实例分割网络-YOLACT使用
1.前言
因为需要跑对比实验,因此学习使用YOLACT训练自已的数据集。
准备工作
1.将自已使用labelme标注的数据集个数 json 转换为 coco数据集 实例分割格式
(其实也是json格式,就是把一个数据集,如train中所有json文件合并在一起)
2.参考视频教程
参考链接:【扫盲】Yolact++实例分割网络训练_哔哩哔哩_bilibili
command.txt是指导 需要更改的地方
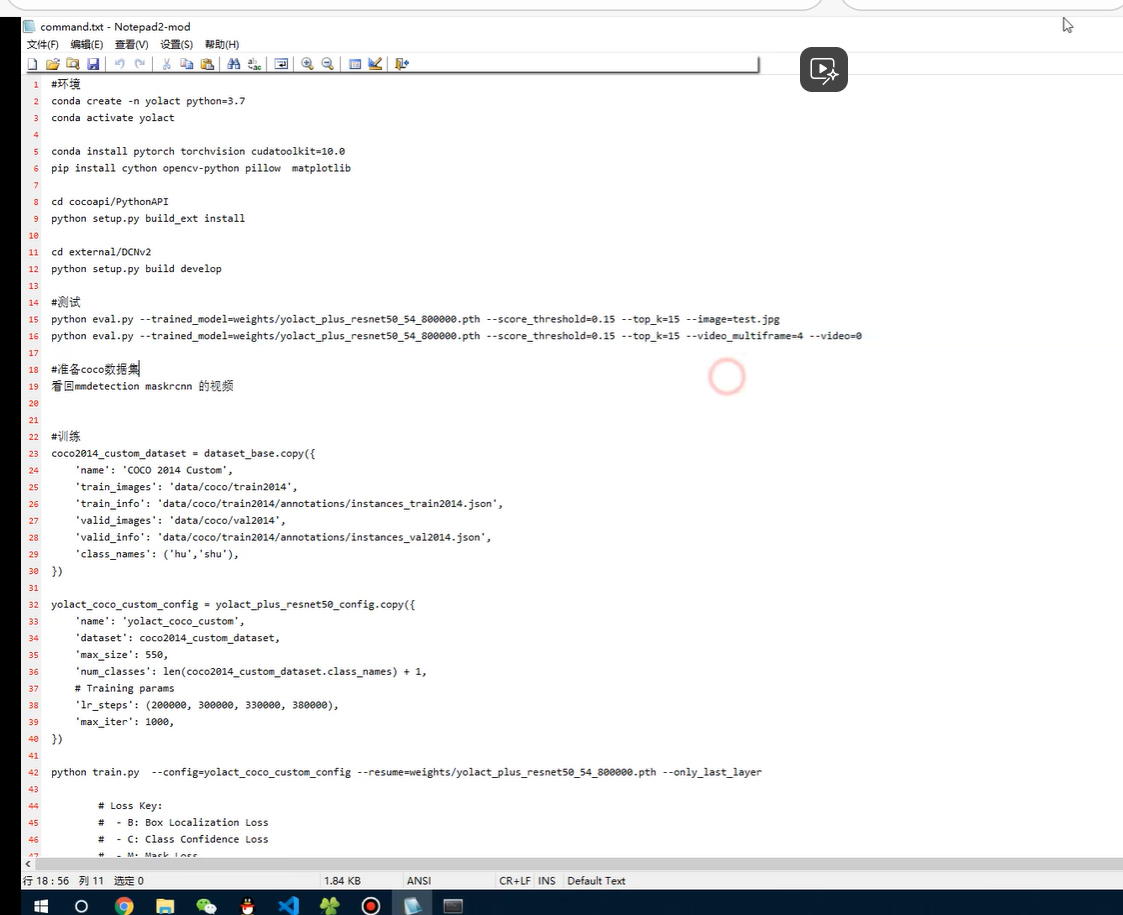

数据集格式 coco 使用 labelme2coco.py 转换
配置文件:
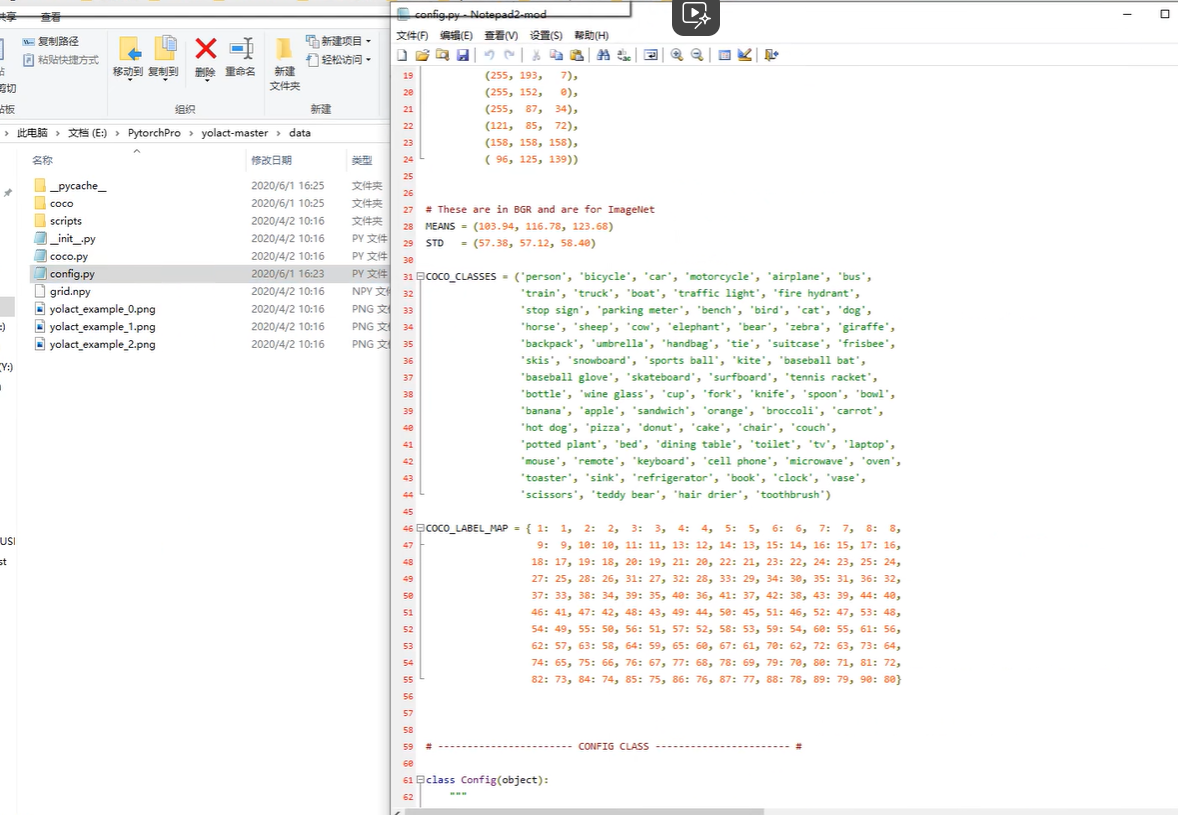
改动地方1:
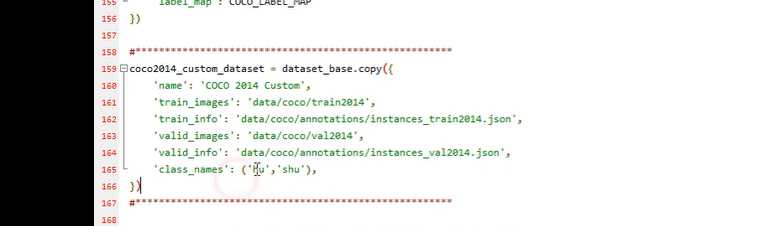
