机器学习的数学基础:神经网络
神经网络
文章目录
- 神经网络
- 神经元模型
- 感知机与多层网络
- 多层前馈神经网络
- 误差逆传播算法
- BP算法伪代码
- 手搓一个简单的BP神经网络模型
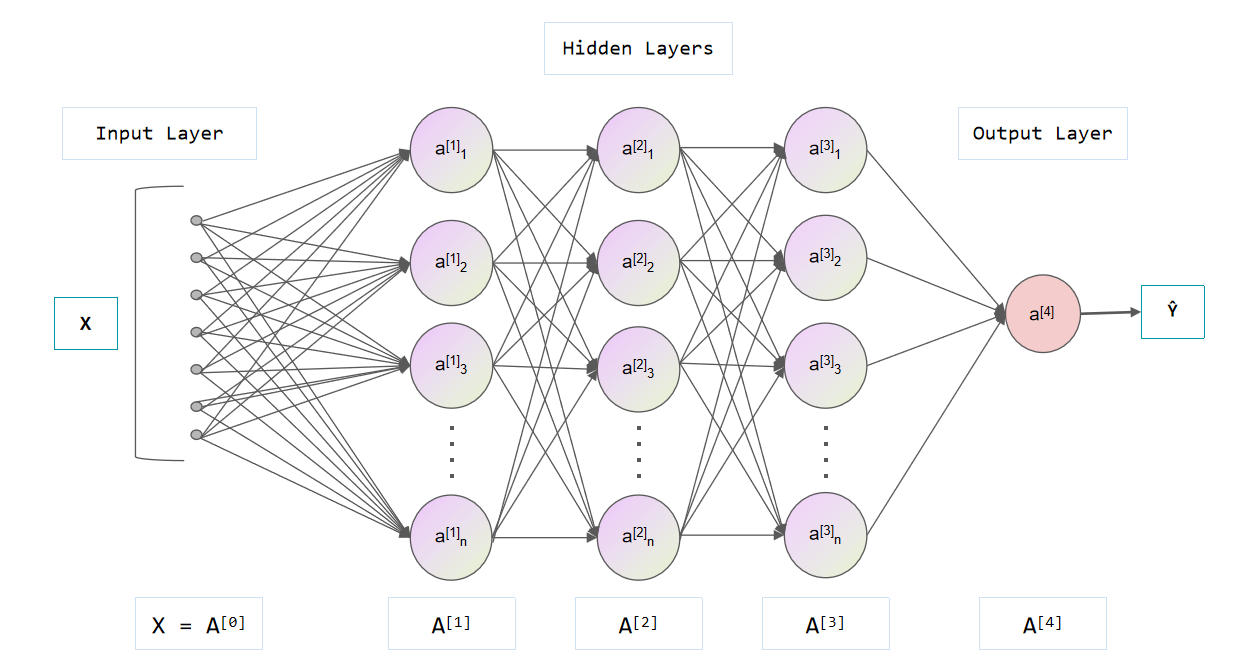
神经元模型
神经网络中的最基本单位,其中沿用至今最为广泛的就是M-P神经元模型。
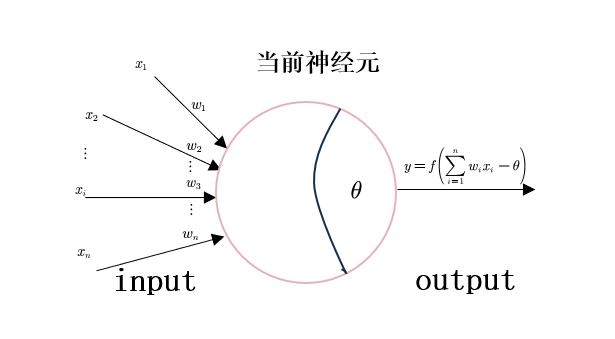
感知机与多层网络
感知机由两层神经元组成,输入层接收外界输入信号后传递给输出层,输出层是M-P神经元,又称"阈值逻辑单元"。
感知机只有输出层神经元进行激活函数处理,学习能力有限,,但事实上,对于线性可分问题,有:
存在一个线性超平面将线性可分模式分开,则感知机学习过程收敛,可以求得最适权向量组。
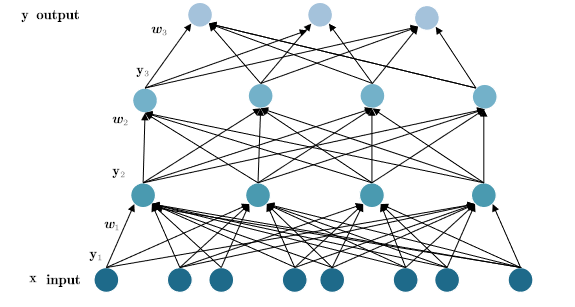
多层前馈神经网络
多层前馈神经网络由输入层、若干隐藏层和输出层组成,各层神经元通过权重连接,信号从输入层单向传递至输出层,层内神经元无连接,层间神经元全连接(或部分连接,如卷积神经网络的局部连接)。
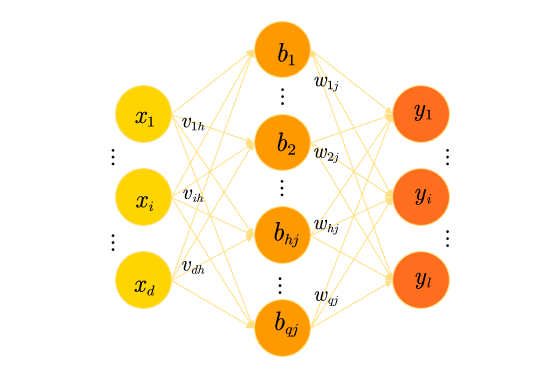
误差逆传播算法
误差逆传播算法(简称 BP 算法)是训练人工神经网络的核心算法,通过高效计算梯度并更新网络参数,使模型能够学习输入与输出之间的映射关系。
其核心思想是“基于梯度下降”策略进行的。
以下图,解释BP算法:
给定数据集合: D = { ( x 1 , y 1 ) , ⋯ , ( x m , y m ) } \mathcal{D}=\{(\boldsymbol{x}_1,\boldsymbol{y}_1),\cdots,(\boldsymbol{x}_m,\boldsymbol{y}_m)\} D={(x1,y1),⋯,(xm,ym)}, x m ∈ R d \boldsymbol{x}_m\in \mathbb{R}^d xm∈Rd, y n ∈ R l \boldsymbol{y}_n\in \mathbb{R}^l yn∈Rl.
参数定义
考虑一个多层前馈神经网络,包含:
- 输入层: d d d 个神经元,接收输入样本 x k ∈ R d \boldsymbol{x}_k \in \mathbb{R}^d xk∈Rd;
- 隐藏层: q q q 个神经元,输出记为 b h b_h bh( h = 1 , 2 , … , q h=1,2,\dots,q h=1,2,…,q);
- 输出层: l l l 个神经元,输出记为 y ^ j k \hat{y}_j^k y^jk( j = 1 , 2 , … , l j=1,2,\dots,l j=1,2,…,l,对应第 k k k 个样本)。
网络参数定义:
- 输入层→隐藏层的连接权: v i h v_{ih} vih(第 i i i 个输入神经元与第 h h h 个隐藏神经元的连接权, i = 1 , … , d i=1,\dots,d i=1,…,d, h = 1 , … , q h=1,\dots,q h=1,…,q);
- 隐藏层→输出层的连接权: w h j w_{hj} whj(第 h h h 个隐藏神经元与第 j j j 个输出神经元的连接权, h = 1 , … , q h=1,\dots,q h=1,…,q, j = 1 , … , l j=1,\dots,l j=1,…,l);
- 隐藏层神经元的阈值: γ h \gamma_h γh( h = 1 , … , q h=1,\dots,q h=1,…,q);
- 输出层神经元的阈值: θ j \theta_j θj( j = 1 , … , l j=1,\dots,l j=1,…,l)。
