NumPy:Python 科学计算的基石
在 Python 的广阔生态系统中,NumPy(Numerical Python)宛如一颗璀璨的明星,占据着至关重要的地位。它为 Python 提供了高效的数值计算能力,成为众多科学计算、数据分析和机器学习库的基础。无论是处理大规模数据集,还是进行复杂的数学运算,NumPy 都展现出了无可比拟的优势。
一、NumPy 的重要性与应用领域
1.1 科学计算的核心地位
NumPy 诞生于对高效数值计算的迫切需求。在 Python 发展早期,虽然其语法简洁、易于学习,但在处理大规模数值数据时,原生数据结构和运算速度显得力不从心。1995 年,Python 的特别兴趣小组 matrix-sig 成立,旨在定义一个数组计算包,Numeric 应运而生,后经 Travis Oliphant 整合 Numarray 的特性,于 2005 年正式创建了 NumPy。自此,它成为 Python 科学计算的核心库,极大地提升了 Python 在数值处理方面的性能。
如今,几乎所有涉及科学计算的 Python 项目都离不开 NumPy。它广泛应用于物理学、天文学、生物学等科研领域,例如在天体物理学中,科学家利用 NumPy 处理大量的天文观测数据,模拟星系演化等复杂过程;在生物学研究里,通过 NumPy 分析基因序列数据,探索生命奥秘。
1.2 数据分析的得力助手
在数据分析领域,NumPy 同样发挥着关键作用。随着数据量的爆炸式增长,高效的数据处理和分析成为了挑战。NumPy 提供了强大的数组操作功能,使得数据分析师能够快速地对大规模数据集进行清洗、转换和分析。例如,在金融数据分析中,分析师可以使用 NumPy 对股票价格、交易数据等进行处理,计算收益率、波动率等指标,为投资决策提供依据。
1.3 机器学习的基础支撑
机器学习算法的实现往往涉及大量的矩阵运算和数据处理。NumPy 的多维数组和高效的数学函数,为机器学习库如 scikit-learn、TensorFlow 和 PyTorch 等提供了坚实的基础。在机器学习模型的训练过程中,数据通常以数组的形式进行存储和处理,NumPy 的高效性确保了模型能够快速收敛,提高训练效率。例如,在图像识别任务中,图像数据被转换为 NumPy 数组,通过 NumPy 的操作对图像进行预处理、特征提取等操作,为后续的模型训练做好准备。
二、NumPy 的核心数据结构:ndarray
2.1 ndarray 的特点与优势
ndarray(n-dimensional array)即多维数组,是 NumPy 的核心数据结构。与 Python 原生的列表相比,ndarray 具有诸多显著优势。首先,ndarray 中的元素必须是相同类型的,这使得它在内存存储上更加紧凑和高效。在存储一个包含大量数字的列表时,Python 列表需要为每个元素单独分配内存空间,并且还要存储元素类型等额外信息,而 ndarray 可以将相同类型的元素连续存储在内存中,大大节省了内存空间。
其次,ndarray 支持矢量化运算,这意味着可以对整个数组进行操作,而无需编写显式的循环。这种矢量化运算在底层由优化的 C 代码实现,避免了 Python 循环的解释性开销,从而显著提高了运算速度。例如,计算两个数组对应元素的和,如果使用 Python 列表,需要通过循环逐个元素相加,而使用 ndarray 只需简单地将两个 ndarray 相加即可,运算速度提升可达数十倍甚至数百倍。
2.2 创建 ndarray 的多种方式
使用 np.array () 函数:这是创建 ndarray 最基本的方式,可以将 Python 列表、元组等序列转换为 ndarray。例如:
import numpy as np # 创建一维数组 arr1 = np.array([1, 2, 3, 4, 5]) print(arr1) # 创建二维数组 arr2 = np.array([[1, 2, 3], [4, 5, 6]]) print(arr2) |
创建特殊类型的数组:
全零数组:使用 np.zeros () 函数创建一个指定形状的全零数组。例如,创建一个 3 行 4 列的全零数组:
zeros_arr = np.zeros((3, 4)) print(zeros_arr) |
- 全一数组:通过 np.ones () 函数创建全一数组。如创建一个 2 行 3 列的全一数组:
ones_arr = np.ones((2, 3)) print(ones_arr) |
- 单位矩阵:利用 np.eye () 函数生成单位矩阵。例如,生成一个 3x3 的单位矩阵:
eye_arr = np.eye(3) print(eye_arr) |
- 等差数列数组:借助 np.arange () 函数可以创建在给定间隔内具有一定步长的整数数组。例如,创建从 5 到 10(不包含 10),步长为 2 的数组:
np.arange(5, 10, 2) |
- 等间隔浮点数数组:使用 np.linspace () 函数在指定的区间内生成均匀间隔的数字。例如,在 0 到 1 之间生成 5 个均匀分布的数字:
linspace_arr = np.linspace(0, 1, 5) print(linspace_arr) |
- 随机数组:通过 np.random 模块可以生成各种分布的随机数组。比如,生成一个 2 行 3 列的均匀分布随机数组:
random_arr = np.random.rand(2, 3) print(random_arr) |
2.3 ndarray 的属性
ndarray 具有多个重要属性,这些属性可以帮助我们了解数组的结构和数据特征。
shape:用于获取数组的形状,返回一个元组,元组的每个元素表示对应维度的大小。例如:
arr = np.array([[1, 2, 3], [4, 5, 6]]) print(arr.shape) # 输出 (2, 3),表示2行3列 |
dtype:返回数组中元素的数据类型。例如:
arr = np.array([1, 2, 3]) print(arr.dtype) # 输出 int64 |
size:表示数组中元素的总数,等于 shape 属性中各维度大小的乘积。例如:
arr = np.array([[1, 2, 3], [4, 5, 6]]) print(arr.size) # 输出 6 |
ndim:返回数组的维度数,即秩。例如:
arr = np.array([1, 2, 3]) print(arr.ndim) # 输出 1,一维数组 arr = np.array([[1, 2, 3], [4, 5, 6]]) print(arr.ndim) # 输出 2,二维数组 |
itemsize:以字节为单位返回数组中每个元素的大小。例如:
arr = np.array([1, 2, 3], dtype=np.int32) print(arr.itemsize) # 输出 4,因为int32类型占4个字节 |
三、NumPy 的强大功能
3.1 数组的索引与切片
一维数组的索引与切片:与 Python 列表类似,ndarray 可以通过索引访问单个元素,索引从 0 开始。例如:
arr = np.array([1, 2, 3, 4, 5]) print(arr[0]) # 输出第一个元素 1 print(arr[1:4]) # 输出第2到第4个元素,结果为 [2 3 4] |
二维数组的索引与切片:对于二维数组,需要使用两个索引来访问元素,第一个索引表示行,第二个索引表示列。例如:
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) print(arr[0, 1]) # 输出第1行第2列的元素 2 print(arr[:, 1]) # 输出第2列的所有元素,结果为 [2 5 8] print(arr[1:3, 0:2]) # 输出第2到第3行,第1到第2列的子数组 |
3.2 数组的运算
算术运算:NumPy 支持对数组进行各种算术运算,如加、减、乘、除等。这些运算都是逐元素进行的,即对应位置的元素进行相应运算。例如:
arr1 = np.array([1, 2, 3]) arr2 = np.array([4, 5, 6]) print(arr1 + arr2) # 输出 [5 7 9] print(arr1 - arr2) # 输出 [-3 -3 -3] print(arr1 * arr2) # 输出 [4 10 18] print(arr1 / arr2) # 输出 [0.25 0.4 0.5] |
逻辑运算:可以对数组进行逻辑运算,如大于、小于、等于等。逻辑运算同样是逐元素进行的,返回一个布尔值数组。例如:
arr = np.array([1, 2, 3, 4, 5]) print(arr > 3) # 输出 [False False False True True] print(arr == 2) # 输出 [False True False False False] |
数学函数运算:NumPy 提供了丰富的数学函数,如三角函数、指数函数、对数函数等,可以直接应用于数组。例如:
arr = np.array([0, np.pi/2, np.pi]) print(np.sin(arr)) # 输出 [0. 1. 0.] arr = np.array([1, 2, 3]) print(np.exp(arr)) # 输出 [ 2.71828183 7.3890561 20.08553692] print(np.log(arr)) # 输出 [0. 0.69314718 1.09861229] |
