non-autoregressive sequence generation
非自回归non-autoregressive
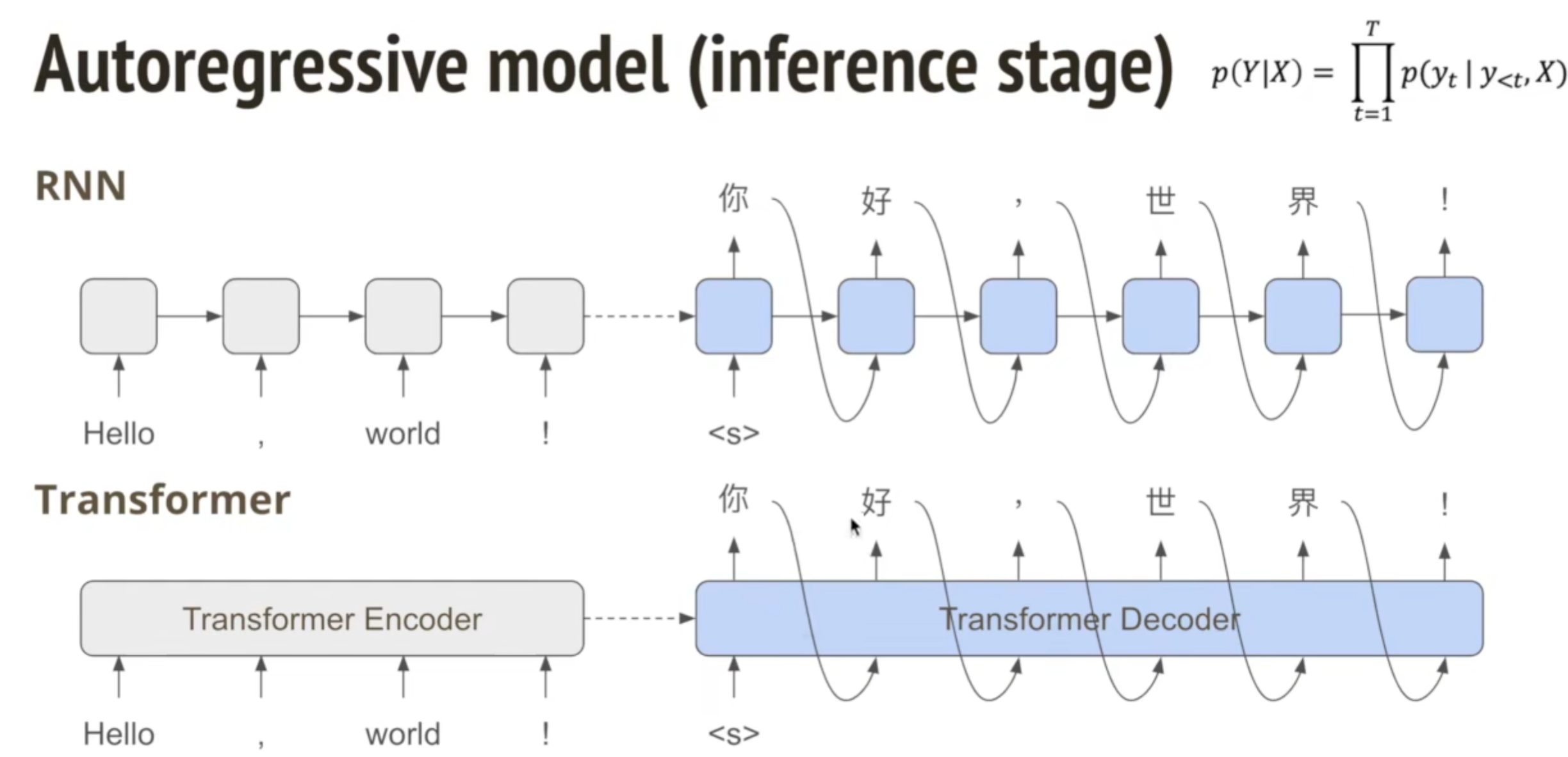
传统rnn是autoregressive,而且encode和decode都是根据上一个input/output,这样花费的时间就和句子长度成正比
transformer的输入是并行的,但是decode阶段还是autoregressive
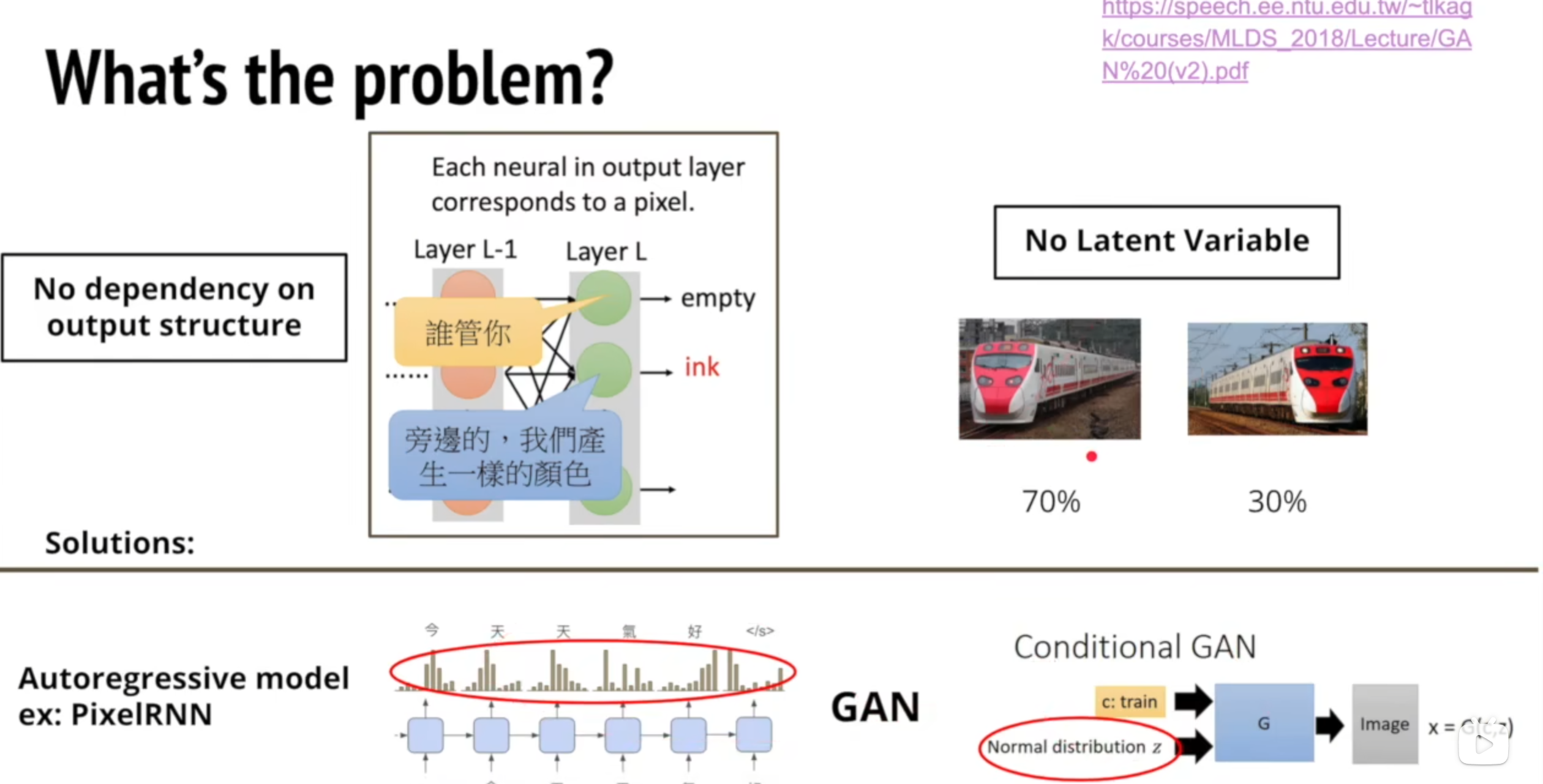
单纯把影像当成 N×M 个独立像素去拟合,会缺乏像素之间的依赖,也无法产生多样化样本,就是普通的network无法学到多样化样本和像素间的依赖;要解决这两个痛点,可以选择自回归模型(PixelRNN/PixelCNN 等)或含潜在变量的生成模型(GAN、VAE 等)
非自回归序列生成(Non-Autoregressive Sequence Generation, NAT)学习笔记
一、概念简介
1.1 自回归(Autoregressive, AR)模型
-
Autoregressive(自回归):每一个输出依赖于前一个输出
-
每一步的生成依赖前一个 token:$y_t \sim P(y_t | y_1, y_2, ..., y_{t-1})$
-
无法并行解码,推理慢
-
示例:Transformer、GPT
1.2 非自回归(Non-Autoregressive, NAT)模型
-
所有 token 可并行生成:$P(y_1, y_2, ..., y_T | x) = \prod_{t=1}^T P(y_t | x)$
-
加速明显,特别适合部署
1.3 应用场景
-
机器翻译
-
图像字幕生成
-
语音识别
二、核心挑战
2.1 多模态问题(Multi-Modality Problem)
-
多模态:同一输入可能对应多个输出选项
-
一个输入可能对应多个正确输出(如“Hello”→“你好”/“哈囉”)
-
没有前后依赖的信息,容易平均化,输出模糊或不自然
-
一个输入可能对应多个正确输出(如“Hello”→“你好”/“哈囉”)
-
没有前后依赖的信息,容易平均化,输出模糊或不自然
2.2 序列长度预测
-
输出序列长度不固定,NAT需先预测长度或通过对齐机制辅助
三、经典模型方法
3.1 Vanilla NAT (Gu et al., ICLR 2018)
-
通过“Fertility”机制预测每个输入token应复制多少次
-
Fertility(表示每个输入 token 应生成多少个输出 token)标签可由外部对齐工具生成(如 fast_align)
-
优化:使用 REINFORCE 微调 Fertility 预测器
