【python实战】二手房房价数据分析与预测

个人主页:@大数据蟒行探索者

目录
一、数据分析目标与任务
1.1背景介绍
1.2课程设计目标与任务
1.3研究方法与技术路线
二、数据预处理
2.1数据说明
2.2数据清洗
2.3数据处理
三、数据探索分析
四、数据分析模型
五、方案评估
摘要:随着社会经济的迅猛发展,房地产开发建设的速度越来越快,二手房市场迅猛发展,对二手房房产价格评估的需求也随之增大。因此,对二手房房价预测进行研究是必要的。住宅是城市居民的刚性需求,随着城市建设用地越来越紧缺,住宅供需成为城市发展必须解决的一大问题。二手房数量占城市住宅总量的比重较高,并且大多数二手房占据城市配套成熟的优越位置,因此成为城市居民解决刚性需求的重要选择。城市是一个复杂的系统,二手房作为城市的“细胞”,其价格受许多要素影响,不同城市的二手房价格在空间分布上有所不同。
本文使用python爬虫从链家二手房网站上爬取了深圳的在售二手房数据,并对二手房数据进行数据分析,首先查看数据,导入数据,了解数据集的维度,每列数据的数据类型,以及打印部分数据,进行观察。然后进行数据清洗,删除不需要的列,删除重复行数据,删除包含有空值的行数据,以及对异常值进行处理。
数据清洗后,使用所在行政区、参考单价、建筑面积、户型结构、装修情况、配备电梯、建筑结构等指标作为影响深圳二手房售卖每平米价格的主要因素,据此建立模型,使用线性回归、支持向量机和随机森林三种模型进行预测,最终得到较优的深圳二手房房价预测模型,为深圳二手房交易者们提供了一个有较为有实用价值的二手房定价工具。
本文基本符合一个完整数据分析案例的要求,但仍有很多可以改进的地方,如可以采用更复杂的统计学理论深入分析房价分布及其影响因素,对机器学习模型进行调参以尽可能提高预测能力,采用更加直观的数据可视化方式展示数据,并通过数据分析为二手房购买者提供建设性意见。
关键词:深圳 房价 数据清洗
一、数据分析目标与任务
1.1背景介绍
房地产行业是我国国民经济的支柱产业之一,房地产市场的健康发展对促进我国的国民经济发展、维护社会的和谐稳定起着十分重要的作用。近几年,随着我国房地产行业的迅猛发展,房价节节攀升,很多购房者对于居高不下的一手房价格“心灰意冷”,转而将目光投向了比一手房价格低的二手房市场。深圳的二手房成交量也不断创出历史新高,呈现蓬勃发展的态势。但相比于较成熟的一手房市场,二手房市场对政策过于敏感,面对此起彼落的针对楼市过热出台的多项严控政策。根据深圳中原研究中心数据显示,2021年10月份深圳全市二手房住宅过户套数为1605套,环比下降9.1%,过户套数为2012年3月以来的最低值。深圳二手房月度成交量出现十连跌。
二手房市场的发展具有重要的意义。二手房市场的发展,不仅有利于住宅一级市场的繁荣、缩短新建商品住宅的销售周期,而且可以满足居民置业升级和梯度消费的需求,补充和保障中低收入户的住房需求。区别于一手房,二手房交易流程长,涉及主体多,法律关系错综复杂,纠纷时常发生,风险无处不在,所以对深圳二手房市场现状和政策的分析研究也就具备了可行性和必要性。同时,通过运用经济理论和方法对北京市二手房市场现状的研究,可以了解和学习国家相关的房贷信息和货币政策,从宏观上把握二手房市场的存在价值和发展趋势,为参与到二手房交易的个人或者家庭提供一些积极有效的参考信息和应该注意的问题,使其具有较强的现实意义和参考价值。
