GPTBots在AI大语言模型应用中敏感数据匿名化探索和实践
背景
随着人工智能技术的快速发展,尤其是大语言模型(LLM-large language model)在金融、医疗、客服等领域的广泛应用,处理海量数据已成为常态。然而,这些数据中往往包含个人可识别信息(PII-Personally Identifiable Information),如姓名、身份证号、电话号码、信用卡号等敏感信息。若未经妥善处理,这些信息的泄露可能导致严重的隐私侵犯、身份盗窃或金融诈骗等后果。例如,2023年某金融公司因智能客服系统未有效过滤用户隐私数据,导致信用卡号泄露,引发了广泛关注。
此外,全球范围内对数据隐私的监管日益严格。中国的《个人信息保护法》以及《生成式人工智能服务管理暂行办法》、欧盟的《通用数据保护条例》(GDPR)、美国加州《消费者隐私法》(CCPA)、美国《健康保险携带与责任法案》(HIPAA)等法规明确要求企业在处理敏感数据时必须采取保护措施,确保数据合规性。
敏感数据匿名化作为一种关键技术,通过识别并替换或掩码文本中的PII实体,能够在不影响数据可用性的前提下,显著降低隐私风险,保障模型训练、推理和应用过程中的数据安全。不同语言、领域的信息提取需要结合命名实体识别(NER)、规则匹配、深度学习等多种方法相结合,且还要兼顾性能与准确率的平衡。因此,在LLM Agent系统中嵌入敏感信息匿名化机制,不仅有助于符合法律合规要求,避免敏感信息外泄,还能提升系统安全性与用户信任度,是构建可靠LLM应用的关键环节。例如,在医疗领域,匿名化后的患者数据可用于模型推理使用,而无需暴露个人身份信息。
GPTBots作为世界领先的企业级AI大语言模型应用Agent平台,为企业提供端到端的 AI 解决方案,将 AI 智能体应用于客户服务、企业搜索、数据洞察等场景。在企业AI应用落地过程中,经常遇到因为企业避免内部敏感数据避免泄漏,无法使用模型厂商功能强大的AI大模型服务的问题,即使在企业内部独立部署模型推理服务,也面临着算力成本高、开源模型效果不稳定、并发性能不足等诸多缺点。为此,GPTBots团队在AI大语言模型应用中敏感数据匿名化进行了深入的探索和实践。
数据匿名技术选型对比分析
presidio组件介绍
Presidio 是由微软开源的一款数据保护和匿名化软件开发框架(https://github.com/microsoft/presidio),其名称源自拉丁语“praesidium”,意为“保护”或“驻防”。Presidio 旨在为文本和图像中的个人可识别信息(PII)提供快速、上下文感知的识别与匿名化功能,广泛应用于金融、医疗、市场营销和数据分析等领域。
Presidio 由两个核心组件构成:Analyzer(分析器)和 Anonymizer(匿名化器)。Analyzer 利用命名实体识别(NER)、正则表达式、基于规则的逻辑以及校验和等多种技术,检测文本中的 PII 实体,如姓名、电话号码、信用卡号等。Anonymizer 则通过替换、掩码、加密等操作对检测到的 PII 进行匿名化处理。Presidio 支持多语言 PII 识别,并允许用户通过 API 或代码自定义识别器和匿名化逻辑,以适应特定业务需求。
Presidio 的设计注重可扩展性和灵活性,支持 Docker 和 Kubernetes 部署,能够无缝集成到数据处理流水线中。此外,Presidio 提供可逆匿名化功能,允许在特定场景下恢复原始数据,适用于需要同时保护隐私和保留数据完整性的场景.
对比分析
以下是对 Presidio 与其他类似 NER 和匿名化组件(如 Amazon Comprehend、Google DLP、Flair、spaCy)的优缺点对比:
| 工具 | 优点 | 缺点 |
| Presidio | 开源免费,社区活跃;支持多语言 PII 识别;提供可逆匿名化;高精度识别;支持容器化部署,微软开源组件成熟度高,底层集成spaCy、stanza、transformers分析引擎 | 依赖外部 NLP 模型,配置复杂;特定领域 PII 需自定义;图像匿名化功能不成熟 |
| Amazon Comprehend | 云端服务,开箱即用;集成 AWS 生态;多语言支持,速度快 | 商业化产品,成本高;非开源,定制性有限;需上传云端,隐私风险 |
| Google DLP | 支持 100+ 信息类型;提供风险分析报告;集成 Google Cloud | 非开源,成本高;定制性有限;需联网处理,敏感数据风险 |
| Flair | 开源轻量,NER 性能优异;支持多语言; | 无内置匿名化功能;配置技术门槛高;特定 PII 支持有限,模型运行性能偏低 |
| spaCy | 开源,社区广泛;高效 NER 模型;多语言支持,轻量级 | PII 识别功能有限,需额外开发;匿名化需自行实现,开发成本高 |
总结:Presidio 在开源性、灵活性和多语言支持方面具有显著优势,特别适合需要高度定制化的场景。相比商业化产品(如 Amazon Comprehend 和 Google DLP), Presidio 成本更低且更透明;相比纯 NER 工具(如 Flair 和 spaCy), Presidio 提供完整的匿名化流水线,功能更全面。因此选择Presidio框架作为构成数据匿名功能的核心组件。
Presidio介绍
Presidio 组件介绍
Presidio 提供了一个灵活、可扩展的框架,主要由以下核心组件构成:
1. Analyzer(分析器):
- 功能:负责检测和识别文本或图像中的敏感信息(如姓名、信用卡号、电话号码、地址等)。
- 工作原理:使用预定义或自定义的识别器(Recognizers),结合自然语言处理(NLP)、正则表达式、预训练模型等技术,分析输入数据并返回敏感实体的位置和置信度评分。
- 定制化:支持开发者创建特定类型的识别器,例如针对全角格式的信用卡号或特定地区的电话号码。
2. Anonymizer(匿名化器):
- 功能:对分析器检测到的敏感信息进行脱敏处理,例如将姓名替换为占位符(如 <PERSON>)、对信用卡号进行掩码处理等。
- 工作原理:根据配置的策略,执行替换、掩码或自定义脱敏操作,确保输出数据不包含敏感信息。
- 定制化:支持通过 YAML 文件或代码定义脱敏规则,例如指定替换字符或脱敏格式。
3. Image Redactor(图像脱敏模块):
- 功能:处理图像中的敏感信息,使用光学字符识别(OCR)技术检测图像中的文本,并对敏感内容进行编辑或遮盖。
- 应用场景:适用于扫描文档、身份证照片等场景,生成脱敏后的图像。
- 目前不太成熟,不建议在生产环境中使用,未来可以依赖多模态模型(multimodal-LLM)能力来解决。
4. Structured(格式化数据模块)
- 功能:扩展了 Presidio 的功能,专注于表格格式和半结构化格式 (JSON) 等结构化数据格式。它利用 Presidio-Analyzer 的检测功能来识别包含个人身份信息 (PII) 的列或键,并在这些列/键名称与检测到的 PII 实体之间建立映射。检测之后,Presidio-Anonymizer 用于对被识别为包含 PII 的列中的每个值应用去识别技术,确保敏感数据得到适当的保护。
- 应用场景:适用于json、表格、数据库、数据仓库等格式化批量数据的匿名。对AI大语言模型应用场景较少。
