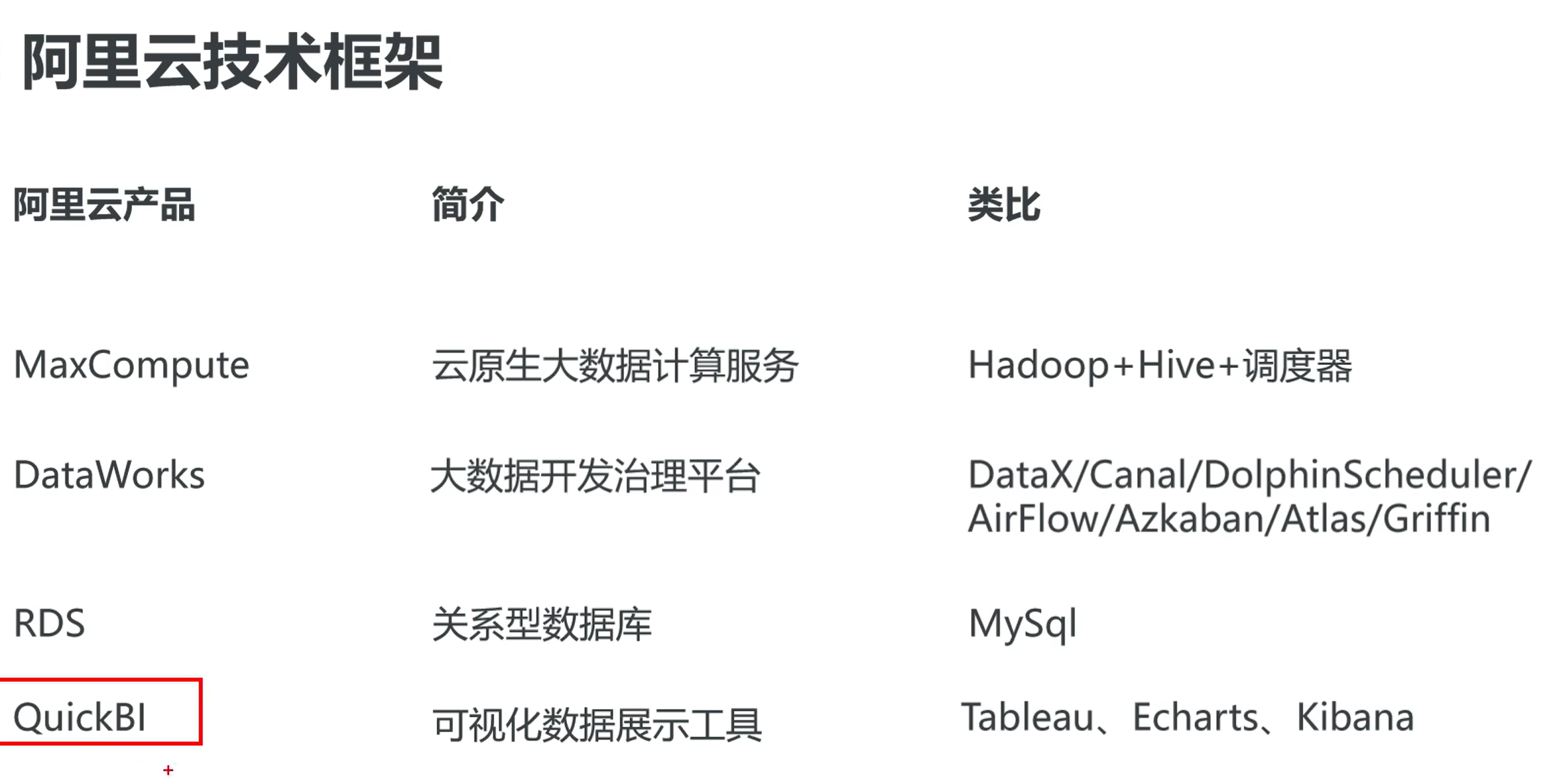
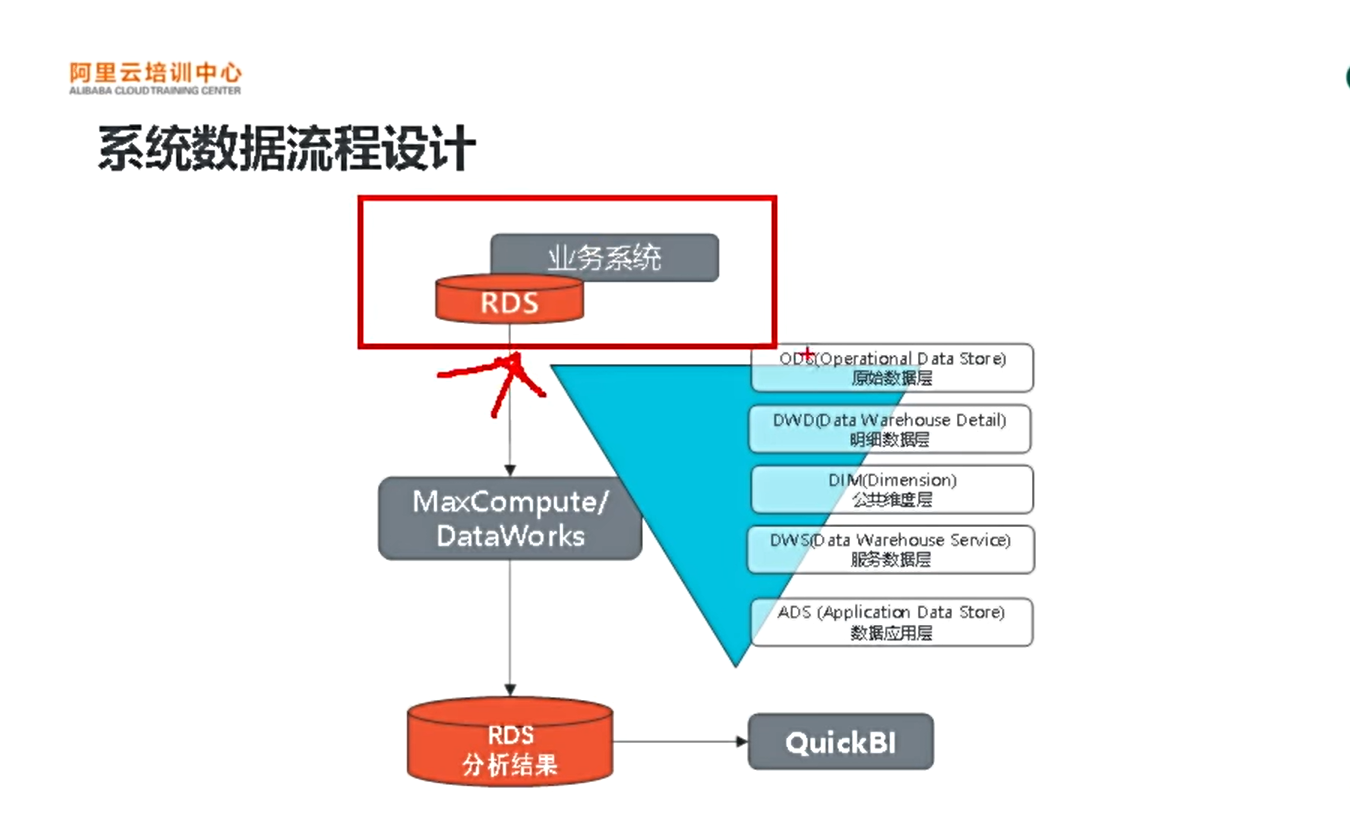
2.使用到的技术框架
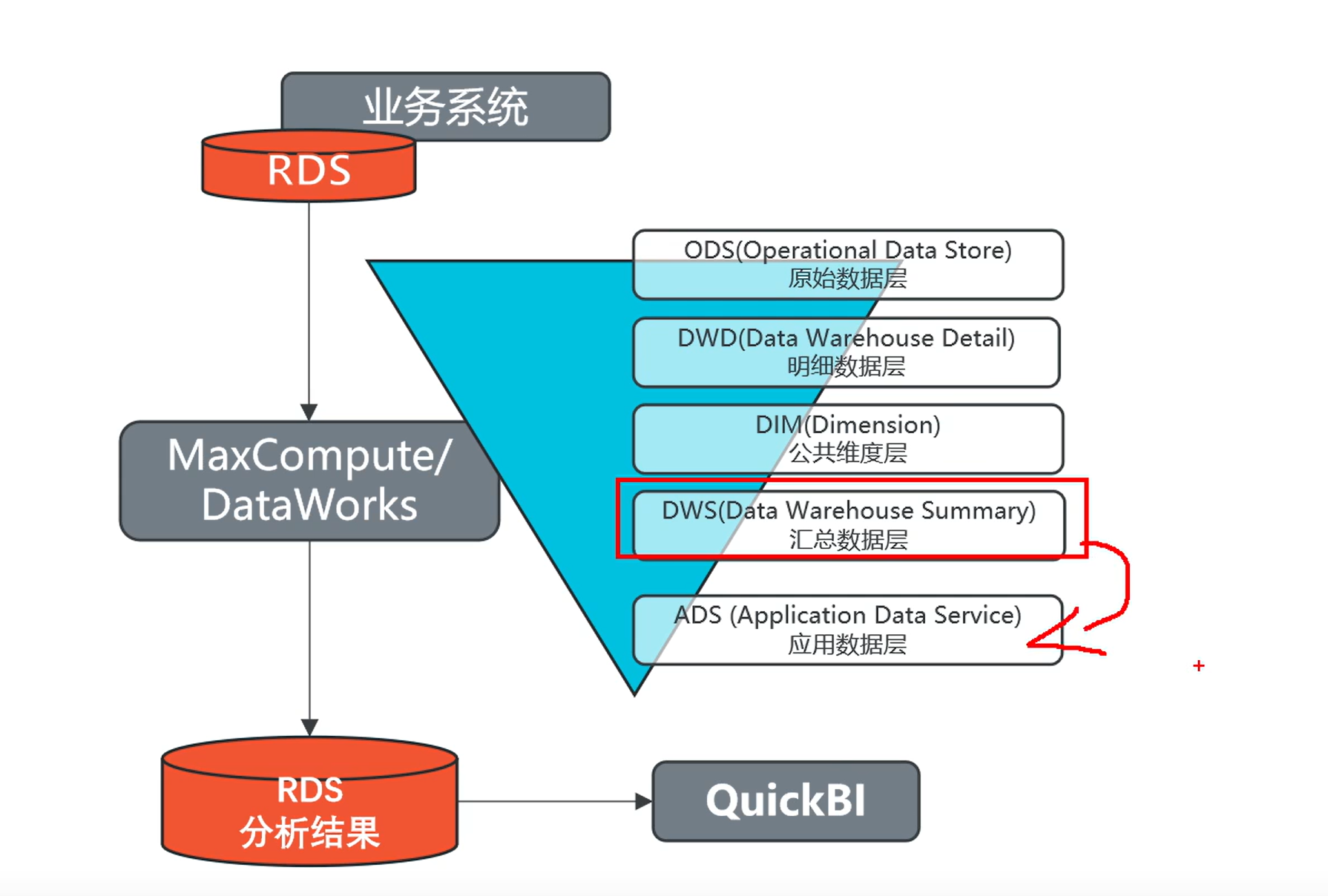
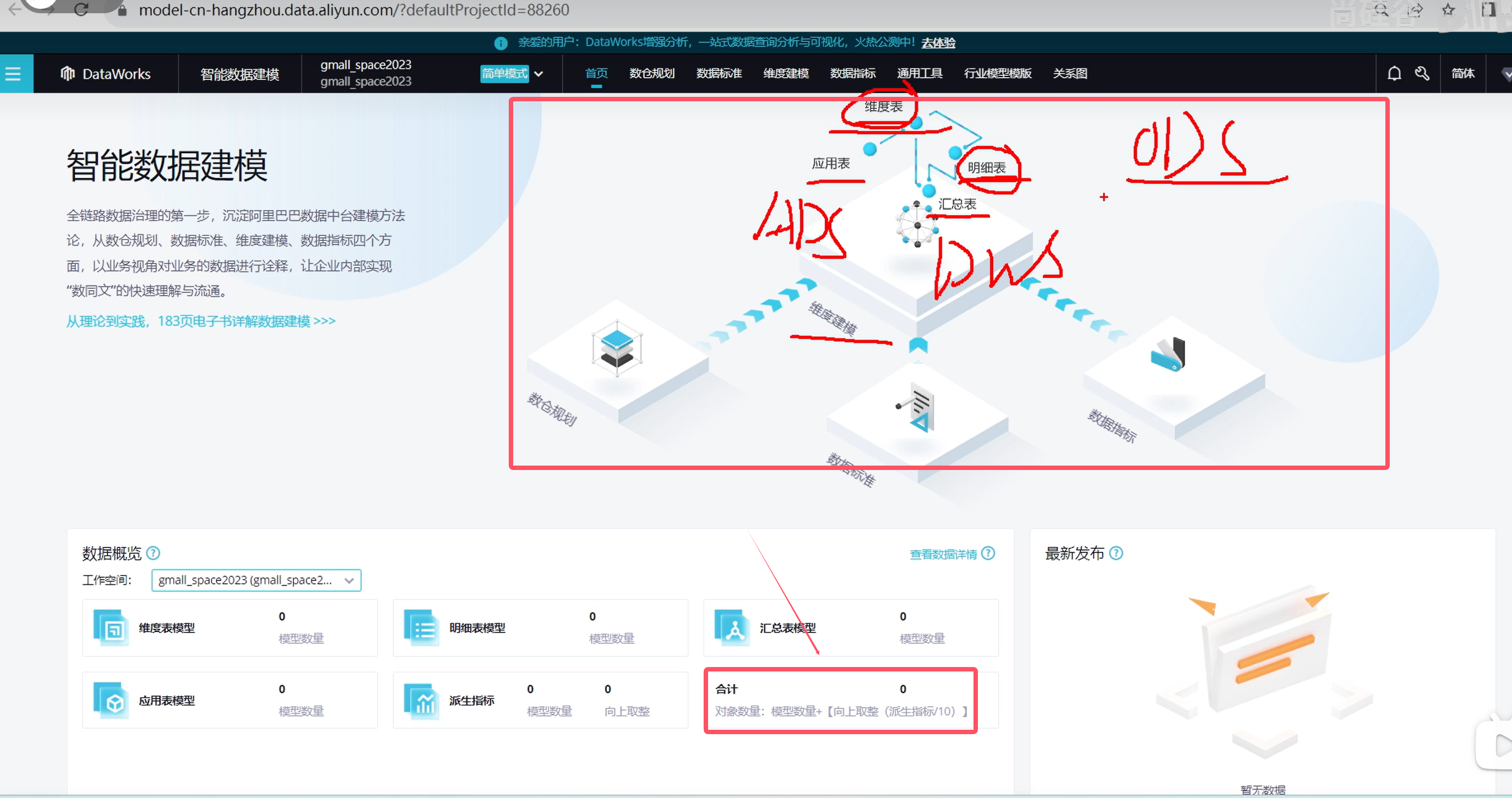
系统数据流程设计
DataWorks和MaxCompute
DataWorks基于阿里云MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。作为阿里巴巴数据中台的建设者,DataWorks从2009年不断沉淀阿里巴巴大数据建设方法论,同时与数万名政务/金融/零售/互联网/制造等客户携手,助力产业数字化升级。
MaxCompute是面向分析的企业级SaaS模式云数据仓库,以ServerLess架构提供快速、全托管的在线数据仓库服务,消除了传统数据库平台在资源拓展和弹性方面的限制,最小化用户运维投入,使您可以经济并且高效的分析处理海量数据,数以万计的企业正基于MaxCompute进行数据计算与分析,将数据搞笑转换为业务洞察
说明: DataWorks是一个大的数据治理平台,可以在里面选择MaxCompute
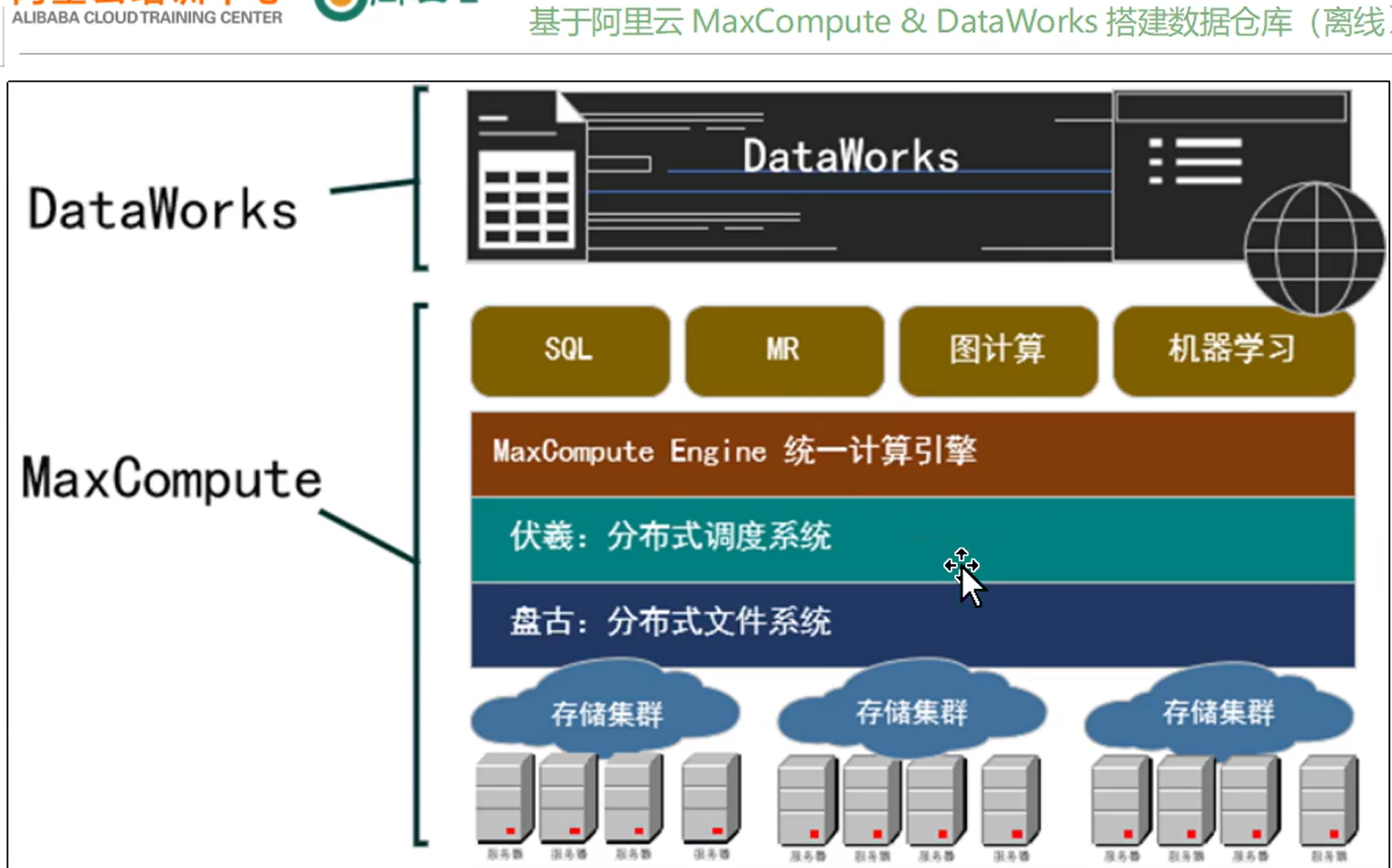
盘古: 相当于Hadoop中的HDFS
复习: 相当于Hadoop中的YARN
MaxCompute Engine:相当于MR、Tez等计算引擎
MaxCompute和DataWorks一起向用户提供完善的ETL和数仓管理能力,以及SQL、MR、Graph等多种经典的分布式计算模型,能够更快速地解决用户海量数据计算问题,有效降低企业成本,保障数据安全
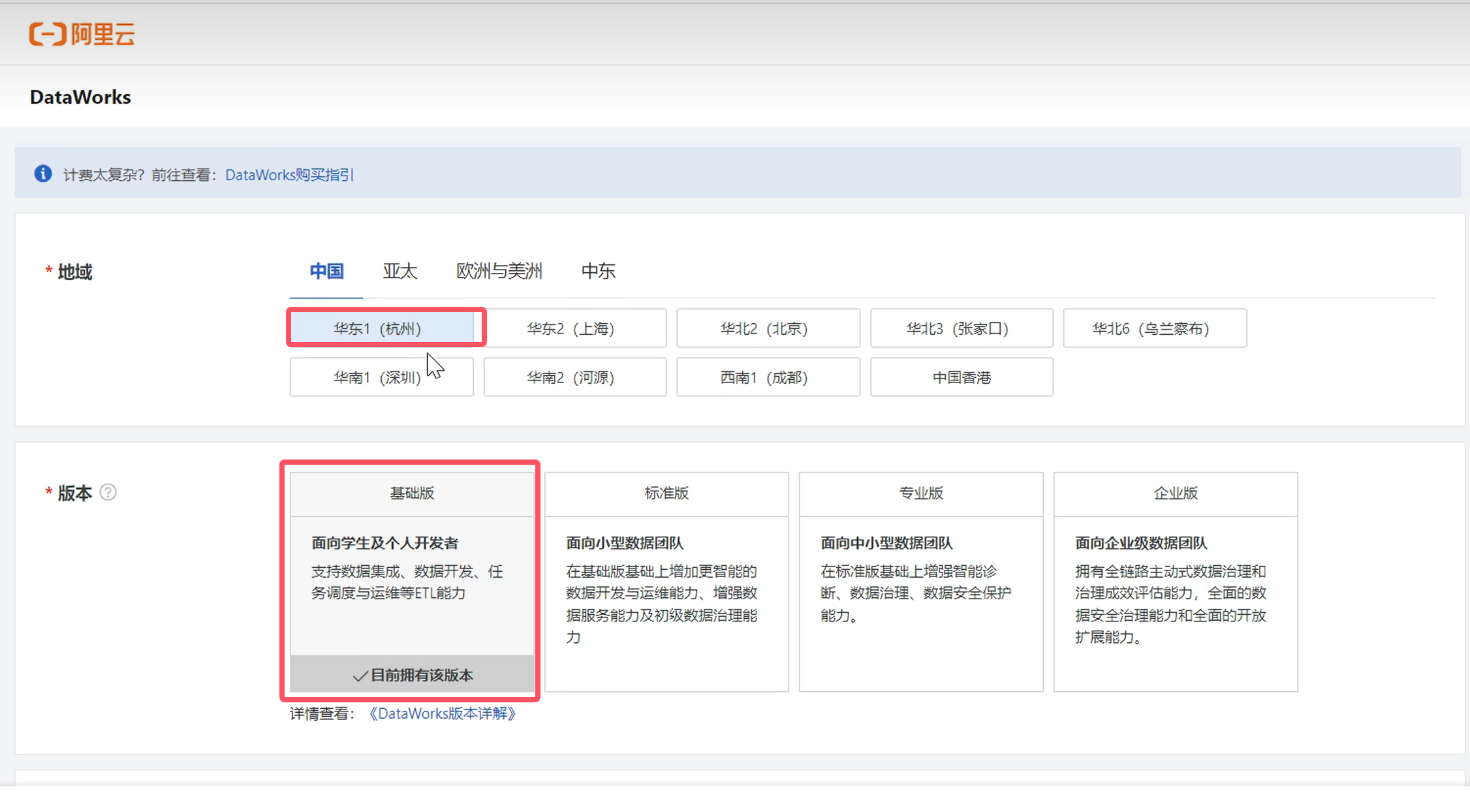
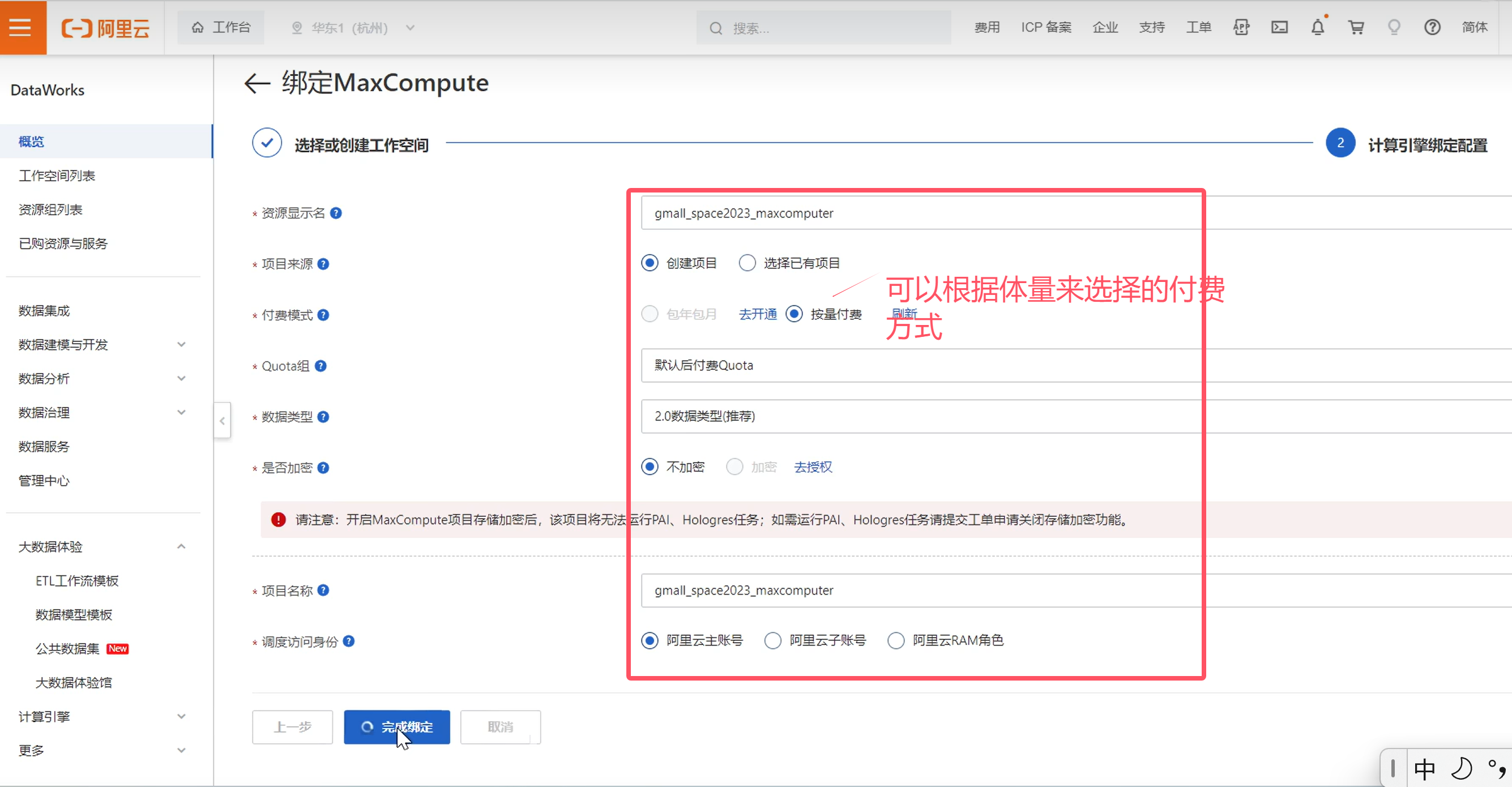
创建工作空间
控制台入口: 控制台入口
登录阿里云平台
购买完成之后,回到原始页面,点击管理控制台
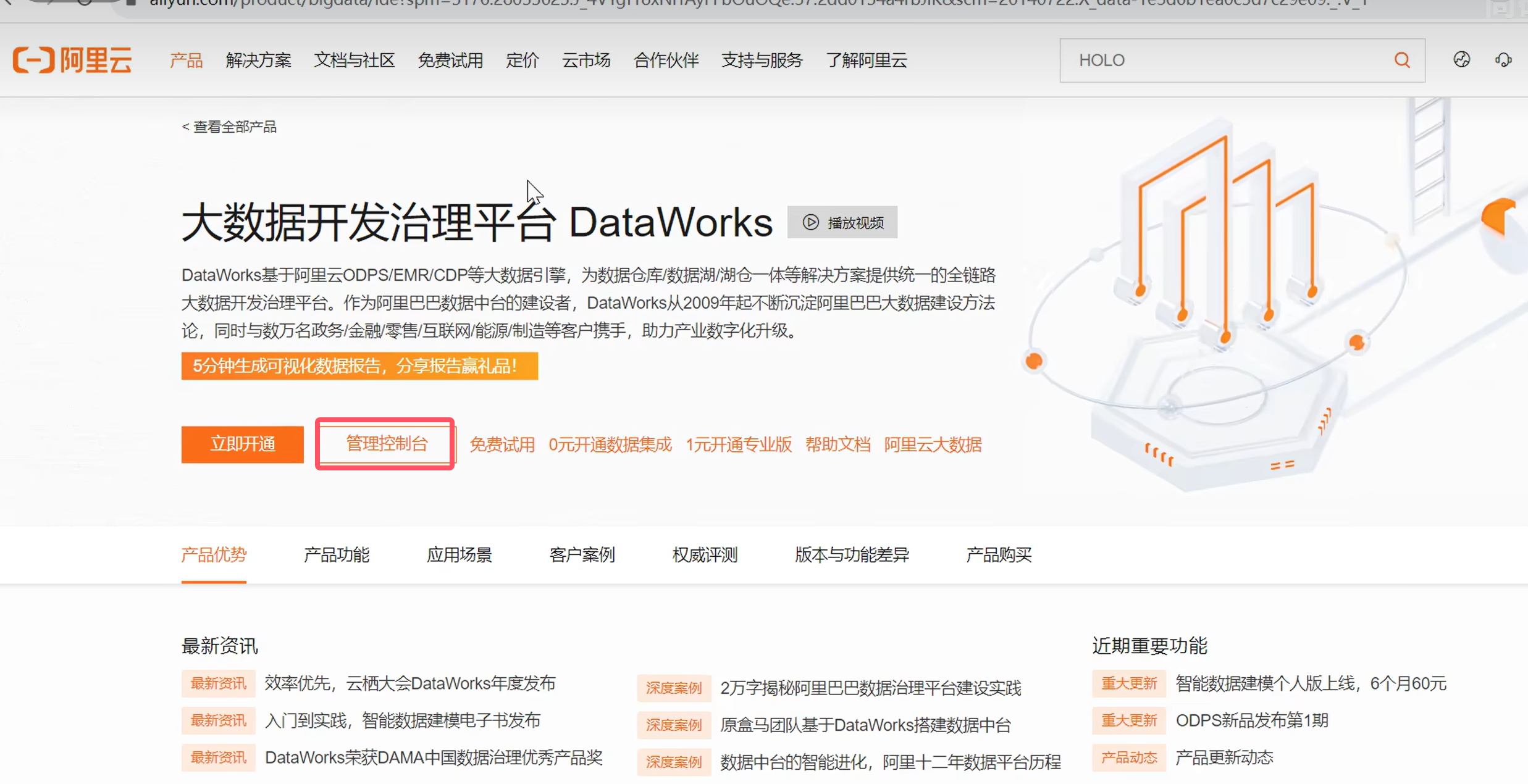
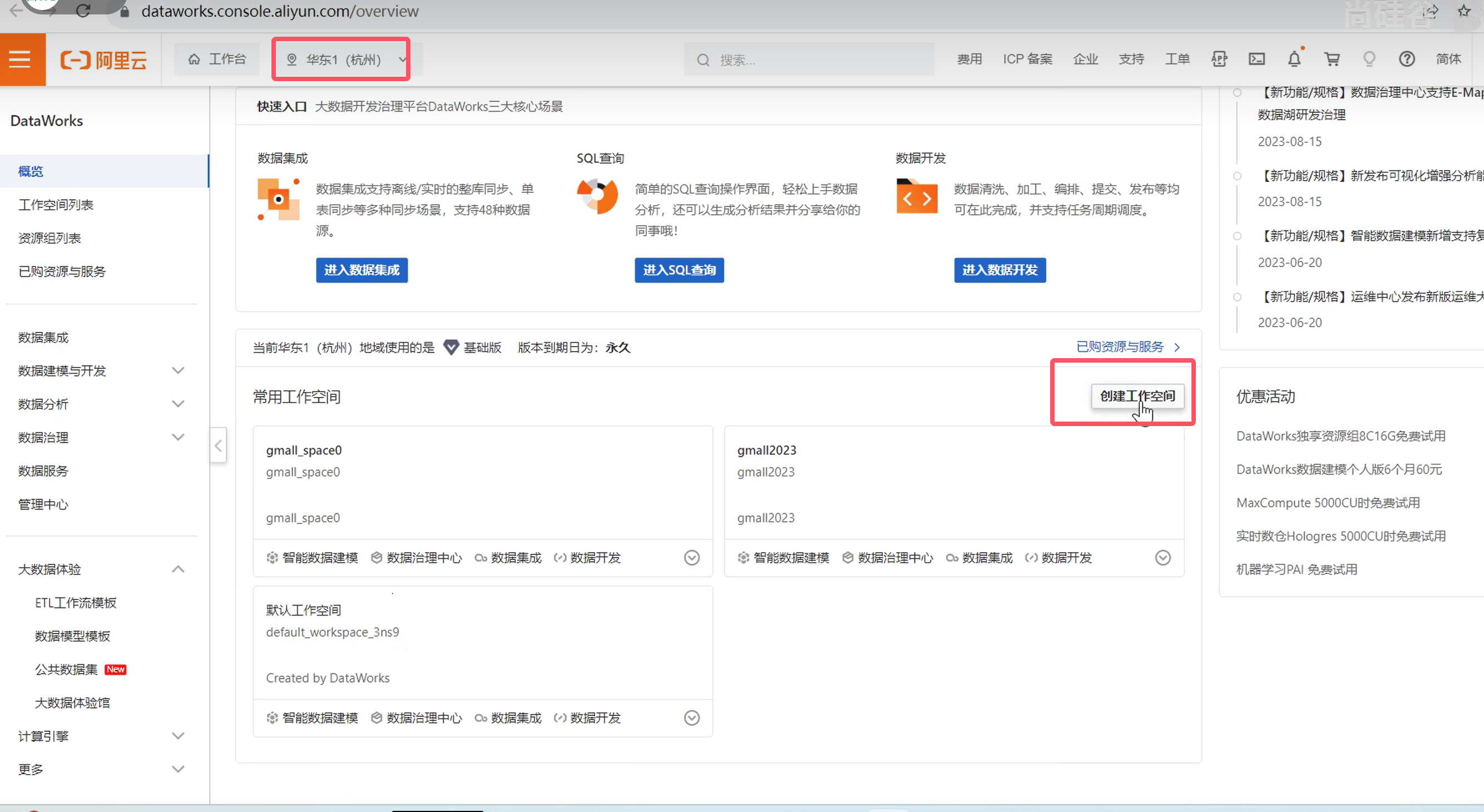
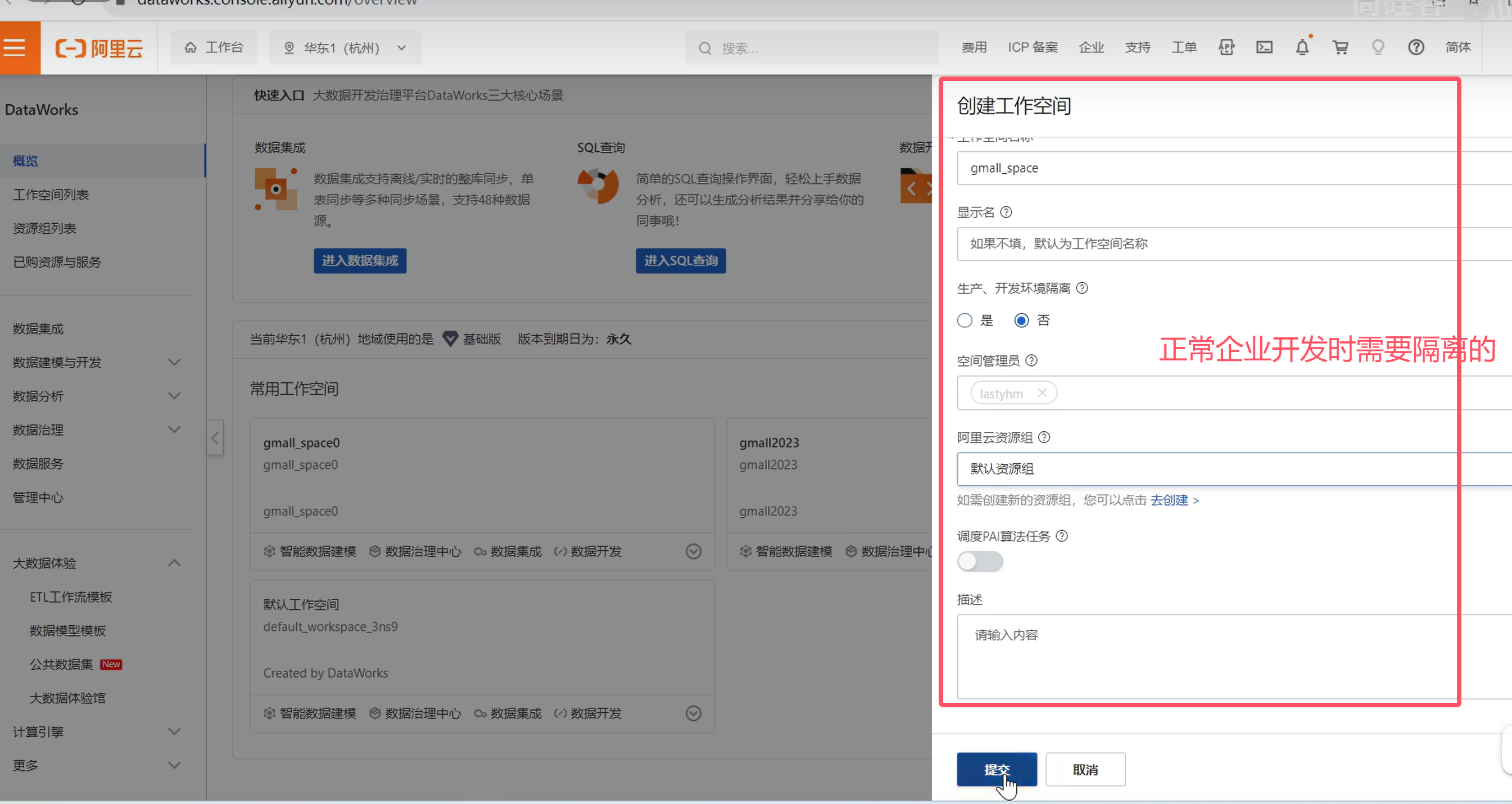
如下则创建成功
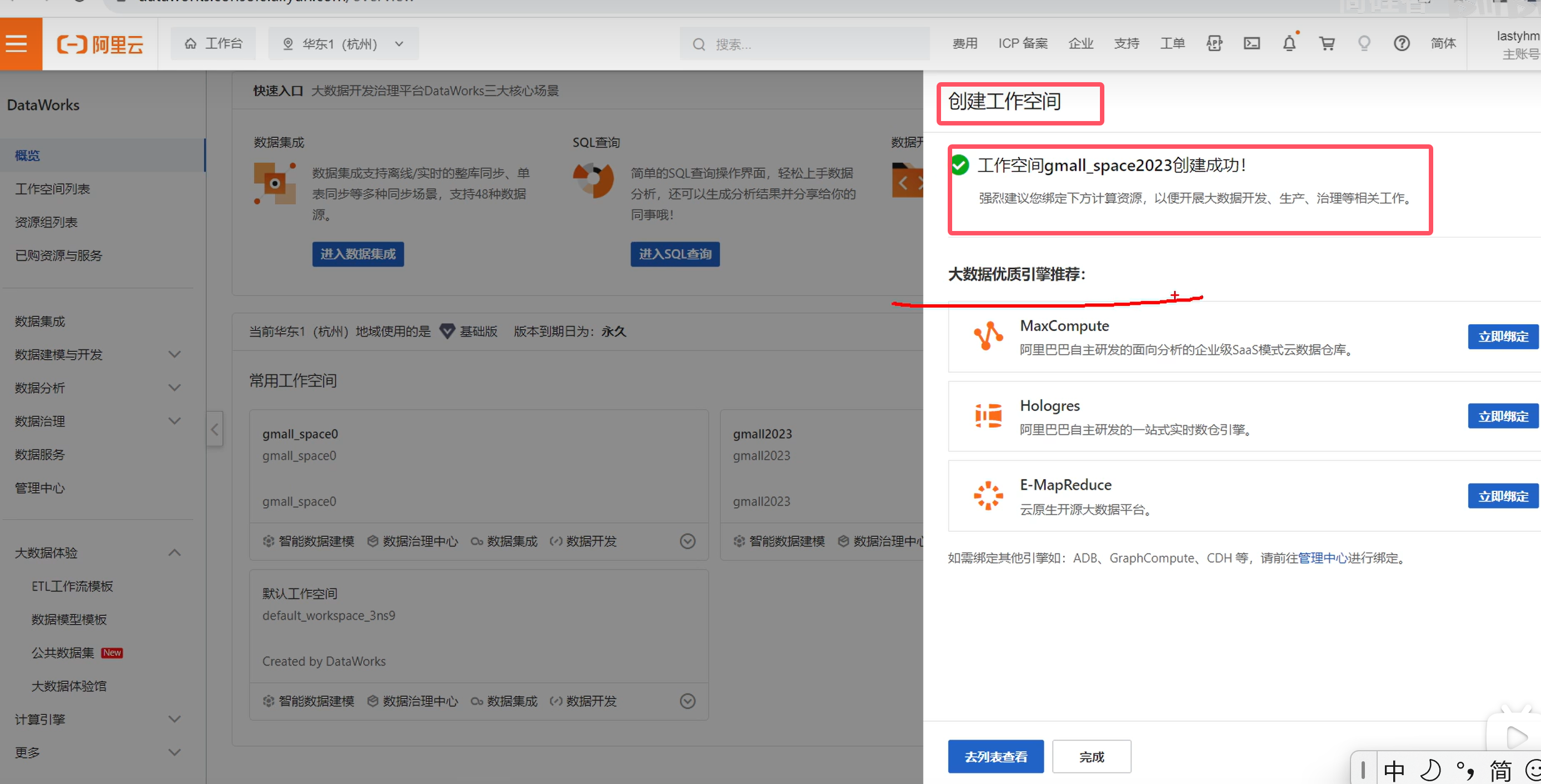
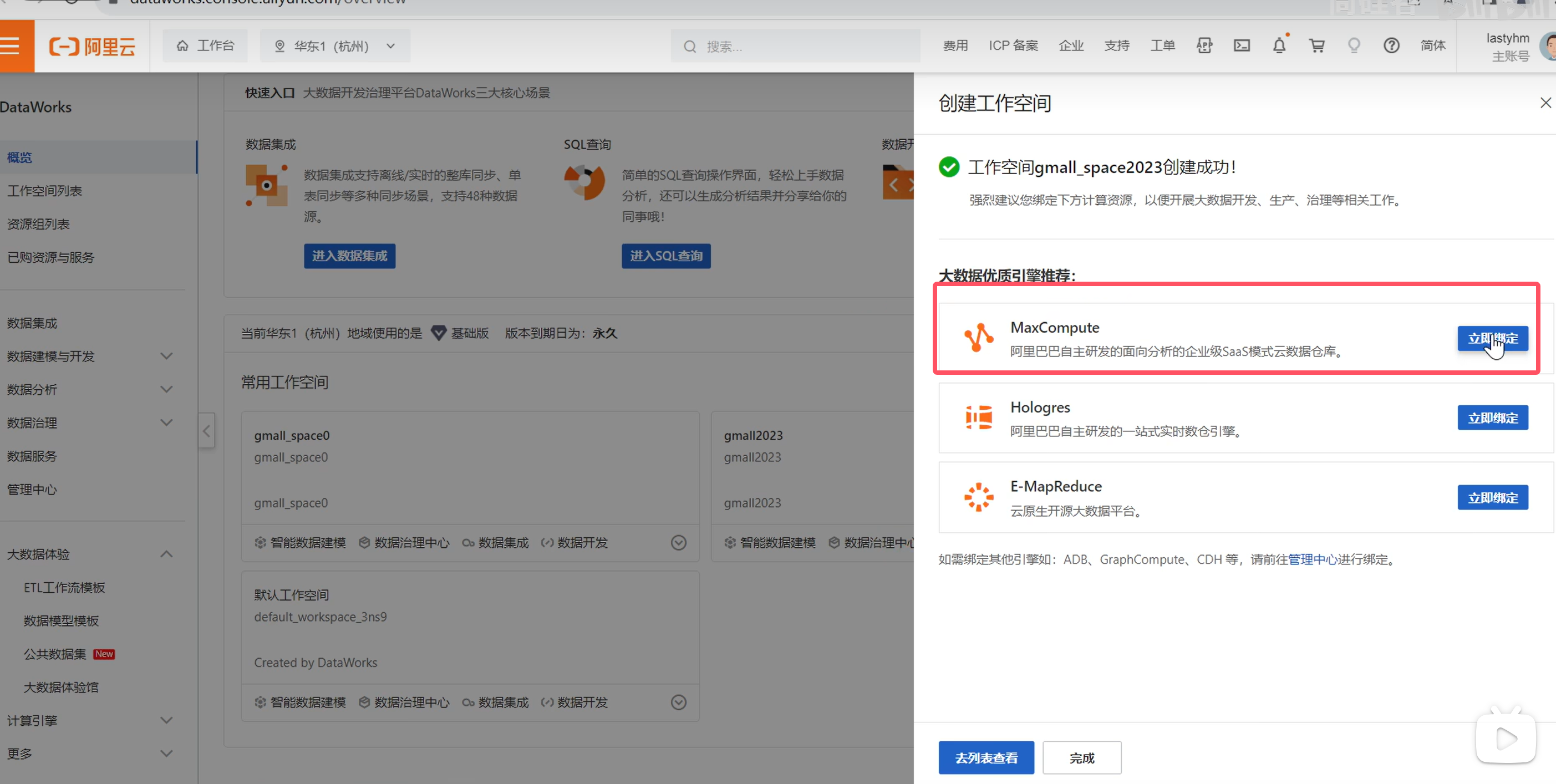
点击立即绑定MaxCompute

点击前往DataStudion进行数据开发,进入如下页面
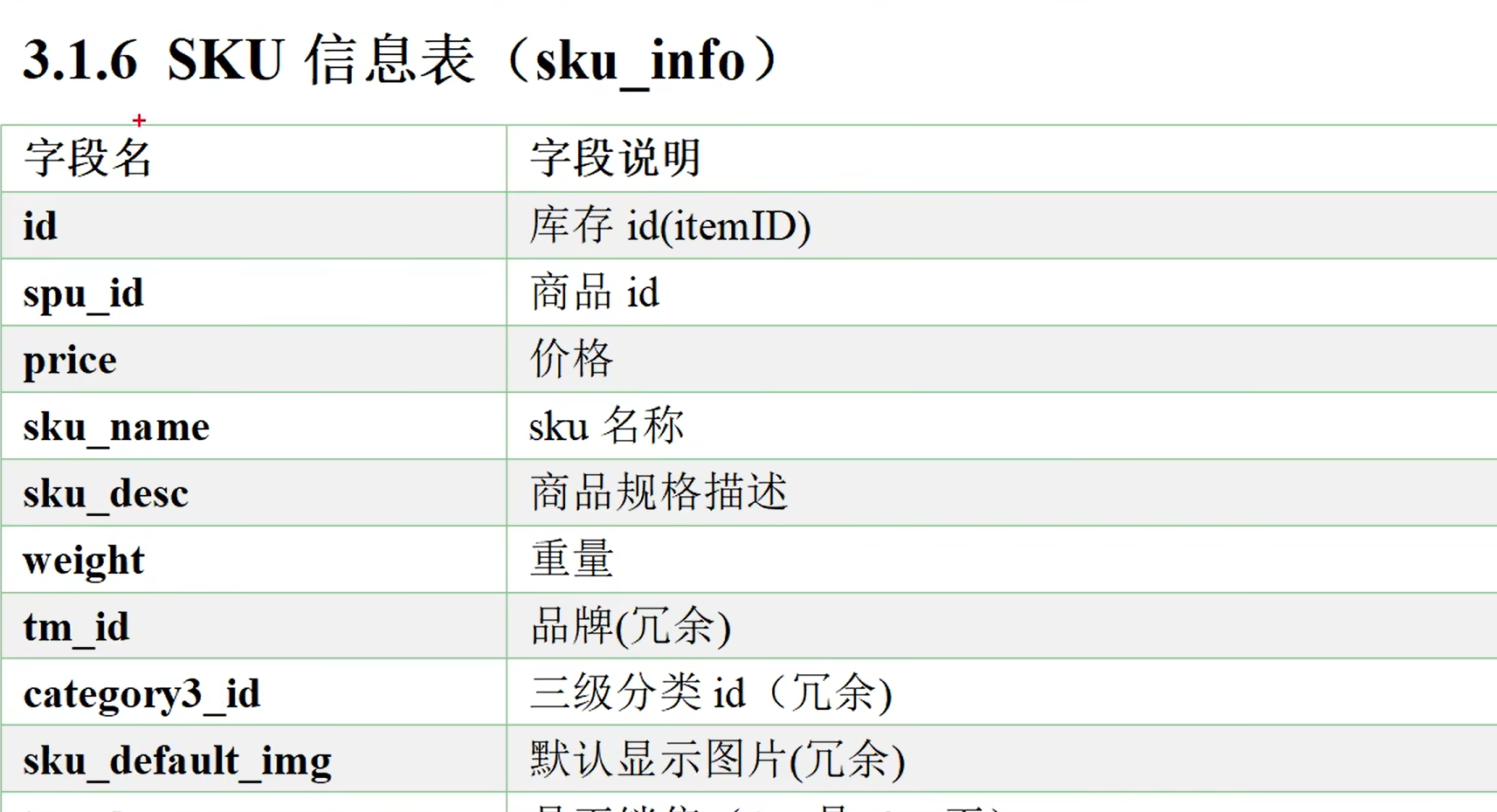