1.2课程设计目标与任务
住宅是城市居民的刚性需求,随着城市建设用地越来越紧缺,住宅供需成为城市发展必须解决的一大问题。二手房数量占城市住宅总量的比重较高,并且大多数二手房占据城市配套成熟的优越位置,因此成为城市居民解决刚性需求的重要选择。城市是一个复杂的系统,二手房作为城市的“细胞”,其价格受许多要素影响,不同城市的二手房价格在空间分布上有所不同。通过研究二手房价格空间分布及影响因素,对房地产健康发展具有重要的意义。
本次课程设计需要对二手房市场背景展开调研,爬取某一具体城市的二手房数据集,分析影响该城市二手房价格的主要因素,并构建相应的二手房房价估值模型,实现房价的预测。
1.3研究方法与技术路线
首先查看数据,导入数据,了解数据集的维度,每列数据的数据类型,以及打印部分数据,进行观察。然后进行数据清洗,删除不需要的列,删除重复行数据,删除包含有空值的行数据,以及对异常值进行处理。数据清洗后,对数据进行探索性分析找到影响房价的主要因素建立模型进行房价预测。
本次课程设计采用python编程,使用jupyter notebook开发环境进行开发。
二、数据预处理
2.1数据说明
- 数据规模:38762 rows × 29 columns
- 数据文件:本文通过对爬取到的 38762套深圳二手房数据进行数据分析,通过简单数据清洗、可视化作图等多个方式进行探索性分析以及房价预测。
- 数据字段:数据集中汇总了深圳市目前的38000+个二手房数据,包含房屋详细数据、经纬度等29个字段,字段主要包括:小区名称、行政区、区域、参考总价、参考单价、房屋户型、所在楼层、建筑面积、户型结构、套内面积、建筑类型、经纬度 等 29个字段,具体字段如下所示:
- 小区名称
- 行政区
- 区域
- 编号
- 参考总价
- 参考单价
- 房屋户型
- 所在楼层
- 建筑面积
- 户型结构
- 套内面积
- 建筑类型
- 朝向
- 建筑结构
- 装修情况
- 梯户比例
- 配备电梯
- 挂牌时间
- 交易权属
- 上次交易时间
- 房屋用途
- 房屋年限
- 产权所属
- 抵押信息
- 房本备件
- 房协编码
- 经度
- 纬度
- 城市
共29个字段,其中,小区名称、行政区、区域、总价、单价等都是最常见的基本信息户型、楼层、面积、建筑类型、房屋朝向、建筑结构等都是房屋的具体属性信息挂牌时间、交易权属、上次交易时间、抵押信息等都是房屋的交易信息经纬度是房屋所在的百度经纬度数据,城市是额外新增的一个字段,本次均为:深圳。
- 数据样本:利用data.head()输出前5行数据查看如下图所示。
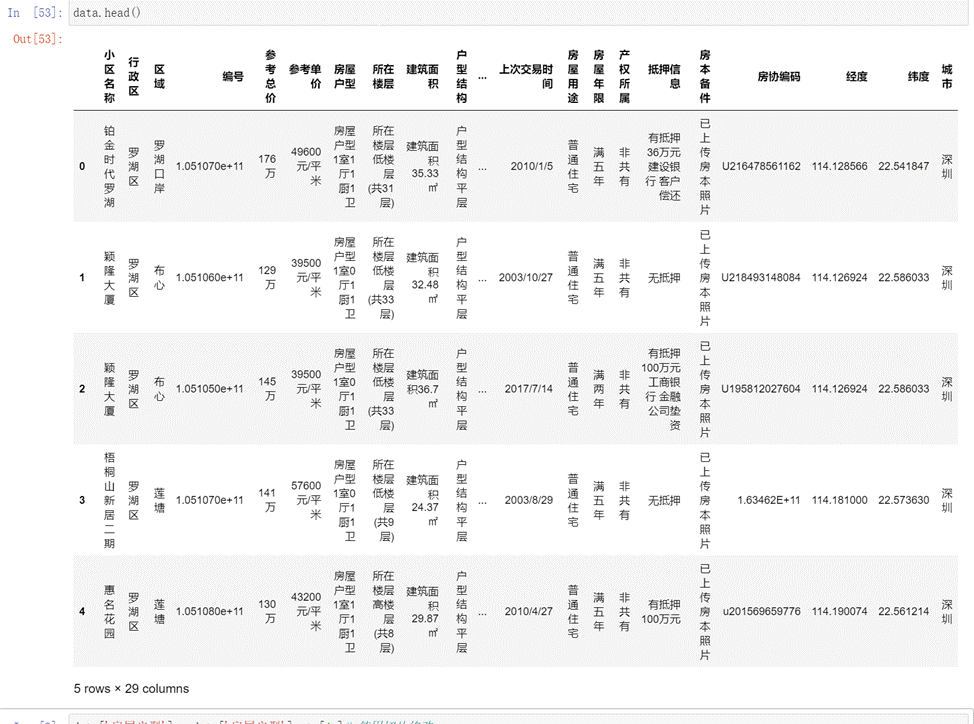
图1 数据样本
打印数据集每列的信息如下图所示,其中,参考总价、参考单价、建筑面积、套内面积 等都属于数值类型。因为在爬取数据的数据没有进行数据清洗,网站上是什么就存储成什么,这也是为了保护数据的真实性,但是在实际分析过程中,特别是建模中,这类数据通常都是存储成数值型,方便可视化的同时也能保证模型快速收敛,所以在后面会转换数据类型。

