Leetcode刷题 | Day67_图论12_Floyd算法 / A*算法
一、学习任务
- Floyd 算法代码随想录
- A * 算法(A star算法)A * 算法精讲 (A star算法) | 代码随想录
二、具体题目
1.Floyd 算法97. 小明逛公园
【题目描述】
小明喜欢去公园散步,公园内布置了许多的景点,相互之间通过小路连接,小明希望在观看景点的同时,能够节省体力,走最短的路径。
给定一个公园景点图,图中有 N 个景点(编号为 1 到 N),以及 M 条双向道路连接着这些景点。每条道路上行走的距离都是已知的。
小明有 Q 个观景计划,每个计划都有一个起点 start 和一个终点 end,表示他想从景点 start 前往景点 end。由于小明希望节省体力,他想知道每个观景计划中从起点到终点的最短路径长度。 请你帮助小明计算出每个观景计划的最短路径长度。
【输入描述】
第一行包含两个整数 N, M, 分别表示景点的数量和道路的数量。
接下来的 M 行,每行包含三个整数 u, v, w,表示景点 u 和景点 v 之间有一条长度为 w 的双向道路。
接下里的一行包含一个整数 Q,表示观景计划的数量。
接下来的 Q 行,每行包含两个整数 start, end,表示一个观景计划的起点和终点。
【输出描述】
对于每个观景计划,输出一行表示从起点到终点的最短路径长度。如果两个景点之间不存在路径,则输出 -1。
本题是经典的多源最短路问题。
在这之前我们讲解过,dijkstra朴素版、dijkstra堆优化、Bellman算法、Bellman队列优化(SPFA) 都是单源最短路,即只能有一个起点。
而本题是多源最短路,即 求多个起点到多个终点的多条最短路径。
新的最短路算法-Floyd 算法。
Floyd 算法对边的权值正负没有要求,都可以处理。
Floyd算法核心思想是动态规划。
核心思想
Floyd算法要解决的问题:在一个有权图中,找到任意两点间的最短路径。
四步详解
1. DP数组定义
grid[i][j][k] = 从节点i到节点j,只允许经过编号≤k的节点作为中介的最短距离关键理解:k不是单个节点,而是一个"许可集合" {1,2,...,k}
- 当k=0时:不允许经过任何中介节点(直连)
- 当k=1时:只允许经过节点1作为中介
- 当k=2时:允许经过节点1或2作为中介
2. 状态转移方程
对于每个k,考虑两种情况:
grid[i][j][k] = min(grid[i][j][k-1], grid[i][k][k-1] + grid[k][j][k-1]);
// 不经过节点k/经过节点k逻辑:要么最优路径不经过k,要么经过k(此时分解为i→k + k→j)
3. 初始化
vector<vector<vector<int>>> grid(n + 1, vector<vector<int>>(n + 1, vector<int>(n + 1, 10005))); // 因为边的最大距离是10^4,无直接连接直接设为最大值for(int i = 0; i < m; i++){cin >> p1 >> p2 >> val;grid[p1][p2][0] = val;grid[p2][p1][0] = val; // 注意这里是双向图4. 遍历顺序
for (int k = 1; k <= n; k++) { // 最外层:逐步放开中介节点限制for (int i = 1; i <= n; i++) { // 遍历所有起点for (int j = 1; j <= n; j++) { // 遍历所有终点grid[i][j][k] = min(grid[i][j][k-1], grid[i][k][k-1] + grid[k][j][k-1]);}}}为什么k在最外层:因为计算k层需要完整的(k-1)层数据,必须逐层计算。
#include <iostream>
#include <vector>
#include <list>
using namespace std;int main() {int n, m, p1, p2, val;cin >> n >> m;vector<vector<vector<int>>> grid(n + 1, vector<vector<int>>(n + 1, vector<int>(n + 1, 10005))); // 因为边的最大距离是10^4for(int i = 0; i < m; i++){cin >> p1 >> p2 >> val;grid[p1][p2][0] = val;grid[p2][p1][0] = val; // 注意这里是双向图}// 开始 floydfor (int k = 1; k <= n; k++) {for (int i = 1; i <= n; i++) {for (int j = 1; j <= n; j++) {grid[i][j][k] = min(grid[i][j][k-1], grid[i][k][k-1] + grid[k][j][k-1]);}}}// 输出结果int z, start, end;cin >> z;while (z--) {cin >> start >> end;if (grid[start][end][n] == 10005) cout << -1 << endl;else cout << grid[start][end][n] << endl;}
}2.A * 算法(A star算法)127. 骑士的攻击
【题目描述】
在象棋中,马和象的移动规则分别是“马走日”和“象走田”。现给定骑士的起始坐标和目标坐标,要求根据骑士的移动规则,计算从起点到达目标点所需的最短步数。
