第二章 机器学习基本概念
课程来源:学堂在线 -- 清华大学 -- 大数据机器学习
提纲
- 基本术语
- 监督学习
- 假设空间
- 学习三要素
- 奥卡姆剃刀定理
- 没有免费的午餐定理
- 训练误差和测试误差
- 正则化
- 泛化能力
- 生成模型与判别模型
基本术语
数据集:用来描述事物的全部特性
事例/样本:数据集中的每一条记录
属性/特征:形状、味道为属性,圆形、甜则为属性值
特征向量:将几个属性建立直角坐标系,每个样本则会是一个向量形式呈现
分类问题:预测或输出的值为离散值(人脸识别、动作识别)
回归问题:预测或输出的为连续的值(房价预测、股票价格预测)
二分类任务:只涉及两个类别的分类问题(是否问题)
多分类问题
聚类任务:相似的事物归为一组
多标签标柱问题:一个变量序列的输入获得一个变量序列的输出
多标签问题:在分类任务上,给出多个标签(如图像识别中,给出猫、狗),用于处理复杂场景图像
监督学习

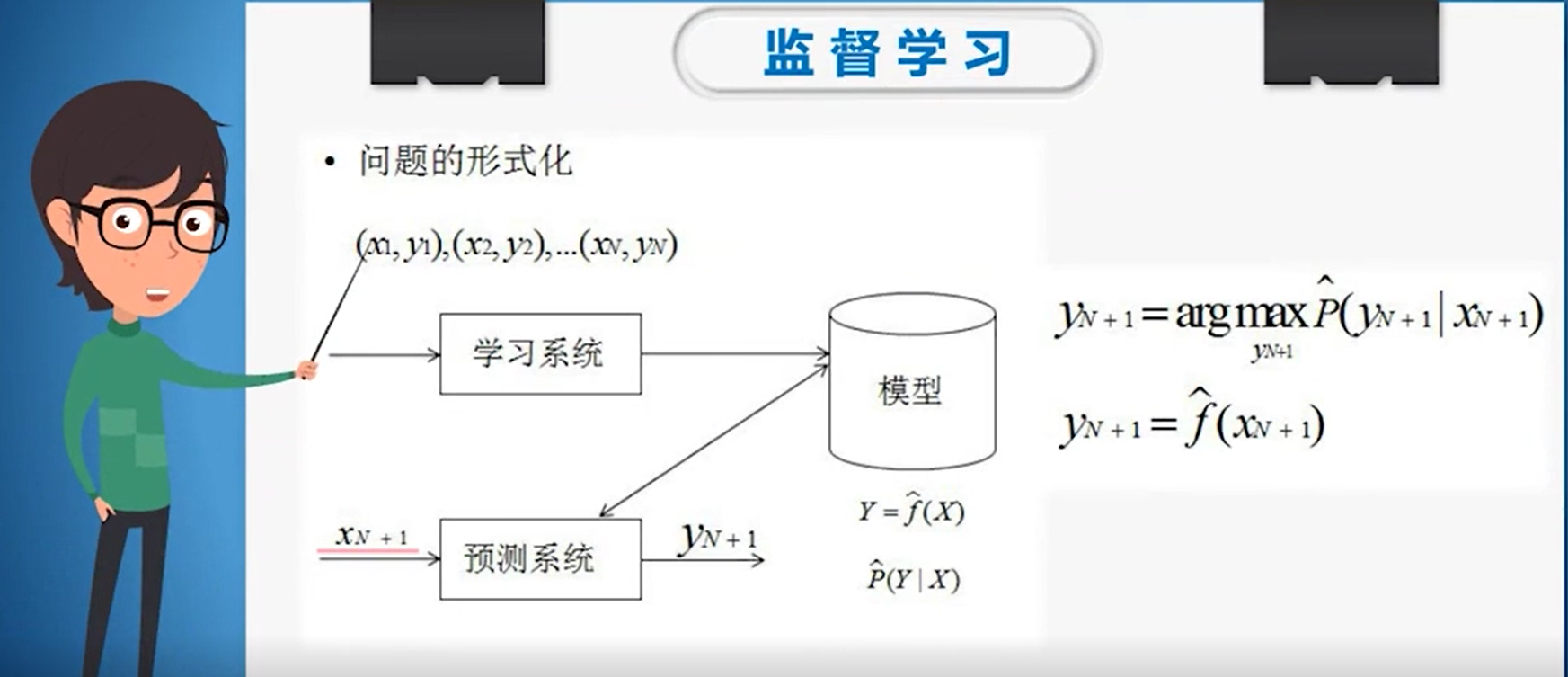
先对数据进行学习,得到模型,再由模型得到预测系统,通过测试数据判断预测系统是否准确率达标
假设空间
所有模型的集合称为假设空间
学习:搜索所有假设空间,与训练集匹配
版本空间:存在一个与训练集一致的假设集合
学习方法三要素

