消息队列的使用
使用内存队列来处理基于内存的【生产者-消费者】场景
思考和使用Disruptor
-
Disruptor可以实现单个或多个生产者生产消息,单个或多个消费者消息,且消费者之间可以存在消费消息的依赖关系
-
使用Disruptor需要结合业务特性,设计要灵活
-
什么业务场景适合使用Disruptor
-
Disruptor核心优势在于极致的低延迟和极高吞吐量,且通信发生在单个JVM进程内部的场景
-
高频交易系统 (HFT - High-Frequency Trading):
-
场景描述: 金融市场中的算法交易,需要在微秒甚至纳秒级别对市场数据做出反应,并快速下单。延迟每降低一点,都可能带来巨大的竞争优势。
-
为何适合: Disruptor 最初就是为 LMAX 交易所设计的,用于处理海量的订单和行情数据。其低延迟特性对于捕捉转瞬即逝的交易机会至关重要。它可以用于订单处理流水线、市场数据分发、风险控制计算等。
-
-
实时风控与反欺诈系统:
-
场景描述: 在支付、交易、登录等关键操作发生时,需要实时分析用户行为、交易模式等,快速识别潜在的风险或欺诈行为,并在毫秒级内做出决策(如阻止交易、要求额外验证)。
-
为何适合: 需要处理高并发的事件流,并进行复杂的规则匹配和计算,同时对响应时间有极高要求。Disruptor 可以作为事件处理引擎的核心,确保快速处理和决策。
-
-
高性能日志处理框架:
-
场景描述: 应用程序产生大量日志,需要异步地、高效地将日志事件从业务线程传递给日志写入线程,同时尽量减少对业务线程性能的影响。
-
为何适合: Log4j2 的 Async Loggers 就是基于 Disruptor 实现的。它可以显著降低日志记录操作对应用主线程的阻塞时间,提高应用的整体吞吐量。
-
-
游戏服务器事件处理:
-