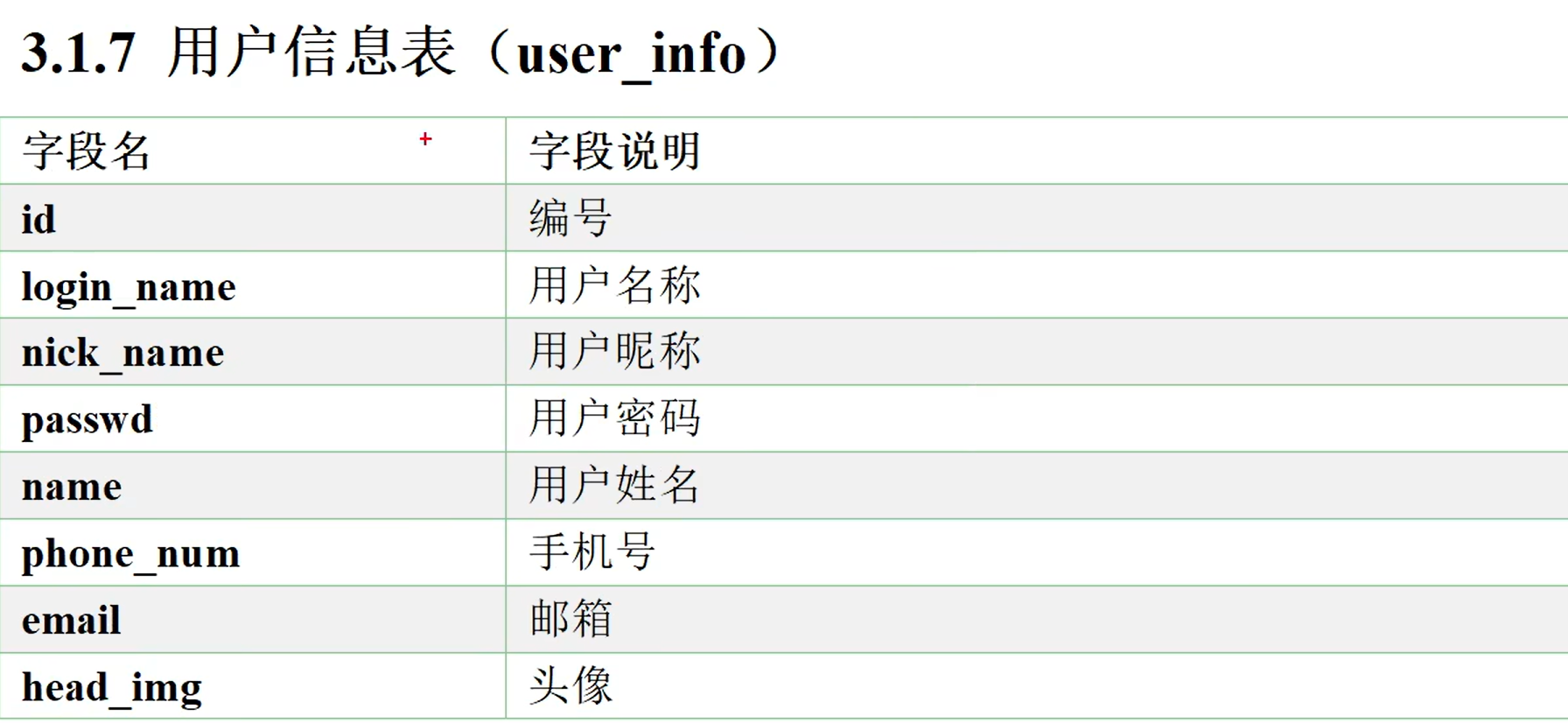
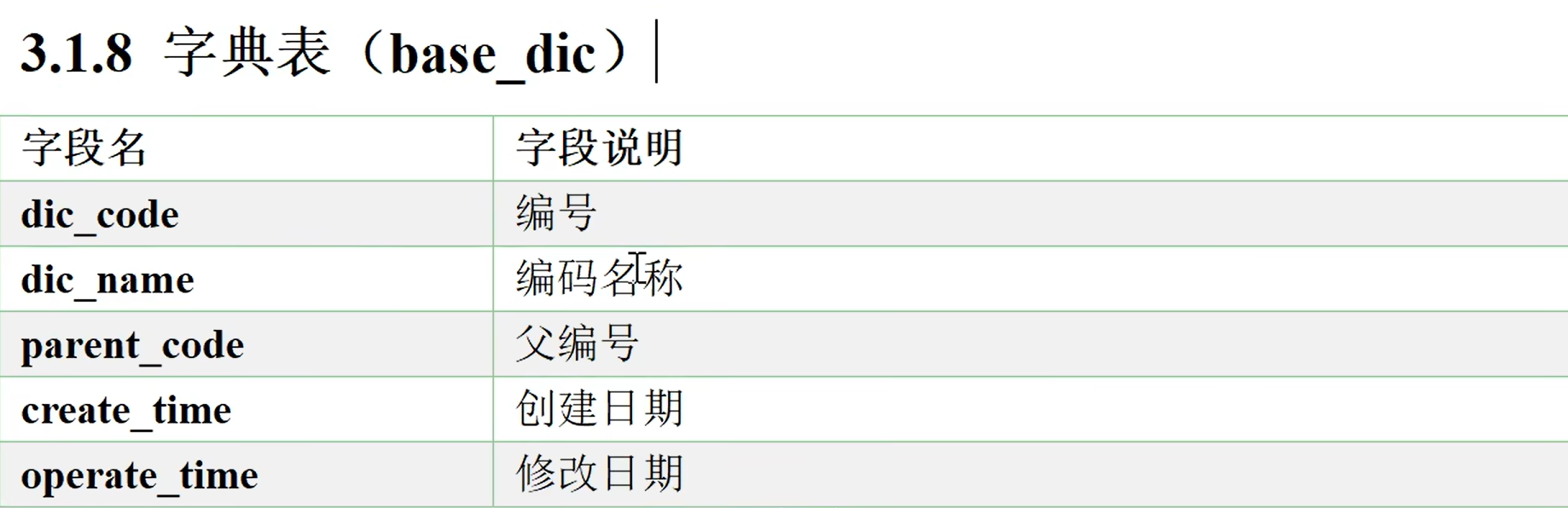
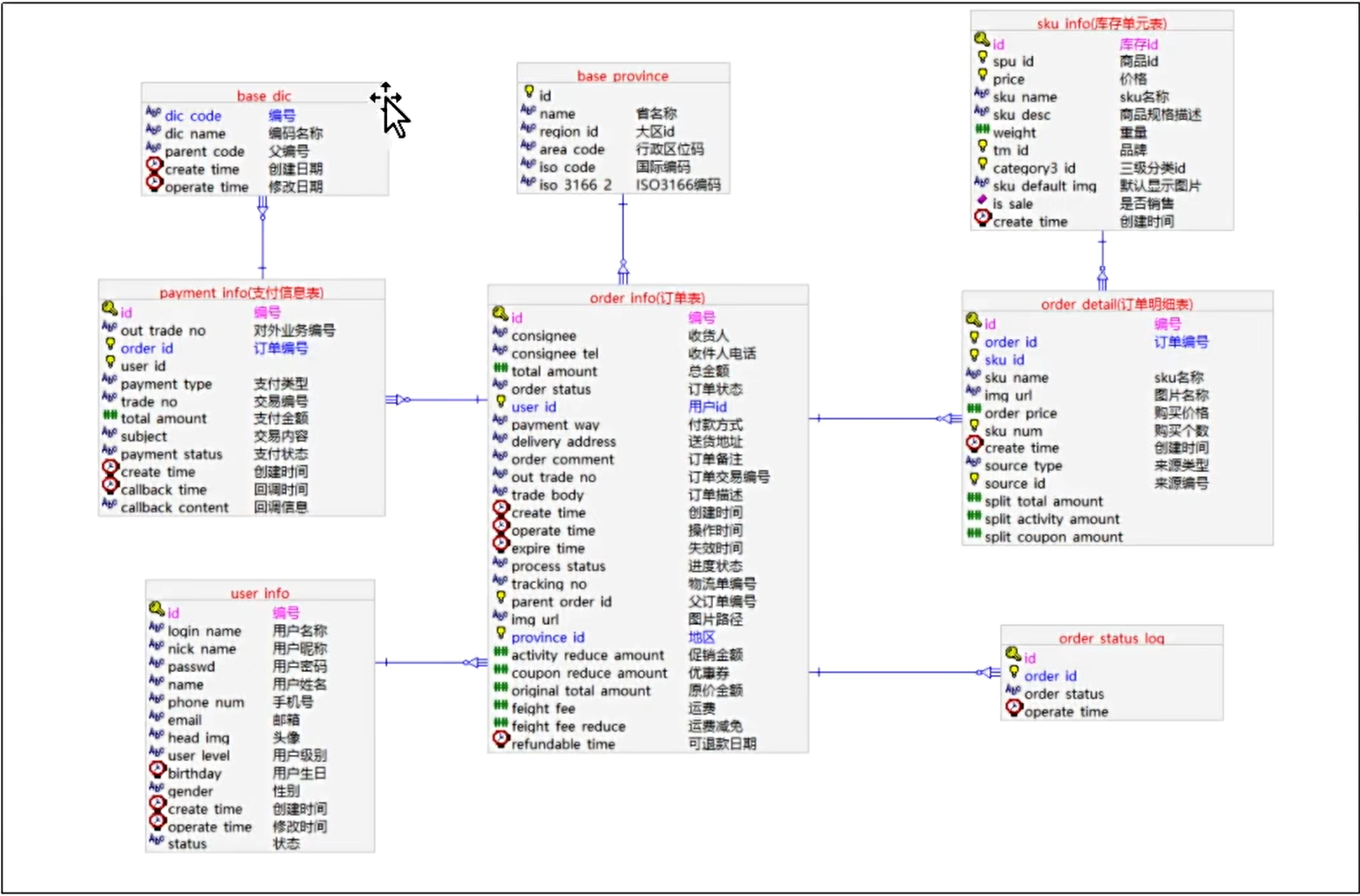
业务表格
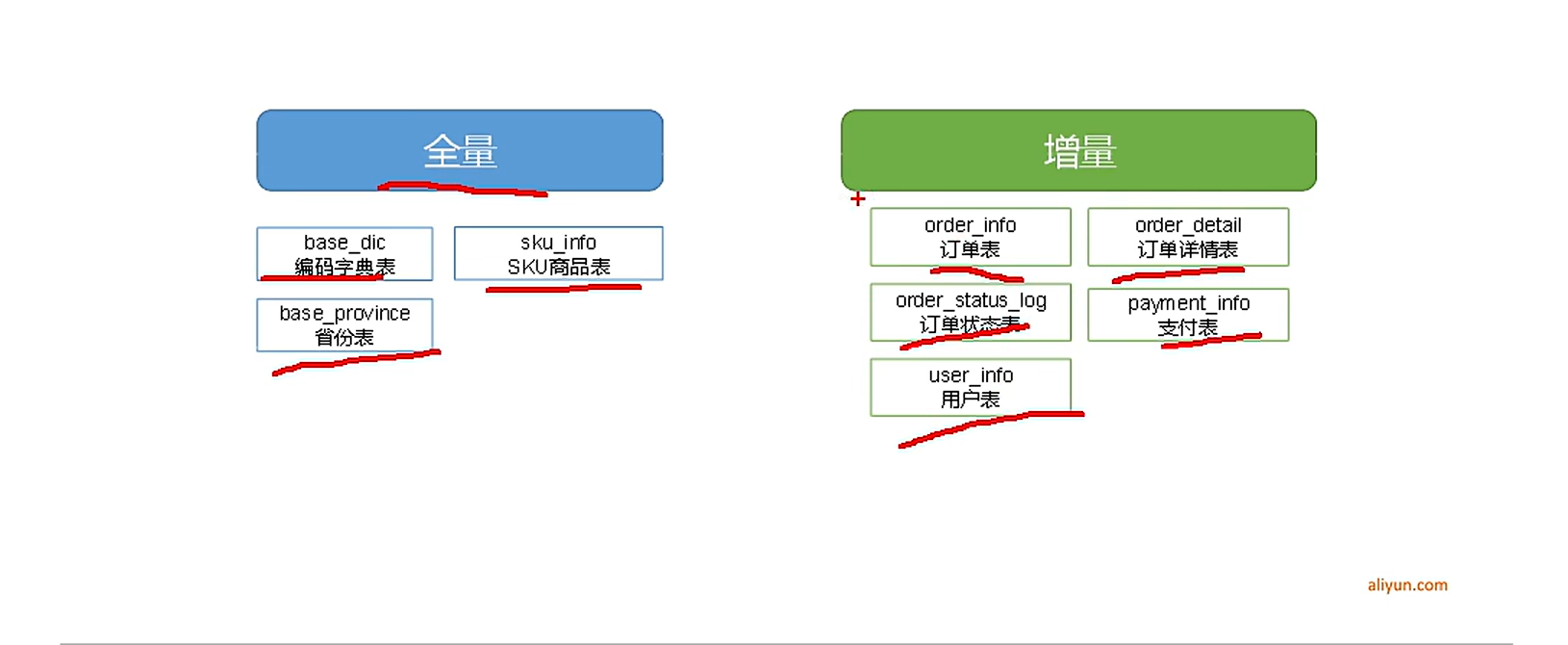
需要的业务表
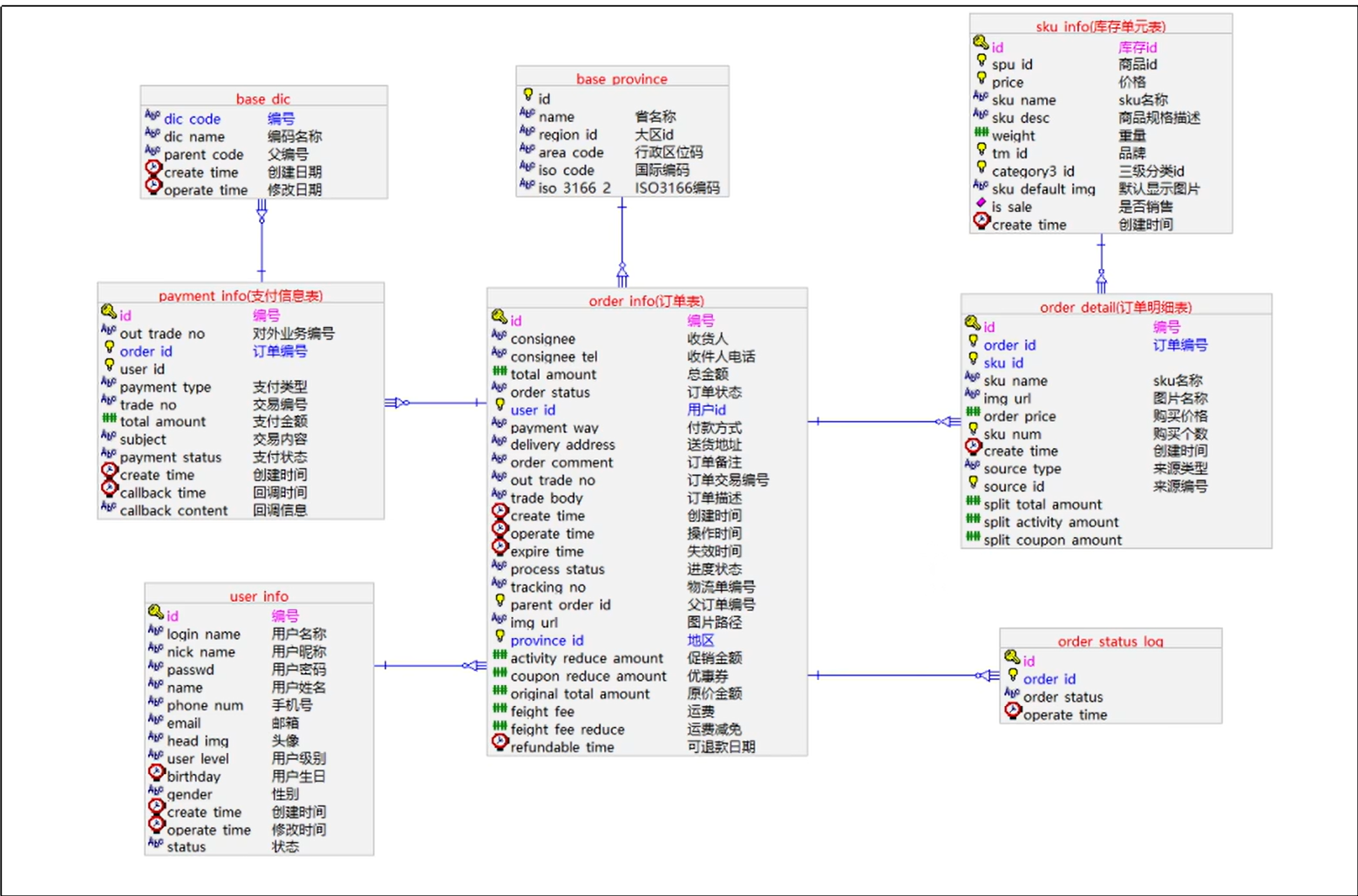
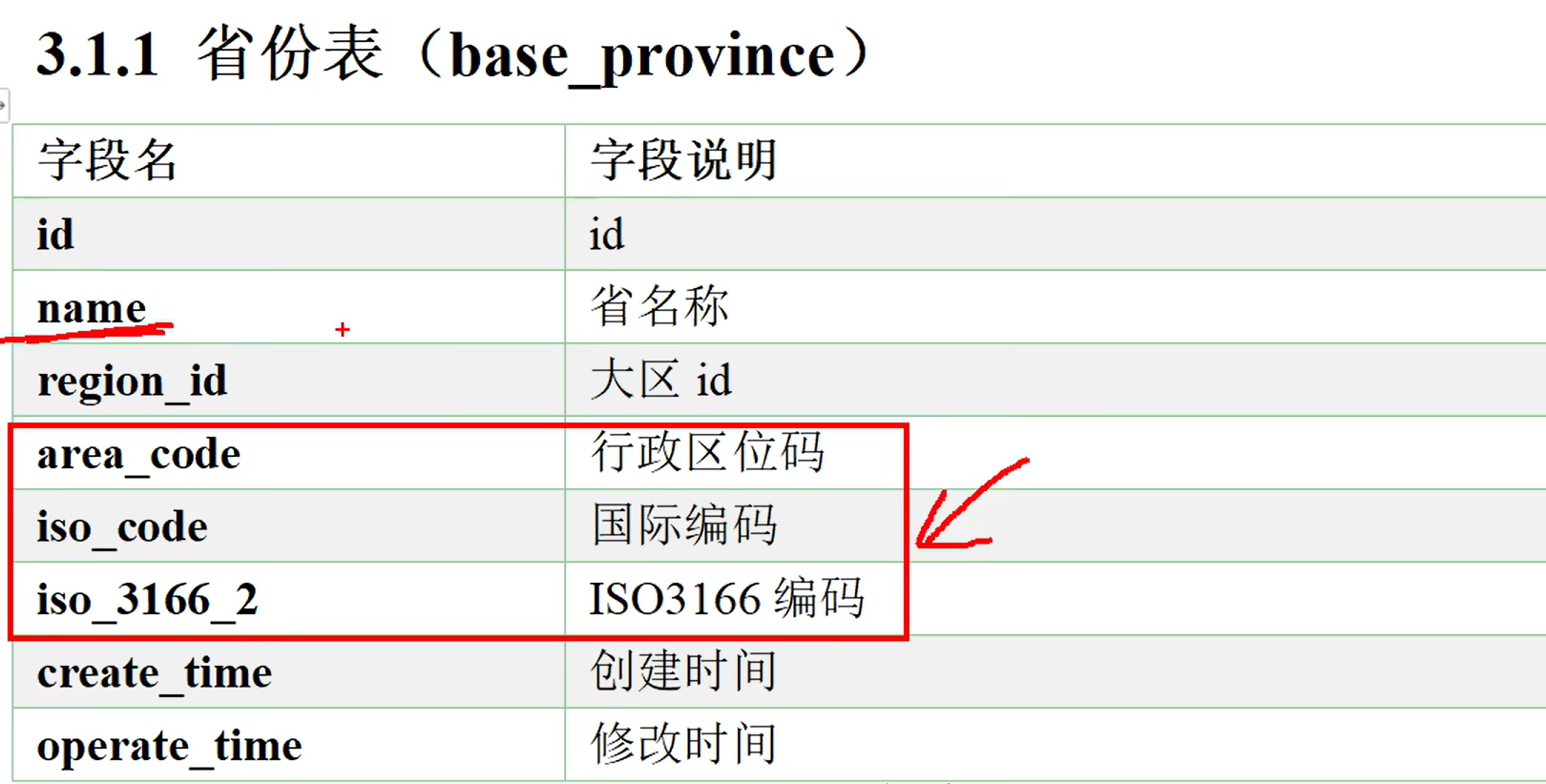
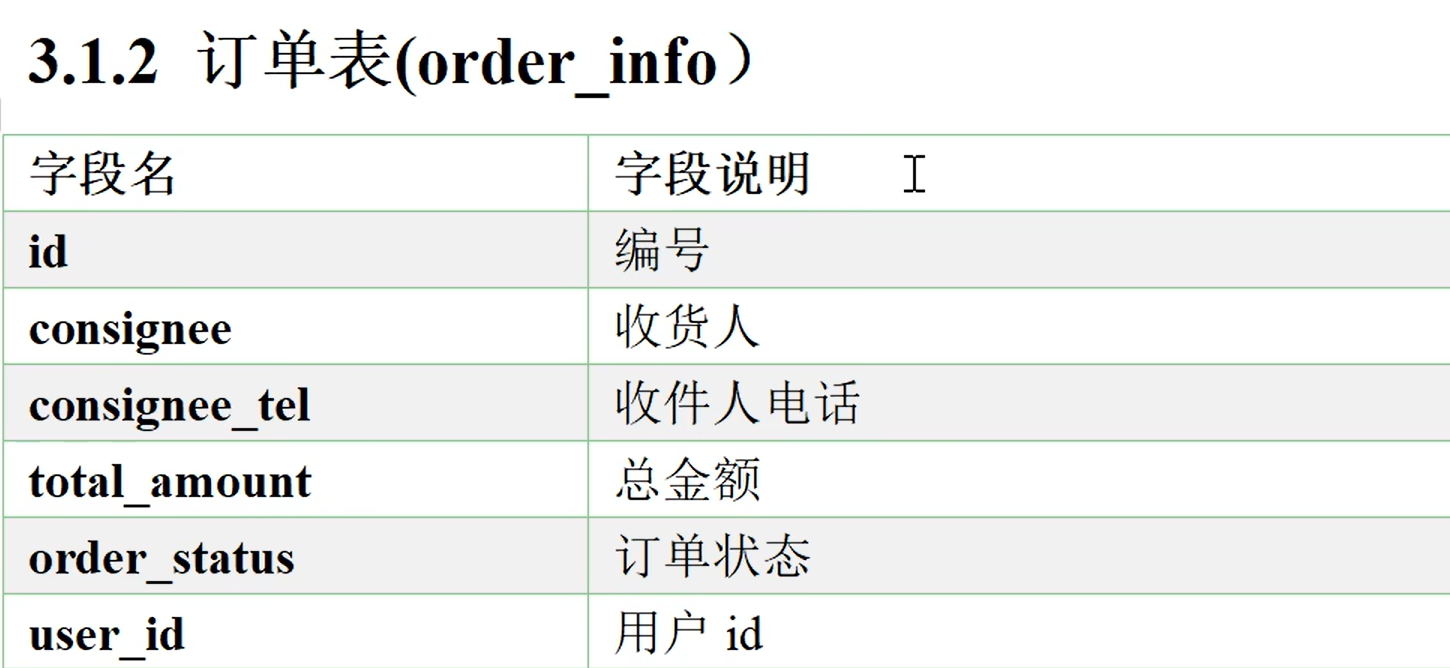
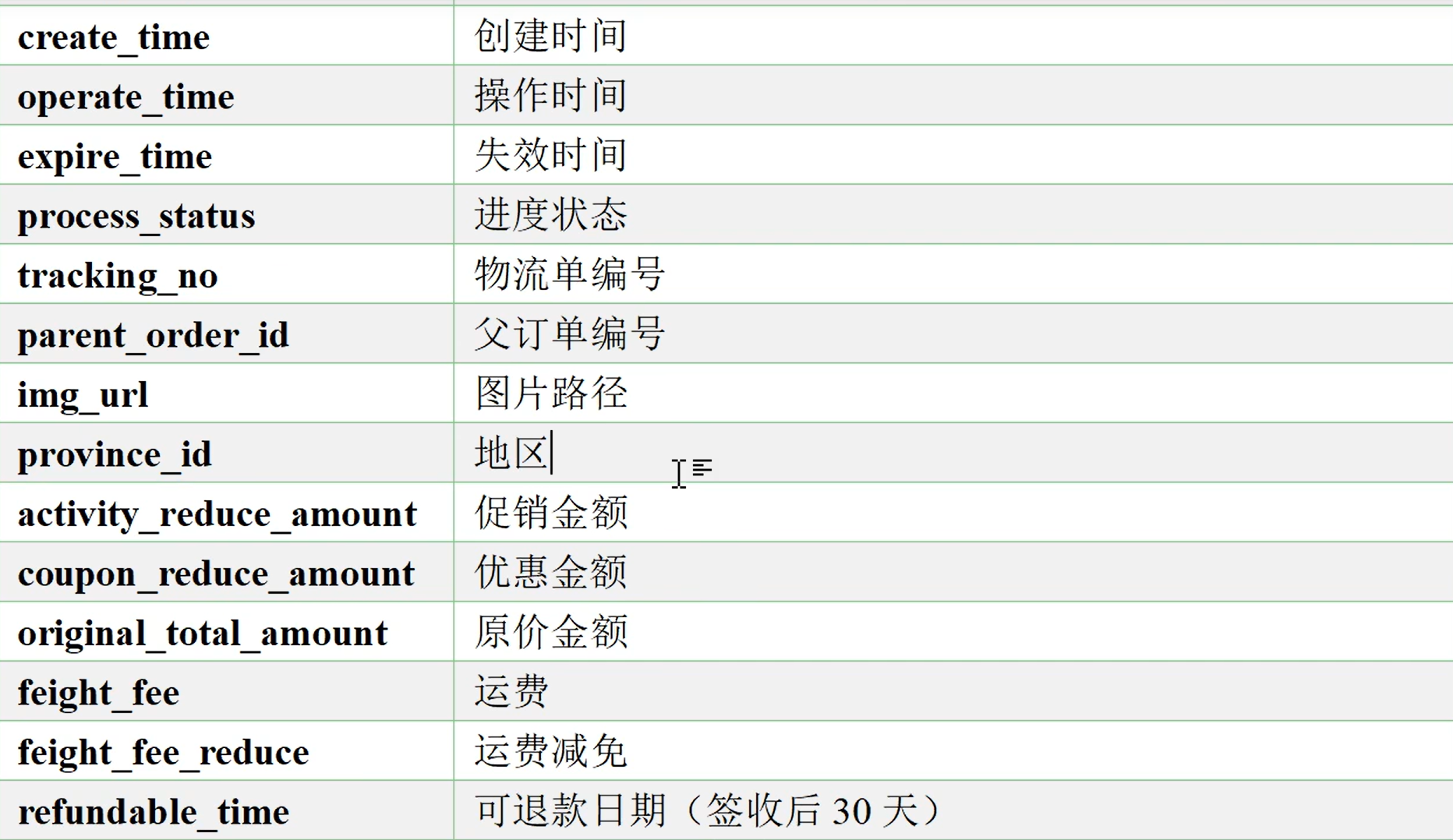

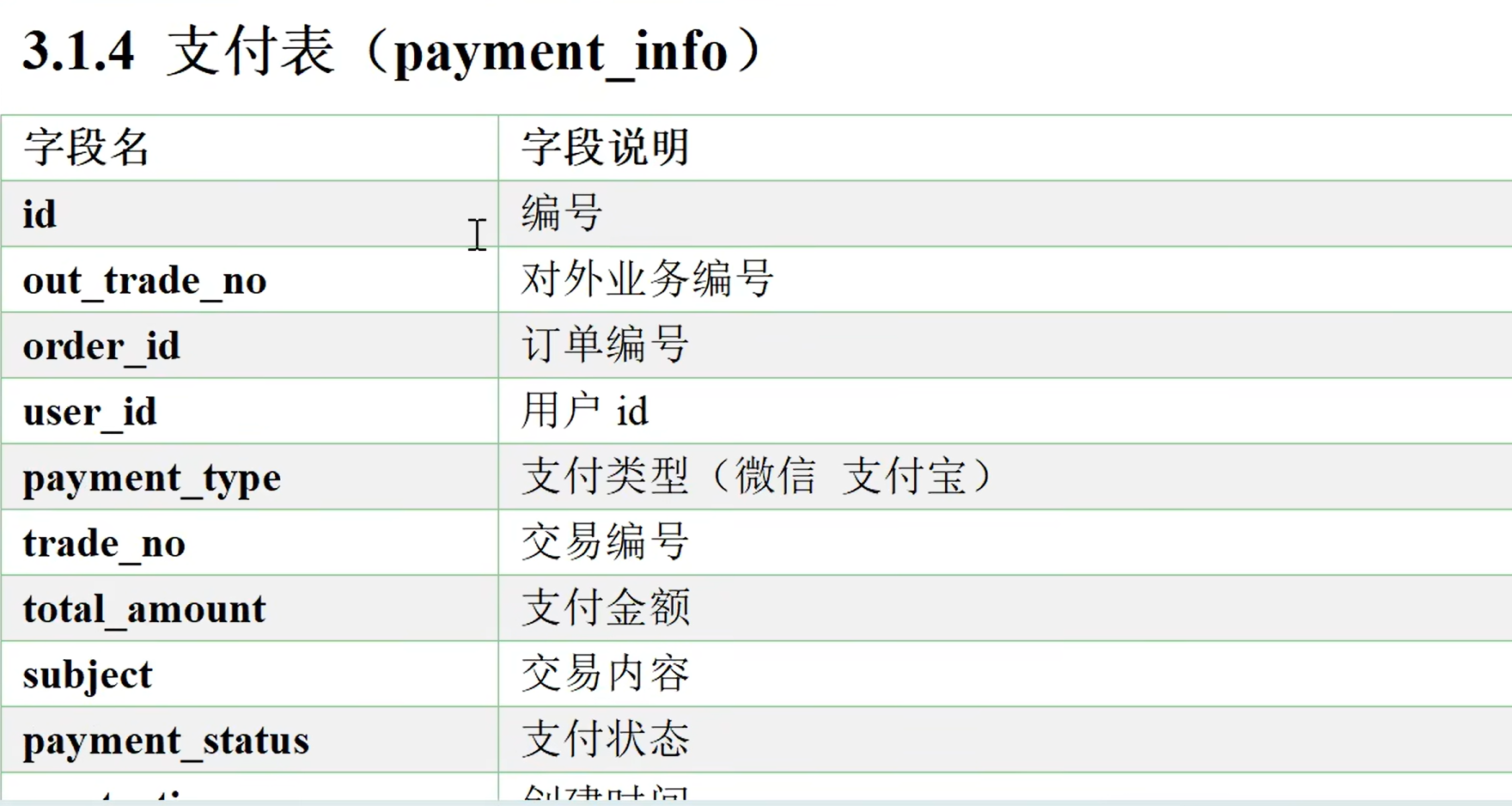
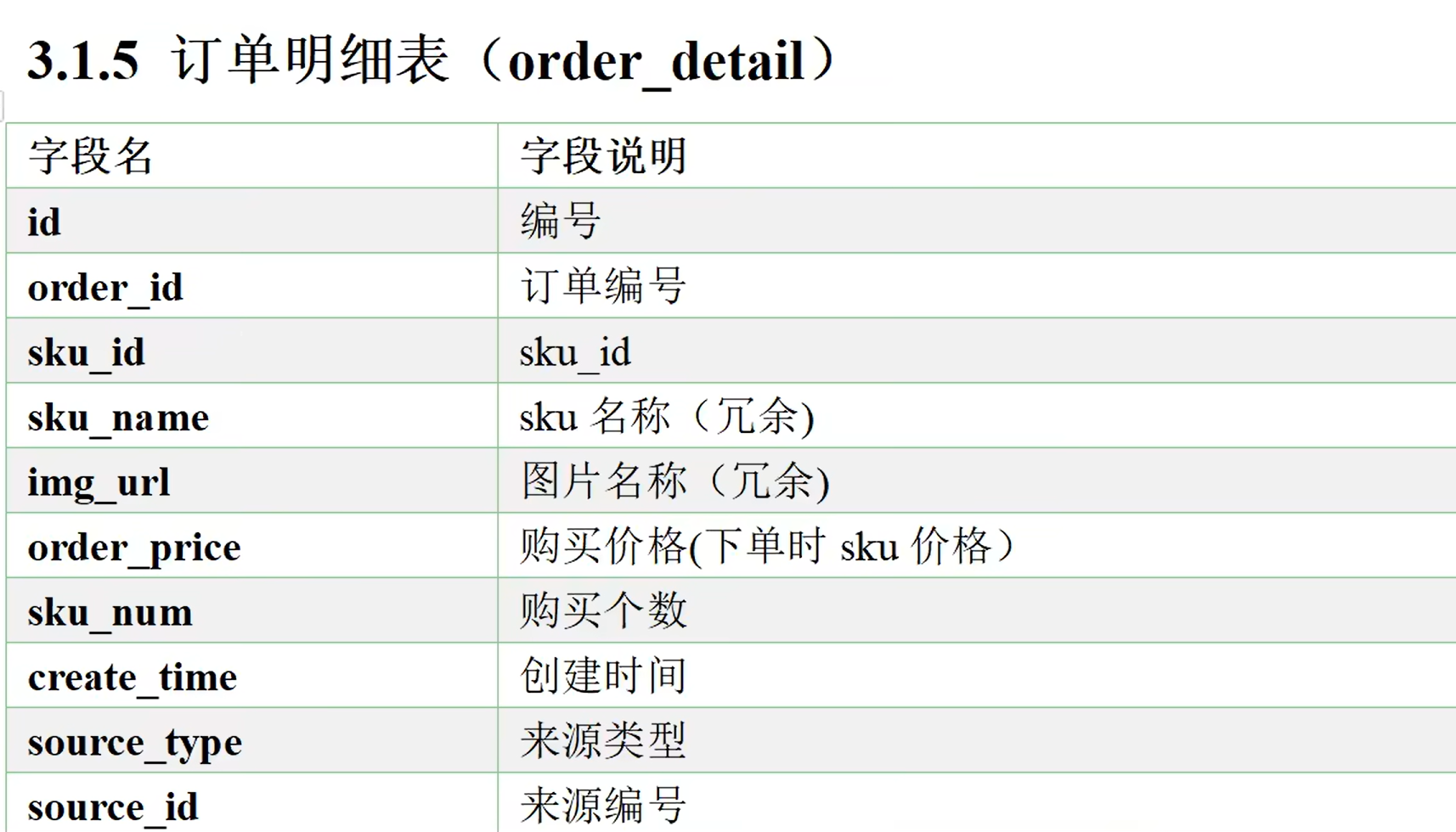
假设现在在你的数据库mysql或者RDS中已经有了上面那些表,现在需要将这些数据按照一定的规则同步到数仓里面

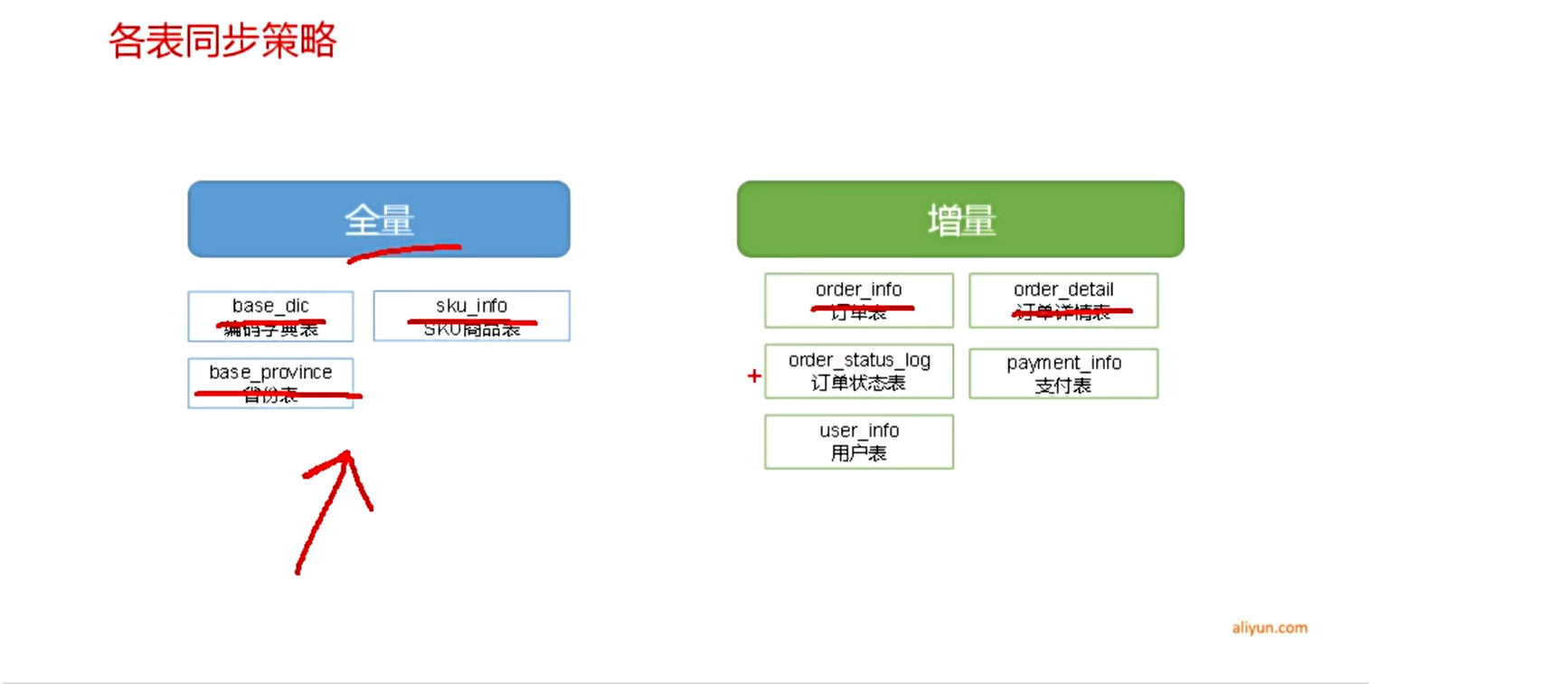
根据对比,可以得出以下结论:
通常情况,业务表数据量比较大,优先考虑增量,数据量比较小,优先考虑全量
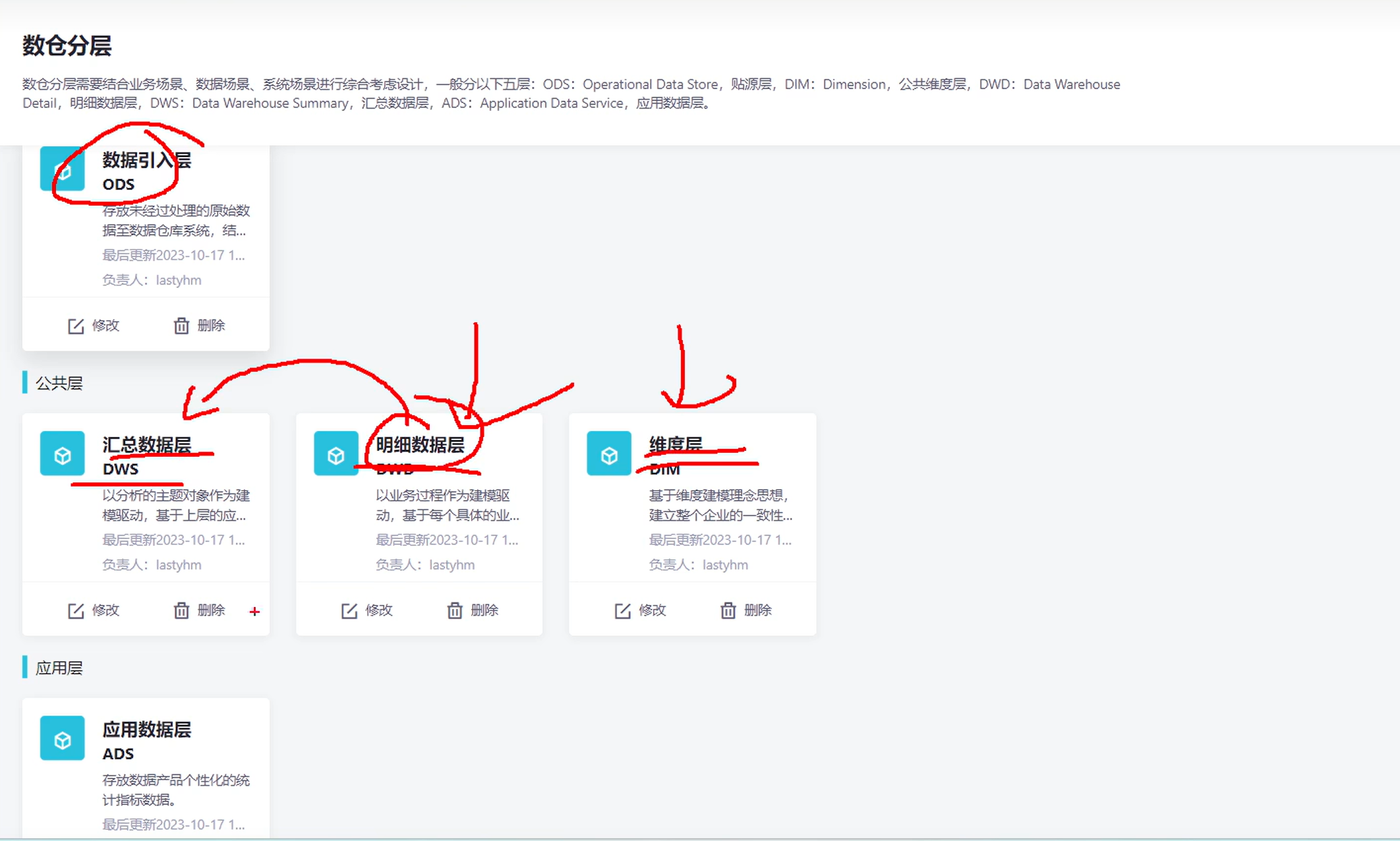
下面开始进行建模
说明: 数仓建模工具是直接嵌套在dataworks里面的
回到阿里云页面,如下操作进入建模
此时进入到该页面
刚开始进来啥也没有,因为你还没有创建各种模型
需要对做的需求业务进行分类
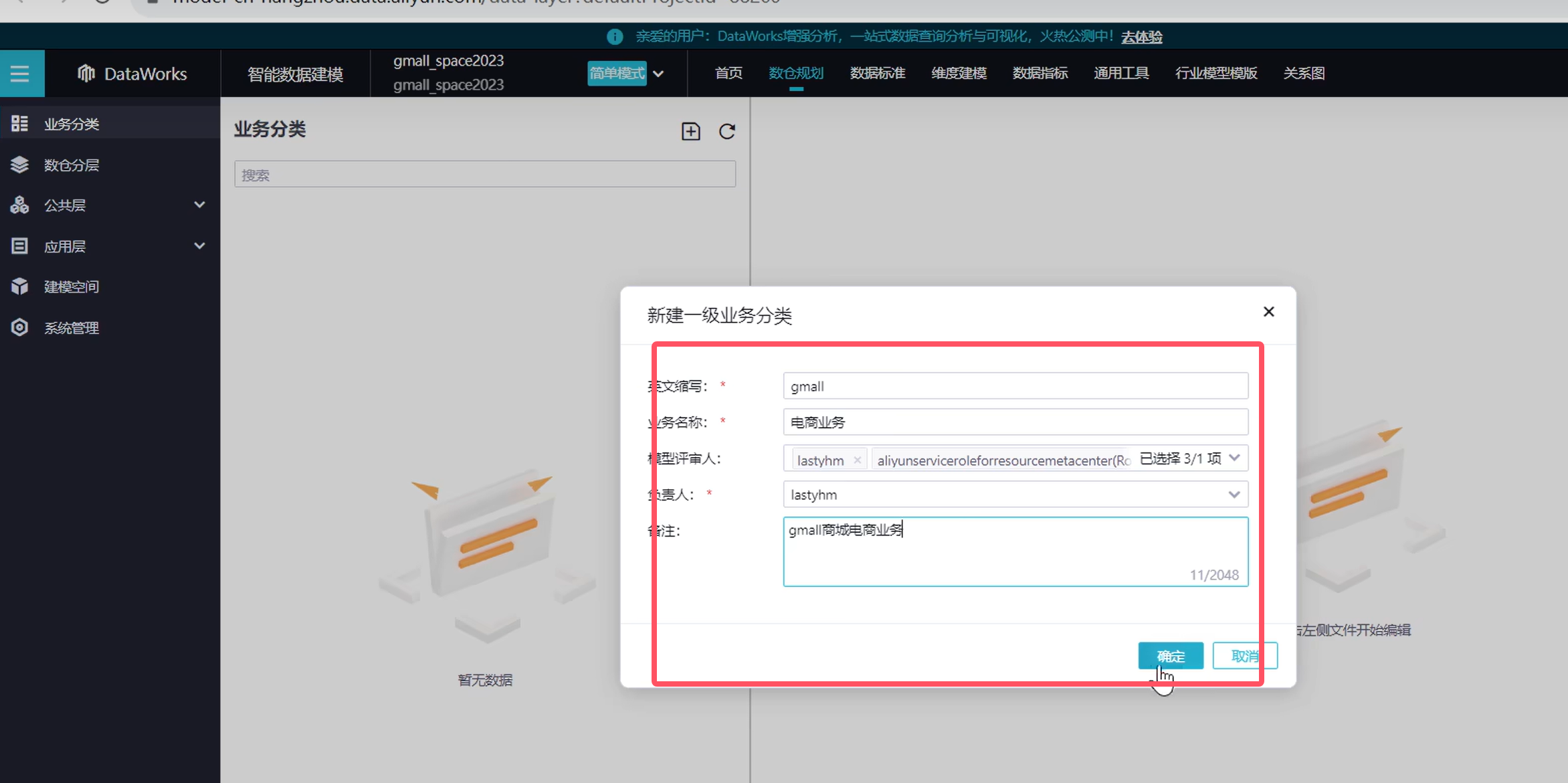
可以看到业务分类创建出来了
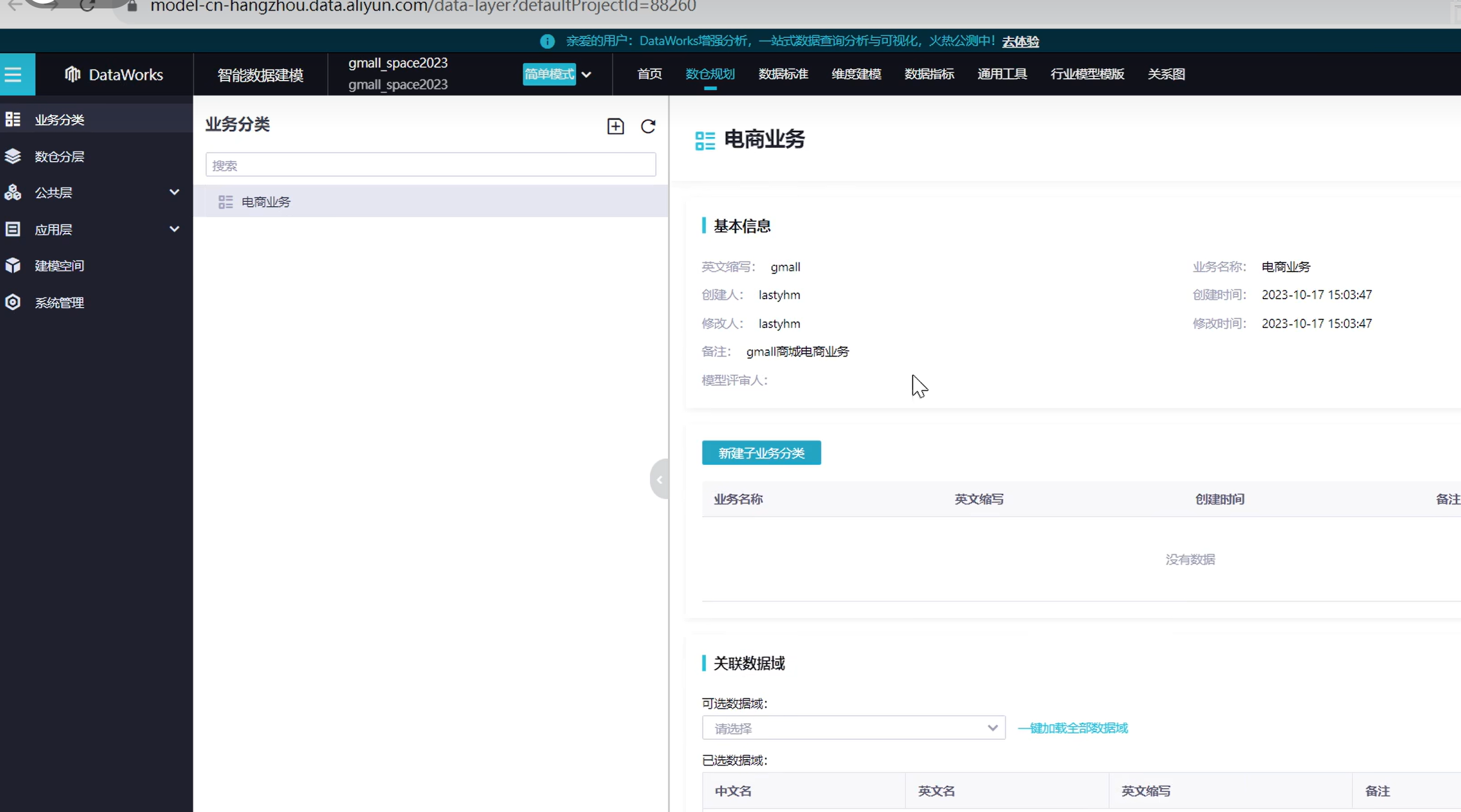
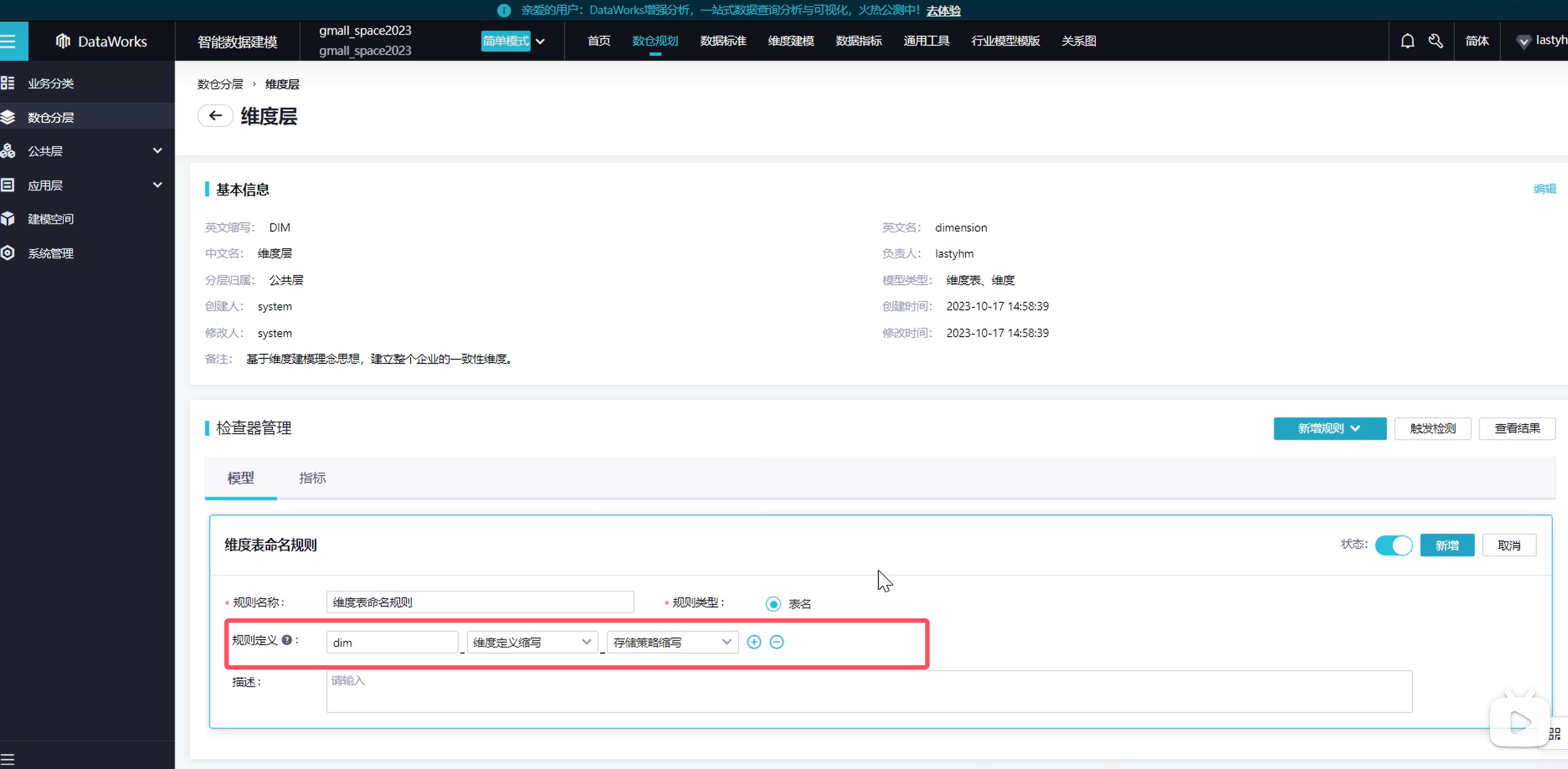
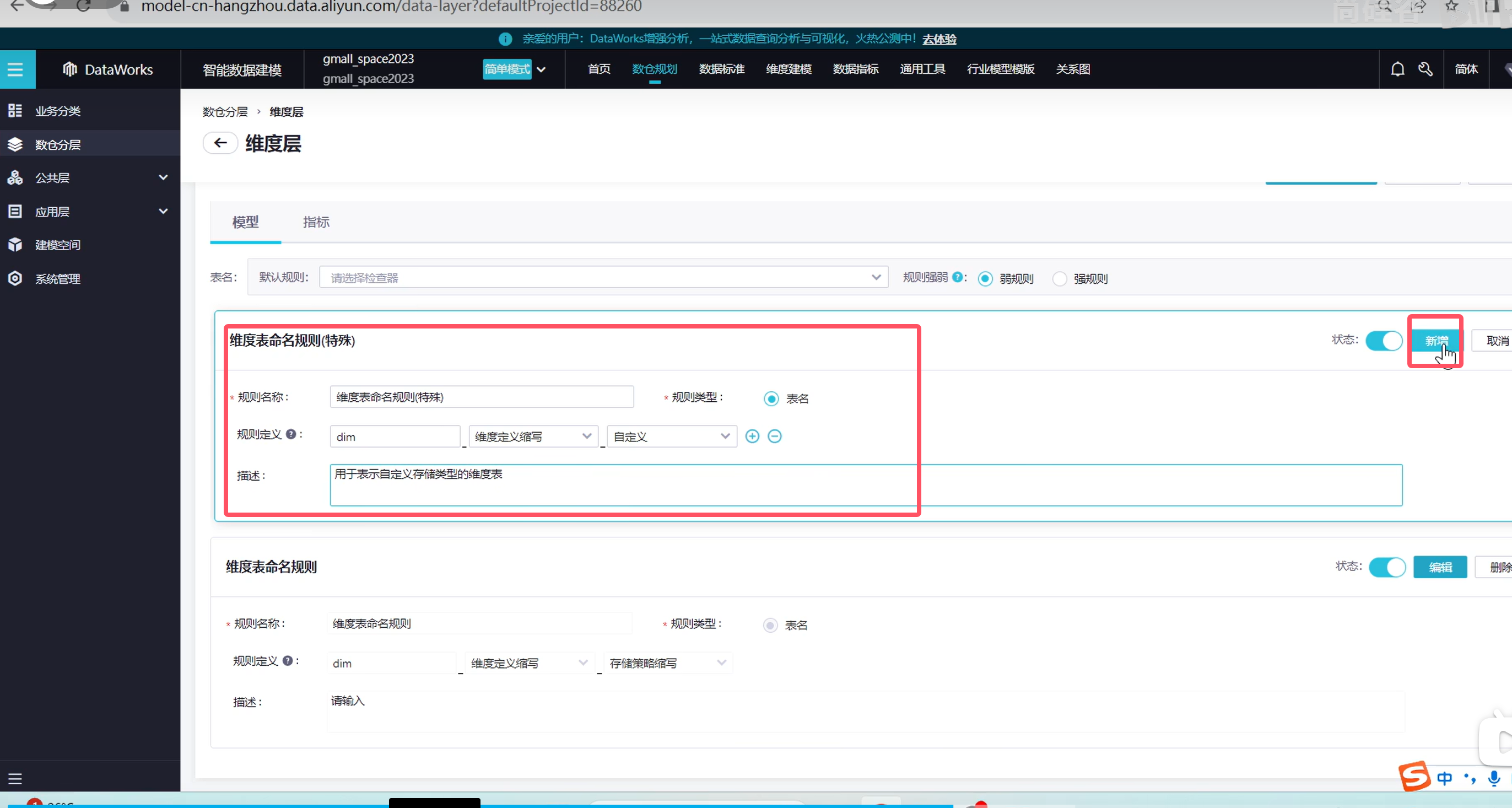
退出,接下来创建明细数据层
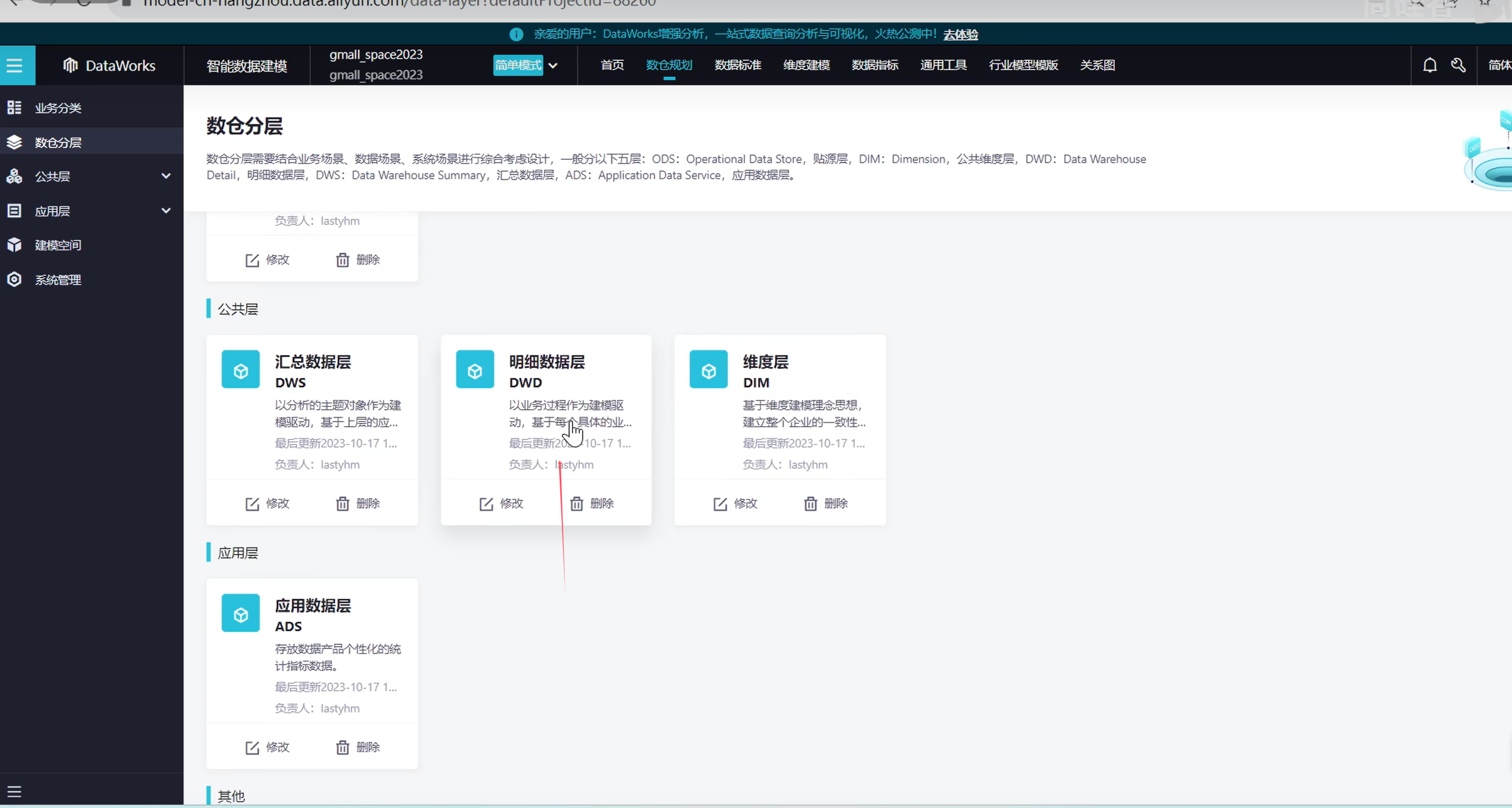

退出,接下来创建数据汇总层
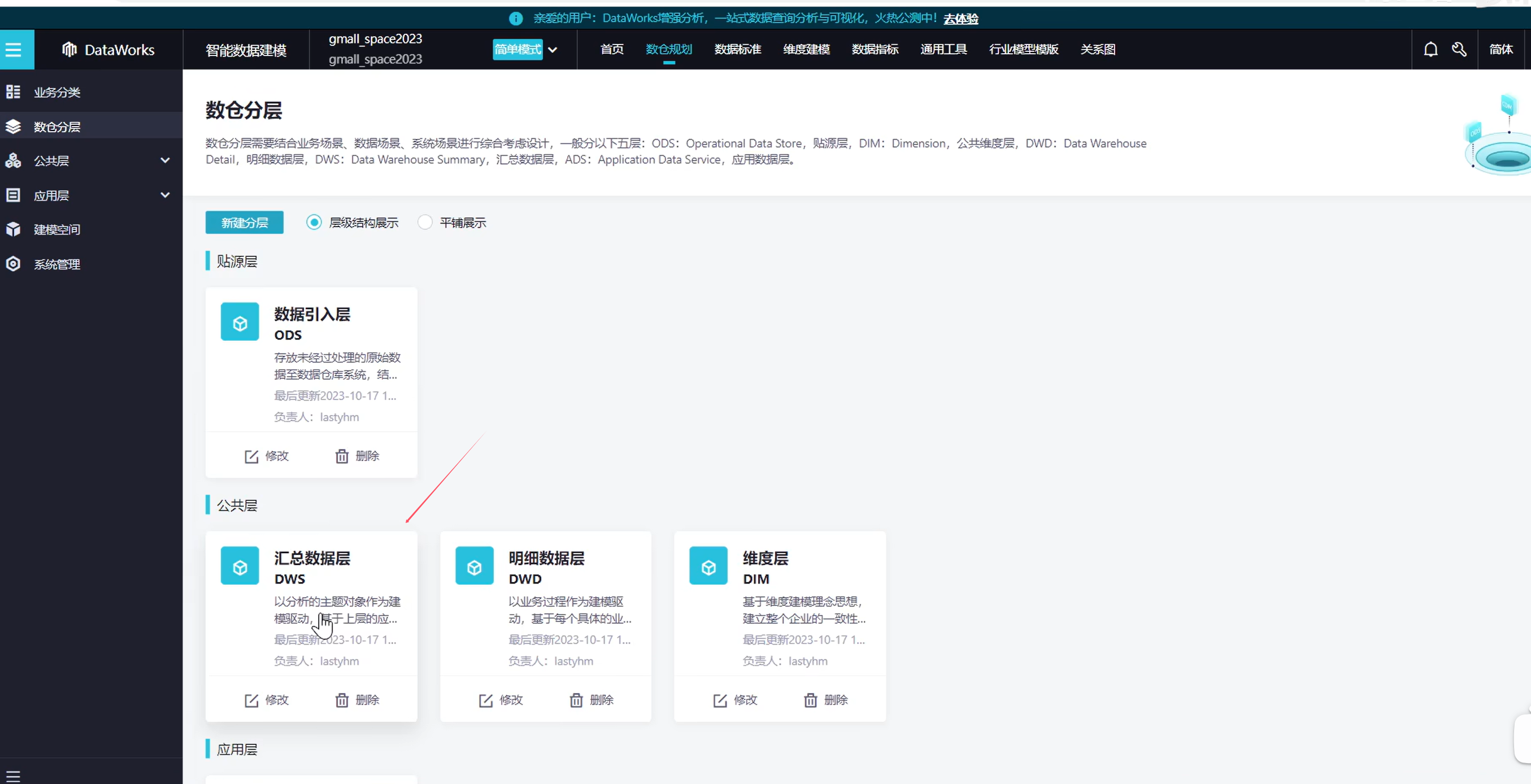
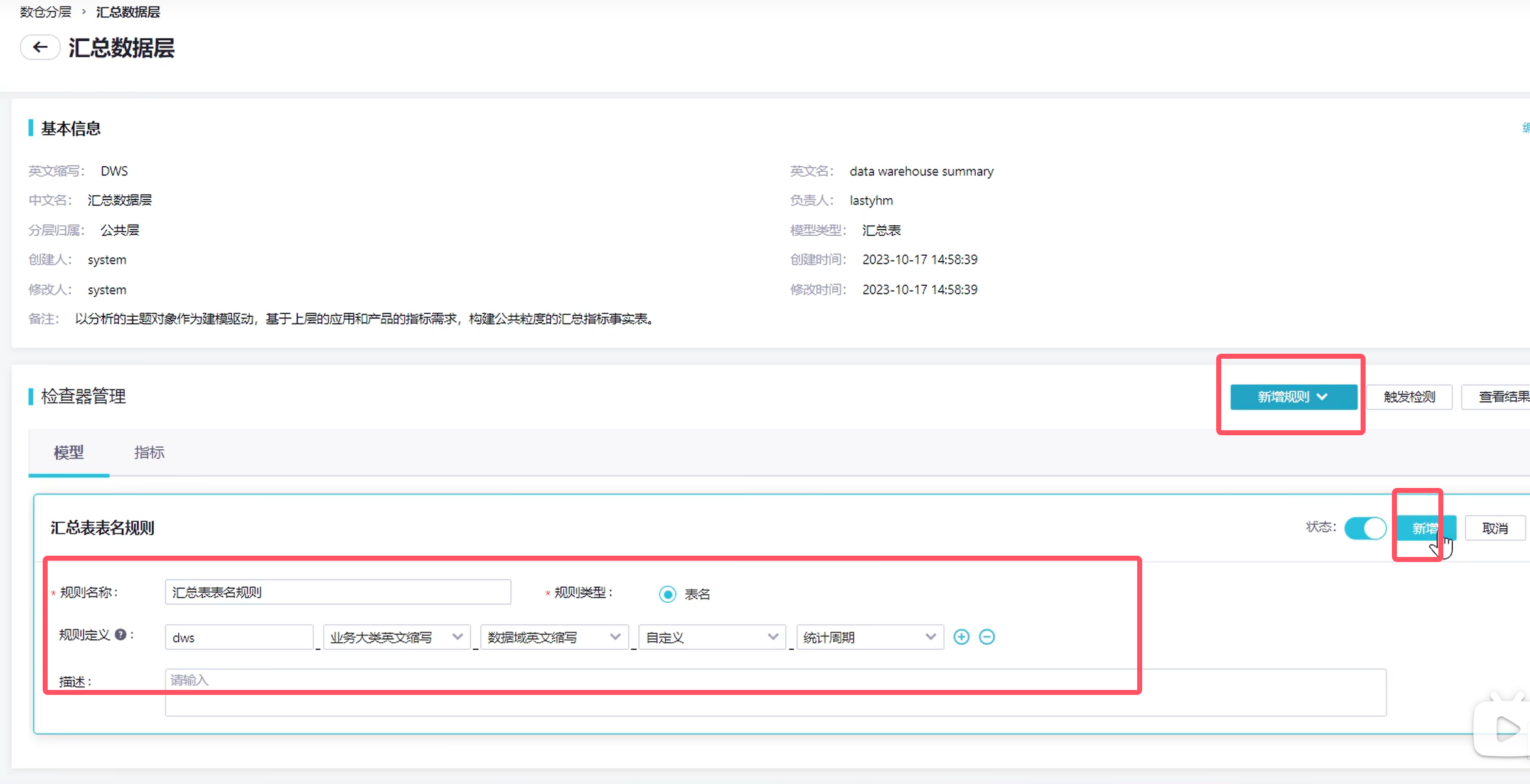
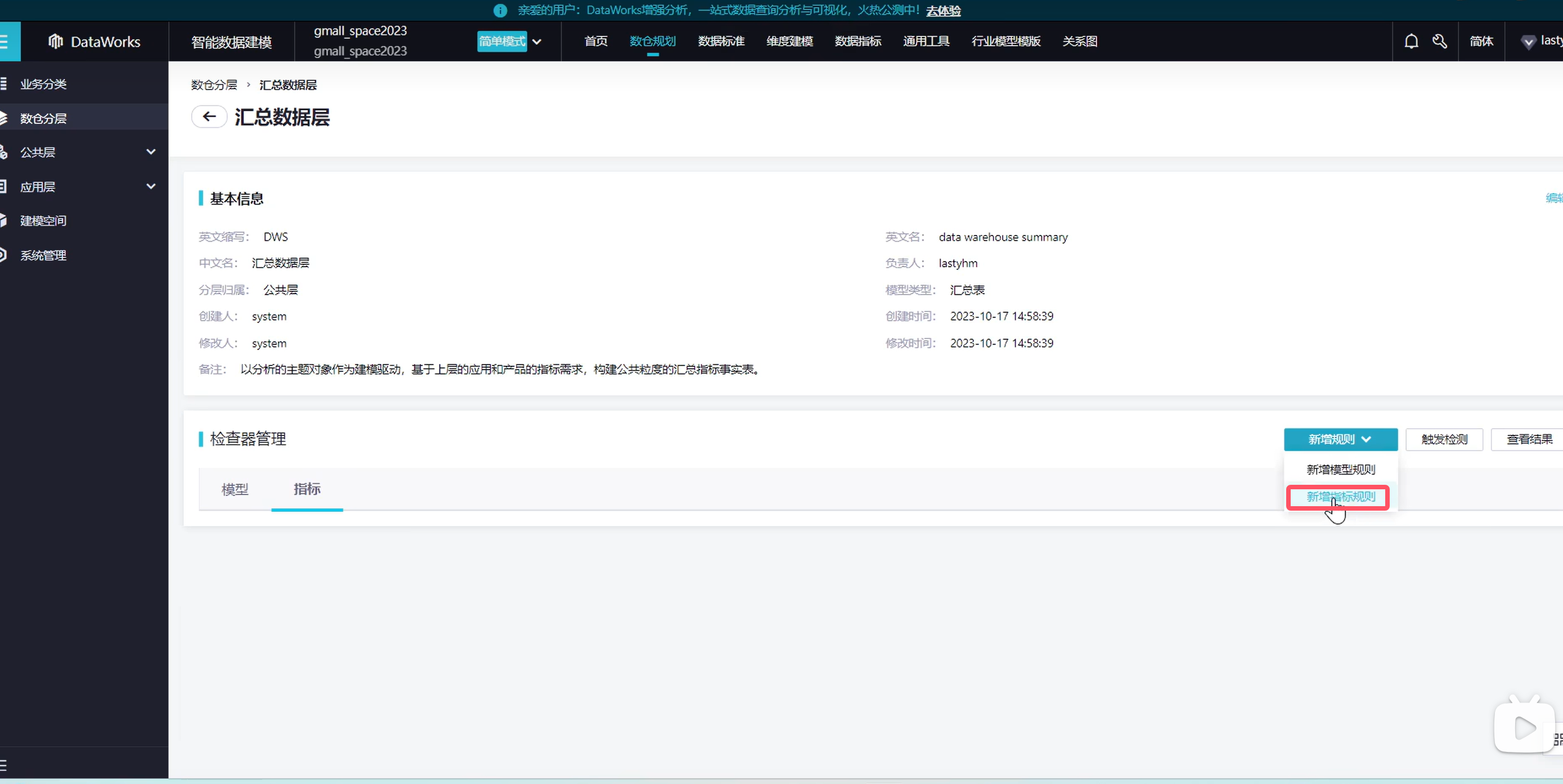
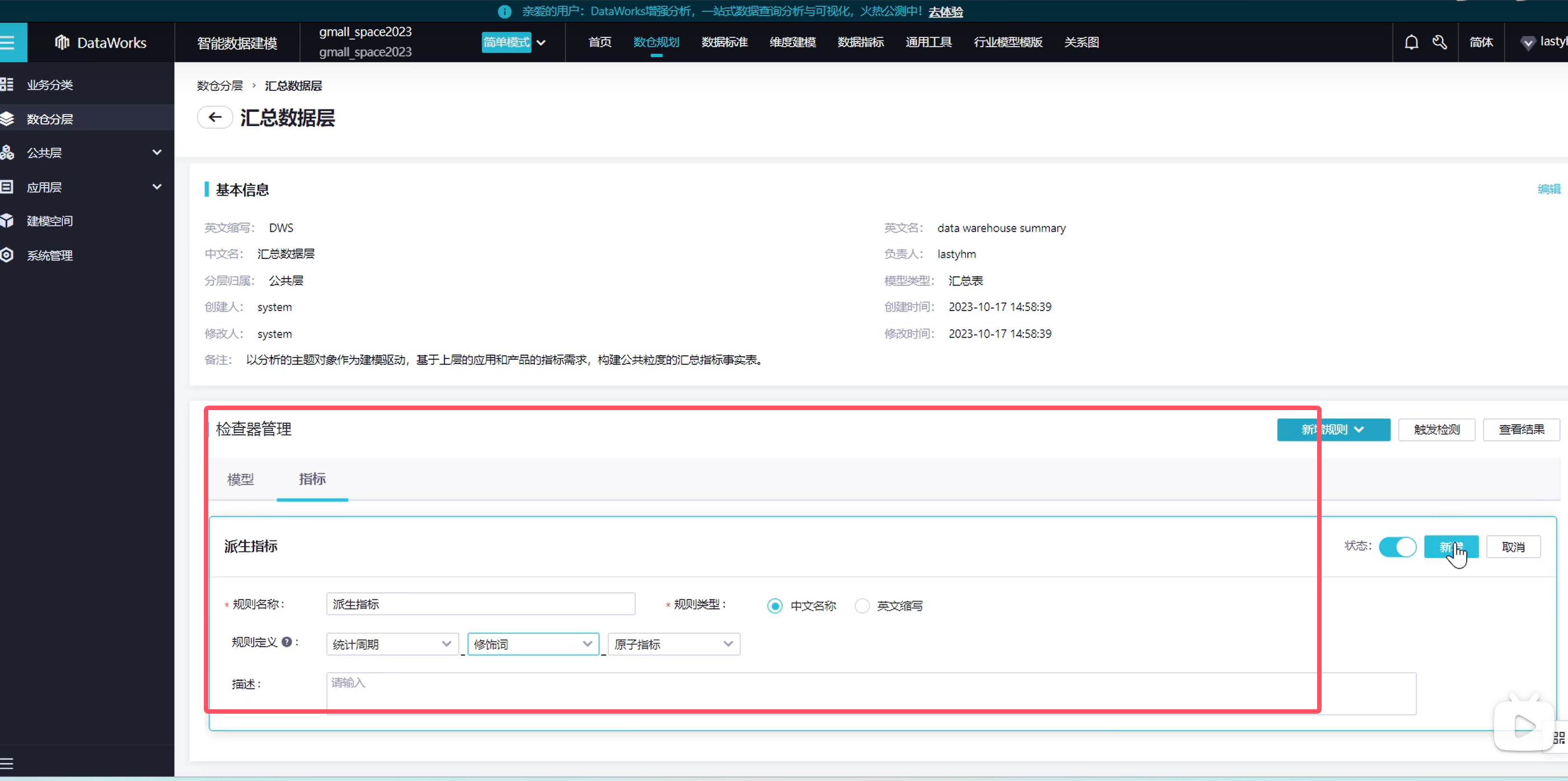
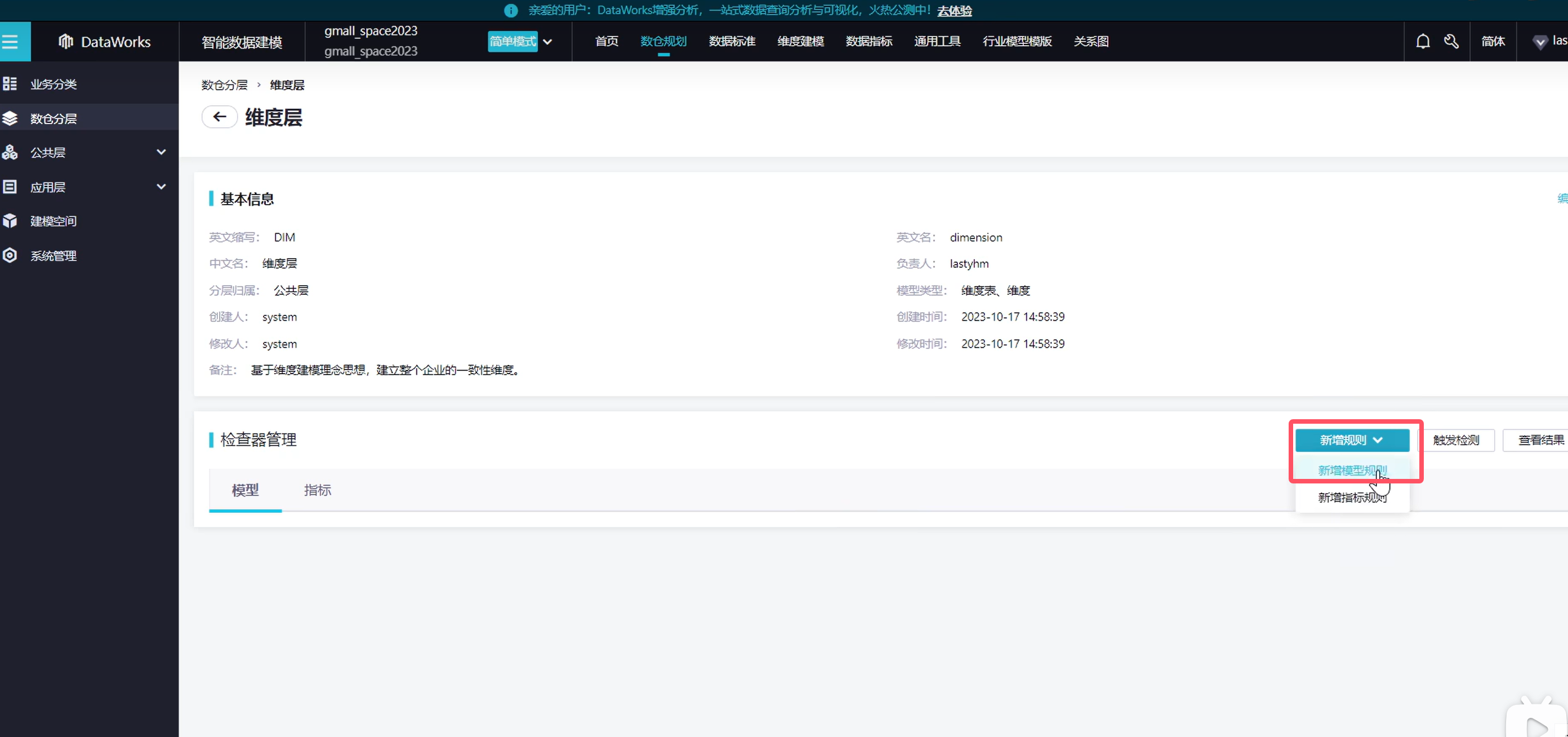
在新建一个指标
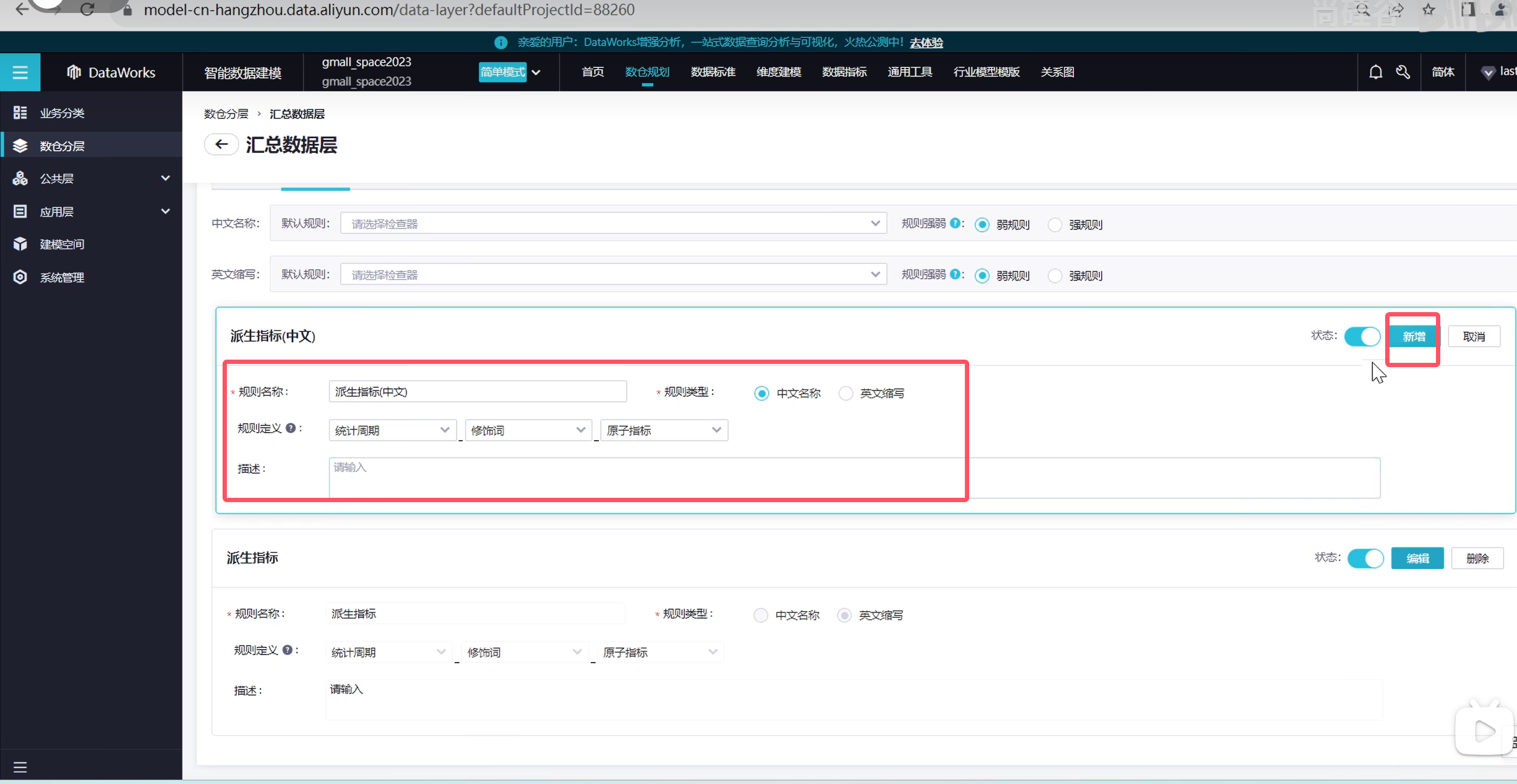