图2 数据集每列信息
2.2数据清洗
- 缺失值处理
缺失值处理的三种方法:直接使用含有缺失值的特征;删除含有缺失值的特征(该方法在包含缺失值的属性含有大量缺失值而仅仅包含极少量有效值时是有效的);缺失值补全。而本次我们采用的是若是存在含有空值的行,则本地删除含有空值的行数据。
也就是将存在遗漏信息属性值的对象(元组,记录)删除,从而得到一个完备的信息表。这种方法简单易行,在对象有多个属性缺失值、被删除的含缺失值的对象与信息表中的数据量相比非常小的情况下是非常有效的,类标号(假设是分类任务)缺少时通常使用。然而,这种方法却有很大的局限性。它是以减少历史数据来换取信息的完备,会造成资源的大量浪费,丢弃了大量隐藏在这些对象中的信息。在信息表中本来包含的对象很少的情况下,删除少量对象就足以严重影响到信息表信息的客观性和结果的正确性;当每个属性空值的百分比变化很大时,它的性能非常差。因此,当遗漏数据所占比例较大,特别当遗漏数据非随机分布时,这种方法可能导致数据发生偏离,从而引出错误的结论。
通过处理我们发现含有缺失值的行数为494行,缺失值处理后的结果如下所示。

图3 缺失值处理
- 重复行处理
在数据的收集过程中,可能会存在重复观测的出现,例如通过网络爬虫,就比较容易产生重复数据重复值一般采取删除法来处理,看出检测数据集的记录是否存在重复,使用duplicated (英文单词的意思就是重复,复制的意思)方法,但是该方法返回的是数据集每一行的检验结果,为了能够得到最直接的结果,可以使用any函数,该函数表示的是在多个条件判断中,只有一个条件为True,则any函数的结果就为True。正如结果所示,any函数的运用返回True值,说明该数据集是存在重复观测的。然后再使用drop_duplicates删除重复观测。
重复行处理结果如下图所示,可以发现只删除了一行的数据,说明只有一行重复值。

图4 重复行处理
- 异常值处理
- 发现房屋户型、所在楼层、户型结构、建筑面积、套内面积、建筑类型、朝向、建筑结构、装修情况、配备电梯、梯户比例这几个字段在数据集中前四个字符都是多余的,故对其利用字符串切片进行删除如下图所示。

图5 删除多余字符
- 观察参考总价字段发现,可以看到参考总价有两种形式,带单位的和不带单位的,这里我们直接确定成数值(方便在回归模型中应用),同理,参考单价字段可以采用同样的处理方式。但是单价的单位是具体到元的,将参考单价的单位改成与总价的单位保持一致为万/平方米。