presidio-analyzer
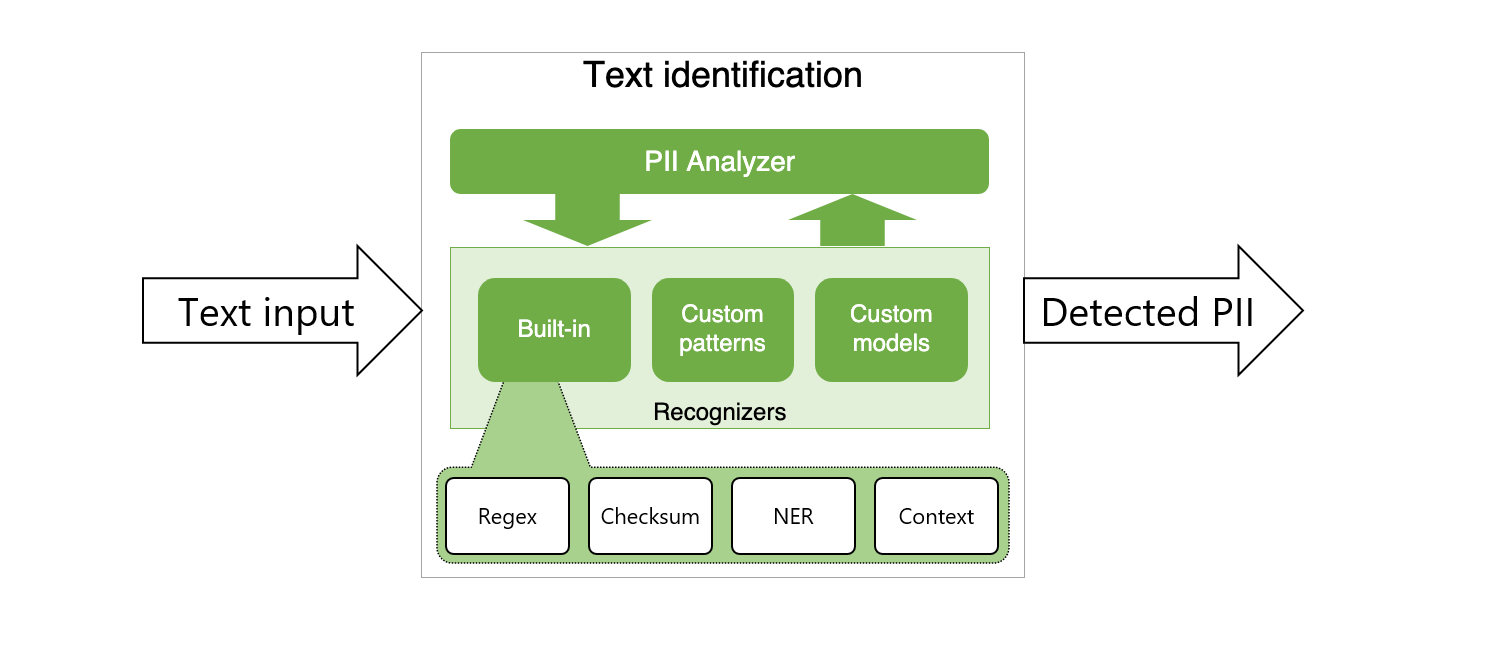
analyzer引擎:spaCy、stanza、transformers
Presidio 的 Analyzer 引擎是其 PII 识别核心,负责检测文本中的敏感信息。它结合了多种技术,包括命名实体识别(NER)、正则表达式、基于规则的逻辑以及校验和上下文分析,以确保高精度识别。Analyzer 支持以下主要 NLP 框架和模型:
1. spaCy
A. 介绍:spaCy 是一个高效的开源 NLP 库,广泛用于 NER 任务。Presidio 默认使用 spaCy 的预训练模型(如 en_core_web_lg)来识别姓名、地点、组织等实体。
B. 特点:
-
轻量级,速度快,适合实时应用。
-
支持多语言模型,包括英语、中文、日语、韩语等。
-
通过上下文分析增强 PII 识别精度,例如区分普通词汇和敏感实体的上下文。
C. 局限性:
-
对于非标准或特定领域的 PII(如行业特定的编码),需要自定义规则。
2. Stanza
A. 介绍:Stanza 是由斯坦福大学开发的 NLP 库,提供高质量的 NER 模型,特别适合处理复杂的语言结构。
B. 特点:
-
支持多语言,包括低资源语言,比如阿拉伯语、泰语、缅甸语、越南语等小语种。
-
提供细粒度的 NER 标签,适合需要高精度识别的场景。
-
集成深度学习模型,性能强劲。
C. 局限性:
-
模型较大,部署可能需要更多资源。
-
对某些语言的支持可能不如 spaCy 成熟。
3. Transformers
A. 介绍:Transformers 是 Hugging Face 提供的 NLP 库,基于 Transformer 架构,支持 BERT、RoBERTa 等先进模型。
B. 特点:
-
在 NER 任务上表现出色,准确率高。
-
支持微调自定义模型,以适应特定领域的 PII 识别需求。
-
可以处理长文本和复杂上下文。
C. 局限性:
-
计算资源需求较高,可能不适合资源受限的环境。
-
模型训练和微调需要专业知识。
Presidio 的 Analyzer 引擎支持以上三种 NLP 框架,用户可以根据具体需求选择合适的引擎。例如,在需要高性能和准确率的场景下,可以选择 Transformers;而在资源受限或需要快速部署的场景下,spaCy 是一个更好的选择。
presidio-anonymizer
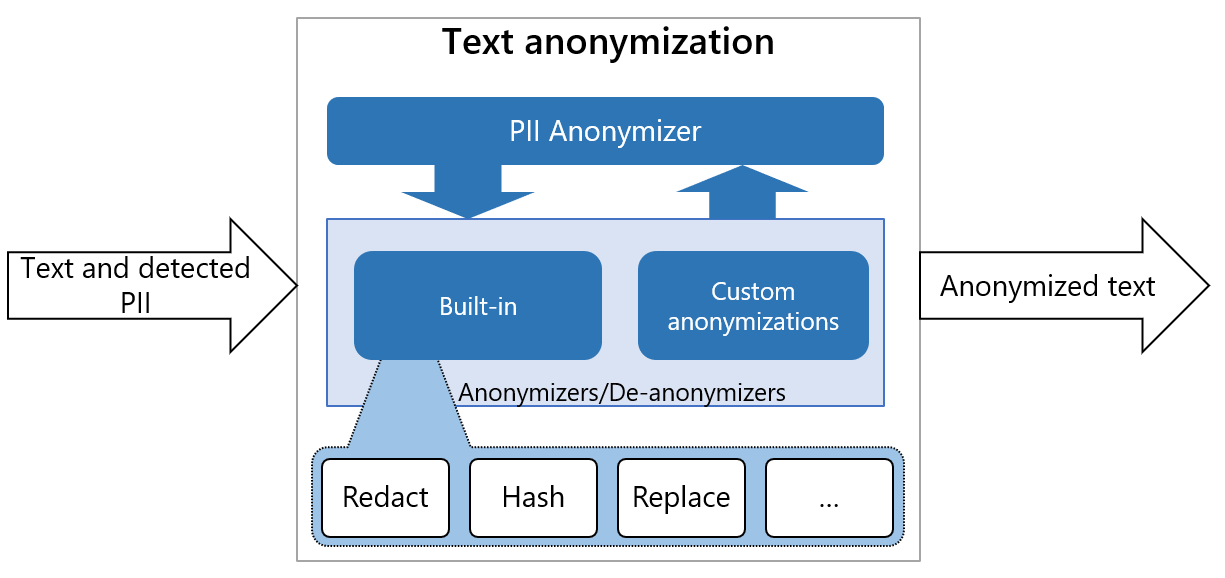
anonymizer实现方法:replace、redact、hash、mask、encrypt、custom
Presidio 的 Anonymizer 组件提供了多种匿名化方法,允许用户根据不同需求选择合适的策略。这些方法包括:
| 方法 | 描述 | 参数 | 用例 |
| Replace | 将 PII 替换为指定值,默认替换为实体类型(如 [PERSON]) |
| 保留数据结构,隐藏具体信息(如姓名替换为 [NAME]) |
| Redact | 完全删除 PII 实体 | 无 | 高度敏感数据,确保 PII 不可恢复 |
| Hash | 使用哈希函数(如 SHA-256 或 SHA-512)生成不可逆哈希值 |
| 存储或传输 PII,使用哈希值代替原始数据 |
| Mask | 用指定字符(如 *)部分替换 PII 字符 |
| 显示部分信息,隐藏关键部分(如信用卡号后几位) |
| Encrypt | 使用加密密钥对 PII 进行可逆加密 |
| 需在特定条件下恢复原始数据(如合规审计) |
| Custom | 使用 lambda 函数自定义匿名化逻辑 |
| 标准方法无法满足需求时,使用自定义逻辑 |
Presidio 的 Anonymizer 通过这些多样的方法,为用户提供了灵活且强大的数据保护工具,适用于各种不同场景的数据匿名化需求。
探索和实践
为了实现数据匿名功能,GPTBots在平台增加一个数据匿名子系统,架构如图:
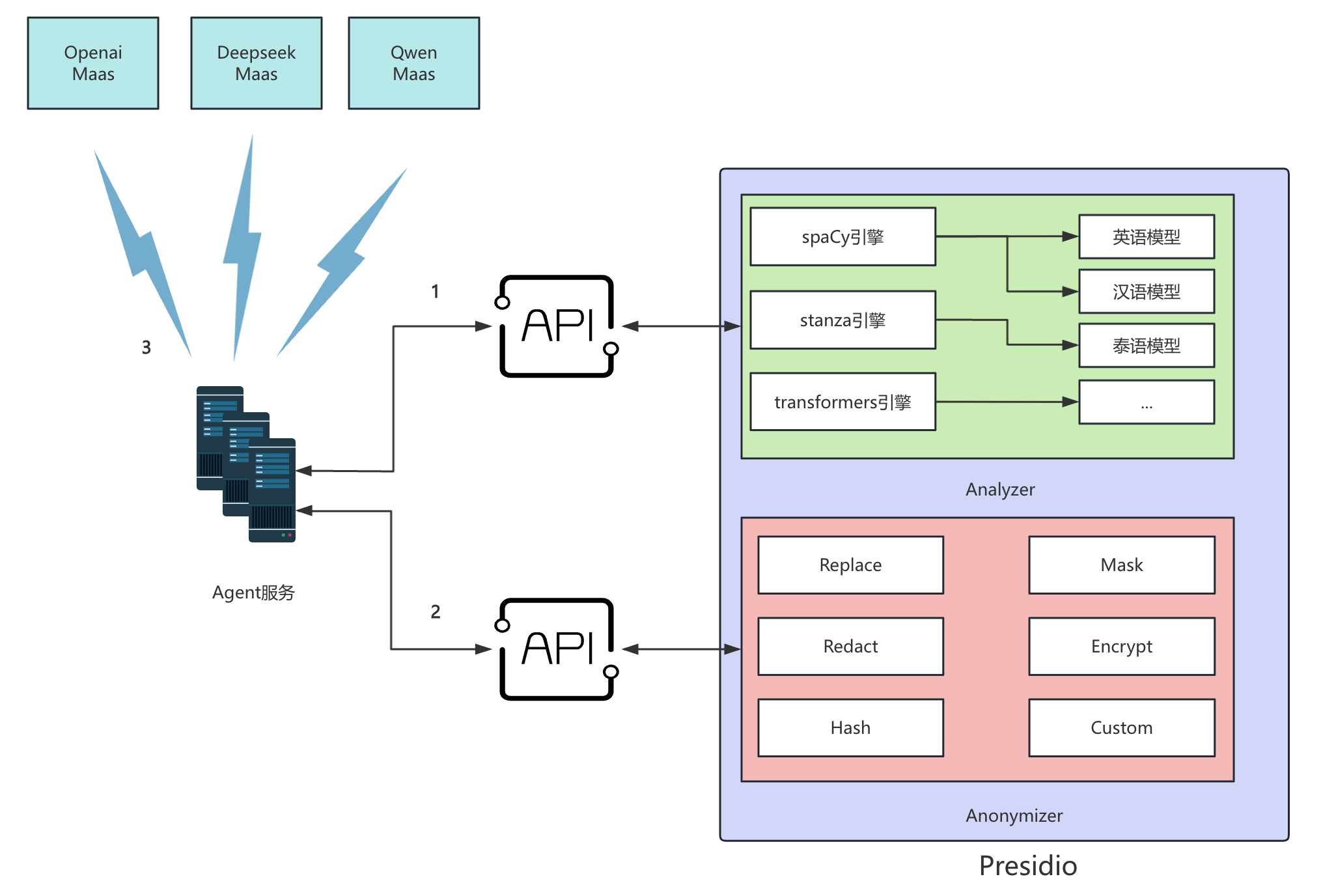
流程简述
-
Agent服务在访问模型厂商Maas服务之前,将content内容通过api网关发送给Presidio-analyzer进行识别;
-
Presidio-analyzer将识别结果返回给Agent服务;
-
Agent服务确认结果有效性后,将content原文和识别结果一起发送给Presidio-anonymizer进行匿名操作;
-
Presidio-anonymizer将匿名后的结果返回给Agent服务;
-
Agent服务接收到匿名后的content结果,重新拼接为模型请求调用模型厂商的Maas服务实现模型推理;
-
模型厂商返回推理结果后,按照匿名记录进行还原操作,实现敏感数据的安全匿名AI推理。
analyzer关键代码实现
软件版本
python版本:3.12
presidio版本:2.2.358
spaCy版本:3.8.2
stanza版本:1.10.1
一个简单例子:
from presidio_analyzer import AnalyzerEngine, PatternRecognizer, Pattern
from presidio_analyzer.nlp_engine import NlpEngineProvider
from typing import List, Optional
from presidio_analyzer.recognizer_result import RecognizerResult# 定义自定义识别器类
class CustomIDRecognizer(PatternRecognizer):# 定义要识别的模式:假设是 "ID-" 开头,后面跟 6 位数字PATTERNS = [Pattern(name="custom_id_pattern",regex=r"ID-\d{6}",score=0.85 # 置信度分数),]# 上下文关键词,增强识别准确性CONTEXT = ["id", "identifier", "number"]def __init__(self, supported_language: str = "en"):super().__init__(supported_entity="CUSTOM_ID",patterns=self.PATTERNS,context=self.CONTEXT,supported_language=supported_language)def invalidate_result(self, pattern_text: str) -> Optional[List[RecognizerResult]]:"""可选:添加额外的验证逻辑例如,检查是否符合特定规则"""return None# 主函数
