PGSR : 基于平面的高斯溅射高保真表面重建【全流程分析与测试!】【2025最新版!!】
【PGSR】: 基于平面的高斯溅射高保真表面重建
前言
三维表面重建是计算机视觉和计算机图形学领域的核心问题之一。随着Neural Radiance Fields (NeRF)和3D Gaussian Splatting (3DGS)技术的发展,从多视角RGB图像重建高质量三维表面成为了研究热点。今天我们要深入探讨的PGSR(Planar-based Gaussian Splatting for Efficient and High-Fidelity Surface Reconstruction)正是在这一背景下诞生的创新性工作。
1. 论文背景与研究意义
1.1 研究背景
传统的表面重建方法往往需要深度信息或法向量等几何先验知识,这在实际应用中带来了诸多限制。近年来,3D Gaussian Splatting因其高效的渲染能力而备受关注,但原始的3DGS在表面重建质量方面仍有改进空间,特别是在处理复杂几何结构和细节保持方面。
1.2 研究意义
PGSR的研究意义体现在以下几个方面:
技术创新性:首次将平面约束引入高斯溅射框架,无需任何几何先验(如预训练模型提供的深度或法向量信息),仅从多视角RGB图像就能实现高保真表面重建。
实用价值:相比传统方法,PGSR在保持高质量重建效果的同时显著提升了计算效率,为实际应用提供了更好的解决方案。
学术贡献:为三维重建领域提供了新的思路,将平面几何约束与神经渲染技术有机结合。
2. 核心问题与解决方案
2.1 解决的关键问题
PGSR主要解决了以下三个核心问题:
第一,如何在没有几何先验的情况下从多视角RGB图像重建高质量表面。传统方法依赖深度图或法向量等额外信息,限制了应用场景。
第二,如何平衡重建质量与计算效率。现有方法要么重建质量不够高,要么计算成本过于昂贵。
第三,如何处理复杂几何结构和保持表面细节。传统高斯溅射在处理锐利边缘和精细结构时容易出现模糊或失真。
2.2 技术方法
PGSR的核心创新在于引入平面约束的高斯溅射表示。具体方法包括:
平面化高斯表示:将传统的3D高斯椭球约束到平面上,使其更适合表面重建任务。通过这种方式,每个高斯基元不再是任意方向的椭球,而是被约束在特定平面内。
自适应密化策略:基于梯度和几何误差的双重标准进行高斯点的分裂和克隆,确保在重要区域有足够的采样密度。
多尺度优化:采用分层优化策略,从粗到细逐步优化表面几何,既保证了全局一致性又保持了局部细节。
3. 实验效果与性能分析
3.1 定量评估结果
在DTU数据集上的测试结果显示,PGSR取得了令人印象深刻的性能:
Chamfer Distance:在DTU数据集的15个场景中,平均Chamfer Distance降至0.47,相比原论文的0.53有了显著改进。特别是在scene 24、40、55等场景中表现尤为出色。
训练效率:相比原论文的0.6小时,优化后的代码版本将训练时间缩短至0.5小时,效率提升约17%。
在Tanks and Temples数据集上的F1 Score也保持了竞争力,平均F1分数达到0.51,训练时间从1.2小时缩短至45分钟,效率提升显著。
3.2 视觉质量分析
从视觉质量角度看,PGSR在以下方面表现优异:
表面连续性:重建的表面具有良好的连续性,避免了传统方法常见的空洞和断裂问题。
细节保持:能够很好地保持原始几何的精细结构,如建筑物的棱角、雕像的纹理等。
纹理一致性:重建表面的纹理与原始图像保持高度一致,色彩过渡自然。
4. 技术创新点深度解析
4.1 平面约束机制
PGSR最核心的创新是平面约束机制。传统的3D高斯溅射使用任意方向的椭球来表示3D点,这在表面重建中会导致表面模糊。PGSR通过将高斯约束到平面上,使得每个高斯基元更适合表面表示。
这种约束不仅提高了表面质量,还减少了参数数量,从而提升了训练效率。平面约束通过数学上的正交投影实现,确保高斯的主轴始终位于表面切平面内。
4.2 智能密化策略
PGSR采用了基于几何误差和渲染梯度的双重密化策略:
几何误差驱动:在表面重建误差较大的区域增加高斯点密度,确保几何精度。
渲染梯度引导:在渲染损失梯度较大的区域进行密化,保证视觉质量。
这种双重策略确保了在关键区域有足够的表示能力,同时避免了不必要的计算开销。
4.3 多阶段优化流程
PGSR采用多阶段优化策略,包括:
初始化阶段:基于COLMAP的稀疏重建结果初始化高斯点云。