图6 参考单价与参考总价字段处理
- 在分析参考总价的时候发现有的总价小于10w,不符合逻辑,我们将这些数据提取出来观察如下所示。

图7 总价小于10w的数据
- 可以发现这些房屋总价的单位是亿不是万,所以需要对这部分房屋的总价进行处理如下图所示。
图8 总价处理
- 观察套内面积发现缺失的字段较多,并且在爬取数据时出现的错误也较多,故删除套内面积字段如下图所示。

图9 套内面积处理
- 观察户型结构字段发现户型结构字段存在错误数据,将这些存在错误数据的元组删除得到新的数据集data1如下图所示。

图10 户型结构处理
2.3数据处理
- 所在楼层字段过于冗长,为了方便计算,直接取描述性数据,例如中楼层、高楼层如下图所示。

图11 所在楼层处理
- 观察房屋户型字段我们发现都是x室x厅x厨x卫,但在实际中一般我们在说户型的时候,都只是说 xx室xx厅,很少去关注后面的厨房和卫生间个数,所以我们只取前两个属性,利用正则表达式进行匹配如下图所示。

图12 房屋户型处理
- 分析建筑面积字段,将对应的 ㎡ 剔除掉,保证字段为数值类型,需要注意的是有部分数据为空的,官方标记的是“暂无数据”,这部分我们需要进行缺失值填充。例如:房屋价格存在缺失,可以使用同一区域内的均价进行填充;房屋类型存在缺失,可以使用同一小区的其他房屋该字段的众数进行填充;多个房屋区域存在缺失,可以通过自定义距离函数计算最近的小区并进行相应填充。填充方法如下图所示。

图13 缺失值填充方法
首先col1、col2是辅助列,target_col 是目标列。例如:对建筑面积进行缺失填充,按照填充规则,会根据同一个小区同一户型的建筑面积的均值进行填充,对应的,目标列就是 “建筑面积”,辅助列col1、col2就是 ”小区名称、房屋户型”。另外,当你的辅助列只有一个时,对应的 col_2 可以传入一个空字符串,例如上述中的 “”。其次是 col1_value、col2_value 和 target_value,对应的表示建筑面积缺失该数据的辅助列字段的值。data 表示整个数据集。target_type 表示填充目标列的类型,像建筑面积就是数值型,使用均值填充;像房屋户型是字符类型,使用众数填充。
利用上述缺失值填充方法对建筑面积进行缺失值填充:
data.loc[data['建筑面积']=='暂无数据', '建筑面积'] = data.loc[data['建筑面积']=='暂无数据', ['小区名称', '房屋户型', '建筑面积']].apply(lambda x: get_nan_info("小区名称", "房屋户型", x[0], x[1], data, target_col="建筑面积", target_value=x[2]), axis=1)
- 对于户型结构字段,通过观察可以发现户型结构中也存在“暂无数据”的缺失值,故我们利用'小区名称', '房屋户型'两个字段来确定怎样填充户型结构字段,剩余的利用众数来填充如下图所示。

