ReLU的变体
在深度学习中,ReLU(Rectified Linear Unit)是最常用的激活函数之一,但其存在一些局限性(如死亡ReLU问题)。为解决这些问题,研究者们提出了多种变体。以下是常见的ReLU变体及其核心特点:
一、基础ReLU及其问题
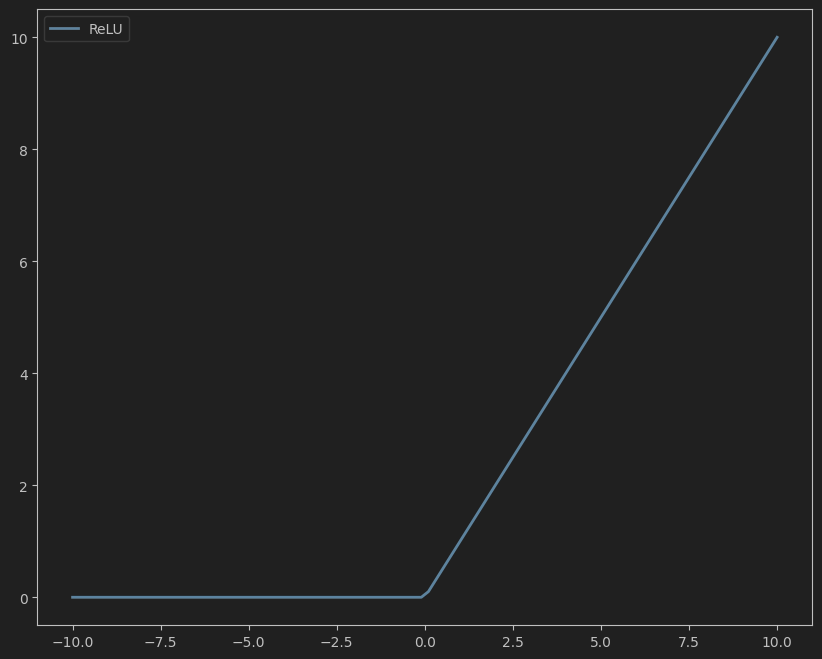
公式:
ReLU ( x ) = max ( 0 , x ) \text{ReLU}(x) = \max(0, x) ReLU(x)=max(0,x)
局限性:
- 死亡ReLU问题:当输入为负数时,梯度为0,导致神经元无法更新。
- 输出非零中心化:均值恒大于0,可能导致梯度更新不稳定。
二、主要变体
1. LeakyReLU(带泄露的ReLU)
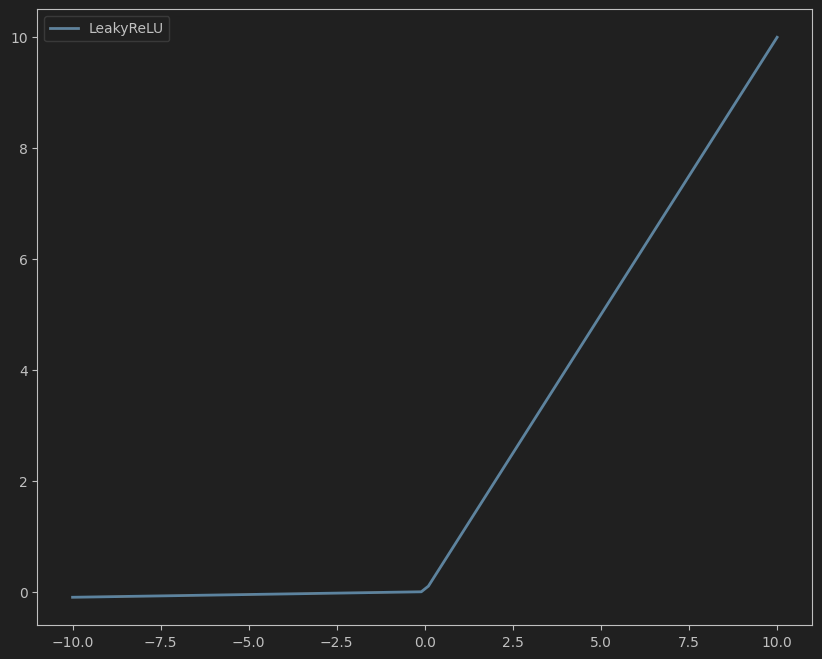
公式:
LeakyReLU ( x ) = { x , if x ≥ 0 α x , if x < 0 \text{LeakyReLU}(x) = \begin{cases} x, & \text{if } x \geq 0 \\ \alpha x, & \text{if } x < 0 \end{cases} LeakyReLU(x)={x,αx,if x≥0if x<0
其中 α \alpha α 是一个小的常数(如0.01),允许负数输入有非零梯度。
特点:
- 解决死亡ReLU问题,保证所有输入都有梯度。
- PyTorch实现:
nn.LeakyReLU(alpha)
2. PReLU(参数化ReLU)
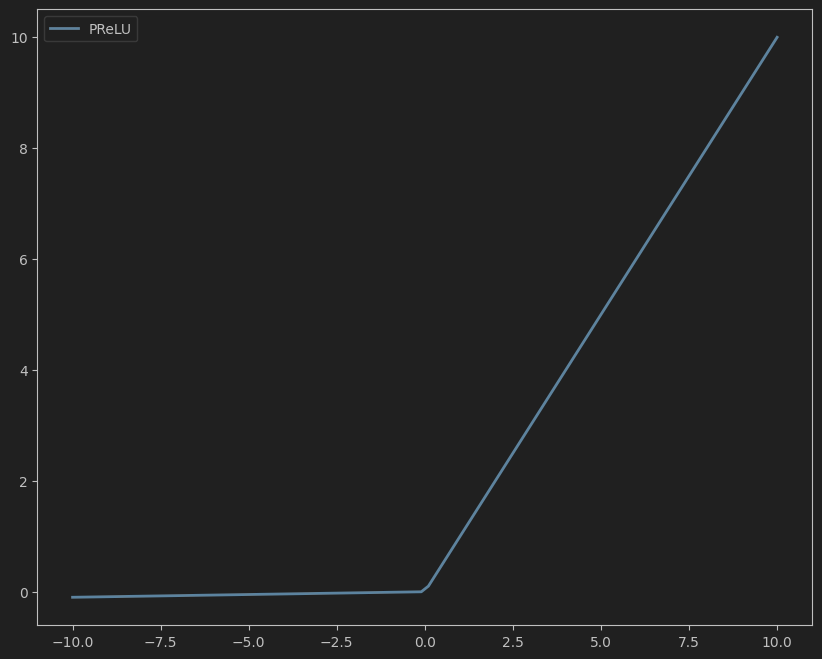