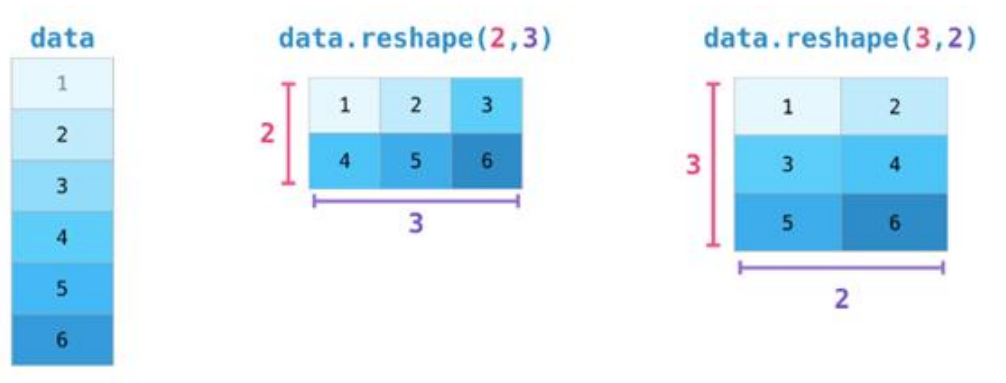
3.3 数组的变形与重塑
reshape () 函数:使用 reshape () 函数可以改变数组的形状,前提是新形状的元素总数与原数组相同。例如,将一个一维数组转换为二维数组:
arr = np.array([1, 2, 3, 4, 5, 6]) reshaped_arr = arr.reshape(2, 3) print(reshaped_arr) |
flatten () 函数:flatten () 函数用于将多维数组展平为一维数组。例如:
arr = np.array([[1, 2], [3, 4]]) flattened_arr = arr.flatten() print(flattened_arr) # 输出 [1 2 3 4] |
transpose () 函数:transpose () 函数用于对数组进行转置,对于二维数组,相当于交换行和列。例如:
arr = np.array([[1, 2], [3, 4]]) transposed_arr = np.transpose(arr) print(transposed_arr) # 输出 [[1 3] [2 4]] |
3.4 数组的拼接与分割
拼接数组:可以使用 np.concatenate () 函数沿指定轴拼接多个数组。例如,沿行方向拼接两个二维数组:
arr1 = np.array([[1, 2], [3, 4]]) arr2 = np.array([[5, 6], [7, 8]]) concatenated_arr = np.concatenate((arr1, arr2), axis=0) print(concatenated_arr) |
也可以沿列方向拼接:
concatenated_arr = np.concatenate((arr1, arr2), axis=1) print(concatenated_arr) |
分割数组:通过 np.split () 函数可以将数组沿指定轴分割成多个子数组。例如,将一个二维数组沿行方向平均分割成 3 个子数组:
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) split_arr = np.split(arr, 3, axis=0) print(split_arr) |
3.5 数组的统计计算
求和:使用 np.sum () 函数计算数组元素的总和。可以指定 axis 参数来计算沿某个轴的和。例如,计算二维数组每列的和:
arr = np.array([[1, 2, 3], [4, 5, 6]]) print(np.sum(arr, axis=0)) # 输出 [5 7 9] |
计算每行的和:
print(np.sum(arr, axis=1)) # 输出 [6 15] |
求平均值:np.mean () 函数用于计算数组元素的平均值。同样可以指定 axis 参数。例如,计算数组的平均值:
arr = np.array([1, 2, 3, 4, 5]) print(np.mean(arr)) # 输出 3.0 |
求中位数:通过 np.median () 函数获取数组的中位数。例如:
arr = np.array([1, 2, 3, 4, 5]) print(np.median(arr)) # 输出 3 |
求最大值和最小值:使用 np.max () 和 np.min () 函数分别获取数组的最大值和最小值。例如:
arr = np.array([1, 2, 3, 4, 5]) print(np.max(arr)) # 输出 5 print(np.min(arr)) # 输出 1 |
还可以使用 np.argmax () 和 np.argmin () 函数获取最大值和最小值的索引。例如:
arr = np.array([1, 3, 2, 5, 4]) print(np.argmax(arr)) # 输出 3,即最大值5的索引 print(np.argmin(arr)) # 输出 0,即最小值1的索引 |
3.6 线性代数运算
矩阵乘法:在 NumPy 中,使用 np.dot () 函数进行矩阵乘法运算。例如:
arr1 = np.array([[1, 2], [3, 4]]) arr2 = np.array([[5, 6], [7, 8]]) result = np.dot(arr1, arr2) print(result) |
求逆矩阵:对于方阵,可以使用 np.linalg.inv () 函数求其逆矩阵。例如:
arr = np.array([[1, 2], [3, 4]]) inv_arr = np.linalg.inv(arr) print(inv_arr) |