说明一下,模型是指我们的表,指标指的是表里的某个细节
下面操作应用数据层
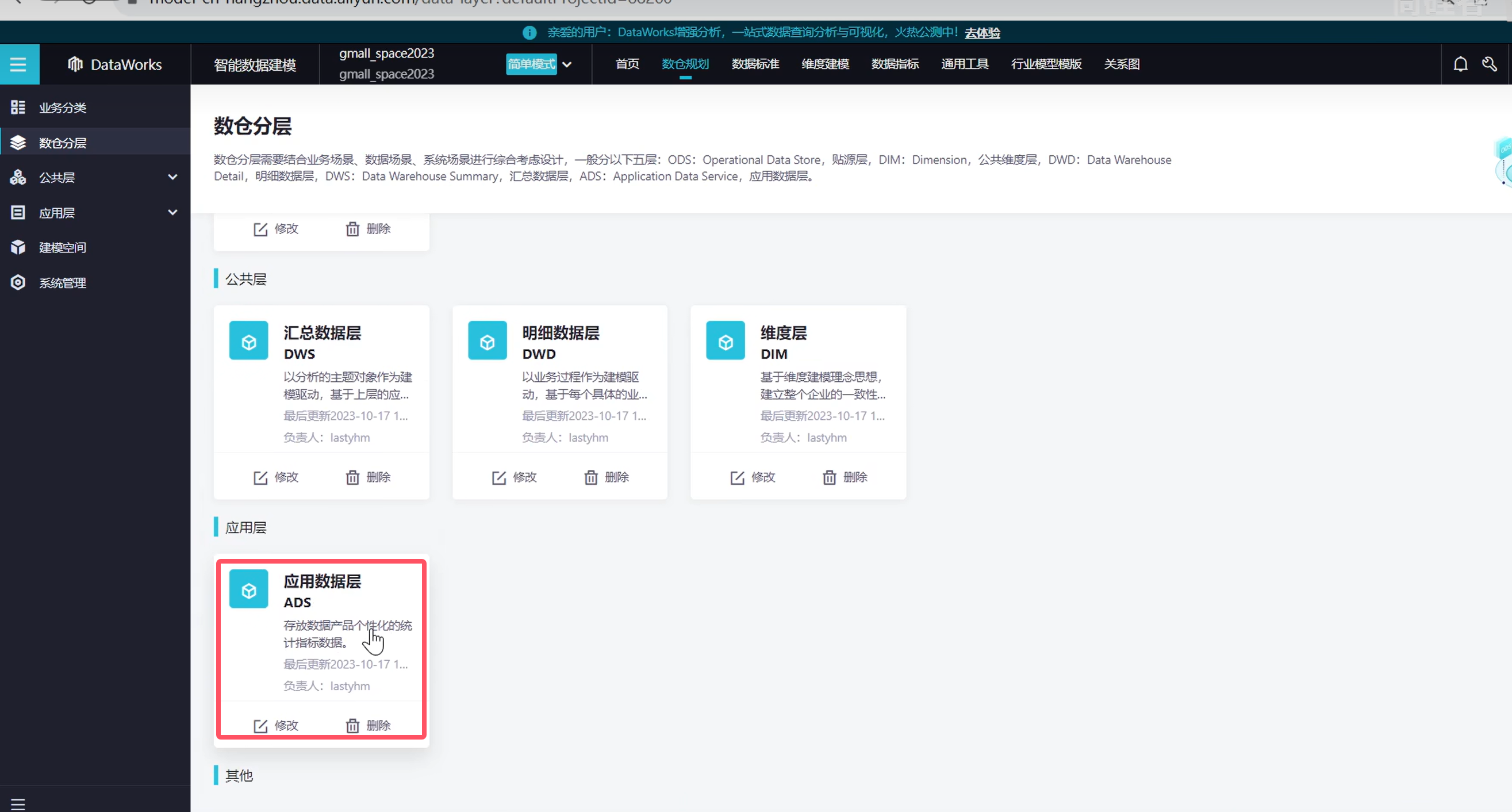
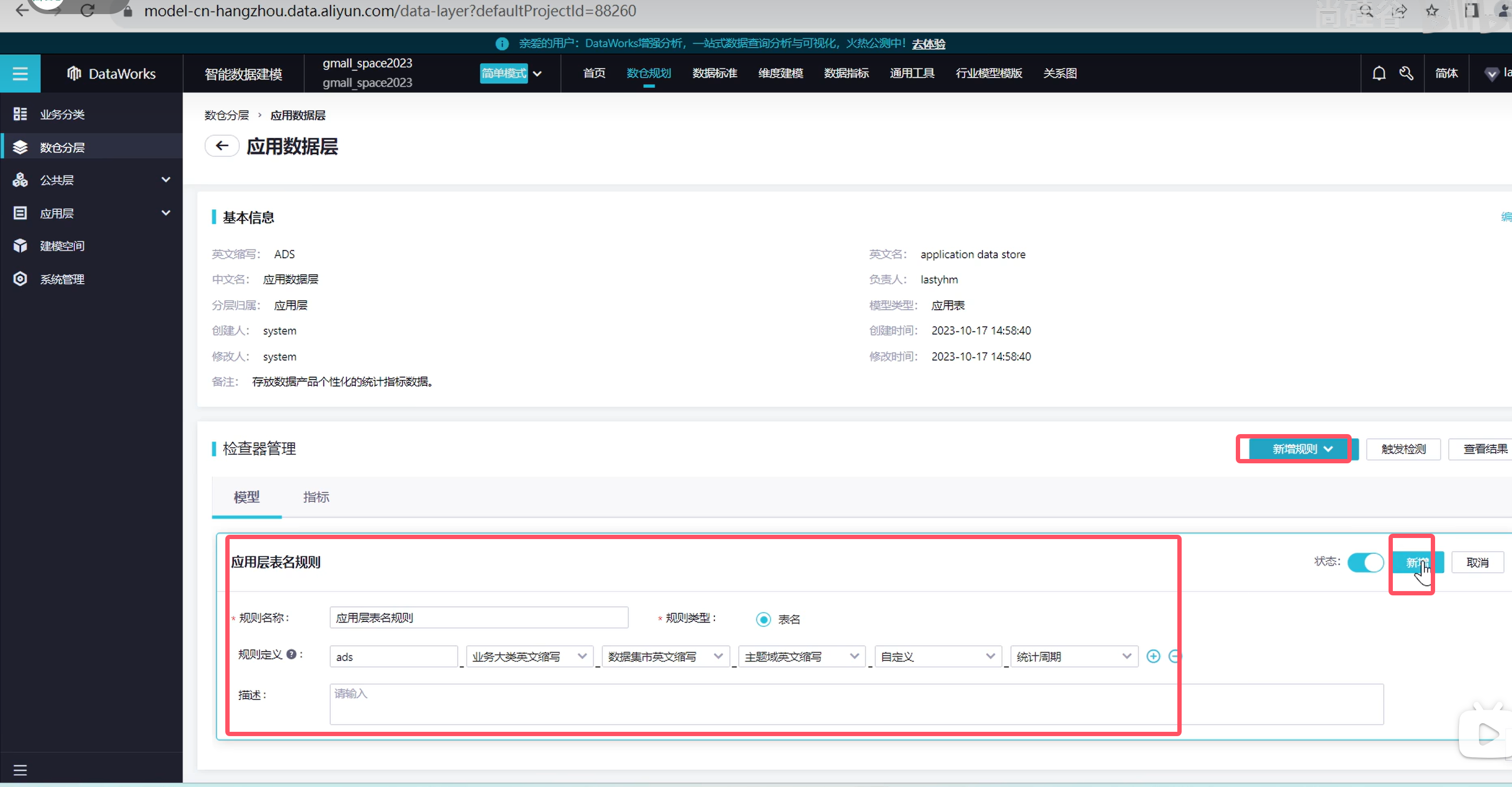
定义数据域
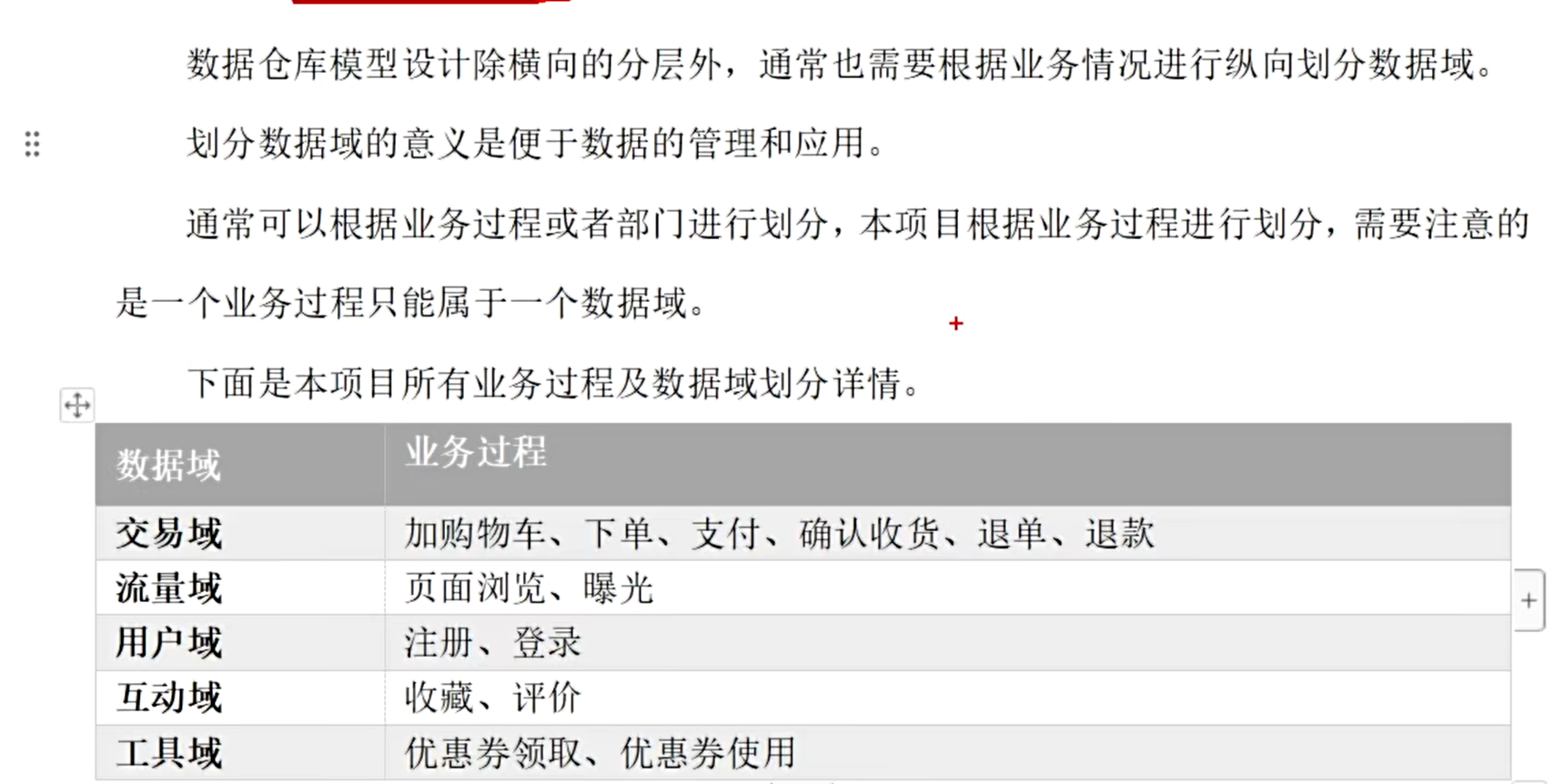
创建数据域
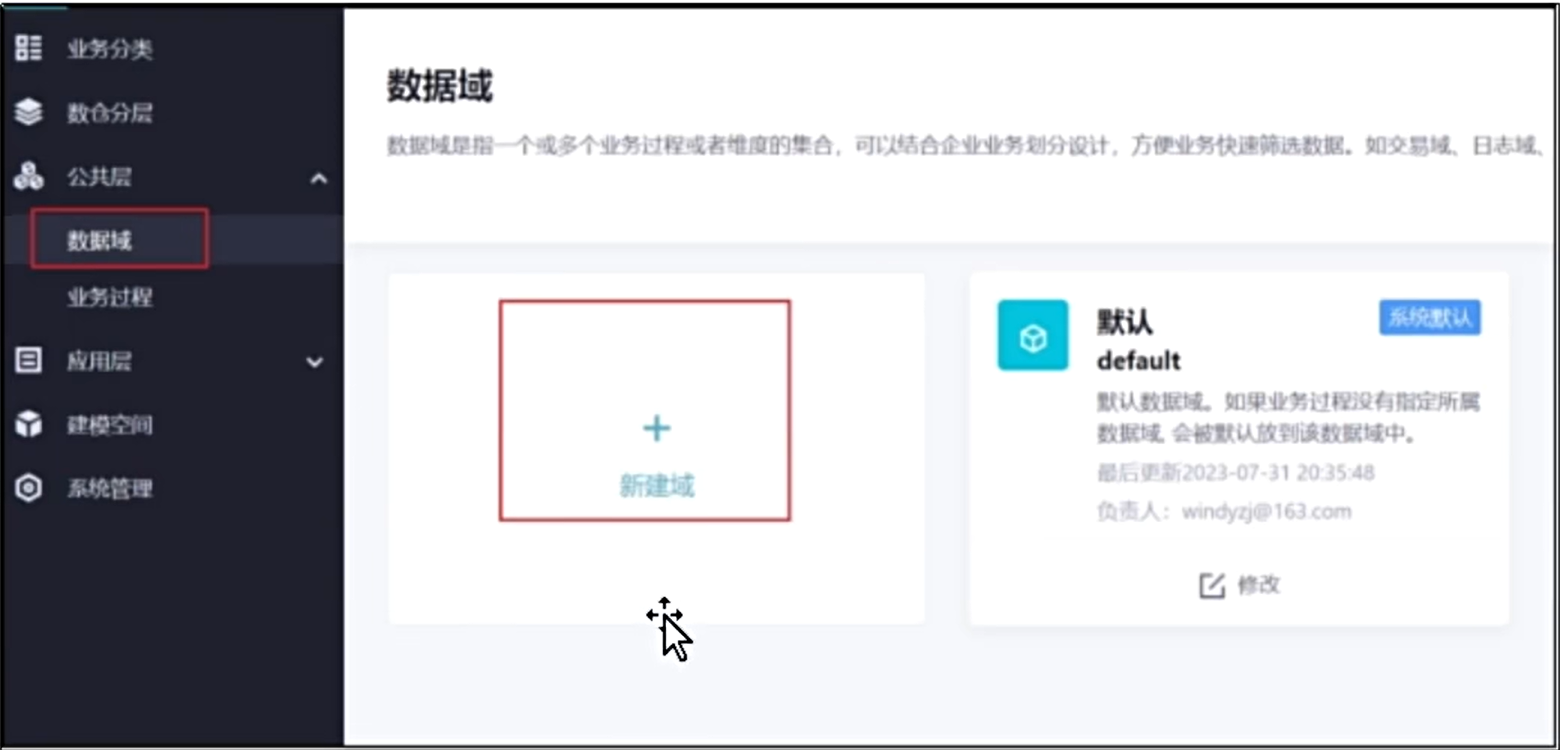
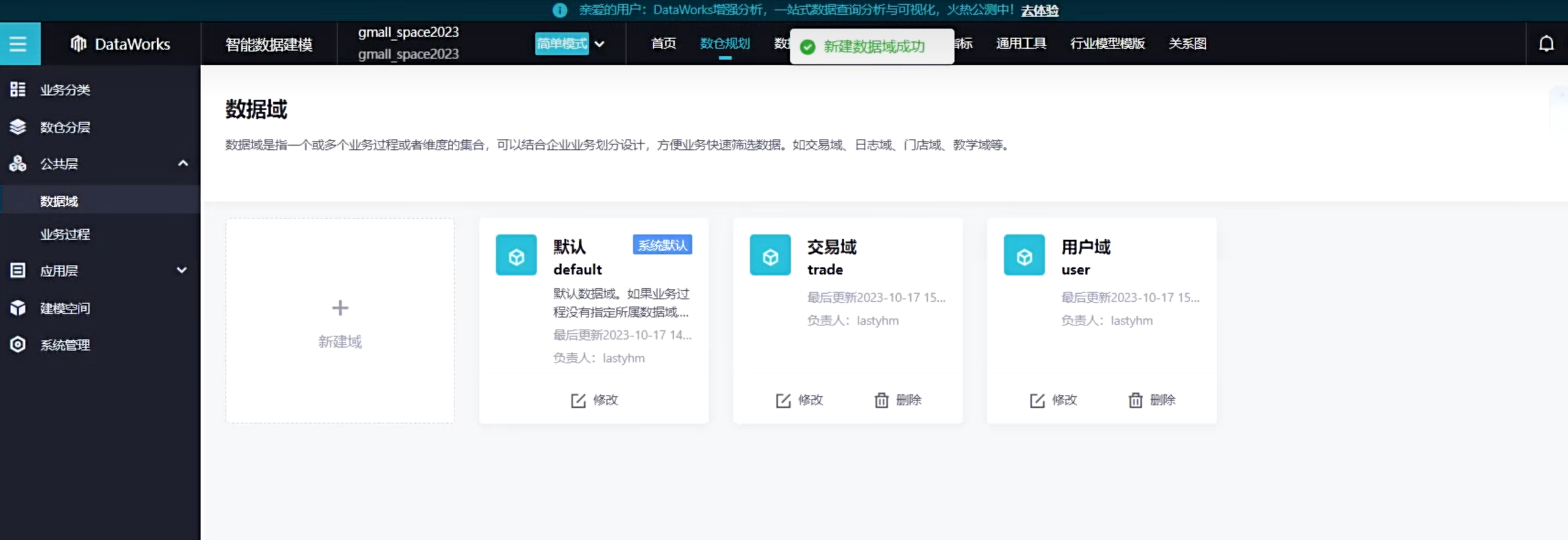
创建一个用户域,然后在创建一个交易域
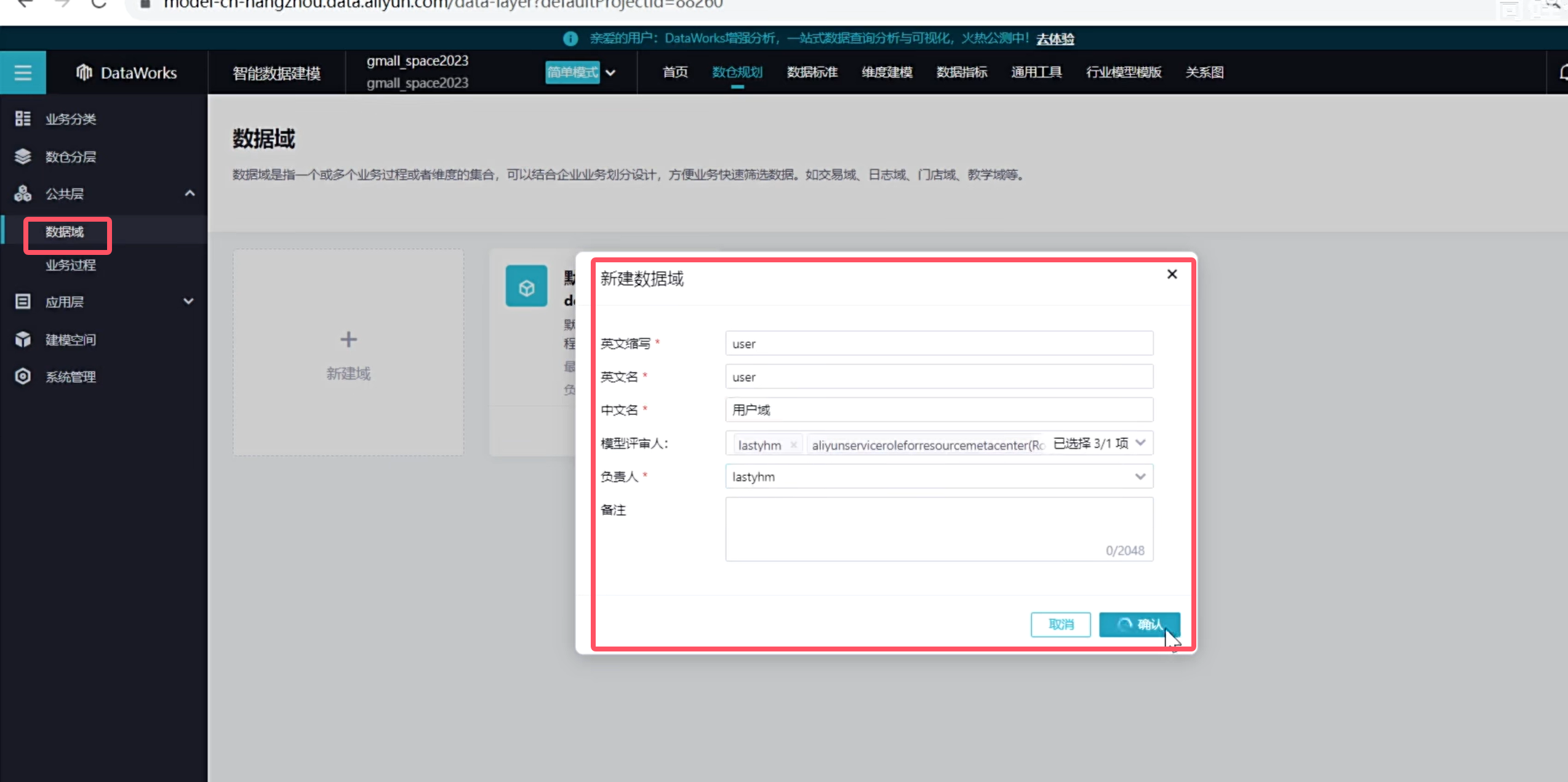
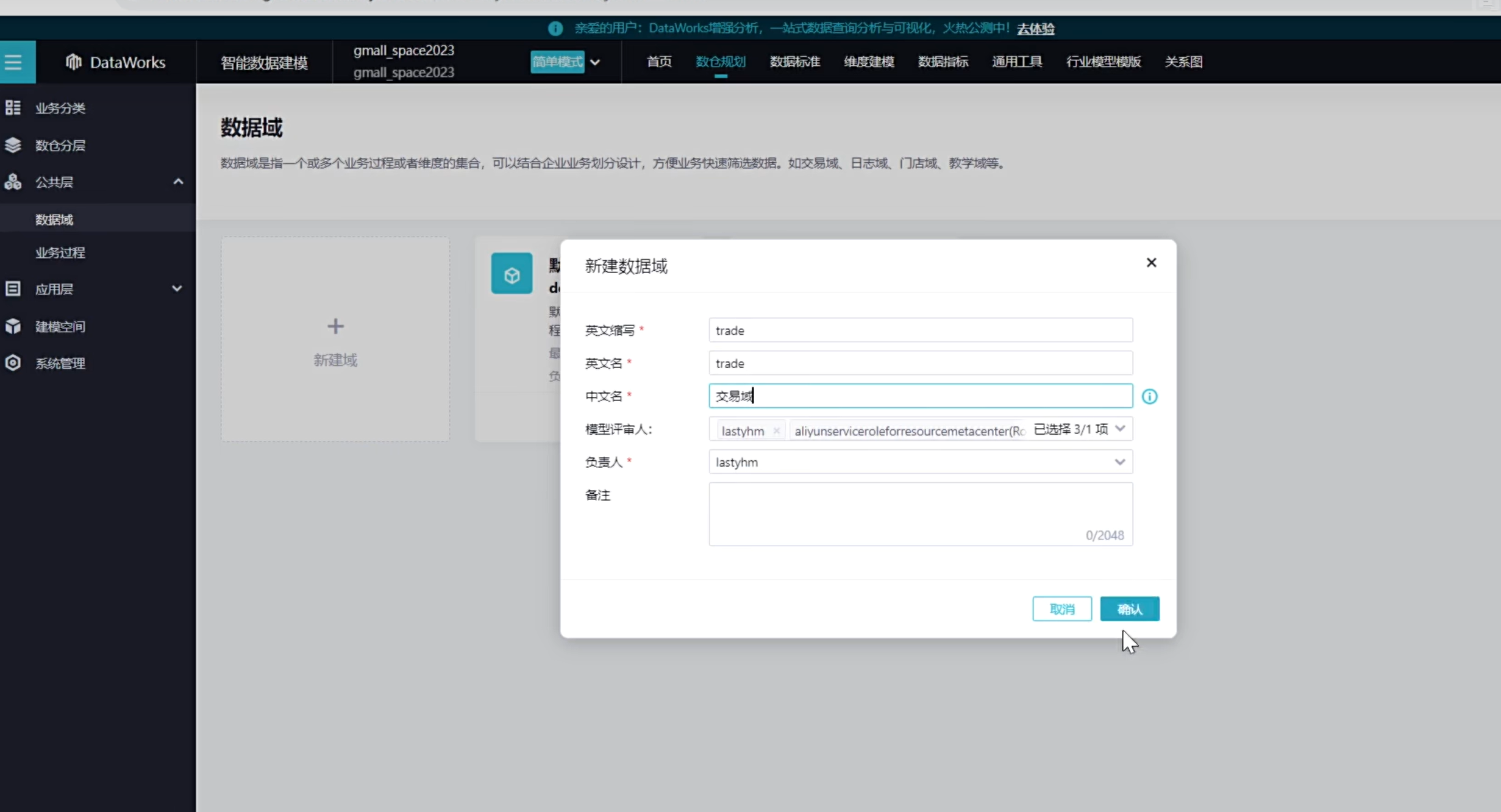
创建如下
定义业务过程
首先是在定义业务过程中,系统会针对你的数据域定义几个默认的业务过程,我们一般忽略
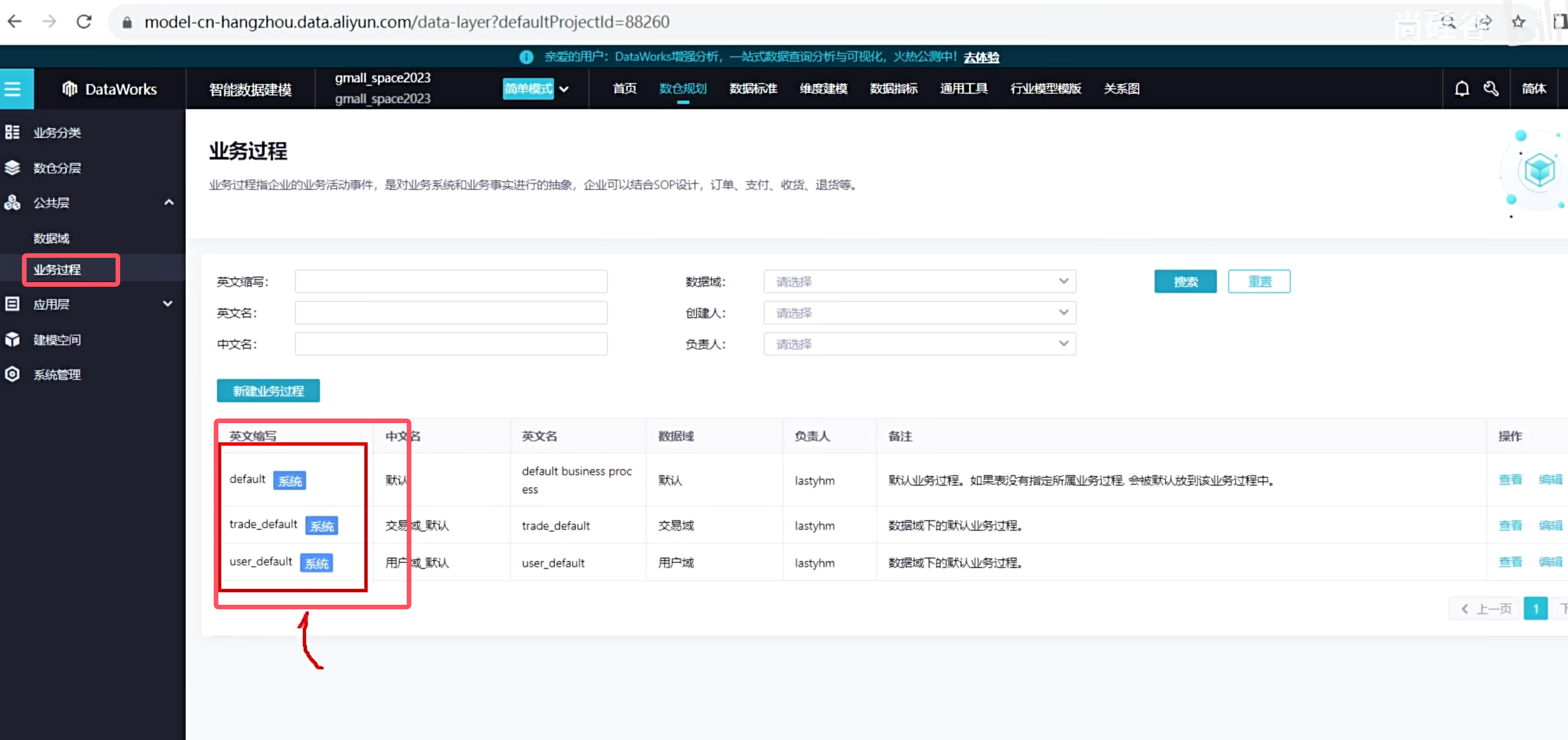
新建业务过程,一个业务过程只能对应一个数据域
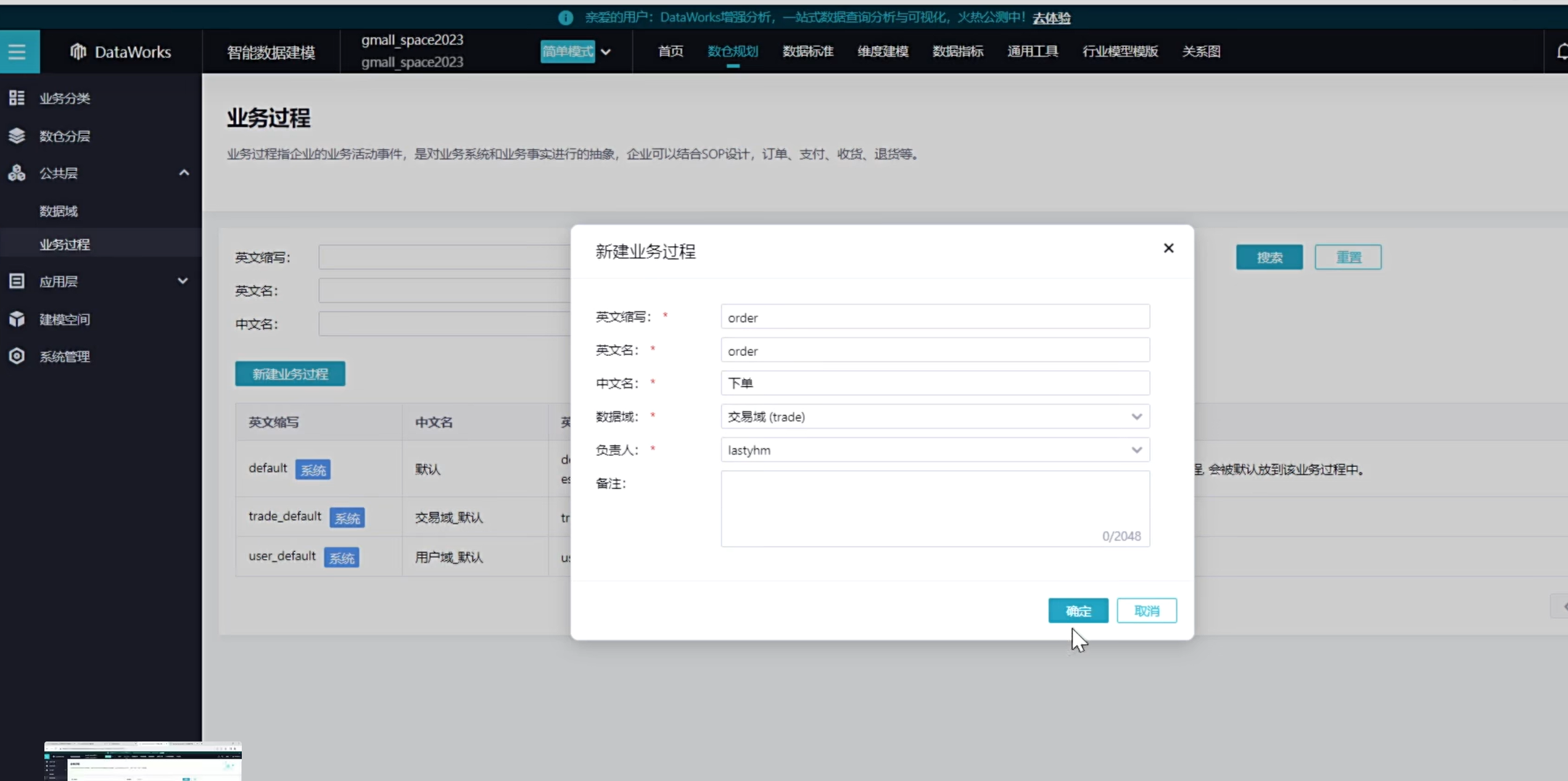
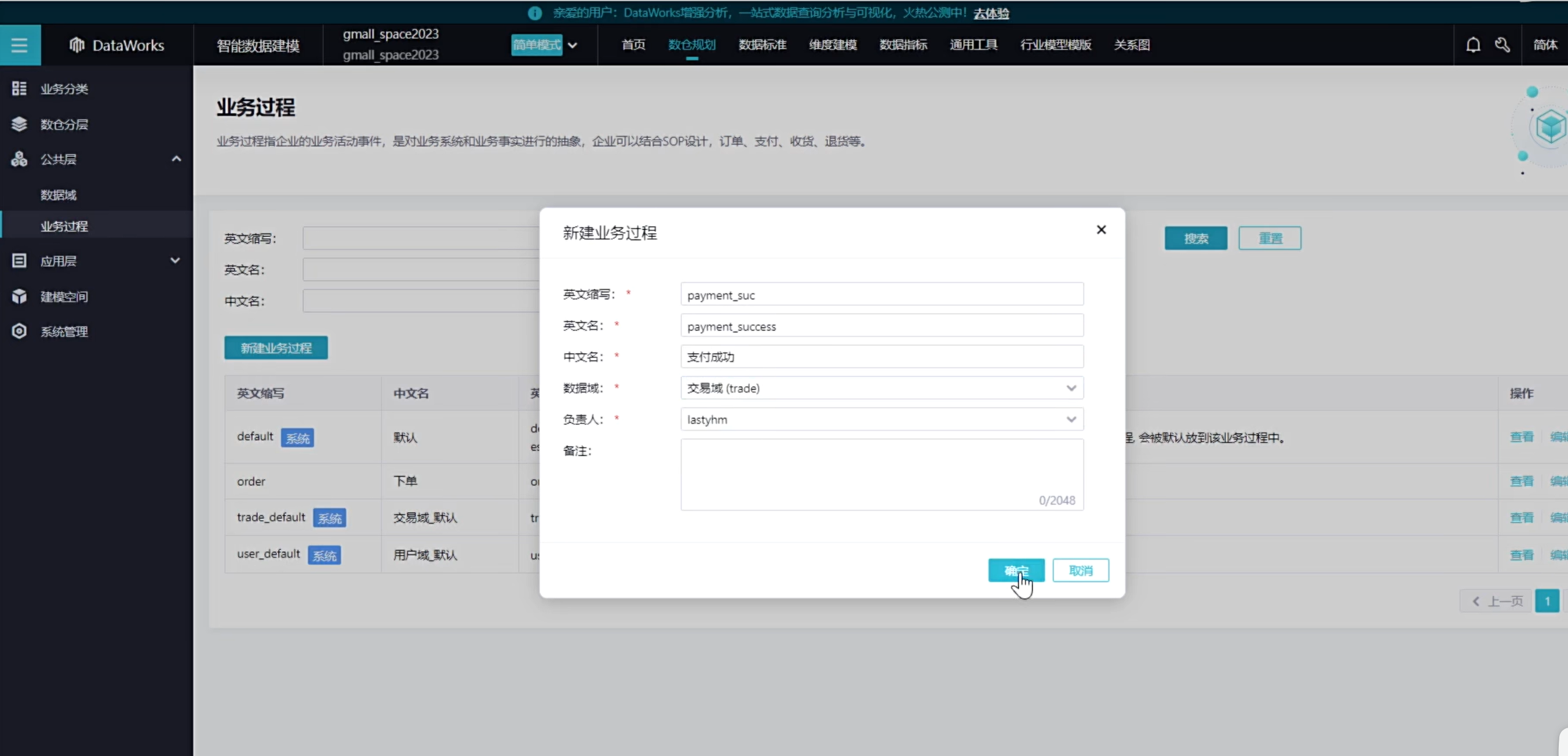
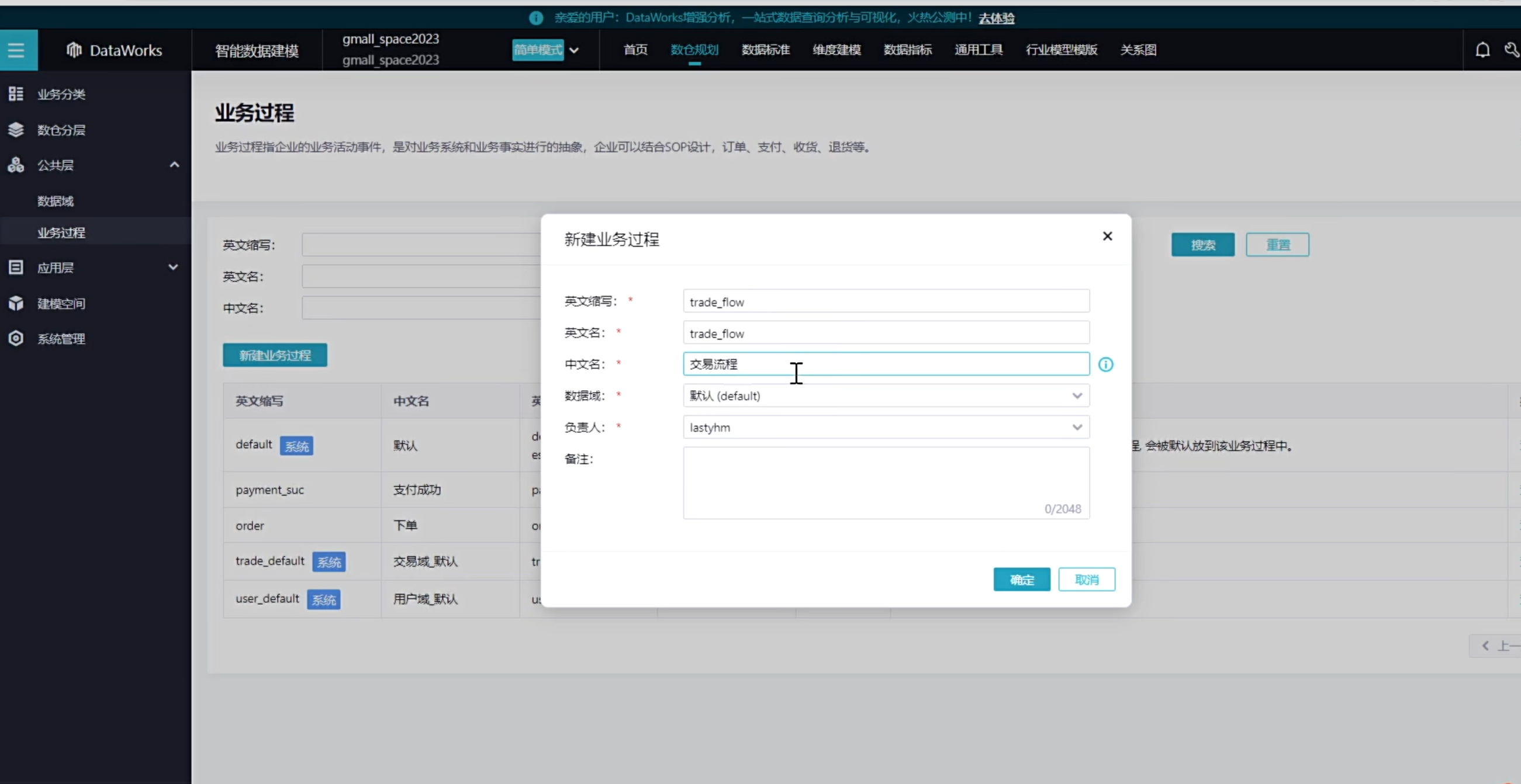
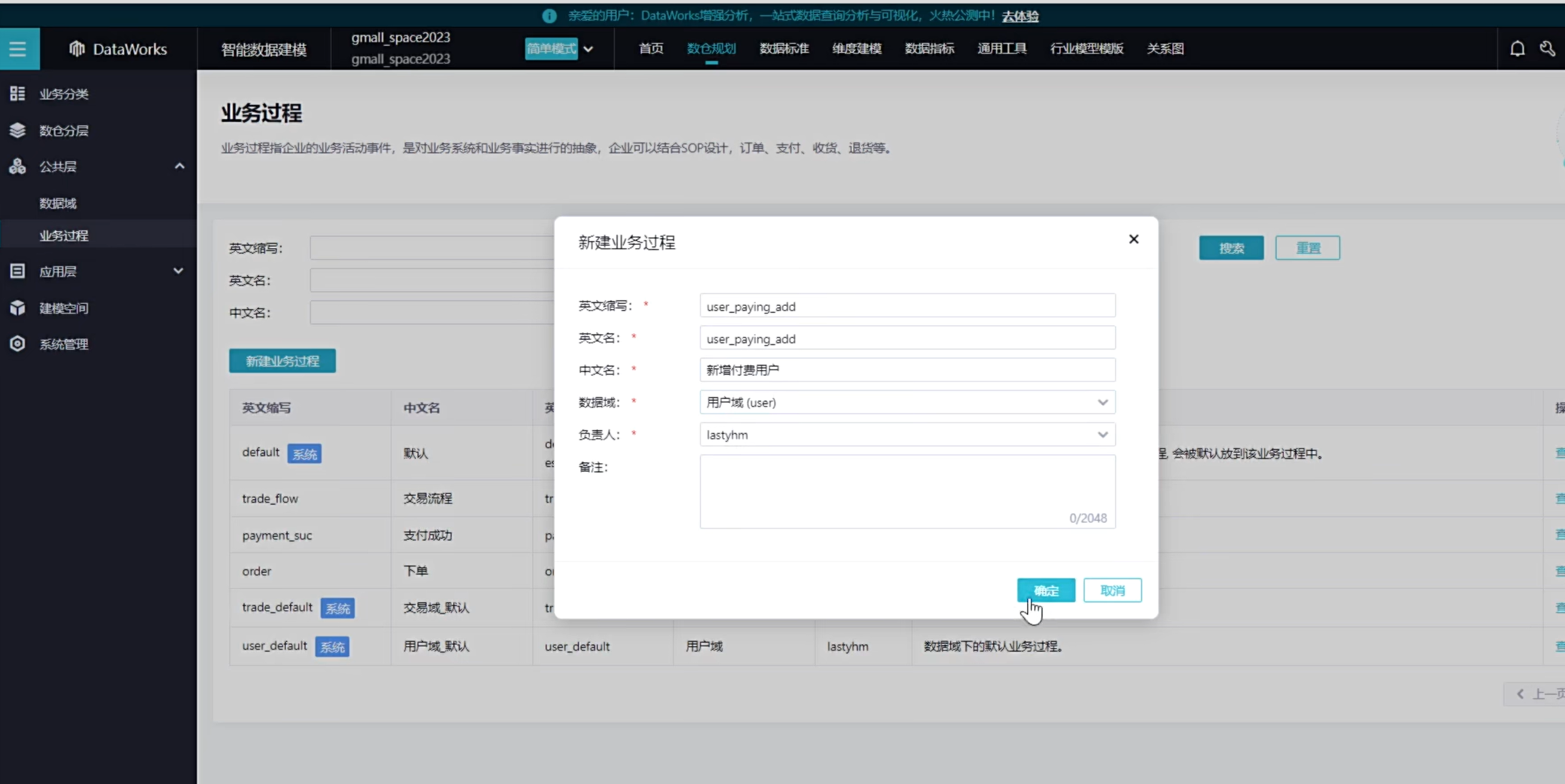
可以看到创建了如下四种业务过程
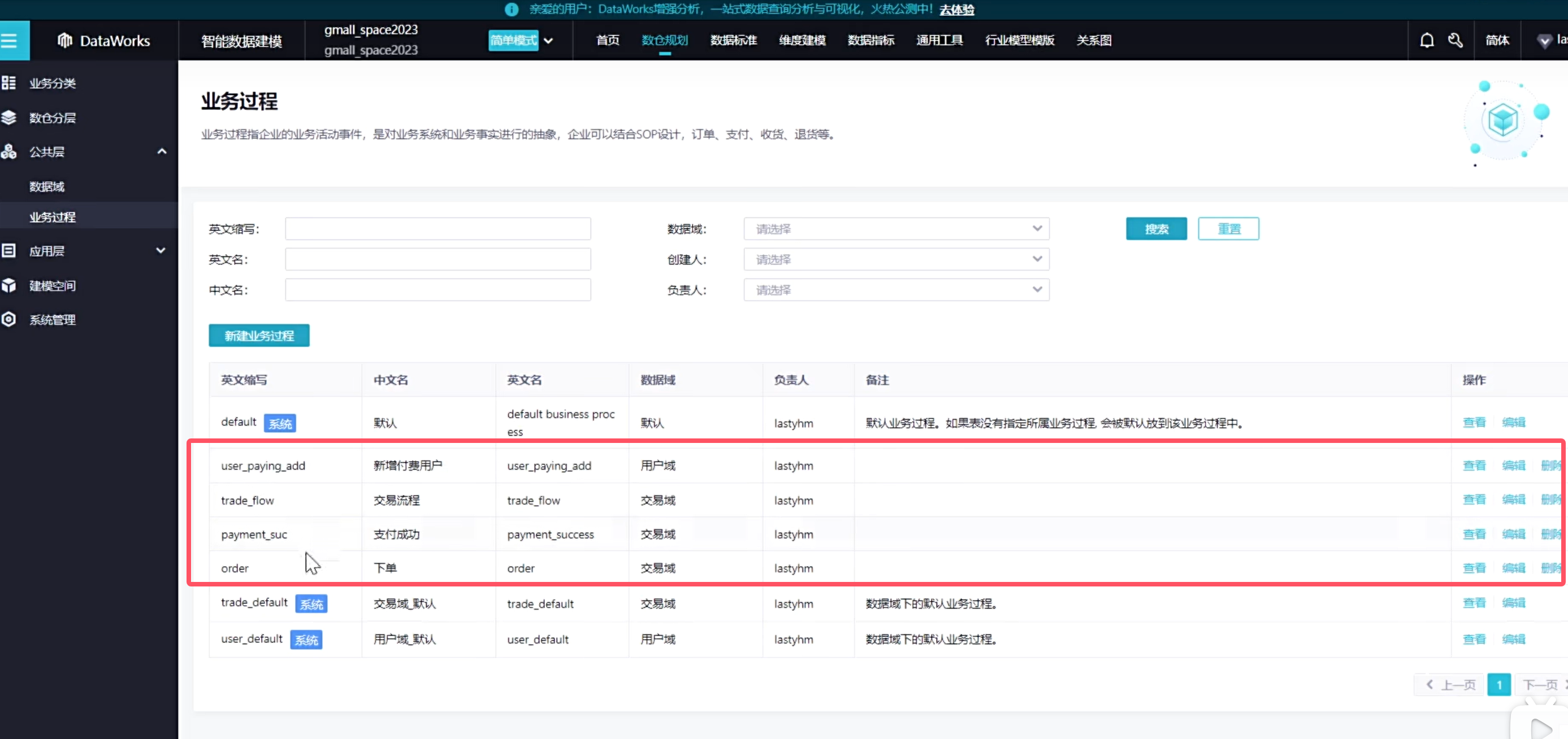
说明一下新增付费用户,就是可以通过用户表和订单表进行一个join操作,操作完了发现该用户没有下过单,说明他是一个新的付费用户,那摩当前订单就是他新增的首单,这时候他就是属于新增的付费用户,后续可以根据这个统计每天新增的付费用户有哪些
业务数据准备
业务数仓系统流程设计
业务表结构
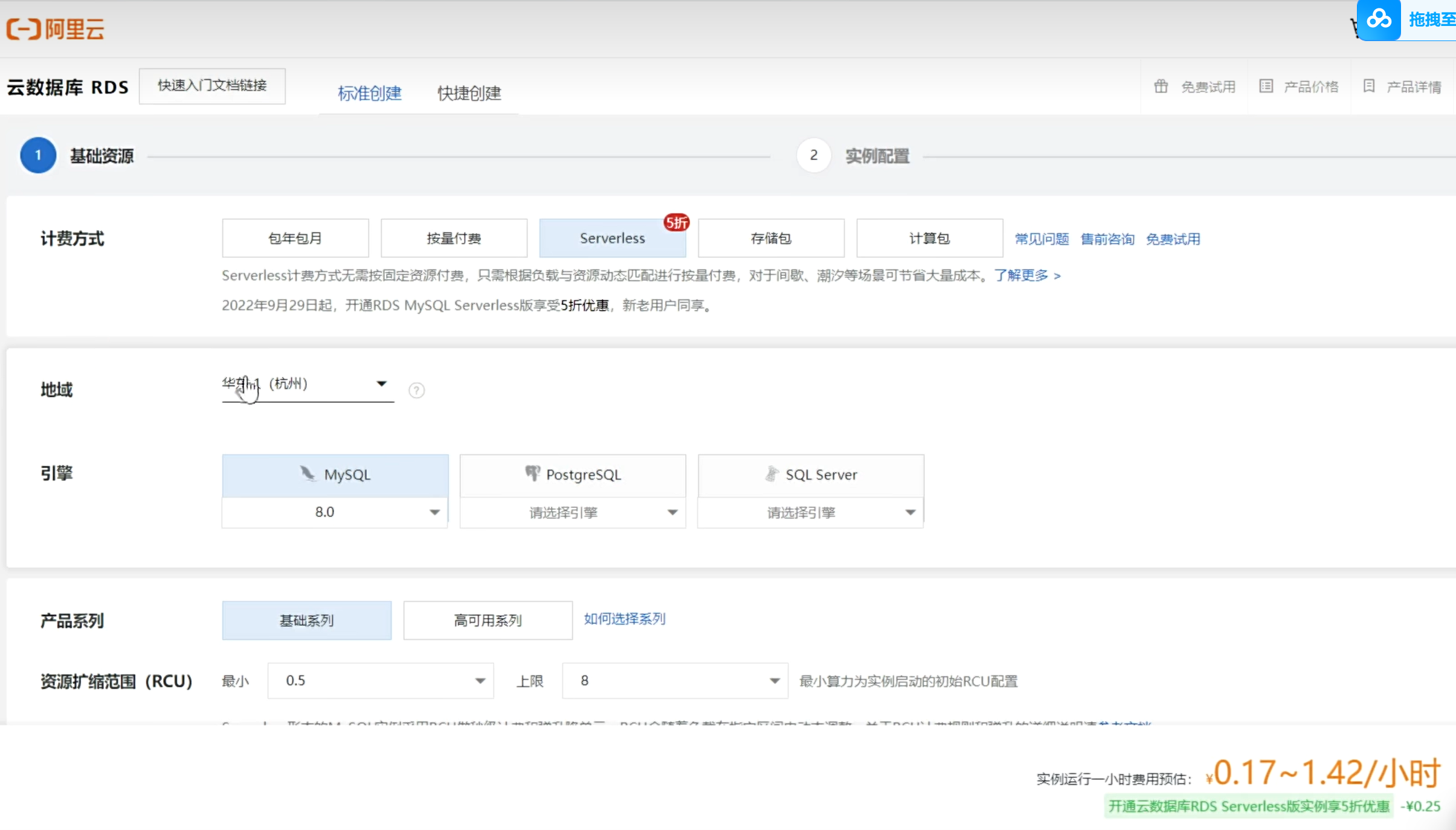
RDS服务器准备
RDS服务器购买
阿里云关系型数据库(Relational Database Service,简称RDS) 是一种稳定可靠、可弹性伸缩的在线数据库服务
购买RDS for MySQL服务器: https://www.aliyun.com/product/rds/mysql
点击立即购买
支付完成之后点击去控制台
控制台列表
注意:实例一旦创建,服务开始计费,使用过程中不能停机,只能释放实例。
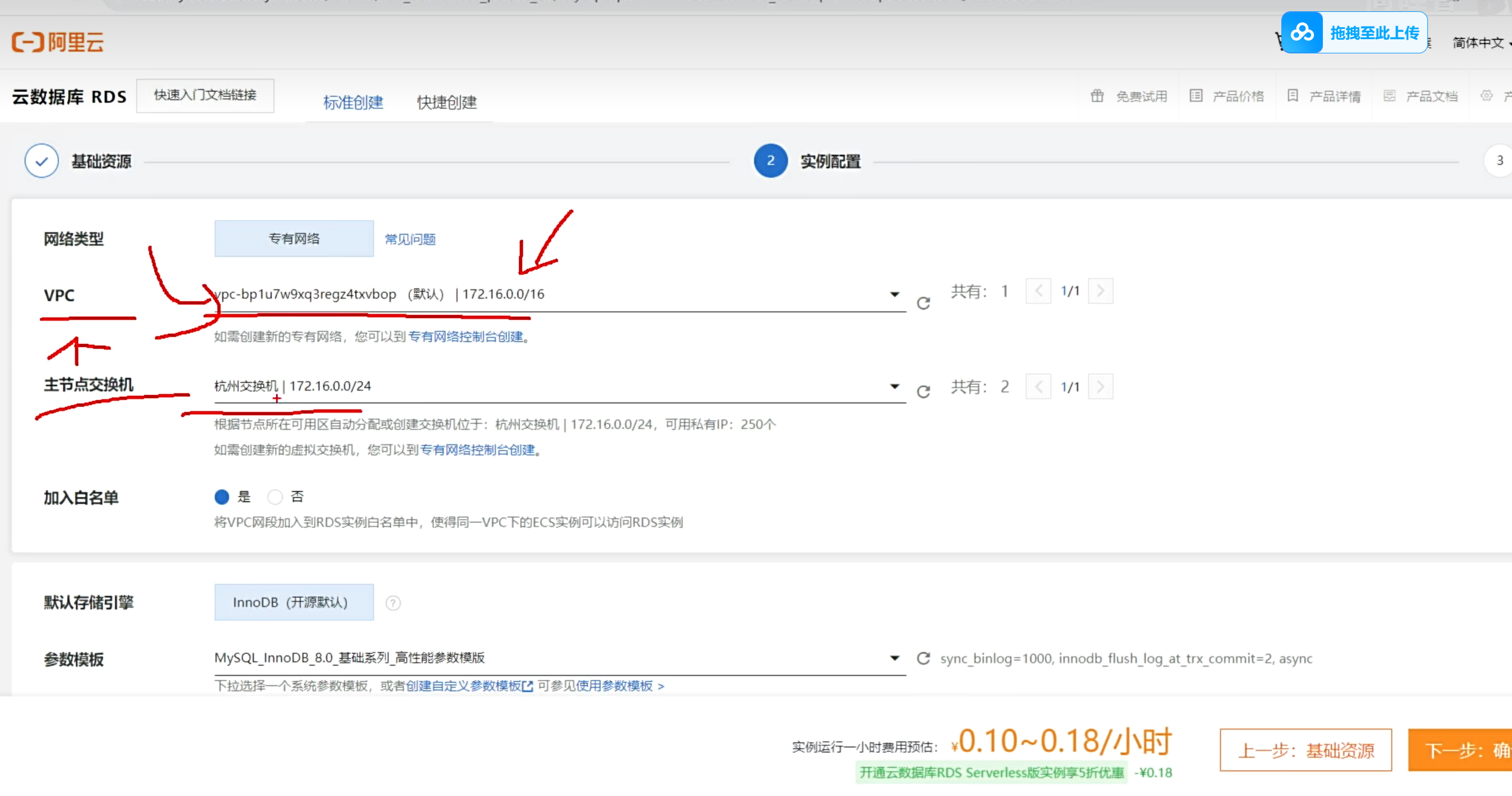
RDS服务器配置
服务建立好以后,首先要建立连接通道,可以让用户远程操控RDS服务器
1)从列表中点入实例
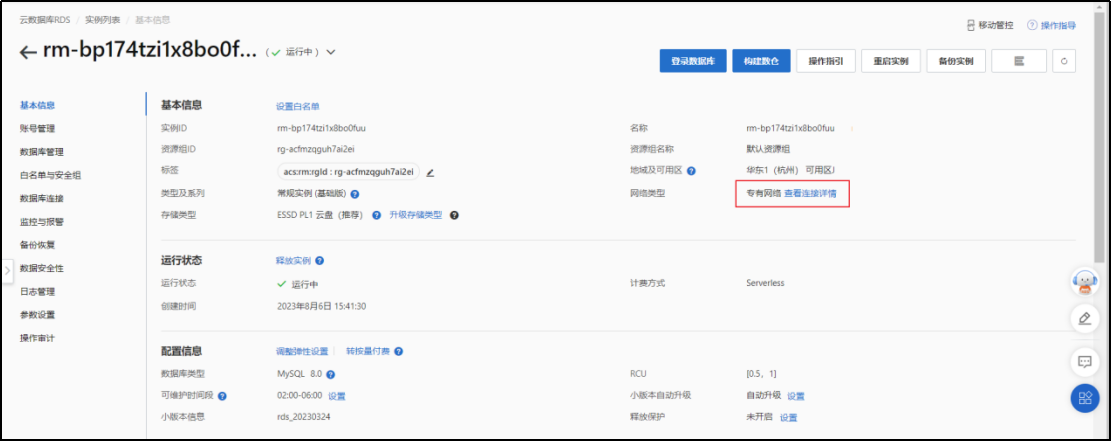