def main():# 创建 NLP 引擎configuration = {"nlp_engine_name": "spacy","models": [{"lang_code": "en", "model_name": "en_core_web_lg"}],}provider = NlpEngineProvider(nlp_configuration=configuration)nlp_engine = provider.create_engine()# 初始化分析引擎并添加自定义识别器analyzer = AnalyzerEngine(nlp_engine=nlp_engine,supported_languages=["en"],default_language="en")# 添加自定义识别器custom_recognizer = CustomIDRecognizer()analyzer.registry.add_recognizer(custom_recognizer)# 测试文本text = "My custom ID is ID-123456 and another one is ID-987654."# 执行分析results = analyzer.analyze(text=text,language="en",entities=["CUSTOM_ID"],return_decision_process=True)# 输出结果print("Analysis Results:")for result in results:print(f"- Entity: {result.entity_type}")print(f" Text: {text[result.start:result.end]}")print(f" Score: {result.score}")print(f" Start: {result.start}, End: {result.end}")print("---")if __name__ == "__main__":main()api部分
AnalyzerRequest:识别请求协议
| PARAMETER | DESCRIPTION |
|
| the text to analyze TYPE: |
|
| the language of the text TYPE: |
|
| List of PII entities that should be looked for in the text. If entities=None then all entities are looked for. TYPE: |
|
| cross call ID for this request TYPE: |
|
| A minimum value for which to return an identified entity TYPE: |
|
| Whether the analysis decision process steps returned in the response. TYPE: |
|
| List of recognizers which will be used only for this specific request. TYPE: |
|
| List of context words to enhance confidence score if matched with the recognized entity's recognizer context TYPE: |
|
| List of words that the user defines as being allowed to keep in the text TYPE: |
|
| How the allow_list should be interpreted; either as "exact" or as "regex". - If TYPE: |
|
| regex flags to be used for when allow_list_match is "regex" TYPE: |
请求举例:
curl -X POST http://localhost:5002/analyze \
-H "Content-Type: application/json" \
-d '{"text": "我的名字是张伟,电话号码是138-1234-5678,身份证:371427111111111111,银行卡号:6214111111111111,ip地址:1.1.1.1,username:testuser,password:123456789pw,住在北京市朝阳区。","language": "zh"
}'返回结果:
[{"analysis_explanation": null,"end": 71,"entity_type": "CREDIT_CARD","recognition_metadata":{"recognizer_identifier": "ZhCreditCardRecognizer_139805391664224","recognizer_name": "ZhCreditCardRecognizer"},"score": 1.0,"start": 55},{"analysis_explanation": null,"end": 84,"entity_type": "IP_ADDRESS","recognition_metadata":{"recognizer_identifier": "ZhIpRecognizer_139805391663648","recognizer_name": "ZhIpRecognizer"},"score": 1.0,"start": 77},{"analysis_explanation": null,"end": 25,"entity_type": "CHINA_MOBILE_NUMBER","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391666000","recognizer_name": "PatternRecognizer"},"score": 0.8500000000000001,"start": 13},{"analysis_explanation": null,"end": 26,"entity_type": "CHINA_LANDLINE_NUMBER","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391666288","recognizer_name": "PatternRecognizer"},"score": 0.8500000000000001,"start": 14},{"analysis_explanation": null,"end": 93,"entity_type": "USERNAME","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391667104","recognizer_name": "PatternRecognizer"},"score": 0.8500000000000001,"start": 85},{"analysis_explanation": null,"end": 102,"entity_type": "USERNAME","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391667104","recognizer_name": "PatternRecognizer"},"score": 