求特征值和特征向量:通过 np.linalg.eig () 函数可以计算方阵的特征值和特征向量。例如:
arr = np.array([[1, 2], [3, 4]]) eigenvalues, eigenvectors = np.linalg.eig(arr) print("特征值:", eigenvalues) print("特征向量:", eigenvectors) |
3.7 随机数生成
均匀分布随机数:使用 np.random.uniform () 函数生成在指定范围内均匀分布的随机数。例如,生成一个 2 行 3 列,范围在 5 到 10 之间的均匀分布随机数数组:
np.random.uniform(5, 10, size=(2, 3)) |
正态分布随机数:通过 np.random.normal () 函数生成符合正态分布的随机数。例如,生成一个均值为 0,标准差为 1 的正态分布随机数数组:
np.random.normal(0, 1, size=(2, 3)) |
随机整数:使用 np.random.randint () 函数生成指定范围内的随机整数。例如,生成 10 个范围在 5 到 10 之间的随机整数:
np.random.randint(5, 10, 10) |
3.8 广播机制
广播机制是 NumPy 的一个强大特性,它允许不同形状的数组进行算术运算。当两个数组进行运算时,如果它们的形状不相同,NumPy 会尝试对它们进行广播,使得它们能够进行运算。广播的规则如下:
- 从后向前比较两个数组的形状,如果对应维度的大小相同,或者其中一个数组在该维度的大小为 1,则可以进行广播。
- 如果某个维度的大小不满足上述条件,则广播失败。
例如,一个形状为 (3, 1) 的数组和一个形状为 (1, 4) 的数组可以进行广播,得到一个形状为 (3, 4) 的结果。
arr1 = np.array([[1], [2], [3]]) arr2 = np.array([4, 5, 6, 7]) result = arr1 + arr2 print(result) |
在这个例子中, arr1 的形状为 (3, 1),arr2 的形状为 (1, 4),在进行加法运算时,NumPy 会自动将 arr1 沿列方向复制 4 次,将 arr2 沿行方向复制 3 次,从而得到一个形状为 (3, 4) 的结果数组。广播机制极大地简化了不同形状数组之间的运算,提高了代码的简洁性和运算效率。
四、NumPy 在实际项目中的应用案例
4.1 数据预处理中的应用
在一个电商销售数据分析项目中,原始数据以 CSV 文件形式存储,包含了大量的销售记录,如订单号、客户 ID、购买时间、商品名称、价格、数量等信息。在对这些数据进行分析之前,需要进行数据预处理,其中涉及到大量的数组操作。
首先,使用 NumPy 读取 CSV 文件数据并转换为 ndarray 数组。例如:
import numpy as np data = np.genfromtxt('sales_data.csv', delimiter=',', skip_header=1) |
这里 np.genfromtxt() 函数用于从文本文件中读取数据,delimiter=',' 指定了字段之间的分隔符为逗号,skip_header=1 表示跳过文件的第一行(通常为表头)。
假设数据中存在一些缺失值,用 -1 表示。可以使用 NumPy 来查找并处理这些缺失值。例如,统计缺失值的数量:
missing_count = np.count_nonzero(data == -1) print("缺失值数量:", missing_count) |
然后,可以将缺失值替换为该列的平均值。先找到包含缺失值的列,再计算每列的平均值并进行替换:
for col in range(data.shape[1]): col_data = data[:, col] valid_data = col_data[col_data != -1] if len(valid_data) > 0: mean_value = np.mean(valid_data) data[:, col][data[:, col] == -1] = mean_value |
此外,还可能需要对数据进行标准化处理,以便后续的数据分析和建模。例如,对价格列进行标准化:
price_col = data[:, 4] price_mean = np.mean(price_col) price_std = np.std(price_col) data[:, 4] = (price_col - price_mean) / price_std |
通过这些 NumPy 操作,有效地对原始销售数据进行了清洗和预处理,为后续的深入分析奠定了基础。
4.2 机器学习模型训练中的应用