场景描述: 大型多人在线游戏(MMO)服务器需要处理来自成千上万玩家的并发操作(移动、攻击、聊天等),并实时更新游戏世界状态,广播给其他相关玩家。
-
为何适合: 游戏服务器对延迟非常敏感,任何卡顿都会严重影响玩家体验。Disruptor 可以用来构建高效的事件处理循环,快速响应玩家输入并分发状态更新。
-
-
实时数据分析与复杂事件处理 (CEP - Complex Event Processing):
-
场景描述: 从各种数据源(如传感器、网络流量、用户行为日志)接收高速数据流,实时识别特定模式、趋势或异常,并触发相应动作。
-
为何适合: 需要在大量数据涌入时,以极低的延迟进行匹配和分析。Disruptor 可以作为CEP引擎内部事件排队和分发的骨干。
-
-
网络数据包处理/高性能网络应用:
-
场景描述: 构建需要处理大量并发连接和高速网络数据包的服务器应用,如自定义的应用层网关、高性能代理服务器等。
-
为何适合: 当网络 I/O 线程接收到数据包后,需要快速地将这些数据包(或解析后的事件)分发给工作线程进行处理。Disruptor 可以作为 I/O 线程和业务逻辑处理线程之间的高效桥梁。
-
-
任务调度与并行计算的内部协调:
-
场景描述: 在一个复杂的计算任务中,可以将任务分解为多个阶段,由不同的线程组处理。阶段之间的数据传递需要高效且低延迟。
-
为何适合: 如果这些阶段都在同一个JVM内部,并且对性能要求极高,Disruptor 可以作为这些并行处理单元之间的数据交换通道,避免传统队列的锁竞争开销。
-
-
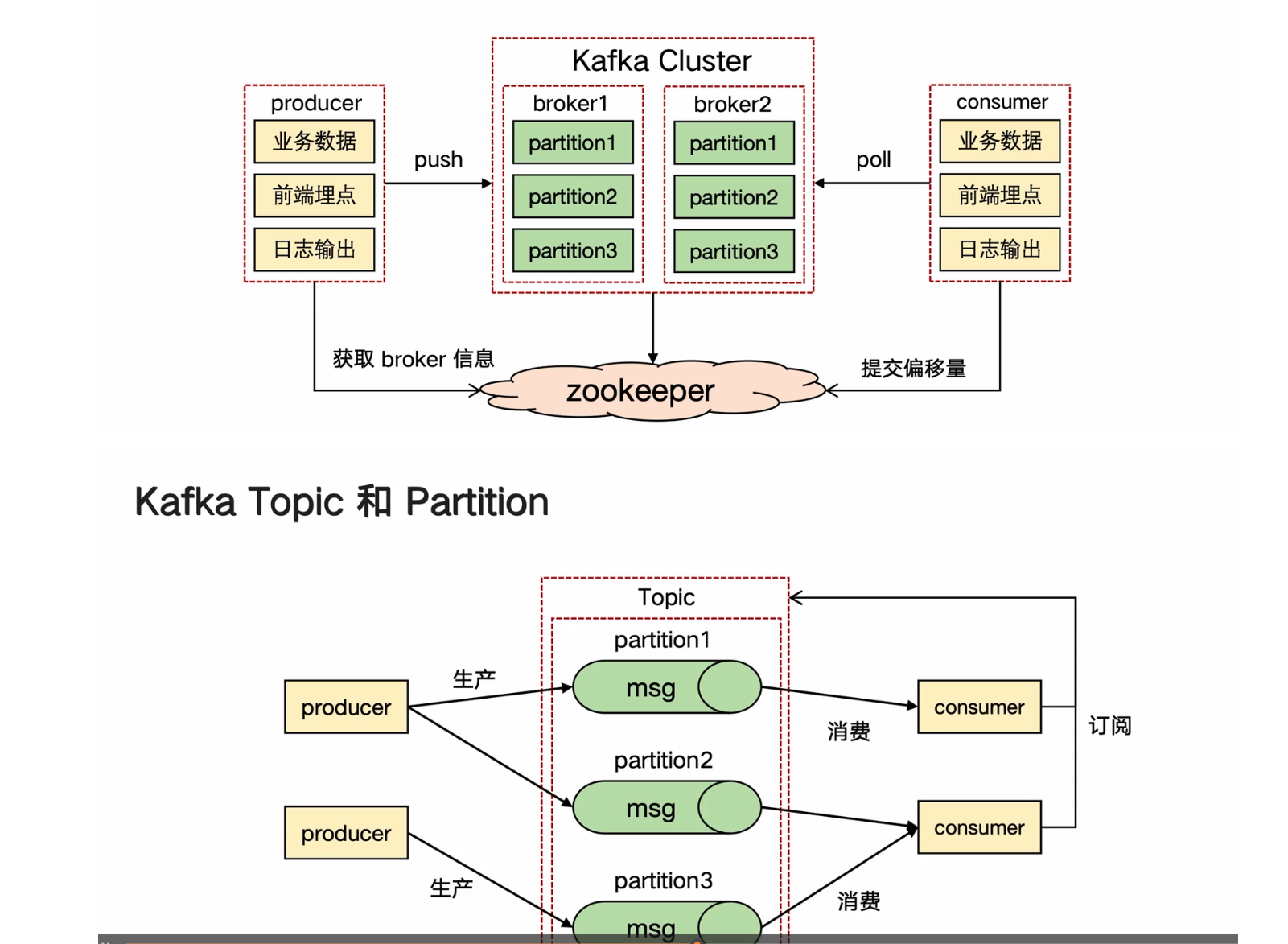
Kafka
消息队列的设计意图
当消费不均衡(生产者生产的过快或消费者消费的过快)时,就在生产者和消费者中间加一个缓冲层,这个缓冲层就是消息队列
消息队列是分布式系统中的重要组件