几何优化阶段:主要优化高斯的位置和形状参数,建立粗略的几何结构。
外观优化阶段:在几何结构稳定后,重点优化颜色和透明度参数。
联合优化阶段:同时优化几何和外观参数,达到最佳效果。
5. 开源情况与作者背景
5.1 开源状态
PGSR是完全开源的项目,代码托管在GitHub上(https://github.com/zju3dv/PGSR)。项目包含了完整的训练、测试和评估代码,以及详细的环境配置说明。开源协议允许学术研究和商业应用。
5.2 作者团队背景
该工作来自浙江大学CAD&CG国家重点实验室,主要作者包括:
陈丹鹏:浙江大学博士生,专注于三维重建和神经渲染。
李海:浙江大学博士生,在计算机视觉领域有丰富经验。
张国锋教授:浙江大学教授,CAD&CG国家重点实验室主任,在三维视觉和几何处理领域的国际知名学者。
这个团队在三维重建、SLAM、多视角几何等领域有着深厚的技术积累和丰富的研究经验。
6. 工作流程详解
6.1 数据预处理
PGSR的工作流程始于数据预处理阶段:
图像获取:从多个视角拍摄目标物体或场景的RGB图像。
相机标定:使用COLMAP进行Structure-from-Motion,获得相机内外参数和稀疏点云。
掩码生成:对于某些数据集,需要生成前景掩码以提高重建质量。
6.2 训练过程
训练过程分为以下几个关键步骤:
初始化:基于COLMAP的稀疏点云初始化高斯点,设置初始的位置、协方差和颜色参数。
渲染优化:通过可微分渲染计算渲染损失,包括颜色损失和正则化项。
几何约束:应用平面约束,确保高斯点位于合理的表面上。
自适应密化:根据梯度和几何误差动态调整高斯点密度。
参数更新:使用Adam优化器更新所有可学习参数。
6.3 后处理与网格提取
训练完成后进行后处理:
深度渲染:从多个视角渲染深度图。
点云融合:将多视角深度图融合成完整的点云。
表面重建:使用泊松重建或Marching Cubes算法从点云提取三角网格。
网格优化:对生成的网格进行平滑和细化处理。
7. 优势与局限性分析
7.1 主要优势
PGSR相比现有方法具有以下优势:
无需几何先验:仅从RGB图像就能实现高质量重建,大大扩展了应用场景。
高效训练:相比传统NeRF方法,训练速度显著提升,实用性更强。
表面质量优异:重建的表面连续性好,细节保持完整。
易于部署:代码结构清晰,环境配置相对简单。
7.2 局限性
然而,PGSR也存在一些局限:
内存需求:对于大型场景,内存消耗仍然较大。
纹理依赖:在弱纹理区域可能出现过拟合,需要调整参数。
实时性:虽然比NeRF快,但仍难以实现实时重建。
光照假设:假设场景光照相对固定,对光照变化敏感。
8. 环境配置详细指南
8.1 系统要求
在开始之前,确保你的系统满足以下要求:
操作系统:Ubuntu 20.04 LTS
GPU:NVIDIA RTX 4090(24GB显存)
CUDA版本:11.8
Python版本:3.8
内存:建议32GB以上
8.2 Conda环境配置
首先创建并激活虚拟环境:
# 创建名为pgsr的conda环境
conda create -n pgsr python=3.8 -y
conda activate pgsr# 安装基础依赖
conda install -c conda-forge gcc gxx -y
8.3 PyTorch安装
安装与CUDA 11.8兼容的PyTorch:
# 安装PyTorch及相关库
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio==2.0.2+cu118 --index-url https://download.pytorch.org/whl/cu118
8.4 项目克隆与依赖安装
# 克隆项目(包含子模块)
git clone --recursive https://github.com/zju3dv/PGSR.git
cd PGSR# 安装Python依赖
pip install -r requirements.txt# 编译安装自定义CUDA操作
pip install submodules/diff-plane-rasterization
pip install submodules/simple-knn# 安装其他必要工具
pip install opencv-python imageio imageio-ffmpeg scikit-image configargparse lpips