在一个简单的线性回归模型训练中,使用 NumPy 来处理数据和实现模型的训练过程。假设有一组房屋面积和价格的数据,用于训练一个预测房屋价格的线性回归模型。
首先,准备数据。将房屋面积存储在一个 ndarray 中作为特征 X,将对应的价格存储在另一个 ndarray 中作为标签 y:
X = np.array([[100], [120], [150], [80], [130]]) y = np.array([200, 220, 250, 180, 230]) |
接下来,初始化线性回归模型的参数 w(权重)和 b(偏置),并设置学习率 learning_rate 和迭代次数 num_iterations:
w = np.zeros((1, 1)) b = 0 learning_rate = 0.001 num_iterations = 1000 |
在训练过程中,通过不断迭代来更新参数 w 和 b,以最小化损失函数(这里使用均方误差损失函数)。每次迭代需要计算预测值、误差和梯度,这些计算都可以利用 NumPy 的高效数组运算来实现:
for i in range(num_iterations): y_pred = np.dot(X, w) + b error = y_pred - y m = len(X) gradient_w = (1 / m) * np.dot(X.T, error) gradient_b = (1 / m) * np.sum(error) w = w - learning_rate * gradient_w b = b - learning_rate * gradient_b |
在这个例子中,np.dot() 函数用于矩阵乘法,计算预测值 y_pred;np.sum() 函数用于计算误差的总和,从而得到梯度。通过 NumPy 的矢量化运算,大大提高了模型训练的效率。经过训练后,得到的参数 w 和 b 就可以用于预测新的房屋价格。
4.3 科学计算中的应用:模拟布朗运动
布朗运动是一种随机运动,在物理学、金融等领域有广泛应用。使用 NumPy 可以方便地模拟布朗运动。
布朗运动的位移可以用以下公式表示:
X(t) = X(0) + \sum_{i=1}^{n} \epsilon_i \sqrt{\Delta t}
其中 X(0) 是初始位置, \epsilon_i 是服从标准正态分布的随机数, \Delta t 是时间间隔。
下面是使用 NumPy 模拟布朗运动的代码:
import numpy as np import matplotlib.pyplot as plt # 模拟参数 num_steps = 1000 dt = 0.01 initial_position = 0 # 生成服从标准正态分布的随机数 epsilon = np.random.normal(0, 1, num_steps) # 计算位移 displacements = epsilon * np.sqrt(dt) # 计算位置 positions = np.cumsum(displacements) + initial_position # 绘制布朗运动轨迹 plt.plot(np.arange(num_steps) * dt, positions) plt.xlabel('时间 t') plt.ylabel('位置 X(t)') plt.title('布朗运动模拟') plt.show() |
在这段代码中,首先使用 np.random.normal() 生成服从标准正态分布的随机数 epsilon,然后计算位移 displacements,通过 np.cumsum() 函数计算累积位移得到位置 positions,最后使用 matplotlib 库绘制布朗运动的轨迹。通过这样的模拟,可以深入研究布朗运动的特性,如扩散系数等,为相关领域的研究提供支持。
五、NumPy 的扩展与生态系统
5.1 与其他科学计算库的集成
1.与 SciPy 的协同工作:SciPy 是基于 NumPy 构建的更为高级的科学计算库,它在 NumPy 的基础上提供了更多的功能,如优化算法、线性代数求解、信号处理、图像处理等。例如,在求解线性方程组时,NumPy 提供了基本的矩阵运算功能,而 SciPy 的 scipy.linalg 模块则提供了更高效、更全面的线性方程组求解方法。假设我们有一个线性方程组 Ax = b ,其中 A 是系数矩阵, b 是常数向量,可以使用以下代码求解:
import numpy as np from scipy import linalg A = np.array([[1, 2], [3, 4]]) b = np.array([5, 6]) x = linalg.solve(A, b) print("线性方程组的解:", x) |