消息队列的作用
-
异步:提升吞吐量
-
解耦:减少依赖,生产者和消费者之间没有直接的依赖,一个系统的故障不会影响另一个系统,保证系统的稳定性和健壮性
-
削峰填谷:消除短时负载过高
-
削峰:生产者的速度非常的高,并发流量非常的大,此时可以增加消费者线程,提高并发处理能力,来达到生产和消费的平衡
-
填谷:生产的频率降低,流量变小,此时可以减少一些消费者线程,来达到生产和消费的平衡
-
-
顺序性保证
-
可靠性保证:数据持久化
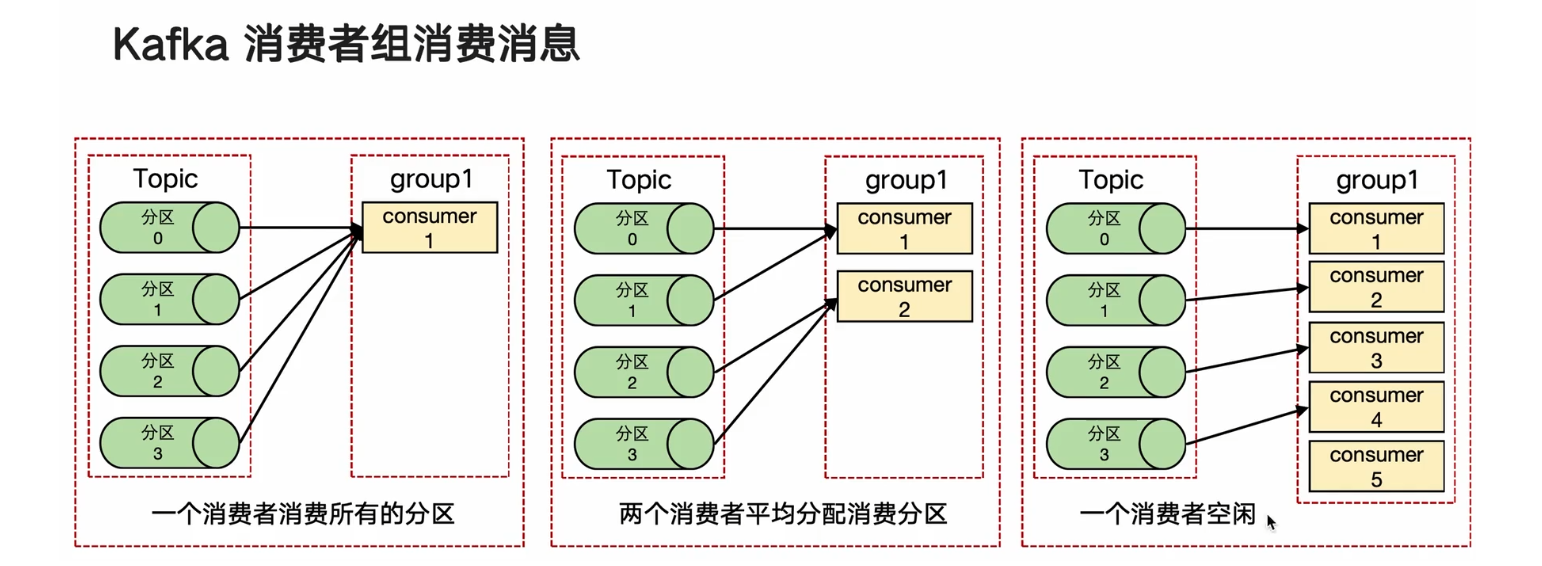
从整体的角度来看Kafka
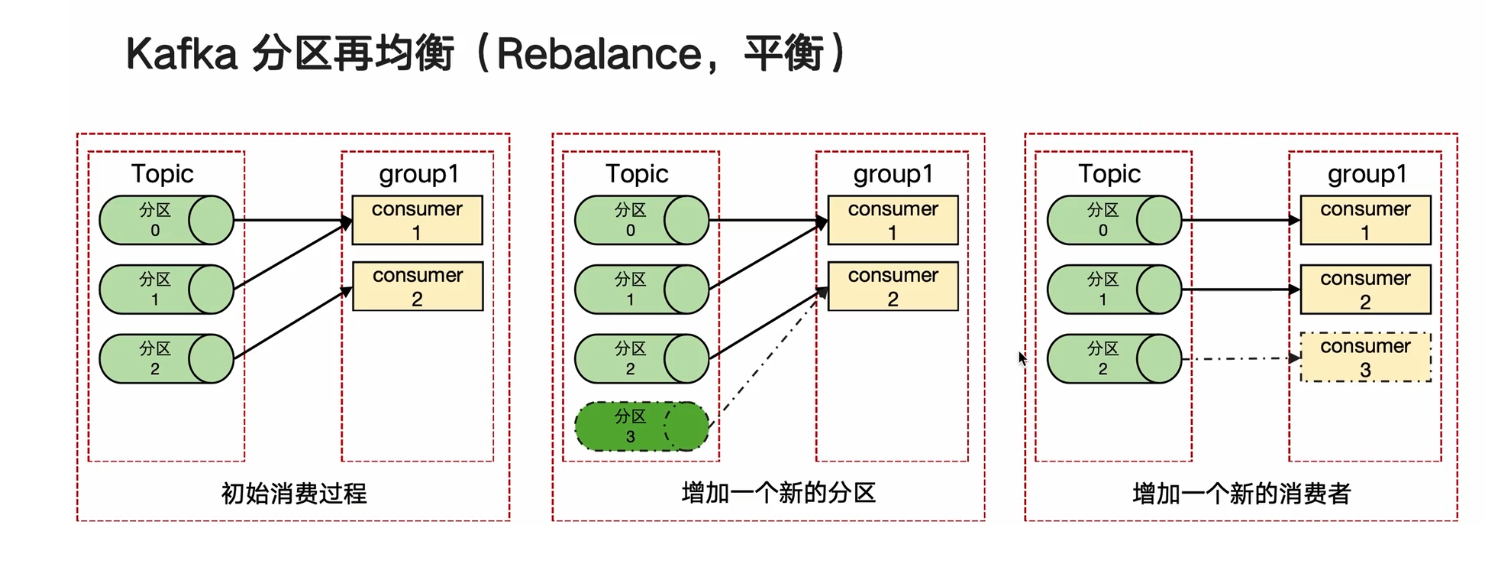
Kafka分区再均衡(Rebalance, 平衡)
Kafka数据存储
-
日志文件消息格式

消息丢失和重复消费
Kafka消息丢失
从Kafka生产,消息持久化,消费过程看消息丢失