图14 户型结构填充
- 对于建筑类型字段,通过观察可以发现建筑类型中也存在“暂无数据”和未知结构的缺失值,故我们利用'小区名称', '房屋户型'两个字段来确定怎样填充建筑类型字段,剩余的利用众数来填充如下图所示。
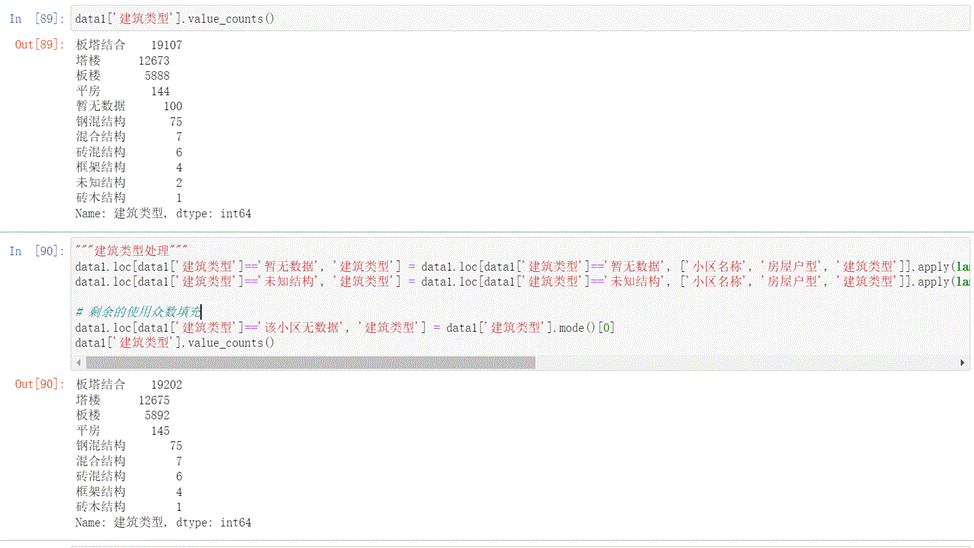
图15 建筑类型填充
- 对于建筑结构字段,通过观察可以发现建筑结构中也存在“暂无数据”和未知结构的缺失值,故我们利用'小区名称', '房屋户型'两个字段来确定怎样填充建筑结构字段,剩余的利用众数来填充如下图所示。
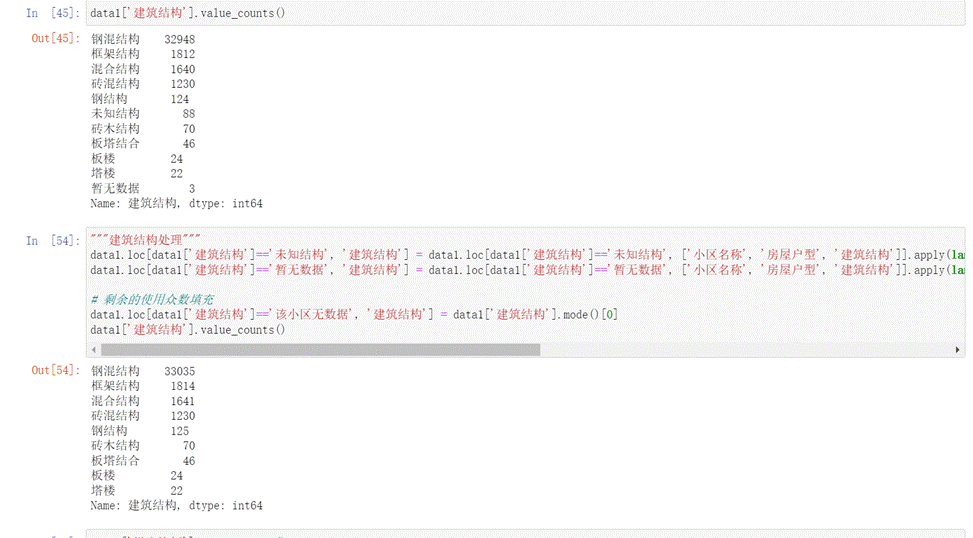
图16 建筑结构填充
- 配备电梯、房屋年限、装修情况和上面类似,这里就不再赘述了。
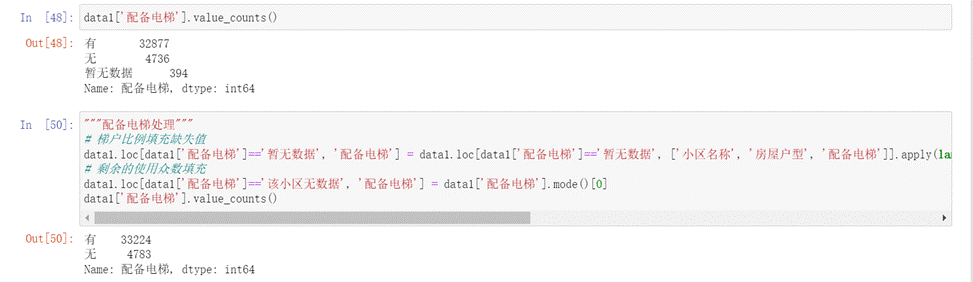
图17 配备电梯填充