3.2 Knowledge Distillation(知识蒸馏)
-
使用AR模型生成训练目标
-
Student NAT 模仿 Teacher AR 的输出,减少模态不确定性
3.3 Noisy Parallel Decoding (NPD,噪声并行解码)
-
多次采样Fertility→生成多个候选→用AR模型评分→选最优
四、进阶模型演化
4.1 Iterative Refinement (iNAT,迭代式精化)
-
初始粗生成 + 多次 mask 再预测
-
Mask-Predict(Ghazvininejad et al., 2019)
-
每轮mask最不确定的token,迭代优化
4.2 Insertion-Based NAT(基于插入的非自回归模型)
-
每次预测插入新词,直到完整句子
-
Insertion Transformer(Stern et al., 2019)
-
KERMIT(Chan et al., 2019)可同时建模 P(x), P(y), P(x|y), P(y|x)
4.3 Edit-Based NAT:Levenshtein Transformer(基于编辑的非自回归模型)
-
模仿编辑距离算法:插入+删除实现序列变换
-
用 imitation learning 学习插入、删除策略
4.4 CTC-Based NAT
-
CTC(连接时序分类,Connectionist Temporal Classification)是一种适用于对齐不明确的序列建模方法 使用 CTC (Connectionist Temporal Classification) 解码
-
适用于语音等序列对齐明确的任务
-
代表作:E2E NAT with CTC(Libovický et al., 2018)
4.5 Imputer(补全器模型,Chan et al., 2020)
-
融合 Mask-Predict 和 CTC
-
先使用 ConvNet 提取特征,再通过多轮 mask 完善序列
五、效果评估
| 模型 | 速度 | 准确度 | 优势 | 代表作 |
|---|---|---|---|---|
| AR Transformer | 慢 | 高 | 准确 | Vaswani et al. 2017 |
| Vanilla NAT | 快 | 较低 | 并行生成 | Gu et al., 2018 |
| Mask-Predict | 中等 | 中高 | 精细迭代 | Ghazvininejad et al. 2019 |
| LevT | 中等 | 中高 | 插删灵活 | Gu et al., 2019 |
| CTC NAT | 快 | 中等 | 对齐明确 | Libovický et al., 2018 |
六、总结与思考
6.1 优点
-
并行生成,加速显著
-