仅更改 class_names , 将里面的标签换成自已的标签
改动地方2:
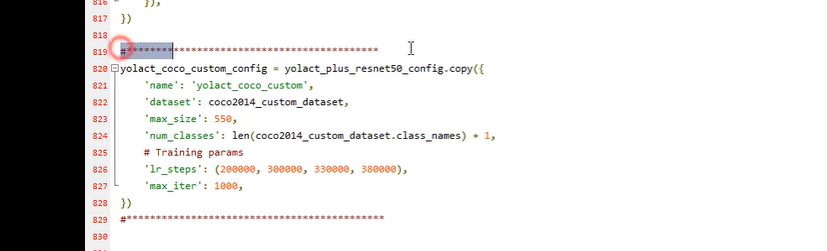
需要更改的地方:
max_iter 迭代轮次 ,可以设为100
学习率跟着训练轮次的变换改动
若训练轮次几万,学习率则分为1/4 (没有听懂)
8:00
在train.py 看看哪里需要修改
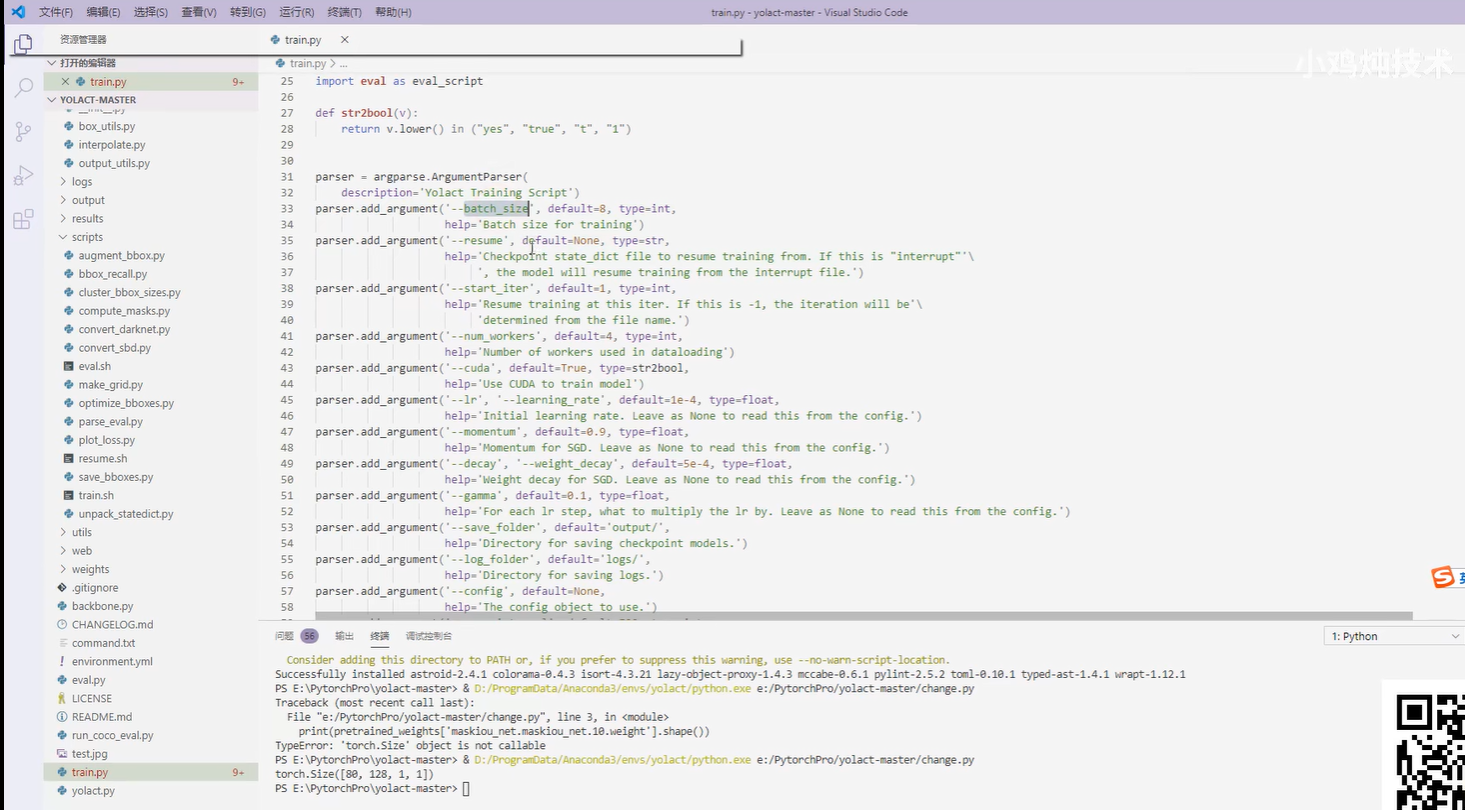
改1:
batch_size
改2:
学习率

训练
训练输出,可以忽略 error
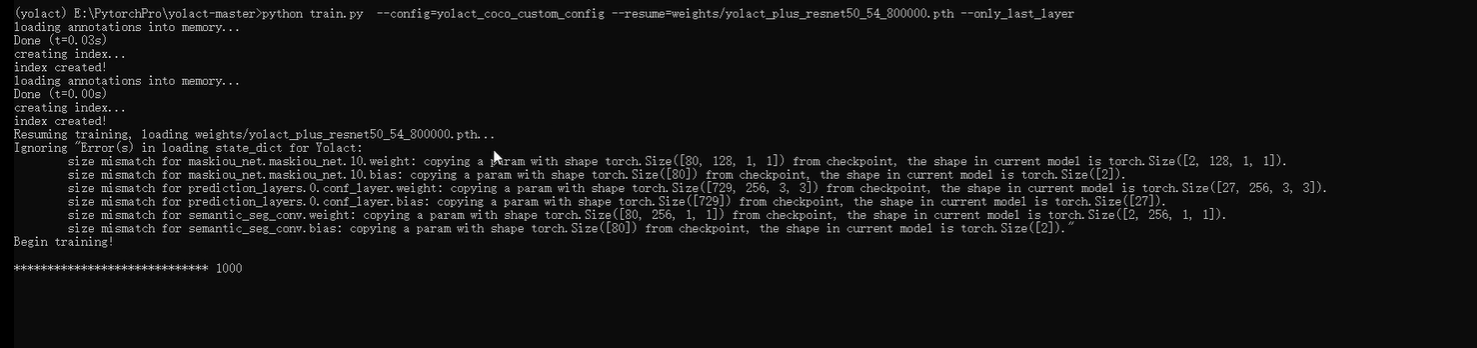
训练权重输出(权重文件名字不可以更改)


3.个人使用过程中遇到的问题及解决方法
官方代码:
dbolya/yolact: A simple, fully convolutional model for real-time instance segmentation.
制作数据集教程:
Training with custom data · Issue #70 · dbolya/yolact
我认为我的培训取得了进步,非常感谢您的宝贵建议。Labelme 和 labelme2coco.py 完美地创建数据集。对于计划在自定义数据集上微调/训练模型的任何人,请按照以下步骤作:
- 下载并安装 Labelme (https://kkgithub.com/wkentaro/labelme)
- 使用多边形标记选项进行标记(存储库有很好的教程)
- 将为每个标记为
- 现在使用创建label.txt(示例:https://kkgithub.com/wkentaro/labelme/blob/master/examples/instance_segmentation/labels.txt)
- 生成 coco 样式 json : ./labelme2coco.py <labelled_data_folder> <out_folder> --labels labels.txt
更多详细信息 : https://kkgithub.com/wkentaro/labelme/tree/master/examples/instance_segmentation
做!数据集已创建。现在继续执行 yolact 存储库中关于自定义训练的说明
202598,展示这样。明天搞。
参考资料:
1.【扫盲】Yolact++实例分割网络训练_哔哩哔哩_bilibili
2.【实例分割】用自己的数据复现yolact网络-含python源码-CSDN博客
3.【实例分割yolact++】从头训练自己的yolact++模型-CSDN博客