公式:
PReLU ( x ) = { x , if x ≥ 0 α x , if x < 0 \text{PReLU}(x) = \begin{cases} x, & \text{if } x \geq 0 \\ \alpha x, & \text{if } x < 0 \end{cases} PReLU(x)={x,αx,if x≥0if x<0
其中 α \alpha α 是可学习的参数,不同通道或神经元可拥有不同的 α \alpha α 值。
下面的prelu图像我设置了weight=0.01,所以初始的时候跟leaky_relu形状好像是一样的,不过prelu的weight可学习,后面能动态调整
特点:
- 比LeakyReLU更灵活,通过学习优化 α \alpha α 值。
- PyTorch实现:
nn.PReLU(num_parameters=1, init=0.25)
3. ELU(指数线性单元)
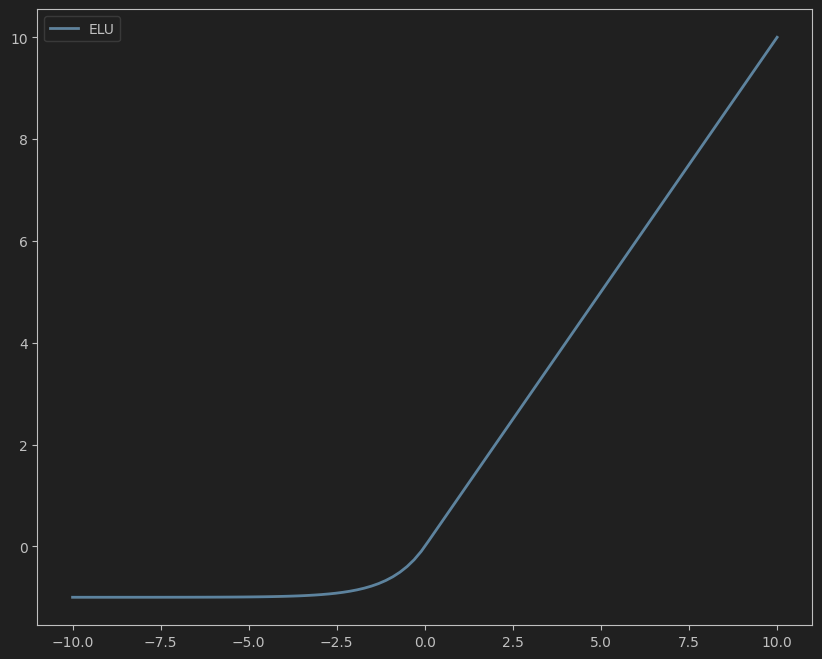
公式:
ELU ( x ) = { x , if x ≥ 0 α ( exp ( x ) − 1 ) , if x < 0 \text{ELU}(x) = \begin{cases} x, & \text{if } x \geq 0 \\ \alpha (\exp(x) - 1), & \text{if } x < 0 \end{cases} ELU(x)={x,α(exp(x)−1),if x≥0if x<0
其中 α \alpha α 是超参数,通常取1。
特点:
- 输出均值接近0,减轻梯度消失问题。