适合实时任务,如翻译、语音识别
6.2 缺点
-
输出精度略逊
-
多模态问题难解
6.3 提升方向
-
蒸馏技术+多阶段精化
-
插入/编辑策略更拟人
-
引入显式语义控制机制
七、参考论文
-
Gu et al., 2018 - Vanilla NAT
-
Ghazvininejad et al., 2019 - Mask-Predict
-
Gu et al., 2019 - Levenshtein Transformer
-
Stern et al., 2019 - Insertion Transformer
-
Chan et al., 2020 - Imputer
-
Libovický et al., 2018 - CTC NAT
非自回归序列生成(NAT)讲解
以下是基于《Non-Autoregressive Sequence Generation》文档内容,对非自回归序列生成(NAT)的原理和应用的详细讲解,数学公式以可读形式呈现,旨在帮助您深刻理解。
1. 序列生成简介
序列生成是指根据输入条件 x,生成输出序列 y = (y₁, y₂, ..., yₜ)。常见任务包括:
- 机器翻译:将一种语言翻译为另一种语言(如英文到德文)。
- 图像描述生成:为图像生成文本描述(如“一个女人在公园里扔飞盘”)。
- 文本到图像生成:根据文本生成图像(如“一只狗在跑”)。
传统方法使用自回归模型(AR),其概率分布为:
p(y | x) = ∏t=1T p(yₜ | y<t, x)
每个标记 yₜ 依赖于之前标记 y<t 和输入 x。自回归模型(如RNN、Transformer)通过注意力机制捕捉依赖关系,但因顺序生成,推理速度较慢。
2. 非自回归序列生成(NAT)
NAT通过并行生成所有标记来加速推理,其概率分布为:
p(y | x) = ∏t=1T p(yₜ | x)
每个标记 yₜ 仅依赖输入 x,不依赖之前标记 y<t,实现一步或少量步骤生成。
主要特点
- 并行解码:所有标记同时生成,推理速度远超AR模型。
- 独立性假设:假设标记在给定输入下条件独立,简化计算但可能影响连贯性。
- 基于Transformer:利用Transformer的注意力机制建模复杂关系。
3. NAT的挑战
NAT在保持输出质量方面面临以下挑战:
- 依赖关系建模:
- AR模型通过顺序生成捕捉标记间依赖(如句子语法)。
- NAT的独立性假设可能导致:
- 输出不连贯:生成语法或语义不连贯的序列。
- 重复或不一致:如文本到图像生成中,输出可能是多种描述的“平均”(文档第7页)。
- 输出结构:
- 在图像生成中,传统方法将输出神经元映射到像素,忽略结构依赖(文档第8页)。
- 在文本生成中,NAT难以处理变长序列和输入输出对齐。
- 性能差距:
- 单步NAT模型性能低于AR模型。例如,基础Transformer(AR)在英文到德文(En→De)翻译中BLEU分数为27.8,而单步NAT(如“Iterative Refinement”)仅13.9(文档第70页)。
4. NAT的解决方案与进展
为应对挑战,研究者提出了多种技术:
4.1 迭代精炼(Iterative Refinement)
概念:通过多次迭代精炼预测,平衡速度与质量。
示例:Imputer模型(文档第71页)性能随迭代增加提升:
- 2次迭代:En→De 27.5,De→En 30.2。
- 4次迭代:En→De 28.0,De→En 31.0。
- 8次迭代:En→De 28.2,De→En 31.3。
比较:4-8次迭代后,Imputer接近基础Transformer性能,推理速度仍较快。
4.2 连接时序分类(CTC)
概念:CTC(文档第76页,Graves et al., 2006)处理未分割序列数据,解决对齐问题。
应用:在语音识别中,CTC-based NAT模型表现良好,如“CTC (Our Work)”单次迭代实现字符错误率(CER)5.6,单词错误率(WER)16.7(文档第68页)。
优势:适用于变长序列和对齐任务,如语音到文本和机器翻译。
4.3 知识蒸馏(Knowledge Distillation)
概念:使用预训练AR模型的输出(蒸馏数据)训练NAT模型(文档第72页,Gu et al., 2020)。
效果:图4(文档第73页)显示,NAT模型在较大AR模型(big AT)的蒸馏数据上性能优于真实数据。
机制:AR模型提供结构化序列,降低NAT建模依赖的复杂性。
4.4 专用NAT模型
- Levenshtein Transformer (LevT)(文档第74页,Gu et al., 2019):通过插入和删除操作精炼序列。
- Insertion Transformer (InsT)(文档第75页,Stern et al., 2019):通过迭代插入生成序列,约需 log₂ n 次迭代。
- KERMIT(文档第75页,Chan et al., 2019):基于插入的生成模型,增强依赖建模。
- Mask-Predict(文档第76页,Ghazvininejad et al., 2019):迭代预测掩码标记,提高连贯性。
- Imputer(文档第75页,Chan et al., 2020):结合填补和动态规划,少量迭代表现优异。
4.5 其他技术
- 生育率预测(文档第70页,Gu et al., 2018):预测输入标记对应的输出标记数量。
- 辅助正则化(文档第70页,Wang et al., 2019):提高训练稳定性。
- N-gram损失(文档第70页,Shao et al., 2020):优化n-gram一致性。
