NeuralRecon技术详解:从单目视频中实现三维重建
引言
三维重建是计算机视觉领域中的一项关键技术,它能够从二维图像中恢复出三维形状和结构。随着深度学习的发展,基于学习的方法已经成为三维重建的主流。NeuralRecon是一种先进的三维重建方法,它能够从单目视频中实时生成高质量的三维模型。本文将详细介绍NeuralRecon的技术原理、步骤以及如何利用TSDF(截断符号距离函数)进行三维重建。
TSDF(截断符号距离函数)在三维重建中的作用和原理
什么是TSDF?
TSDF是一种用于三维重建和表面表示的技术。它通过记录每个体素(voxel)到最近表面的距离来表示三维形状。这里的“体素”是三维空间中的一个像素,类似于二维图像中的像素。
TSDF的工作原理
-
体素网格:
- 首先,创建一个三维体素网格,这个网格覆盖了我们希望重建的三维空间区域。每个体素都有一个位置和大小。
-
距离记录:
- 每个体素记录一个距离值,这个值表示该体素到最近表面的距离。这个距离可以是正的、负的或零:
- 正距离:体素在表面外部。
- 负距离:体素在表面内部。
- 零距离:体素正好在表面上。
- 每个体素记录一个距离值,这个值表示该体素到最近表面的距离。这个距离可以是正的、负的或零:
-
截断:
- TSDF中的“截断”意味着距离值被限制在一个特定的范围内(例如,-1到1)。超出这个范围的体素将被设置为最大或最小值。这有助于处理噪声和不准确的测量。
-
表面重建:
- 通过分析体素网格中的TSDF值,可以重建出三维表面。通常,表面被定义为TSDF值从正变负或从负变正的边界。
- 通过分析体素网格中的TSDF值,可以重建出三维表面。通常,表面被定义为TSDF值从正变负或从负变正的边界。
示例步骤
假设我们有一个简单的三维物体,我们希望使用TSDF来重建其表面:
-
初始化体素网格:
- 创建一个覆盖物体的三维体素网格。
-
获取深度图:
- 使用深度相机或激光雷达获取物体的深度图。深度图记录了每个像素到物体表面的距离。
-
计算体素距离:
- 将深度图中的距离值转换为体素网格中的TSDF值。例如,如果一个体素在深度图中的距离是0.5米,那么它的TSDF值就是0.5。
-
截断距离值:
- 将所有超出范围(例如,-1到1)的TSDF值截断到这个范围内。
-
重建表面:
- 使用TSDF值重建物体表面。通常,这涉及到找到TSDF值从正变负或从负变正的边界。
应用
TSDF技术广泛应用于三维扫描、机器人导航、增强现实等领域。它允许从多个视角捕获的数据中重建三维模型,是一种强大的工具,用于理解和操作三维空间。
详细步骤解析

步骤 1: 转换操作(ds,深度图中的数值)
在三维重建中,深度图提供了从相机到物体表面的直接距离信息。每个像素点的深度值 ds 表示从相机到该点的直线距离。这些深度值是重建三维模型的基础数据,因为它们直接关联到物体表面的空间位置。
步骤 2: 遍历每一个体素,计算其在世界坐标系中的位置
体素是三维空间中的像素,是构成三维模型的基本单元。在这一步中,我们需要确定每个体素在世界坐标系中的位置。这通常通过遍历体素网格并将其索引转换为世界坐标来实现。世界坐标系是一个全局参考框架,用于描述物体在空间中的位置。
步骤 3: 根据初始化“大块”时设置的极点位置和体素大小决定
在初始化过程中,我们需要设置体素的大小和它们在世界坐标系中的位置。这涉及到选择一个起始点(极点)和定义体素的尺寸。这些参数决定了体素网格的分辨率和覆盖范围,对重建的精度和细节有重要影响。
步骤 4: 将其在世界坐标中的值转换成其在相机坐标系中的位置(位姿RT已知)
