DAY 34 超大力王爱学Python
- CPU性能的查看:看架构代际、核心数、线程数
- GPU性能的查看:看显存、看级别、看架构代际
- GPU训练的方法:数据和模型移动到GPU device上
- 类的call方法:为什么定义前向传播时可以直接写作self.fc1(x)
ps:在训练过程中可以在命令行输入nvida-smi查看显存占用情况

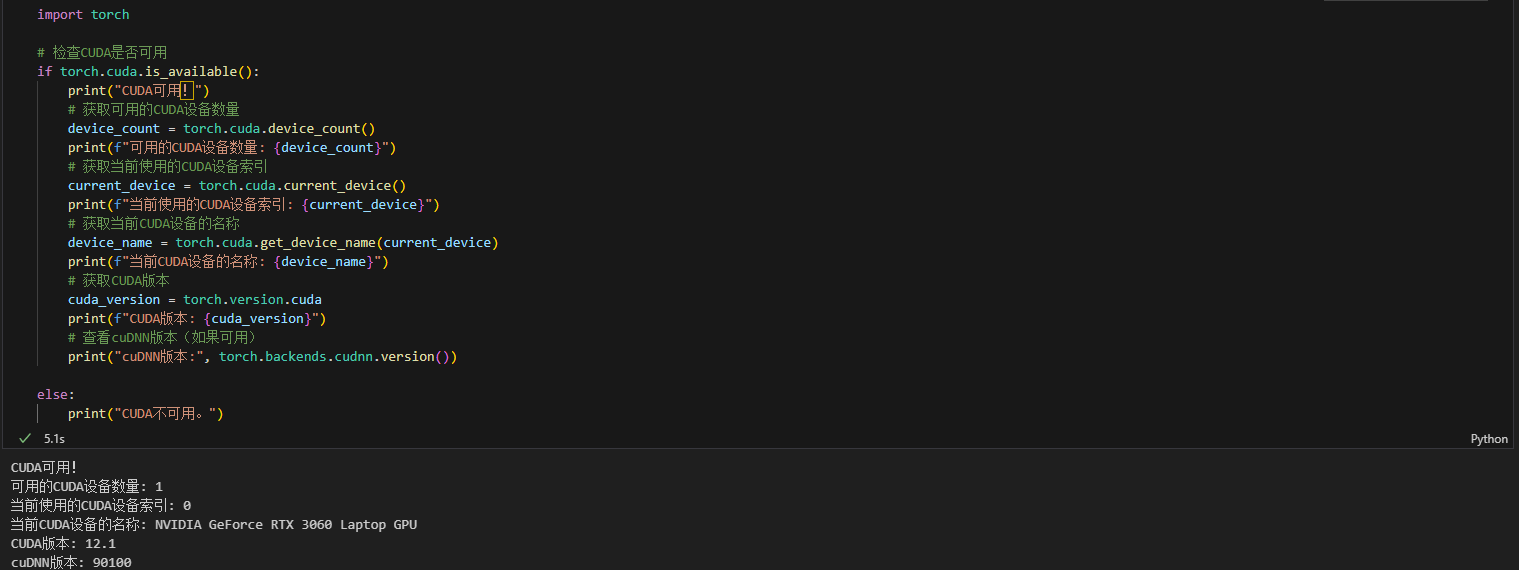

import torch
import time# 模拟训练循环(去除无关同步操作)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
X_train, y_train = torch.randn(120, 4).to(device), torch.randint(0, 3, (120,)).to(device)
model = torch.nn.Sequential(torch.nn.Linear(4, 3)).to(device)
optimizer = torch.optim.Adam(model.parameters())
criterion = torch.nn.CrossEntropyLoss()num_epochs = 20000
losses = []
start_time = time.time()for epoch in range(num_epochs):optimizer.zero_grad()outputs = model(X_train)loss = criterion(outputs, y_train)loss.backward()optimizer.step()# 仅在必要时记录(如间隔1000次),减少同步次数if (epoch + 1) % 1000 == 0:losses.append(loss.item()) # 同步操作,仅在间隔大时执行time_all = time.time() - start_time
print(f'Training time: {time_all:.2f} seconds')问题分析:记录次数与剩余时长无线性关系的原因
1. 同步操作的本质(GPU-CPU 数据传输)
- loss.item() 是同步操作:每次从 GPU 读取标量损失到 CPU,会阻塞 GPU 后续计算(需等待 CPU 完成)。但损失是标量(1 个值),数据传输开销极小(远小于张量传输),因此对总时间影响有限。
- 小数据集的计算特性:鸢尾花数据特征少(4 维)、样本少(训练集 120 个),每个 epoch 的 GPU 计算时间极短(微秒级),而同步开销(纳秒级)占比低,导致记录次数变化对总时间的影响被 “淹没”。
2. GPU 计算的并行性与开销波动
- 内核启动开销:GPU 执行张量运算时,每次内核启动(如矩阵乘法、激活函数)有固定开销。当记录间隔大(记录次数少),GPU 更连续执行内核(减少启动次数),可能略微提升效率;间隔小(记录次数多)时,频繁同步(虽开销小)但内核启动更分散,两者效率差异不明显,导致剩余时长变化小。
- Python 循环的开销:训练循环中的for循环在 Python 中本身有开销(解释器执行),但在小 epoch 数(如 20000)下,这部分开销与 GPU 计算相比可忽略,进一步弱化记录次数的影响。
3. 实验数据的特殊性
- 表格数据中的剩余时长波动小(~10%):说明记录操作的开销占总时间比例低(即使记录次数相差 20 倍,总时间变化仅约 10%)。这是因为:
- 损失记录的开销本身极小(标量传输 + 列表 append,均为 CPU 轻量操作)。
- GPU 计算主导总时间,而小数据集的 GPU 计算时间本身稳定(无明显波动),导致剩余时长(总时长 - 固定计算时长)变化不显著。
4. 对比实验的改进思路
- 增大数据集 / 模型复杂度:若使用百万级样本或深层神经网络,GPU 计算时间占比提升,此时记录次数(同步开销)的影响会更明显(线性关系可能显现)。
- 异步数据传输(非阻塞):在 PyTorch 中,可尝试先异步记录损失(如loss.detach().cpu(),但仍需同步item()),但本质上标量传输无法完全异步,效果有限。
- profiling 分析 :使用torch.profiler或nvidia-smi监控 GPU 利用率,观察记录操作对 GPU idle 时间的影响,验证开销占比。
代码巩固:优化训练循环的性能(减少同步开销)
优化点:
- 减少同步频率:仅在间隔较大时记录损失(如每 1000 epoch),降低 GPU-CPU 同步次数,提升 GPU 利用率。
- 避免不必要的操作:训练时若无需实时监控损失,可完全移除记录(或仅在训练结束后记录最终损失),最大化 GPU 计算效率。
总结
记录次数与剩余时长无明显线性关系,本质是小数据集下同步开销占比极低,GPU 计算主导总时间,且同步操作(标量传输)本身开销可忽略。若需验证线性关系,需在大数据集 / 复杂模型上实验,此时同步开销(如频繁的张量传输、日志记录)会成为性能瓶颈,显现出与记录次数的线性关系。
@浙大疏锦行