图18 房屋年限填充
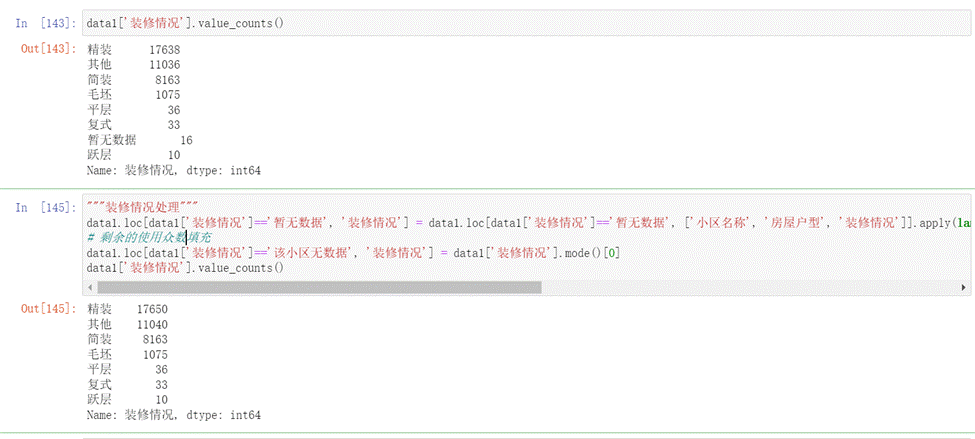
图19 装修情况填充
- 通过对抵押信息字段的观察发现,抵押信息看似很多,但是其实说白了就两种,有抵押和无抵押,直接进行处理即可,将其分为有抵押和无抵押如下图所示。
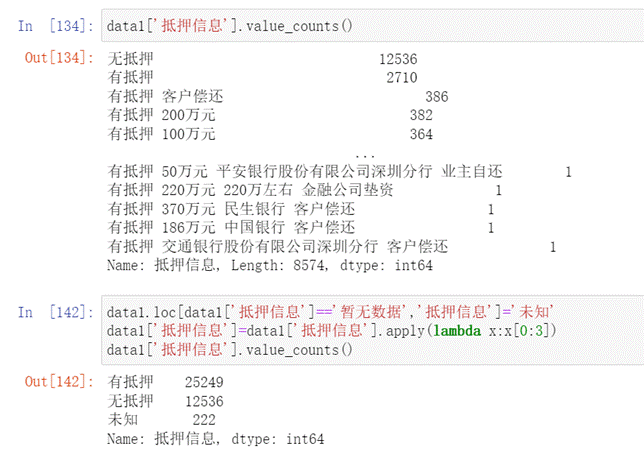
图20 抵押信息处理
- 本次设计预处理最难的部分也就是缺失值填充部分,刚开始我们并没有去处理“暂无数据”或者“该小区无数据”等缺失值字段进行分析,分析到后面发现了这个错误,想到必须对其进行填充,然后讨论并分析才设计出这种填充方法。
三、数据探索分析
1. 结合可视化呈现,对数据进行探索性分析
- 整体房价分析
对深圳市的整体二手房价进行处理,包括最高价格、最低价格、平均价格和中位数价格分布。
- 地理位置对房价的影响
采用行政区划作为地理位置的影响因素,从行政区划方面对深圳二手房的数据进行分析。
- 建筑面积对房价的影响
作为房屋类型的影响因素之一,从建筑面积方面对深圳二手房的数据进行分析。
- 所在楼层对房价的影响
作为房屋类型的影响因素之一,从所在楼层方面对深圳二手房的数据进行分析。
- 户型结构对房价的影响
作为房屋类型的影响因素之一,从户型结构方面对深圳二手房的数据进行分析。
- 建筑类型对房价的影响
作为房屋类型的影响因素之一,从建筑类型方面对深圳二手房的数据进行分析。
- 建筑结构对房价的影响
作为房屋类型的影响因素之一,从建筑结构方面对深圳二手房的数据进行分析。
- 抵押信息对房价的影响
作为房屋类型的影响因素之一,从是否抵押方面对深圳二手房的数据进行分析。
- 房屋年限对房价的影响
作为房屋类型的影响因素之一,从房屋使用年限方面对深圳二手房的数据进行分析。
- 装修情况对房价的影响
作为房屋类型的影响因素之一,从装修情况方面对深圳二手房的数据进行分析。
- 配备电梯对房价的影响
作为房屋类型的影响因素之一,从是否配备电梯方面对深圳二手房的数据进行分析。
- 深圳二手房房屋户型占比情况
通过绘制饼图,展示深圳二手房的房屋户型占比情况。
- 深圳二手房所在楼层占比情况
通过绘制柱状图,统计深圳各楼层二手房数量分布。
- 深圳二手房房屋朝向分布情况
通过绘制柱状图,统计深圳二手房房屋朝向分布情况。
- 深圳各区域二手房平均单价
通过绘制柱状图,展现深圳各区域二手房平均单价。
- 可视化呈现结果
- 整体房价分析