为了将世界坐标转换为相机坐标,我们需要使用相机的位姿信息,包括旋转矩阵 R 和平移向量 T。这些信息描述了相机相对于世界坐标系的位置和方向。通过应用这些变换,我们可以计算出每个体素相对于相机的位置。
步骤 5: 根据相机内参,转换到像素坐标
最后,我们需要将相机坐标系中的点转换到像素坐标系中。这需要使用相机的内参,如焦距和主点坐标。这些参数描述了相机的成像特性,将三维空间中的点映射到二维图像平面上。一旦我们得到像素坐标,就可以从深度图中获取对应的深度值,完成从图像数据到三维空间信息的转换。
TSDF的计算和应用
TSDF值的计算
TSDF值是通过比较体素到相机的距离 dv(通过相机位姿和内参计算得到)和从深度图中得到的深度值 ds 来计算的。计算公式为 d(x) = ds - dv。这个差值表示体素相对于最近表面的符号距离。
- 正距离:如果
d(x) > 0,体素位于表面外部。 - 负距离:如果
d(x) < 0,体素位于表面内部。 - 零距离:如果
d(x) = 0,体素正好在表面上。
TSDF的应用
TSDF值的应用包括:
- 表面重建:通过找到TSDF值从正变负或从负变正的边界,可以重建出物体的表面。
- 噪声处理:通过截断TSDF值,可以减少噪声和不准确测量的影响。
- 多视角融合:TSDF方法可以整合来自多个视角的深度信息,生成一致的三维模型。
示例代码
以下是一个简化的示例代码,展示了如何使用TSDF进行三维重建:
import numpy as npdef compute_tsdf(depth_map, camera_pose, camera_intrinsics, voxel_size):# 假设 depth_map 是深度图,camera_pose 是相机位姿,camera_intrinsics 是相机内参voxel_grid = np.zeros((100, 100, 100)) # 初始化体素网格for i in range(voxel_grid.shape[0]):for j in range(voxel_grid.shape[1]):for k in range(voxel_grid.shape[2]):world_coords = np.array([i, j, k]) * voxel_sizecamera_coords = np.dot(camera_pose, np.append(world_coords, 1))[:3]pixel_coords = np.dot(camera_intrinsics, camera_coords)pixel_coords = pixel_coords[:2] / pixel_coords[2]ds = depth_map[int(pixel_coords[1]), int(pixel_coords[0])]dv = np.linalg.norm(camera_coords)tsdf = ds - dvvoxel_grid[i, j, k] = tsdfreturn voxel_grid# 示例参数
depth_map = np.random.rand(480, 640) # 随机生成深度图
camera_pose = np.eye(4) # 单位矩阵作为相机位姿
camera_intrinsics = np.array([[1000, 0, 320], [0, 1000, 240], [0, 0, 1]]) # 相机内参
voxel_size = 0.05 # 体素大小# 计算TSDF
tsdf_grid = compute_tsdf(depth_map, camera_pose, camera_intrinsics, voxel_size)