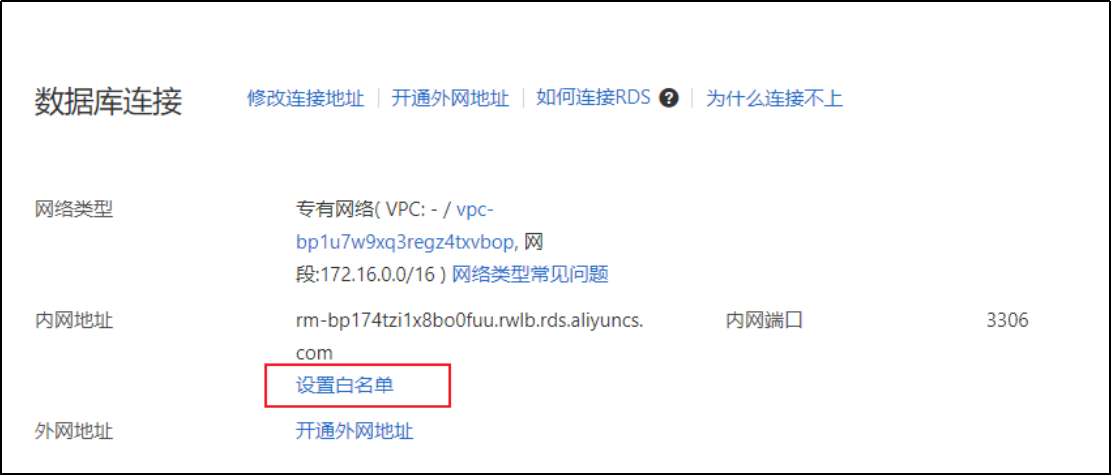
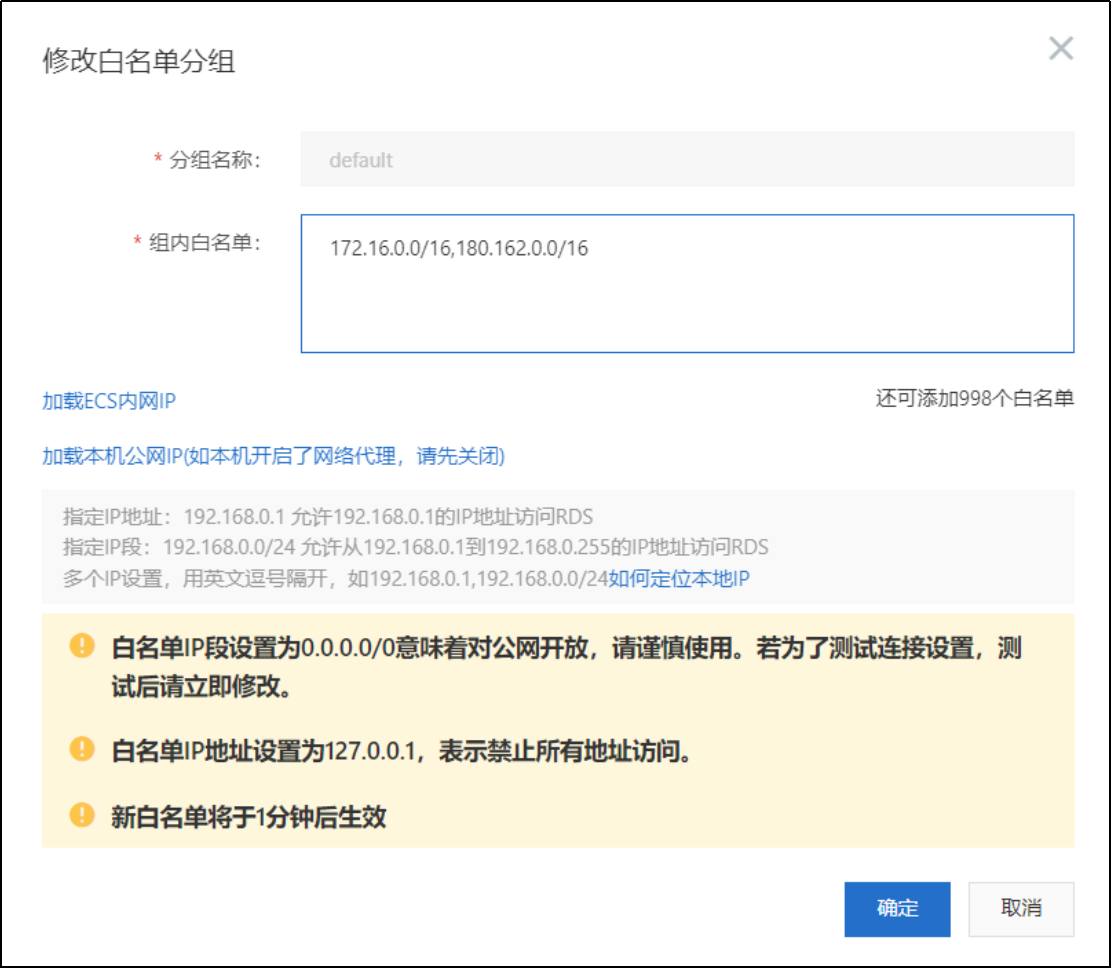
2)配置白名单
白名单:白名单上的IP地址,是可以访问该RDS服务器,其他IP地址都拒绝。
白名单的IP地址都是本机对外显示的外网地址。获取外面IP地址的方法,就是在百度上搜索IP查询。
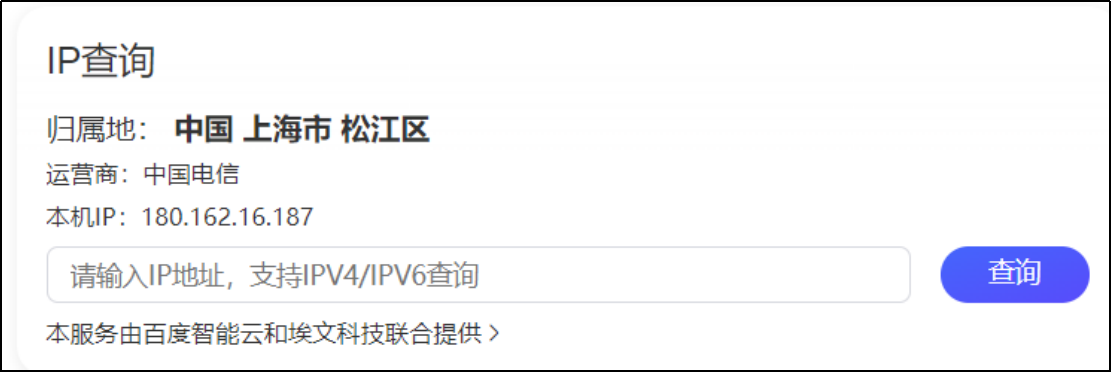
配置白名单详情
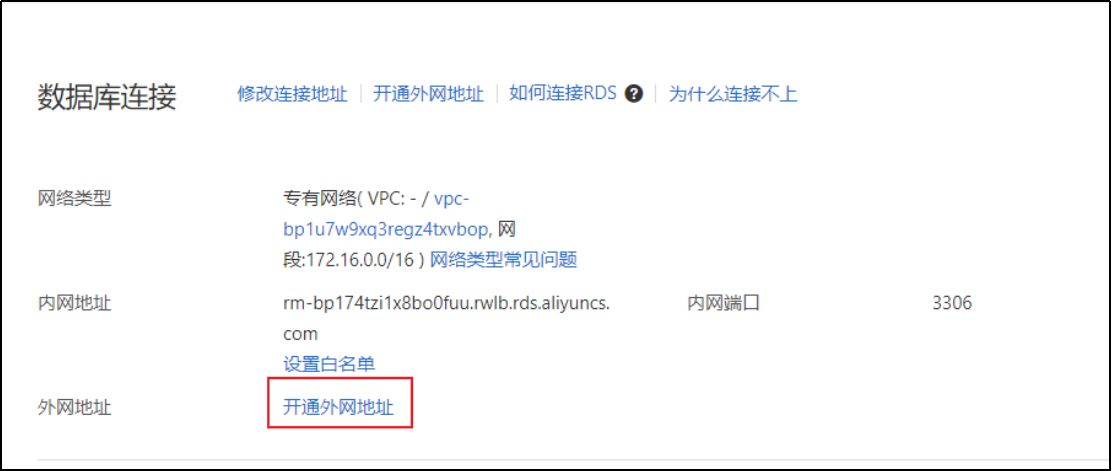
4)基本信息->申请外网地址

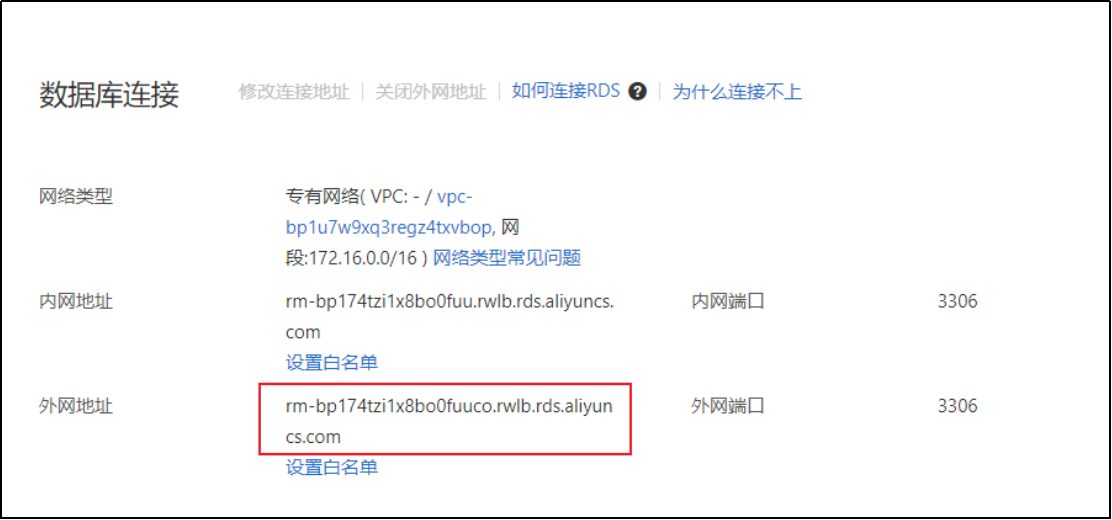
框住的部分就是,用户可以通过客户端工具直接访问的地址。
5)账号管理->创建账号
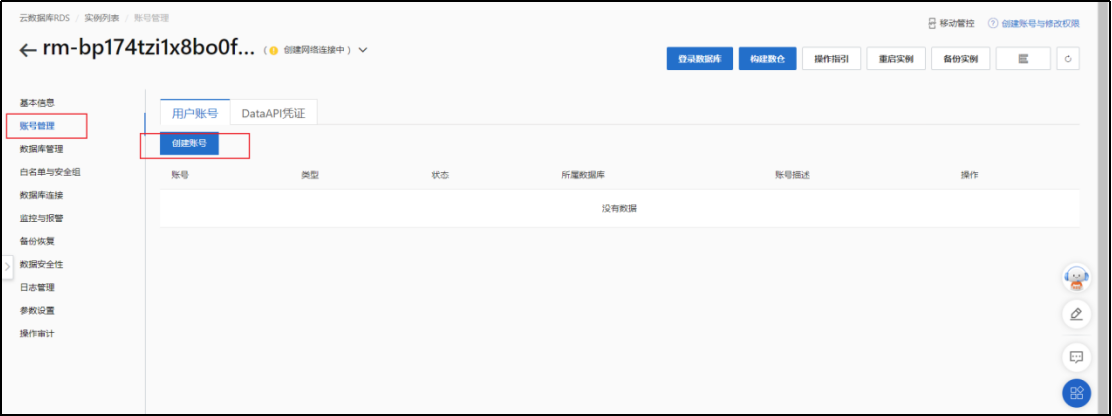
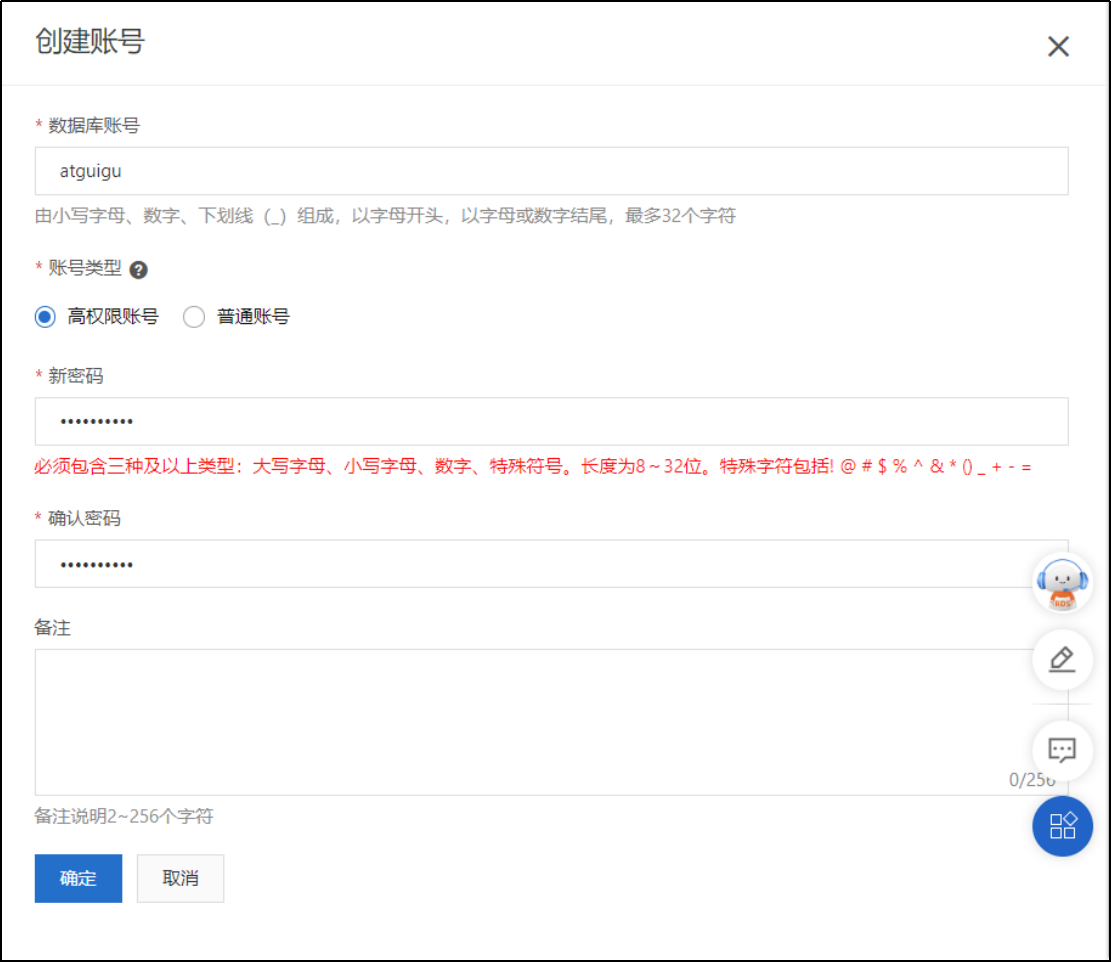
RDS服务器连接
1)利用客户端工具进行登录
注意:SQL主机地址,一定是RDS服务器暴露的外网IP地址。
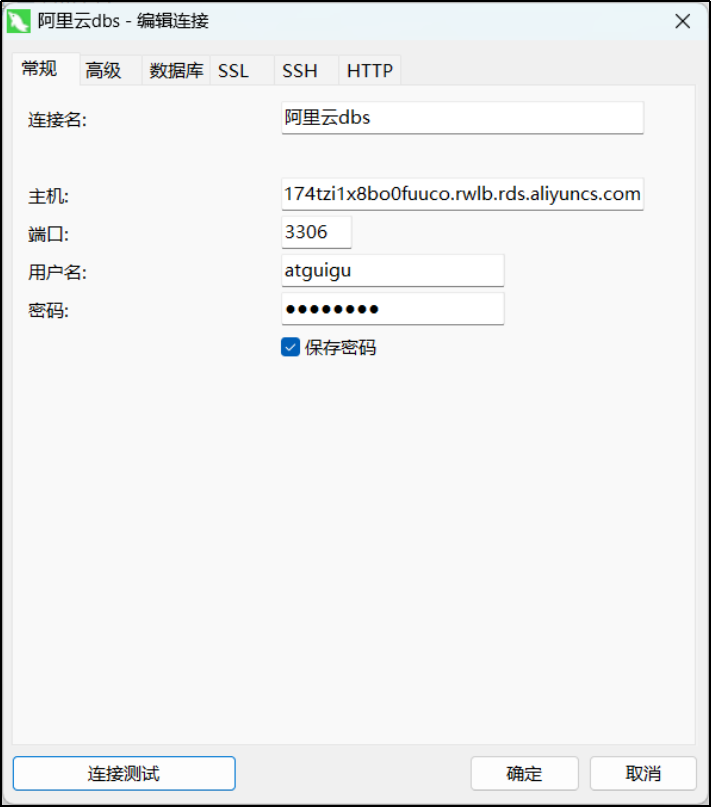
一旦登录成功,那么RDS服务就和一台本地安装的服务器操作起来基本差不多
创建业务数据库及表
建立业务数据库
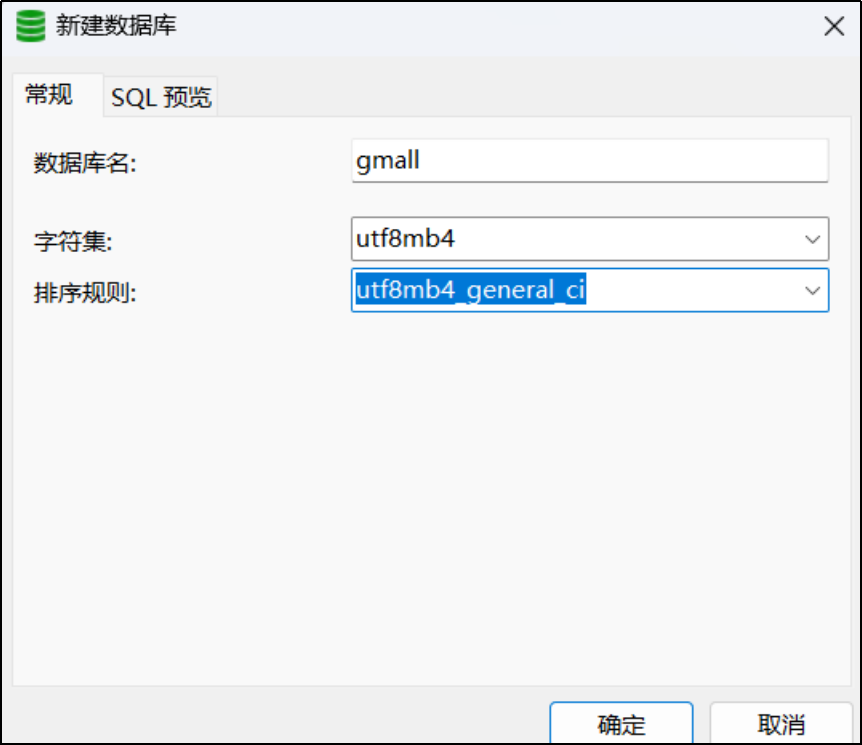
2)导入数据库脚本
数据导入后可以看到有表
6. 业务数仓系统流程设计
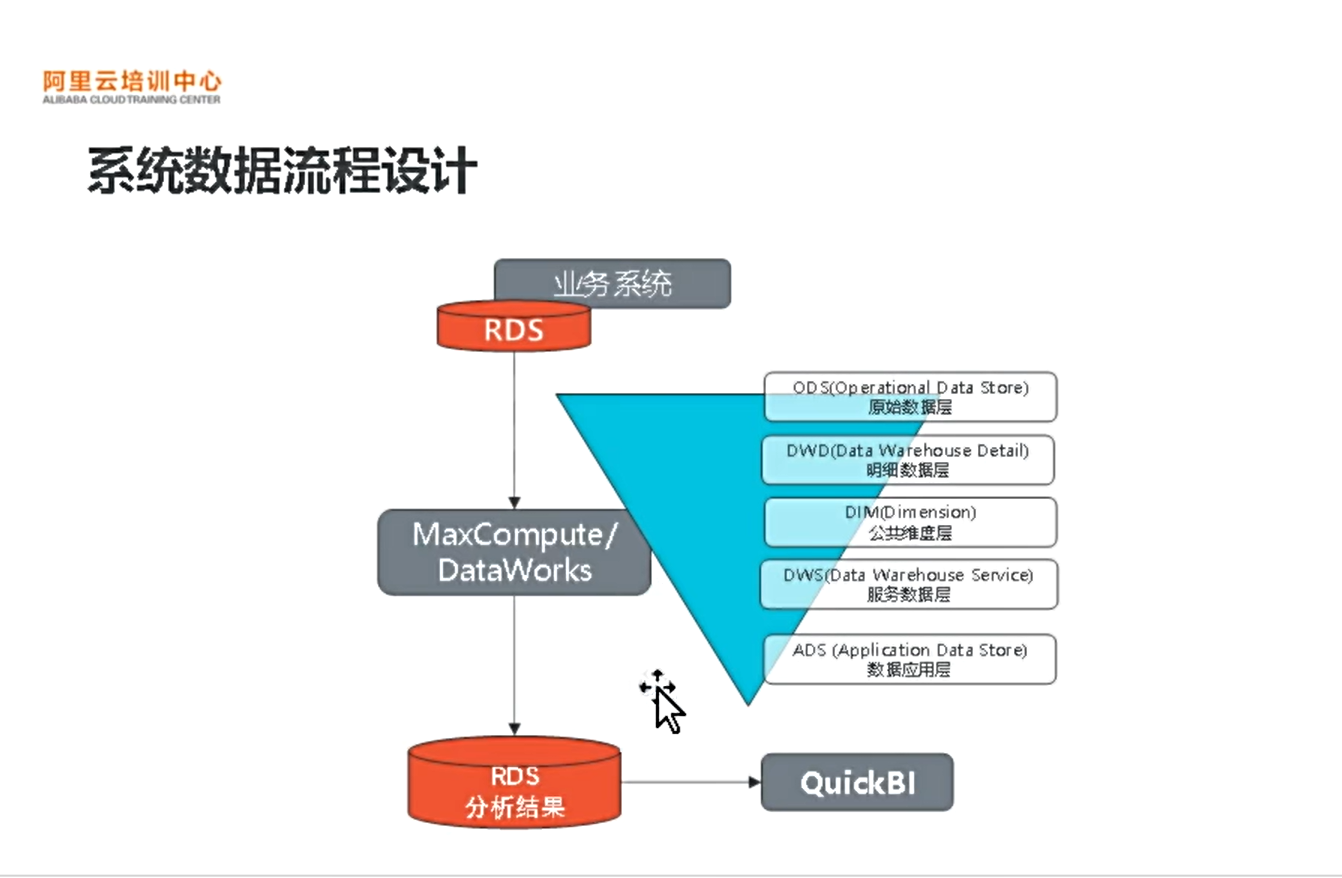
下面将数据导入到odps
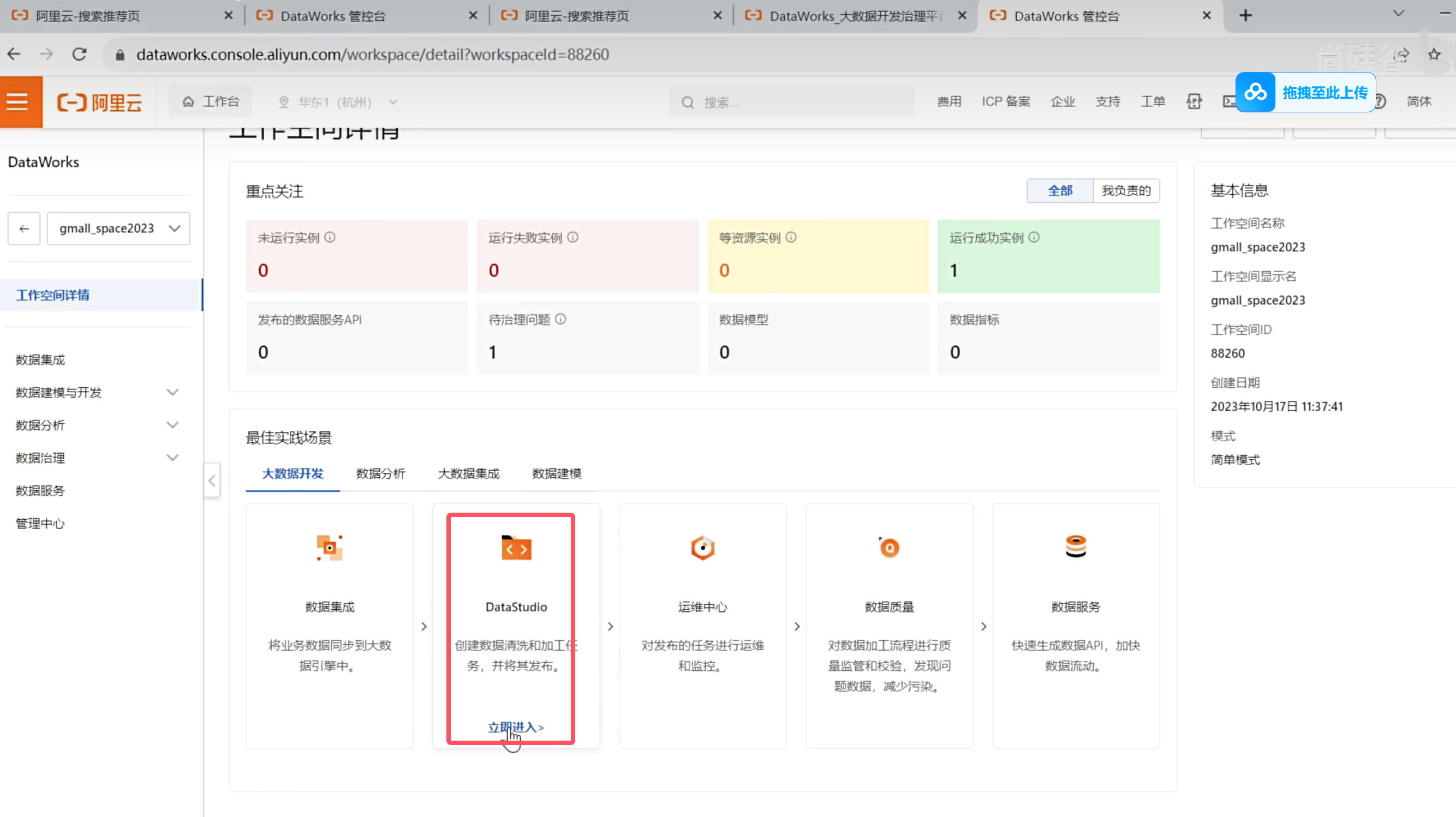
进入到DataWorks工作台页面
调整自己喜欢的页面设置
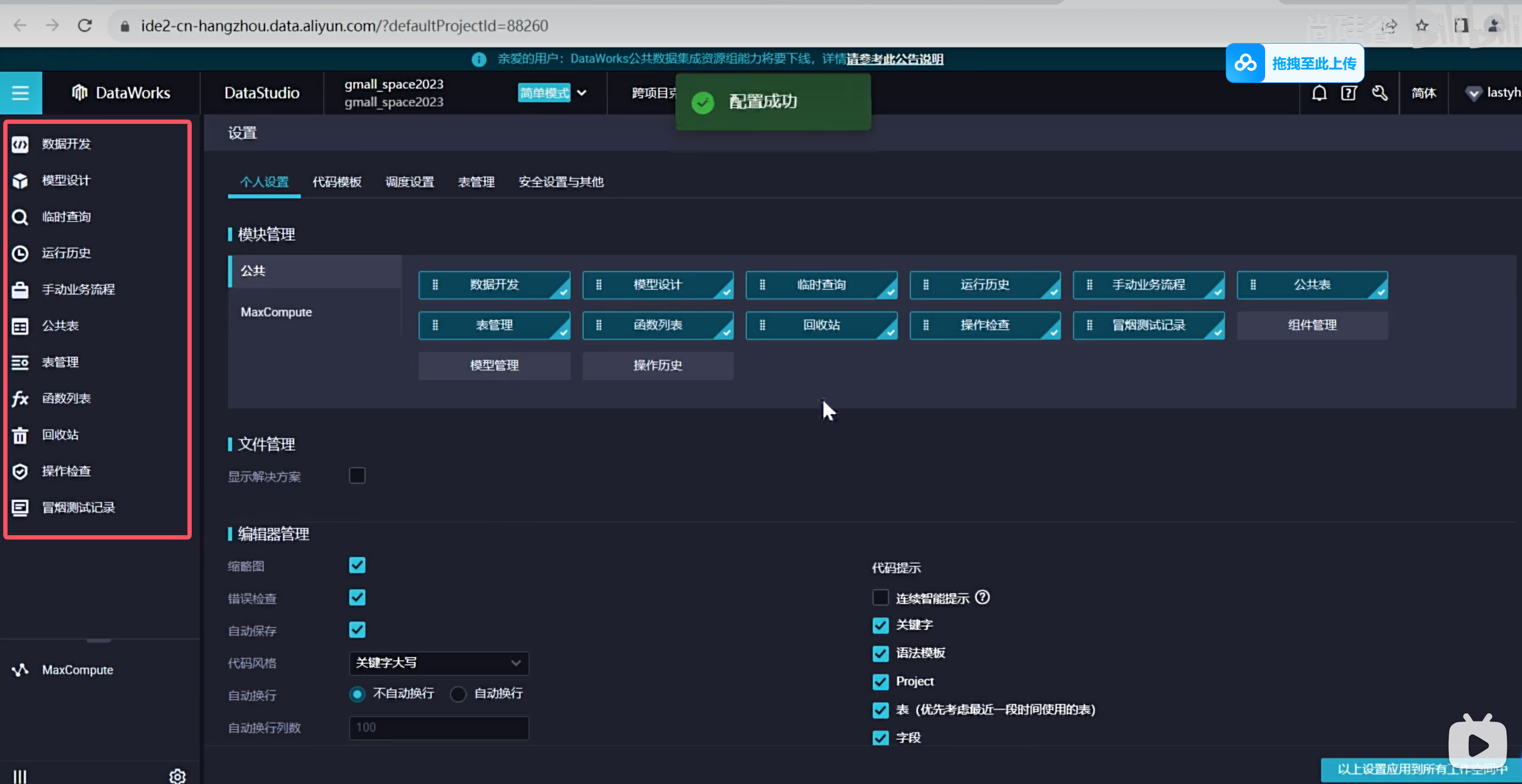
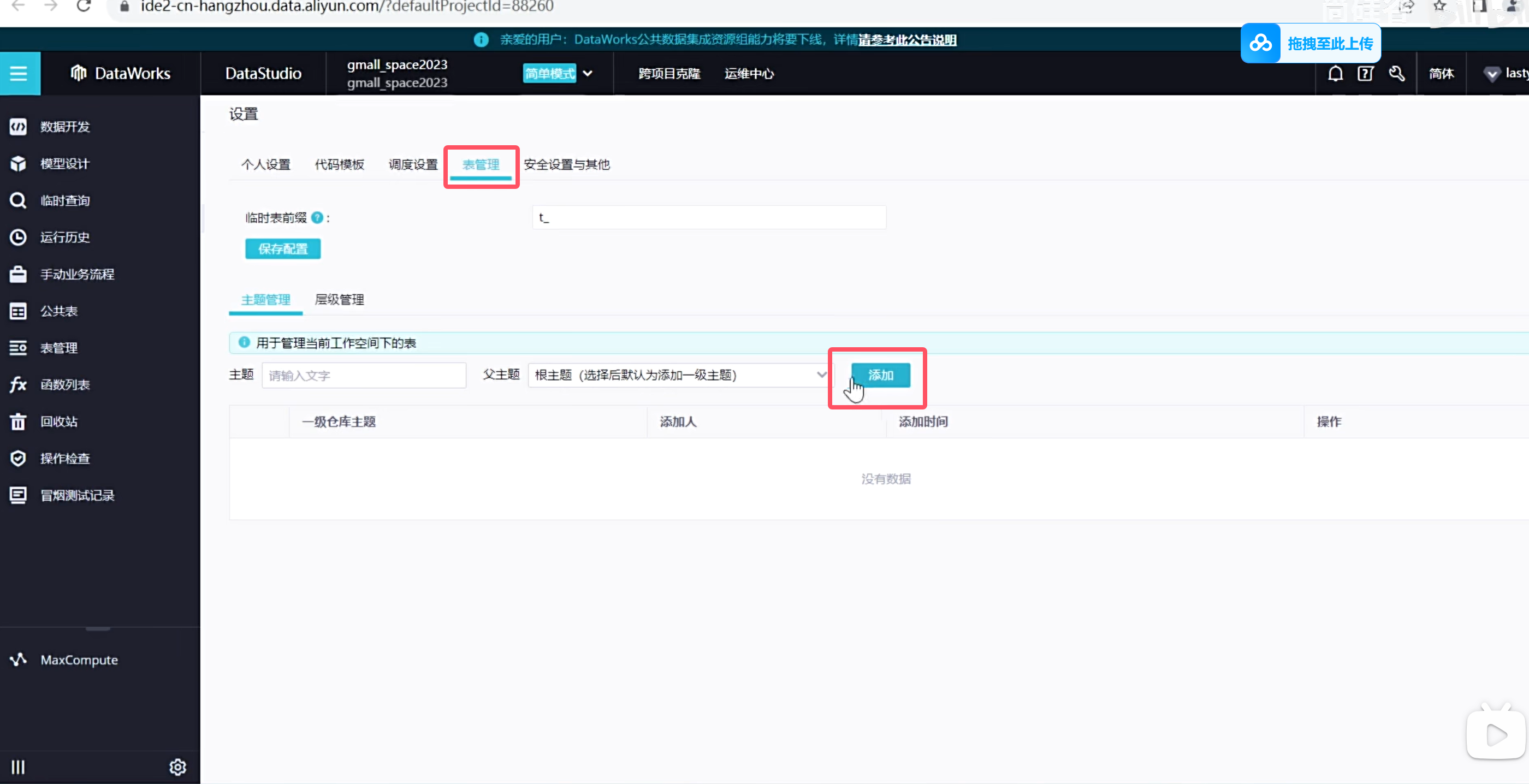
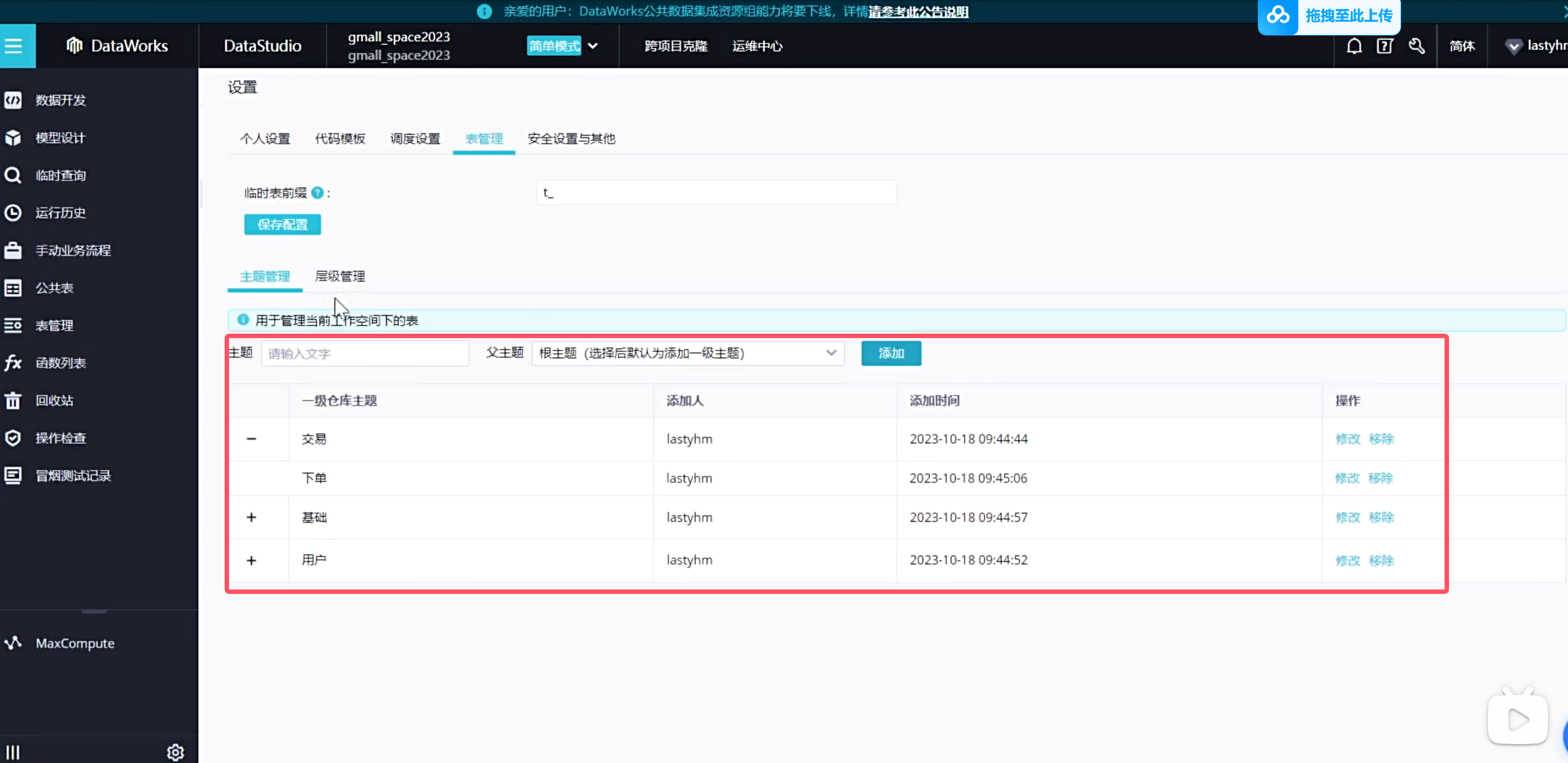
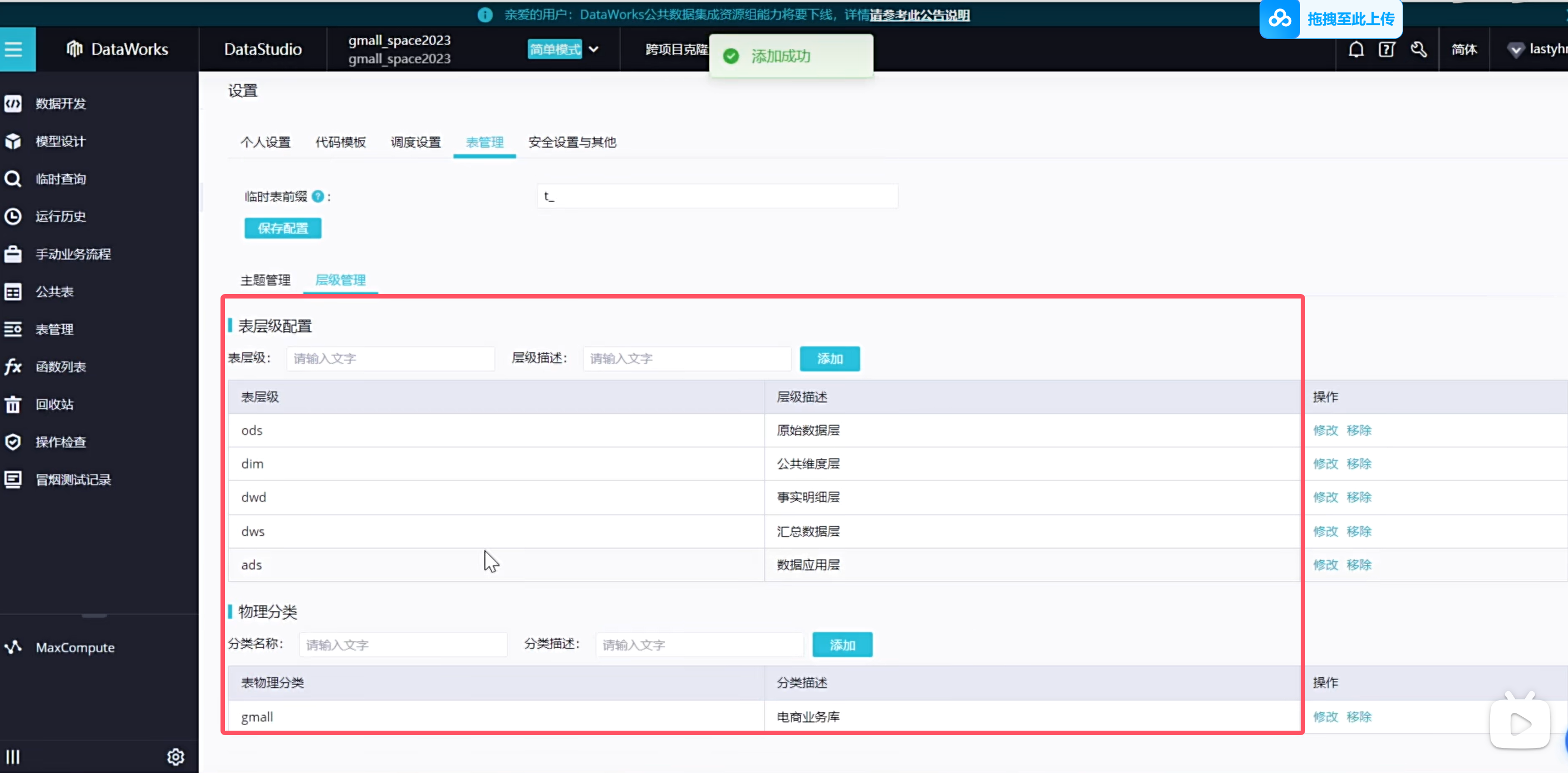
在表管理上一般会设置一些主题,方便类似于文件夹,方便我们后续开发的时候更容易找到
数据同步
ODS层存储的是原始数据,即不需要对数据进行任何处理,所以直接使用DataWorks的同步工具将数据导入到MaxComputer中即可。
同步策略

各表同步策略
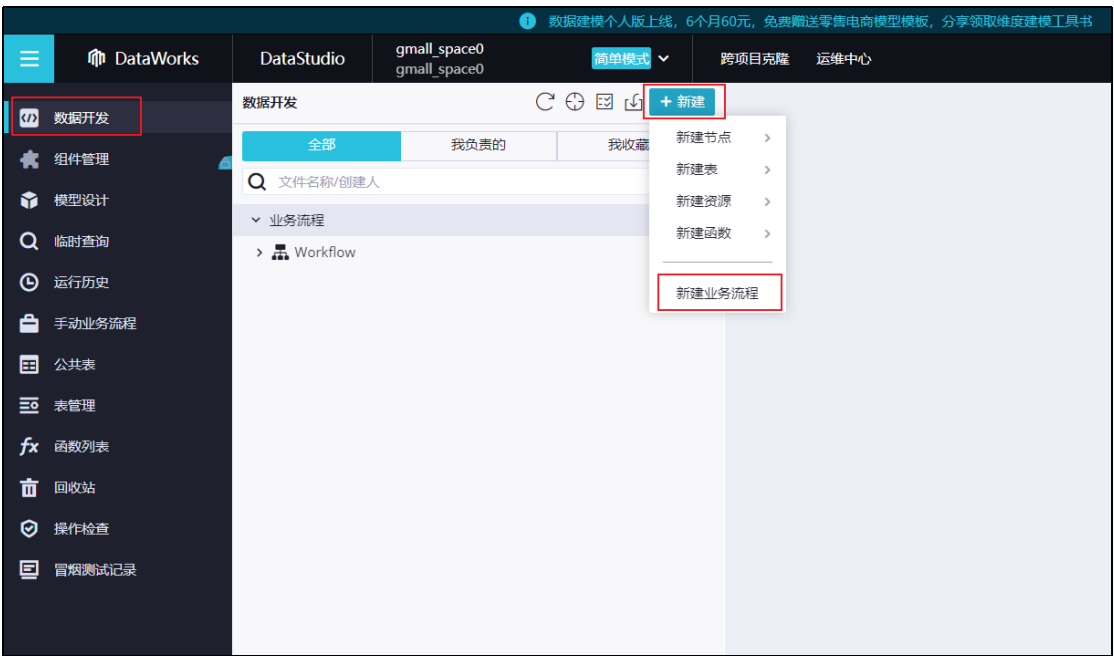
首先在数据开发空间中创建业务流程
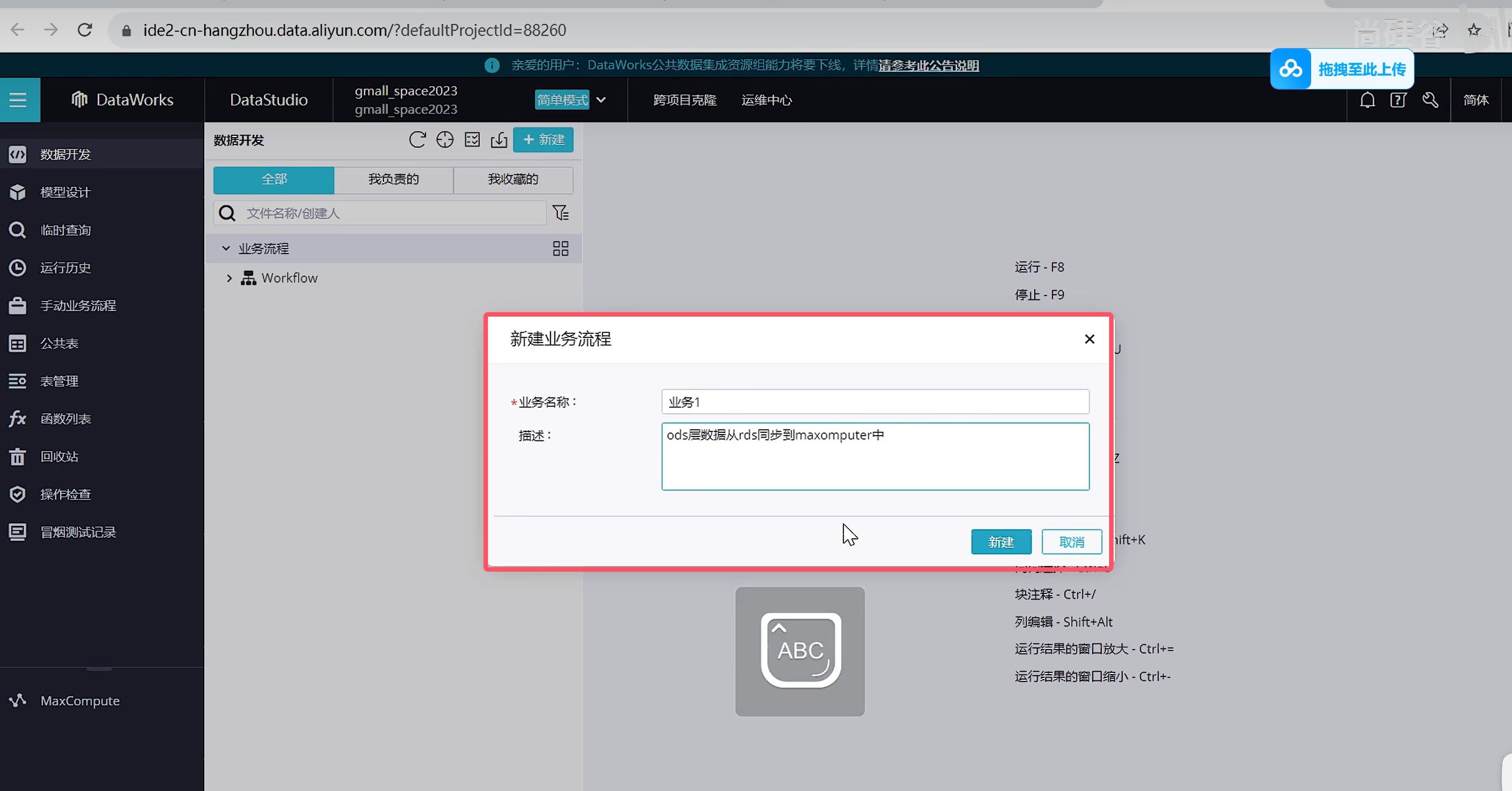