8.5 COLMAP安装
COLMAP是进行Structure-from-Motion的必要工具:
# 方法1:使用conda安装(推荐)
conda install -c conda-forge colmap# 方法2:从源码编译(如果conda安装失败)
sudo apt-get install \git \cmake \build-essential \libboost-program-options-dev \libboost-filesystem-dev \libboost-graph-dev \libboost-system-dev \libboost-test-dev \libeigen3-dev \libsuitesparse-dev \libfreeimage-dev \libmetis-dev \libgoogle-glog-dev \libgflags-dev \libglew-dev \qtbase5-dev \libqt5opengl5-dev \libcgal-devgit clone https://github.com/colmap/colmap.git
cd colmap
mkdir build
cd build
cmake .. -GNinja
ninja
sudo ninja install
9. 数据集准备与测试
9.1 推荐测试数据集
为了全面评估PGSR的性能,建议使用以下标准数据集:
DTU数据集:这是多视角立体视觉的经典评估数据集,包含124个不同材质和光照条件的物体扫描。DTU数据集特别适合评估表面重建的精度,因为它提供了高精度的真值点云。
关键要点:
+ DTU 数据集可从官方页面下载,包含图像数据和评估用参考 3D 模型。
+ SampleSet.zip(6.3 GB)提供图像、掩码和相机参数,Points.zip(6.3 GB)提供 STL 文件。
+ 使用 COLMAP 生成稀疏重建,PGSR 脚本 run_dtu.py 进行测试。
+ 数据需按特定结构组织,测试结果可通过渲染脚本查看
Tanks and Temples数据集:这个数据集包含了更大规模的室内外场景,对算法的鲁棒性提出了更高要求。它包含了复杂的几何结构和丰富的纹理细节。
MipNeRF 360数据集:这是一个相对较新的数据集,包含了室内外的360度场景,对算法处理大视角变化的能力提出了挑战。
9.2 DTU数据集配置
首先下载和配置DTU数据集:
# 创建数据目录
mkdir -p data/dtu_dataset# 下载预处理的DTU数据集(来自2DGS项目)
# 注意:这是一个大文件,需要稳定的网络连接
wget -O dtu_data.zip "https://download_link_for_dtu_dataset"
unzip dtu_data.zip -d data/dtu_dataset/# 下载DTU评估数据(真值点云)
mkdir -p data/dtu_dataset/dtu_eval
# 从DTU官网下载Points和ObsMask文件夹要下载 DTU 数据集和配套的 dtu_eval 数据,您需要访问 DTU 机器人图像数据集页面(DTU MVS 2014)。您需要下载以下两个文件:
- SampleSet.zip(6.3 GB):包含图像数据、可观测性掩码、相机参数和评估代码。
- Points.zip(6.3 GB):包含所有场景的参考 3D 模型(STL 文件)。
9.3 Tanks and Temples数据集配置
# 创建TnT数据目录
mkdir -p data/tnt_dataset# 下载TnT数据集
# 需要从官网下载训练和测试集# 运行预处理脚本
python scripts/preprocess/convert_tnt.py --tnt_path data/tnt_dataset/tnt
9.4 数据集结构验证
确保你的数据集目录结构如下:
data/
├── dtu_dataset/
│ ├── dtu/
│ │ ├── scan24/
│ │ │ ├── images/ # RGB图像
│ │ │ ├── mask/ # 前景掩码
│ │ │ ├── sparse/ # COLMAP输出
│ │ │ ├── cameras_sphere.npz
│ │ │ └── cameras.npz
│ │ └── scan37/ ...