损失函数
模型一次预测的好坏
损失函数值越小,模型越好
风险函数
平均意义上模型预测好坏

在机器学习中,损失函数用于衡量模型预测与实际结果之间的差异。计算损失函数的期望值有几个重要原因:
-
泛化能力:损失函数的期望值可以帮助我们评估模型在未见数据上的表现。通过计算期望,我们考虑了所有可能的输入数据分布,而不仅仅是训练数据。这有助于提高模型的泛化能力,即在新数据上的表现。
-
稳定性:期望值提供了一种稳定的损失度量方式。单个样本的损失可能会有很大的波动,而期望值通过平均化这些波动,提供了一个更稳定和可靠的指标。
-
优化目标:在训练模型时,我们通常希望最小化损失函数的期望值。这是因为期望值代表了模型在整个数据分布上的平均表现,通过优化期望值,我们可以确保模型在整体上表现良好。
-
理论基础:许多机器学习算法的理论基础依赖于期望值。例如,最大似然估计和贝叶斯推断等方法都涉及到期望的计算。
总之,损失函数的期望值是评估和优化模型性能的关键工具,帮助我们构建更准确和可靠的机器学习模型。

但是联合概率密度未知
经验分险估计期望分险

如何高效求解最优化解成为机器学习的重要问题
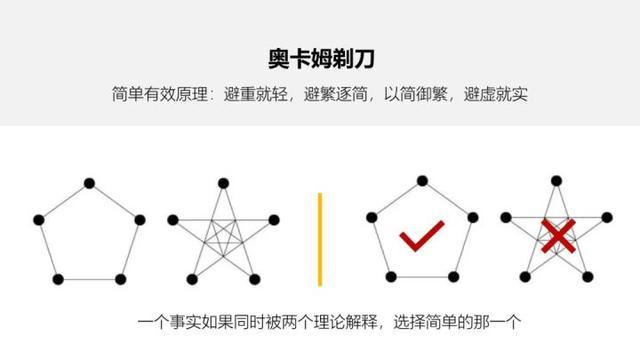
奥卡姆剃须刀
如无必要,勿增实体 --剔除不必要的纷争
没有免费午餐定理
如果一个拟合算法A在某些问题上比B算法效果好,则必然存在一些问题,B算法效果比A好
假设1.所有问题出现的机会相同或同等重要2.真实函数f均匀分布
训练误差&测试误差