- 负值部分具有软饱和性,对噪声更鲁棒。
- PyTorch实现:
nn.ELU(alpha=1.0)
4. SELU(缩放指数线性单元)
公式:
SELU ( x ) = λ ⋅ { x , if x ≥ 0 α ( exp ( x ) − 1 ) , if x < 0 \text{SELU}(x) = \lambda \cdot \begin{cases} x, & \text{if } x \geq 0 \\ \alpha (\exp(x) - 1), & \text{if } x < 0 \end{cases} SELU(x)=λ⋅{x,α(exp(x)−1),if x≥0if x<0
其中 λ ≈ 1.0507 \lambda \approx 1.0507 λ≈1.0507 和 α ≈ 1.67326 \alpha \approx 1.67326 α≈1.67326 是固定!常量。
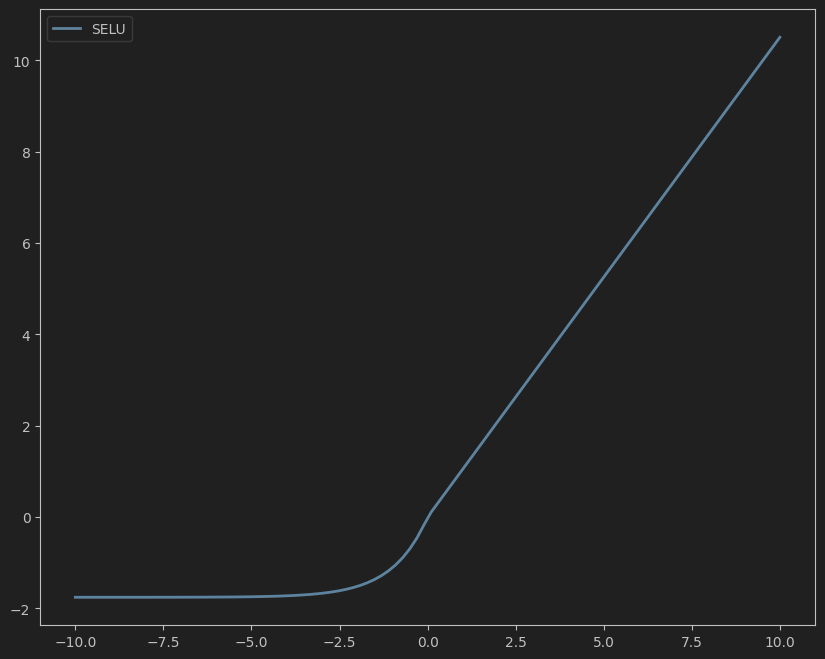
特点:
- 具有自归一化特性(Self-Normalizing),输入会自动保持均值为0、方差为1。
- 需配合高斯初始化使用,否则可能失效。
- PyTorch实现:
nn.SELU()
5. GELU(高斯误差线性单元)
公式:
GELU ( x ) = x ⋅ Φ ( x ) ≈ 0.5 x ( 1 + tanh ( 2 π ( x + 0.044715 x 3 ) ) ) \text{GELU}(x) = x \cdot \Phi(x) \approx 0.5x \left(1 + \tanh\left(\sqrt{\frac{2}{\pi}}(x + 0.044715x^3)\right)\right) GELU(x)=x⋅Φ(x)≈0.5x(1+tanh(π2(x+0.044715x3)))