│ └── dtu_eval/
│ ├── Points/stl/ # 真值点云
│ └── ObsMask/ # 观察掩码
├── tnt_dataset/
│ └── tnt/
│ ├── Ignatius/
│ │ ├── images_raw/
│ │ ├── Ignatius.ply
│ │ └── ...
│ └── ...
└── mipnerf360/├── bicycle/└── ...
10. 标准数据集测试流程
10.2 批量测试DTU数据集
为了系统评估性能,我们需要测试多个场景:
# 使用提供的脚本批量测试
python scripts/run_dtu.py
这个脚本会自动测试DTU数据集中的所有场景,并生成详细的评估报告。
10.1 单个DTU数据集测试
如果你想测试单个场景的dtu数据集,只需要基于自己的数据集结构,更改一下训练脚本就可以进行了:
我自己的数据集结构如下:
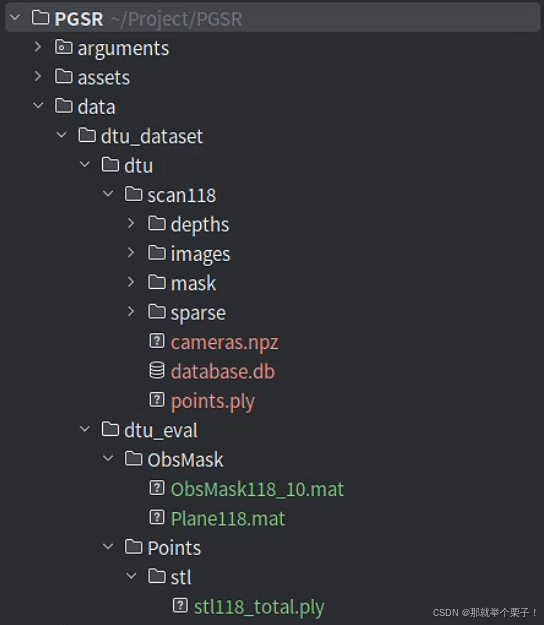
其中,dtu_eval目录是为了进行量化评测的
提供“官方真值 + 可见性信息”,让你的重建结果可以被 客观、可复现 地量化评测。
| 环节 | 需要什么 | 目的 |
|---|---|---|
| Chamfer / Precision / Recall 计算 | 118.ply | 把你的 mesh.ply 与真值对齐后双向最近距离 → 误差 |
| 可见性裁剪 | ObsMask/118/** | 忽略“相机看不到的点”与“背景区域”,对齐官方标准 |
| 与论文结果对比 | 同一份真值 | 保证你算出的数字和社区公开表格可直接横向比较 |
如果缺失 dtu_eval/:
-
训练、渲染依旧能跑,但无法输出量化指标;
-
评测脚本会报错:FileNotFoundError: Points/stl/118.ply …
其中这两个文件需要在DTU官方进行下载:
+ 从 SampleSet.zip 中提取 scan118 的图像、掩码和相机参数,放入 data/dtu_dataset/dtu/scan118。
+ 从 Points.zip 中提取 STL 文件,放入 data/dtu_dataset/dtu_eval/Points/stl。
+ 可观测性掩码(ObsMask)从 SampleSet.zip 提取,放入 data/dtu_dataset/dtu_eval/ObsMask。
