MOT challenge使用方法及数据集说明
https://zhuanlan.zhihu.com/p/384838953
MOT challenge数据集介绍:
训练集和测试集:
一共8个视频序列,4个训练集,4个测试集。测试集的gt没有给出,因此想要得到测试集的结果需要在MOT官网上传你的结果去评估。 每个图片都是jpg格式,且命名为6个数字的文件如(000001.jpg) 平均每帧有246个行人。 除了行人,注释还包括车辆和自行车等其他类别。
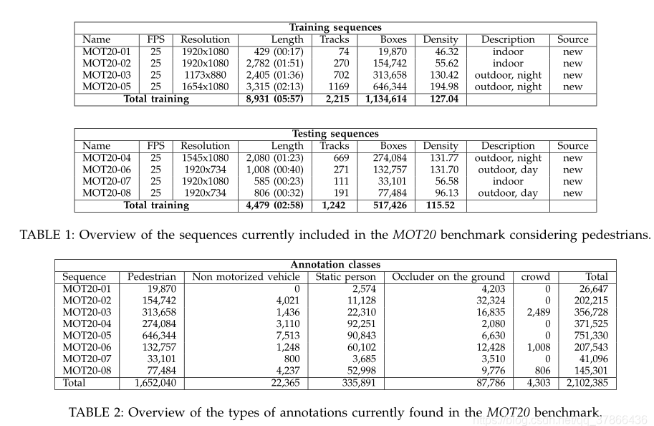
标注det.txt和gt.txt文件:
如下图所示,每一列分别代表一些信息
1:该目标出现的帧号
2:该目标被分配的唯一ID号,在det(检测)文件中为-1
3:目标bbox左上角的x坐标。
4:目标bbox左上角的y坐标。
5:目标bbox的宽
6:目标bbox的高
7:置信度。det中表示该目标是行人的概率,gt中若评估该目标则设为1,忽略则设置为0
8:gt中表示该目标的类别,Det为-1
9:可见率,gt中表示该目标可见的程度,可能被遮挡或者是图像边框裁剪导致目标不完整,值为0-1。det中为-1

det样例:

gt样例:
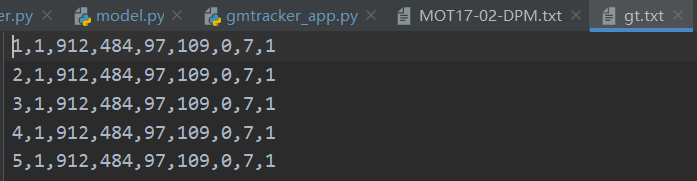
测试集提交格式:
每个视频序列一个txt文本,命名为sequence.txt,每一行表示一个目标,包含10个值,以,分割:<frame>,<id>,<bb_left>,<bb_top>,<bb_width>,<bb_height>,<conf>,<x>,<y>,<z>
前7个值和训练集的gt意义一样,conf填充1,最后3个值表示3D MOT,评估2D数据集时,最后3个值xyz填充为-1,同样,评估3D数据集时,将bbox4个值填充为-1
对应frame, id和bbox坐标都是从1开始,如下:
提交时,需要将所有视频序列的结果打包成zip,包括训练集,只需要将训练集的gt复制过来。
评估:
评价跟踪性能的好坏,MOTchallenge提供了一个评估脚本可以直接下载使用,点击网站,截止2021-06-26官方发布的最新的评估方法 数据关联 即预测和gt进行匹配。
评估tracker性能的好坏,有两个先决条件:
决定每个假设输出是TP还是FP
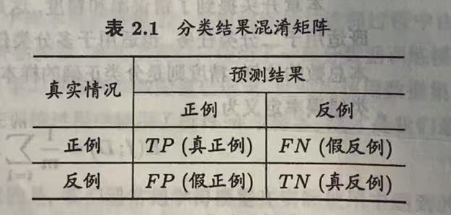
通过计算GT和预测的框的IOU,当大于阈值0.5时被评估是TP,小于阈值则为FP。
所有预测都没有找到GT中的目标,则被评估为FN,TN表示背景。
FN和FP越少表示结果越好。
很明显,很可能同一个目标会被多个假设匹配。在计算数字之前在一个GT最多对应一个假设,一个假设不能对应多个GT的限制下要建立GT和假设目标的对应关系。
细节:
①我们认为每个GT轨迹有唯一的开始和结束点,没有片段。当一个目标离开视野,又重新出现,被视为一个新的目标分配新的id。
②如果和假设
在第t-1帧时匹配,即使在第t帧
和
的距离低于阈值
,仍然将
,
匹配。
另请注意,虽然 id-sw的数量保持较低当然是可取的,但仅凭它们的绝对数量并不总是能表达评估整体性能,而应考虑恢复目标的数量。
举例说明:
4个例子表示匹配的情况。
每条虚线表示一个GT的轨迹,每条实线表示不同预测的轨迹,不同颜色表示不同ID,如红线表示ID1,蓝线表示ID2。
阴影部分表示GT和预测的阈值范围。阴影中的轨迹没有被涂黑的GT,表示没有预测和GT匹配被评估为FN,被涂黑的表示被跟踪到,实线连接的目标被涂成实心表示该ID和GT匹配成功,评估为TP。实线的空心被评估为FP,虚线的空心被评估为FN。
当GT在第t帧和ID2匹配成功,然而在第t-1帧和ID1匹配成功,即发生了ID转换。如(a)的4,5。
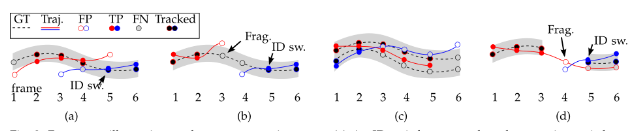
从图c可以看到,第三帧时蓝色轨迹和上面的GT轨迹距离最近但是还是将GT分配给了红色轨迹,是因为第二帧是红色轨迹和GT匹配成功,如果红色轨迹也在阈值范围内后面就优先匹配红色轨迹。
对比图a,第5帧时,红色轨迹在阈值外,蓝色轨迹最靠近GT且在阈值内,将GT分配给了蓝色轨迹,发生了id-sw。
图d,表示了re-id特征不够鲁棒,第5帧蓝色轨迹更靠近GT且第4帧GT轨迹断了,没有映射,因此将蓝色轨迹分配给GT,导致id-sw。
tracker-to-target分配算法:
①对所有帧,通过匈牙利算法匹配预测bbox和GT。
②相比于mot17,考虑了非常拥挤的情况,将预测框和distractor,static person, reflection, person on vehicle,class=(8,7,12,2)这些类别的gt overlap>0.75(注意:mot16-17是0.5)的框排除。
③在最终评估的时候,只使用被标注为pedestrains的框。
motmetrics对应code:
def eval_frame(self, frame_id, trk_tlwhs, trk_ids, rtn_events=False):# results 预测的bbox和idtrk_tlwhs = np.copy(trk_tlwhs)trk_ids = np.copy(trk_ids)# gtsgt_objs = self.gt_frame_dict.get(frame_id, [])gt_tlwhs, gt_ids = unzip_objs(gt_objs)[:2]# ignore boxesignore_objs = self.gt_ignore_frame_dict.get(frame_id, [])ignore_tlwhs = unzip_objs(ignore_objs)[0]# remove ignored resultskeep = np.ones(len(trk_tlwhs), dtype=bool)iou_distance = mm.distances.iou_matrix(ignore_tlwhs, trk_tlwhs, max_iou=0.5)# pdb.set_trace()# 从预测中剔除掉和需要忽略的gt相匹配的bboxif len(iou_distance) > 0:match_is, match_js = mm.lap.linear_sum_assignment(iou_distance)match_is, match_js = map(lambda a: np.asarray(a, dtype=int), [match_is, match_js])match_ious = iou_distance[match_is, match_js]match_js = np.asarray(match_js, dtype=int)match_js = match_js[np.logical_not(np.isnan(match_ious))] # 得到和需要忽略的gt匹配的预测下标keep[match_js] = Falsetrk_tlwhs = trk_tlwhs[keep]trk_ids = trk_ids[keep]# get distance matrixiou_distance = mm.distances.iou_matrix(gt_tlwhs, trk_tlwhs, max_iou=0.5)# accself.acc.update(gt_ids, trk_ids, iou_distance)if rtn_events and iou_distance.size > 0 and hasattr(self.acc, 'last_mot_events'):events = self.acc.last_mot_events # only supported by https://github.com/longcw/py-motmetricselse:events = Nonereturn events度量目标类别定义为沿着视野范围可达的没有物理遮挡的所有直立行走的人。
reflections,反射,在透明墙和窗户背后的人被排除。 骑自行车或者其他交通工具的人也被排除在目标类别之外。 在最终评估的时候只使用那些被标记为pedestrains的框。
定义:
MOTA:
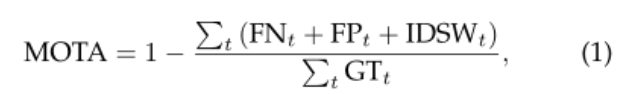
t是帧的下标, 表示t帧时ground truth的目标数量。MOTA的值域为(-∞, 100] 为负表示跟踪导致的错误的数量超过了场景中所有物体的总和。
MOTP:
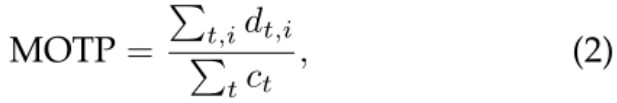
表示TP和对应的gt目标的边框重叠率,
表示t帧的匹配数量。
所以MOTP衡量的是位置精度,实际是检测器的定位精度,所以MOTP和跟踪器的表现关系不大。
Track quality measures 跟踪质量度量:
每个GT的轨迹可以被分为: - mostly tracked(MT) - partially tracked(PT) - mostly lost(ML) 这个度量不需要GT在整个轨迹中保持相同ID。 如果跟踪到的时间占gt的生命周期的80%,则被认为是MT,如果少于20%则被认为是ML,其他都是PT。 the number of track fragmentations(FM) 轨迹段的数量表示没有跟踪到的gt轨迹的次数。
MOT Challenge使用方法:
在官网点击右上角的log in
在MOT下方找到create a new method
![]()
![]()
点击Create a new method,填写对应的信息
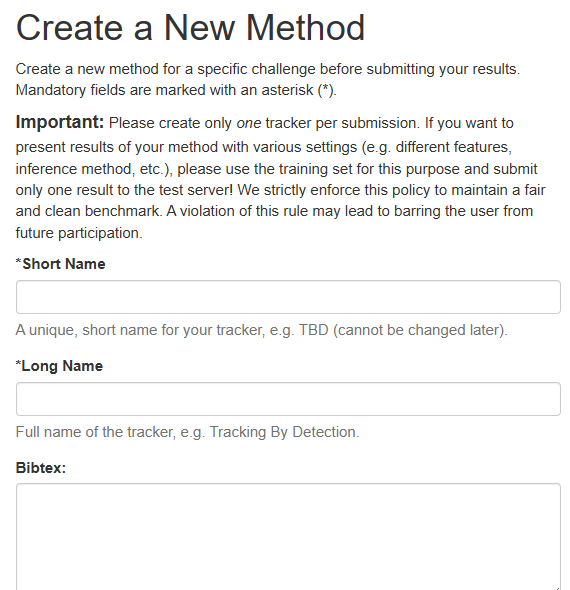
其中,shortname不能重复,需要起一个比较特殊的,填写后可以看到主页的MOT下面出现了刚刚建立的项目,此时所有的信息都是空的