0.8500000000000001,"start": 94},{"analysis_explanation": null,"end": 111,"entity_type": "PASSWORD","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391666768","recognizer_name": "PatternRecognizer"},"score": 0.8500000000000001,"start": 103},{"analysis_explanation": null,"end": 111,"entity_type": "USERNAME","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391667104","recognizer_name": "PatternRecognizer"},"score": 0.8500000000000001,"start": 103},{"analysis_explanation": null,"end": 123,"entity_type": "PASSWORD","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391666768","recognizer_name": "PatternRecognizer"},"score": 0.8500000000000001,"start": 112},{"analysis_explanation": null,"end": 123,"entity_type": "USERNAME","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391667104","recognizer_name": "PatternRecognizer"},"score": 0.8500000000000001,"start": 112},{"analysis_explanation": null,"end": 7,"entity_type": "PERSON","recognition_metadata":{"recognizer_identifier": "SpacyRecognizer_139805460569152","recognizer_name": "SpacyRecognizer"},"score": 0.85,"start": 5},{"analysis_explanation": null,"end": 132,"entity_type": "LOCATION","recognition_metadata":{"recognizer_identifier": "SpacyRecognizer_139805460569152","recognizer_name": "SpacyRecognizer"},"score": 0.85,"start": 126},{"analysis_explanation": null,"end": 26,"entity_type": "USERNAME","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391667104","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 13},{"analysis_explanation": null,"end": 26,"entity_type": "PASSWORD","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391666768","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 13},{"analysis_explanation": null,"end": 49,"entity_type": "PASSWORD","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391666768","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 31},{"analysis_explanation": null,"end": 49,"entity_type": "USERNAME","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391667104","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 31},{"analysis_explanation": null,"end": 43,"entity_type": "CHINA_LANDLINE_NUMBER","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391666288","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 31},{"analysis_explanation": null,"end": 40,"entity_type": "TAIWAN_LANDLINE_NUMBER","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391665712","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 31},{"analysis_explanation": null,"end": 39,"entity_type": "HONGKONG_LANDLINE_NUMBER","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391665232","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 31},{"analysis_explanation": null,"end": 40,"entity_type": "HONGKONG_MOBILE_NUMBER","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391665568","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 32},{"analysis_explanation": null,"end": 49,"entity_type": "CHINA_PASSPORT","recognition_metadata":{"recognizer_identifier": "ChinesePassportRecognizer_139805391663456","recognizer_name": "ChinesePassportRecognizer"},"score": 0.4,"start": 