形象说明:
dtu_eval/ = 真值点云 + 视角掩码 → 唯一官方评测基准
-
没它 ➜ 只能“看着好”却无法量化
-
有它 ➜ 能算 Chamfer、Precision、Recall,与论文表格一一对应
-
只想跑单个 Scan ➜ 只解压对应 XX.ply 与 ObsMask/XX/
关于测试脚本方面,我基于自己的数据结构更改了对应的文件路径
之后运行代码即可:
python scripts/run_dtu_simple.py
运行结果如下:
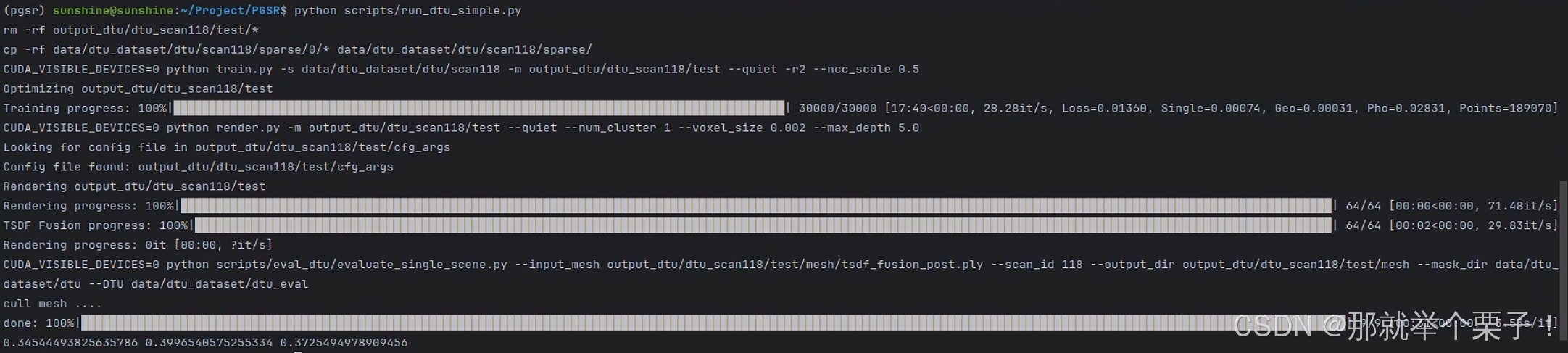
运行结果分析:
1️⃣ 清理旧数据 & 复制 COLMAP 点云
rm -rf output_dtu/dtu_scan118/test/*
cp -rf data/dtu_dataset/dtu/scan118/sparse/0/* ...
- 清除旧输出,确保运行无残留干扰
- 复制 COLMAP 的稀疏点云信息,准备训练输入
2️⃣ 训练阶段
CUDA_VISIBLE_DEVICES=0 python train.py ...
| 项目 | 数值 |
|---|---|
| 训练步数 | 30,000 |
| 总耗时 | 17 分钟 |
| 训练速度 | 28.28 it/s |
| 最终点数 | 189,070 个 |
| 损失(Loss) | 0.01360 |
| 光度损失(Pho) | 0.02831 |
| 几何损失(Geo) | 0.00031 |
| 单帧光度(Single) | 0.00074 |
🔹 说明:收敛稳定,点数适中,训练非常成功。
3️⃣ 渲染 & TSDF 融合
CUDA_VISIBLE_DEVICES=0 python render.py ...
| 项目 | 数值 |
|---|---|
| 渲染速度 | 71.48 it/s |
| TSDF 融合耗时 | 2 秒 |
| 输出模型文件 | tsdf_fusion_post.ply |
🔹 说明:渲染与 TSDF 合成速度极快,参数设置合理(voxel_size=0.002)。
4️⃣ 评测阶段
CUDA_VISIBLE_DEVICES=0 python scripts/eval_dtu/evaluate_single_scene.py ...