- 基于提示的训练(文档第70页,Li et al., 2019):利用AR模型提示引导NAT训练。
5. 性能比较
5.1 单步NAT模型(文档第70页)
单步NAT速度快,但性能较低:
- NAT with Fertility:En→De 17.7,De→En 21.5。
- Our Work (CTC):En→De 25.7,De→En 28.1。
- 基础Transformer(AR):En→De 27.8,De→En 31.2。
5.2 多步NAT模型(文档第71页)
多步NAT通过迭代提升性能:
- Imputer(4次迭代):En→De 28.0,De→En 31.0。
- Mask-Predict(10次迭代):En→De 27.0,De→En 30.5。
接近AR性能,同时保持较快推理速度。
5.3 语音识别(文档第68页)
CTC-based NAT在语音识别中表现良好:
- Sabour et al. (2019):CER 3.1,WER 9.3。
- CTC (Our Work):CER 5.6,WER 16.7。
6. NAT的应用
- 机器翻译:快速翻译(如英文到德文、罗马尼亚文)。
- 图像描述生成:并行生成图像描述。
- 文本到图像生成:需解决结构依赖问题(文档第7页)。
- 语音识别:CTC-based NAT用于音频转录(文档第68页)。
- 文本生成:Imputer等技术用于通用序列建模(文档第69页)。
7. NAT的优势
- 速度:并行解码显著快于AR模型。
- 可扩展性:适合实时应用,如实时翻译。
- 灵活性:支持变长序列和复杂任务。
8. 实践理解与实现
- 理解Transformer:
熟悉Transformer的编码器-解码器结构和自注意力机制。
- 实验迭代精炼:
使用PyTorch/TensorFlow实现NAT模型(如Gu et al., 2018),加入迭代精炼。
- 使用知识蒸馏:
训练AR Transformer,用其输出训练NAT模型(参考文档第73页)。
- 应用CTC:
使用torch.nn.CTCLoss处理未分割序列。
- 评估权衡:
比较BLEU(翻译)或CER/WER(语音),调整迭代次数。
- 探索预训练模型:
使用Hugging Face的NAT模型,微调于特定任务。
9. 关键要点
- 原理:NAT并行生成标记,假设条件独立,区别于AR的顺序生成。
- 挑战:依赖建模和连贯性问题导致性能差距。
- 解决方案:迭代精炼、CTC、知识蒸馏及专用模型提升质量。
- 应用:适用于低延迟任务,如翻译、描述生成和语音识别。
- 性能:多步NAT接近AR性能,兼顾速度与质量。
通过研读引用的论文(如Gu et al., 2018; Chan et al., 2020)并实验实现,您可以深入掌握NAT。如需代码示例或深入讲解某技术,请告知!