前向传播
隐藏层第 h h h 个神经元的输入为:
α h = ∑ i = 1 d v i h x i − γ h \alpha_h = \sum_{i=1}^d v_{ih} x_i - \gamma_h αh=i=1∑dvihxi−γh
经过 Sigmoid 激活函数 f ( x ) = 1 1 + e − x f(x) = \frac{1}{1+e^{-x}} f(x)=1+e−x1 后,输出为:
b h = f ( α h ) b_h = f(\alpha_h) bh=f(αh)
输出层第 j j j 个神经元的输入为:
β j = ∑ h = 1 q w h j b h − θ j \beta_j = \sum_{h=1}^q w_{hj} b_h - \theta_j βj=h=1∑qwhjbh−θj
经过 Sigmoid 激活函数后,输出为:
y ^ j k = f ( β j ) \hat{y}_j^k = f(\beta_j) y^jk=f(βj)
均方误差
对第 k k k 个训练样本 ( x k , y k ) (\boldsymbol{x}_k, \boldsymbol{y}_k) (xk,yk),网络的均方误差为:
E k = 1 2 ∑ j = 1 l ( y ^ j k − y j k ) 2 E_k = \frac{1}{2} \sum_{j=1}^l \left( \hat{y}_j^k - y_j^k \right)^2 Ek=21j=1∑l(y^jk−yjk)2
参数调整
BP 算法基于 梯度下降 优化策略,参数更新方向为损失函数的负梯度。对连接权 w h j w_{hj} whj,更新量为:
Δ w h j = − η ∂ E k ∂ w h j \Delta w_{hj} = -\eta \frac{\partial E_k}{\partial w_{hj}} Δwhj=−η∂whj∂Ek
利用 链式法则 分解梯度:
∂ E k ∂ w h j = ∂ E k ∂ y ^ j k ⋅ ∂ y ^ j k ∂ β j ⋅ ∂ β j ∂ w h j \frac{\partial E_k}{\partial w_{hj}} = \frac{\partial E_k}{\partial \hat{y}_j^k} \cdot \frac{\partial \hat{y}_j^k}{\partial \beta_j} \cdot \frac{\partial \beta_j}{\partial w_{hj}} ∂whj∂Ek=∂y^jk∂Ek⋅∂βj∂y^jk⋅∂whj∂βj
步骤1:计算各部分导数
- ∂ E k ∂ y ^ j k \boldsymbol{\dfrac{\partial E_k}{\partial \hat{y}_j^k}} ∂y^jk∂Ek:由式(5.4),直接求导得 y ^ j k − y j k \hat{y}_j^k - y_j^k y^jk−yjk;
- ∂ y ^ j k ∂ β j \boldsymbol{\dfrac{\partial \hat{y}_j^k}{\partial \beta_j}} ∂βj∂y^jk:Sigmoid 函数的导数性质为 f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) f'(x) = f(x)(1-f(x)) f′(x)=f(x)(1−f(x)),结合式(5.3),得 y ^ j k ( 1 − y ^ j k ) \hat{y}_j^k (1 - \hat{y}_j^k) y^jk(1−y^jk);