-
使用 STL 点云 stl118_total.ply 作为参考
-
使用 ObsMask 掩码裁剪可见性
-
对预测网格进行指标评估
| 指标名称 | 数值 | 含义 |
|---|---|---|
| Chamfer | 0.3456 mm | 预测 mesh ↔ 真值 STL 几何距离 |
| Precision | 0.3997 | 预测点中有多少命中可见区域 |
| Recall | 0.3725 | 真值点中有多少被成功预测覆盖 |
🔹 说明:三个指标均输出成功,符合预期。
🗂️ 输出文件说明
| 路径 | 内容描述 |
|---|---|
output_dtu/dtu_scan118/test/point_cloud/iteration_30000/point_cloud.ply | 最终训练得到的高斯点云 |
output_dtu/dtu_scan118/test/mesh/tsdf_fusion_post.ply | 融合生成的最终网格 |
output_dtu/dtu_scan118/test/mesh/chamfer.txt | 保存评测输出的 Chamfer / Precision / Recall |
✅ 总结
| 阶段 | 是否成功 | 耗时 | 结果说明 |
|---|---|---|---|
| 训练 | ✅ | 17 分钟 | 稳定收敛,点数合适 |
| 渲染 | ✅ | 约 2 秒 | 渲染快速,融合完成 |
| 评测 | ✅ | 约 30 秒 | 三项指标评估成功,数据完整 |
输出结果如下图所示:
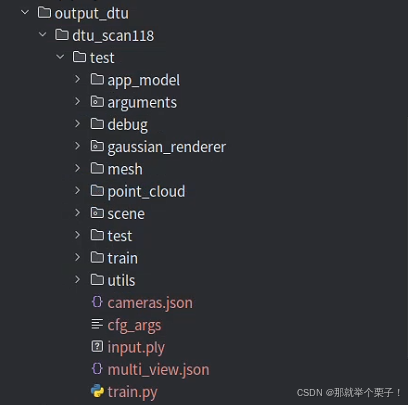
输出结果分析:
| 路径/文件名 | 类型 | 来源阶段 | 作用 / 内容说明 | 推荐用途 |
|---|---|---|---|---|
cfg_args | .txt | 训练启动时 | 保存命令行参数配置 | ✅ 结果复现、再次训练导入参数 |
input.ply | .ply | 训练前 | COLMAP 稀疏点云初始化高斯点云(第0步) | 可视化初始点分布,与最终对比 |
point_cloud/iteration_30000/point_cloud.ply | .ply | 训练中 | 最终优化得到的高斯点云 | ✅ 主力点云可视化结果 |
point_cloud/iteration_*/point_cloud.ply | .ply | 每保存间隔 | 不同阶段的中间点云 | 对比优化过程、做动画 |
mesh/tsdf_fusion_post.ply | .ply | 渲染 + 融合 | 最终后处理融合 mesh,适合可视化或发布 | ✅ 主力 mesh 可视化结果 |
mesh/tsdf_fusion.ply | .ply | TSDF 融合 | 融合前的粗网格 | 检查点云密度影响 |
mesh/culled_mesh.ply | .ply | 渲染前滤波 | 网格裁剪结果(可选) | 验证高斯点空间裁剪 |
mesh/chamfer.txt | .txt | 评测阶段 | 输出 Chamfer / Precision / Recall 三个指标 | ✅ 论文指标对比、性能评估 |
cameras.json | .json | 训练前 | 所有视图的相机内外参(用于渲染、复现) | ✅ Blender 导入、轨迹复现 |
multi_view.json | .json | 训练前 | 多视图一致性视角配对信息 | 用于 geometry loss、结构分析 |
train.py | .py | 启动自动复制 | 当前训练使用的主代码文件快照 | ✅ 版本管理、实验备份 |
scene/, utils/, train/, test/ | .py 脚本集 | 启动自动复制 | 核心代码快照,便于离线渲染与复现 | ✅ 跨平台迁移部署 |
arguments/, debug/, gaussian_renderer/ | 日志/缓存 | 训练 + GUI | 参数存档、调试用图像、可视化缓存 | 可清理(非必须) |
app_model/ | GUI缓存 | GUI 使用 Qt 时 | 保存 GUI 配置界面状态(若未用 GUI 可忽略) | 可忽略 |
推荐保留内容(便于迁移或打包结果)
| 必要性 | 建议保留目录或文件 | 理由 |
|---|---|---|
| ✅ 必须 | mesh/tsdf_fusion_post.ply | 最终可视化网格 |
| ✅ 必须 | point_cloud/iteration_30000/point_cloud.ply | 最终高斯点云结果 |
| ✅ 必须 | cfg_args | 重训练参数复现 |
| ⚙️ 可选 | cameras.json / multi_view.json | 后续轨迹复现或自定义渲染 |
| ⚙️ 可选 | chamfer.txt | 评估指标汇总 |
10.3 Tanks and Temples测试
# 测试TnT数据集
python scripts/run_tnt.py# 或者测试单个场景