结论
TSDF是一种强大的三维重建技术,它通过记录每个体素到最近表面的距离来表示三维形状。本文详细介绍了TSDF的计算过程和在三维重建中的应用,并提供了示例代码。希望读者能够通过本文更好地理解和应用TSDF技术。
NeuralRecon技术详解
NeuralRecon是一种基于深度学习的三维重建方法,主要用于从单目视频或多视图图像生成高质量的三维场景。本文将详细介绍NeuralRecon的技术原理、步骤以及如何利用TSDF进行三维重建。
技术原理
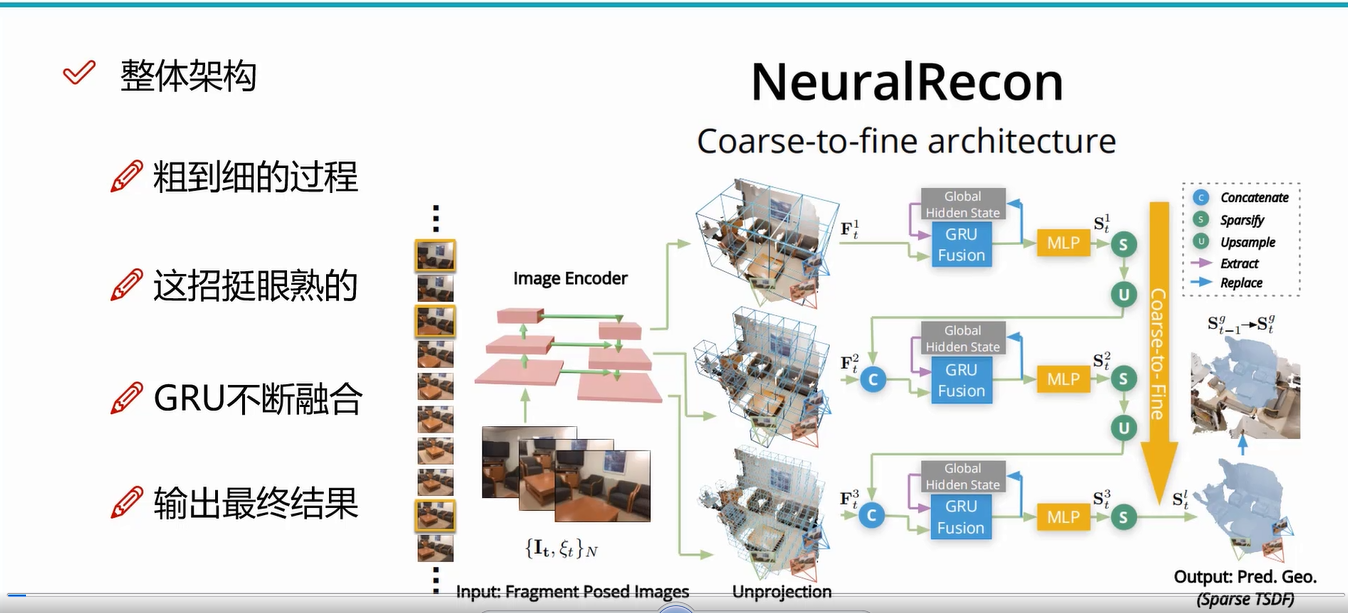
NeuralRecon的核心思想是利用三维稀疏卷积和GRU(门控循环单元)算法,对每个视频片段的稀疏TSDF体进行增量联合重构和融合。这种设计使NeuralRecon能够实时输出精确的相干重建。实验表明,NeuralRecon在重建质量和运行速度上都优于现有的方法。
重建步骤
1. 输入数据
NeuralRecon的输入包括彩色图像和相机位姿信息,这些信息提供了三维场景的基本信息。
2. 初始低分辨率重建
从低分辨率的体素网格开始,通过图像的多视角信息推断初步体素特征。多张图像的特征向量会被相加求平均,以此确定该体素的初步特征向量。
3. ConvGRU 更新特征
使用 ConvGRU 递归更新每层体素特征,保留前一层的有用信息。ConvGRU 的作用是将前一层的体素特征与当前层的信息进行融合,保留有用的信息,并逐层改进。这一机制确保了不同层次之间的特征一致性和逐步细化的过程。
4. MLP 估计 TSDF
特征通过 3D CNN 处理后,进入多层感知机(MLP)模块来估计 TSDF 值。在这一步,网络推断出每个体素的 TSDF 值,表示体素距离真实表面的距离。
5. 逐层细化
每一层增加体素分辨率,并通过上采样和特征融合逐层细化体素特征。为了对齐不同分辨率的体素网格,上一层生成的 TSDF 会通过上采样操作。
6. 输出最终结果
生成高分辨率的 TSDF,表示最终的 3D 场景结构。
NeuralRecon的重建过程在多个步骤中使用了三维稀疏卷积技术。具体来说:
-
图像特征提取和投影:首先,视频片段中的多张图像通过一个卷积神经网络(CNN)提取多个分辨率下的图像深度特征。这些图像特征随后被反向投影到三维空间中,形成三维特征体积。
-
从粗到细的三维场景重建:NeuralRecon采用从粗到细的方法,分阶段地预测并细化场景的几何信息。在每个阶段中,稀疏三维卷积神经网络被用来处理三维特征体,最终通过一个多层感知机(MLP)来预测占有分数(Occupancy score)和TSDF值。占有分数表示三维特征体中体素在TSDF截断距离之内的概率。在每个阶段的最后,占有分数小于阈值的体素,都会被定为空,并被除掉。而在稀疏化之后,稀疏三维特征体被上采样。
-
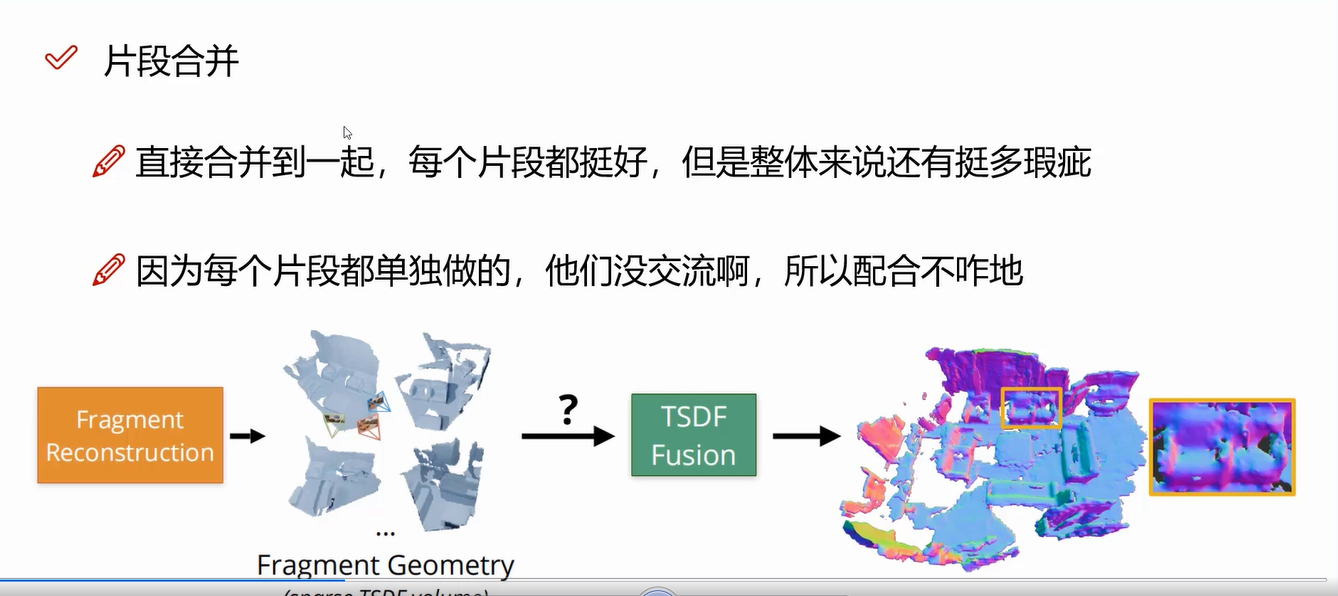
基于GRU的融合:这一步的目的是让片段的重建之间保持一致,希望当前片段的重建可以建立在历史片段重建结果的基础上。具体来说,该方法提出了一个基于GRU的联合重建与融合模块。在每个阶段,三维特征体首先通过一个三维稀疏卷积,并进行三维几何特征提取。然后,三维几何特征会被输入进GRU联合重建与融合模块。该模块会将三维几何特征与在历史片段重建中获得的隐变量进行融合,并通过一个全局感知机回归TSDF和占有分数。