创建业务过程之后可以看到里面有如下内容
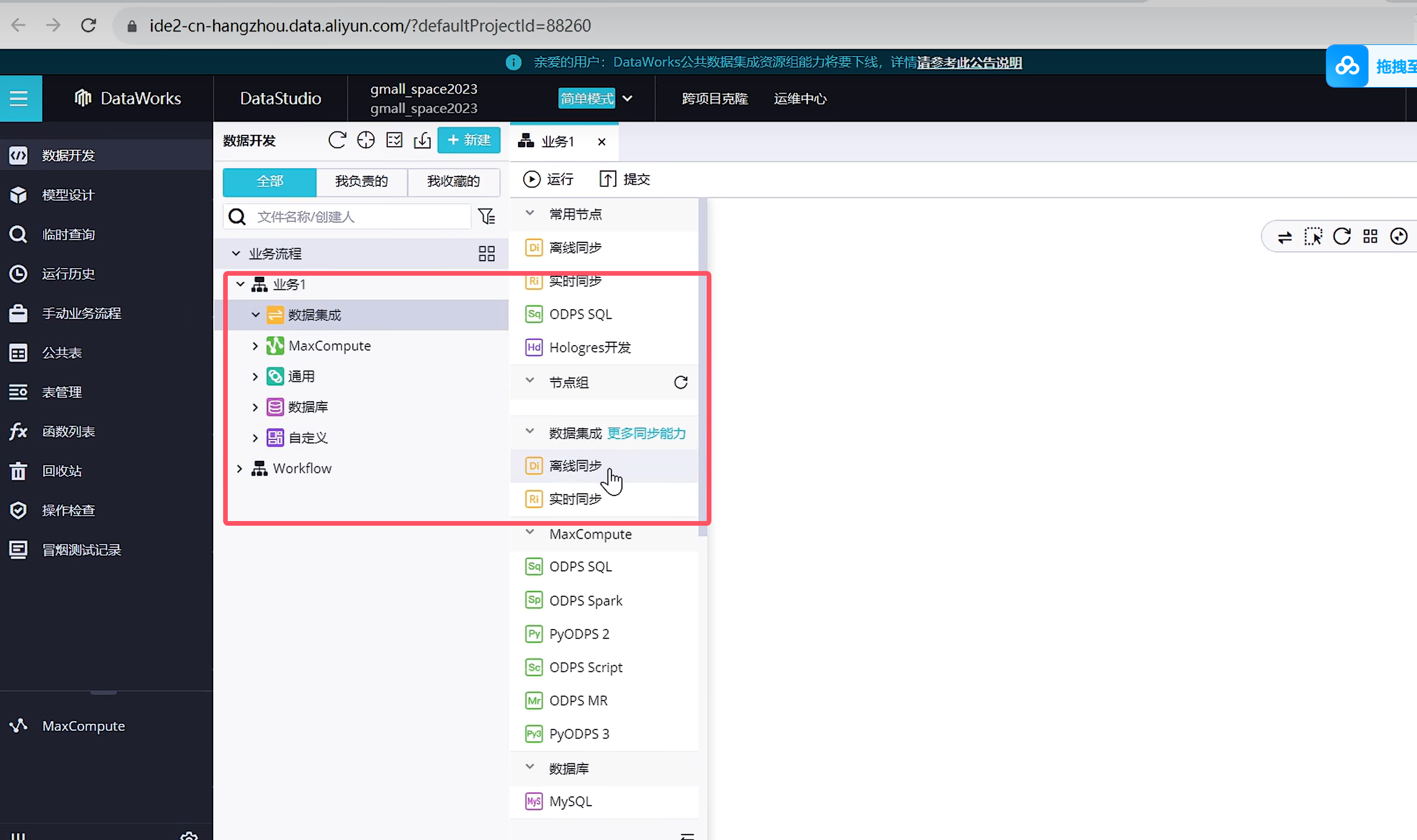
可以看到自己新建的内容
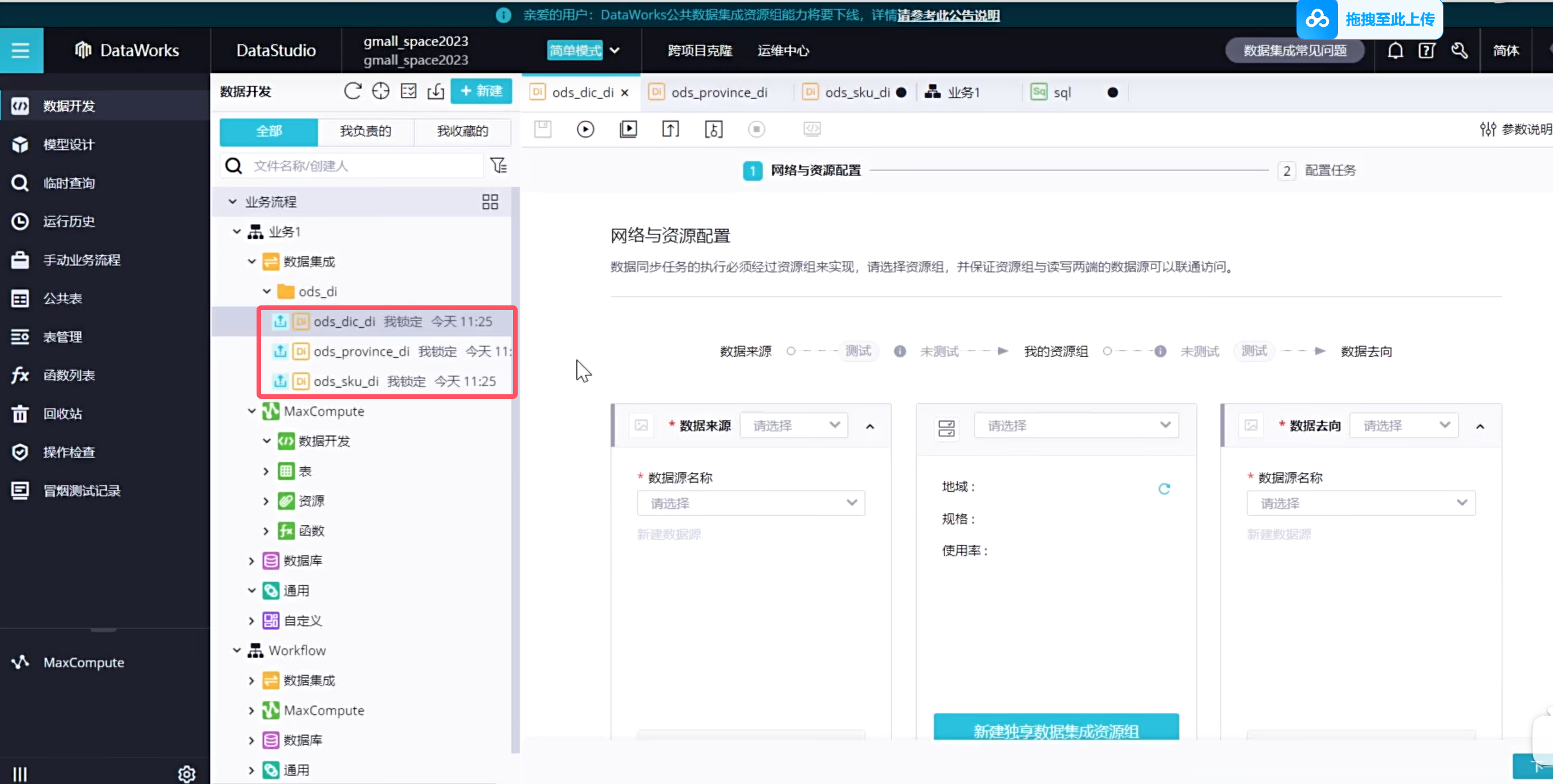
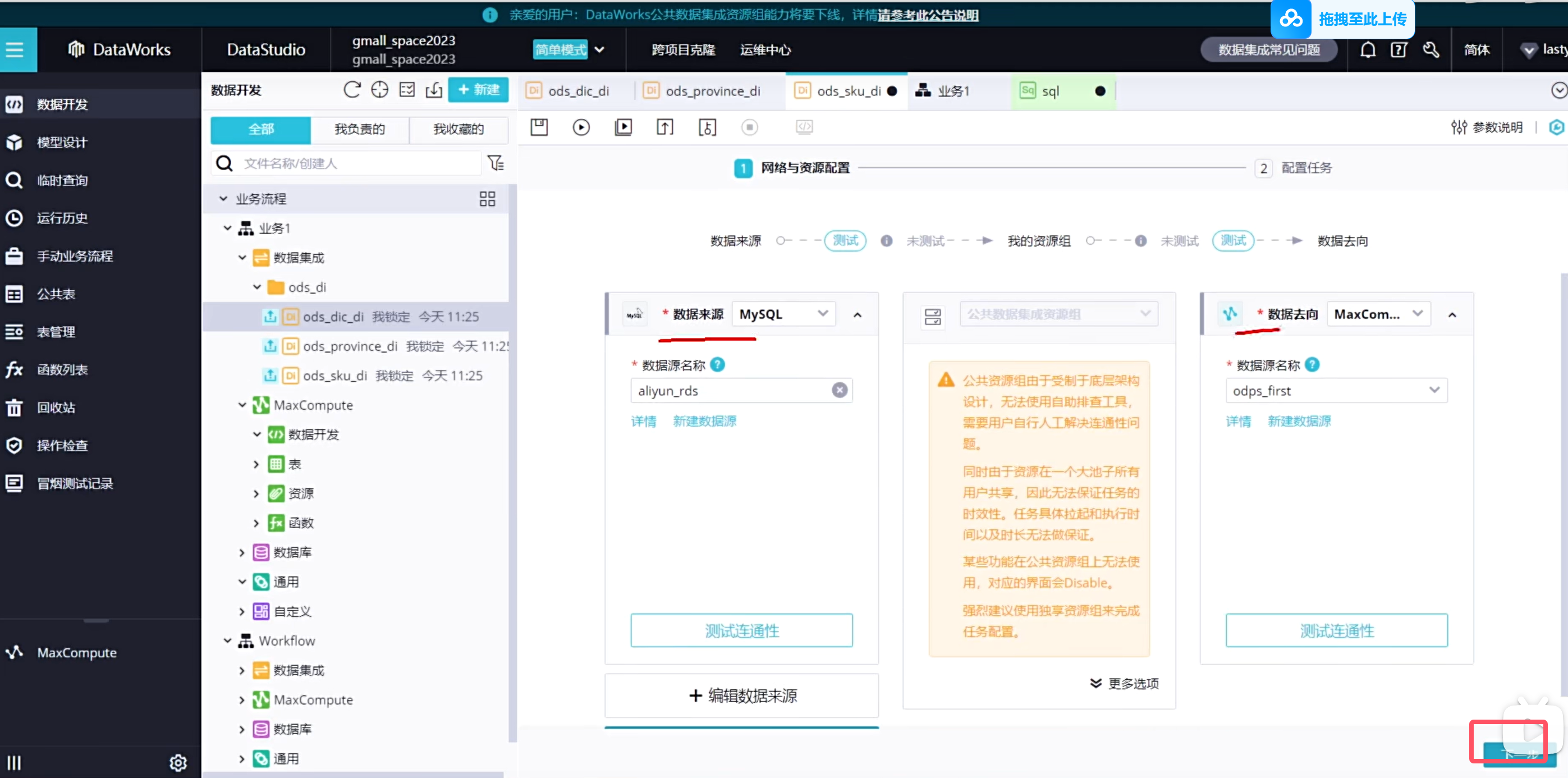
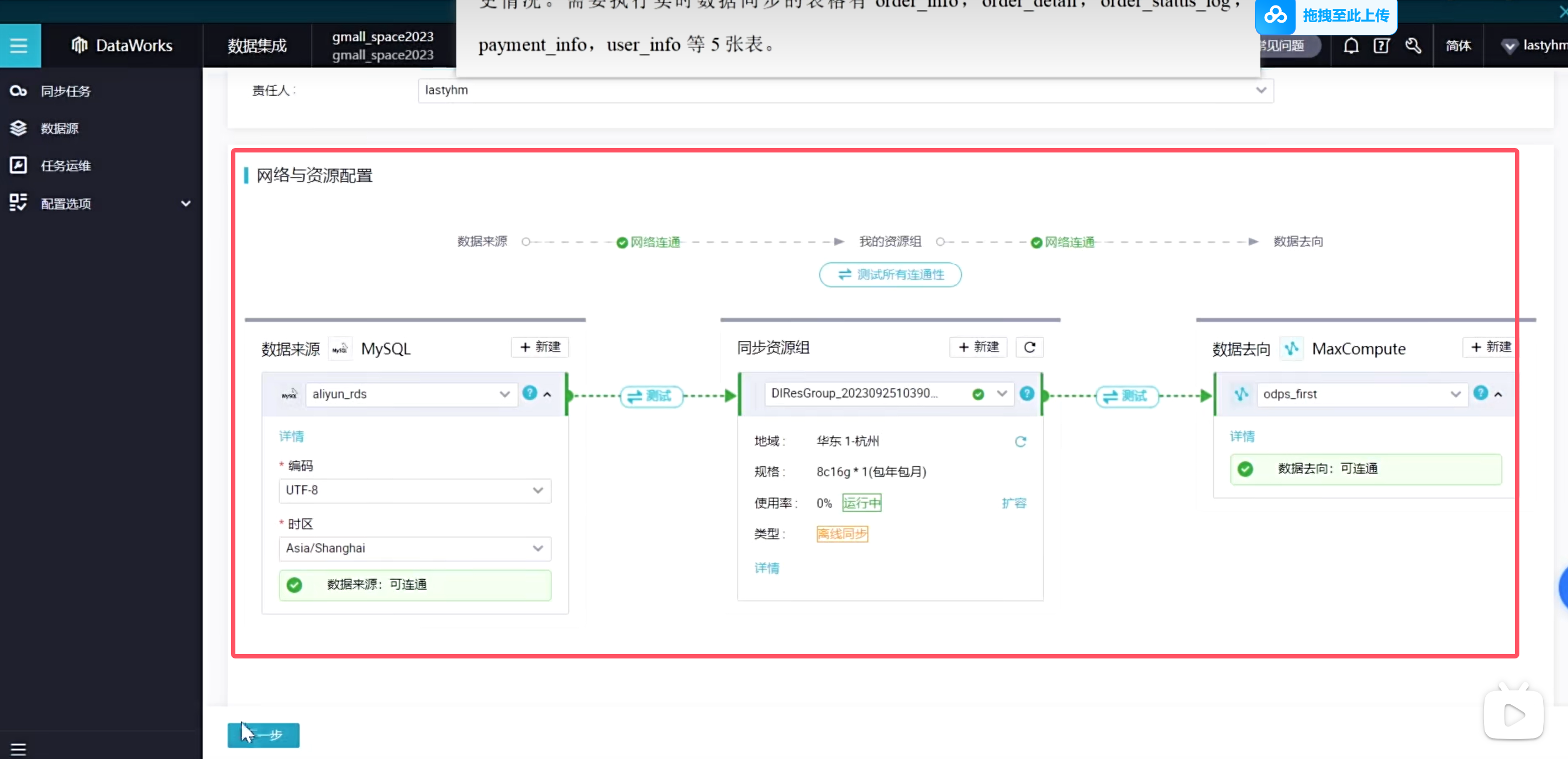
选择数据来源
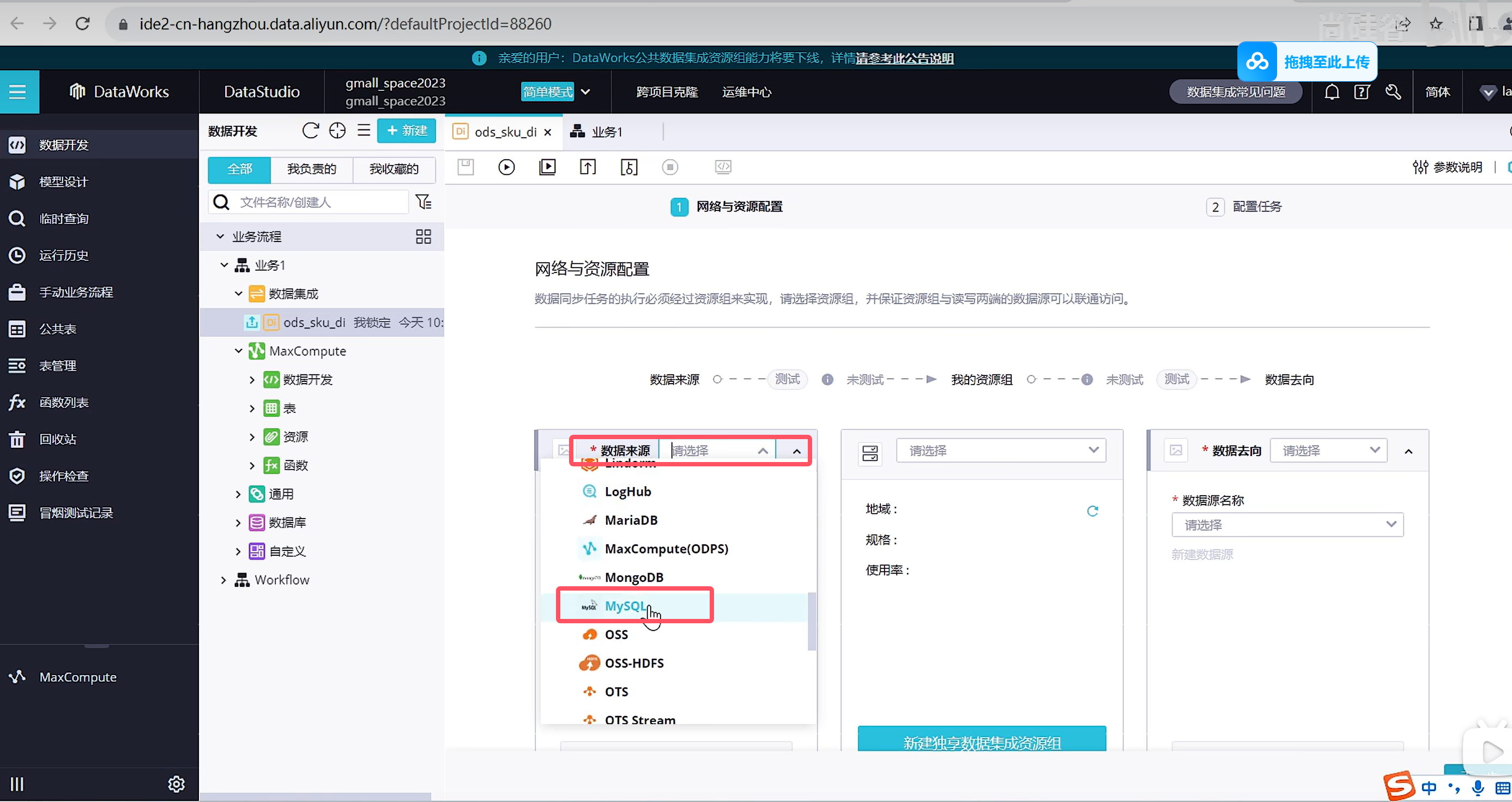
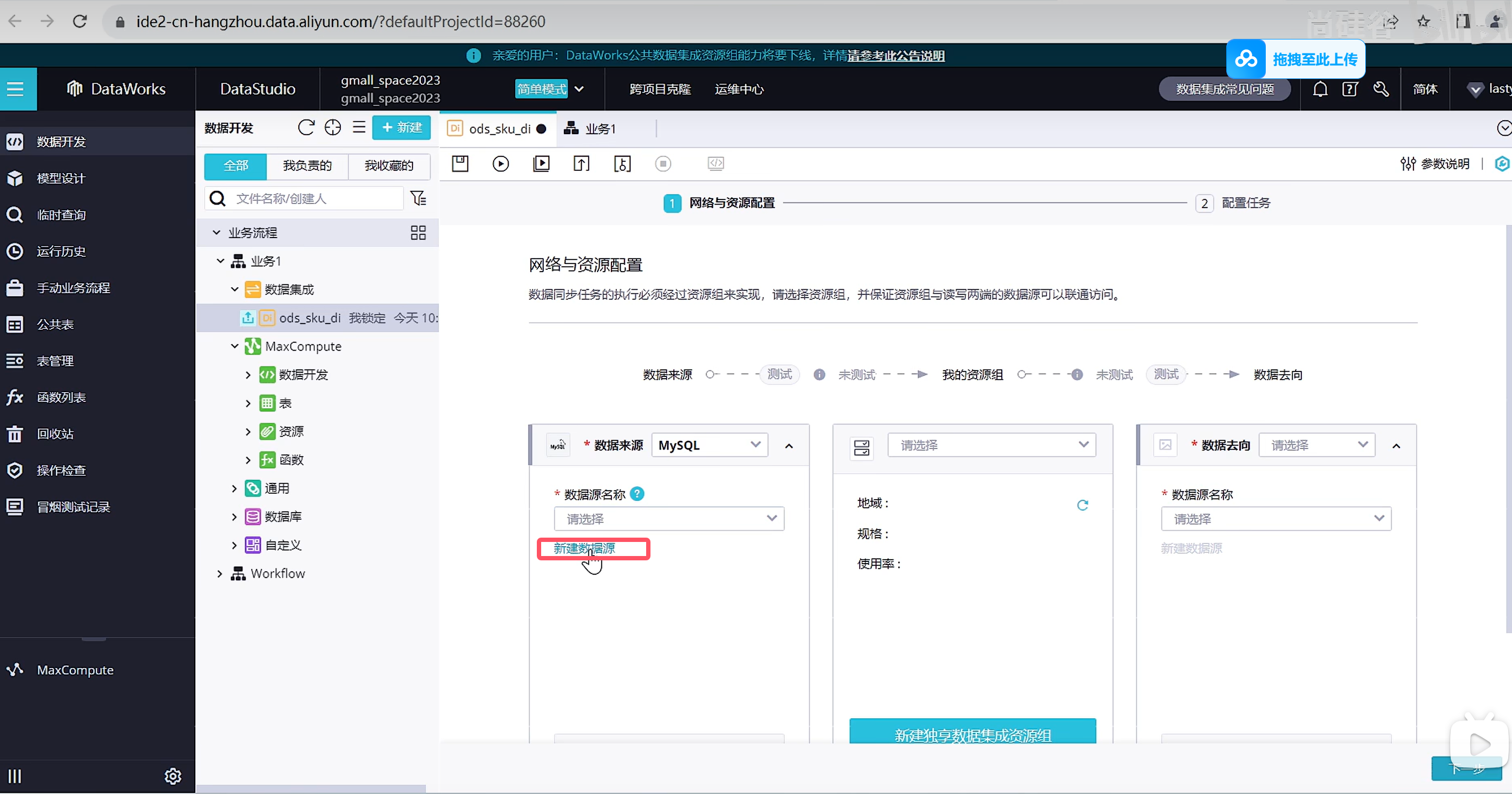
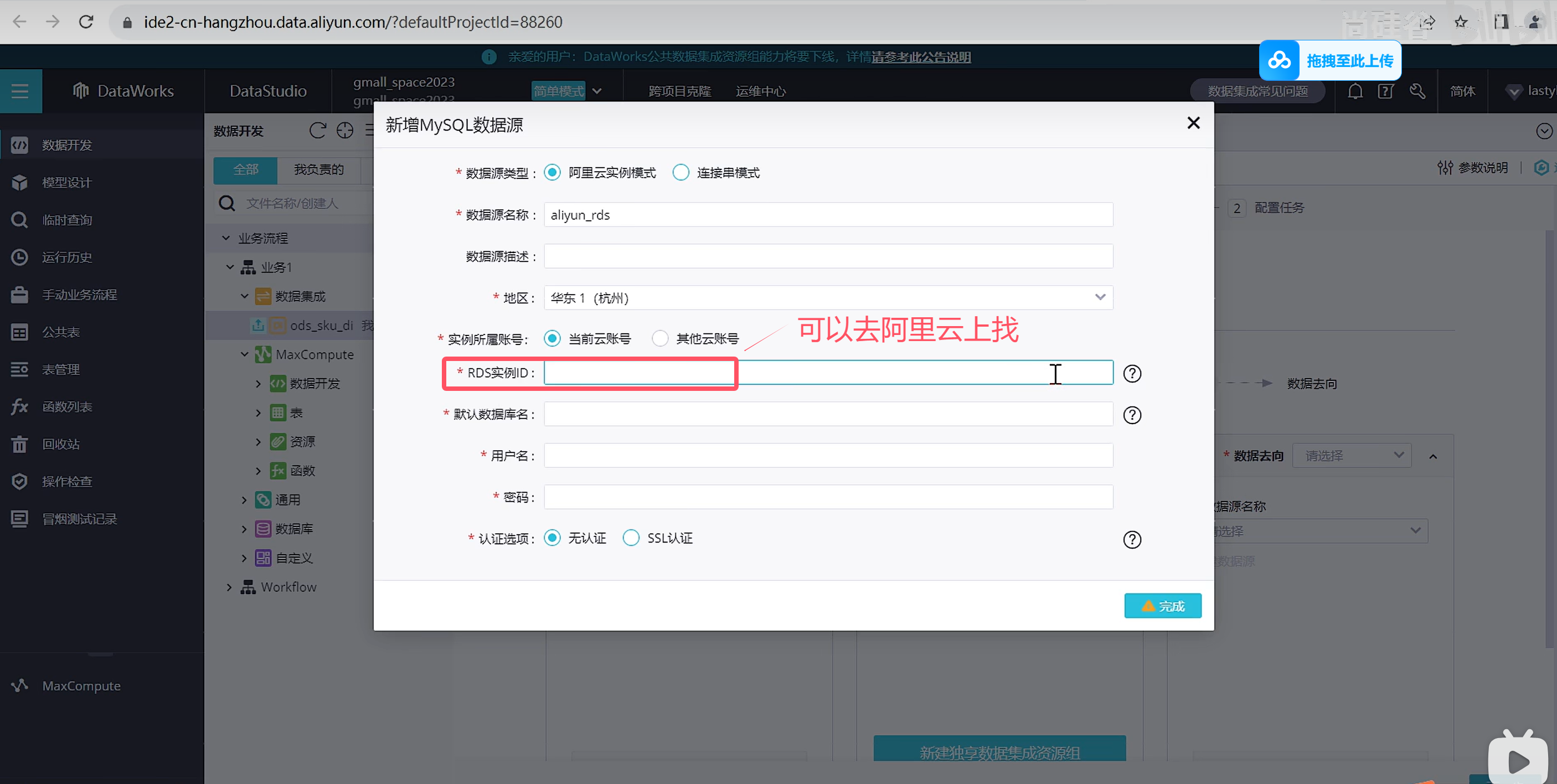

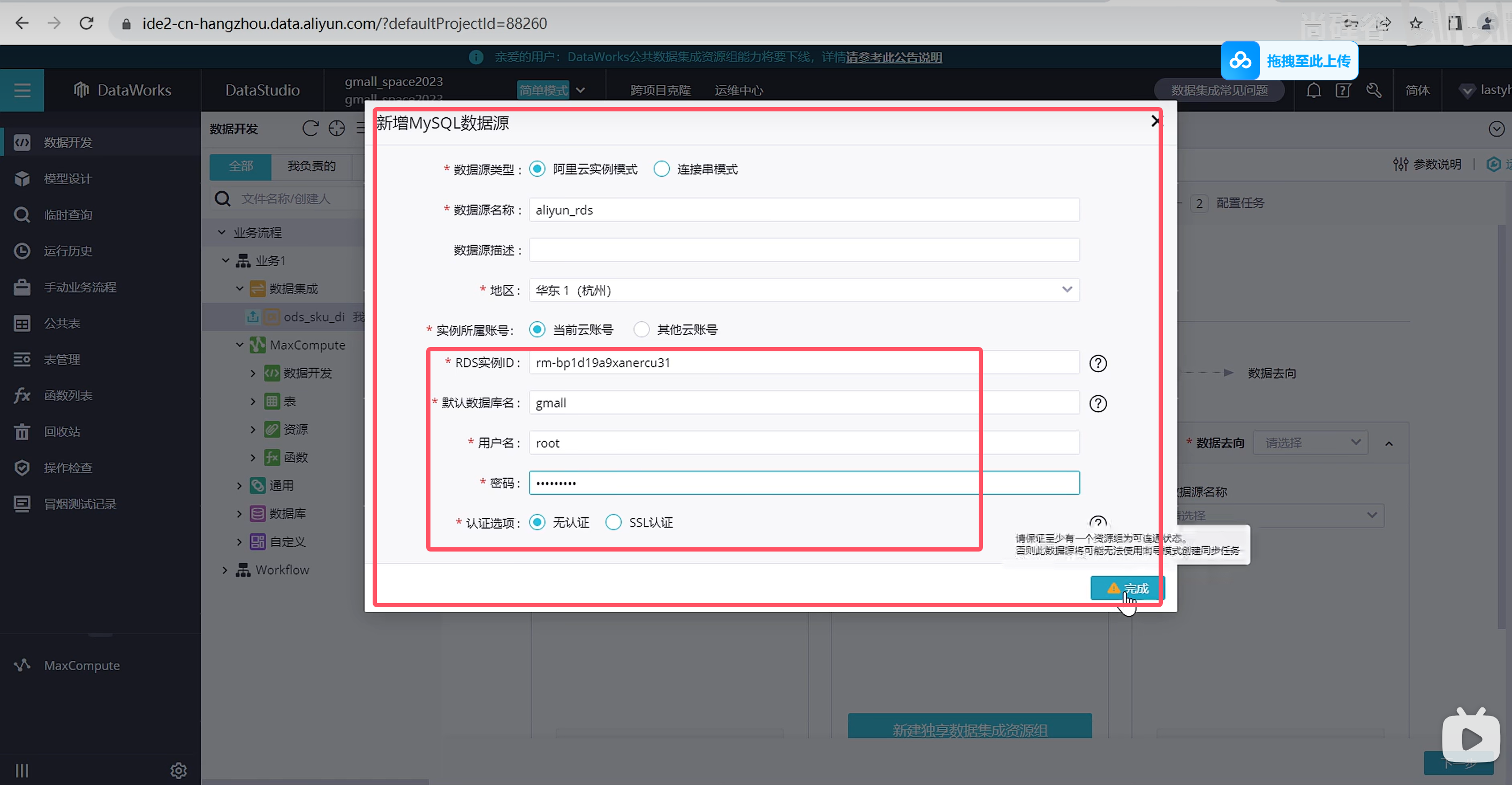
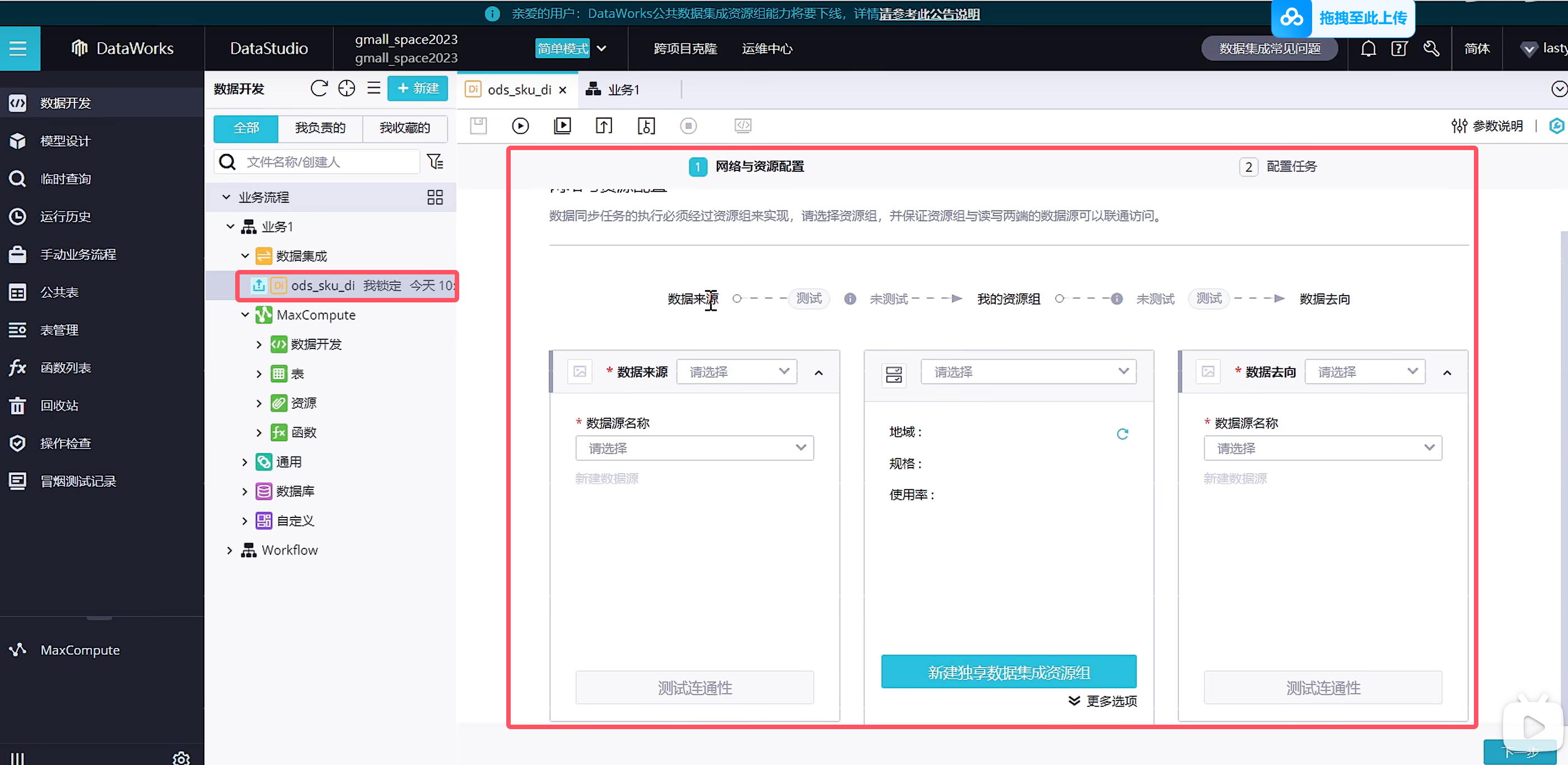
选择资源组,公共资源组可以调试使用,生成使用可以购买独享资源组获得更高效的通道
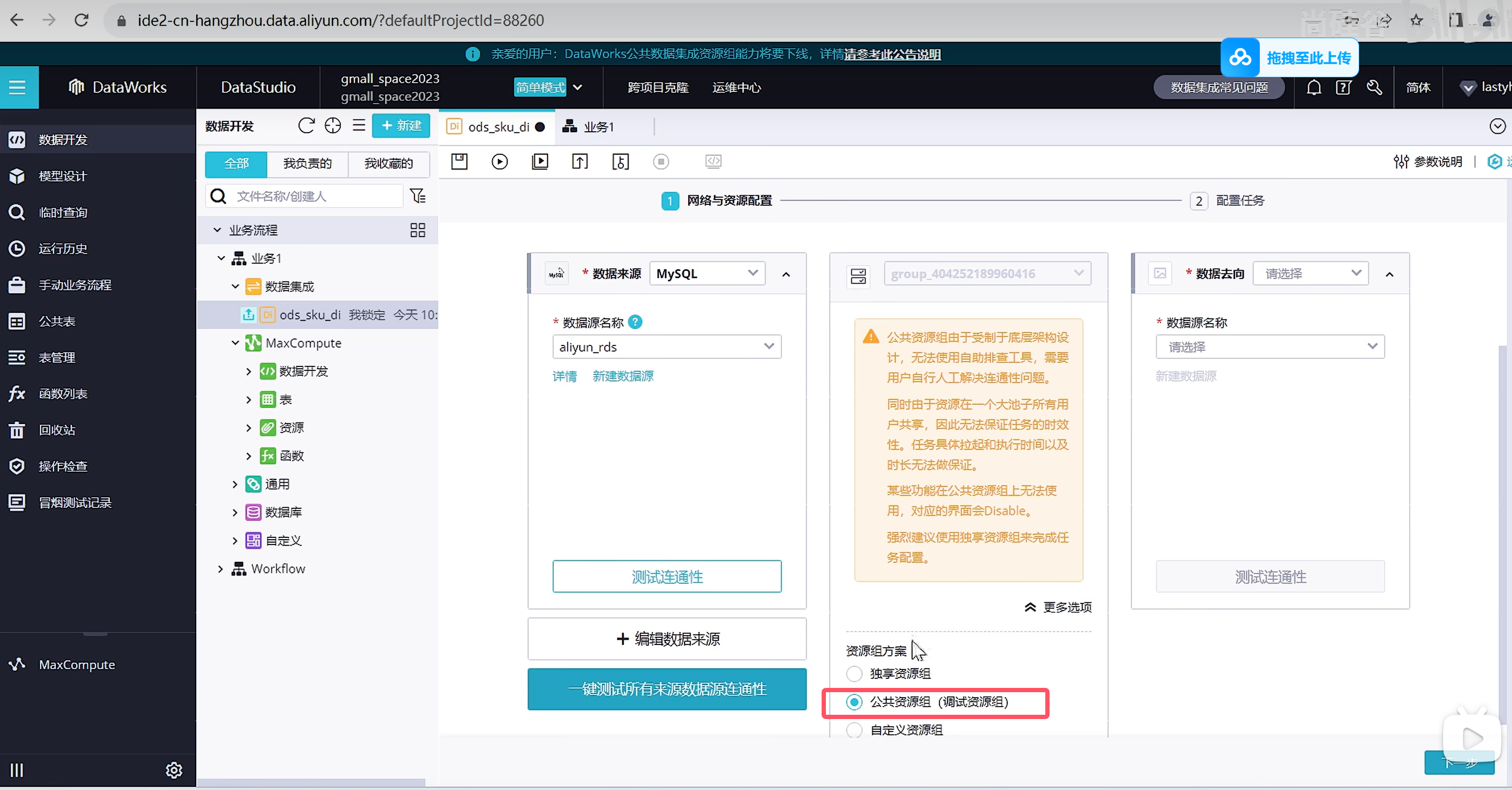
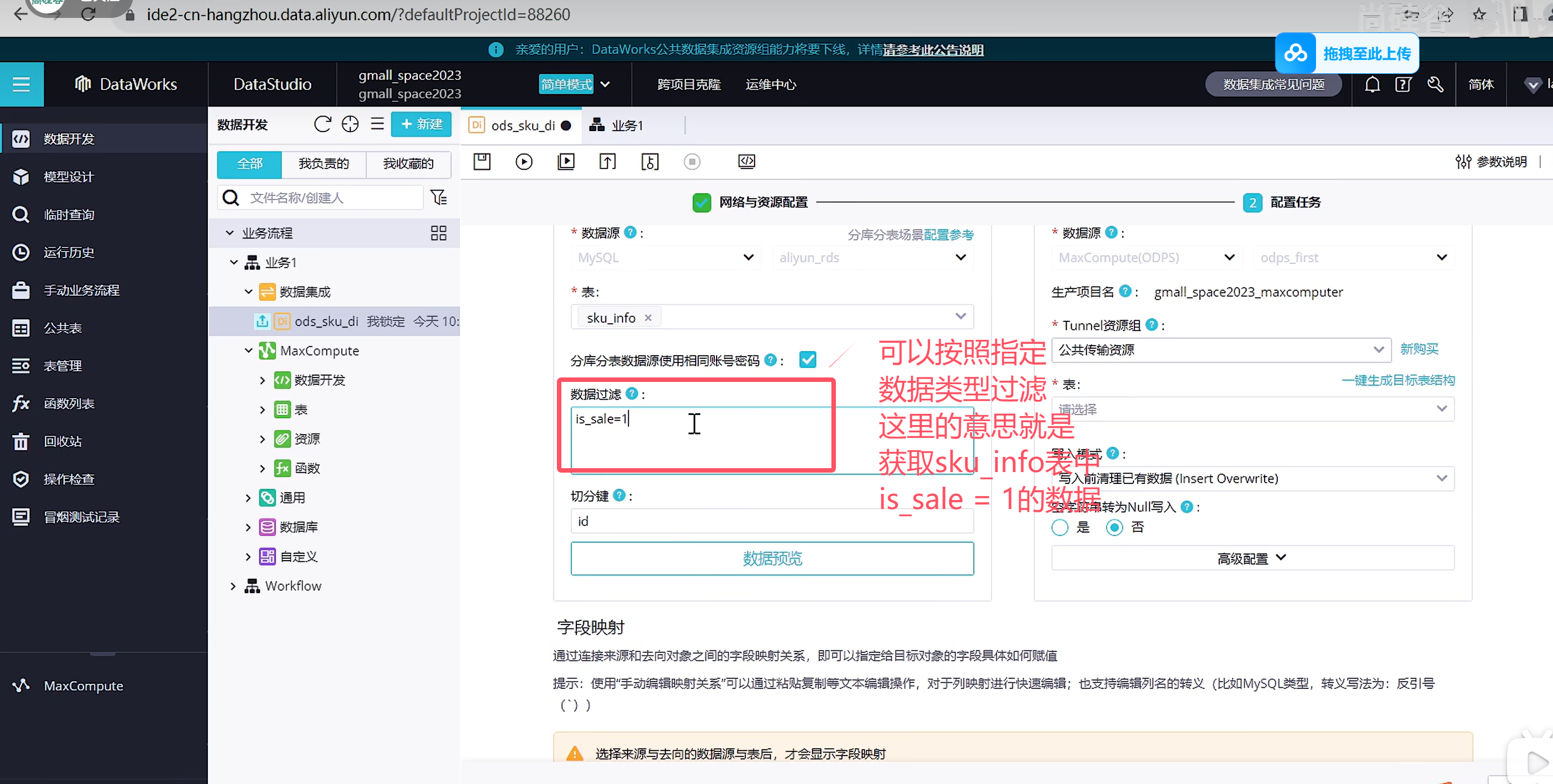
我们这里演示的是不需要过滤的
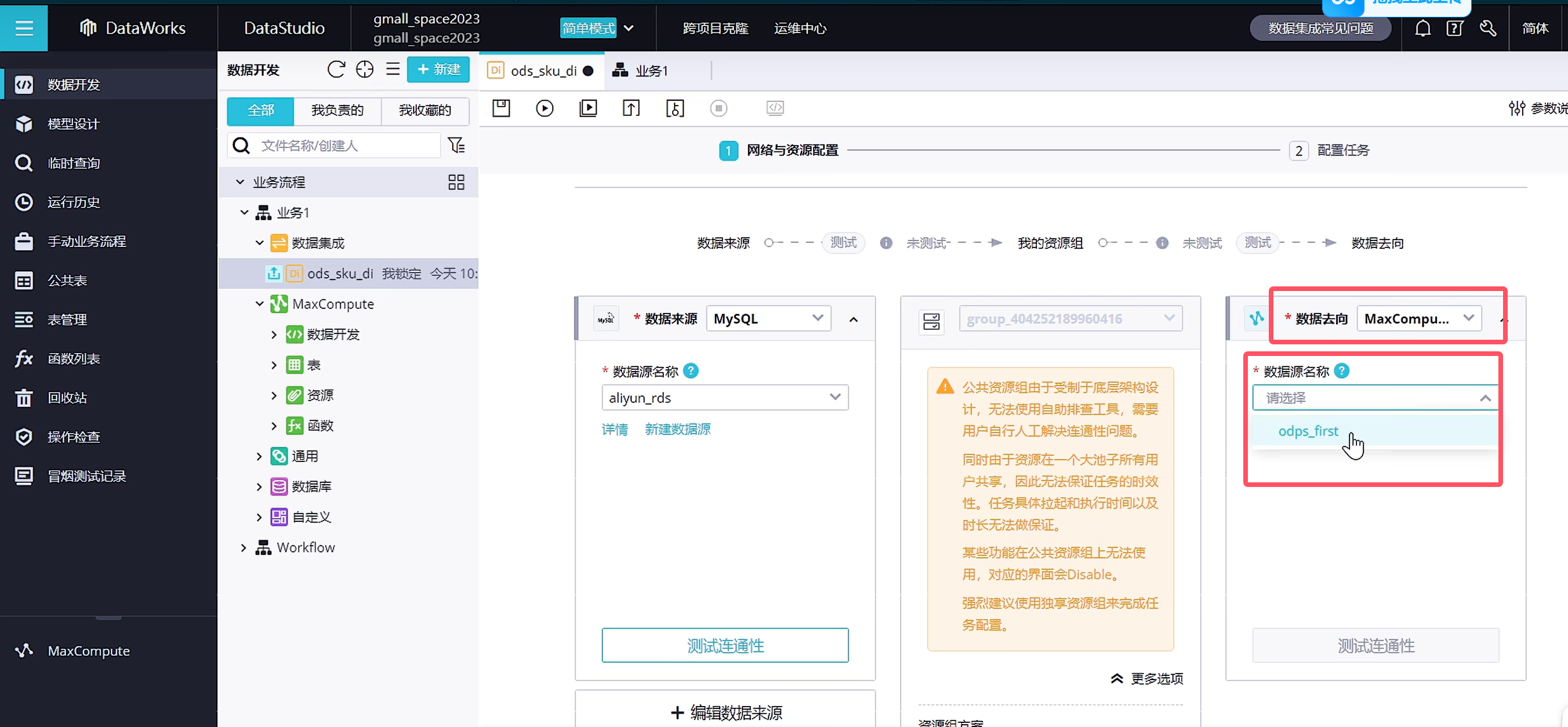
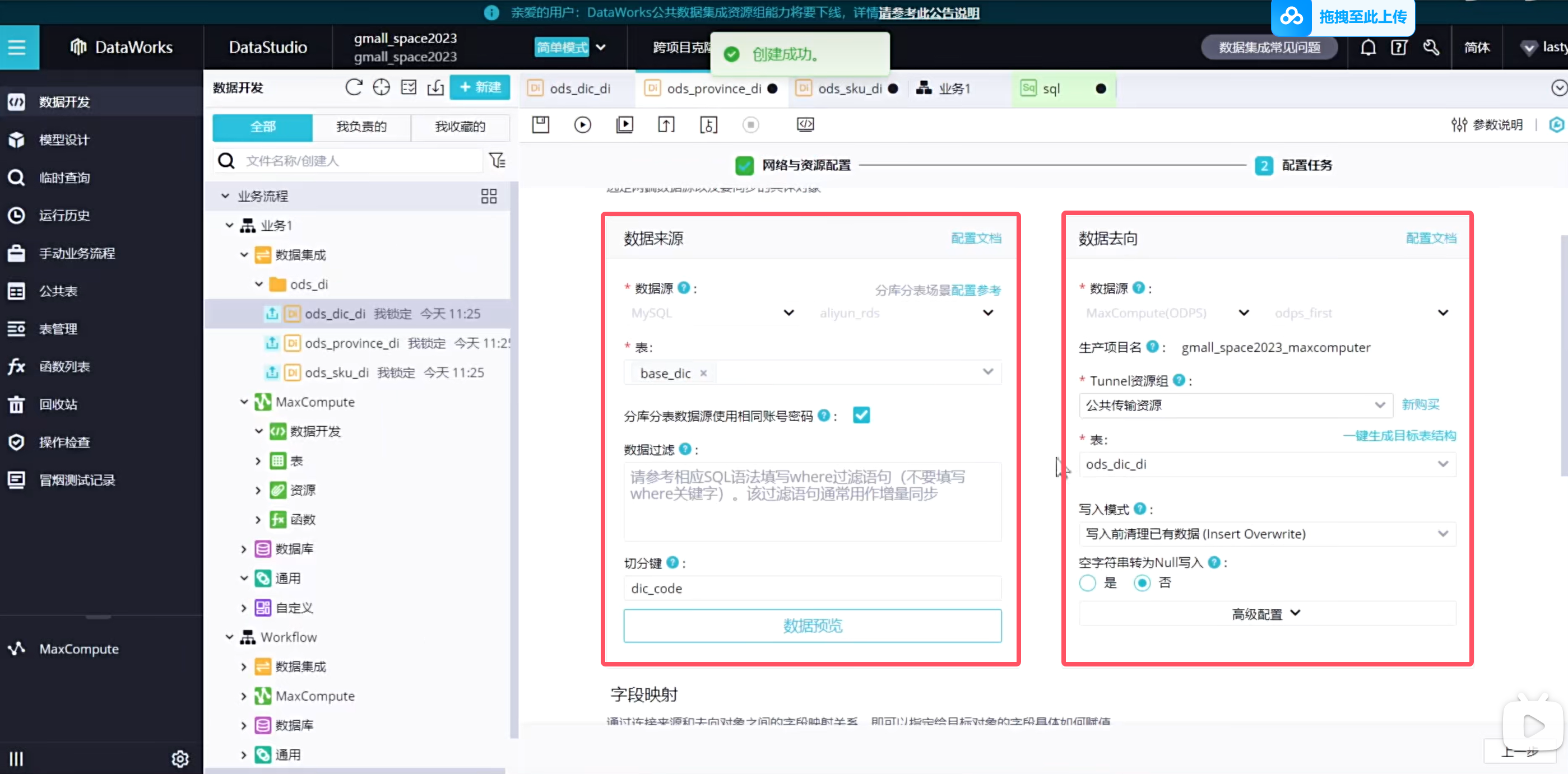
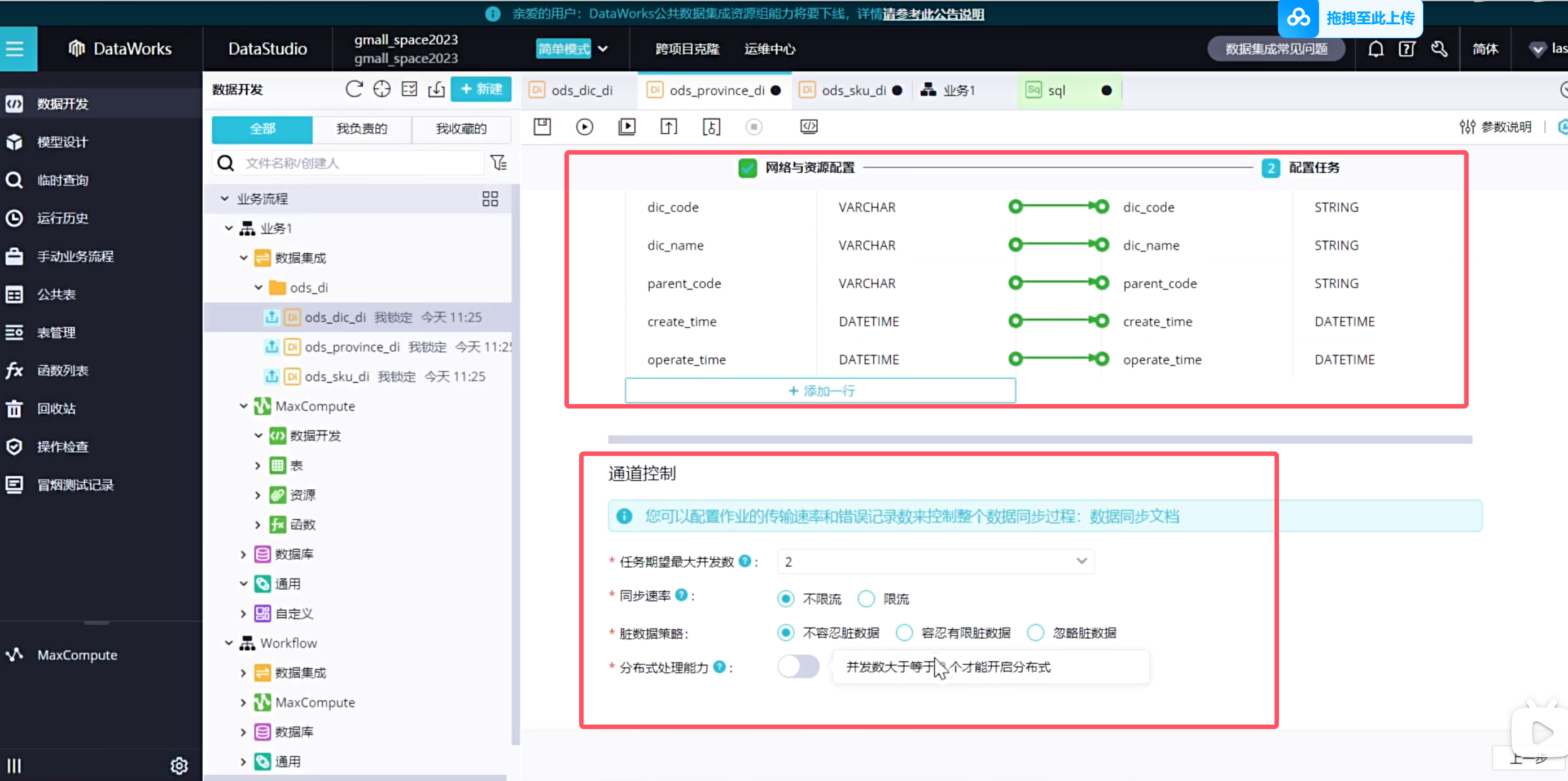
下一步配置数据去向
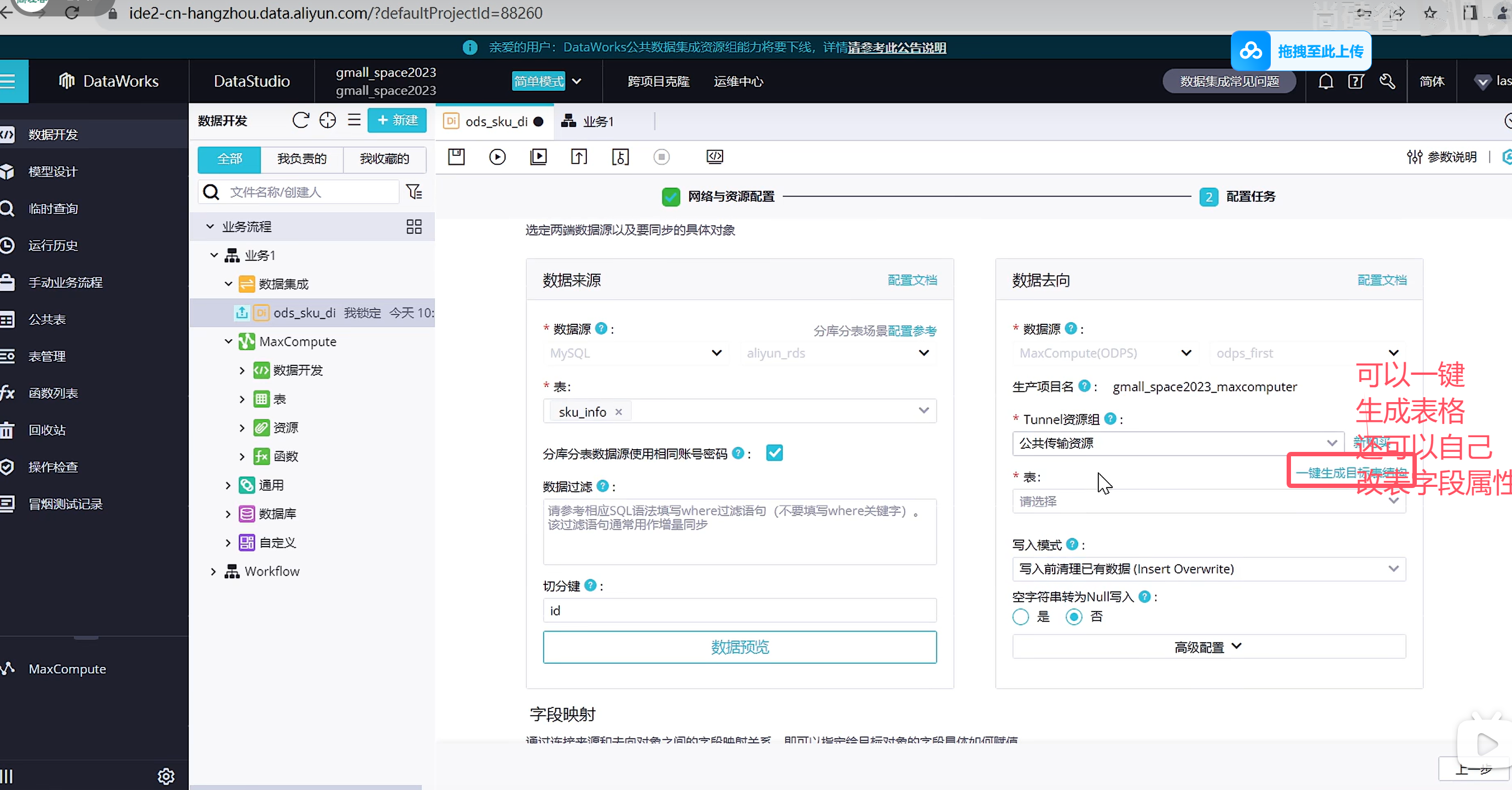
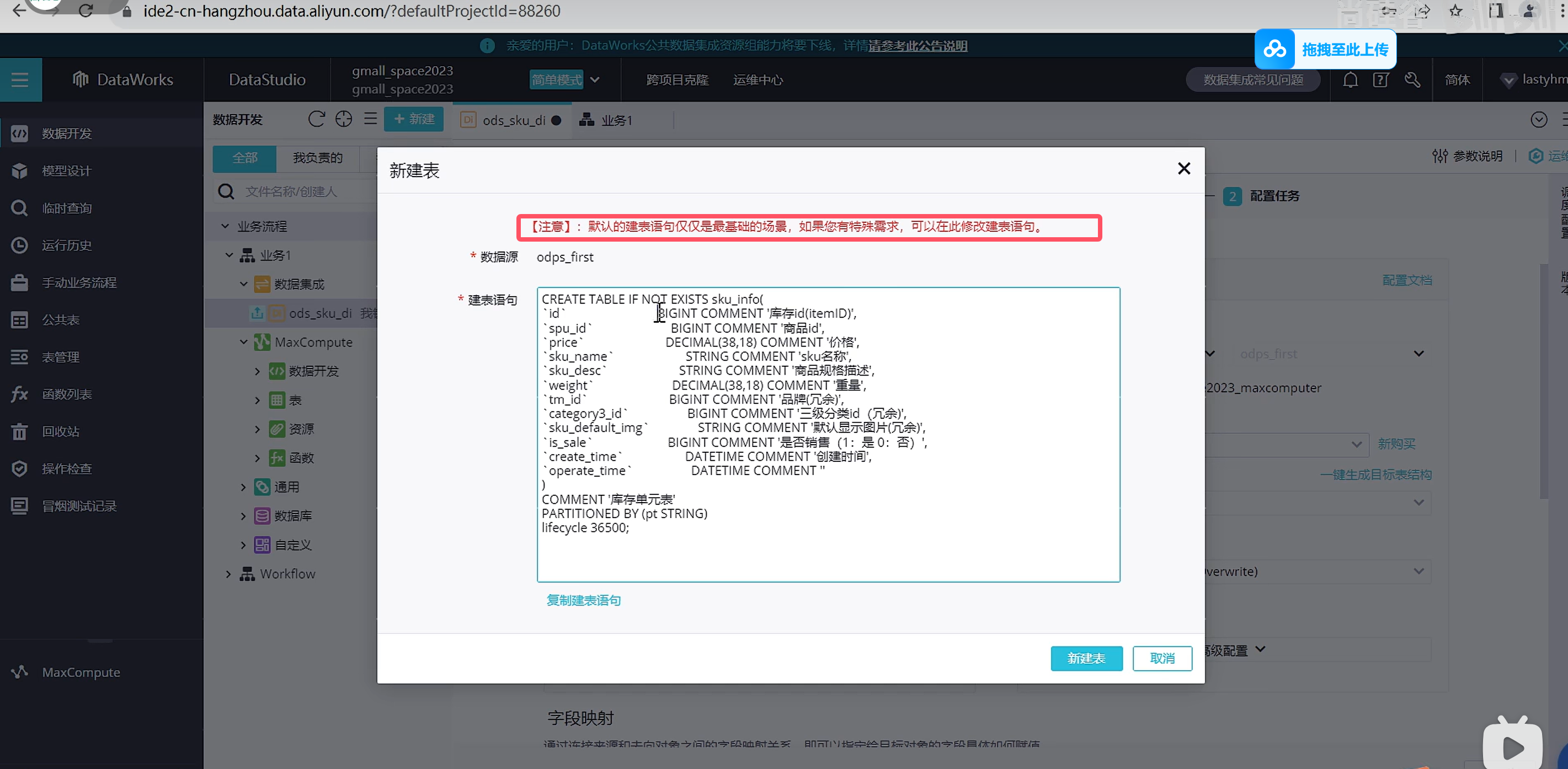
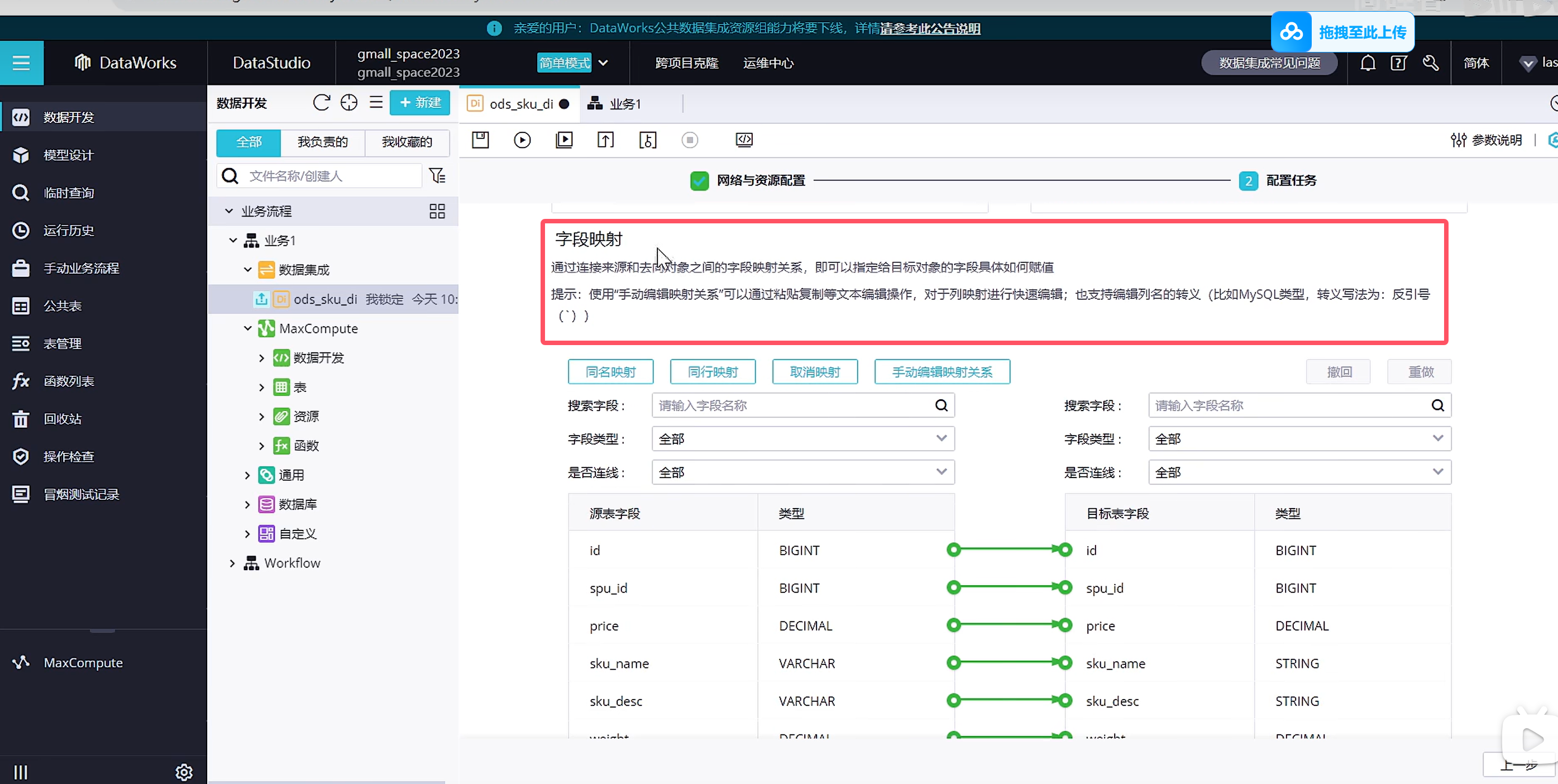
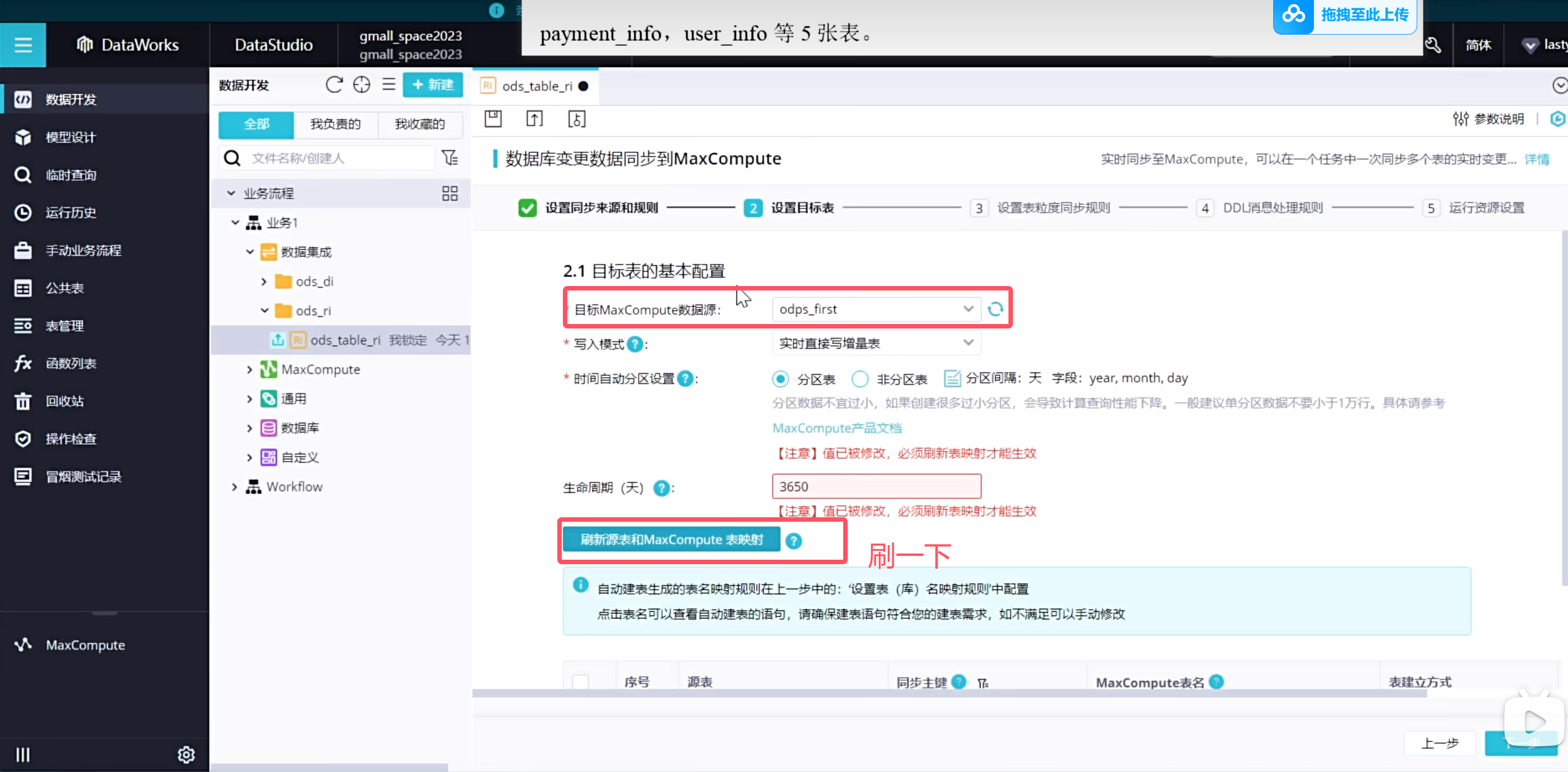
由于我们是自动创建的表结构,因此映射关系是自动帮我们映射好了,也可以进行修改
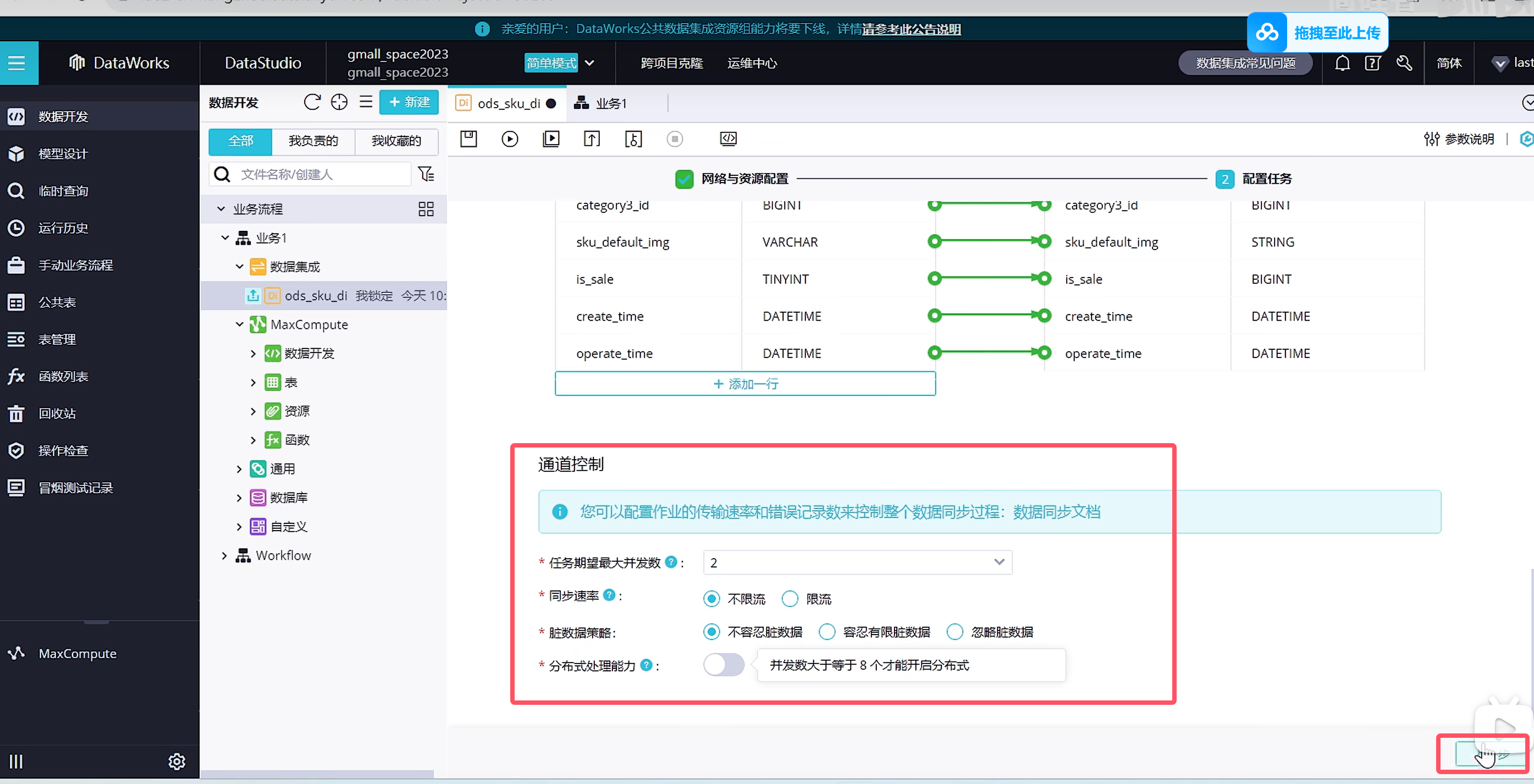
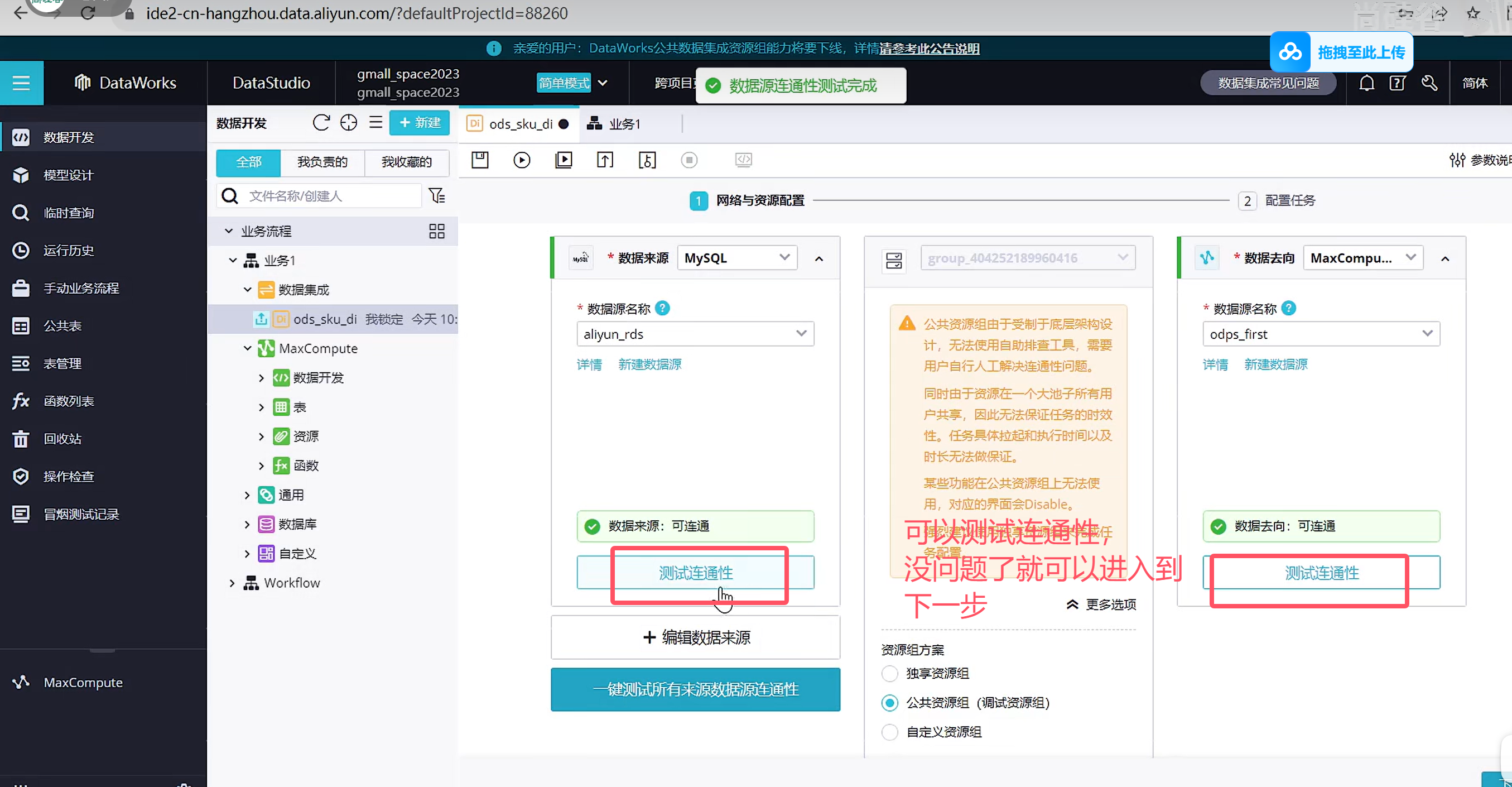
上图不需要点击上一步,应该是到了调度配置了
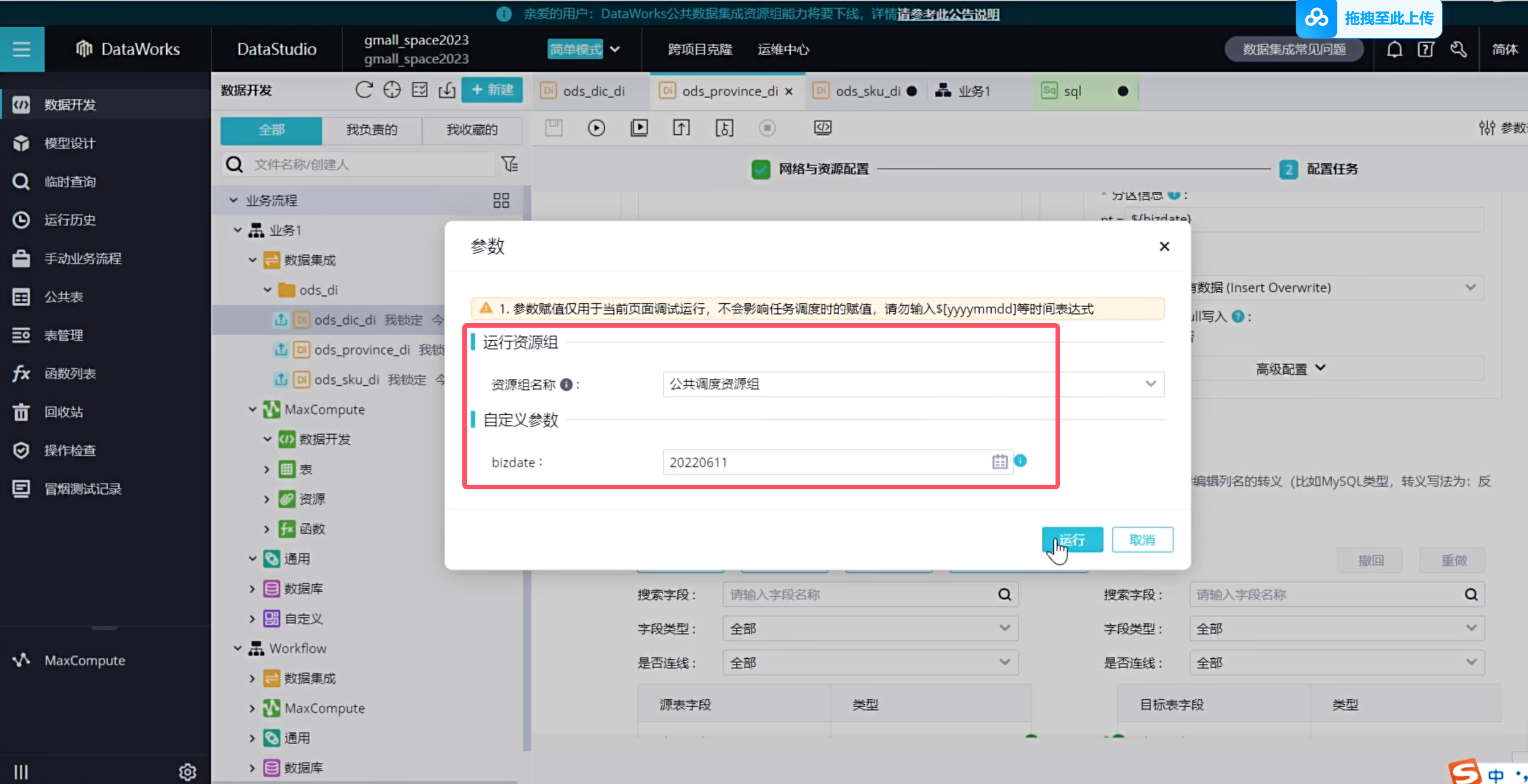
默认的调度是每天同步处理昨天的业务数据,在测试环境中,可以随意填写参数直接运行
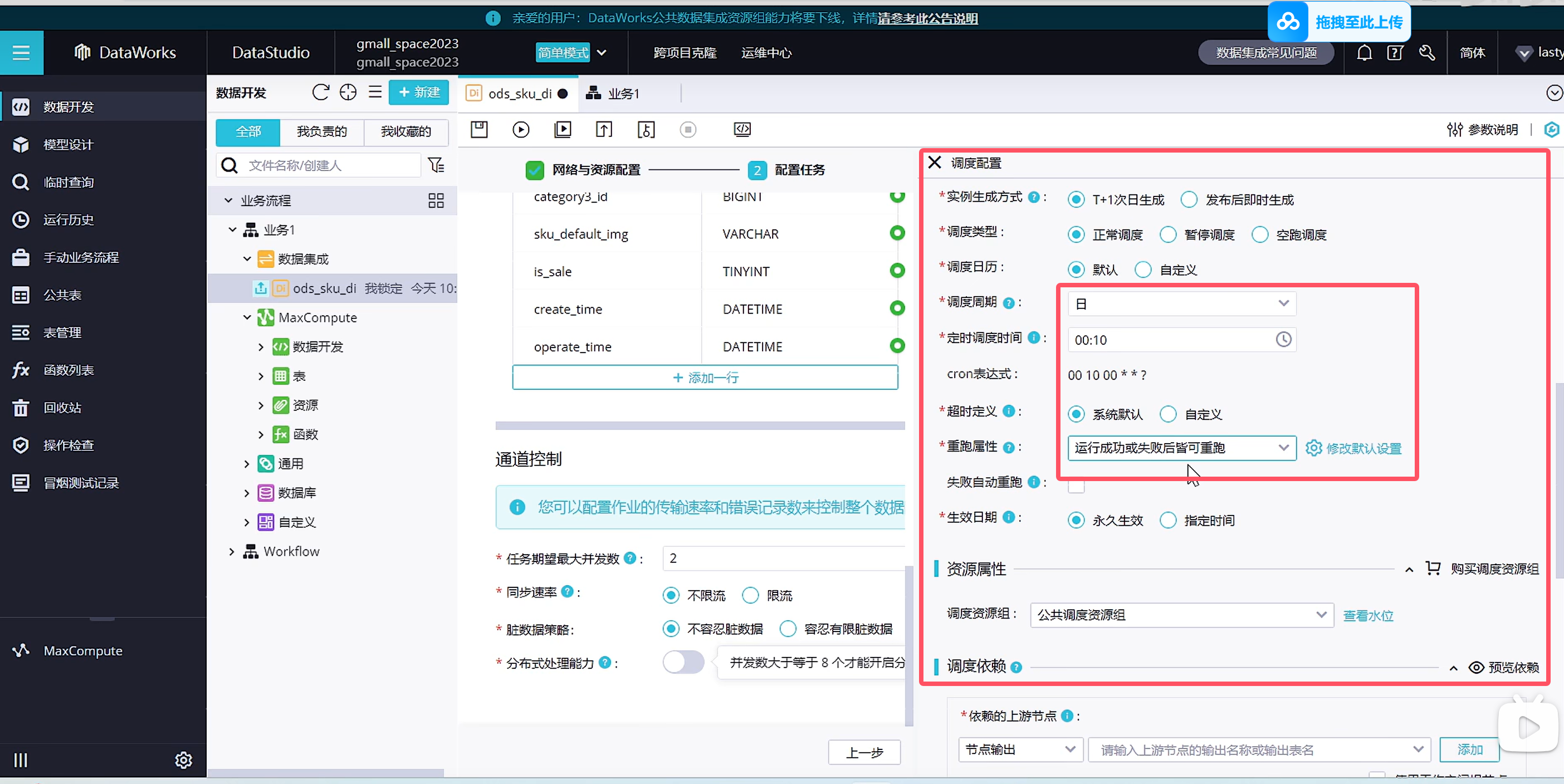
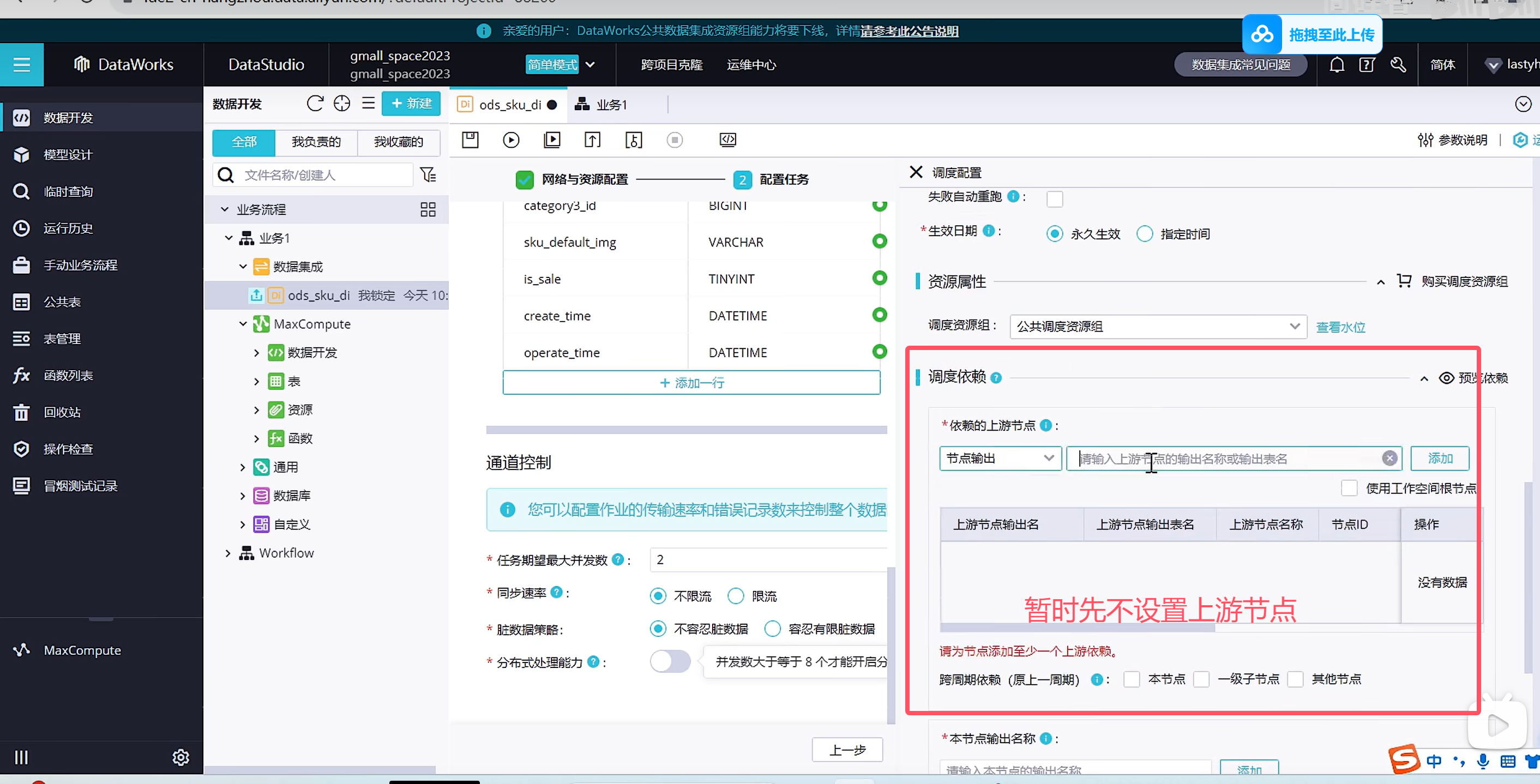
点击保存
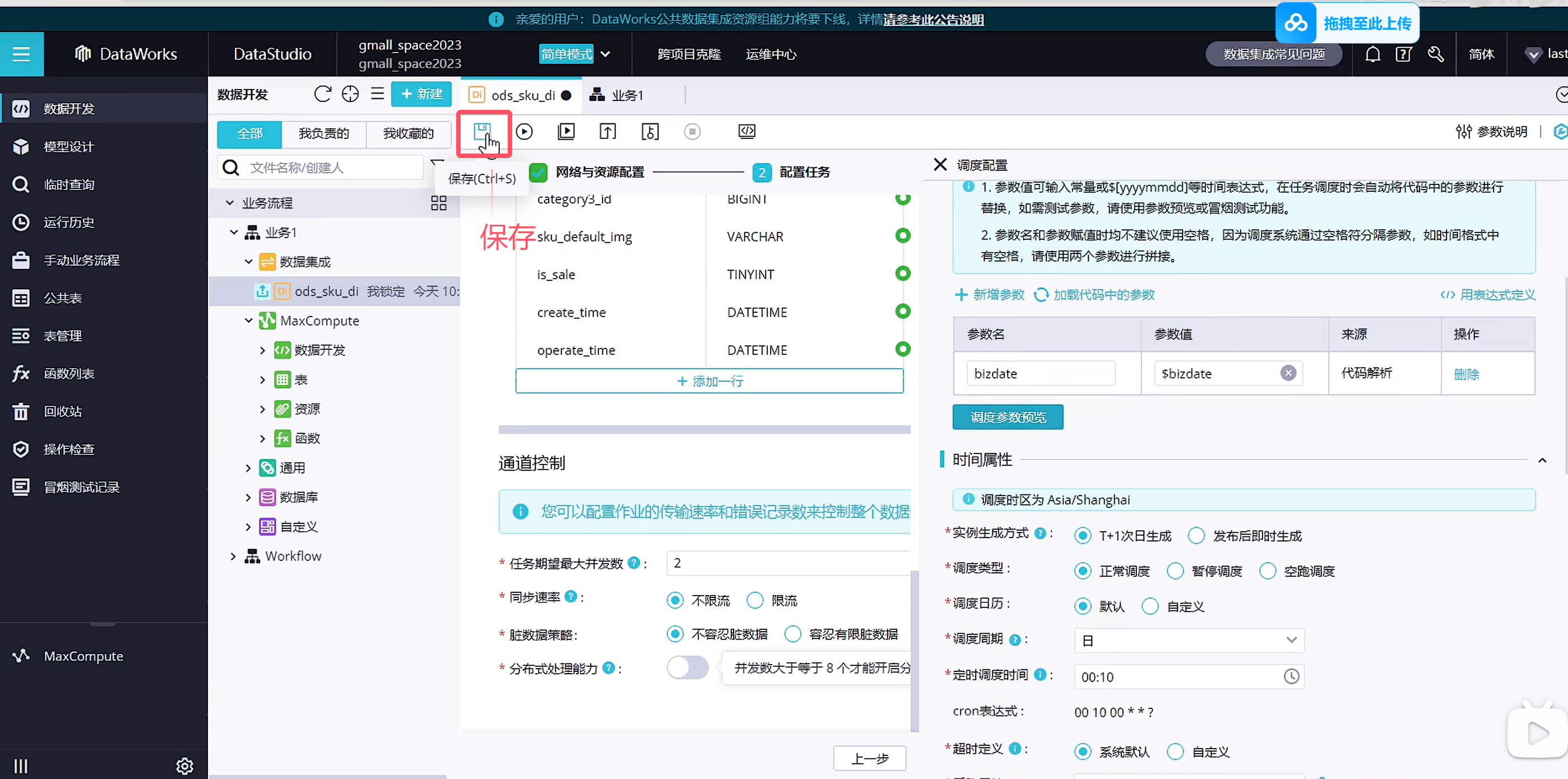