图21 整体房价分析
从统计结果上来看,深圳二手房的最高价格超过50万元/平方米,最低价格不高于2万元/平方米,悬殊极大。房价的平均数和中位数均在5-6万元/平方米。
下面展示深圳整体二手房价格与数量的柱状图:
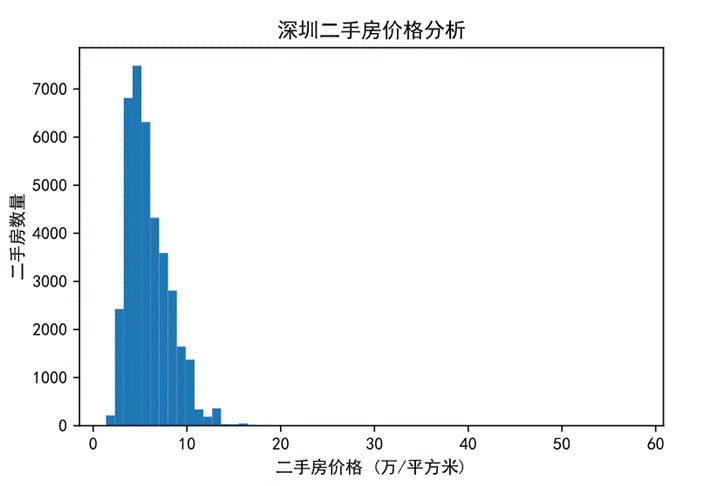
图22 整体房价的柱状图
通过上图可以看出,二手房的价格主要集中在5-6万/平方米;从整体分布来看,其数据分布类似于正态分布,呈现单峰特点。
- 行政区化对房价的影响
①各行政区划内房价的平均值柱状图(按从大到小排序)