点击类似于维修符号的按键,填写相关信息,其中benchmark可以选择我们使用的数据集MOT17,hardware填写上实验使用的cpu或gpu的数据,runtime需要用数字展示,可以将时间计算单位定义为秒
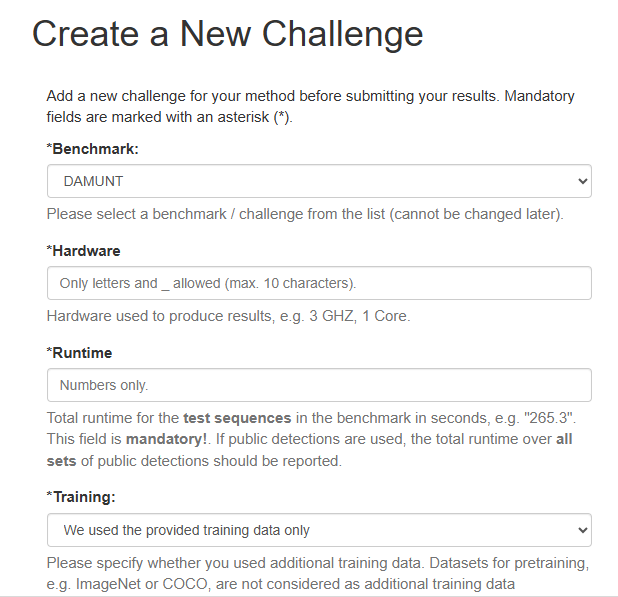
填写完毕后,可以在主页看到以下的更新

点击类似纸飞机的图标,滑到底部可以看到上传数据的字样

需要将得到的txt文本压缩成压缩包进行上传,同时注意它只接受42个txt,所以不能测试部分数据就上传。 提交时,需要将所有视频序列的结果打包成zip,包括训练集,只需要将训练集的gt复制过来。