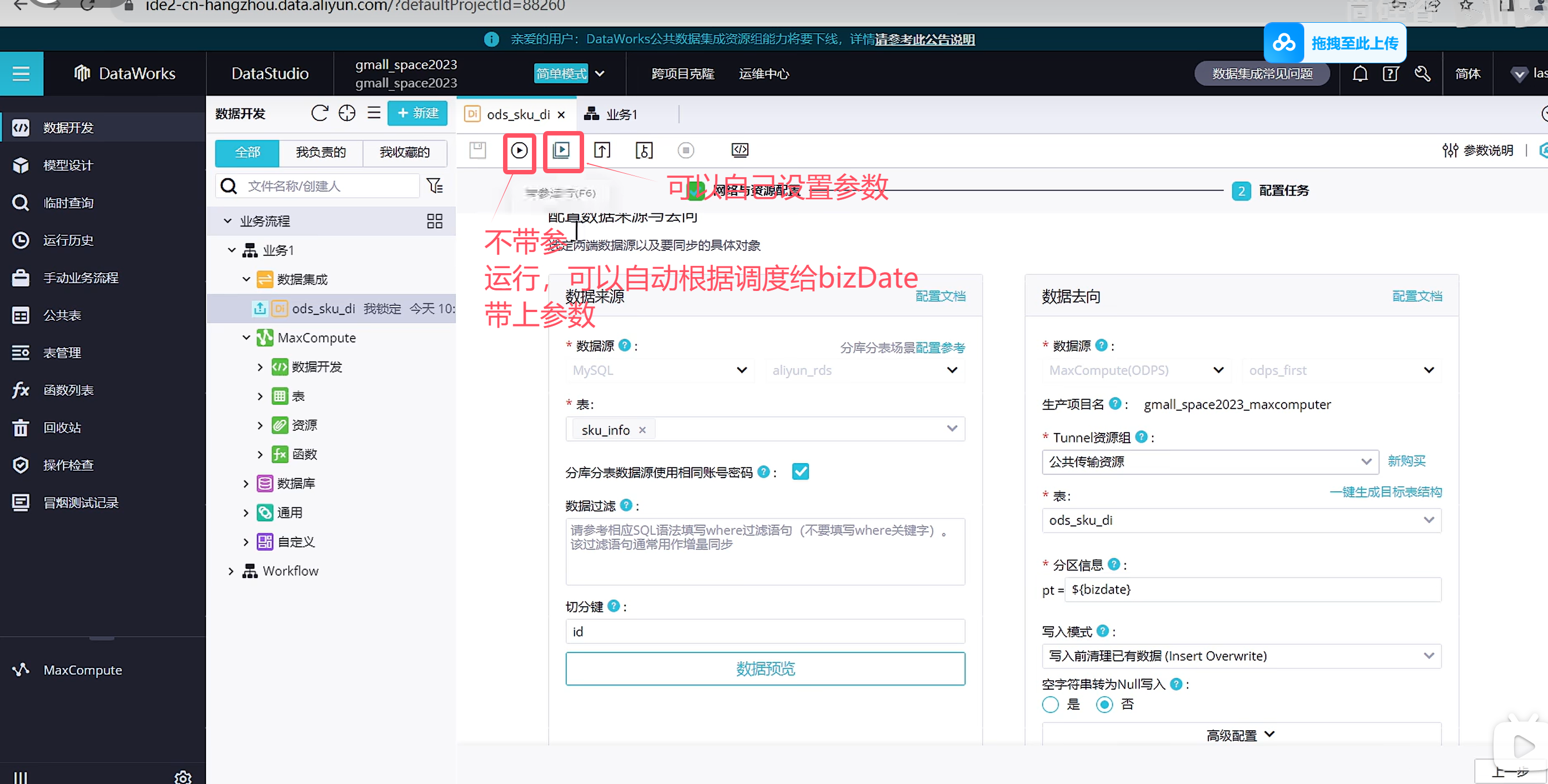
在测试的时候可以自己手动带参数运行,那摩填写的参数就是作为昨天的数据与逆行了
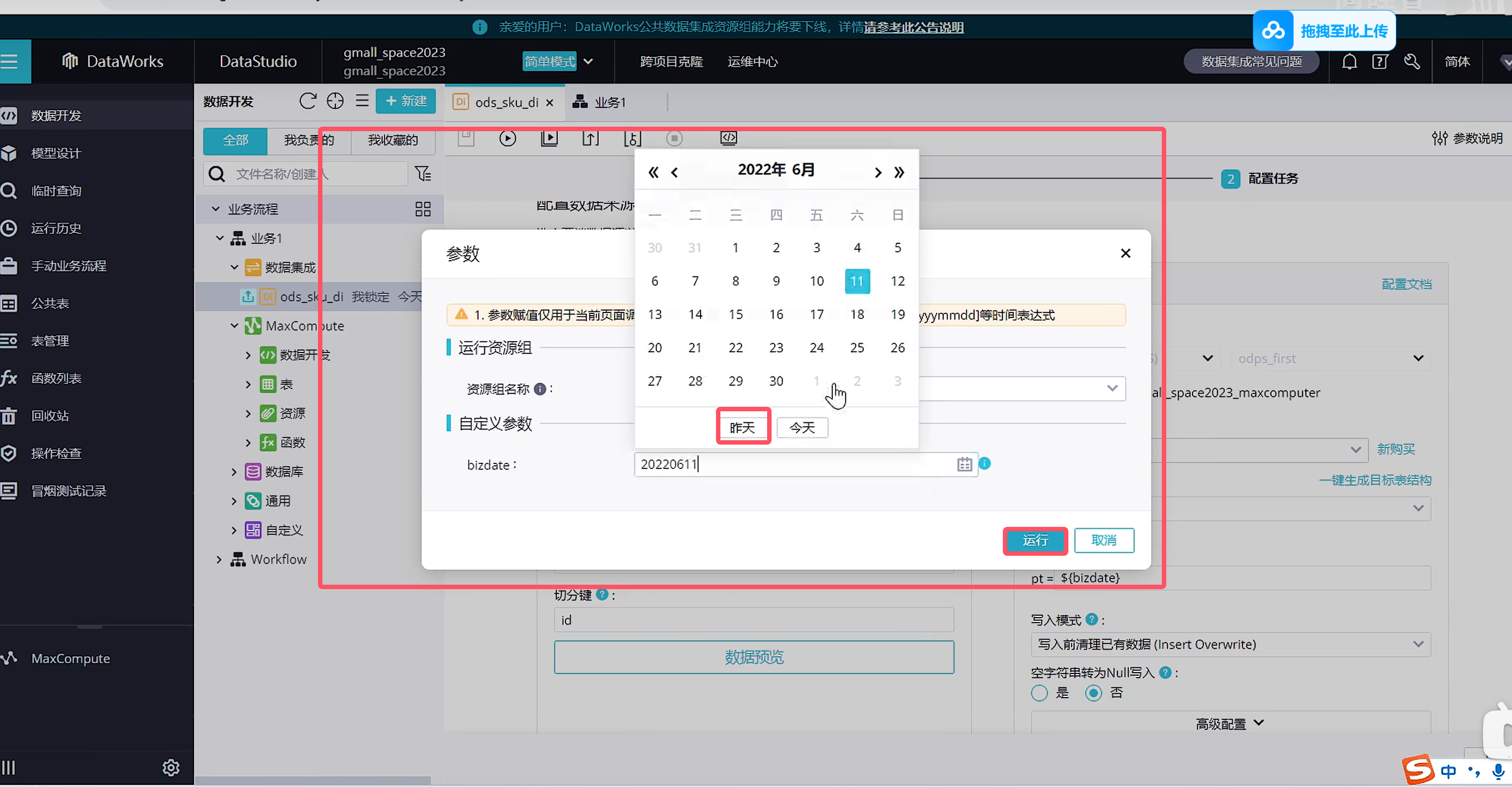
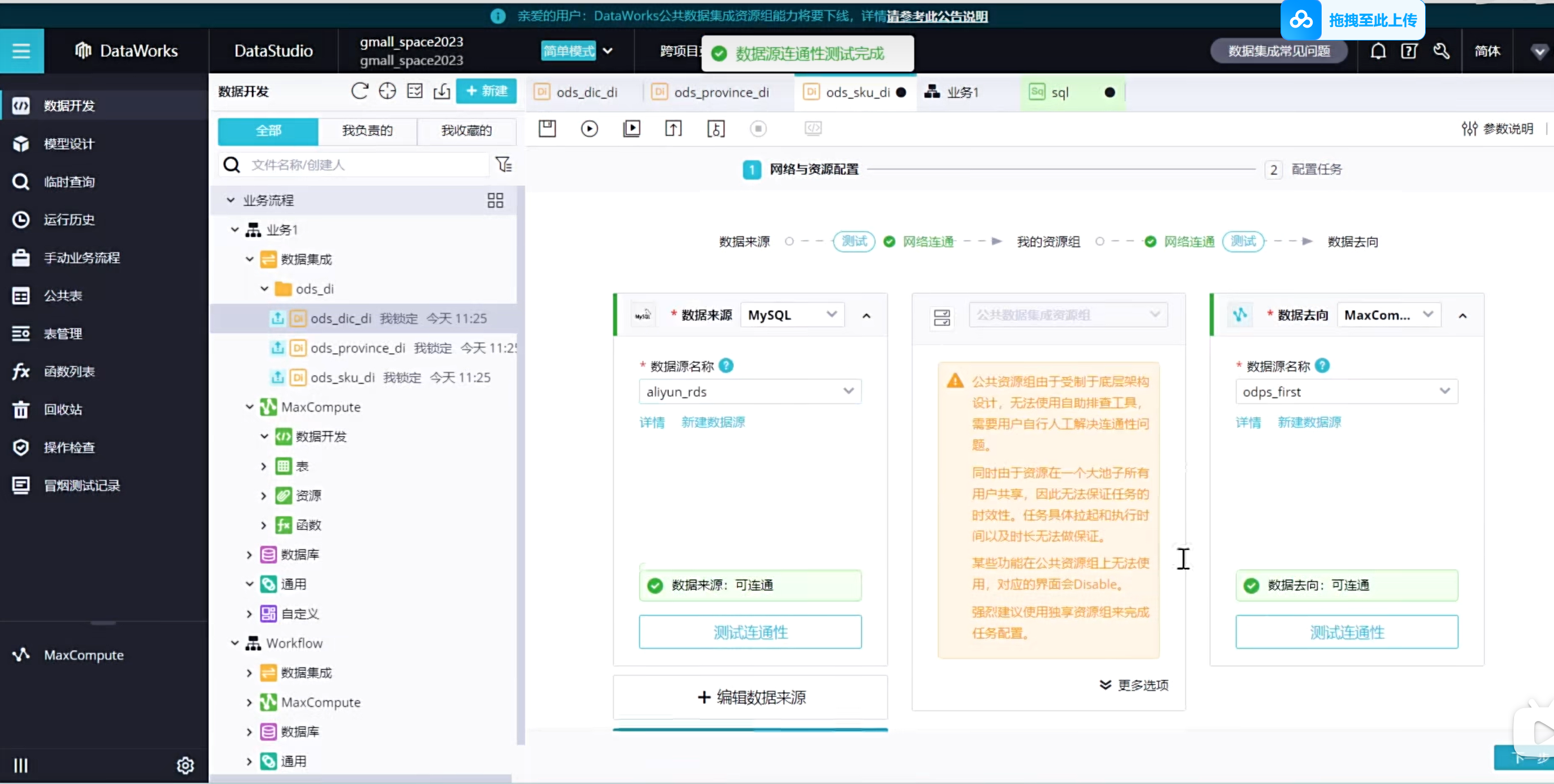
由于我们使用的是公共资源组,所以我们在使用起来的时候是需要排队的,因此需要我们等一下
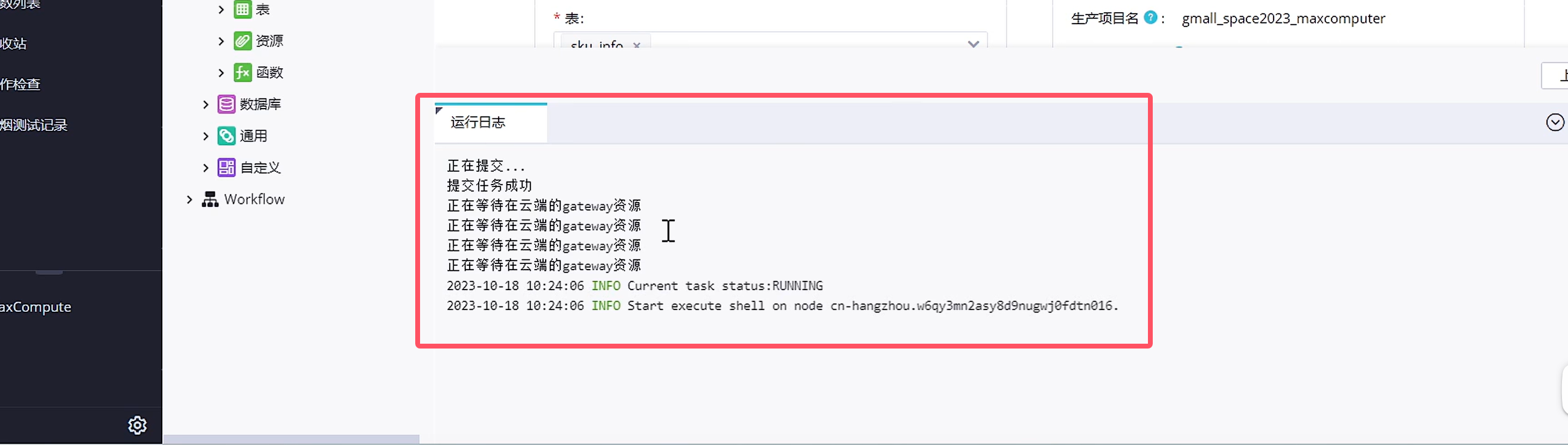
数据同步完了之后,下面我们可以去查看这些数据
创建完成之后,就可以拥有一个临时页面,来帮助我们写sql
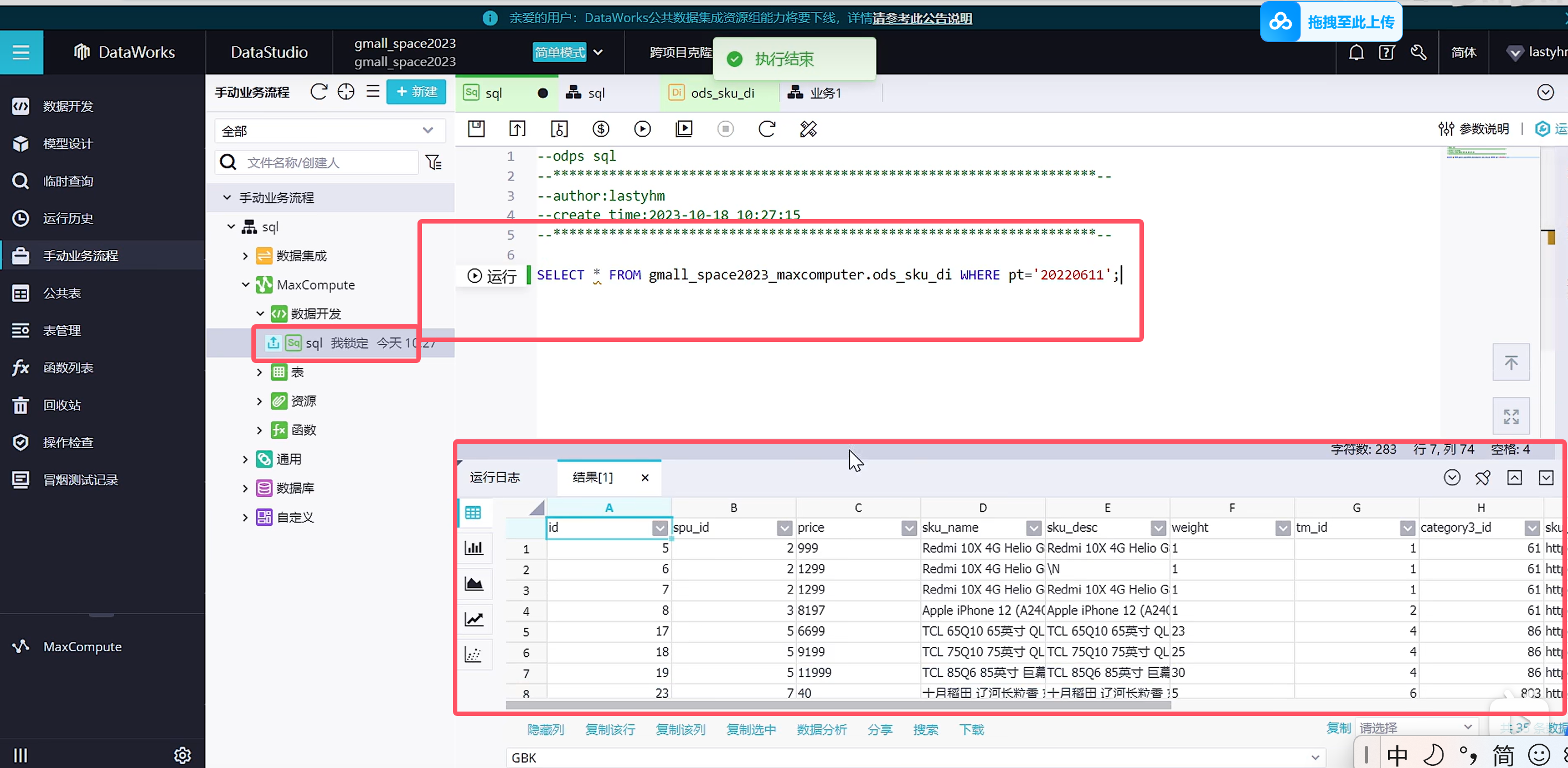
可以看到已经查到了我们导入的数据
还有一种方式可以查看我们的表,在公共表直接搜索我们创建的表

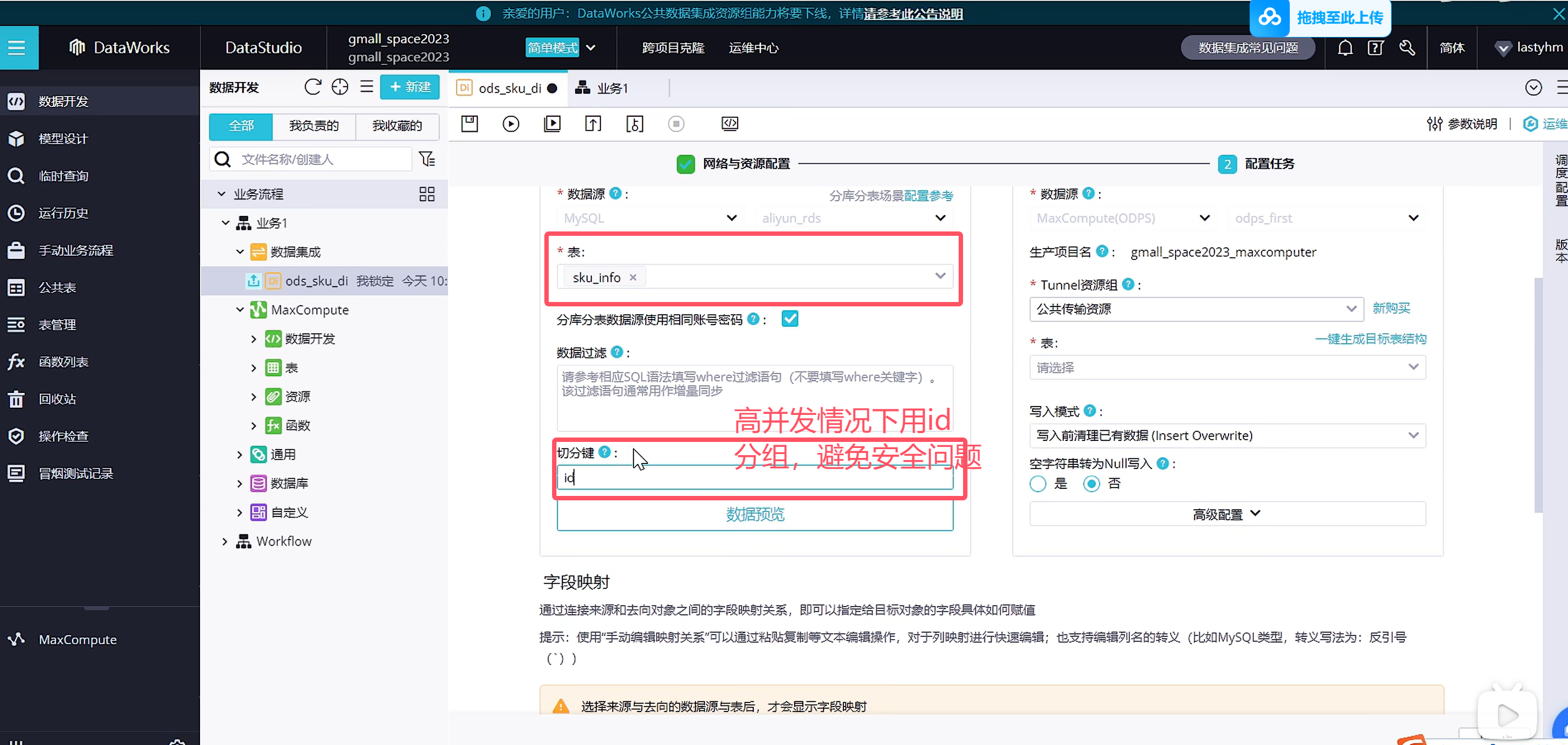
下面来完成完整的离线全量表同步
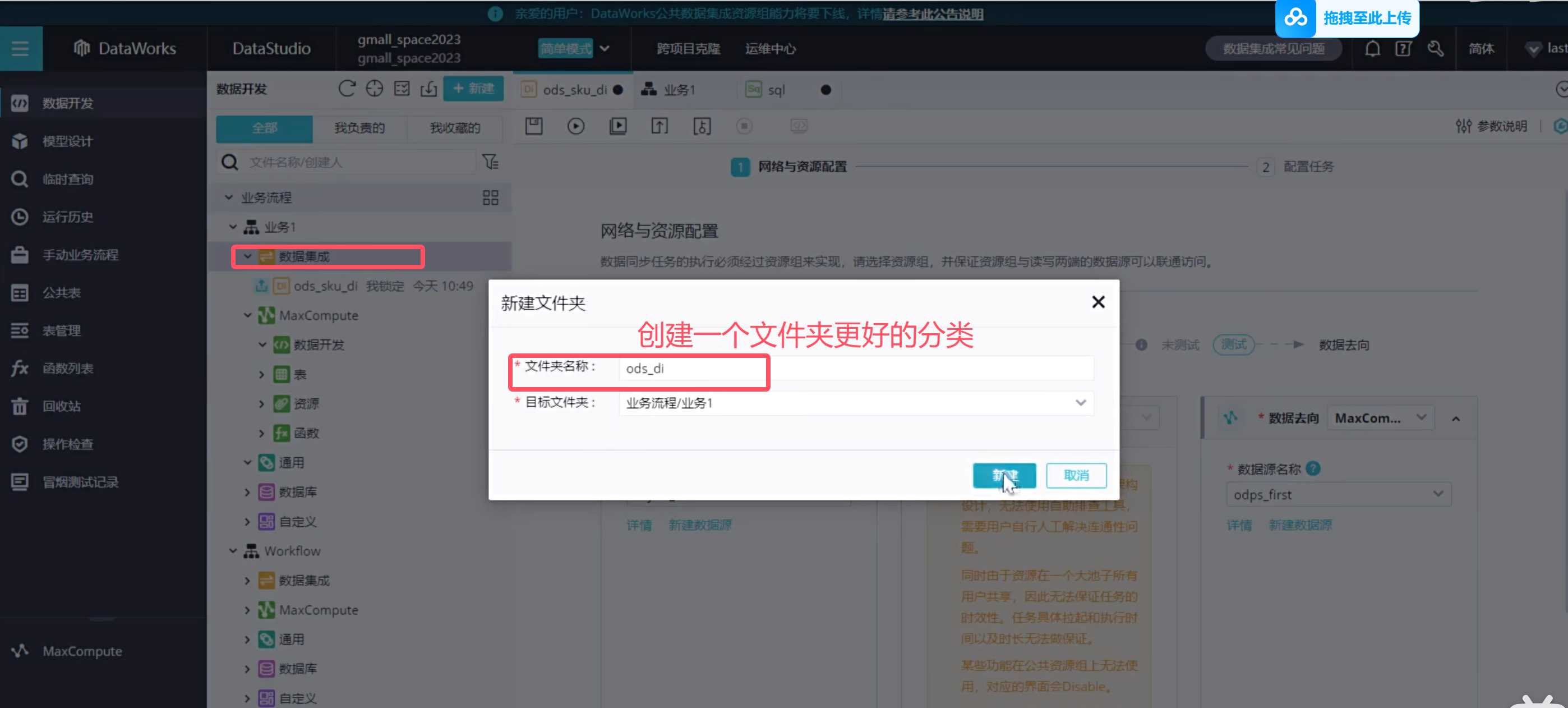
将上一步创建的离线表ods_sku_di移到上图中创建的文件夹下面
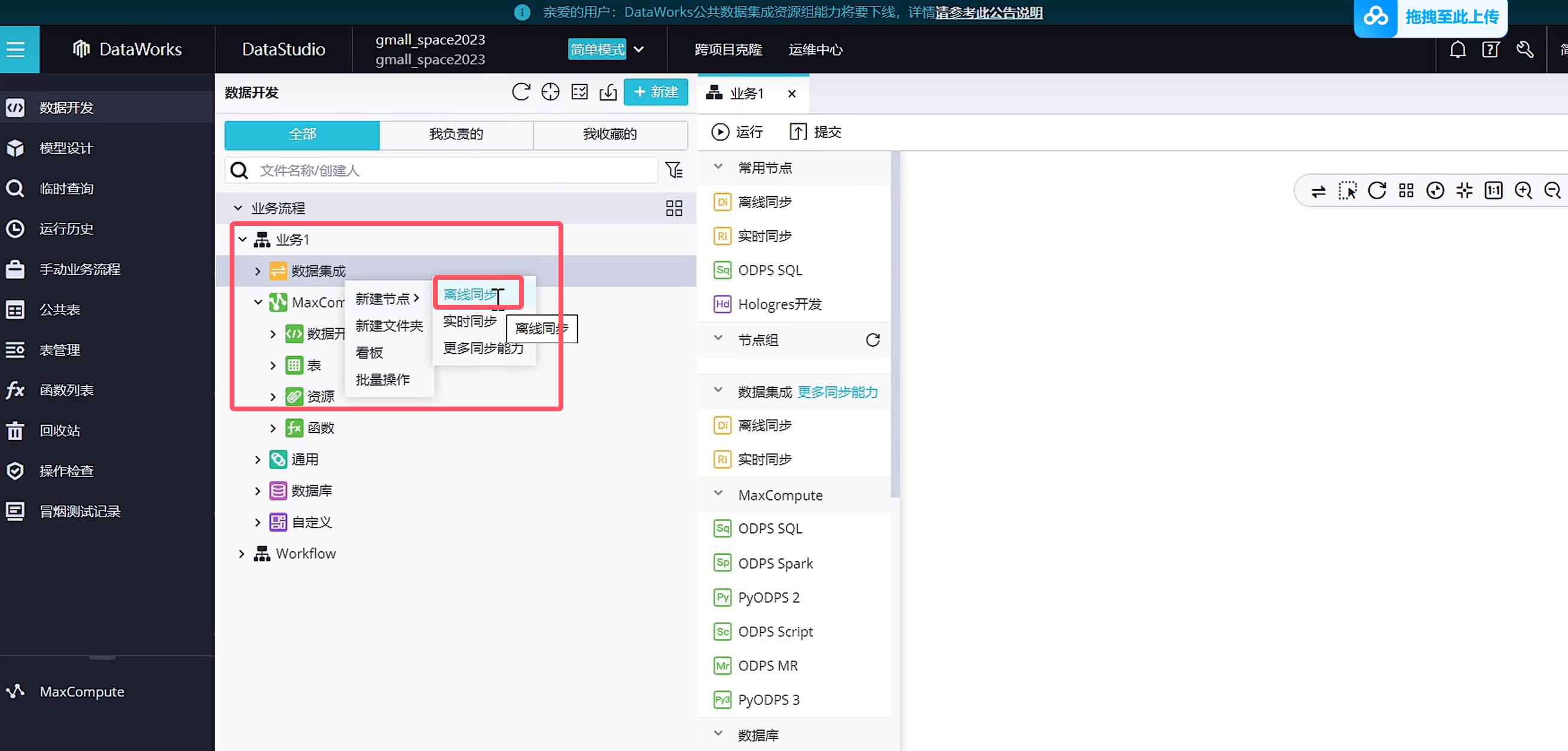
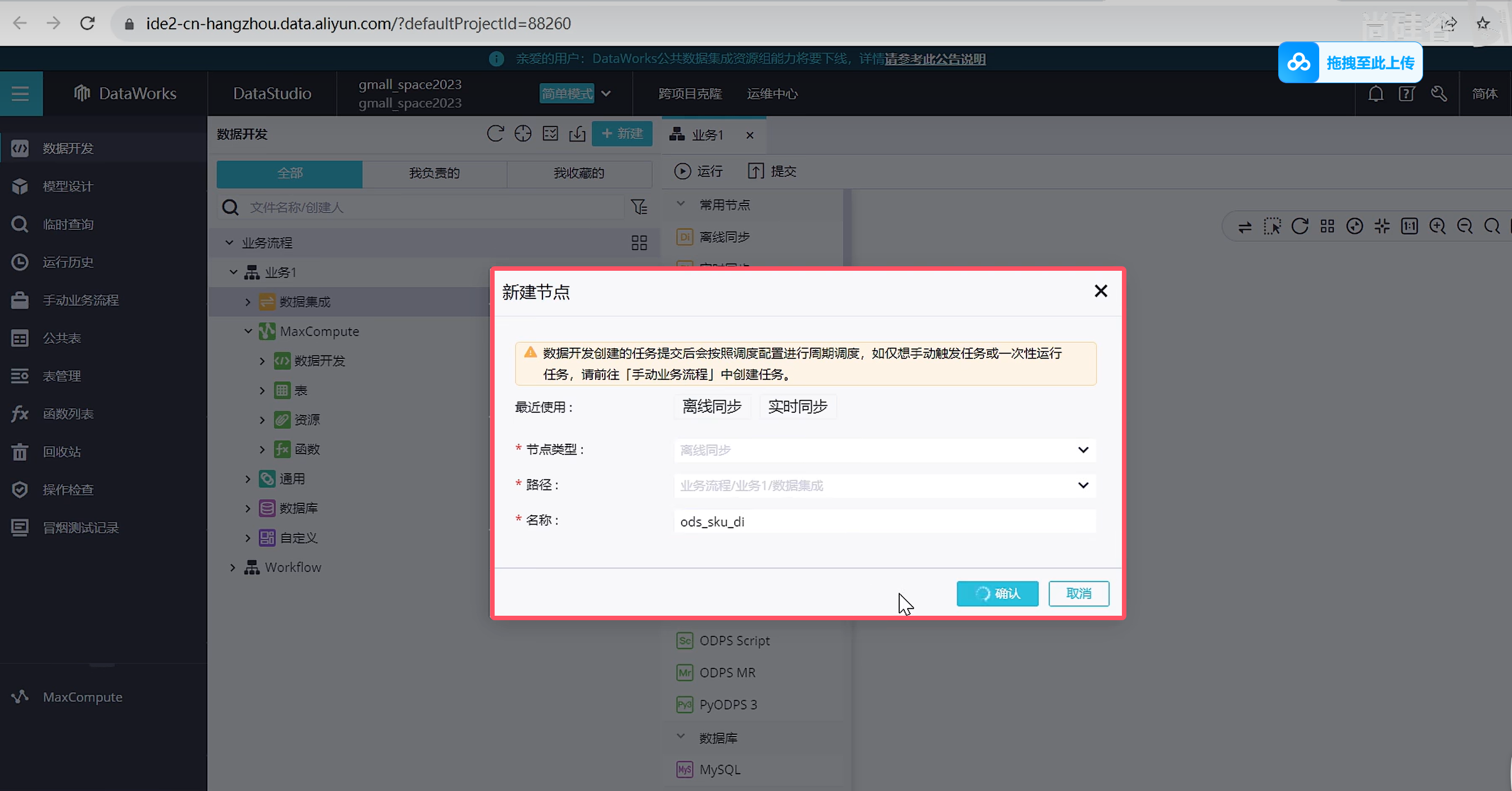
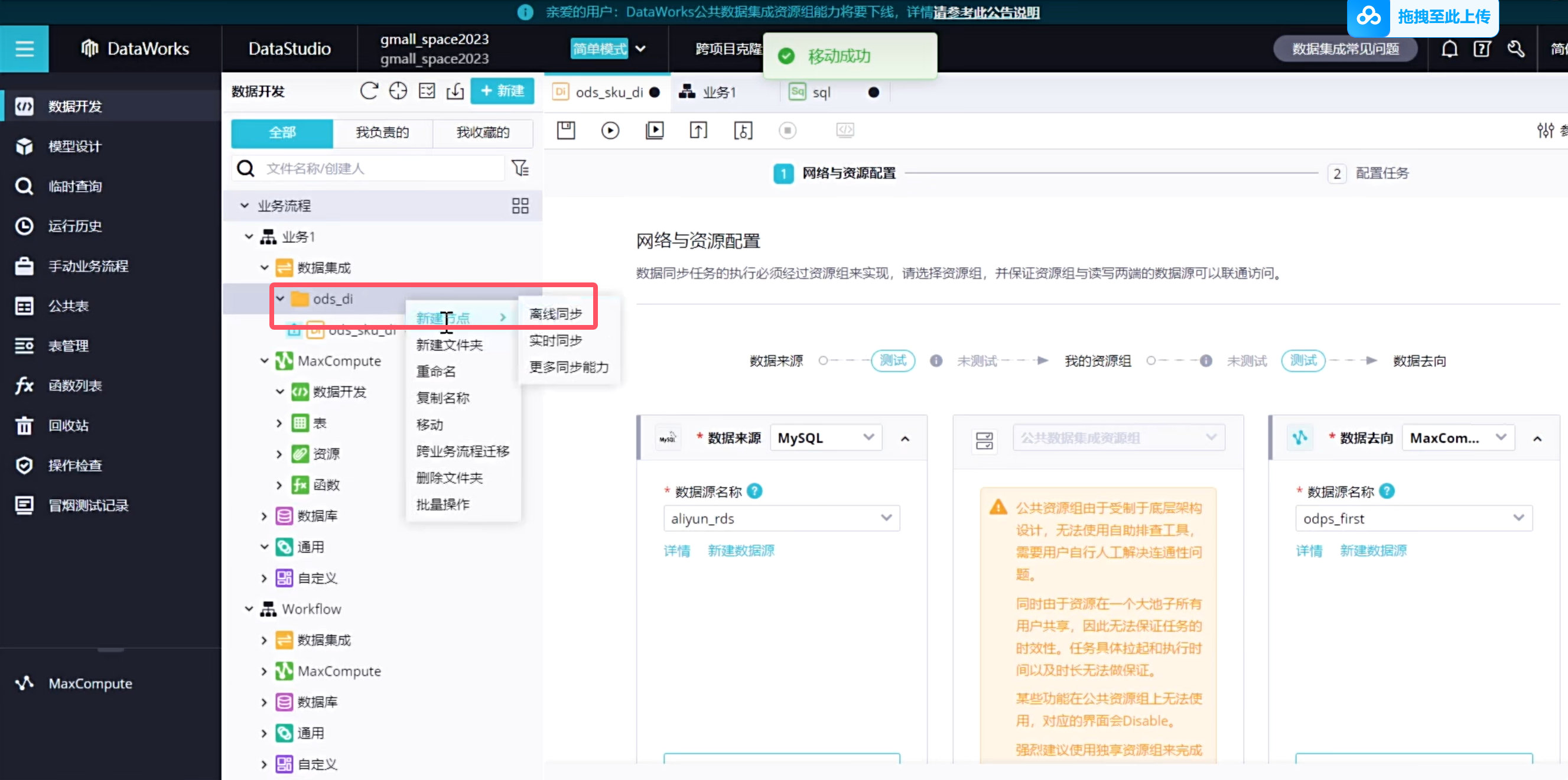
创建新的离线同步节点
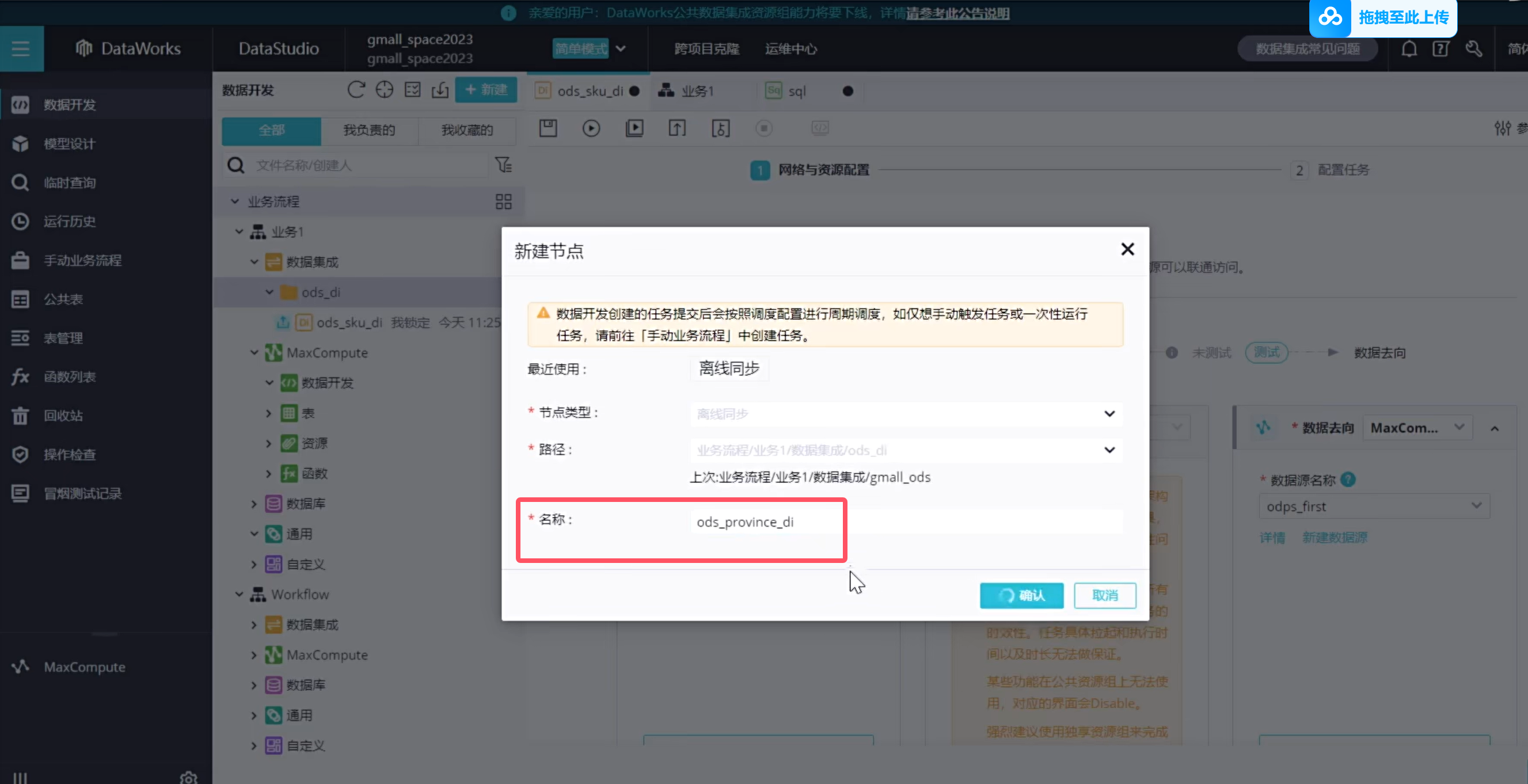
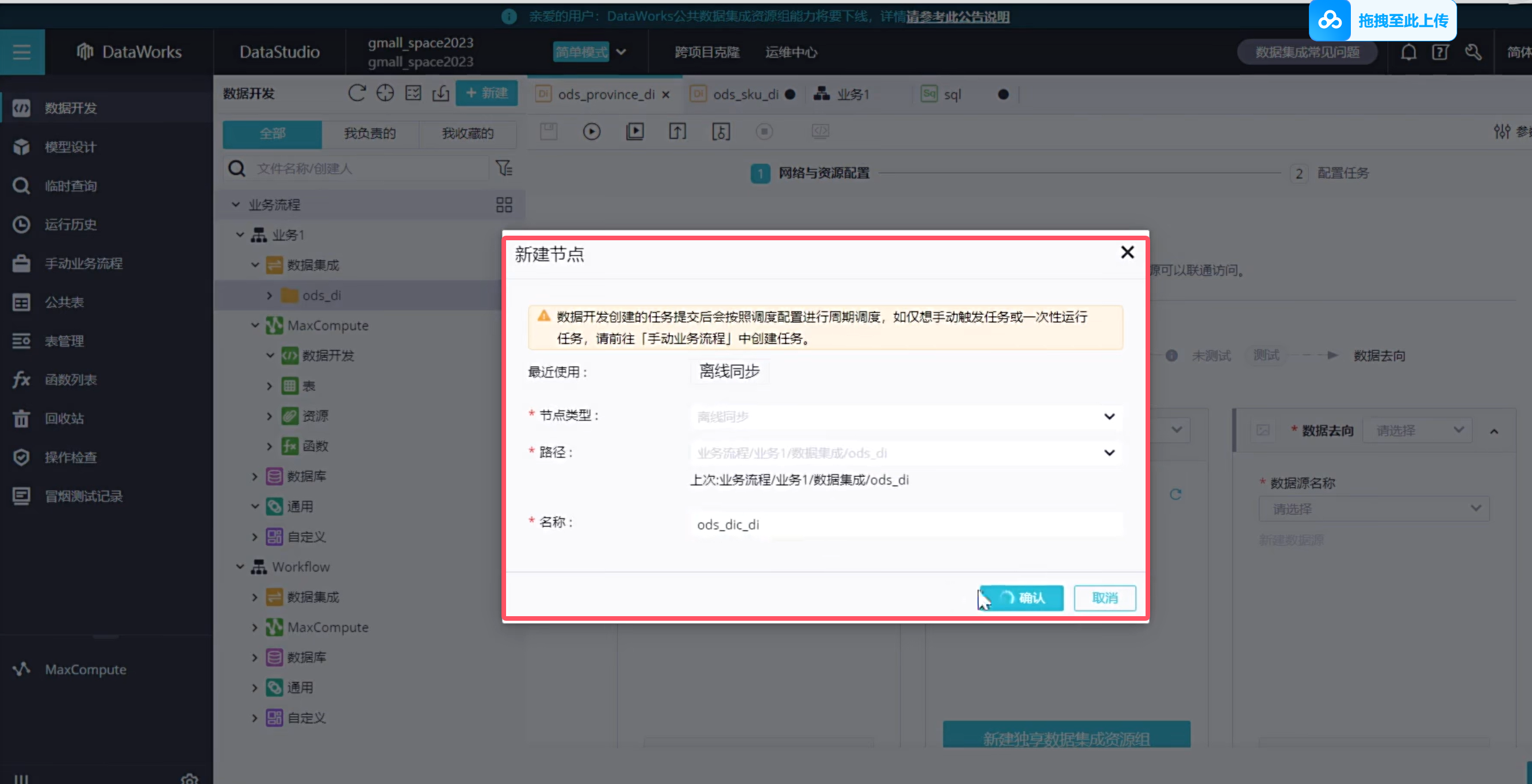
可以看到另外创建的两张离线表
跟第一张表配置方式一样
全部都跟第一张商品表一样的配置即可
等待数据导入完成即可
下面按照正常的规范应该是在临时查询中去查询数据
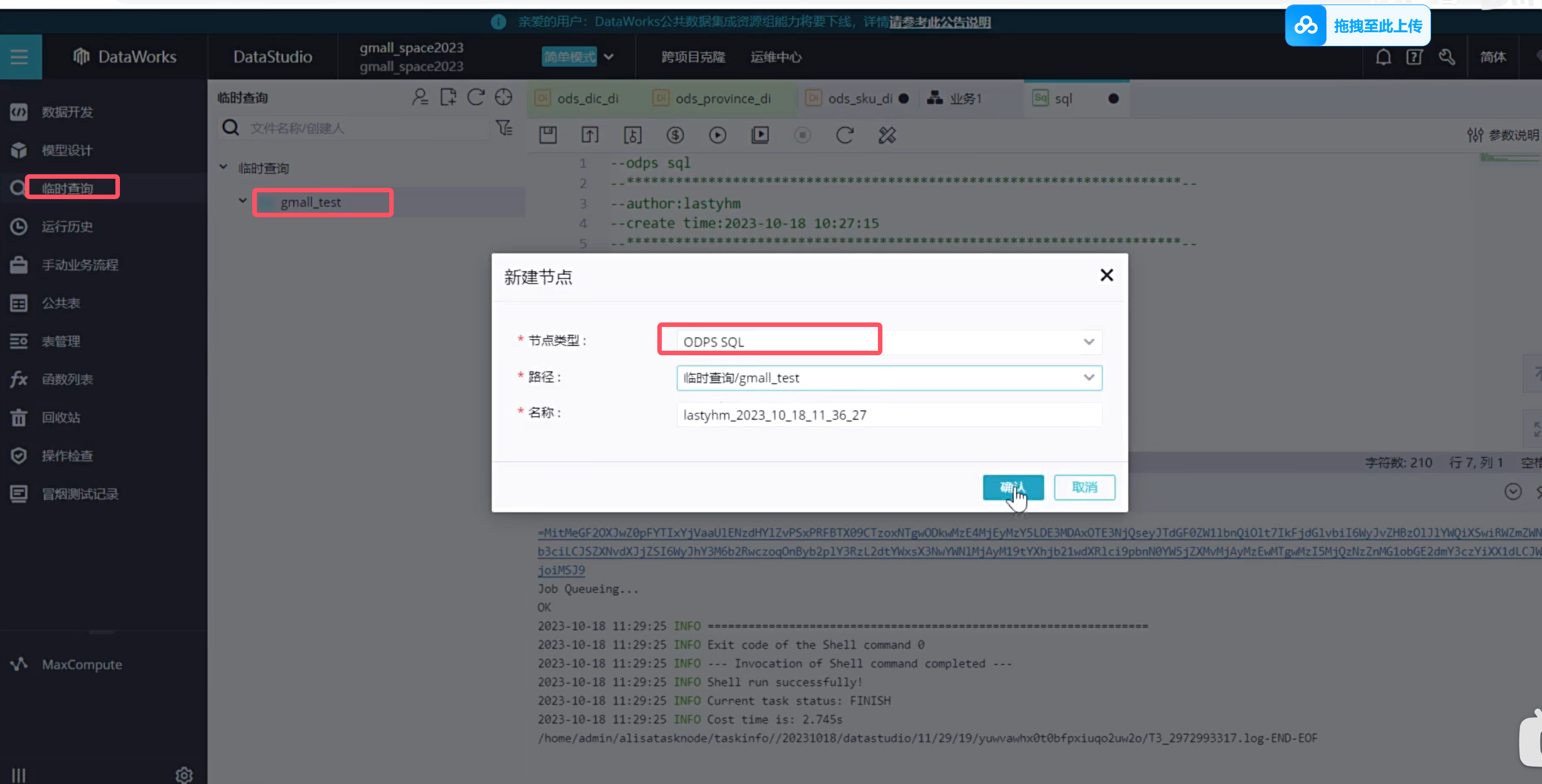
阿里云离线数据查询比较严格,必须带上分区字段,不然会报错
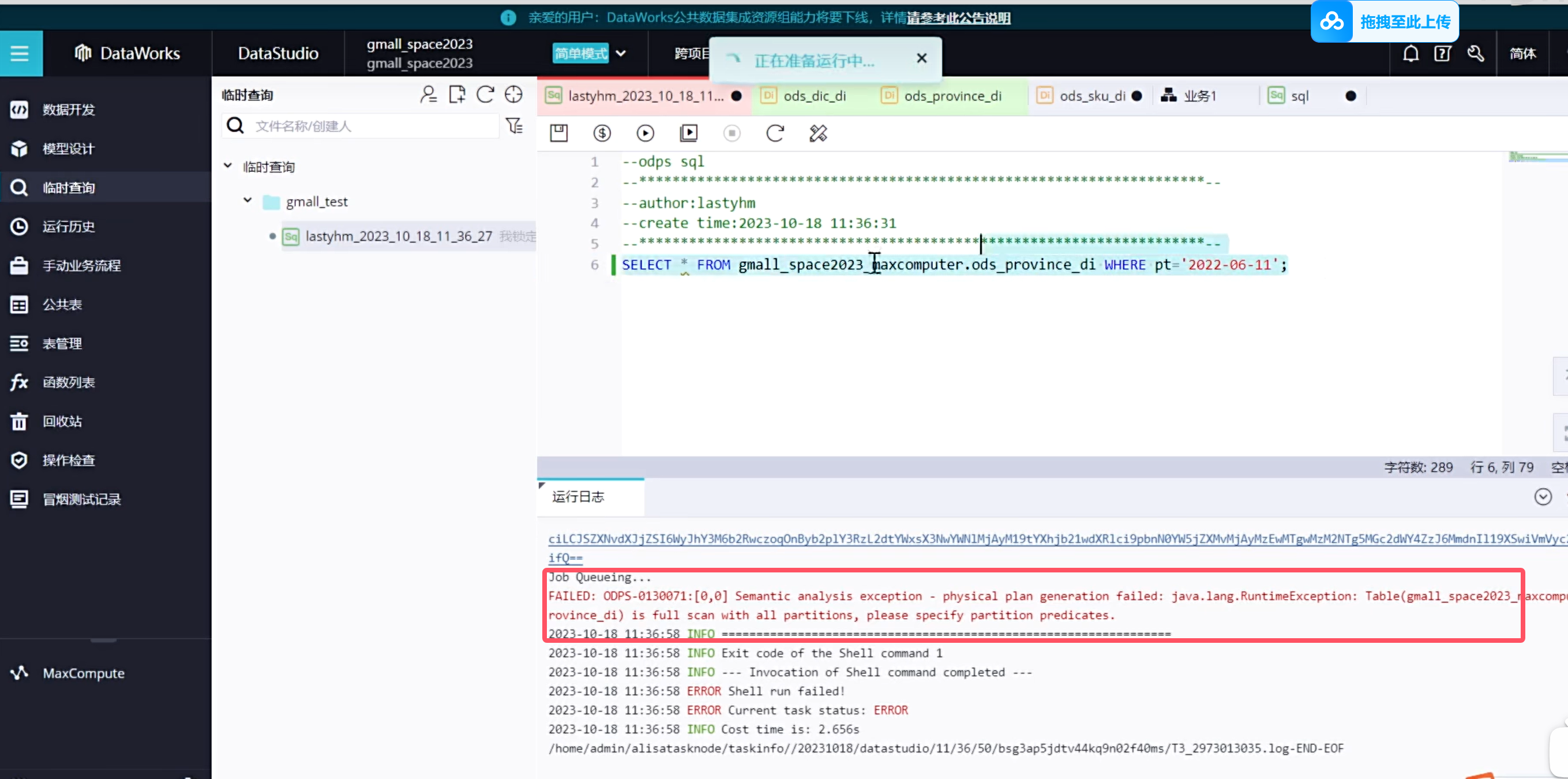
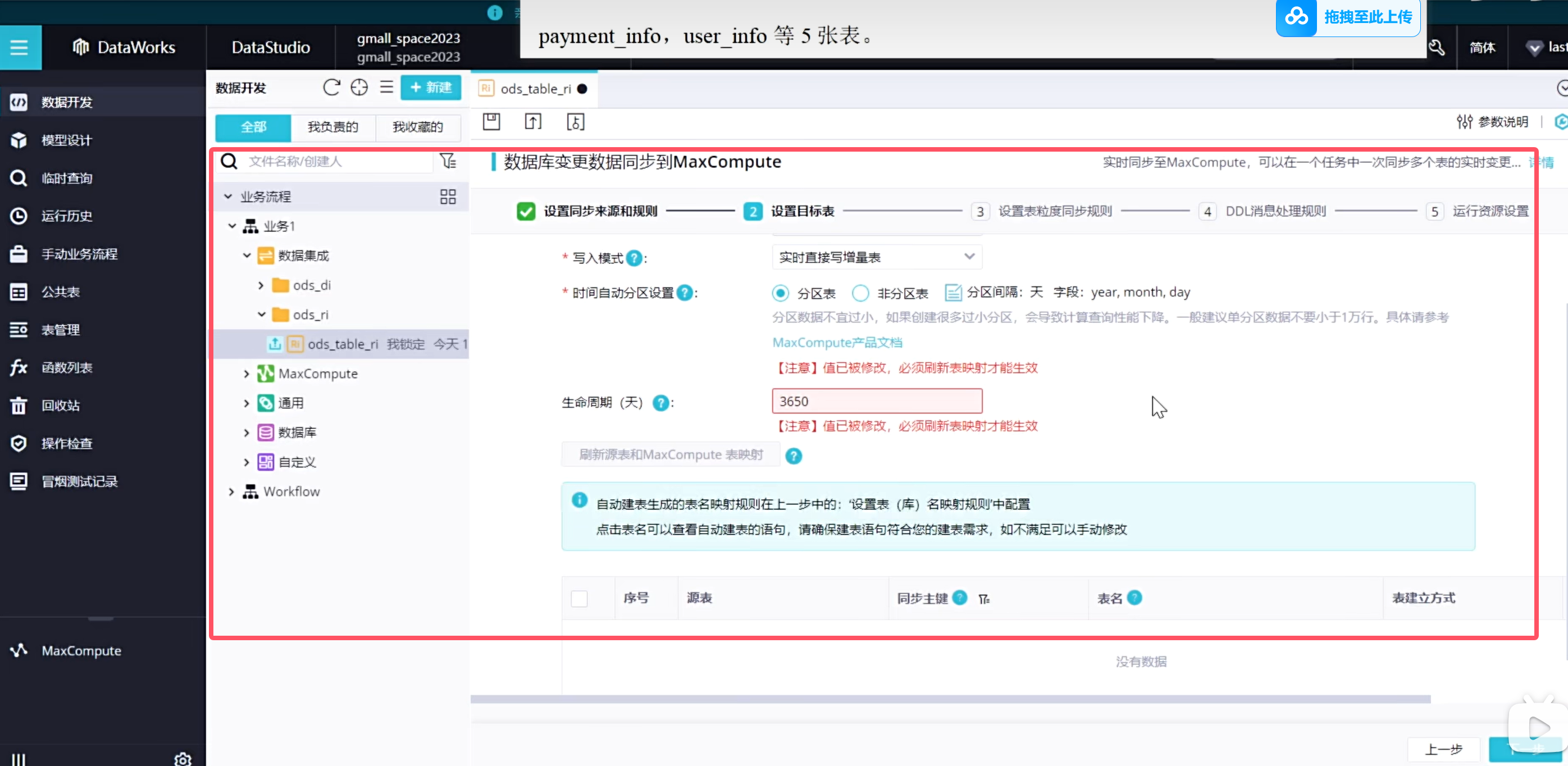
增量表的首次初始化同步
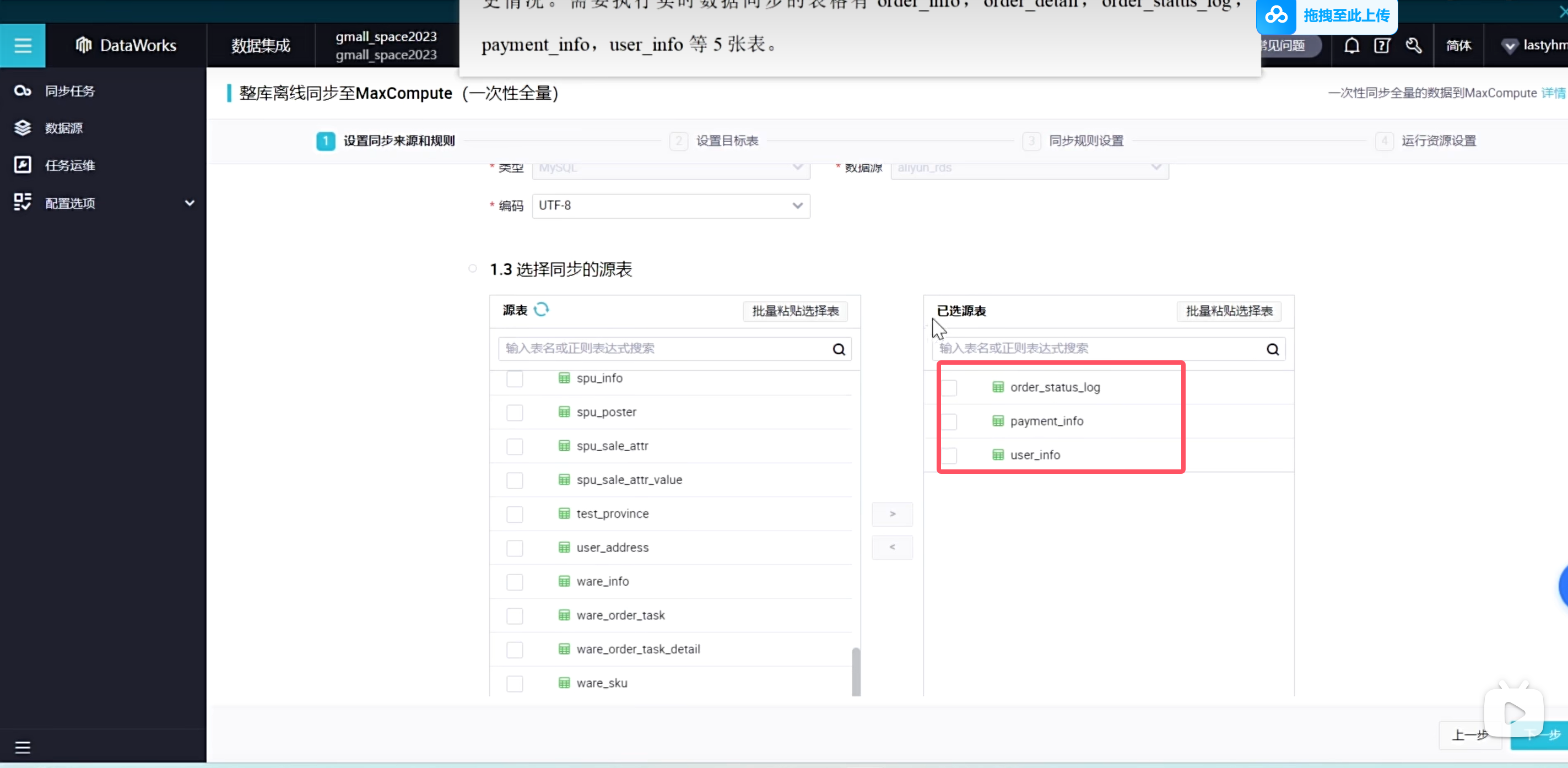
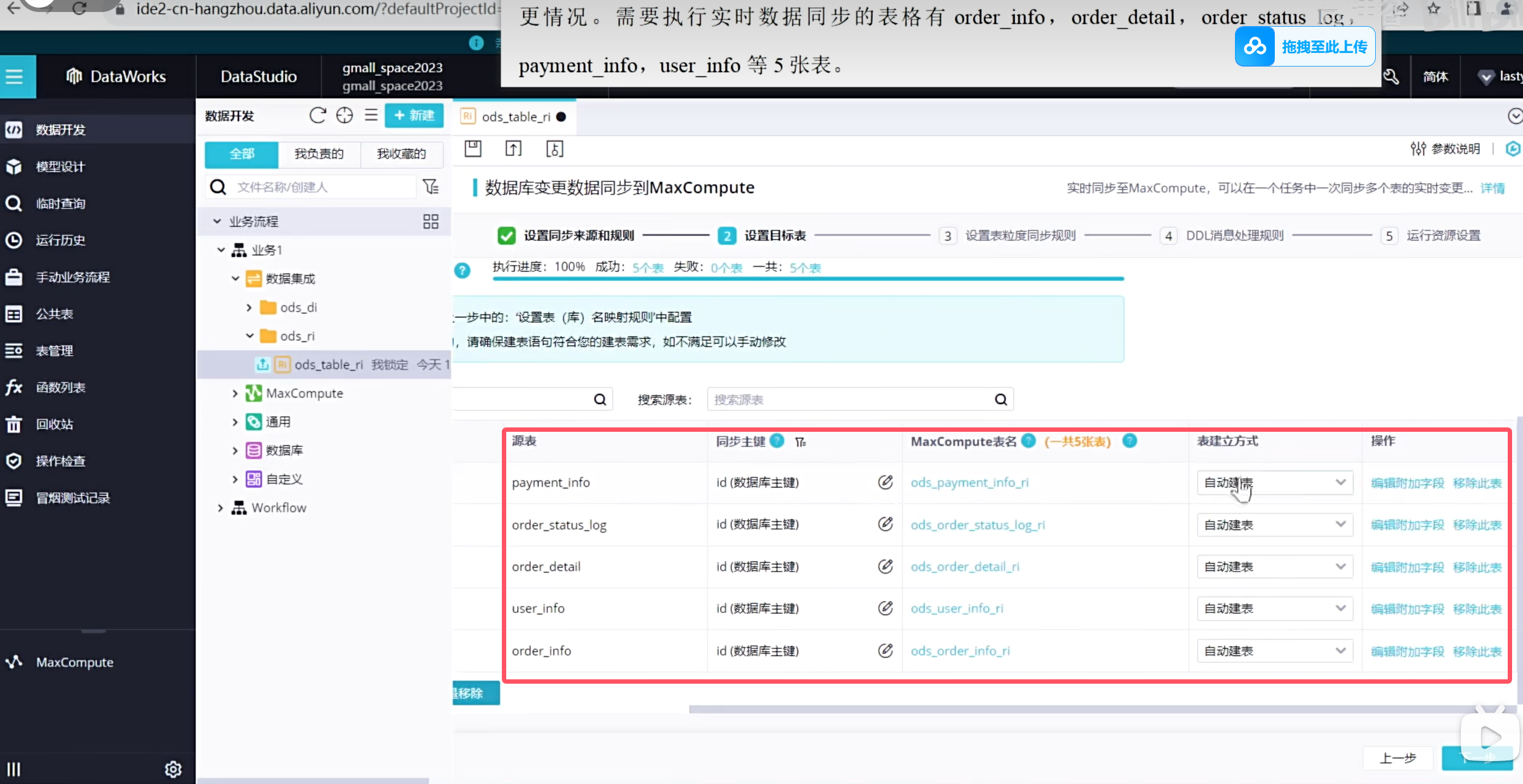
需要执行实时数据同步的表格为增量同步表格,需要保持同步任务,实时监控数据的变更情况。需要执行实时数据同步的表格有order_info,order_detail,order_status_log,payment_info,user_info等5张表。
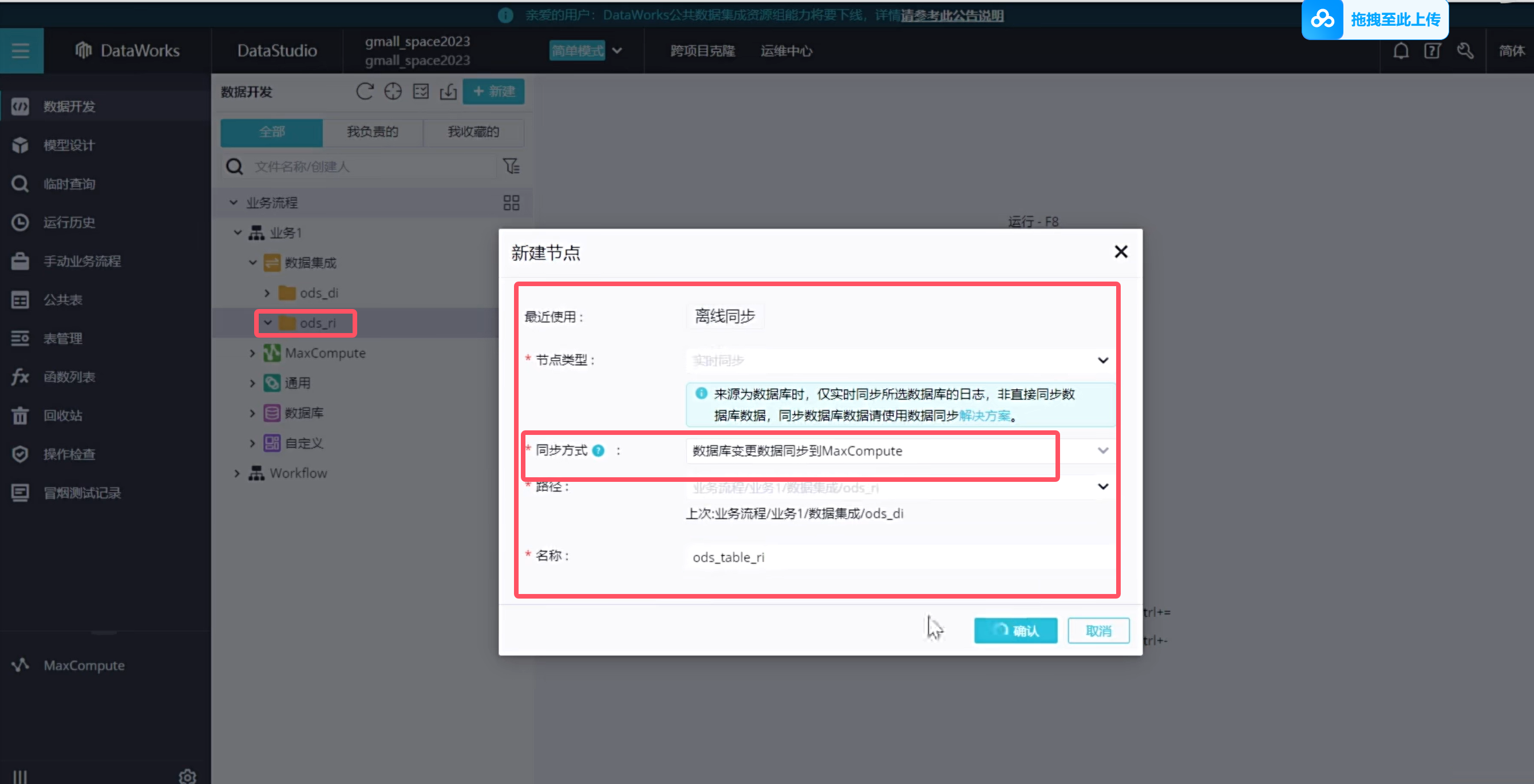