在NeuralRecon中,三维稀疏卷积的使用提高了算子效率,并且与从粗到细的设计相结合,使得预测的TSDF在每个层次上逐渐细化。通过直接重建隐式曲面(TSDF),网络能够在自然三维曲面之前学习局部平滑度和全局形状。这种设计减少了冗余计算,因为在碎片重建过程中,三维表面上的每个区域仅估计一次。
TSDF 计算过程
在计算 TSDF 时,首先通过模型预测获得图片中的深度 ds(从图片中获取的深度信息),然后根据相机的位姿和内参计算出体素的深度 dv(通过相机拍摄的位姿以及相机的内参计算得来),接着计算体素到真实面的距离 d(x) = ds - dv。若 d(x) > 0,则体素位于真实面前;若 d(x) < 0,则体素位于真实面后。最终,通过进一步处理 d(x) 得到 TSDF 值。
示例代码
以下是一个简化的示例代码,展示了如何使用NeuralRecon进行三维重建:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass NeuralRecon(nn.Module):def __init__(self):super(NeuralRecon, self).__init__()self.image_encoder = self._build_image_encoder()self.gru_fusion = self._build_gru_fusion()self.mlp = self._build_mlp()def _build_image_encoder(self):# 构建图像编码器return nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2))def _build_gru_fusion(self):# 构建GRU融合模块return nn.GRU(128, 128, num_layers=1, batch_first=True)def _build_mlp(self):# 构建多层感知机return nn.Sequential(nn.Linear(128, 64),nn.ReLU(inplace=True),nn.Linear(64, 2) # 输出TSDF值和占用率)def forward(self, x):# 前向传播x = self.image_encoder(x)x = x.view(x.size(0), -1, x.size(1))h0 = torch.zeros(1, x.size(0), 128).to(x.device)x, _ = self.gru_fusion(x, h0)x = self.mlp(x)return x# 示例输入
input_tensor = torch.randn(1, 3, 288, 800)
model = NeuralRecon()
output = model(input_tensor)
print(output.shape) # 输出形状应为[batch, num_voxels, 2]
GitHub参考
NeuralRecon的代码可以在GitHub上找到,以下是相关的链接:
- NeuralRecon GitHub Repository
通过这些代码和资源,读者可以更深入地了解NeuralRecon的实现细节,并尝试在自己的项目中应用这一技术。
总结
NeuralRecon是一种强大的三维重建技术,它通过结合深度学习和TSDF方法,实现了从单目视频中实时生成高质量的三维模型。本文详细介绍了NeuralRecon的技术原理、步骤以及如何利用TSDF进行三维重建,并提供了示例代码和GitHub参考链接。希望读者能够通过本文更好地理解和应用NeuralRecon技术。