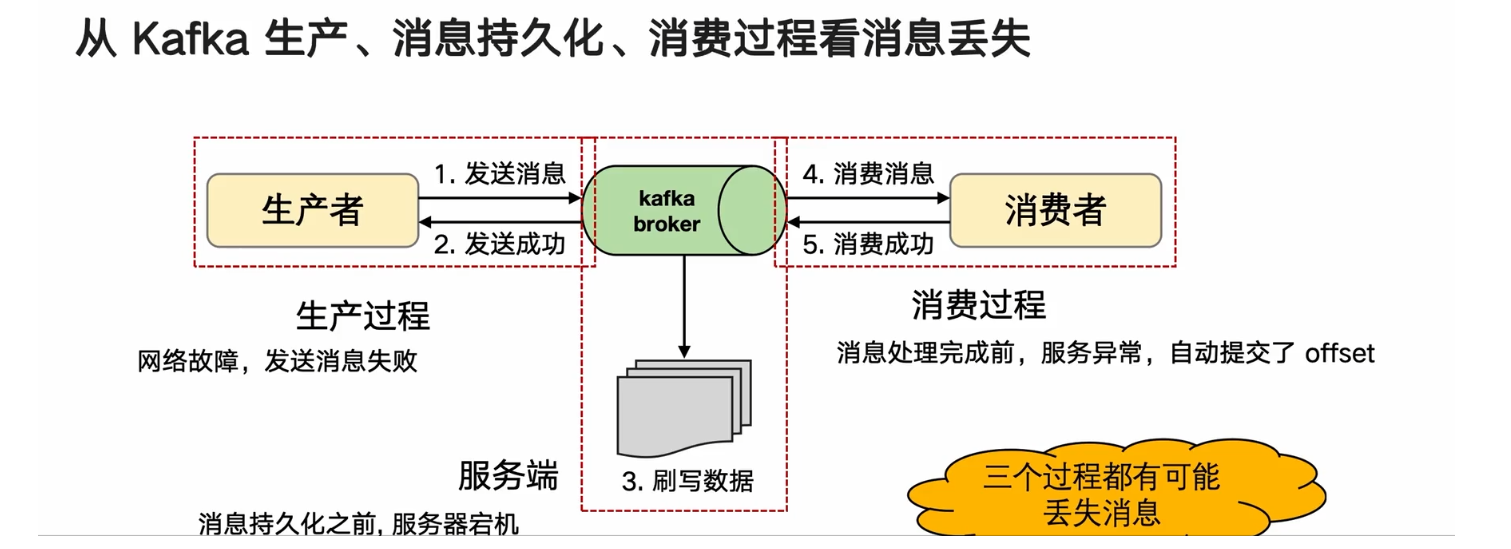
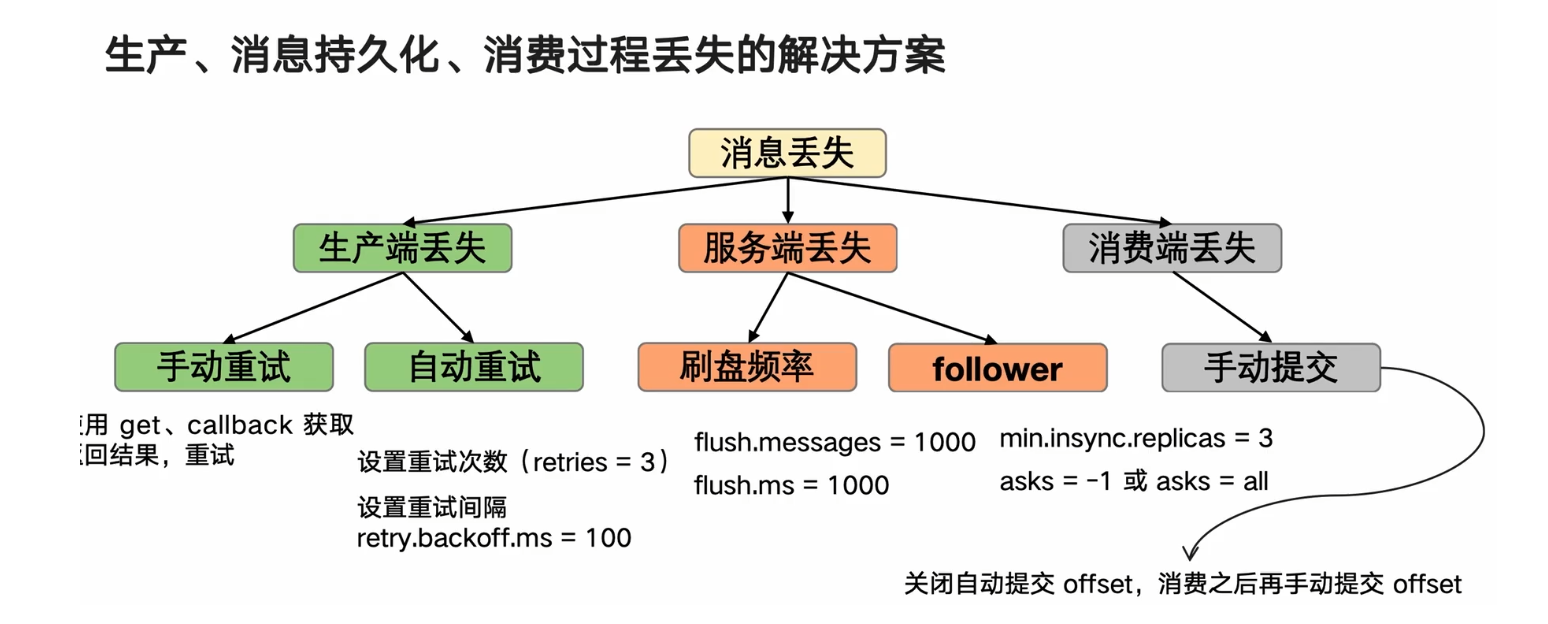
生产,消息持久化,消费过程丢失的解决方案
Kafka重复消费
-
重复消费的根本原因在于:已经消费了数据,但是offset没有成功提交,很大一部分原因是再均衡
-
消费者宕机,重启,消费了消息但是没有提交offset
-
还没有提交offset时,发生了rebalance
-
消息处理耗时太大,超过了(max.poll.interval.ms),发生了rebalance
-
-
重复消费的解决方案
-
最根本的解决方案是消费消息保证幂等性
-
记录消息表,使用唯一索引
-
缓存消费过的消息id(位图)
-
-
使用好Kafka
集成使用Kafka
常见的两种方法使用Kafka
-