实时同步的增量表需要进行首日初始化同步,这种同步是一次性的,需要在手动业务流程中创建:(只展示order_info表格)
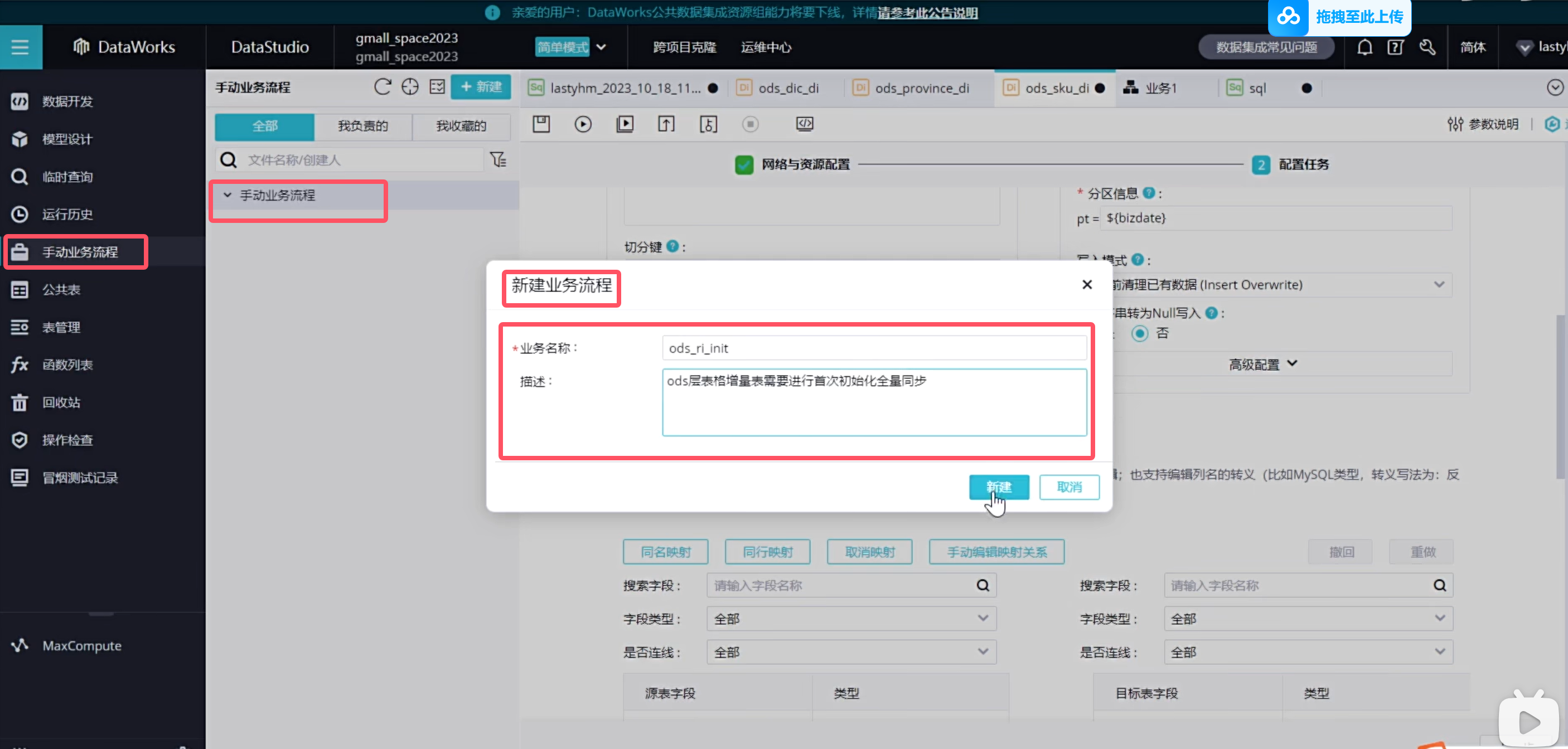
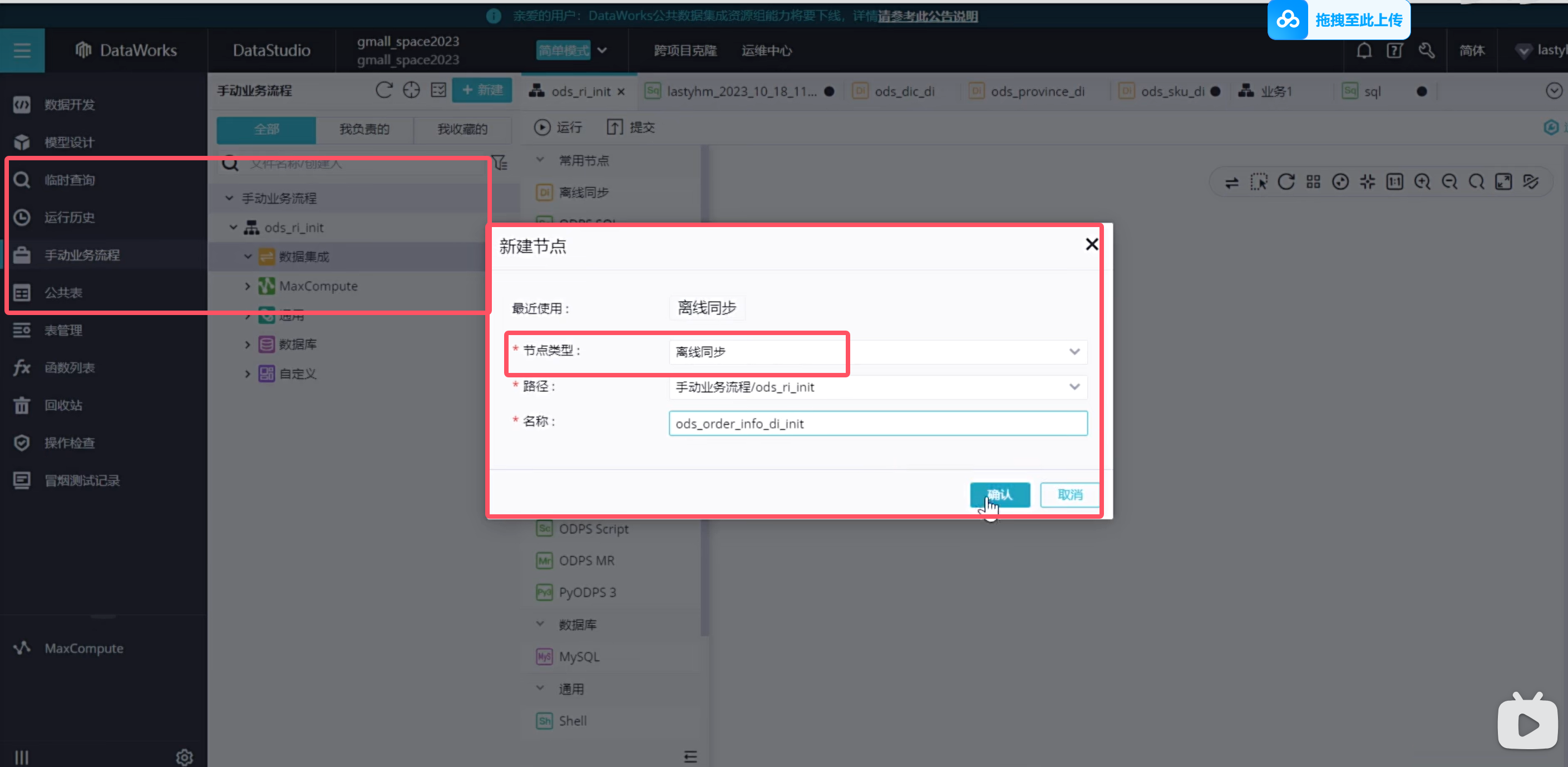
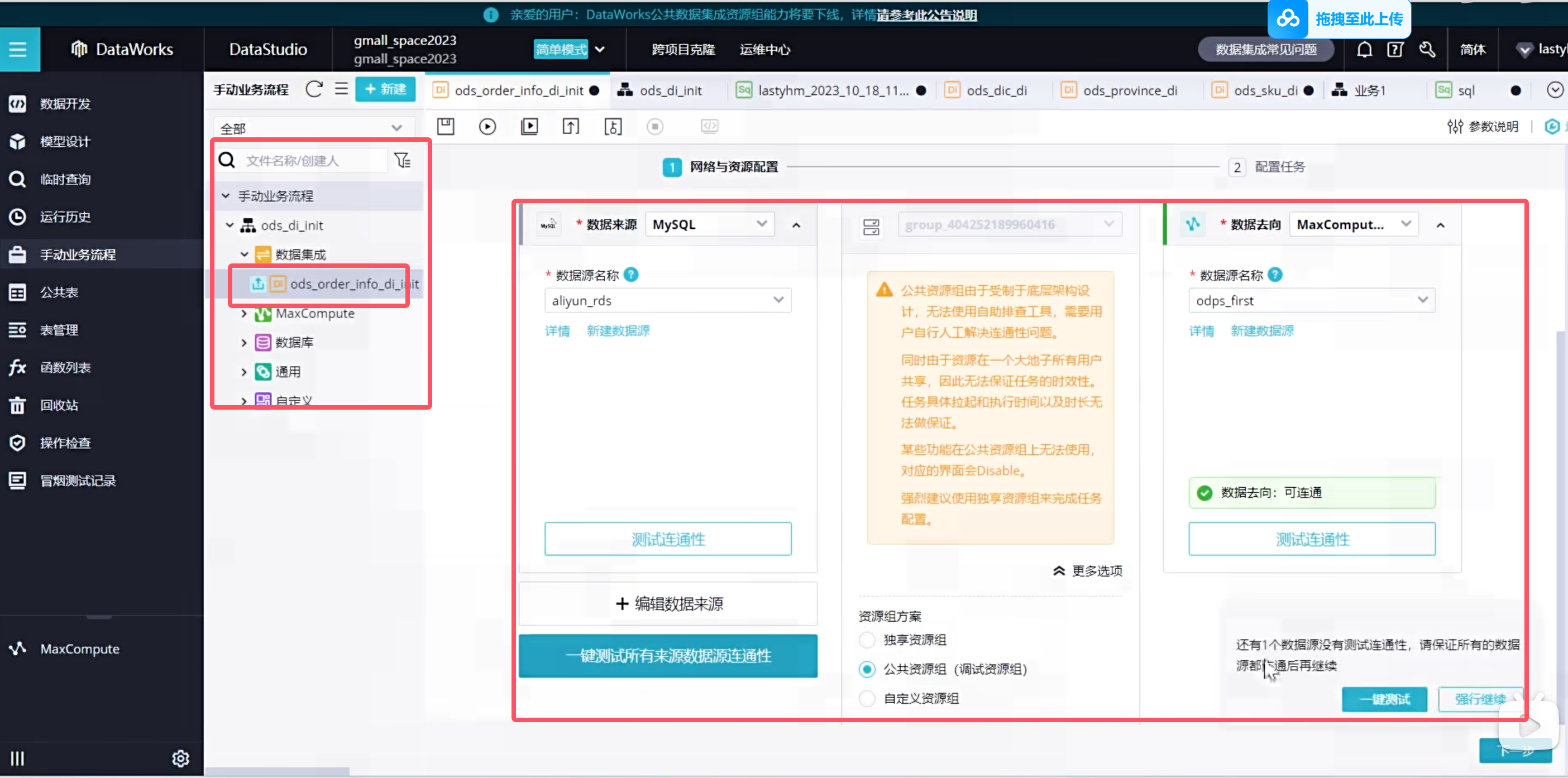
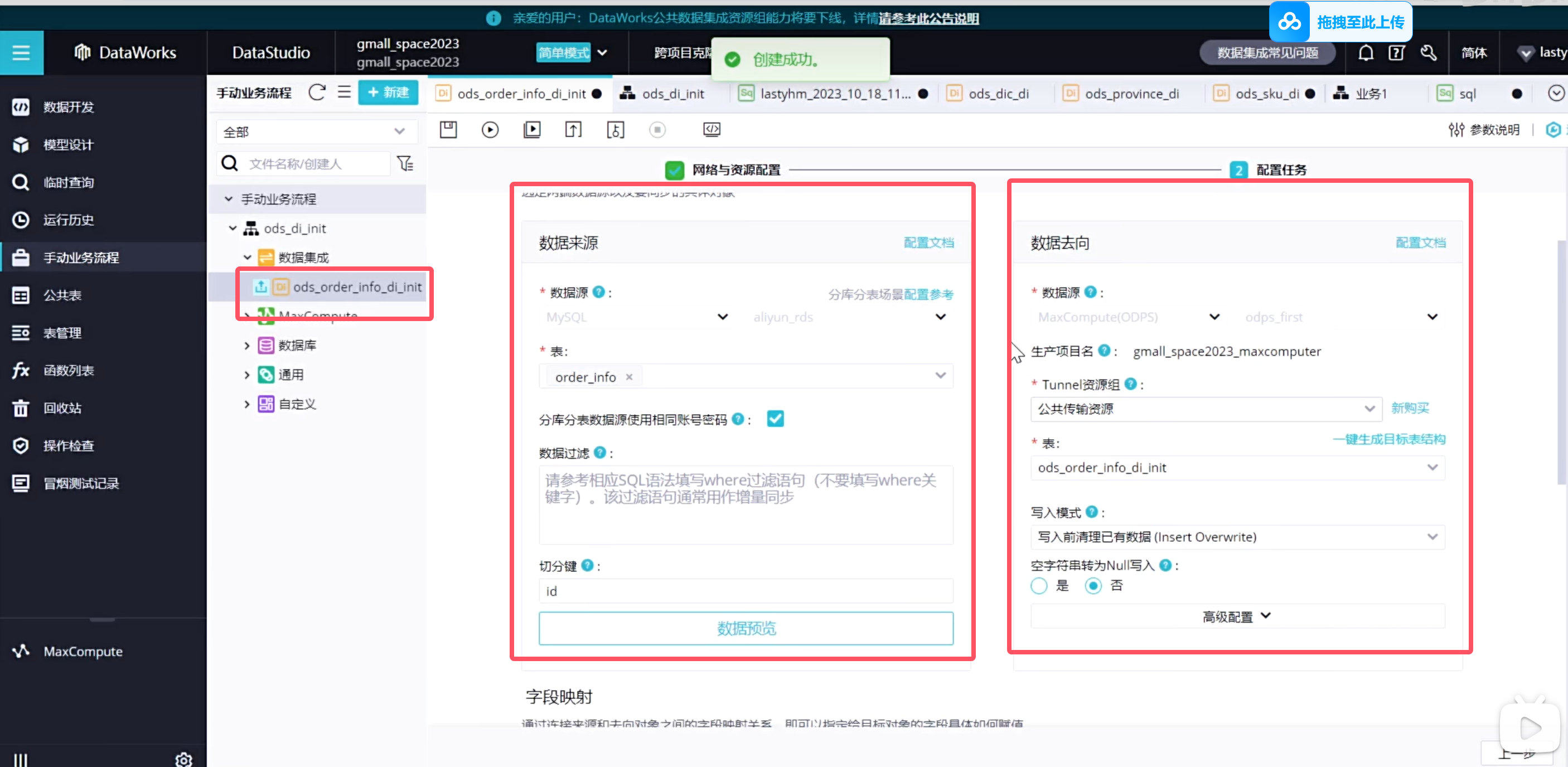
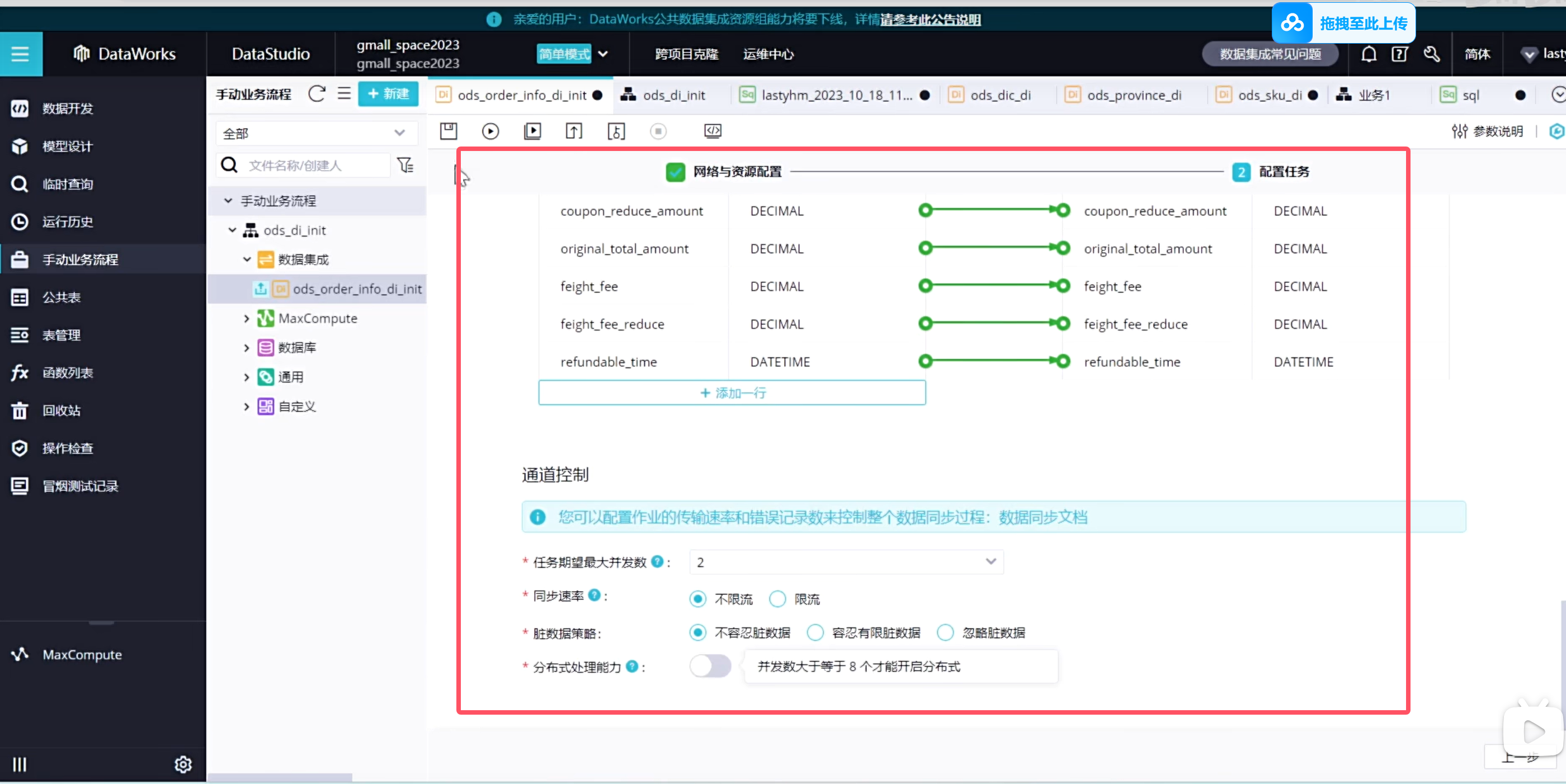
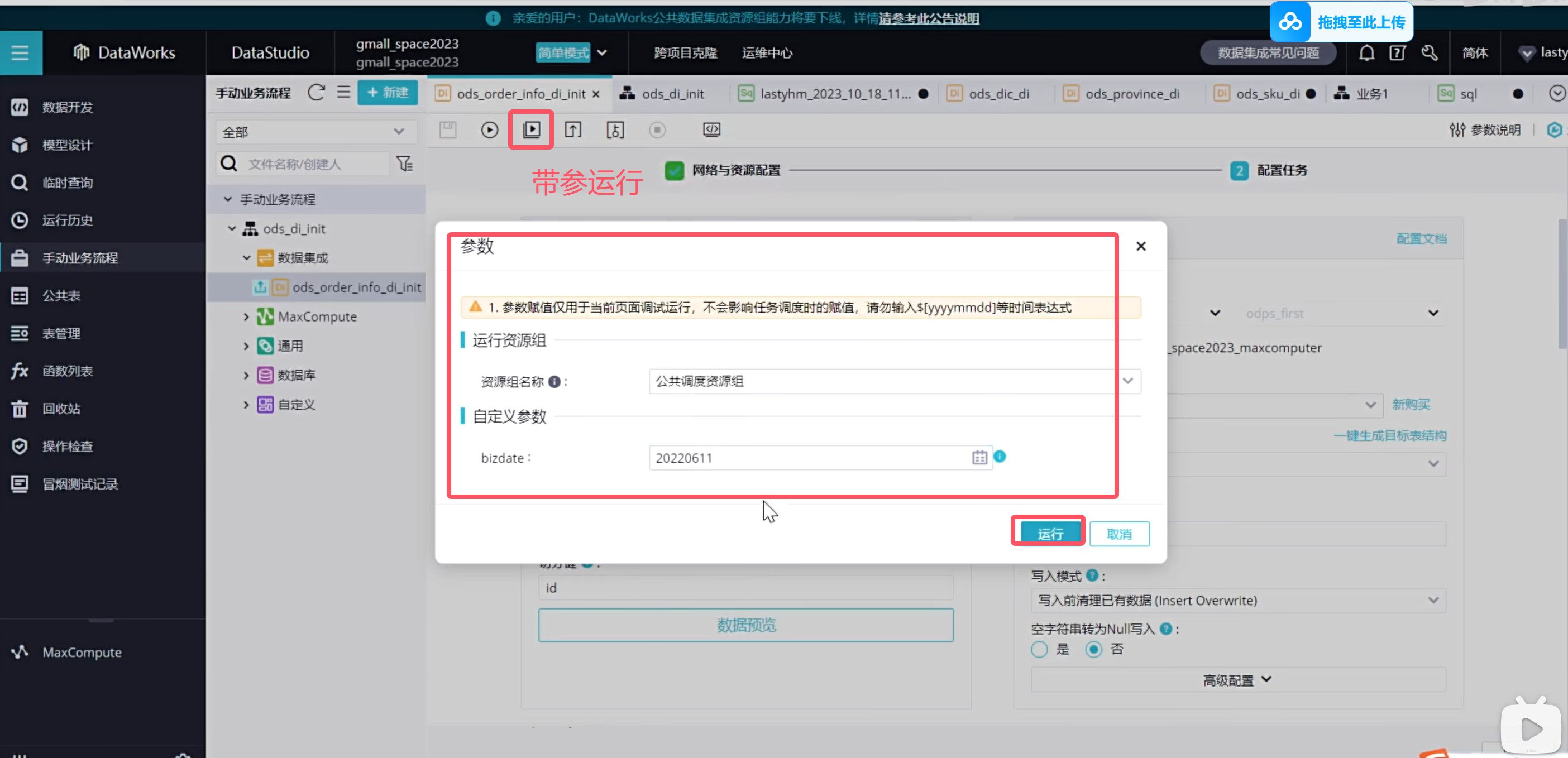
说明手动业务流程是没有调度配置的
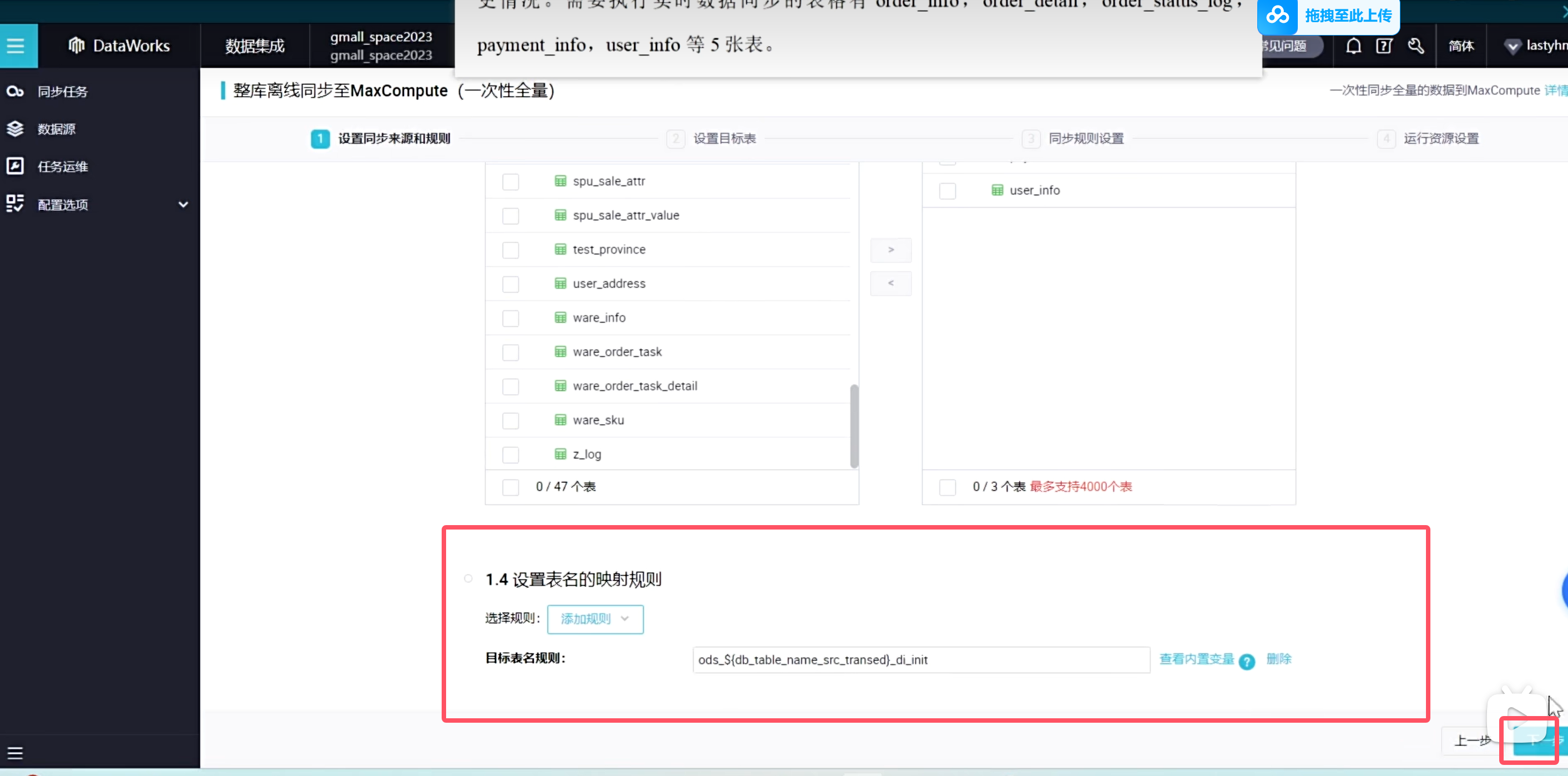
以上所述表的所有流程基本都是那样操作,但是这里有个问题就是,如果我表的数量特别多的话,难道要把每张表都挨个设置一下吗?那样的时间成本就太高了,其实DataWorks给用户提供了批量处理的功能
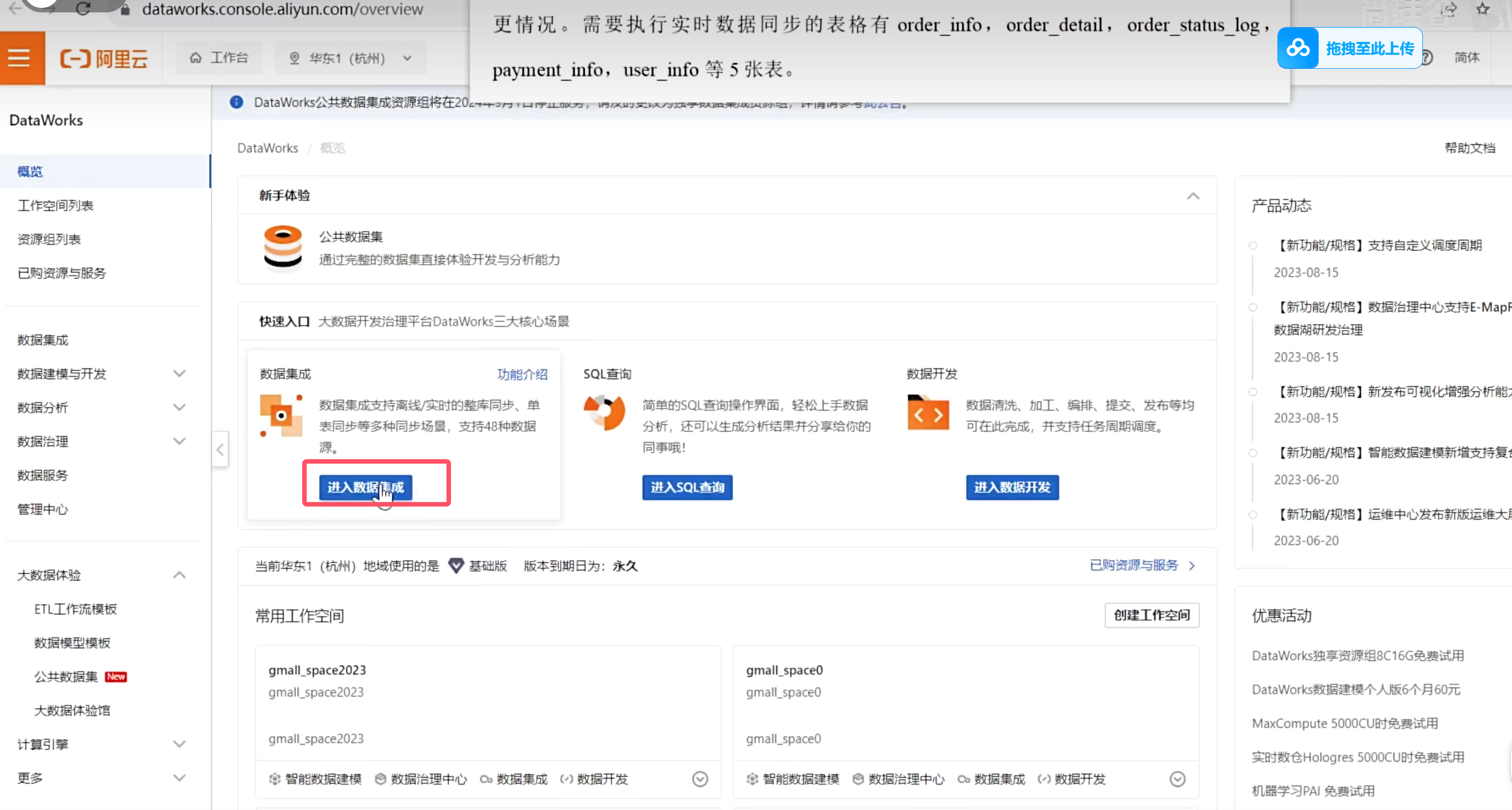
可以看到这里变成了数据集成
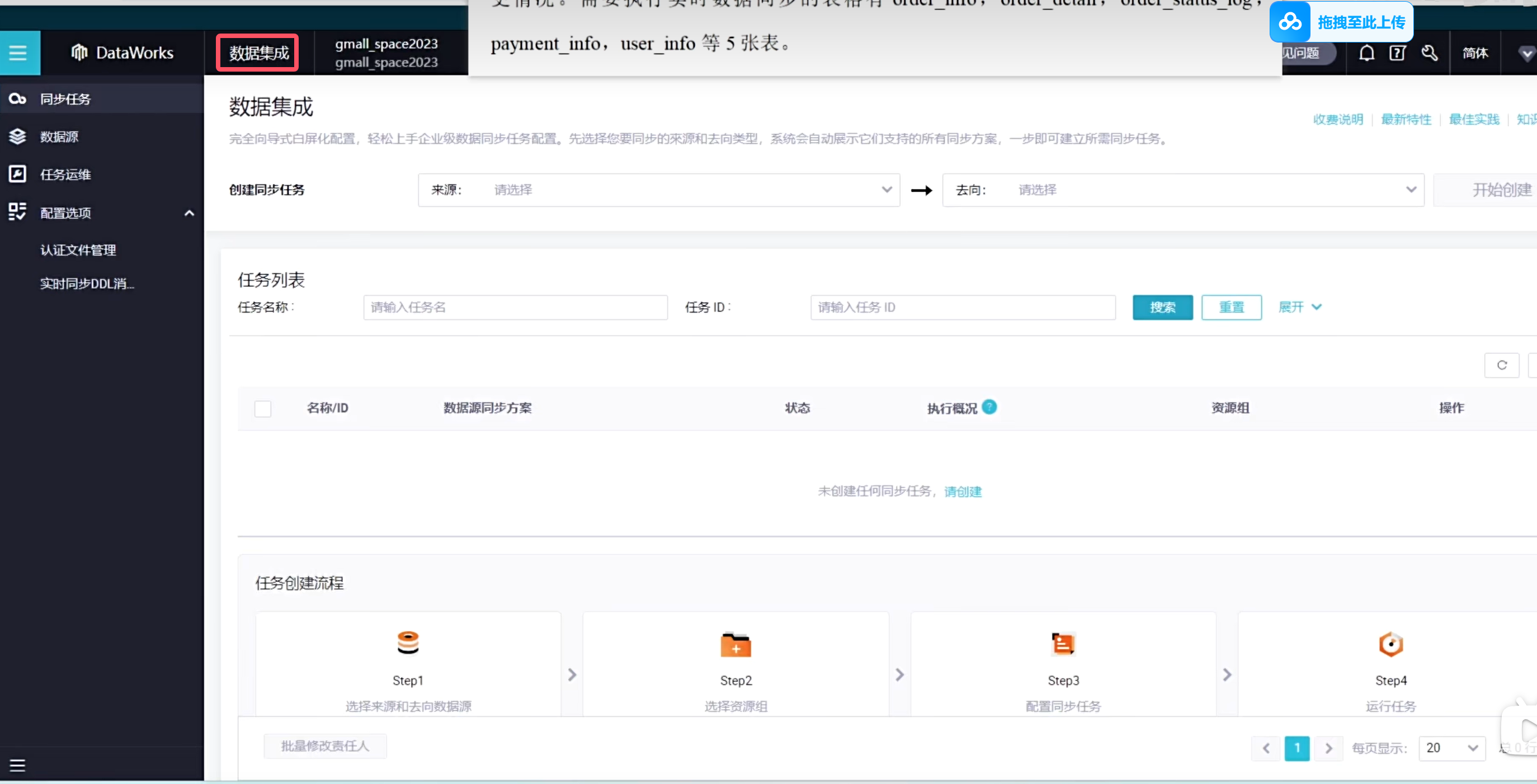
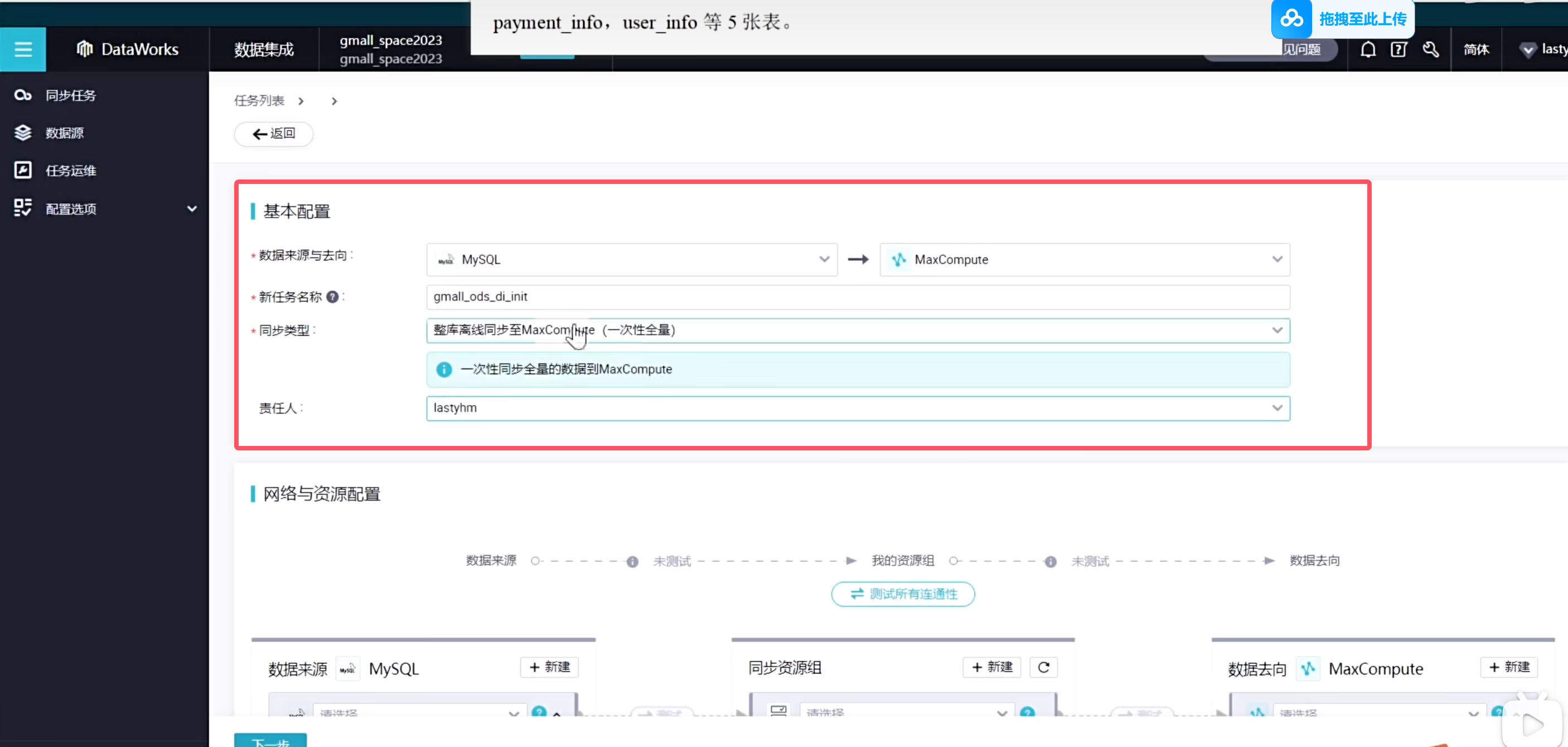
但是当你选择了这种方式同步离线表数据之后,那摩你就相当于一个正式的任务了,不会再让你使用公共资源组了,这是需要额外收费的
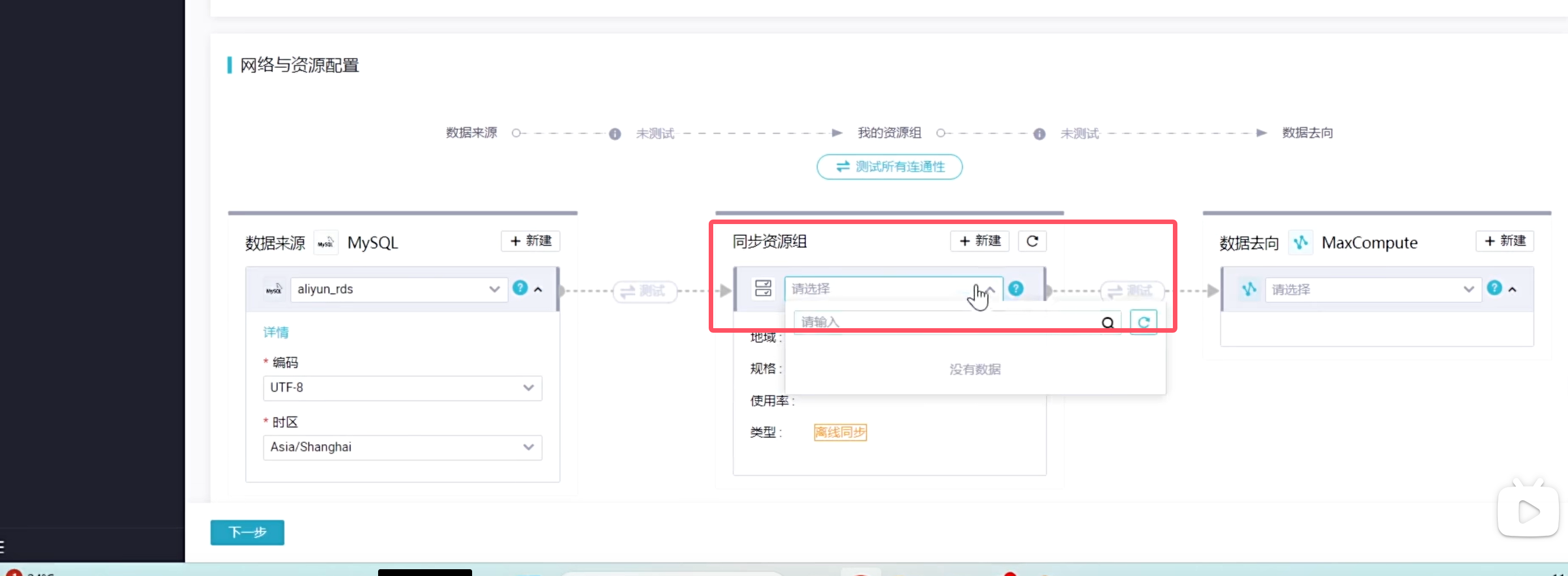
如果你实在不想要一个个的去操作,那你直接购买资源组就行了
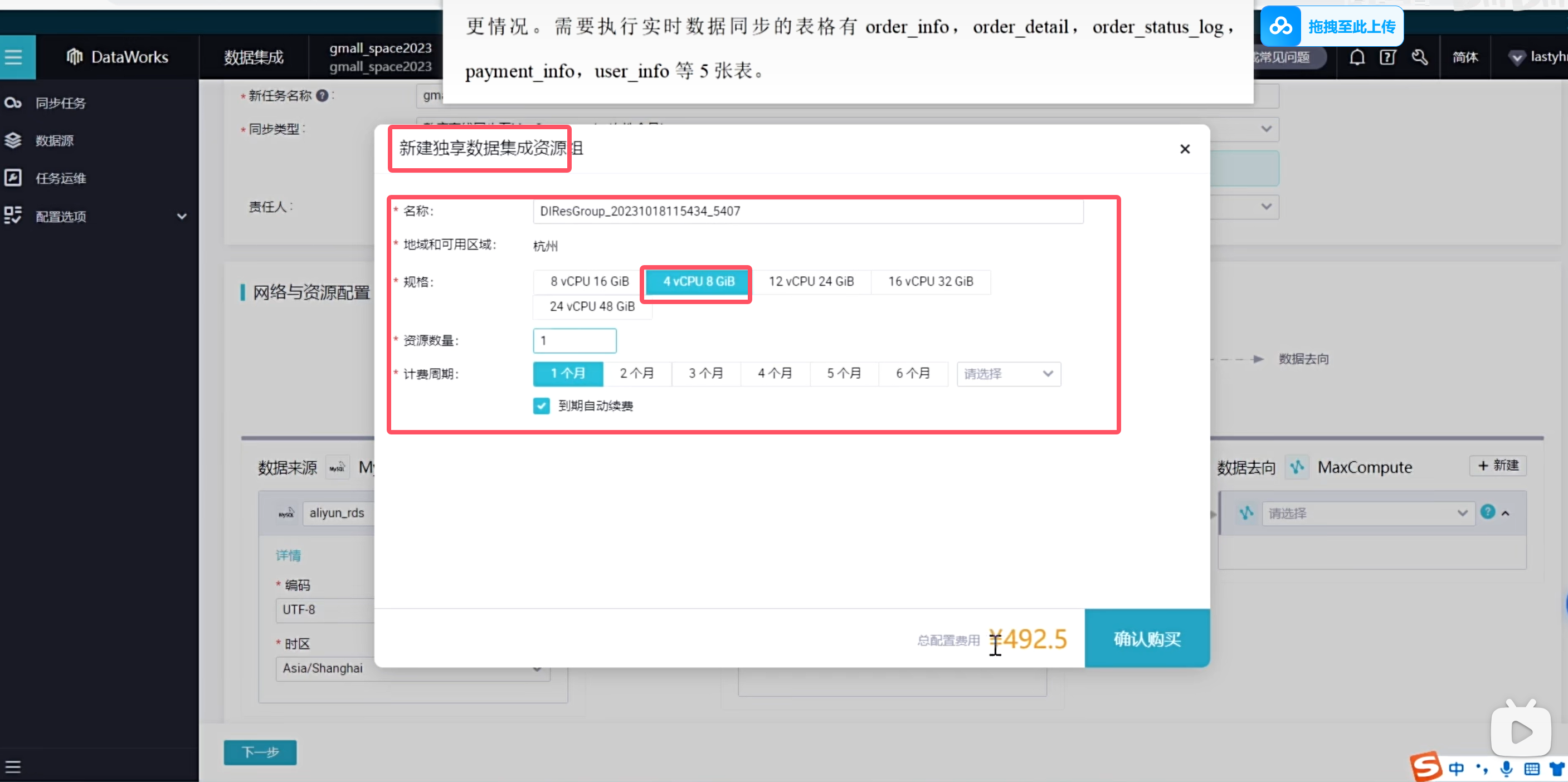
买完之后需要绑定当前的命名空间
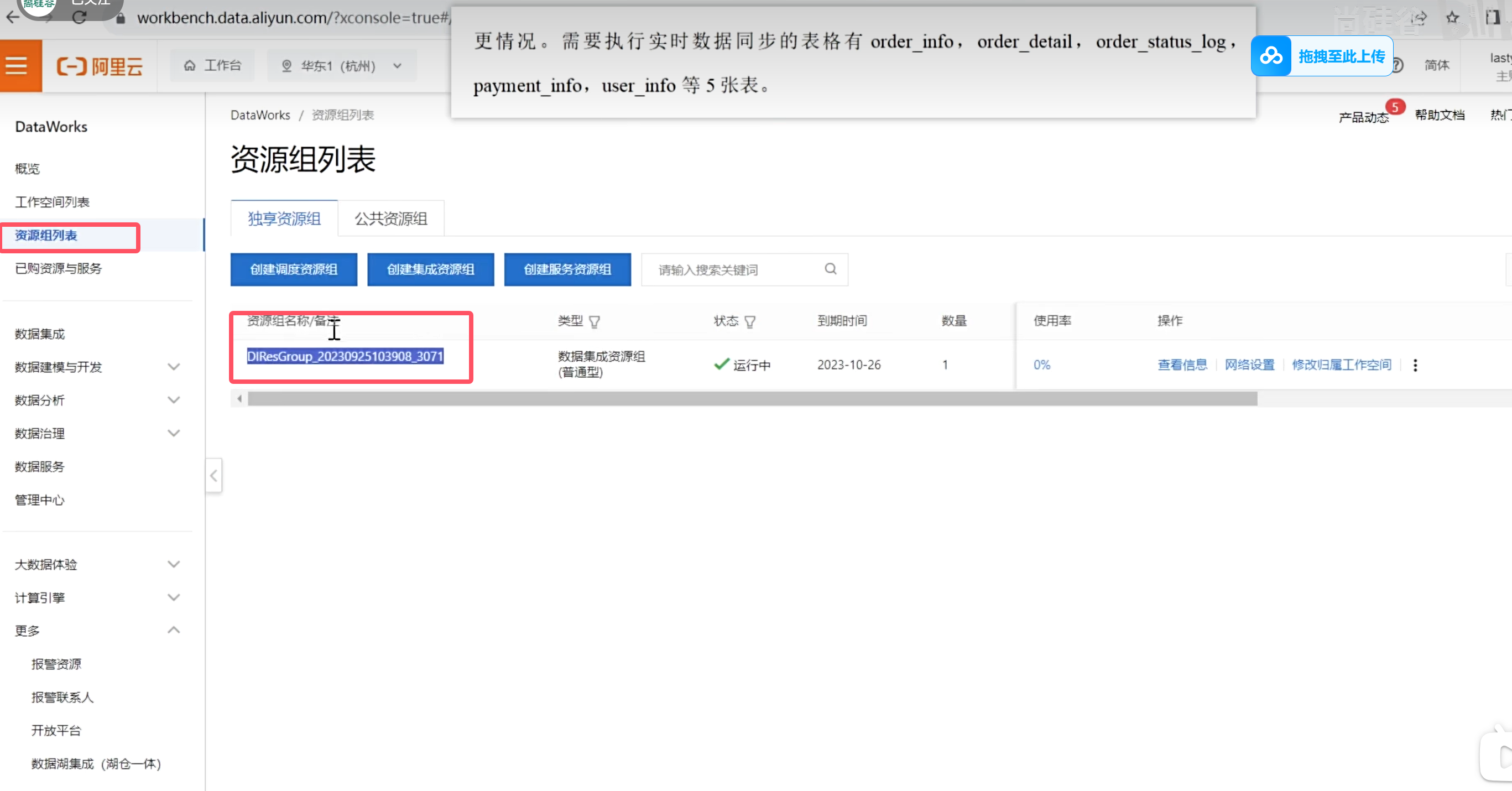
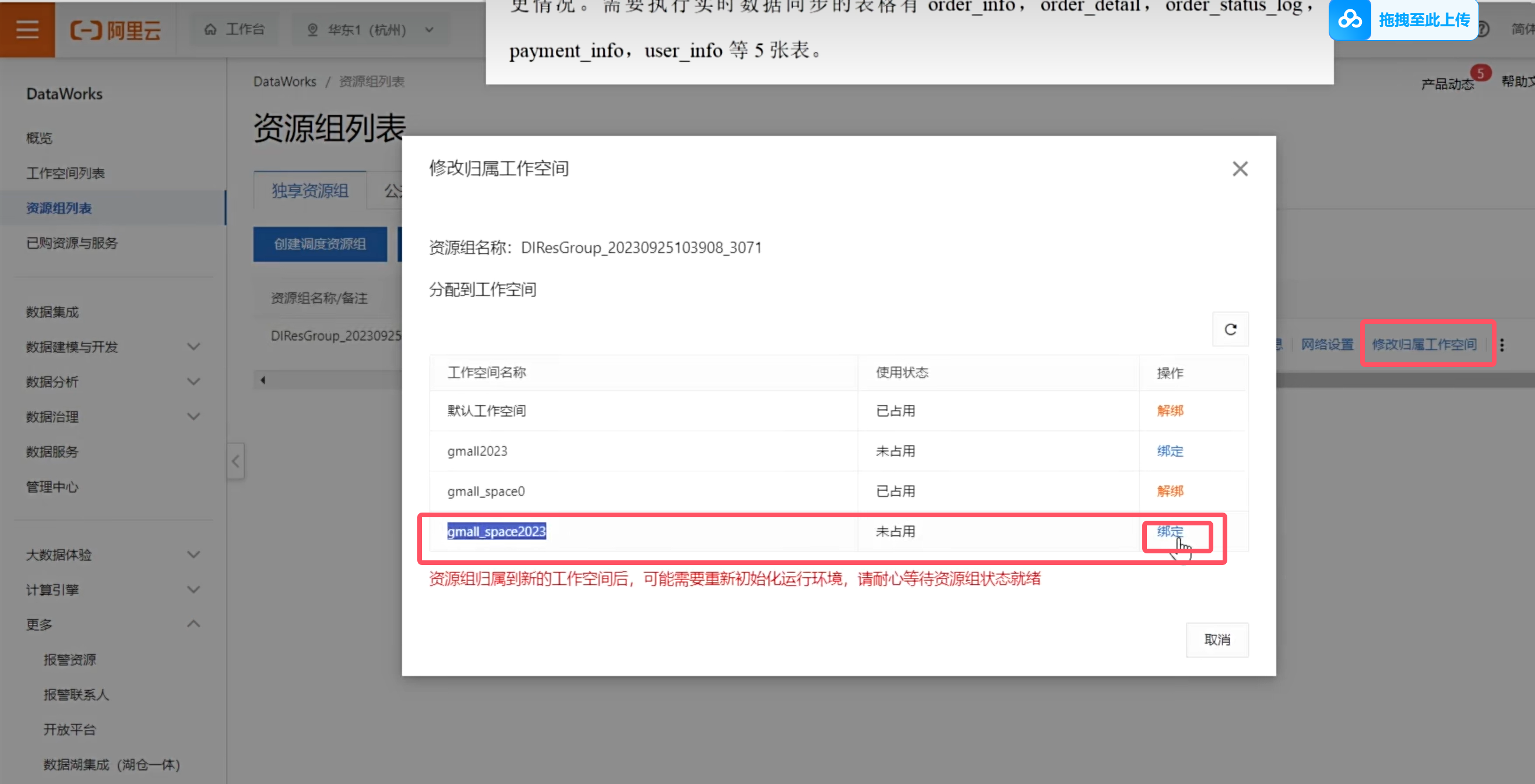
再回到DataWork数据集成页面就有数据了
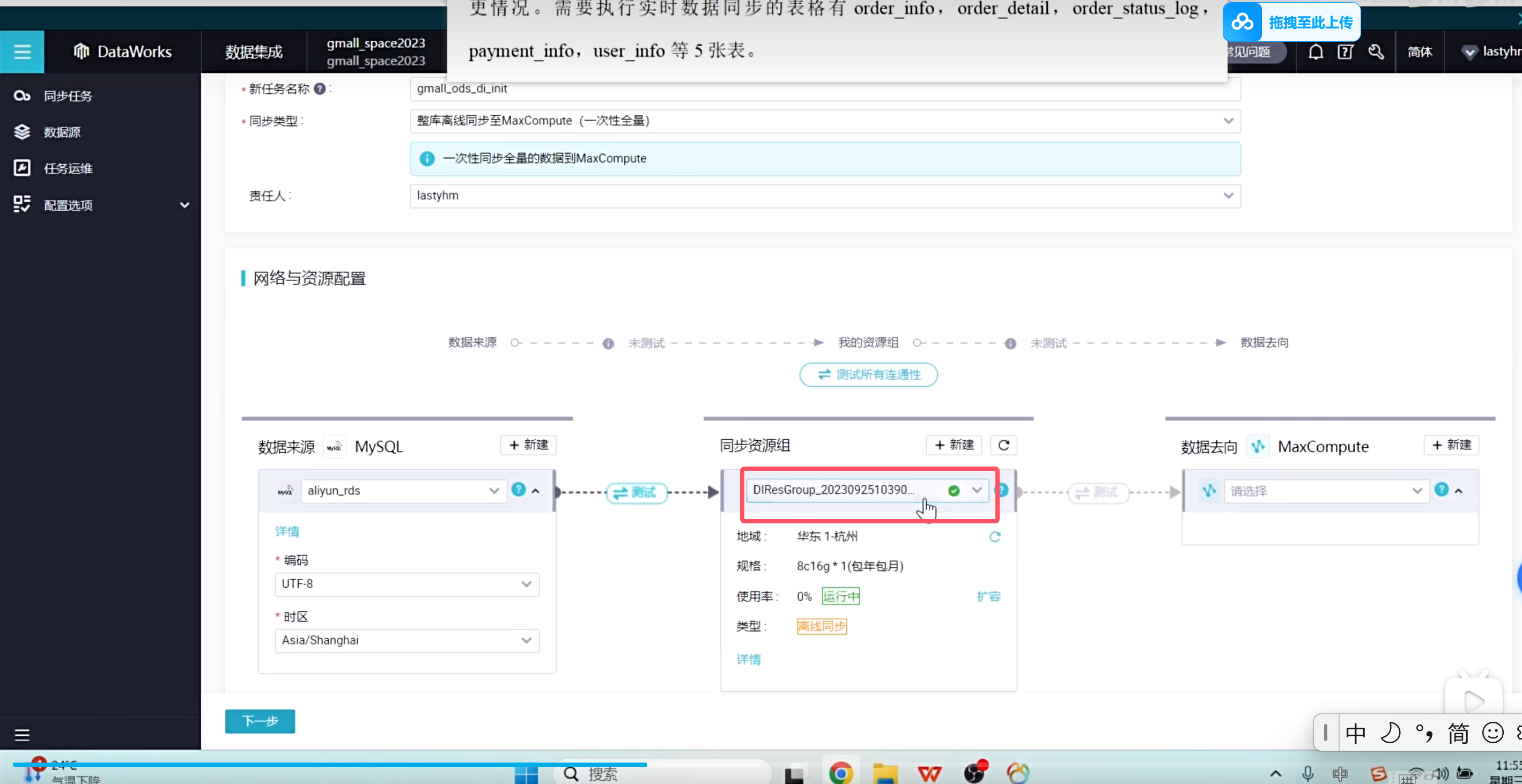
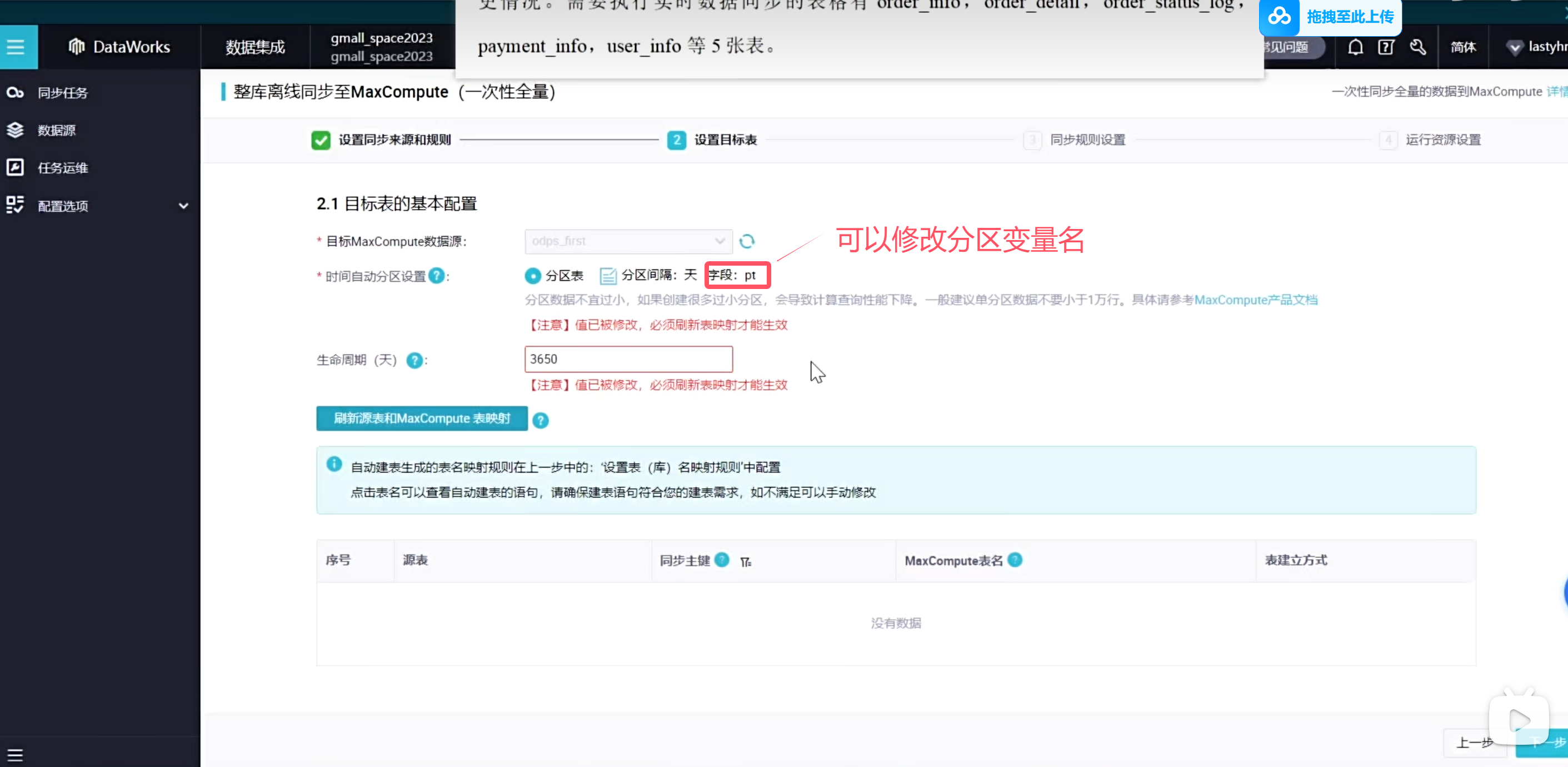
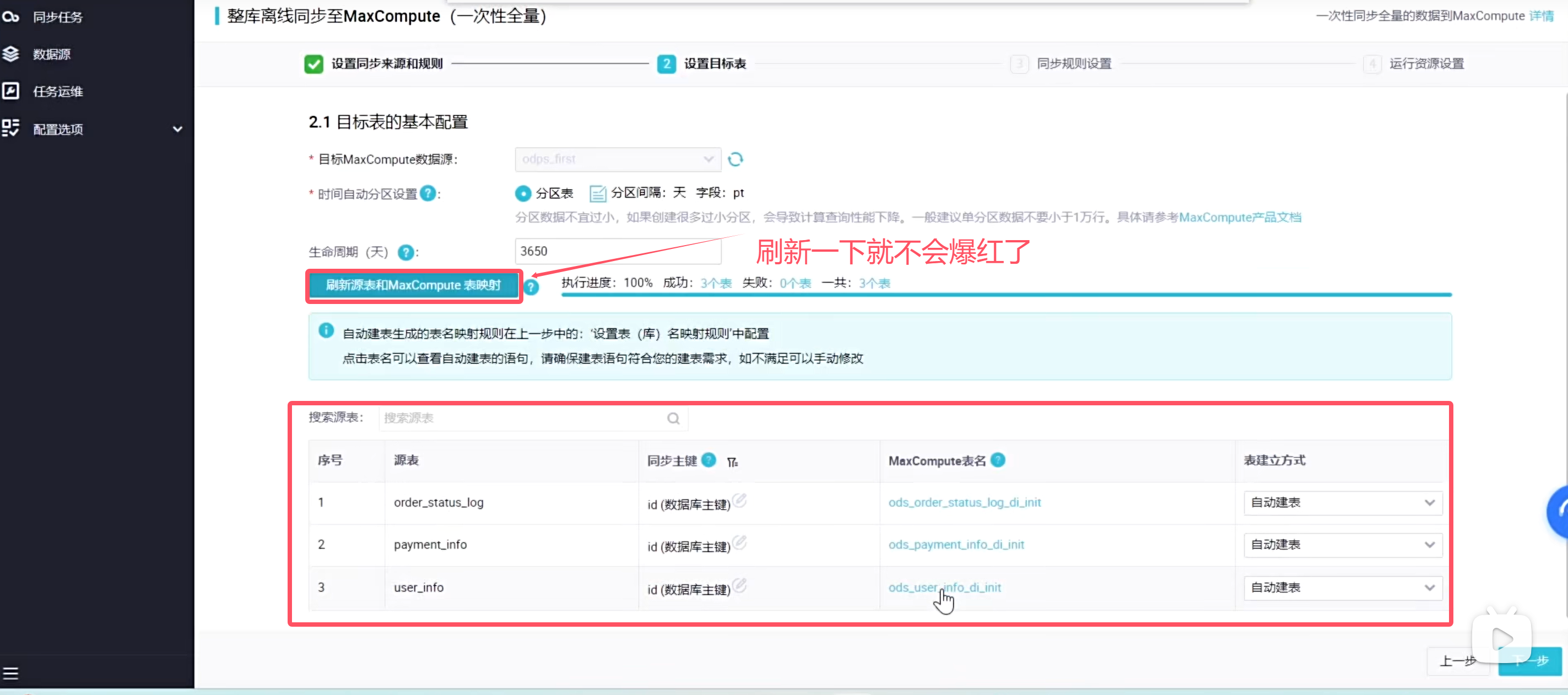
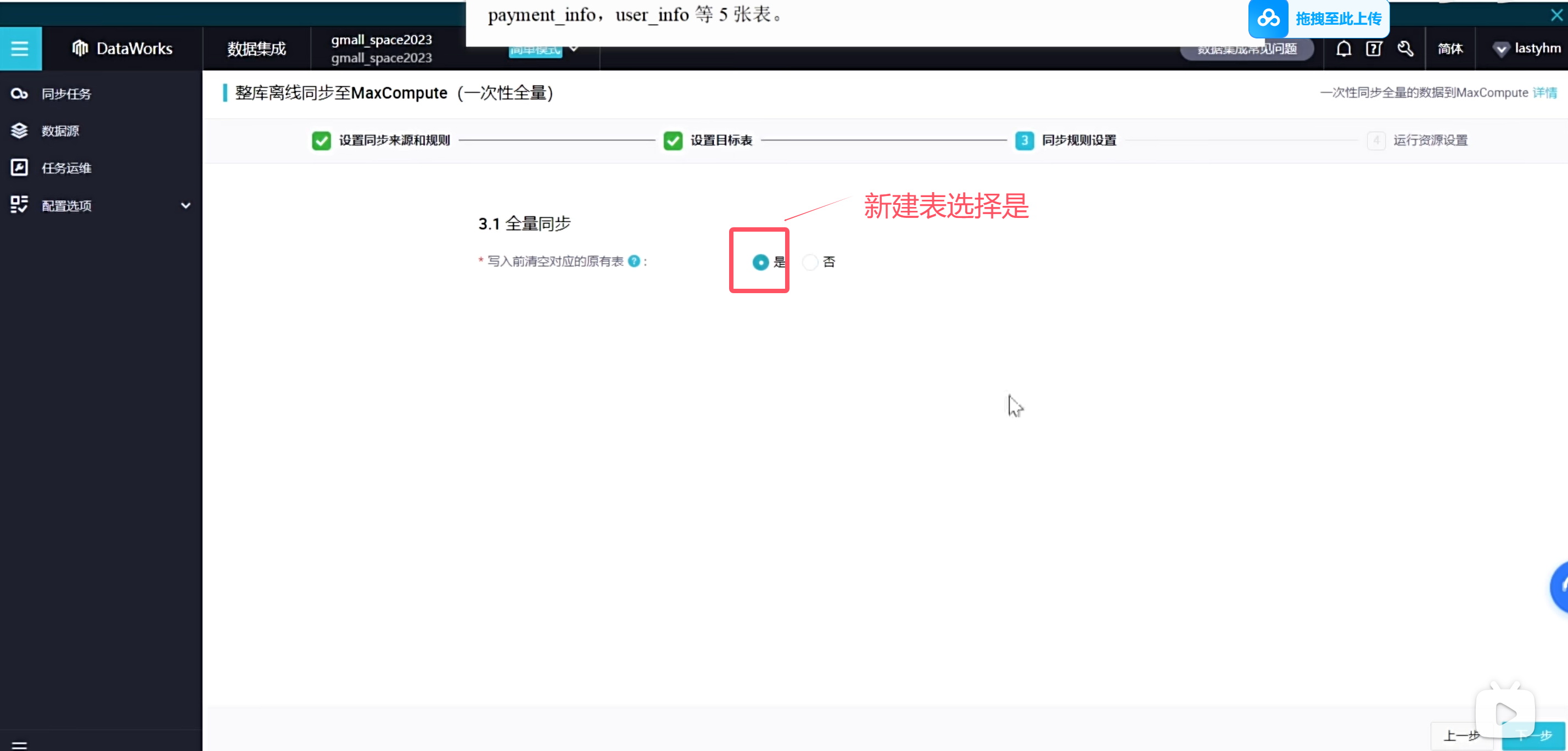
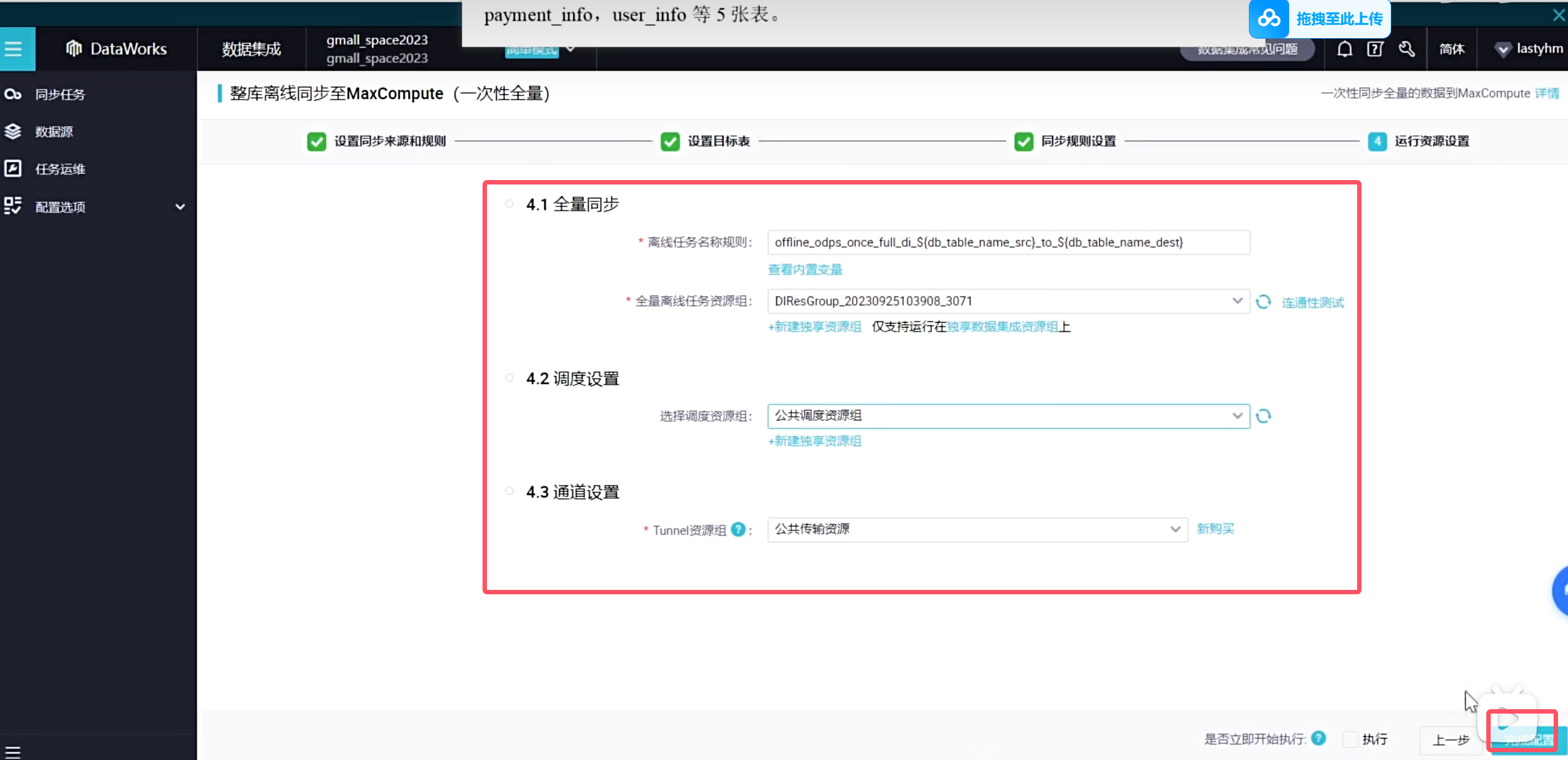
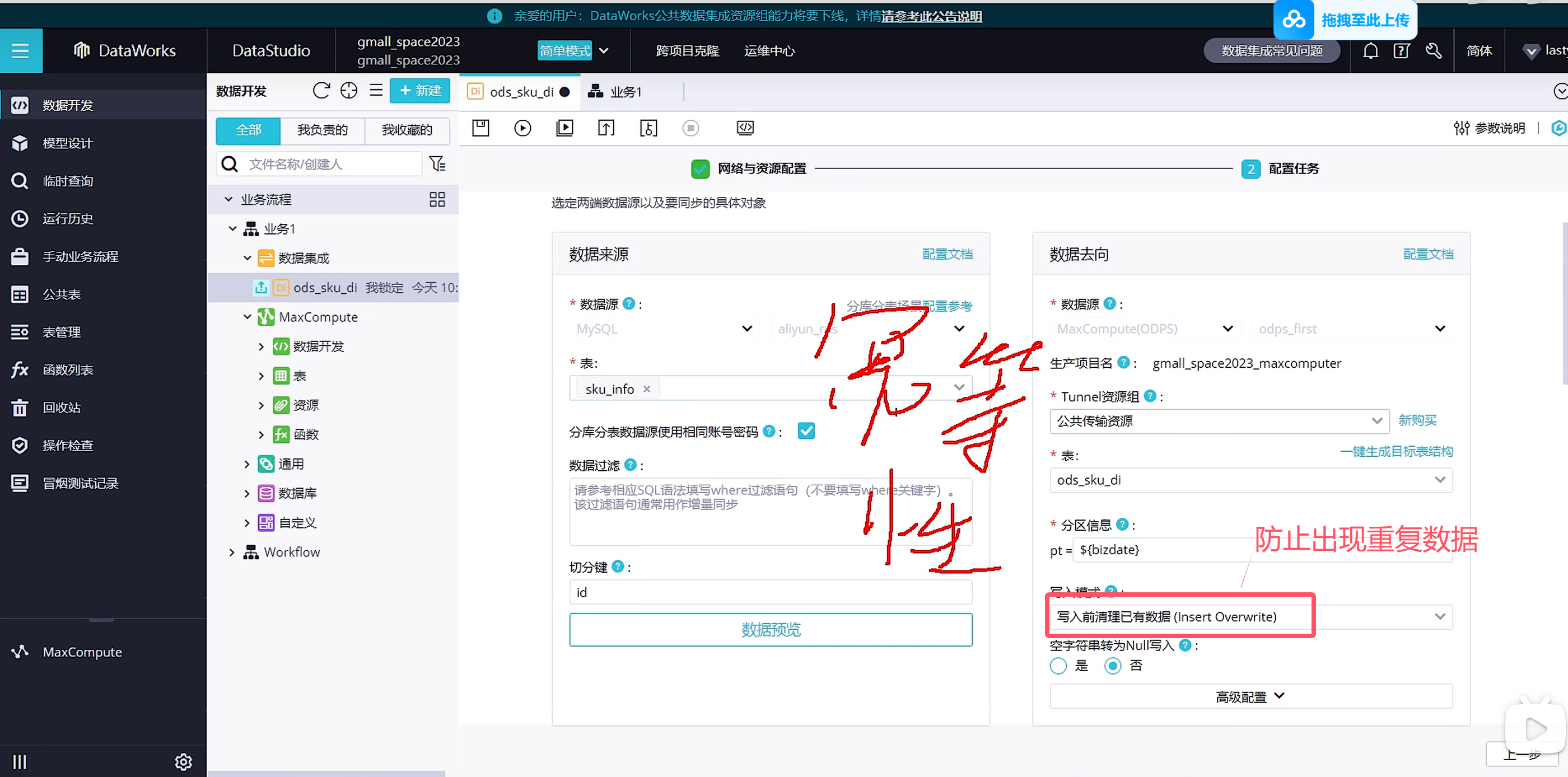
这种批量执行全自动化的是无法自己设置分区时间的,所以这个分区时间就是当前时间的前一天
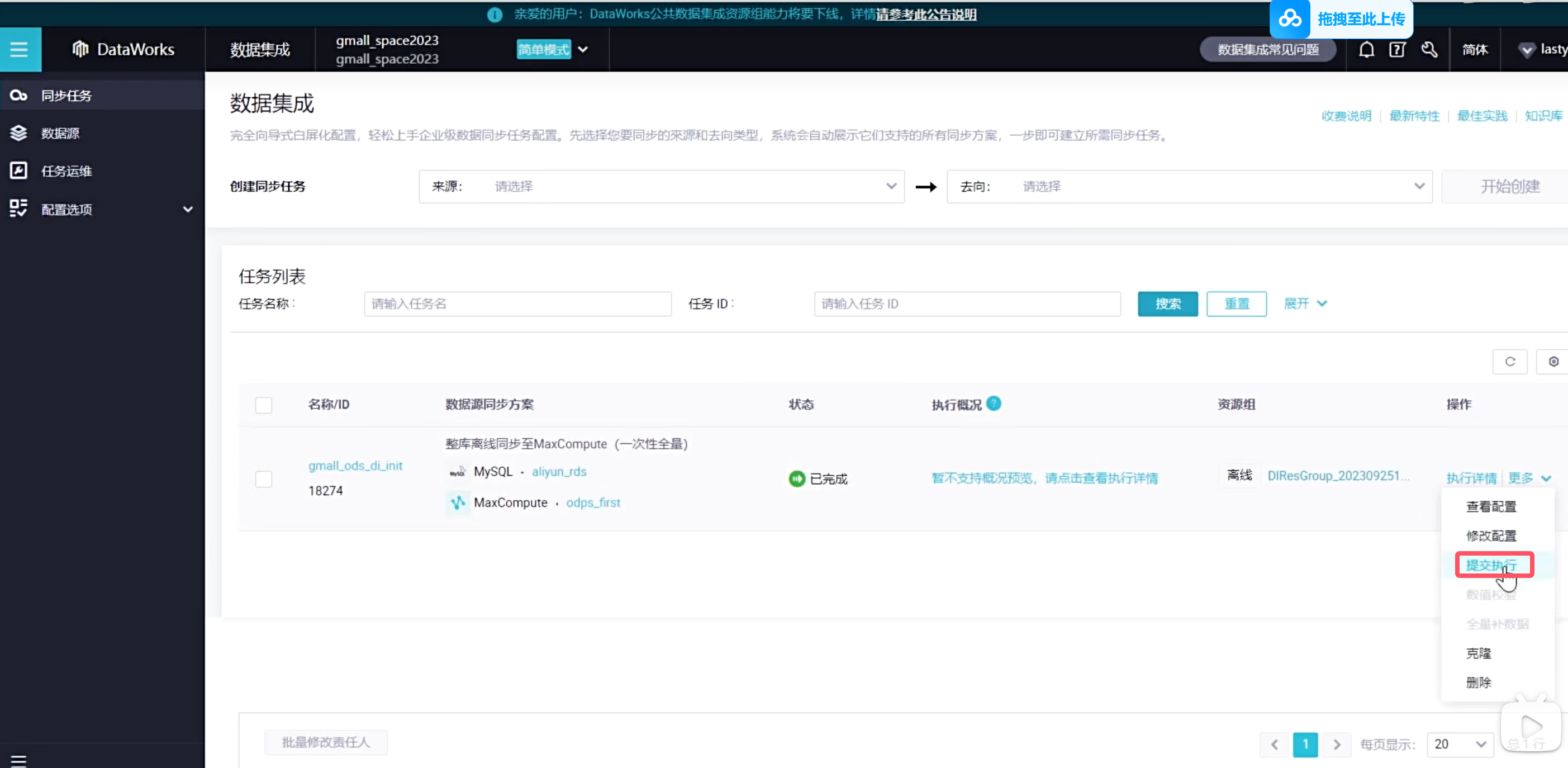