其中 Φ ( x ) \Phi(x) Φ(x) 是标准正态分布的累积分布函数。
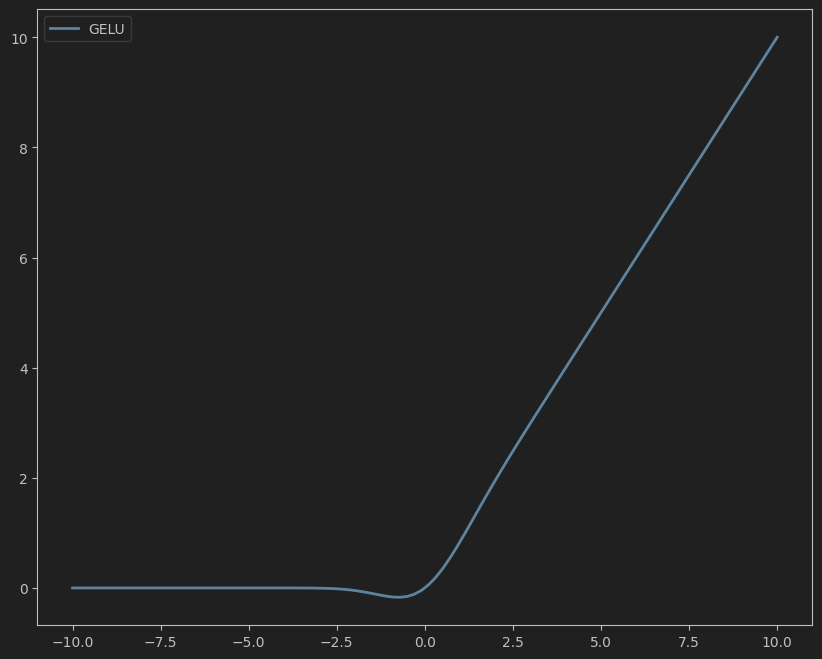
特点:
- 被广泛用于Transformer架构(如BERT、GPT)。
- 输入值越大,激活越“软”(相比ReLU的硬阈值)。
- PyTorch实现:
nn.GELU()
6. Swish/SiLU(自门控线性单元)
公式:
Swish ( x ) = x ⋅ σ ( x ) \text{Swish}(x) = x \cdot \sigma(x) Swish(x)=x⋅σ(x)
其中 σ ( x ) \sigma(x) σ(x) 是Sigmoid函数。
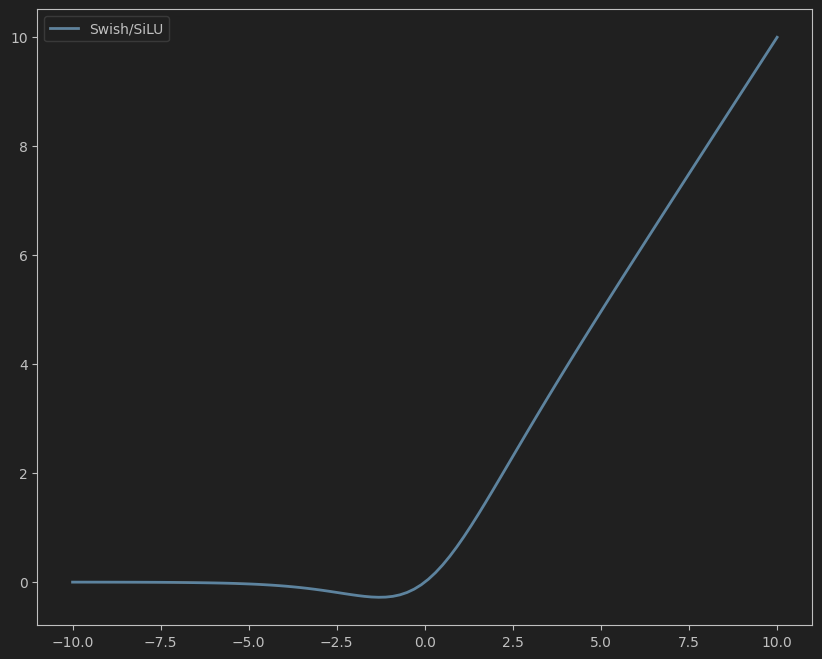
特点:
- 平滑连续,在深层网络中表现优于ReLU。
- 被证明具有自门控特性,类似LSTM中的门控机制。
- PyTorch实现:
nn.SiLU()(SiLU是Swish的别名)
7. Mish
公式:
Mish ( x ) = x ⋅ tanh ( softplus ( x ) ) = x ⋅ tanh ( ln ( 1 + exp ( x ) ) ) \text{Mish}(x) = x \cdot \tanh(\text{softplus}(x)) = x \cdot \tanh(\ln(1 + \exp(x))) Mish(x)=x⋅tanh(softplus(x))=x⋅tanh(ln(1+exp(x)))