40},{"analysis_explanation": null,"end": 71,"entity_type": "USERNAME","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391667104","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 55},{"analysis_explanation": null,"end": 71,"entity_type": "PASSWORD","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391666768","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 55},{"analysis_explanation": null,"end": 67,"entity_type": "CHINA_LANDLINE_NUMBER","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391666288","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 55},{"analysis_explanation": null,"end": 64,"entity_type": "TAIWAN_LANDLINE_NUMBER","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391665712","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 55},{"analysis_explanation": null,"end": 63,"entity_type": "HONGKONG_MOBILE_NUMBER","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391665568","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 55},{"analysis_explanation": null,"end": 64,"entity_type": "HONGKONG_LANDLINE_NUMBER","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391665232","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 56},{"analysis_explanation": null,"end": 71,"entity_type": "CHINA_PASSPORT","recognition_metadata":{"recognizer_identifier": "ChinesePassportRecognizer_139805391663456","recognizer_name": "ChinesePassportRecognizer"},"score": 0.4,"start": 62},{"analysis_explanation": null,"end": 84,"entity_type": "PASSWORD","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391666768","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 77},{"analysis_explanation": null,"end": 84,"entity_type": "USERNAME","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391667104","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 77},{"analysis_explanation": null,"end": 93,"entity_type": "PASSWORD","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391666768","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 85},{"analysis_explanation": null,"end": 102,"entity_type": "PASSWORD","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391666768","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 94},{"analysis_explanation": null,"end": 121,"entity_type": "CHINA_LANDLINE_NUMBER","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391666288","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 112},{"analysis_explanation": null,"end": 121,"entity_type": "HONGKONG_LANDLINE_NUMBER","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391665232","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 113},{"analysis_explanation": null,"end": 121,"entity_type": "TAIWAN_LANDLINE_NUMBER","recognition_metadata":{"recognizer_identifier": "PatternRecognizer_139805391665712","recognizer_name": "PatternRecognizer"},"score": 0.4,"start": 113}
]api在官网presidio-analyzer/app.py基础上,优化并扩充了功能接口,包括:
-
registry_recognizer接口,实现客户自定义recognizer; -
remove_recognizer接口,实现移除客户自定义recognizer; -
为模型添加预置自定义recognizer,比如EMAIL,采用正则表达式来识别;
-
添加多种analyzer引擎,spaCy、stanza、transformers并存,可以支持不同场景的识别;
# -*- coding: utf-8 -*-
"""REST API server for analyzer."""