这种执行都是覆盖写入的,所以可以允许重复执行的,会把之前的数据覆盖掉,不会出现重复数据
还可以批量提交
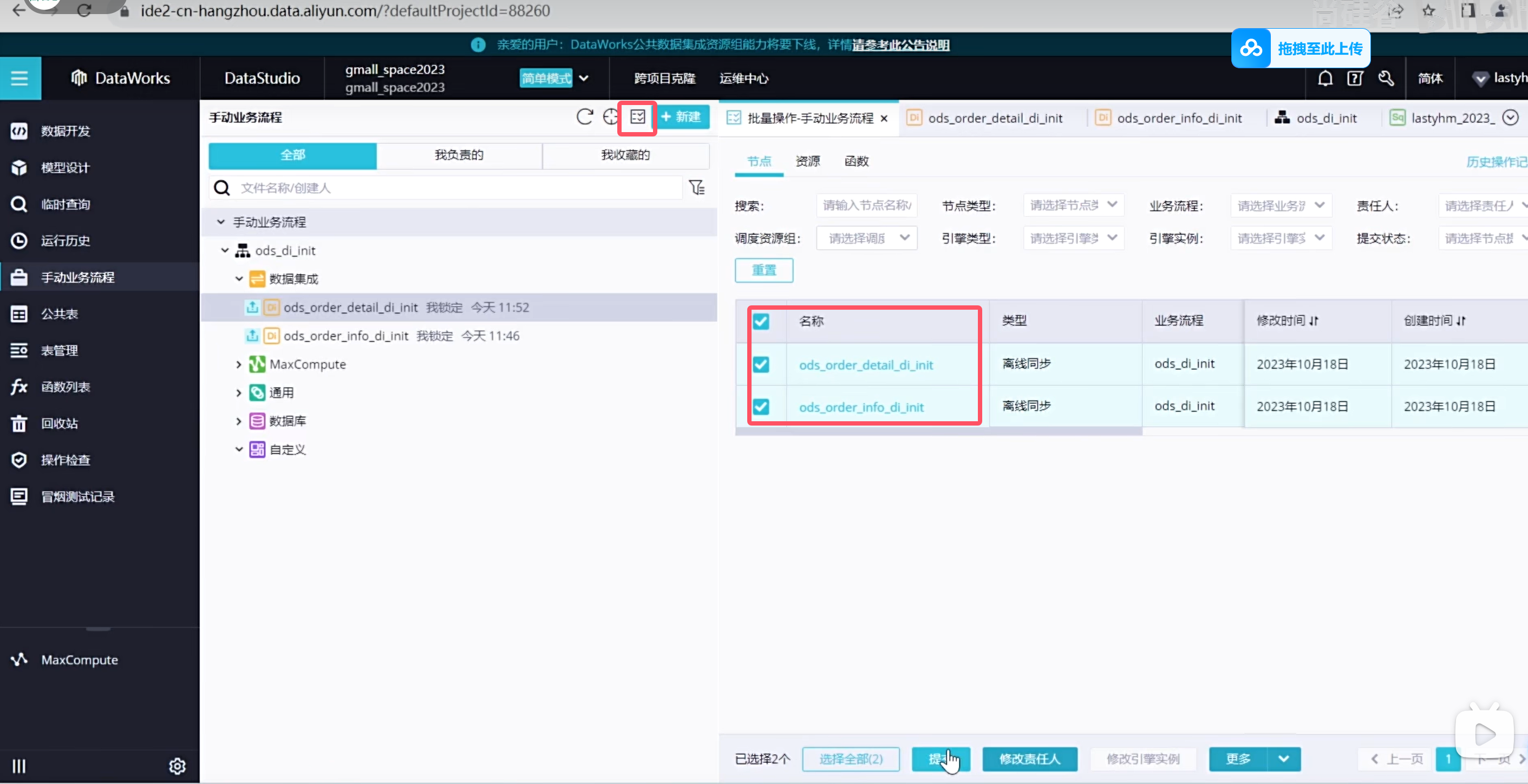
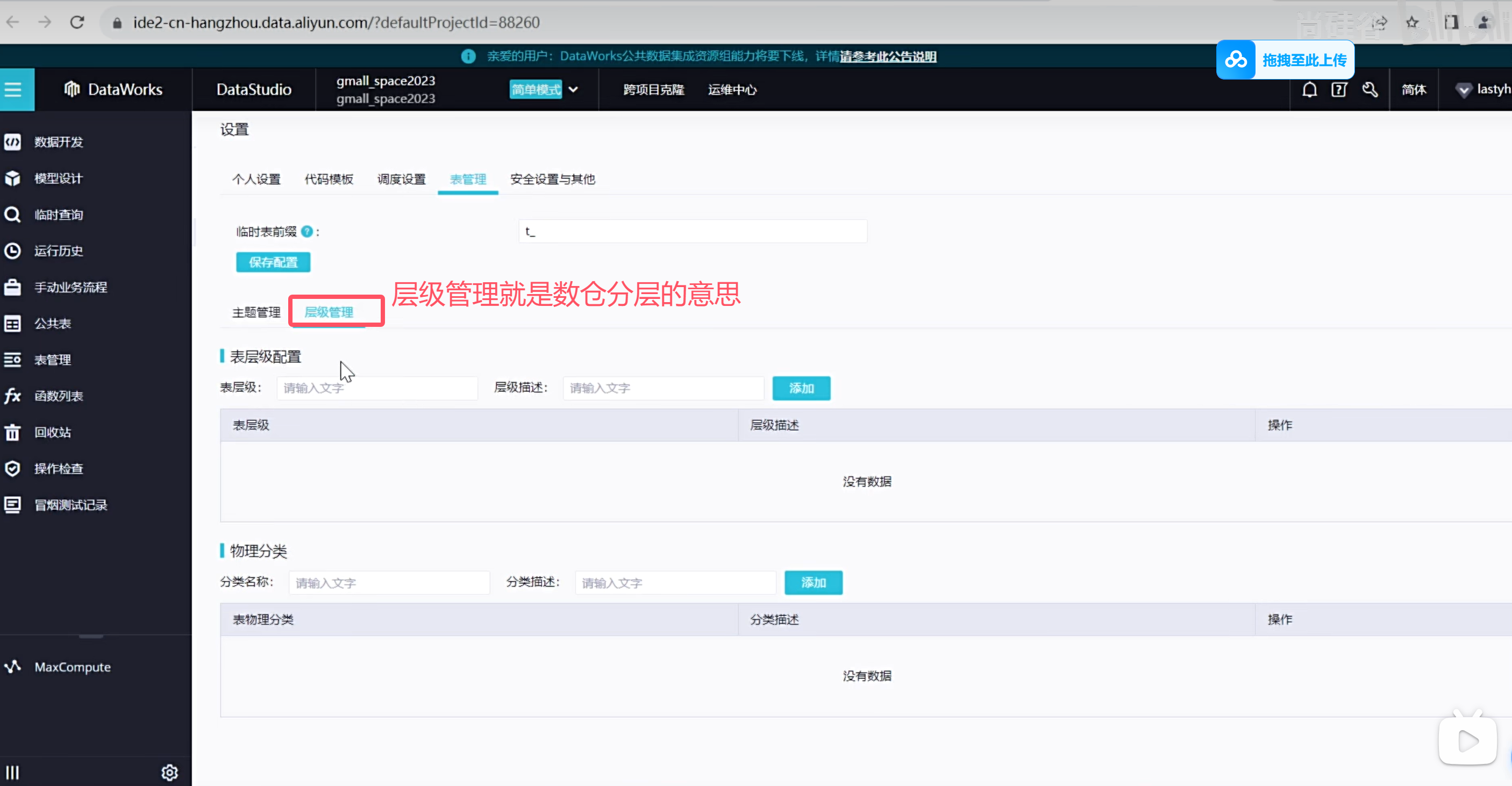
设置表格层级
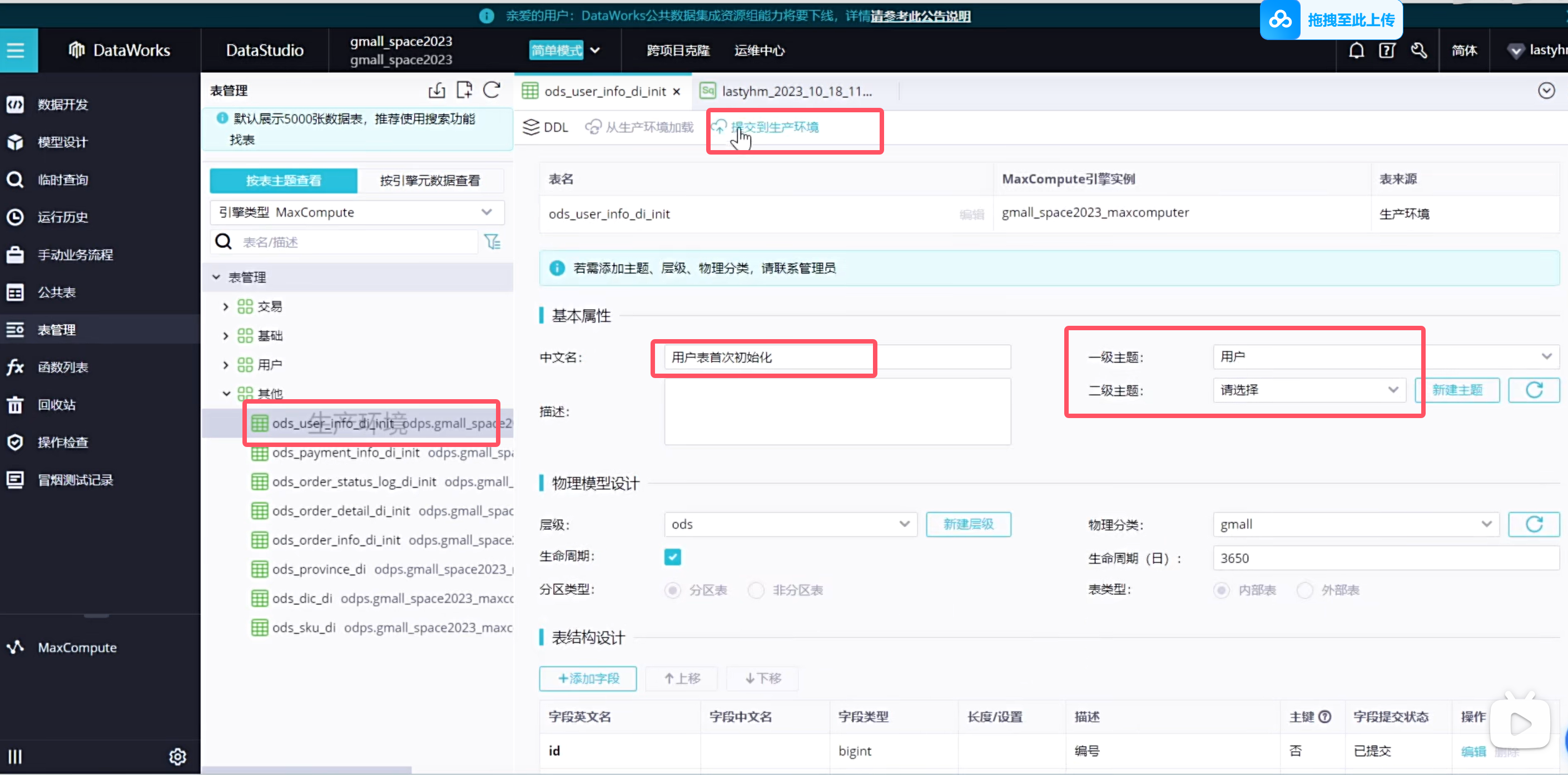
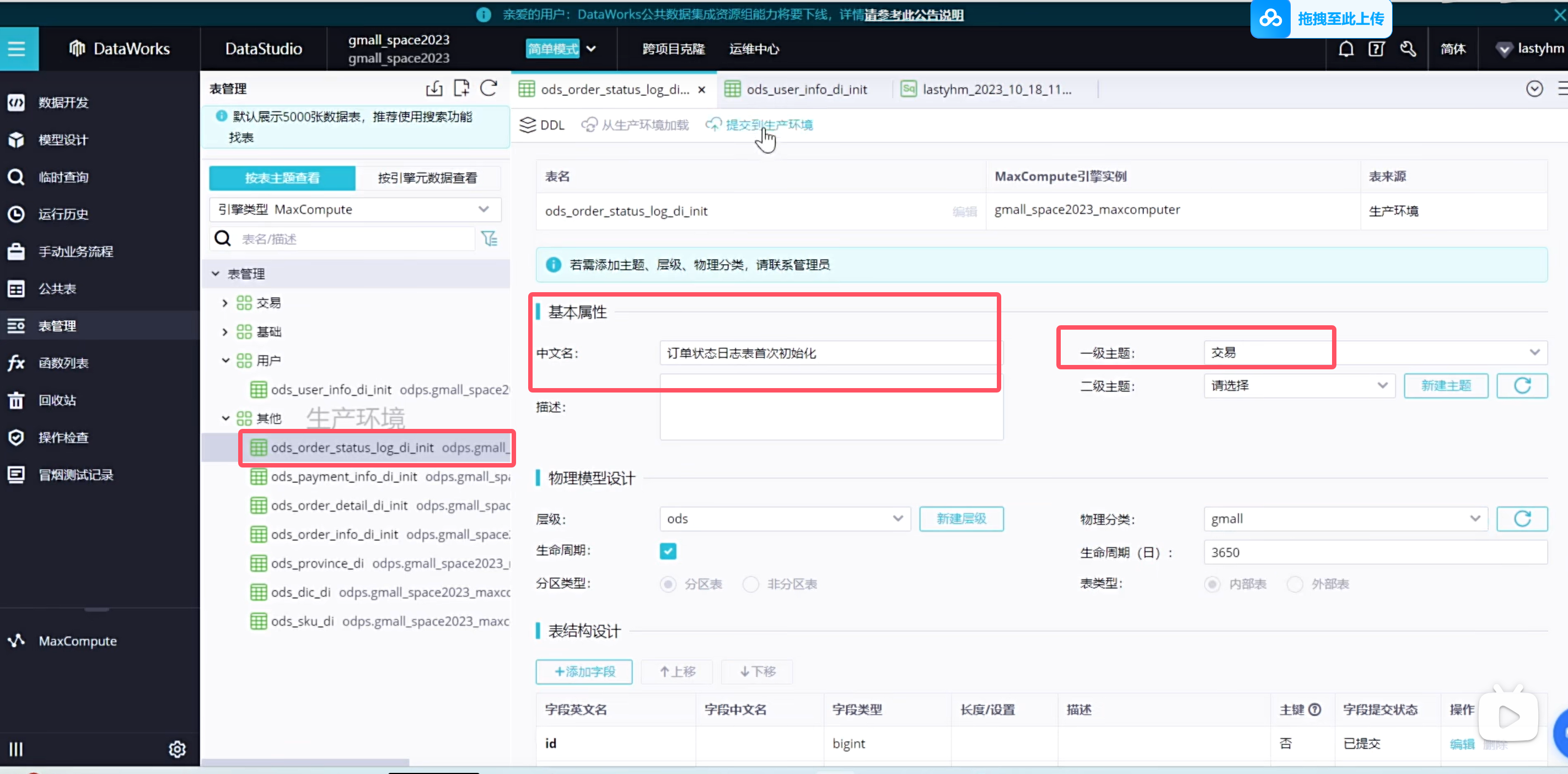
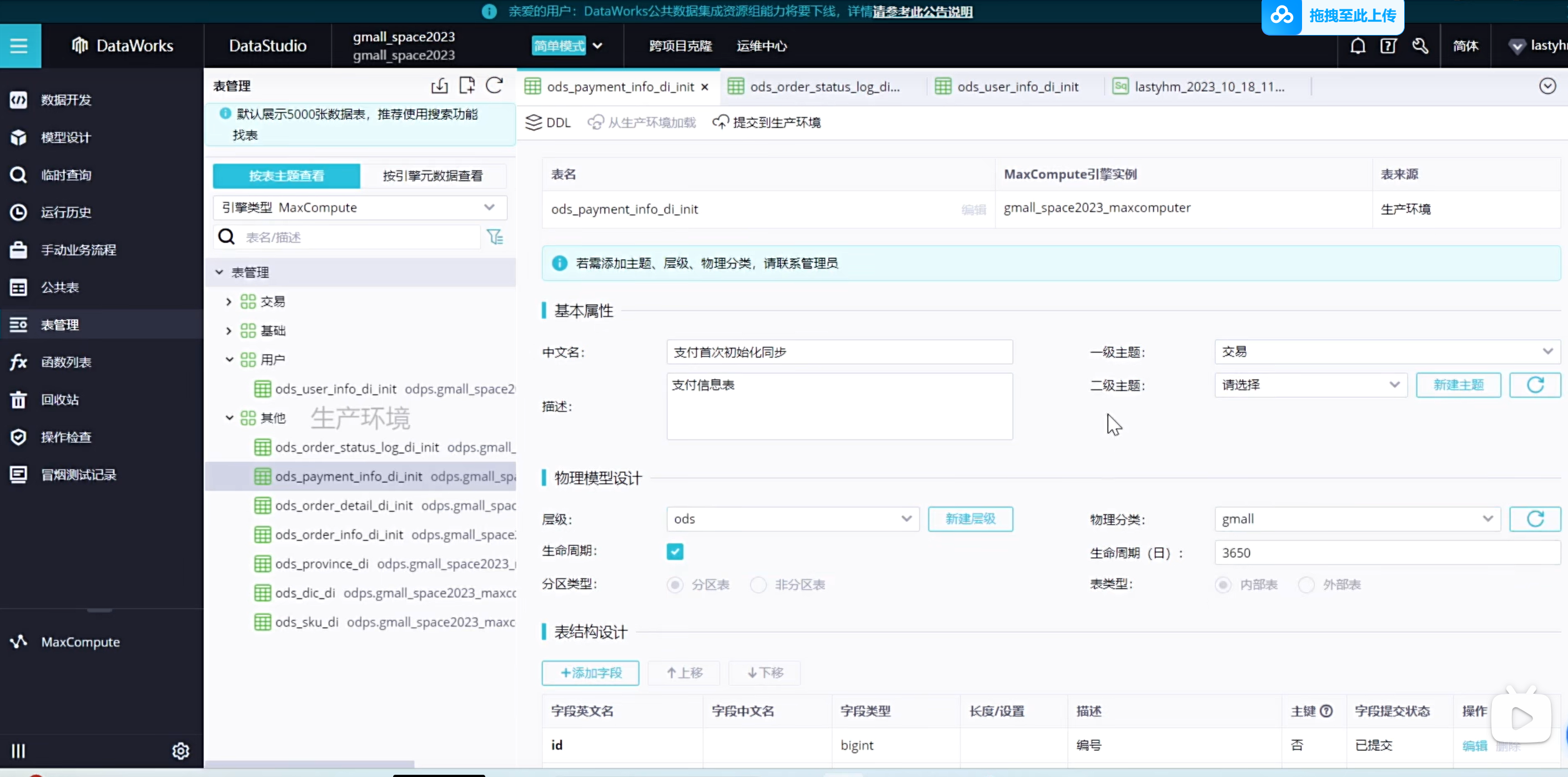
也可以添加二级主题
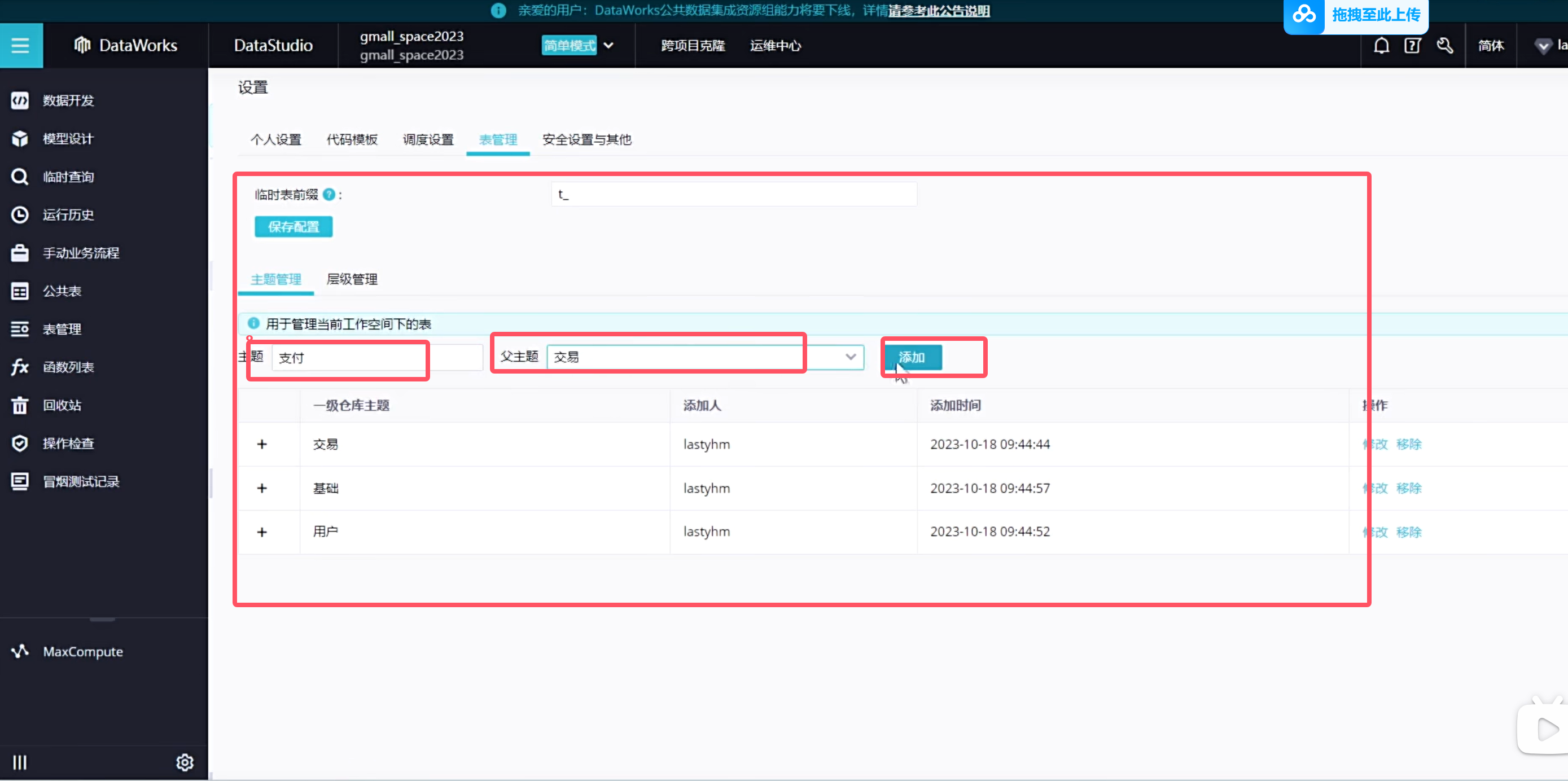
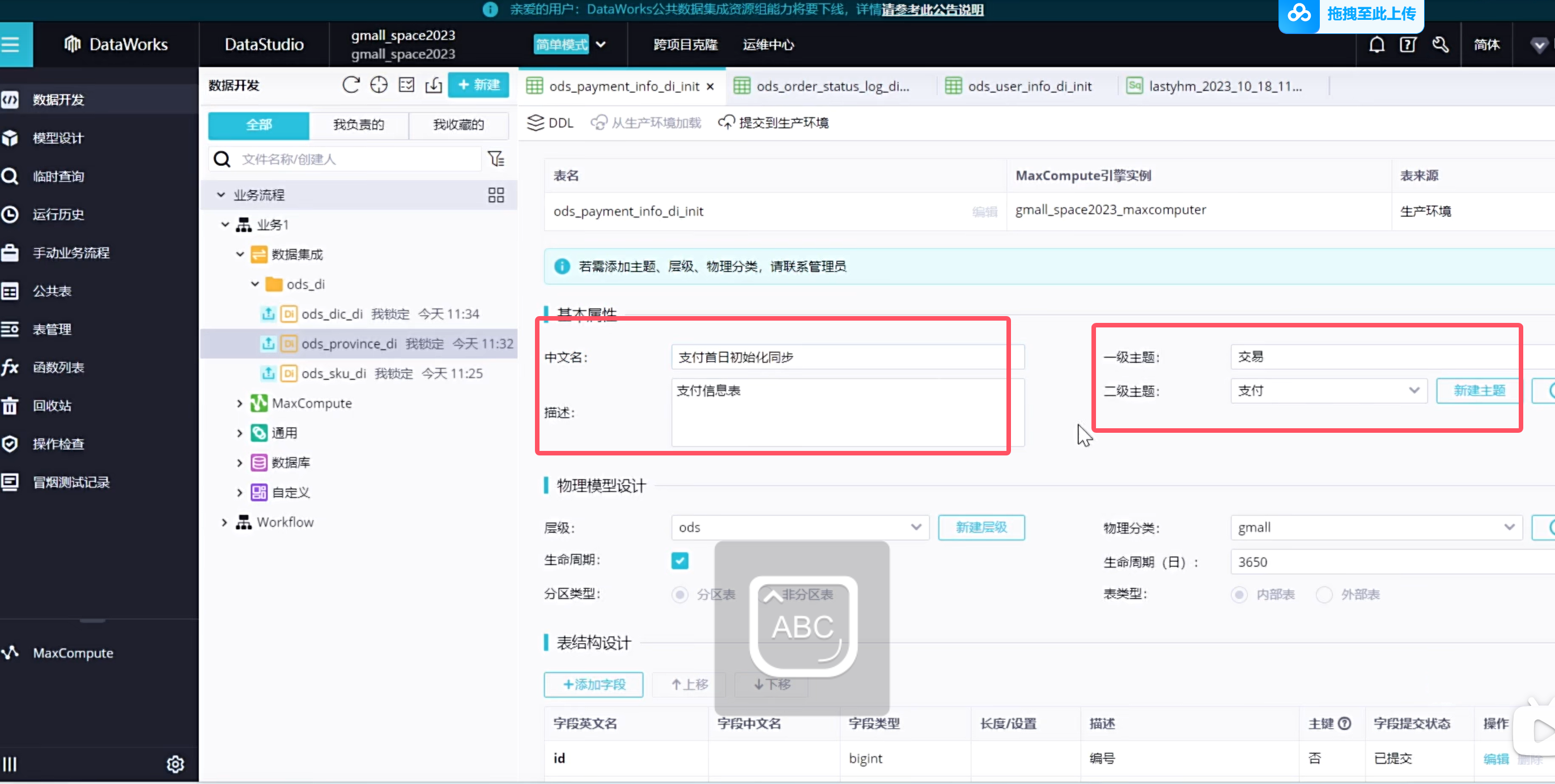
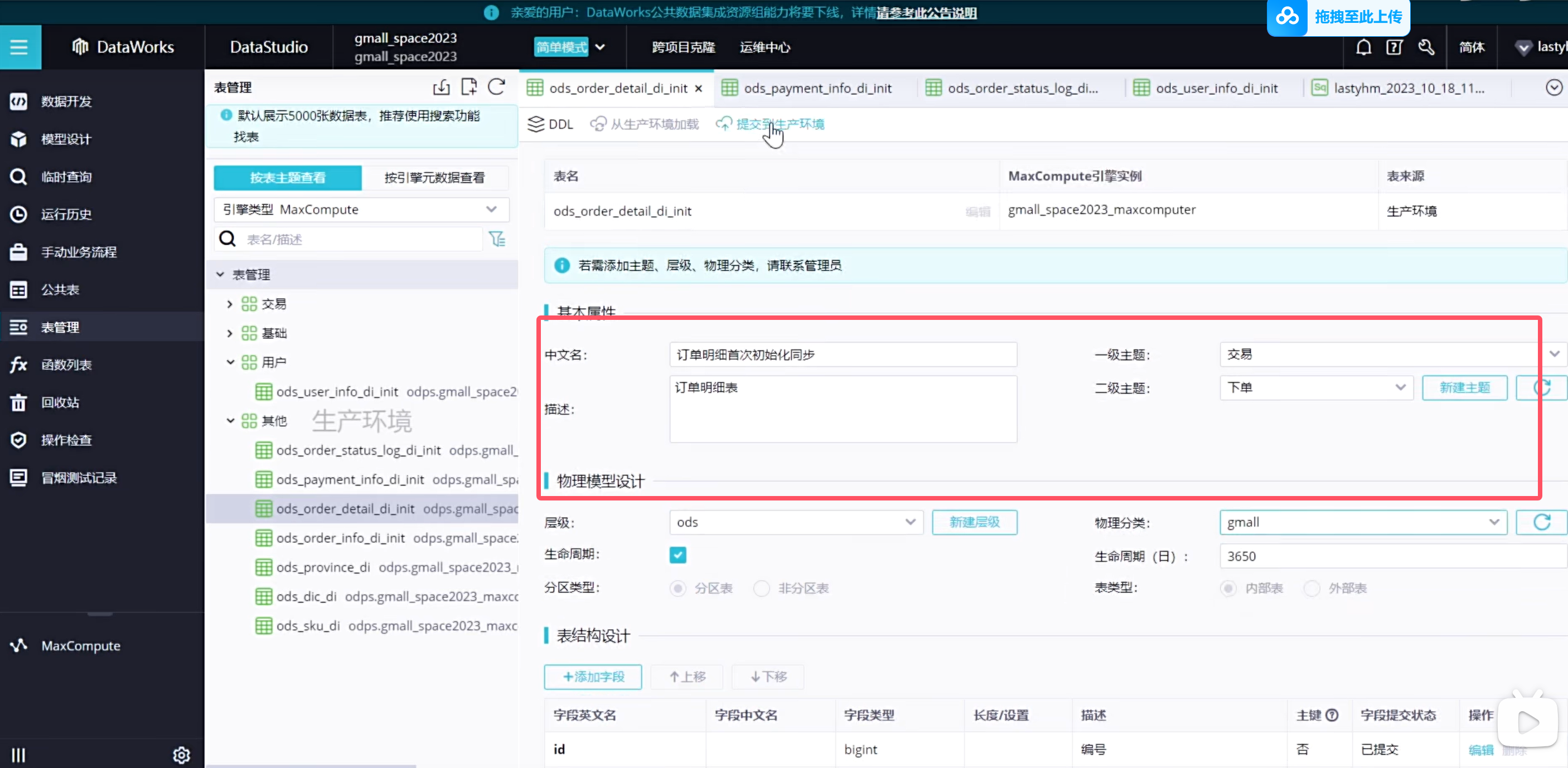
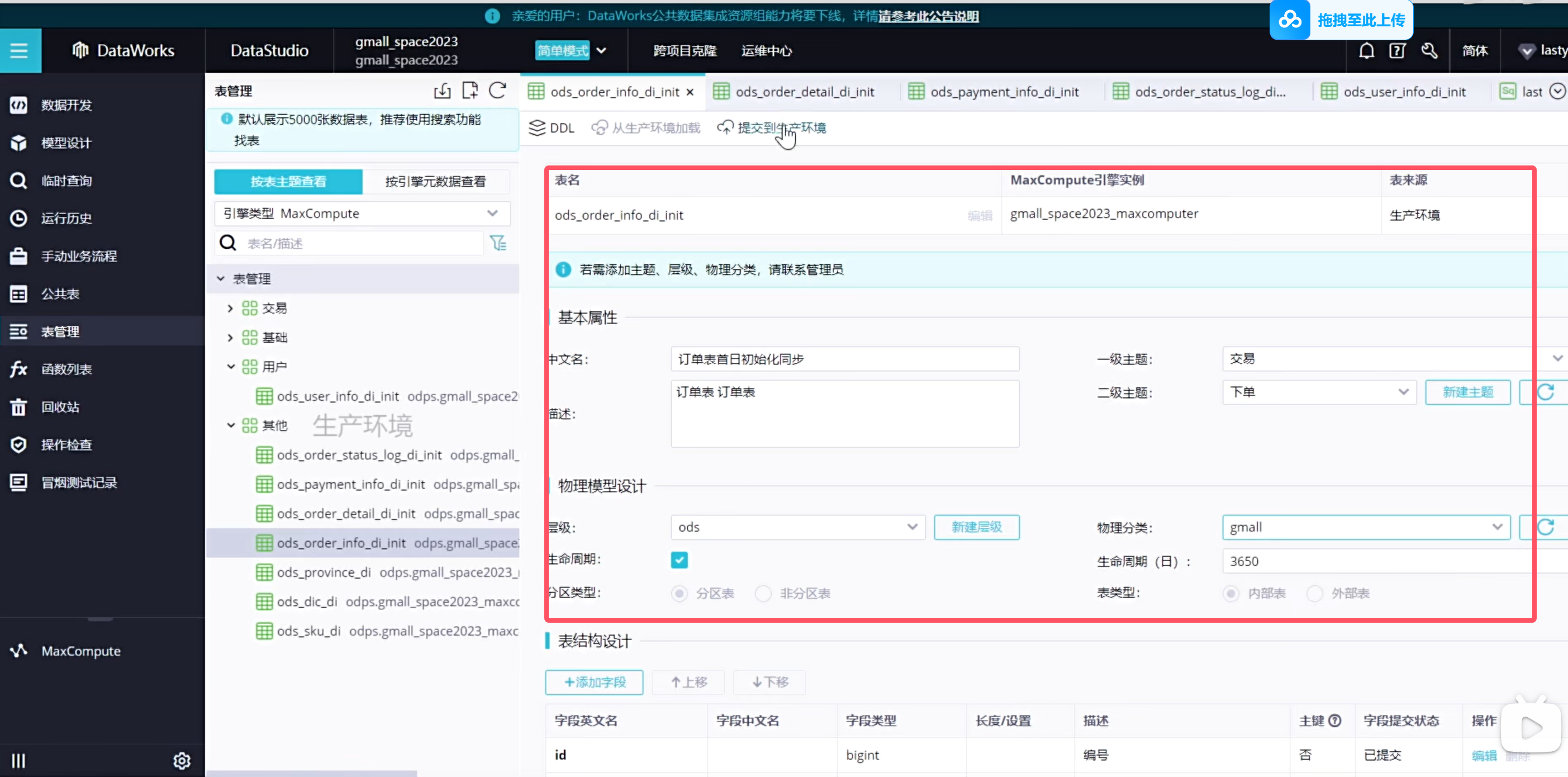
可以看到表都放到了对应的主题下,这样以后查询起来更加方便
增量表的实时同步

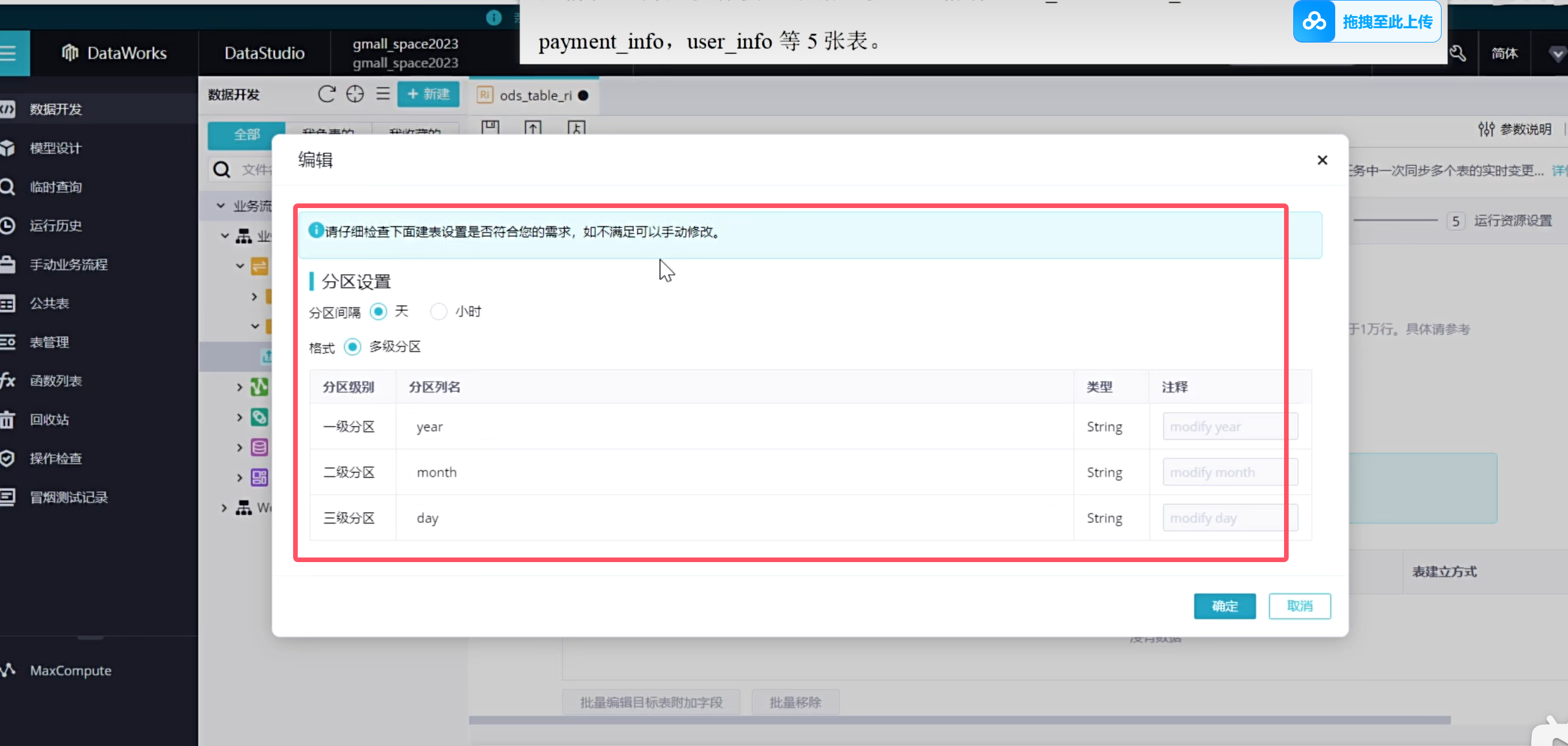
可以看到五张表已经全部创建出来了
点击下一步,开始建表
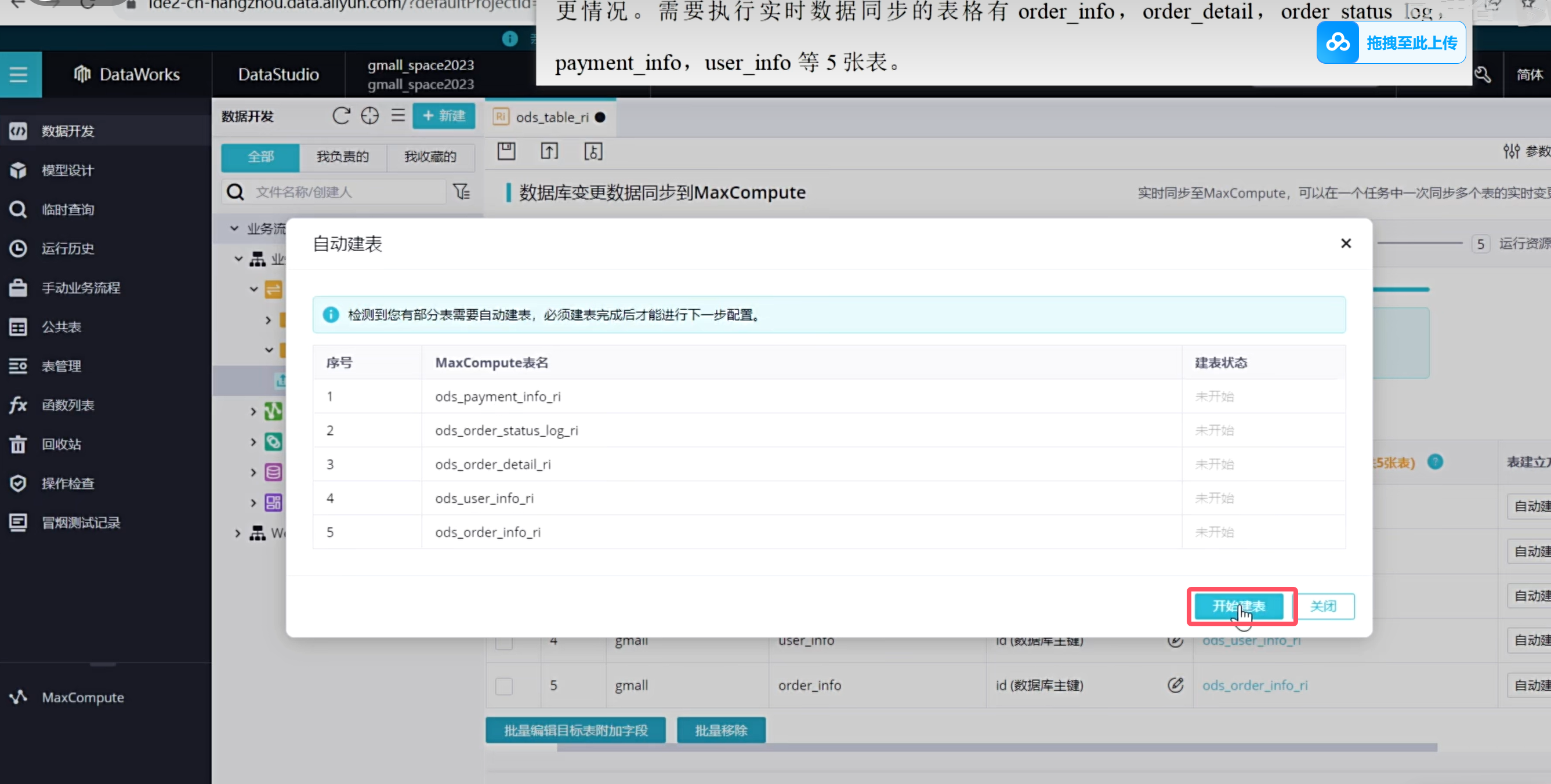
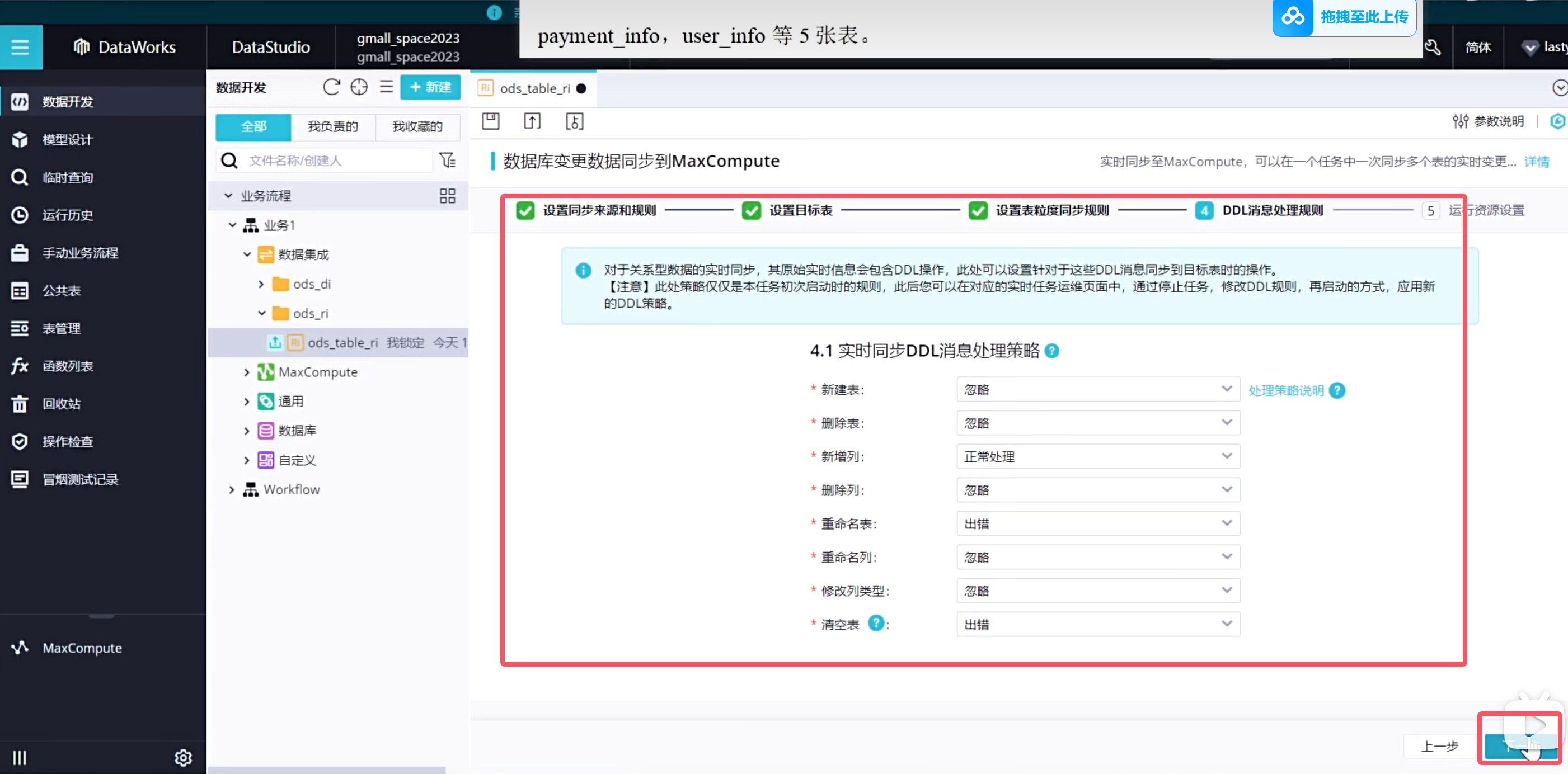
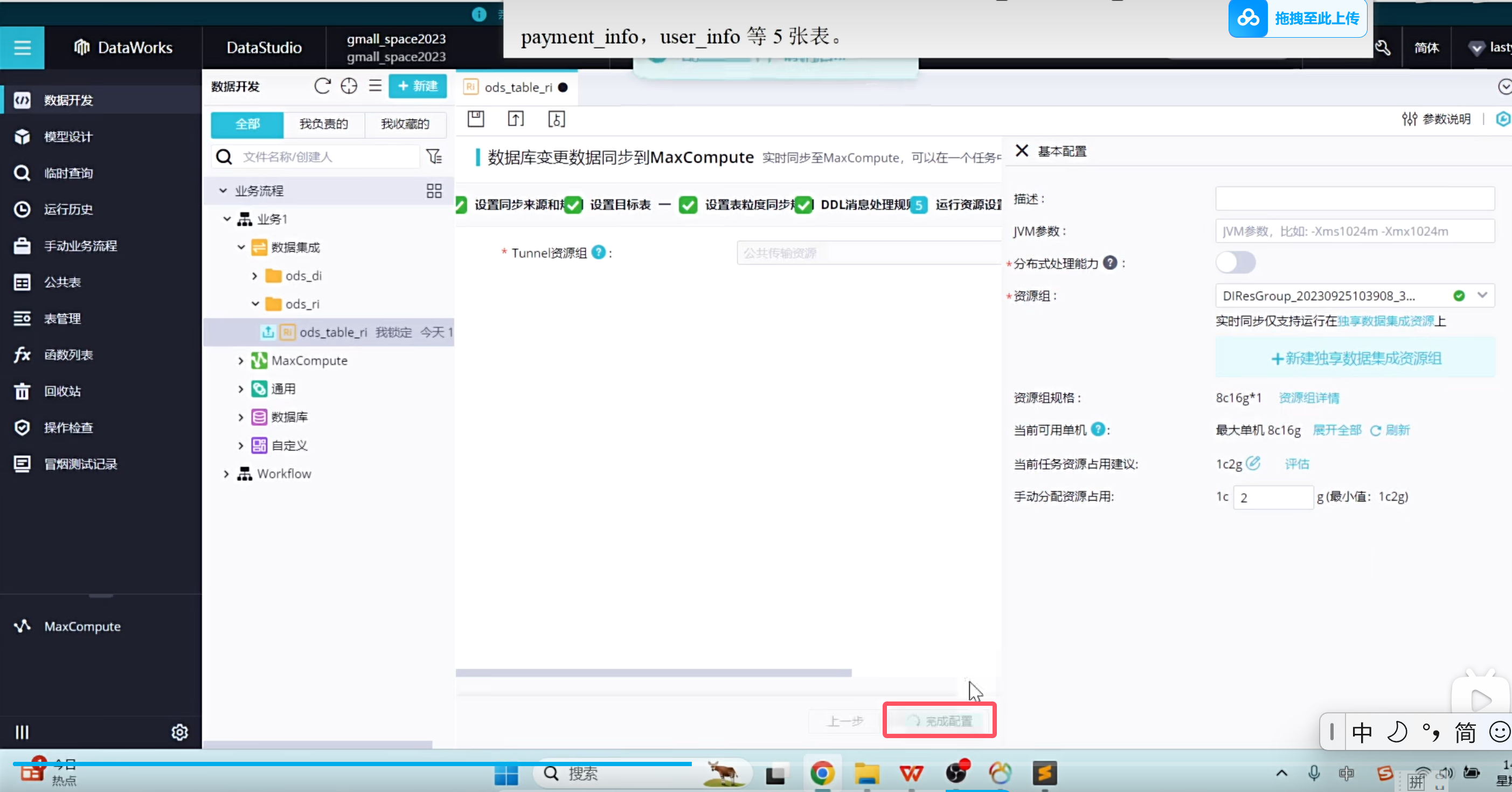
下面需要让任务跑起来
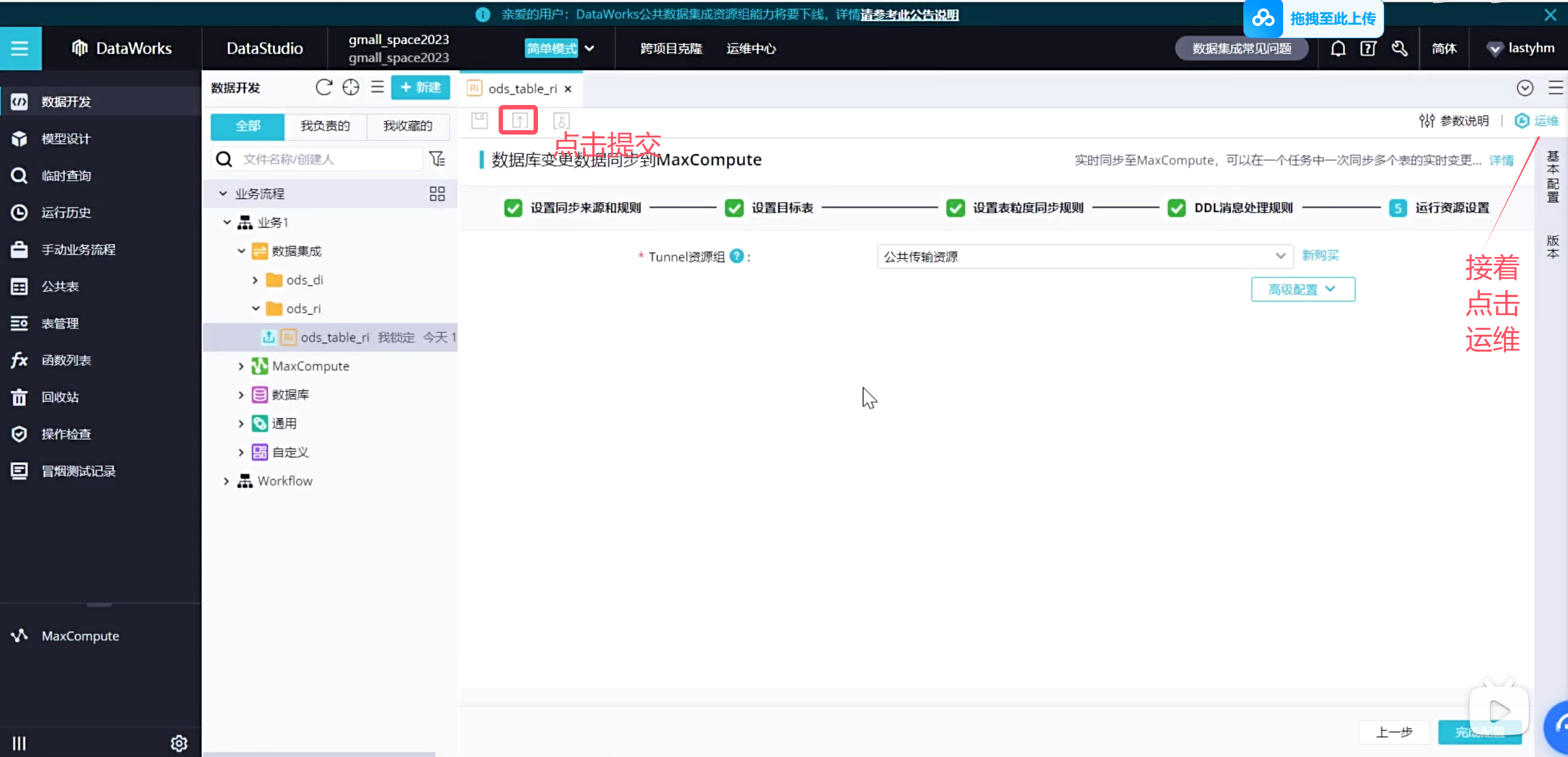
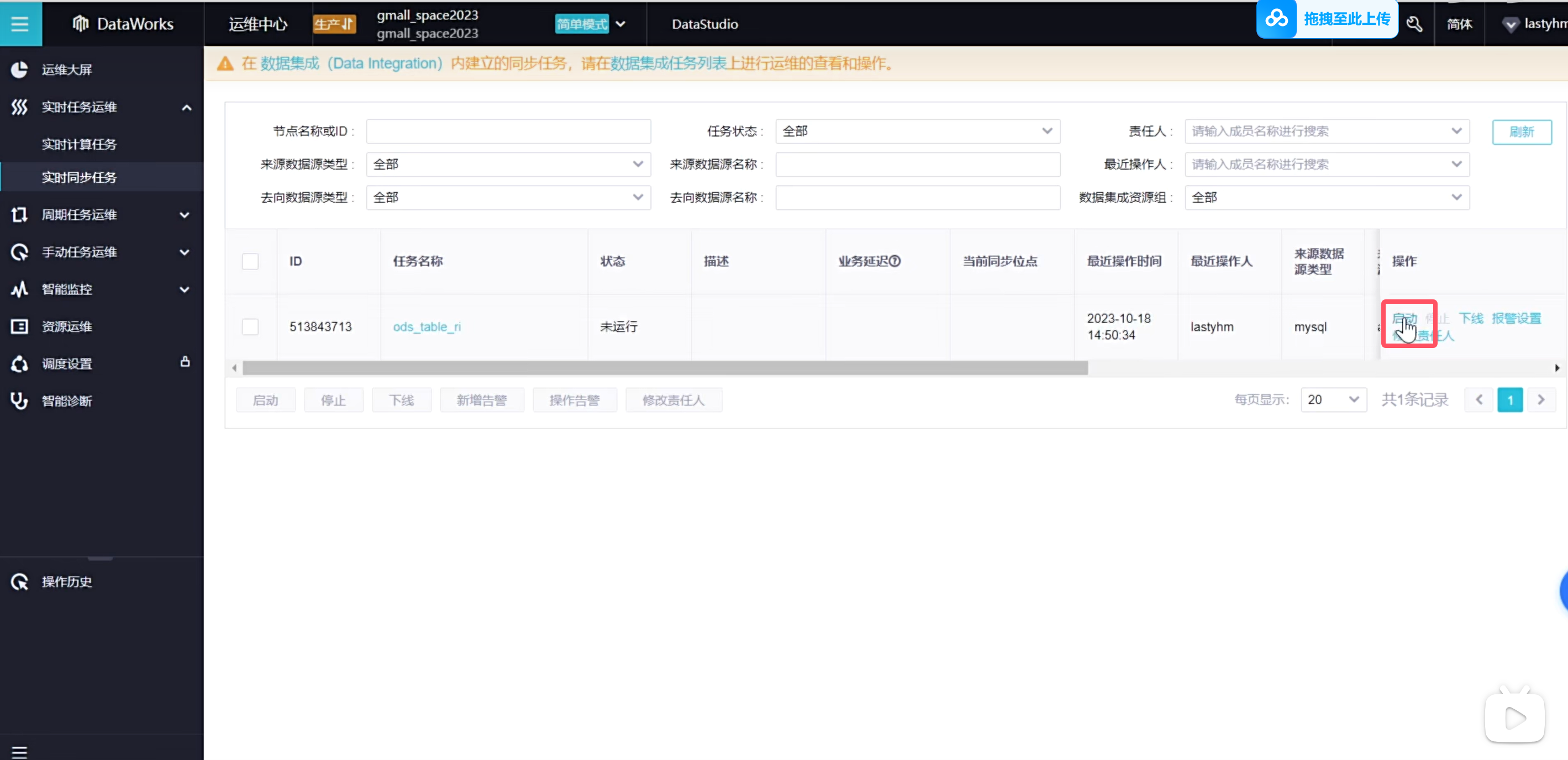
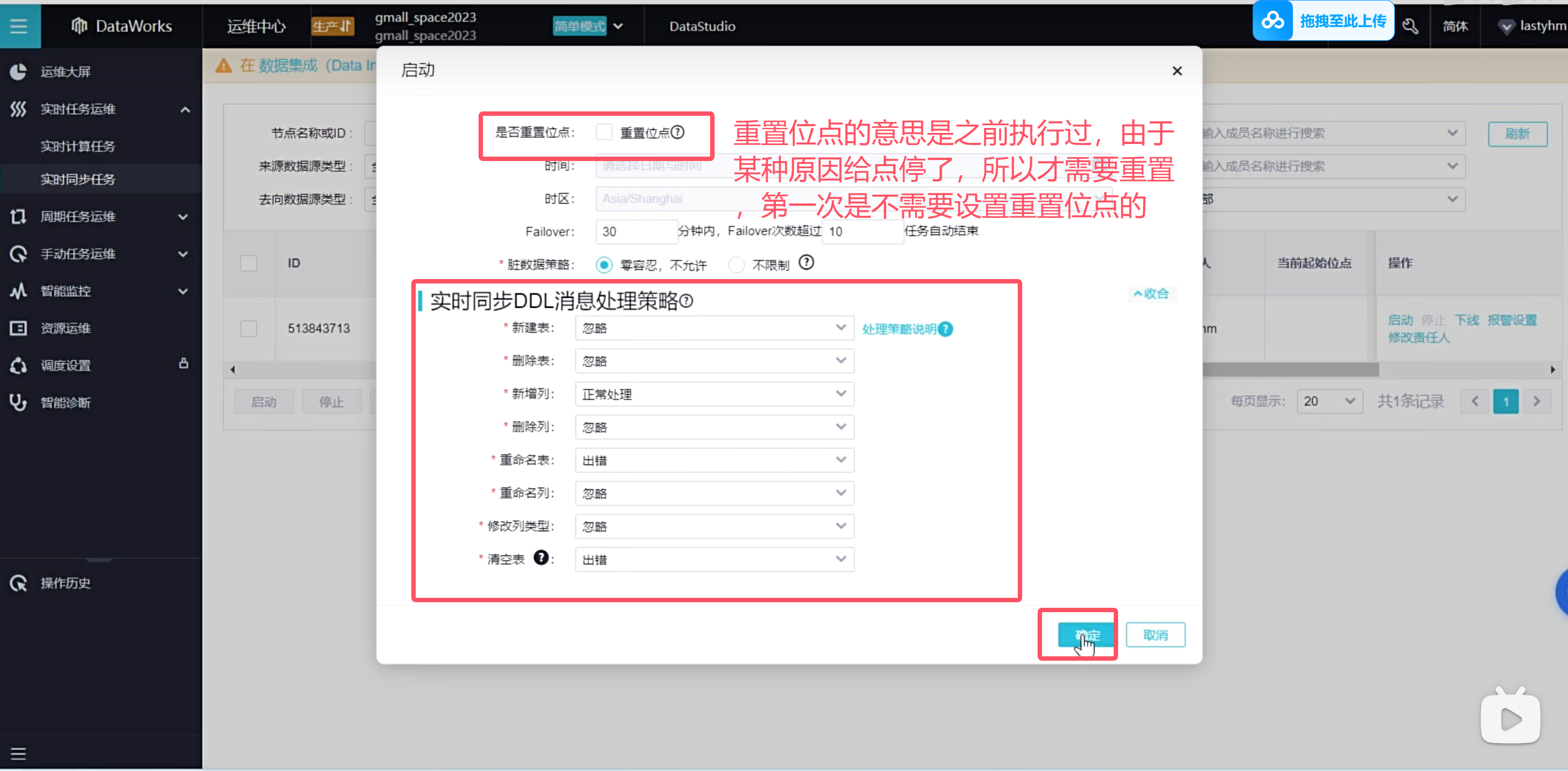
可以看到正在跑起来任务
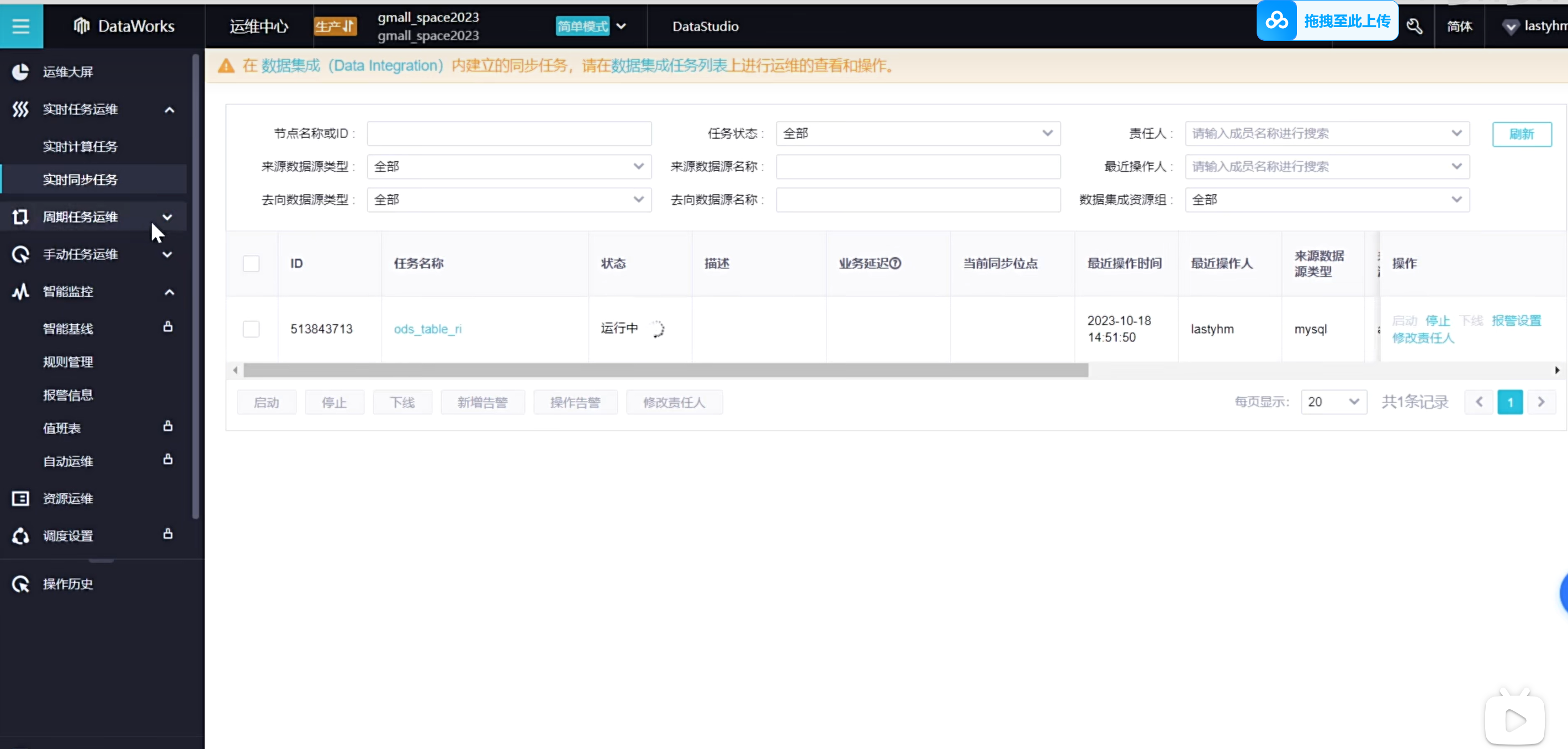
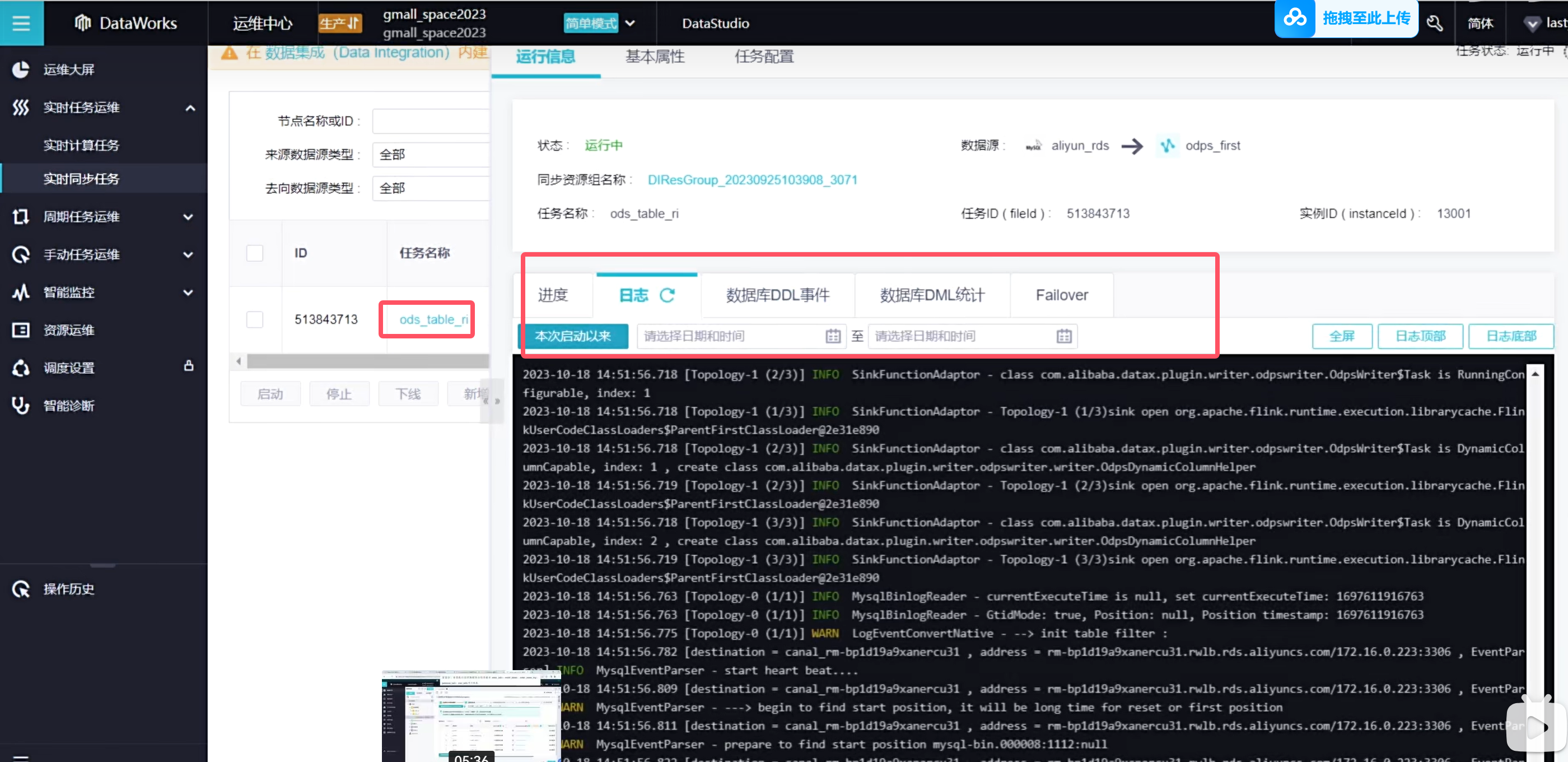
可以查看数据库的一些变化
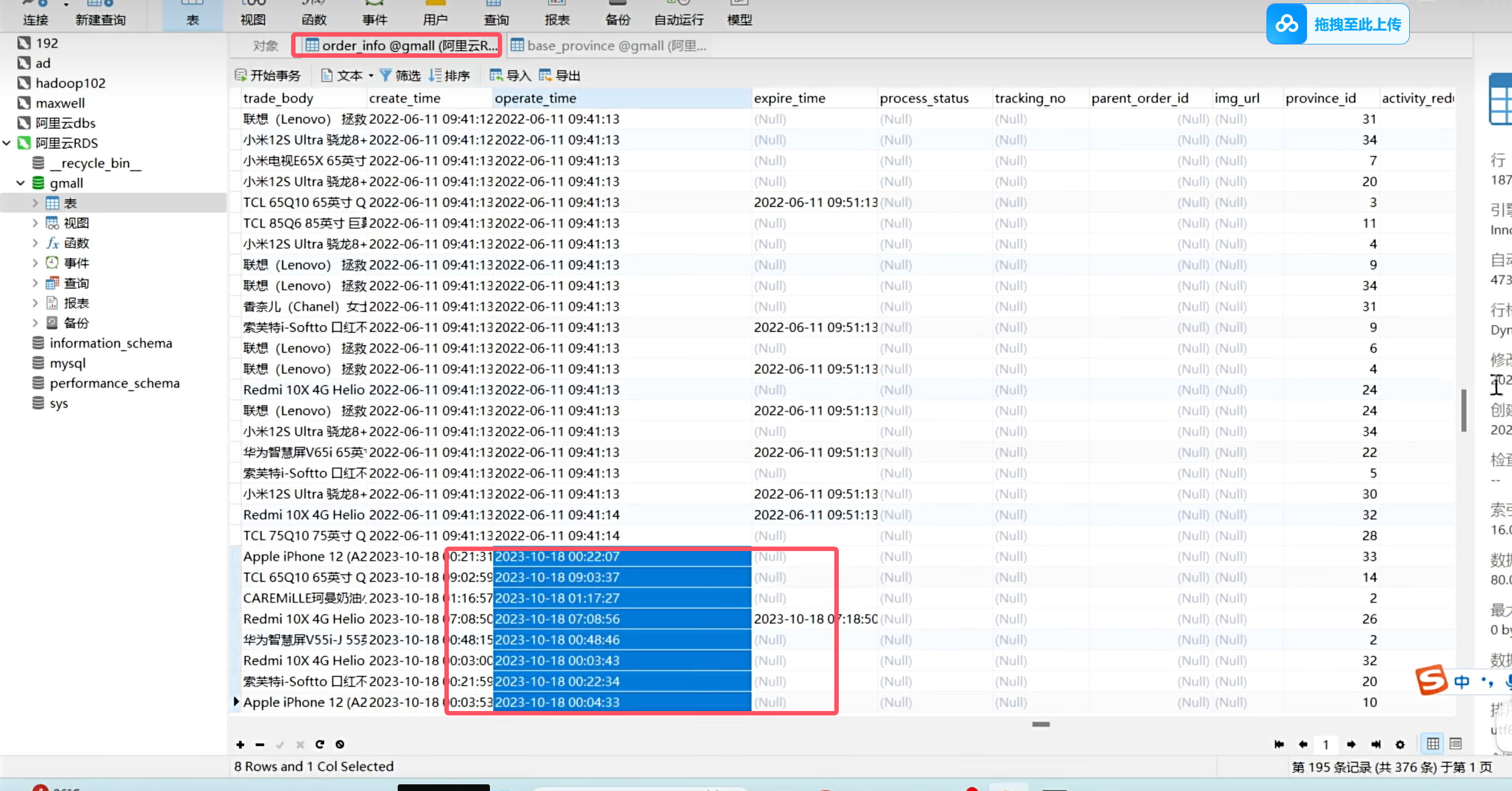
因为目前数据库的数据没啥变化,所以这里可以自己去造数据,然后看odps上的变化,mock过程忽略
可以看到odps上的监控信息
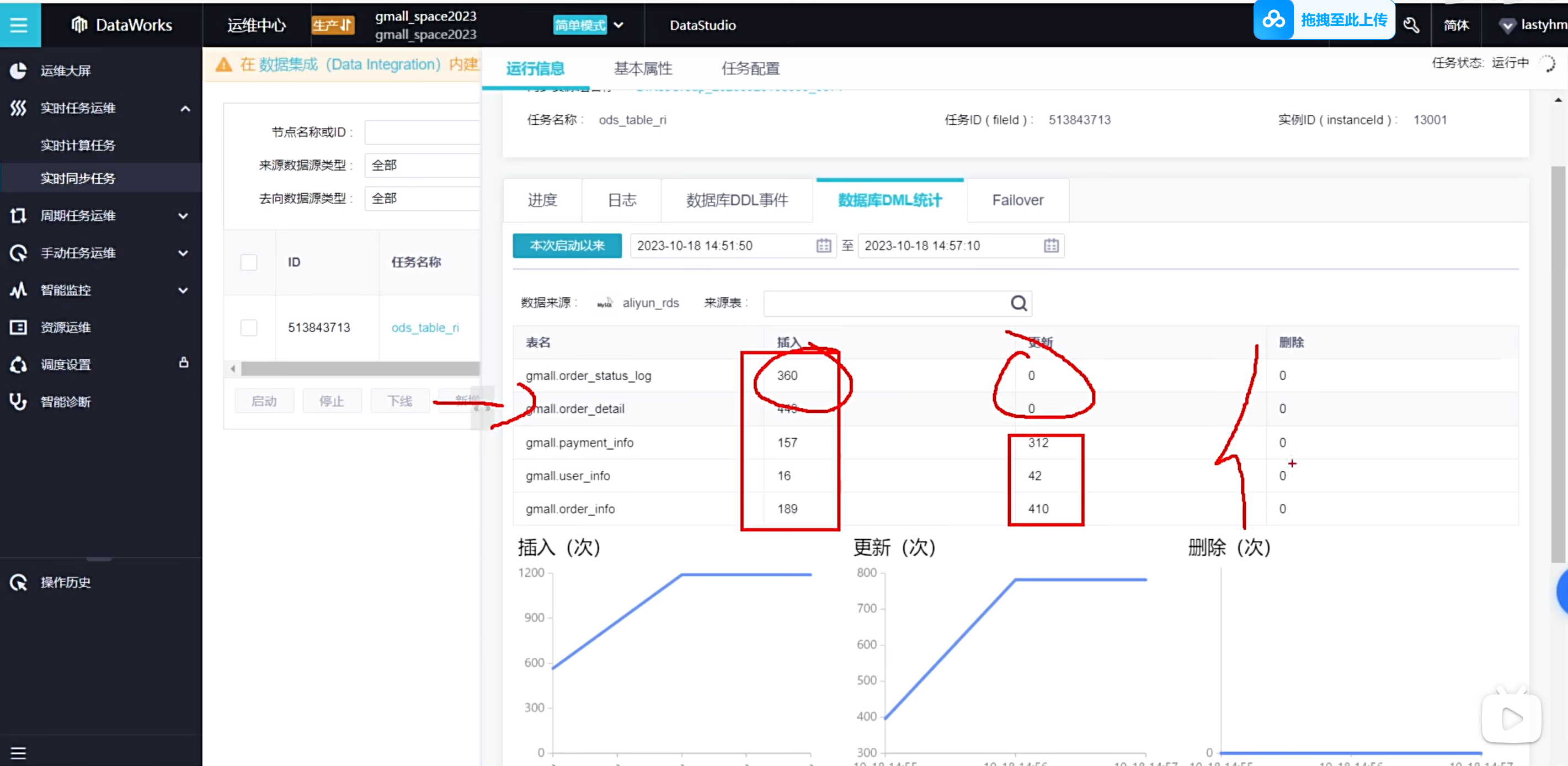
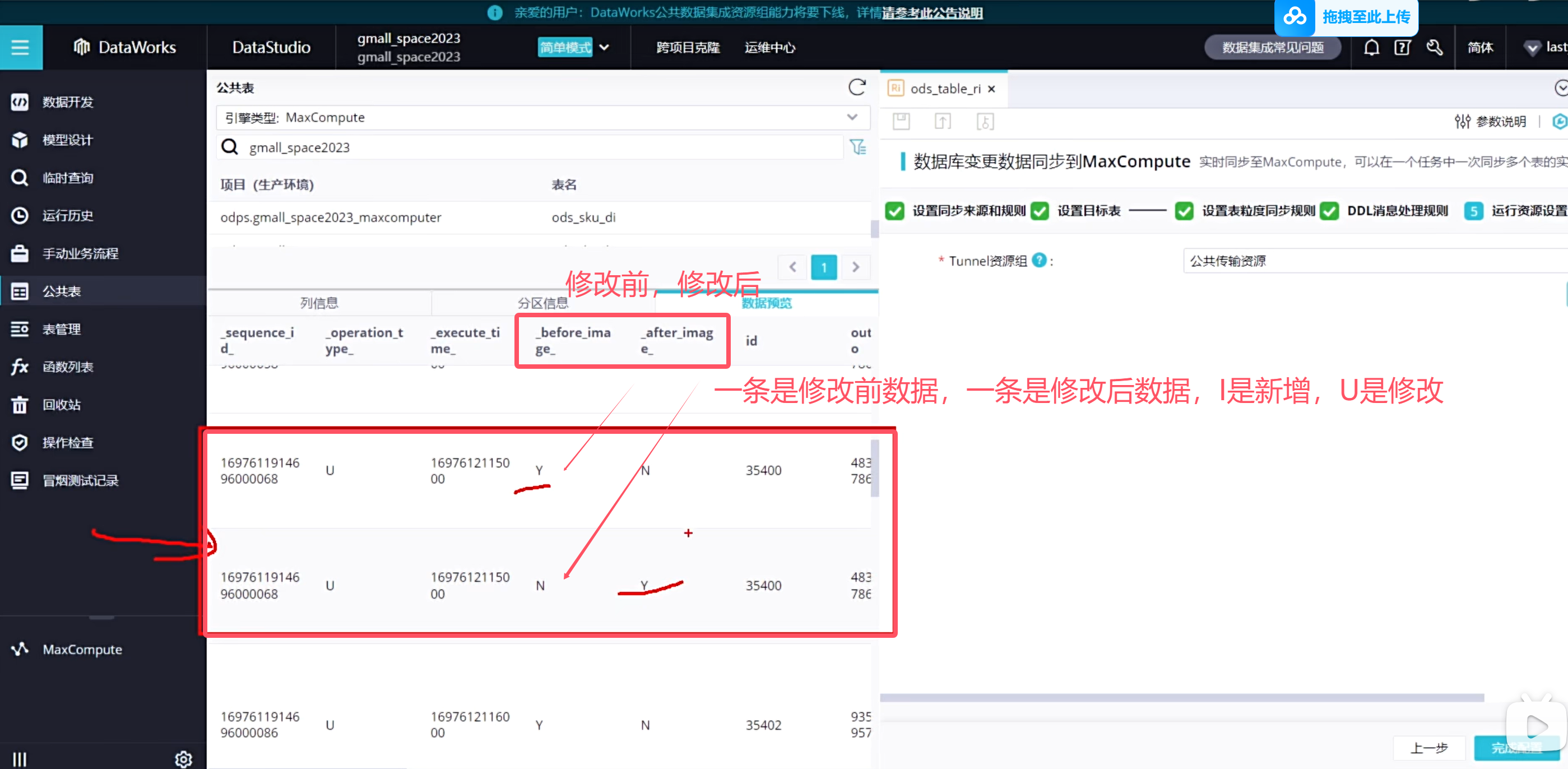
可以去odps是查一下增量表的数据信息
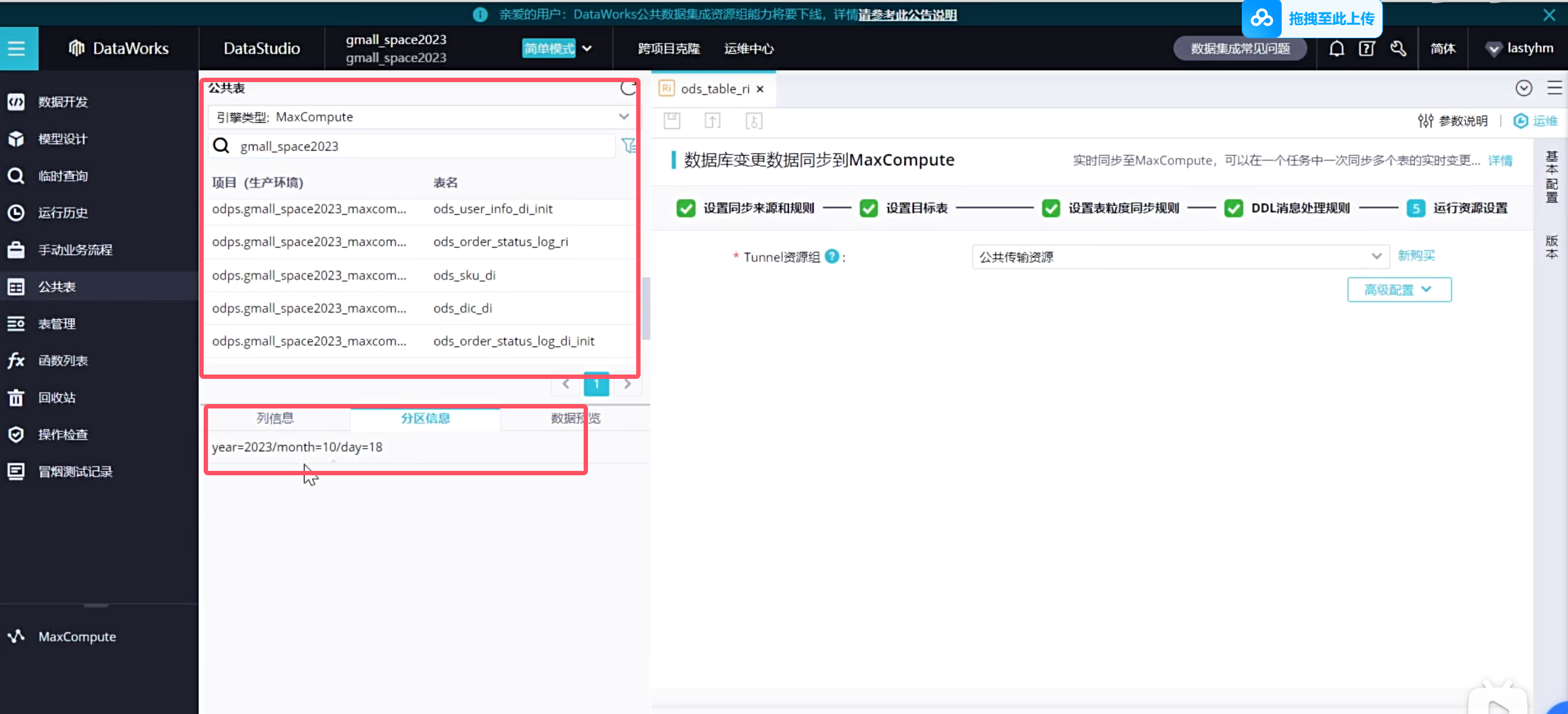
一条修改的数据在增量同步表里面会存在两条数据,一条是修改前的数据,一条是修改后的数据