基于InternLM的情感调节大师FunGPT
基于书生系列大模型,社区用户不断创造出令人耳目一新的项目,从灵感萌发到落地实践,每一个都充满智慧与价值。“与书生共创”将陆续推出一系列文章,分享这些项目背后的故事与经验。欢迎订阅并积极投稿,一起分享经验与成果,推动大模型技术的普及与进步。
本文来自社区投稿,作者Alannikos,书生大模型实战营学员。本文将向大家介绍孵化于书生大模型实战营的项目 ,基于 InternLM 的情感调节大师 FunGPT。
1.项目介绍
在这个快节奏的世界里,我们需要一点调味剂来调和生活。无论是需要一点甜言蜜语来提振精神,还是需要一剂犀利怼语来释放压力,FunGPT 都能满足您的需求。FunGPT 基于 InternLM2.5 系列大模型,利用 XTuner 进行QLoRA指令微调,使模型能够满足用户的个性化要求。同时为了方便用户,我们还发布了 1.8B 系列小模型,减量不减效果;此外,我们还利用 LMDeploy 对多个模型使用感知权重量化(AWQ)算法进行W4A16量化,既节省显存又提升推理速度!
🍬 甜言蜜语模式:
- 心情提升器🌟✨:当您感到低落,我们的甜言蜜语模式能让您的心情瞬间飙升,就像尝了一颗超级甜的蜜糖。
- 自信加油站💪🌈:同时我们的赞师傅会用合适且独特的方式夸奖您,让您的自信心爆棚。
🔪 犀利怼语模式:
- 压力释放阀:当您感到压力山大,我们的怼人模式能让您在怼人的同时,找到释放的出口。
- 幽默吐槽机😂👅:怼师傅的言语不仅犀利,而且幽默风趣,在怼人的过程中,您还能体会到脑洞大开的怼人方式。
项目地址:
https://github.com/Alannikos/FunGPT
视频地址:
https://www.bilibili.com/video/BV1EGBYYtEMA/
InternLM GitHub:
https://github.com/InternLM/InternLM
LMDeploy GitHub
https://github.com/InternLM/lmdeploy
XTuner GitHub:
https://github.com/InternLM/xtuner
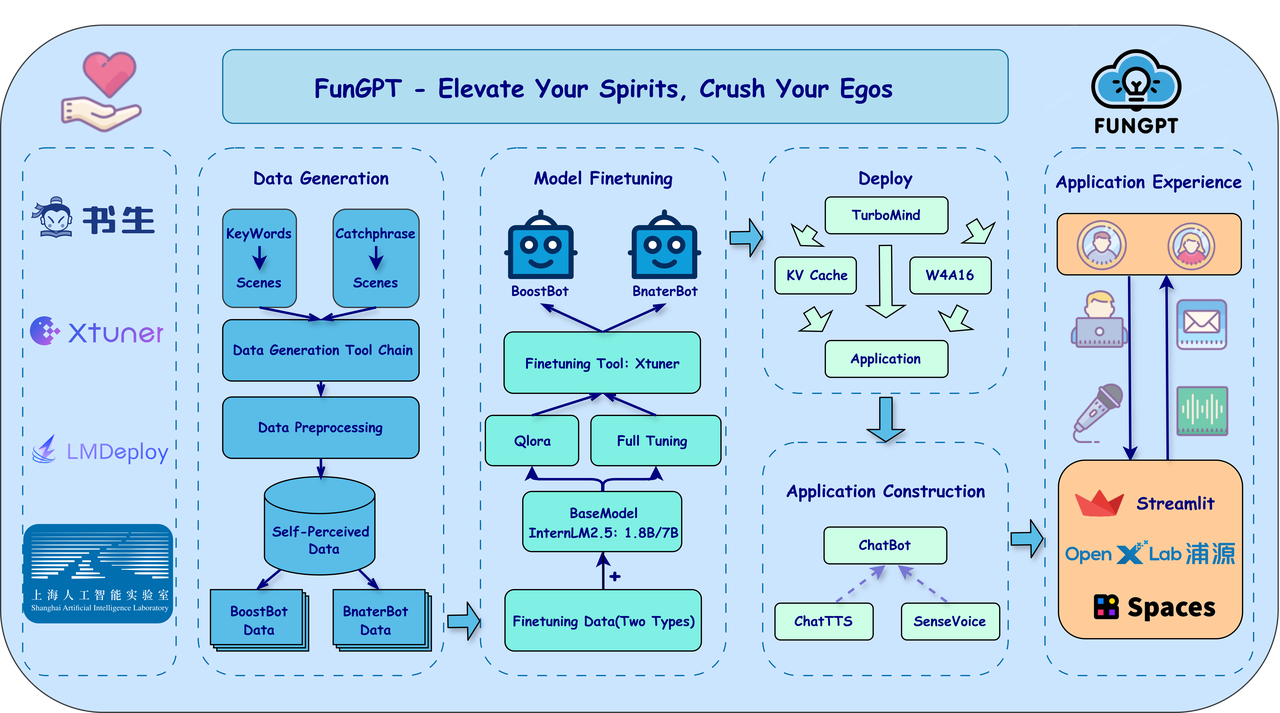
项目架构图
2.技术方法
数据生成
在大模型微调过程中,我们可以借助许多方法进行有监督微调(SFT),不论是通过原生的 LoRA 微调等技术,还是通过封装好的工具,比如 XTuner,我们都需要准备高质量的微调数据。但是通过人工手动标注数据的成本较高,对于大部分个人开发者来说,效率比较低下,本项目的方案就是采用大模型 API 来生成我们所需要的多轮对话数据集,例如使用 InternLM 等(现阶段可直接使用 EDG4LLM 工具,该工具内置 InternLM 等主流模型API),这样的方式简单且易于控制。通常来说,生成的数据集还是能够达到较好的微调效果。
LLM 使用
大语言模型是本项目的核心组件,我们选用了开源的 InternLM2.5 系列作为基础模型。InternLM2.5 具有强大的理解和生成能力,支持长上下文窗口,并且具有较好的中文理解能力。详细的使用方法请参考 https://github.com/Alannikos/FunGPT/blob/main/LLM/models/internlm2_5_7b_chat.py
在本项目中,LLM主要负责对用户输入进行理解和回复生成,同时还需要处理多模态输入,并与ASR和TTS模块进行协同工作。
ASR 使用