import json
import logging
import os
import ipaddress
import re
from logging.config import fileConfig
from pathlib import Path
from typing import Tuple,List,Optional,Dict,Literalfrom flask import Flask, Response, jsonify, request
from presidio_analyzer import AnalyzerEngine, AnalyzerEngineProvider, AnalyzerRequest
from werkzeug.exceptions import HTTPExceptionDEFAULT_PORT = "3000"LOGGING_CONF_FILE = "logging.ini"WELCOME_MESSAGE = r"""_______ _______ _______ _______ _________ ______ _________ _______
( ____ )( ____ )( ____ \( ____ \\__ __/( __ \ \__ __/( ___ )
| ( )|| ( )|| ( \/| ( \/ ) ( | ( \ ) ) ( | ( ) |
| (____)|| (____)|| (__ | (_____ | | | | ) | | | | | | |
| _____)| __)| __) (_____ ) | | | | | | | | | | | |
| ( | (\ ( | ( ) | | | | | ) | | | | | | |
| ) | ) \ \__| (____/\/\____) |___) (___| (__/ )___) (___| (___) |
|/ |/ \__/(_______/\_______)\_______/(______/ \_______/(_______)
"""class RegistryRecognizerRequest:def __init__(self, req_data: Dict):self.entity = req_data.get("entity")self.language = req_data.get("language")self.regex = req_data.get("regex")self.context = req_data.get("context")self.deny_list = req_data.get("deny_list")class RemoteRecognizerRequest:def __init__(self, req_data: Dict):self.entity = req_data.get("entity")self.language = req_data.get("language")class Server:"""HTTP Server for calling Presidio Analyzer."""def __init__(self):fileConfig(Path(Path(__file__).parent, LOGGING_CONF_FILE))self.logger = logging.getLogger("presidio-analyzer")#self.logger.setLevel(os.environ.get("LOG_LEVEL", self.logger.level))self.logger.setLevel("DEBUG")self.app = Flask(__name__)#nlp默认spacy引擎analyzer_conf_file = os.environ.get("ANALYZER_CONF_FILE")nlp_engine_conf_file = os.environ.get("NLP_CONF_FILE")recognizer_registry_conf_file = os.environ.get("RECOGNIZER_REGISTRY_CONF_FILE")#增加stanza引擎 对小语种的支持 https://stanfordnlp.github.io/stanza/ner_models.htmlstanza_nlp_engine_conf_file = os.environ.get("STANZA_NLP_CONF_FILE")# spacy nlpself.logger.info("Starting analyzer engine(spacy)")self.engine: AnalyzerEngine = AnalyzerEngineProvider(analyzer_engine_conf_file=analyzer_conf_file,nlp_engine_conf_file=nlp_engine_conf_file,recognizer_registry_conf_file=recognizer_registry_conf_file).create_engine()self.engine.context_aware_enhancer = LemmaContextAwareEnhancer(context_similarity_factor=0.45, min_score_with_context_similarity=0.35)# stanza nlpself.logger.info("Starting analyzer engine(stanza)")self.stanza_engine: AnalyzerEngine = AnalyzerEngineProvider(analyzer_engine_conf_file=analyzer_conf_file,nlp_engine_conf_file=stanza_nlp_engine_conf_file,recognizer_registry_conf_file=recognizer_registry_conf_file).create_engine()self.stanza_engine.context_aware_enhancer = LemmaContextAwareEnhancer(context_similarity_factor=0.45, min_score_with_context_similarity=0.35)## 为zh模型自定义recognizer# 创建电子邮件地址识别器email_recognizer = PatternRecognizer(supported_entity="EMAIL_ADDRESS",patterns=[email_pattern],supported_language="zh",context=["邮箱", "电子邮件", "联系方式","mail","email"] # 添加中文上下文关键词以提高准确性)self.engine.registry.add_recognizer(email_recognizer)## endself.logger.info(WELCOME_MESSAGE)@self.app.route("/health")def health() -> str:"""Return basic health probe result."""return "Presidio Analyzer service is up"@self.app.route("/remove_recognizer", methods=["POST"])def remove_recognizer() -> str:"""Remove a recognizer."""try:req_data = RemoteRecognizerRequest(request.get_json())if not req_data.entity:raise Exception("No entity provided")if not req_data.language or isinstance(req_data.language,list) is False:raise Exception("No language provided, it must be of array type.")# 存在先删除nlp_engine.registry.remove_recognizer(req_data.entity,req_data.language)except Exception as e:self.logger.error(f"Error occurred while calling the interface remove_recognizer. {e}")return jsonify(error=e.args[0]), 500return "Remove successfully"@self.app.route("/registry_recognizer", methods=["POST"])def registry_recognizer() -> str:"""Registry a recognizer."""try:req_data = RegistryRecognizerRequest(request.get_json())if not req_data.entity:raise Exception("No entity provided")if not req_data.language or isinstance(req_data.language,list) is False:raise Exception("No language provided, it must be of array type.")if not req_data.regex:raise Exception("No regex provided")if is_valid_regex(req_data.regex) is False:raise Exception(f"Invalid regex({req_data.regex})")if req_data.context and isinstance(req_data.language,list) is False:raise Exception("Context must be of array type.")if req_data.deny_list and isinstance(req_data.deny_list,list) is False:raise Exception("Deny_list must be of array type.")# 存在先删除nlp_engine.registry.remove_recognizer(req_data.entity,req_data.language)pattern = Pattern(name=custom_entity,regex=req_data.regex,score=0.4)# 创建新的recognizer并注册custom_recognizer = PatternRecognizer(supported_entity=custom_entity,patterns=[pattern],supported_language=l,context=req_data.context, # 添加中文上下文关键词以提高准确性deny_list=req_data.deny_list, # deny list 代表根据关键字列表进行替换 字符串精准查询替换 score=1)self.engine.registry.add_recognizer(custom_recognizer) except Exception as e:self.logger.error(f"Error occurred while calling the interface registry_recognizer. {e}")return jsonify(error=e.args[0]), 500return "Registered successfully"@self.app.route("/analyze", methods=["POST"])def analyze() -> Tuple[str, int]:"""Execute the analyzer function."""# Parse the request params## 此次省略,可以参考官网@self.app.route("/recognizers", methods=["GET"])def recognizers() -> Tuple[str, int]:"""Return a list of supported recognizers."""## 此次省略,可以参考官网@self.app.route("/supportedentities", methods=["GET"])def supported_entities() -> Tuple[str, int]:"""Return a list of supported entities."""## 此次省略,可以参考官网@self.app.errorhandler(HTTPException)def http_exception(e):return jsonify(error=e.description), e.codedef create_app(): # noqaserver = Server()return server.appif __name__ == "__main__":app = create_app()port = int(os.environ.get("PORT", DEFAULT_PORT))app.run(host="0.0.0.0", port=port)
配置文件部分
主要修改presidio_analyzer/conf目录下spacy.yaml、stanza.yaml、transformers.yaml文件,主要包括:
1. nlp_engine_name,代表选取什么引擎,支持:spacy、stanza、transformers;
2. models,代表语言和模型的对应关系,不同语言对应不同的模型,每个引擎都有属于自己的模型列表;
3. ner_model_configuration,ner相关选项:
A. labels_to_ignore: A list of labels to ignore. For example, O (no entity) or entities you are not interested in returning.