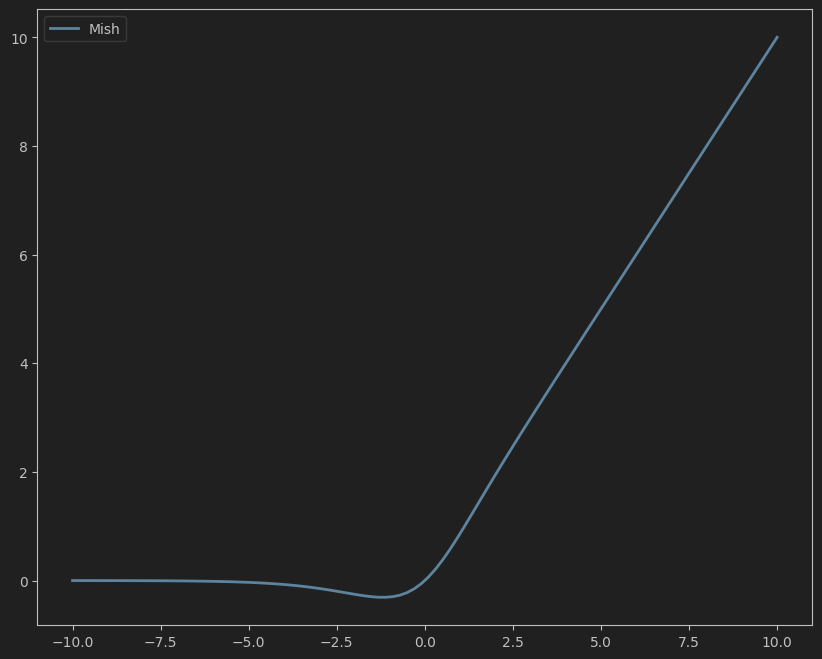
特点:
- 无上界、有下界,平滑连续,且在负值区域有轻微的非零梯度。
- 在图像、语音等任务中表现优异,但计算成本较高。
- PyTorch实现:
nn.Mish()
三、其他变体
- RReLU(随机LeakyReLU): α \alpha α 在训练时随机采样,测试时固定为均值,增强正则化效果。
- GeLU:GELU的近似版本,计算效率更高。
- Softplus: Softplus ( x ) = ln ( 1 + exp ( x ) ) \text{Softplus}(x) = \ln(1 + \exp(x)) Softplus(x)=ln(1+exp(x)),ReLU的平滑近似。
- ThresholdReLU:当输入超过阈值时才激活,否则输出0。
四、选择建议
| 场景 | 推荐激活函数 |
|---|---|
| 常规计算机视觉任务 | ReLU / LeakyReLU |
| 自然语言处理(Transformer) | GELU / Swish |
| 需要自归一化特性 | SELU |
| 对梯度消失敏感的深层网络 | ELU / Mish |
| 轻量级模型或边缘计算 | ReLU / LeakyReLU |
五、总结
ReLU变体通过引入负值区域的梯度(如LeakyReLU、PReLU)、平滑性(如GELU、Swish)或自归一化(如SELU)等特性,缓解了原始ReLU的局限性,提升了模型性能和训练稳定性。实际应用中,需根据任务特点和模型架构选择合适的激活函数。