语音识别模块采用了开源的 SenseVoice 模型,该模型具有优秀的多语言语音识别能力,支持中英文等多语言识别,准确率较高,且能够较好地处理背景噪声。具体的部署和使用说明请查看https://github.com/Alannikos/FunGPT/blob/main/ASR/models/sensevoice.py
在实际应用中,ASR 模块负责将用户的语音输入转换为文本,并传递给 LLM 进行处理。我们提供了流式识别接口,也支持实时语音转写。
TTS 使用
语音合成模块使用了开源的 ChatTTS 模型,该模型能够生成自然流畅的语音。支持多说话人合成,并且可以调节语速和音色等参数。详细的配置和使用方法请参考https://github.com/Alannikos/FunGPT/blob/main/TTS/models/chattts.py
TTS 模块主要负责将 LLM 生成的文本转换为语音输出,支持批量合成模式。我们还提供了情感控制接口,可以根据文本内容自动调整语气和语调,使输出更加自然。
模型微调
为了适应特定场景的需求,我们提供了完整的模型微调流程。本项目主要采用了XTuner提供的QLoRA参数微调方法,该工具提供了友好的配置模板和完善的训练监控。具体的微调流程和参数设置请参考https://github.com/Alannikos/FunGPT/blob/main/Finetune/BoostBot/scripts/internlm2_5_chat_7b_qlora_alpaca_e3_copy.py
微调支持指令对齐、多轮对话等多种任务类型。我们提供了预处理脚本来转换数据格式,同时XTuner也支持增量训练,可以在已有模型基础上继续优化。
模型量化
为了在有限的计算资源下部署大模型,量化是一个重要的优化手段。我们使用 LMDeploy 进行模型量化,在保持模型性能的同时减少显存占用,详细的量化流程请参考 https://github.com/InternLM/lmdeploy
量化完成后,可以通过 LMDeploy 的 Benchmark 进行效果对比,同时 LMDeploy 还提供了不同量化策略的性能对比数据,帮助用户选择最适合的量化方案。
3.快速使用
3.1 部署环境
- 操作系统:Ubuntu 20.04.6 LTS
- CPU:Intel® Xeon® Platinum 8369B CPU @ 2.90GHz(在线 GPU 服务器)
- 显卡:NVIDIA A100-SXM4-80GB, NVIDIA-SMI 535.54.03,Driver Version: 535.54.03,CUDA Version: 12.2
- Python: 3.10.0
3.2 关键依赖信息
Python==3.10.0
torch==2.4.1
torch-complex==0.4.4
torchaudio==2.4.1
torchvision==0.16.2
chattts==0.1.1
streamlit==1.38.0
audio-recorder-streamlit==0.0.10
3.3 部署步骤
Clone 代码或者手动下载代码放置服务器:
git clone https://github.com/Alannikos/FunGPT
配置 Python 环境(推荐使用 conda)
- 进入项目的根目录
cd FunGPT
- 创建conda环境
conda create -n FunGPT python==3.10.0
- 安装第三方库
pip install -r requirements.txt# 大概需要1h左右
下载模型
TTS 模型(若使用则必选)
- git-lfs 安装 由于涉及到模型文件的下载,首先需要保证
git-lfs已经成功安装。对于Linux用户来说,可按照下面的命令安装:
apt install git-lfs
- 启动
LFS