B. model_to_presidio_entity_mapping: A mapping between the transformers model labels and the Presidio entity types.
C. low_confidence_score_multiplier: A multiplier to apply to the score of entities with low confidence.
D. low_score_entity_names: A list of entity types to apply the low confidence score multiplier to.
nlp_engine_name: spacy
models: -lang_code: enmodel_name: en_core_web_lgner_model_configuration:model_to_presidio_entity_mapping:PER: PERSONPERSON: PERSONNORP: NRPFAC: LOCATIONLOC: LOCATIONLOCATION: LOCATIONGPE: LOCATIONORG: ORGANIZATIONORGANIZATION: ORGANIZATIONDATE: DATE_TIMETIME: DATE_TIMElow_confidence_score_multiplier: 0.4low_score_entity_names:-labels_to_ignore:- ORG- ORGANIZATION # has many false positives- CARDINAL- EVENT- LANGUAGE- LAW- MONEY- ORDINAL- PERCENT- PRODUCT- QUANTITY- WORK_OF_ART支持PII类型
PERSON
NRP
LOCATION
ORGANIZATION
DATE_TIME
-----下面是扩展预置自定义识别器(可以灵活扩展)
USERNAME
PASSWORD
CHINA_MOBILE_NUMBER
CHINA_LANDLINE_NUMBER
TAIWAN_MOBILE_NUMBER
TAIWAN_LANDLINE_NUMBER
HONGKONG_MOBILE_NUMBER
HONGKONG_LANDLINE_NUMBER
PHONE_NUMBER
EMAIL_ADDRESS
CHINA_ID
TAIWAN_ID
HKID
CHINA_BANK_ID
CREDIT_CARD
CHINA_PASSPORT
anonymizer实现
anonymizer实现比较简单,原理就是依据analyzer的结果,对原始文本进行匿名编辑操作(在AI场景下,需要自己实现推理结果的还原)。官网描述的很清晰,举个简单例子:
# -*- coding: utf-8 -*-
from presidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import OperatorConfig, RecognizerResult
from faker import Faker
import logging# 配置日志记录
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)def create_fake_name():"""生成假名的函数,用于匿名化 PERSON 实体。"""fake = Faker() # 在函数内创建 Faker 实例,避免全局对象return fake.name()def anonymize_text(text: str, analyzer_results: list[RecognizerResult]) -> str:"""对文本中的敏感信息进行匿名化处理。Args:text (str): 要匿名化的文本。analyzer_results (list[RecognizerResult]): 分析器识别的实体结果。Returns:str: 匿名化后的文本。Raises:ValueError: 如果输入参数无效。Exception: 如果匿名化过程发生错误。"""