这里 linalg.solve() 函数利用了 SciPy 底层优化的算法来求解线性方程组,比单纯使用 NumPy 的矩阵运算更加高效和准确。
2. 与 Pandas 的数据处理整合:Pandas 是专门用于数据处理和分析的库,它与 NumPy 紧密集成。Pandas 的核心数据结构 DataFrame 和 Series 内部都是基于 NumPy 的 ndarray 实现的。在数据处理过程中,常常需要将 Pandas 数据转换为 NumPy 数组进行更高效的数值计算,或者将 NumPy 计算结果转换回 Pandas 数据结构进行进一步的分析和展示。例如,从 Pandas 的 DataFrame 中提取某一列数据转换为 NumPy 数组进行计算:
import pandas as pd import numpy as np data = {'col1': [1, 2, 3, 4, 5]} df = pd.DataFrame(data) col_data = df['col1'].to_numpy() result = np.mean(col_data) * 2 print("计算结果:", result) |
反过来,也可以将 NumPy 数组转换为 Pandas 的 Series 或 DataFrame:
arr = np.array([6, 7, 8, 9, 10]) new_series = pd.Series(arr) print("转换后的Series:", new_series) |
这种紧密的集成使得在数据处理和分析过程中可以充分发挥两者的优势,先使用 Pandas 进行数据清洗、整理和初步分析,再利用 NumPy 进行高效的数值计算,最后将结果用 Pandas 进行可视化和进一步的处理。
3. 与 Matplotlib 的可视化结合:Matplotlib 是 Python 中常用的绘图库,用于数据可视化。NumPy 提供的数据处理和计算能力与 Matplotlib 的可视化功能相得益彰。在绘制各种图表时,数据往往需要先经过 NumPy 的处理和计算,然后再传递给 Matplotlib 进行绘制。例如,绘制一个简单的折线图,展示一组数据的变化趋势:
import numpy as np import matplotlib.pyplot as plt x = np.array([1, 2, 3, 4, 5]) y = np.array([2, 4, 6, 8, 10]) plt.plot(x, y) plt.xlabel('X轴') plt.ylabel('Y轴') plt.title('简单折线图') plt.show() |
在更复杂的可视化场景中,如绘制三维图形、统计图表等,也经常需要使用 NumPy 对数据进行变换、计算统计量等操作,然后再利用 Matplotlib 的丰富绘图函数进行可视化展示。通过这种结合,能够将 NumPy 处理后的数据以直观、清晰的图表形式呈现出来,帮助用户更好地理解数据的特征和规律。
5.2 常用的 NumPy 扩展库
1.Numba:Numba 是一个用于 Python 的即时编译器,它可以显著提高 NumPy 代码的执行速度。Numba 能够将 Python 函数编译为机器码,特别是针对包含大量 NumPy 数组操作的函数。例如,对于一个简单的计算数组元素平方和的函数:
import numpy as np from numba import jit @jit(nopython=True) def sum_of_squares(arr): result = 0 for i in range(len(arr)): result += arr[i] ** 2 return result arr = np.array([1, 2, 3, 4, 5]) print("平方和:", sum_of_squares(arr)) |
在这个例子中,使用 @jit(nopython=True) 装饰器将函数 sum_of_squares 编译为机器码,nopython=True 表示强制 Numba 使用纯机器码编译,不依赖 Python 解释器,从而大大提高了函数的执行效率。对于大规模数组的复杂计算,Numba 的加速效果尤为明显,能够将原本可能需要较长时间运行的代码在短时间内完成计算。
2. Scikit - learn:虽然 Scikit - learn 主要是一个机器学习库,但它在底层大量依赖 NumPy 进行数据处理和计算。Scikit - learn 中的数据通常以 NumPy 的 ndarray 或 Pandas 的 DataFrame 形式存储和传递。例如,在使用 Scikit - learn 的线性回归模型进行数据拟合时:
from sklearn.linear_model import LinearRegression import numpy as np X = np.array([[1], [2], [3], [4], [5]]).reshape(-1, 1) y = np.array([2, 4, 6, 8, 10]) model = LinearRegression() model.fit(X, y) |
这里输入的数据 X 和 y 都是 NumPy 数组,Scikit - learn 在模型训练和预测过程中,会利用 NumPy 的高效数组运算来完成各种操作,如矩阵乘法、数据变换等。Scikit - learn 基于 NumPy 构建,使得机器学习算法的实现更加高效和便捷,同时也借助了 NumPy 在科学计算领域的成熟度和广泛应用。
3. TensorFlow 和 PyTorch:这两个深度学习框架也与 NumPy 有着密切的联系。在深度学习项目中,数据的预处理和后处理阶段经常需要在 NumPy 数组和框架特有的张量(Tensor)之间进行转换。例如,在 TensorFlow 中,可以将 NumPy 数组转换为 TensorFlow 的张量:
import numpy as np import tensorflow as tf arr = np.array([1, 2, 3, 4, 5]) tensor = tf.constant(arr) |
反过来,也可以将张量转换回 NumPy 数组进行进一步处理:
result = tensor.numpy() |
在 PyTorch 中,同样支持类似的转换操作:
import numpy as np import torch arr = np.array([1, 2, 3, 4, 5]) tensor = torch.from_numpy(arr) result = tensor.numpy() |
这种紧密的联系使得开发者可以充分利用 NumPy 的数据处理能力进行数据的准备和分析,然后无缝地将数据导入到深度学习框架中进行模型训练和推理,提高了深度学习项目的开发效率和灵活性。
六、总结与展望
6.1 NumPy 的重要性回顾
NumPy 作为 Python 科学计算的基石,其重要性不言而喻。它通过高效的 ndarray 数据结构和丰富的函数库,为 Python 提供了强大的数值计算能力。从简单的数据处理和分析,到复杂的科学研究、机器学习模型训练以及各种模拟实验,NumPy 都扮演着不可或缺的角色。其优势不仅体现在提高了代码的执行效率,减少了开发时间,还在于它为众多其他科学计算库和框架提供了基础支持,促进了整个 Python 科学计算生态系统的繁荣发展。
6.2 未来发展趋势展望
随着数据量的不断增长和科学计算需求的日益复杂,NumPy 也在不断发展和演进。未来,我们可以期待 NumPy 在以下几个方面取得进一步突破:
- 性能优化持续提升:NumPy 的开发者们将继续致力于优化底层代码,提高数组操作的执行速度。例如,通过利用最新的硬件特性,如多核处理器、GPU 加速等,进一步提升 NumPy 在大规模数据处理和复杂计算场景下的性能。同时,在算法优化方面,也会不断探索更高效的数值计算方法,以满足日益增长的计算需求。
- 功能扩展与完善:随着新的科学计算领域和应用场景的不断涌现,NumPy 有望增加更多的功能。比如,在处理高维数据、稀疏数据以及分布式数据等方面,可能会提供更强大、更便捷的解决方案。此外,对于一些新兴的科学计算方向,如量子计算模拟、生物信息学中的复杂数据分析等,NumPy 可能会针对性地开发新的函数和工具,以更好地支持这些领域的研究和应用。
- 与其他领域的深度融合:NumPy 将与更多的领域进行深度融合,如人工智能、大数据、物联网等。在人工智能领域,除了现有的与机器学习和深度学习框架的紧密合作外,可能会在强化学习、自然语言处理等细分领域发挥更重要的作用,为相关算法的实现提供更高效的数据处理和计算支持。在大数据领域,NumPy 可能会与分布式计算框架更好地集成,实现对大规模分布式数据的高效处理。在物联网领域,NumPy 可以用于处理传感器采集到的大量实时数据,为数据分析和决策提供基础。
- 易用性和可访问性增强:尽管 NumPy 已经具有较高的易用性,但未来可能会进一步改进其 API 设计,使其更加简洁、直观,降低初学者的学习门槛。同时,在文档和教程方面,也会更加完善和丰富,提供更多的示例和解释,帮助用户更好地理解和使用 NumPy 的各种功能。此外,可能会出现更多基于 NumPy 的可视化工具和交互式界面,让用户能够更直观地探索和分析数据,提高数据处理和分析的效率。
总之,NumPy 在 Python 科学计算领域的地位将持续稳固,并在未来的发展中不断焕发出新的活力,为科学研究、数据分析和技术创新等各个领域提供更加强大的支持和动力。希望通过本文的介绍,读者能够对 NumPy 有更深入的理解和掌握,在自己的工作和学习中充分发挥 NumPy 的优势,解决各种复杂的问题。