git lfs install
- 下载 TTS 模型到指定路径
# 1. 进入指定目录
cd /FunGPT/TTS/weights# 2. 从huggingface下载模型
git clone https://huggingface.co/2Noise/ChatTTS
- 无法访问 HuggingFace 用户,可从镜像源下载
# 2. 从镜像源下载模型
git clone https://hf-mirror.com/2Noise/ChatTTS
ASR 模型(若使用则必选)
由于涉及到模型文件的下载,首先需要保证 git-lfs 已经成功安装。对于 Linux 用户来说,可按照下面的命令安装:
# 已下载用户可忽略此条命令
apt install git-lfs
- 启动
LFS
git lfs install
- 下载 TTS 模型到指定路径
# 1. 进入指定目录
cd /FunGPT/ASR/weights# 2. 从huggingface下载模型
git clone https://huggingface.co/FunAudioLLM/SenseVoiceSmall
- 无法访问 HuggingFace 用户,可从镜像源下载
# 2. 从镜像源下载模型
git clone https://hf-mirror.com/FunAudioLLM/SenseVoiceSmall
LLM 模型(必选)
对于 LLM 模型的选择,我们提供了多个选择,效果最佳的模型为 BanterBot-7b-chat 和 BoostBot-7b-chat,其次量化的模型效果也非常不错;此处为了节约下载时间,我们选择了这两个 1_8B 模型: BanterBot-1_8b-chat 和 BoostBot-1_8b-chat 来作为示例,大家可以按照需求自由进行替换即可。
- 启动
LFS
git lfs install
- 下载 LLM 模型到指定路径
# 1. 进入指定目录
cd /FunGPT/LLM/weights# 2. 从huggingface下载BanterBot-1_8b-chat模型
https://huggingface.co/Alannikos768/BanterBot_1_8b-chat# 3. 从huggingface下载BoostBot-1_8b-chat模型
https://huggingface.co/Alannikos768/BoostBot_1_8b-chat
- 无法访问 HuggingFace用户,可从 OpenXLab 下载
# 2. 从OpenXLab下载BanterBot-1_8b-chat模型(国内用户)
git clone https://code.openxlab.org.cn/Alannikos/BanterBot-1_8b-chat.git# 3. 从OpenXLab下载BoostBot-1_8b-chat模型(国内用户)
git clone https://code.openxlab.org.cn/Alannikos/BoostBot-1_8b-chat.git
运行网页脚本
conda activate FunGPTstreamlit run app.py --server.address=127.0.0.1 --server.port=7860
3.4 模型体验
- 如果是在远程服务器上运行的,需要进行端口映射
ssh -p port user@ip -CNg -L 7860:127.0.0.1:7860 -o StrictHostKeyChecking=no
- 然后在体验应用 打开浏览器,输入
http://127.0.0.1:7860,然后点击对应界面即可体验FunGPT