骑士移动规则如图,红色是起始位置,黄色是骑士可以走的地方。
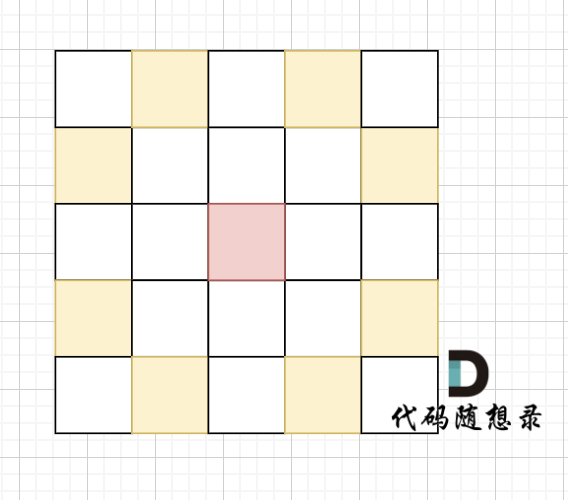
棋盘大小 1000 x 1000(棋盘的 x 和 y 坐标均在 [1, 1000] 区间内,包含边界)
【输入描述】
第一行包含一个整数 n,表示测试用例的数量。
接下来的 n 行,每行包含四个整数 a1, a2, b1, b2,分别表示骑士的起始位置 (a1, a2) 和目标位置 (b1, b2)。
【输出描述】
输出共 n 行,每行输出一个整数,表示骑士从起点到目标点的最短路径长度。
Astar 是一种广搜的改良版。 有的 Astar是 dijkstra 的改良版。
其实只是场景不同而已:
- 我们在搜索最短路的时候, 如果是无权图(边的权值都是1) 那就用广搜,代码简洁,时间效率和 dijkstra 差不多 (具体要取决于图的稠密)
- 如果是有权图(边有不同的权值),优先考虑 dijkstra。
而 Astar 关键在于启发式函数, 也就是影响广搜或者 dijkstra 从 容器(队列)里取元素的优先顺序。
那么 A * 为什么可以有方向性的去搜索,它的如何知道方向呢?
其关键在于启发式函数。
指引搜索的方向的关键代码在这里:
int m=q.front();q.pop();
int n=q.front();q.pop();
从队列里取出什么元素,接下来就是从这里开始搜索。
所以 启发式函数 要影响的就是队列里元素的排序!这是影响BFS搜索方向的关键。
对队列里节点进行排序,就需要给每一个节点权值,每个节点的权值为F,给出公式为:F = G + H
- G:起点达到目前遍历节点的距离
- H:目前遍历的节点到达终点的距离
起点达到目前遍历节点的距离 + 目前遍历的节点到达终点的距离 就是起点到达终点的距离。
本题的图是无权网格状,在计算两点距离通常有如下三种计算方式:
- 曼哈顿距离,计算方式: d = abs(x1-x2)+abs(y1-y2)
- 欧氏距离(欧拉距离) ,计算方式:d = sqrt( (x1-x2)^2 + (y1-y2)^2 )
- 切比雪夫距离,计算方式:d = max(abs(x1 - x2), abs(y1 - y2))
选择哪一种距离计算方式 也会导致 A * 算法的结果不同。
本题,采用欧拉距离才能最大程度体现点与点之间的距离。所以 使用欧拉距离计算 和 广搜搜出来的最短路的节点数是一样的。 (路径可能不同,但路径上的节点数是相同的)
计算出来 F 之后,按照 F 的 大小,来选去出队列的节点。
可以使用 优先级队列 排序,每次都是F最小的节点先出队列。
#include<iostream>
#include<queue>
#include<string.h>
using namespace std;
int moves[1001][1001];
int dir[8][2]={-2,-1,-2,1,-1,2,1,2,2,1,2,-1,1,-2,-1,-2};
int b1, b2;
// F = G + H
// G = 从起点到该节点路径消耗
// H = 该节点到终点的预估消耗struct Knight{int x,y;int g,h,f;bool operator < (const Knight & k) const{ // 重载运算符, 从小到大排序return k.f < f;}
};priority_queue<Knight> que;int Heuristic(const Knight& k) { // 欧拉距离return (k.x - b1) * (k.x - b1) + (k.y - b2) * (k.y - b2); // 统一不开根号,这样可以提高精度
}void astar(const Knight& k)
{Knight cur, next;que.push(k);while(!que.empty()){cur=que.top(); que.pop();if(cur.x == b1 && cur.y == b2)break;for(int i = 0; i < 8; i++){next.x = cur.x + dir[i][0];next.y = cur.y + dir[i][1];if(next.x < 1 || next.x > 1000 || next.y < 1 || next.y > 1000)continue;if(!moves[next.x][next.y]){moves[next.x][next.y] = moves[cur.x][cur.y] + 1;// 开始计算Fnext.g = cur.g + 5; // 统一不开根号,这样可以提高精度,马走日,1 * 1 + 2 * 2 = 5next.h = Heuristic(next);next.f = next.g + next.h;que.push(next);}}}
}int main()
{int n, a1, a2;cin >> n;while (n--) {cin >> a1 >> a2 >> b1 >> b2;memset(moves,0,sizeof(moves));Knight start;start.x = a1;start.y = a2;start.g = 0;start.h = Heuristic(start);start.f = start.g + start.h;astar(start);while(!que.empty()) que.pop(); // 队列清空cout << moves[b1][b2] << endl;}return 0;
}