使用@KafkaListener把消费过程(poll和提交offset)交给框架
-
自己管理消息的拉取(poll)和消息偏移量(offset)的提交
生产者发送消息有三种方式
-
发送之后什么都不管
-
同步发送
-
异步发送
消费者消费消息
-
消费者主动拉取消息消费
-
通过注解实现消息的监听消费(@KafkaListener)
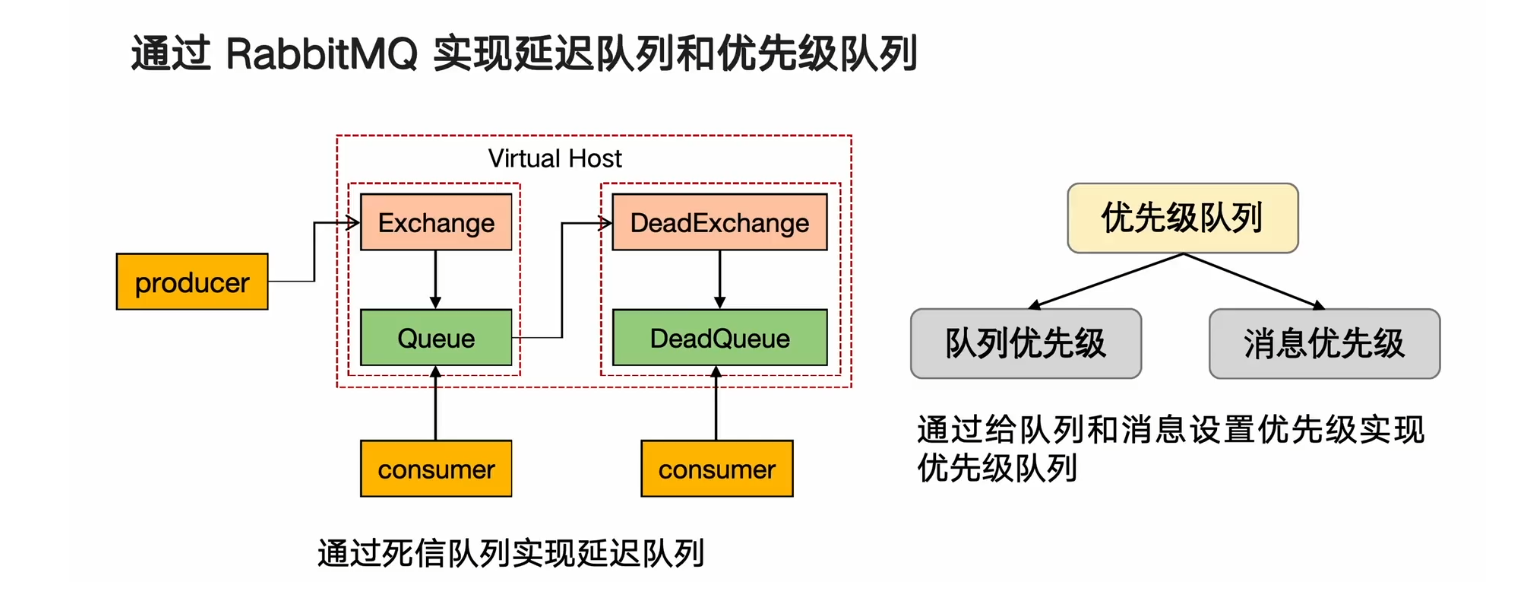
延迟队列和优先级队列
RabbitMQ架构模型
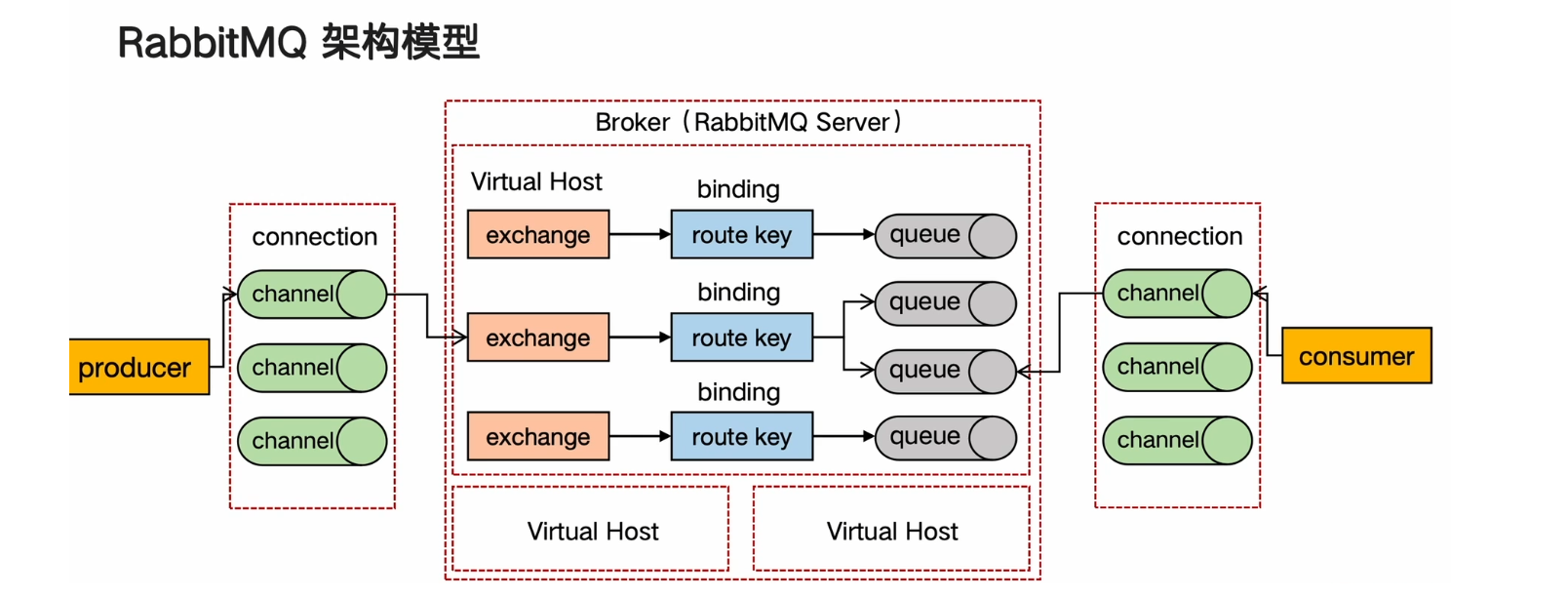
通过RabbitMQ实现延迟队列和优先级队列
死信队列:
死信:如果队列中消息出现以下两种情况,则消息变为死信状态
-
如果消息在队列中的时间超过了我设置的ttl(过期时间)
-
消息队列的消息数量超过了最大的队列长度
优先级队列:最大值是255,最小值是0,值越大,优先级越高