- ∂ β j ∂ w h j \boldsymbol{\dfrac{\partial \beta_j}{\partial w_{hj}}} ∂whj∂βj:由 β j = ∑ h = 1 q w h j b h − θ j \beta_j = \sum_{h=1}^q w_{hj} b_h - \theta_j βj=∑h=1qwhjbh−θj,直接求导得 b h b_h bh。
步骤2:合并梯度
将上述导数代入,得:
∂ E k ∂ w h j = ( y ^ j k − y j k ) ⋅ y ^ j k ( 1 − y ^ j k ) ⋅ b h \frac{\partial E_k}{\partial w_{hj}} = \left( \hat{y}_j^k - y_j^k \right) \cdot \hat{y}_j^k (1 - \hat{y}_j^k) \cdot b_h ∂whj∂Ek=(y^jk−yjk)⋅y^jk(1−y^jk)⋅bh
令 输出层误差项 g j = − ∂ E k ∂ β j g_j = -\dfrac{\partial E_k}{\partial \beta_j} gj=−∂βj∂Ek(负梯度用于更新),则:
g j = y ^ j k ( 1 − y ^ j k ) ( y j k − y ^ j k ) g_j = \hat{y}_j^k (1 - \hat{y}_j^k) \left( y_j^k - \hat{y}_j^k \right) gj=y^jk(1−y^jk)(yjk−y^jk)
因此, w h j w_{hj} whj 的更新量可简化为:
Δ w h j = η ⋅ g j ⋅ b h \Delta w_{hj} = \eta \cdot g_j \cdot b_h Δwhj=η⋅gj⋅bh
类似地,推导隐藏层误差项 e h e_h eh、阈值和输入层连接权的更新:
隐藏层误差项 e h e_h eh
e h = b h ( 1 − b h ) ∑ j = 1 l w h j g j e_h = b_h (1 - b_h) \sum_{j=1}^l w_{hj} g_j eh=bh(1−bh)j=1∑lwhjgj
输出层阈值 θ j \theta_j θj
Δ θ j = − η ⋅ g j \Delta \theta_j = -\eta \cdot g_j Δθj=−η⋅gj
输入层→隐藏层连接权 v i h v_{ih} vih
Δ v i h = η ⋅ e h ⋅ x i \Delta v_{ih} = \eta \cdot e_h \cdot x_i Δvih=η⋅eh⋅xi
隐藏层阈值 γ h \gamma_h γh
Δ γ h = − η ⋅ e h \Delta \gamma_h = -\eta \cdot e_h Δγh=−η⋅eh
BP算法伪代码

手搓一个简单的BP神经网络模型
import numpy as npdef sigmoid(x):return 1 / (1 + np.exp(-x))def sigmoid_derivative(x):return sigmoid(x) * (1 - sigmoid(x))# BP 算法类
class BPNeuralNetwork:def __init__(self, input_size, hidden_size, output_size, learning_rate=0.1):self.input_size = input_size self.hidden_size = hidden_size self.output_size = output_size self.learning_rate = learning_rate self.v = np.random.uniform(0, 1, (self.input_size, self.hidden_size)) self.w = np.random.uniform(0, 1, (self.hidden_size, self.output_size)) self.gamma = np.random.uniform(0, 1, self.hidden_size) self.theta = np.random.uniform(0, 1, self.output_size) def forward_propagation(self, x):# 计算隐藏层输入 α_h 和输出 b_halpha_h = np.dot(x, self.v) - self.gammab_h = sigmoid(alpha_h)# 计算输出层输入 β_j 和输出 \hat{y}_jbeta_j = np.dot(b_h, self.w) - self.thetay_hat = sigmoid(beta_j)return alpha_h, b_h, beta_j, y_hatdef back_propagation(self, x, y, alpha_h, b_h, beta_j, y_hat):g_j = y_hat * (1 - y_hat) * (y - y_hat)e_h = b_h * (1 - b_h) * np.dot(self.w, g_j)self.w += self.learning_rate * np.dot(b_h.reshape(-1, 1), g_j.reshape(1, -1))self.theta -= self.learning_rate * g_jself.v += self.learning_rate * np.dot(x.reshape(-1, 1), e_h.reshape(1, -1))self.gamma -= self.learning_rate * e_hdef train(self, train_data, train_labels, epochs):for epoch in range(epochs):for x, y in zip(train_data, train_labels):alpha_h, b_h, beta_j, y_hat = self.forward_propagation(x)self.back_propagation(x, y, alpha_h, b_h, beta_j, y_hat)def predict(self, x):_, _, _, y_hat = self.forward_propagation(x)return y_hat# 示例
if __name__ == "__main__":# 假设输入是 2 维(d=2),隐藏层 3 个神经元(q=3),输出 1 维(l=1)input_size = 2hidden_size = 3output_size = 1learning_rate = 0.1epochs = 1000train_data = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])train_labels = np.array([[0], [1], [1], [0]])bp_nn = BPNeuralNetwork(input_size, hidden_size, output_size, learning_rate)bp_nn.train(train_data, train_labels, epochs)test_data = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])for x in test_data:result = bp_nn.predict(x)print(f"输入: {x}, 预测输出: {result}")