if not text or not analyzer_results:logger.error("Invalid input: text or analyzer_results is empty")raise ValueError("Text and analyzer_results must not be empty")try:# 配置匿名化器operators = {"PERSON": OperatorConfig("custom", {"lambda": create_fake_name})}anonymizer = AnonymizerEngine()# 执行匿名化result = anonymizer.anonymize(text=text,analyzer_results=analyzer_results,operators=operators)logger.info("Text anonymization successful")return result.textexcept Exception as e:logger.error(f"Anonymization failed: {str(e)}")raisedef main():"""主函数,演示文本匿名化流程。"""try:# 示例输入text_to_anonymize = "My name is Raphael and I like to fish."analyzer_results = [RecognizerResult(entity_type="PERSON", start=11, end=18, score=0.8)]# 执行匿名化anonymized_text = anonymize_text(text_to_anonymize, analyzer_results)print(f"Anonymized text: {anonymized_text}")except Exception as e:logger.error(f"Error in main: {str(e)}")print(f"Error: {str(e)}")if __name__ == "__main__":main()性能测试
服务器:10核40GB (Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50GHz)
locust测试框架
10user 每个user每秒1个请求,每个请求500字符左右
spacy模型:中文最强模型Chinese · spaCy Models Documentation
api中启动一个AnalyzerEngine
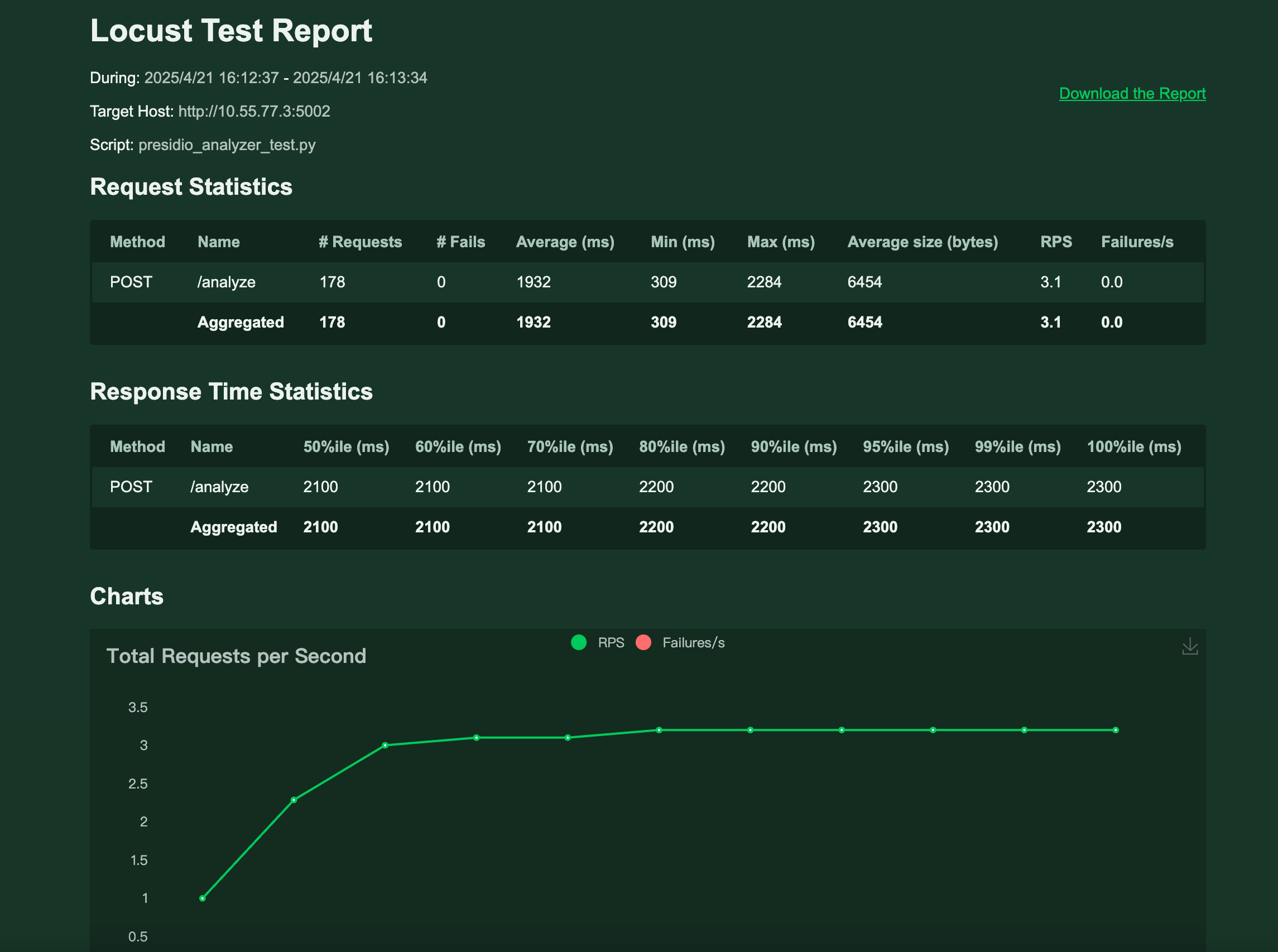
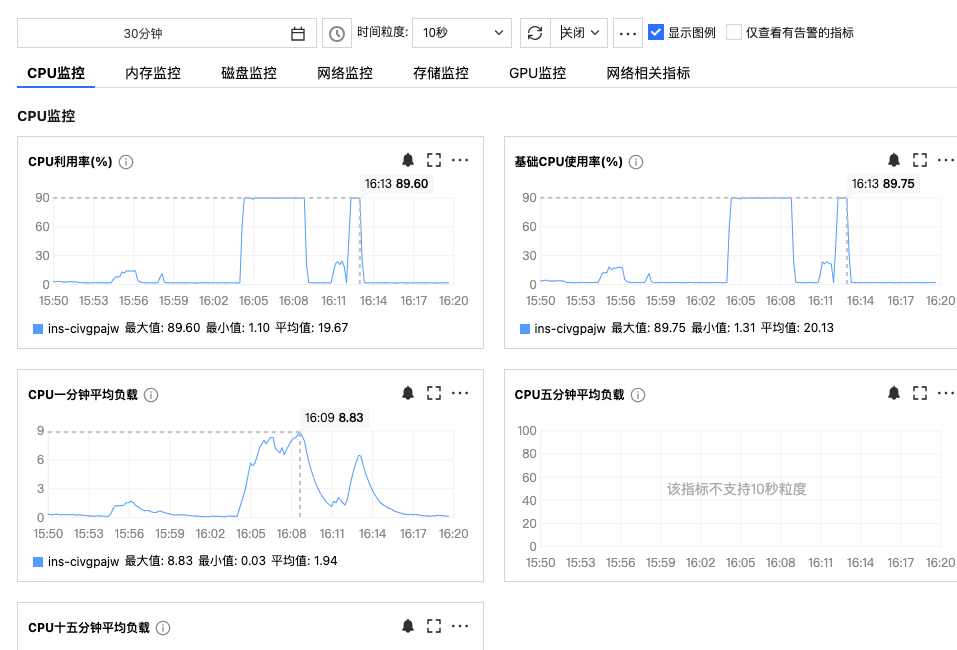
结论:presidio-analyzer主要消耗CPU和内存(text多长会导致oom,推荐不超过10k),10核支持3qps(rpm=180),推理达到10qps(rpm=600)大概要32核,transformers引擎因为使用transformer架构模型,需要用gpu算力来运行,性价比不高,暂时放弃。(上面测试结果仅供参考)
经验分享
在设计开发presidio过程,也遇到过一些问题和思考,这里分享算是抛砖引玉:
1. 在Presidio使用过程中,遇到了几个代码中bug,需要自己来依据需要修改,测试验证尽量全面;
2. analyzer支持的text最大长度,主要依赖使用的model,需要自己实际测试验证,避免oom;
3. 自定义recognizer的score可以通过context提升评分,通过score分数来控制误识别率;
4. 注册和移除recognizer接口,自定义和预置有差别,最好自己来实现;
5. 多语言混合场景,两个解决思路:
A. 采用transformer模型,一个大模型可以同时支持多个语言做ner,不过huggingface上的模型能力参差不齐,训练成本过高,还需要仔细筛选测试验证;
B. 每个语言模型都跑一次,比如中英文混合,中文和英文模型都跑一遍后在汇总确认做匿名。
6. 生产环境打包为docker镜像比较方便,模型文件都要提前下载打包到镜像中,这样可以在内网离线部署运行;
7. anonymizer本身没有使用模型,只是根据analyzer的结果进行字符串编辑,这一步可以考虑自己开发实现更为适合,因为匿名后的数据需要提交给大模型进行推理,可能会丢失关键信息,同时在大模型返回推理结果,可能还要还原文本;
8. 增加analyzer的并发处理能力,可以考虑同时启动多个实例提升并发处理能力;也可以考虑在一个实例中初始化多个AnalyzerEngine,实现一个引擎池,多个请求可以分配给不同的AnalyzerEngine处理。两个方案都可行。不过CPU和内存资源消耗也会成倍增长。
参考
-
Home - Microsoft Presidio
-
Trained Models & Pipelines · spaCy Models Documentation
-
NER Models - Stanza
-
https://huggingface.co/models?pipeline_tag=token-classification