过拟合与模型选择
学习选择的模型过于复杂或包含的参数过多,导致模型对已知数据预测良好,但是对未知的数据预测很差
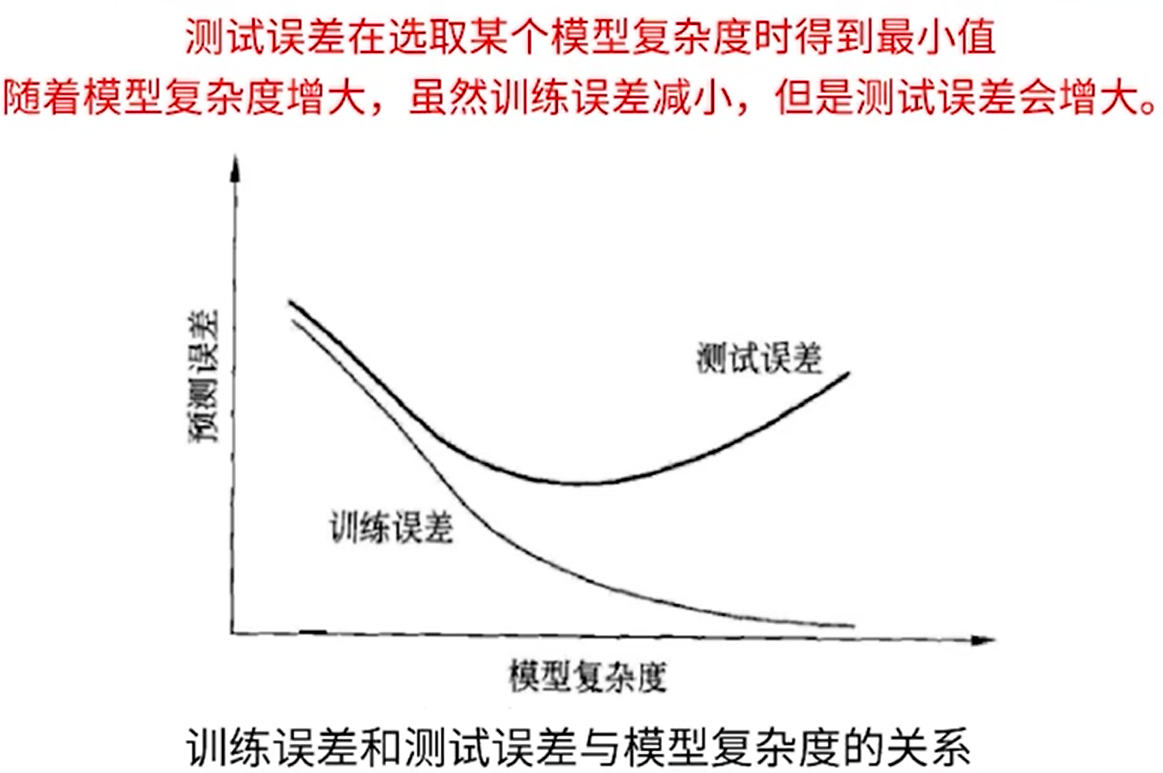
解决方法
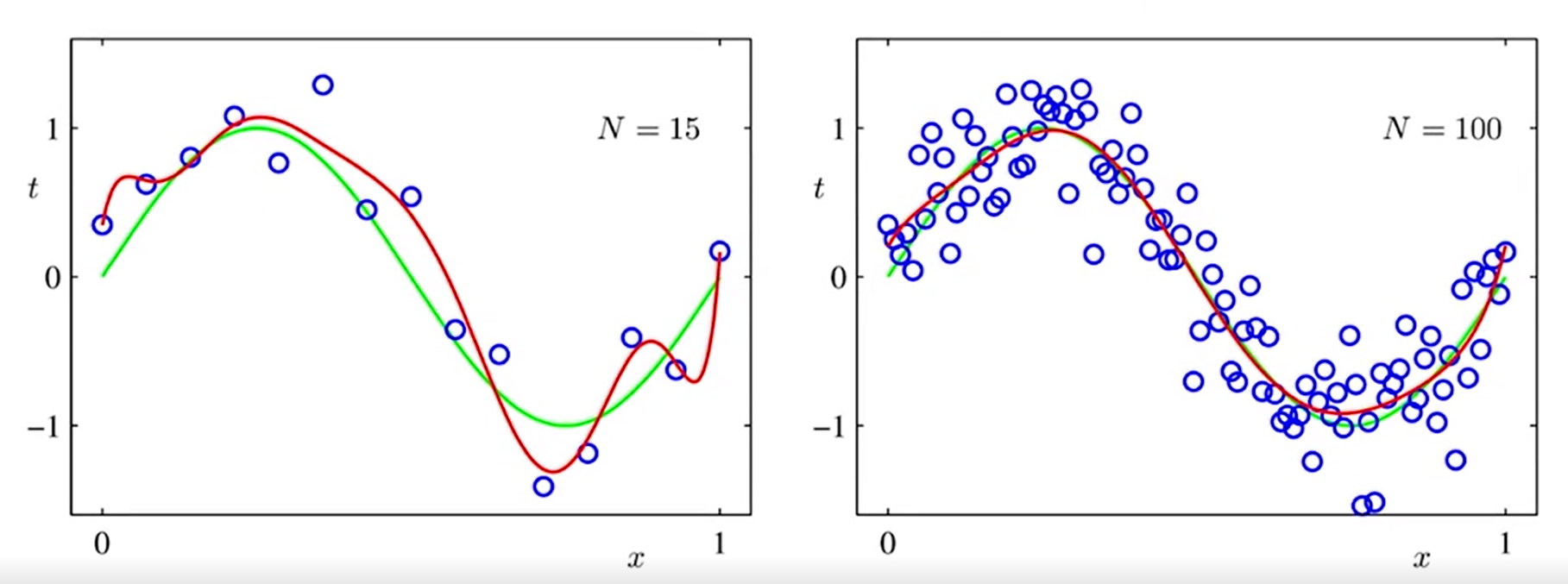
可以采用增加样本集大小的方式减小泛化误差
正则化
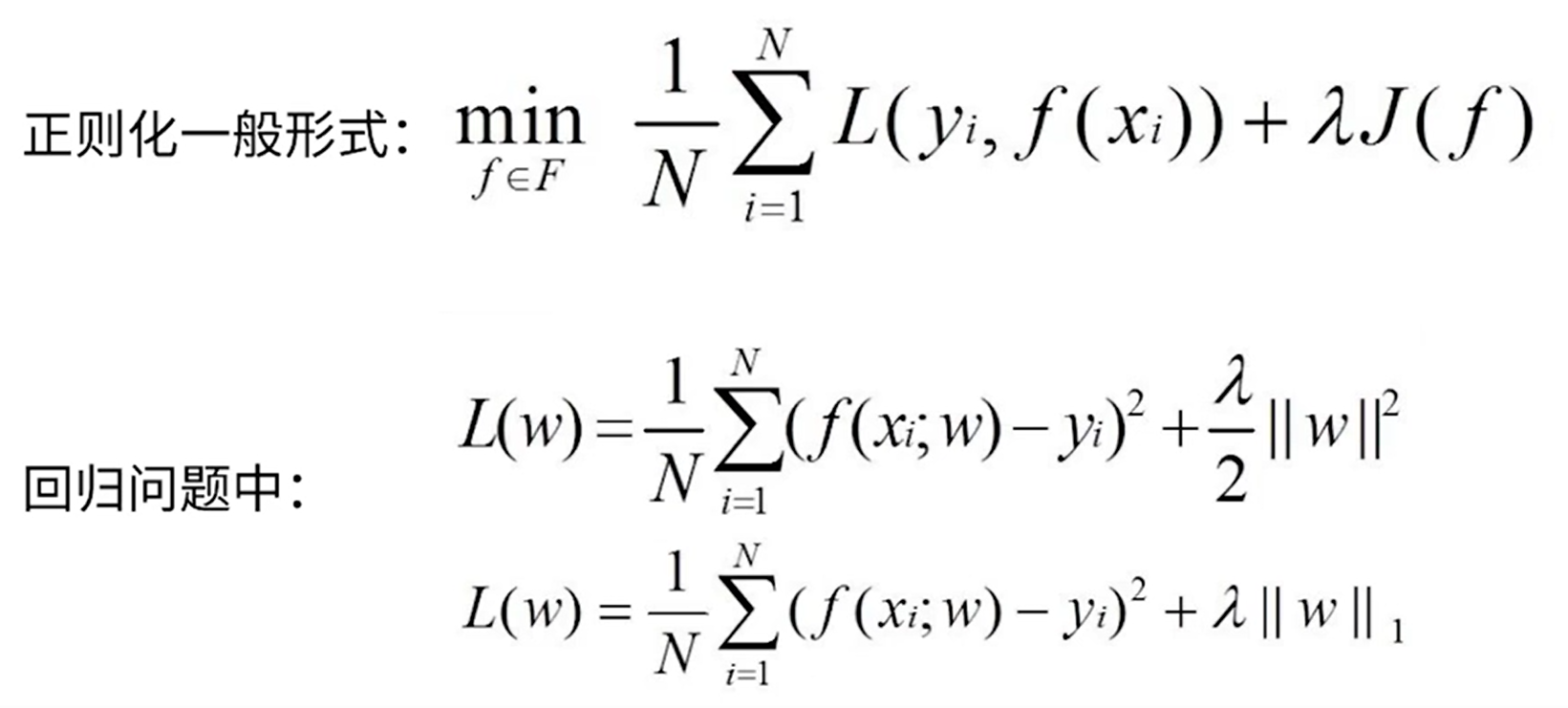
泛化能力
模型泛化能力:学习到的模型对未知数据的预测能力
通过研究泛化误差的概率上界进行对模型泛化能力的判定

生成模型与判别模型
监督学习方法分为生成方法和判别方法

生成模型: 学习收敛速度快,当样本容量增加时,学到的模型可以更快收敛;当存在隐变量时,可以用生成模型,而判别模型不行
判别模型:学习准确度更高;对数据进行抽象,定义特征和使用特征,可以简化学习问题