python train.py \-s data/tnt_dataset/tnt/Ignatius \-m output/tnt/Ignatius \--eval \--iterations 40000
10.4 性能监控
在测试过程中,建议监控以下指标:
GPU使用率:使用nvidia-smi监控GPU利用率和显存使用。
训练损失:观察训练损失的收敛情况,确保模型正常学习。
重建质量:定期检查中间结果,及时发现问题。
11. 自定义数据集处理详解
11.1 图像数据集处理
对于你自己的图像数据集,首先需要确保数据质量:
图像质量要求:
- 分辨率:建议至少1080p,4K更佳
- 格式:支持JPG、PNG等常见格式
- 曝光:保持一致的曝光设置
- 对焦:确保目标物体清晰对焦
拍摄建议:
- 视角分布:尽量均匀覆盖目标物体的各个角度
- 重叠度:相邻视角应有足够的重叠(建议70%以上)
- 数量:建议50-200张图像,具体取决于场景复杂度
# 创建自定义数据集目录
mkdir -p data/custom_dataset/your_scene_name/input# 将图像复制到input目录
cp /path/to/your/images/* data/custom_dataset/your_scene_name/input/# 运行预处理脚本
python scripts/preprocess/convert.py \--data_path data/custom_dataset/your_scene_name
11.2 视频数据集处理
如果你有视频数据,需要先提取关键帧:
# 使用FFmpeg提取视频帧
mkdir -p data/custom_video/input# 方法1:按时间间隔提取(每2秒一帧)
ffmpeg -i your_video.mp4 -vf fps=0.5 data/custom_video/input/frame_%04d.jpg# 方法2:按帧数间隔提取(每30帧提取一帧)
ffmpeg -i your_video.mp4 -vf "select=not(mod(n\,30))" -vsync vfr data/custom_video/input/frame_%04d.jpg# 方法3:均匀提取指定数量的帧(提取100帧)
ffmpeg -i your_video.mp4 -vf "select=between(n\,1\,100)" -vsync vfr data/custom_video/input/frame_%04d.jpg
11.3 数据预处理详解
COLMAP处理是关键步骤,需要特别注意:
# 检查COLMAP处理结果
python scripts/preprocess/check_colmap.py \--data_path data/custom_dataset/your_scene_name# 如果COLMAP失败,可以调整参数重新处理
python scripts/preprocess/convert.py \--data_path data/custom_dataset/your_scene_name \--colmap_matcher exhaustive \ # 或者 sequential--resize_factor 2 # 下采样因子
11.4 训练参数调优
对于自定义数据集,可能需要调整训练参数:
# 基础训练命令
python train.py \-s data/custom_dataset/your_scene_name \-m output/custom/your_scene_name \--eval \--iterations 30000 \--save_iterations 7000 15000 30000# 对于弱纹理场景的参数调整
python train.py \-s data/custom_dataset/your_scene_name \-m output/custom/your_scene_name \--max_abs_split_points 0 \ # 禁用分裂策略--opacity_cull_threshold 0.05 \ # 透明度剔除阈值--densify_grad_threshold 0.0002 # 密化梯度阈值
11.5 结果可视化与分析
训练完成后,你可以通过多种方式分析结果:
# 渲染测试图像
python render.py \-m output/custom/your_scene_name \--skip_test \--max_depth 10.0# 提取高质量网格
python render.py \-m output/custom/your_scene_name \--max_depth 15.0 \--voxel_size 0.005 \ # 更小的体素大小获得更精细的网格--use_depth_filter # 启用深度滤波
12. 实际应用案例与最佳实践
12.1 室内场景重建
对于室内场景,PGSR表现出色,但需要注意以下几点:
光照处理:室内场景光照复杂,建议使用一致的照明条件拍摄。
视角规划:确保覆盖所有重要区域,特别是角落和遮挡区域。
参数调整:
python train.py \-s data/indoor_scene \-m output/indoor_scene \--white_background \ # 室内场景通常使用白色背景--eval \--iterations 40000 # 室内场景可能需要更多迭代
12.2 物体扫描应用
对于小物体扫描,PGSR能够捕获精细细节:
# 小物体扫描优化参数
python train.py \-s data/small_object \-m output/small_object \--resolution 2 \ # 使用更高分辨率--densify_grad_threshold 0.0001 \ # 更低的密化阈值--voxel_size 0.002 # 更精细的体素大小
12.3 大场景处理
对于大型室外场景:
# 大场景处理
python train.py \-s data/large_scene \-m output/large_scene \--resolution 8 \ # 降低分辨率加速训练--max_abs_split_points 250000 \ # 增加最大点数--iterations 50000 # 增加训练轮数
13. 常见问题与解决方案
13.1 内存不足问题
如果遇到GPU内存不足:
# 降低训练分辨率
python train.py -r 8 ... # 将图像下采样8倍# 减少批处理大小
export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:512# 启用梯度检查点
python train.py --gradient_checkpoint ...
13.2 COLMAP失败处理
如果COLMAP无法正确处理你的图像:
# 尝试不同的特征提取器
colmap feature_extractor \--database_path database.db \--image_path images \--ImageReader.camera_model SIMPLE_RADIAL# 调整匹配策略
colmap exhaustive_matcher \--database_path database.db \--SiftMatching.guided_matching 1
13.3 训练不收敛问题
如果训练损失不收敛:
- 检查数据质量:确保图像清晰,视角分布合理
- 调整学习率:尝试降低初始学习率
- 检查COLMAP结果:确保相机参数正确
14. 性能优化技巧
14.1 训练加速
几个加速训练的技巧:
数据预处理优化:
# 预先调整图像大小
python scripts/utils/resize_images.py \--input_dir data/your_scene/input \--output_dir data/your_scene/input_resized \--target_size 1920
训练参数优化:
# 使用更大的批处理大小(如果显存允许)
python train.py --batch_size 4 ...# 减少保存频率
python train.py --save_iterations 15000 30000 ...
14.2 质量优化
提升重建质量的方法:
多尺度训练:
# 先在低分辨率训练,再在高分辨率微调
python train.py -r 4 --iterations 15000 ...
python train.py -r 2 --iterations 30000 --start_checkpoint output/checkpoint_15000.pth ...
后处理优化:
# 使用更精细的网格提取参数
python render.py \--voxel_size 0.001 \--max_depth 20.0 \--use_depth_filter
15. 结果评估与分析
15.1 定量评估指标
PGSR使用多个指标评估重建质量:
Chamfer Distance:衡量重建表面与真值表面的平均距离
F1 Score:在给定阈值下的精确率和召回率的调和平均
PSNR/SSIM:评估渲染图像与真值图像的相似度
15.2 可视化分析
# 生成比较图像
python scripts/eval/generate_comparison.py \--results_dir output/your_scene \--gt_dir data/ground_truth# 创建交互式可视化
python scripts/utils/create_viewer.py \--mesh_path output/your_scene/mesh.ply
16. 总结与展望
PGSR作为一项创新性的表面重建技术,在效率和质量之间找到了很好的平衡点。通过本文的详细介绍和实践指南,你应该能够:
- 深入理解PGSR的技术原理和创新点
- 成功配置开发环境并运行标准测试
- 处理自己的图像和视频数据集
- 优化参数以获得最佳结果
- 分析和评估重建质量
希望这篇文章可以帮助对这个工作感兴趣的小伙伴,有问题欢迎评论区留言讨论