图23 行政区划对平均房价的影响
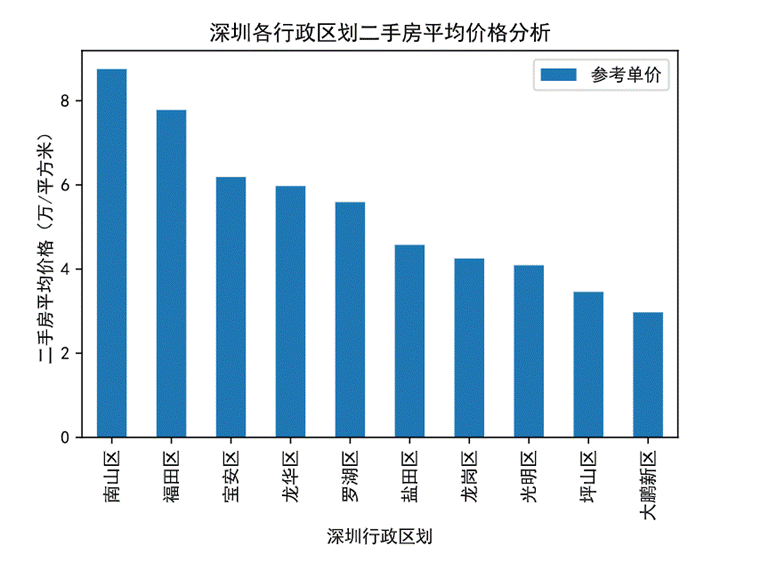
图24 行政区划对平均房价的影响柱状图
从统计结果可以看出南山区的均价最贵,超过8万元/平方米,接下来是福安区7.7万元/平方米左右,宝安区、龙华区和罗湖区,三者房价比较接近,在6-5万元/平方米的区间内。
②各行政区划二手房价格分析箱线图

图25 行政区划对平均房价的影响箱线图代码
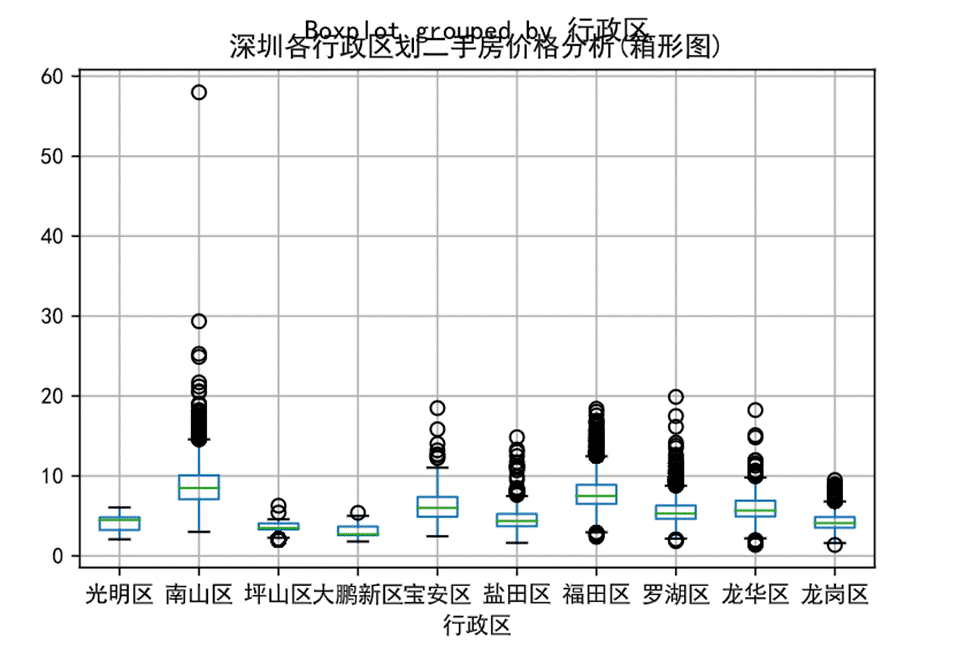
图26 行政区划对平均房价的影响箱线图
从深圳各行政区划二手房价格的箱型图可以看出,南山区、盐田区、福田区、罗湖区具有较多上侧异常值,其中南山区最多。可想而知越靠近知名商圈的房价会特别贵。相反,深圳的周边区划异常值极少,如光明区没有异常值,大鹏新区异常值为1,房价分布区间相对较小。
- 建筑面积对房价的影响
房屋面积在一定程度上反映了房屋类型。例如面积超过200平方米的房子很有可能是别墅,此类房屋往往在优质住宅区内,价格很有可能偏高。
首先查看参考单价随房屋面积的分布,采用散点图进行可视化:
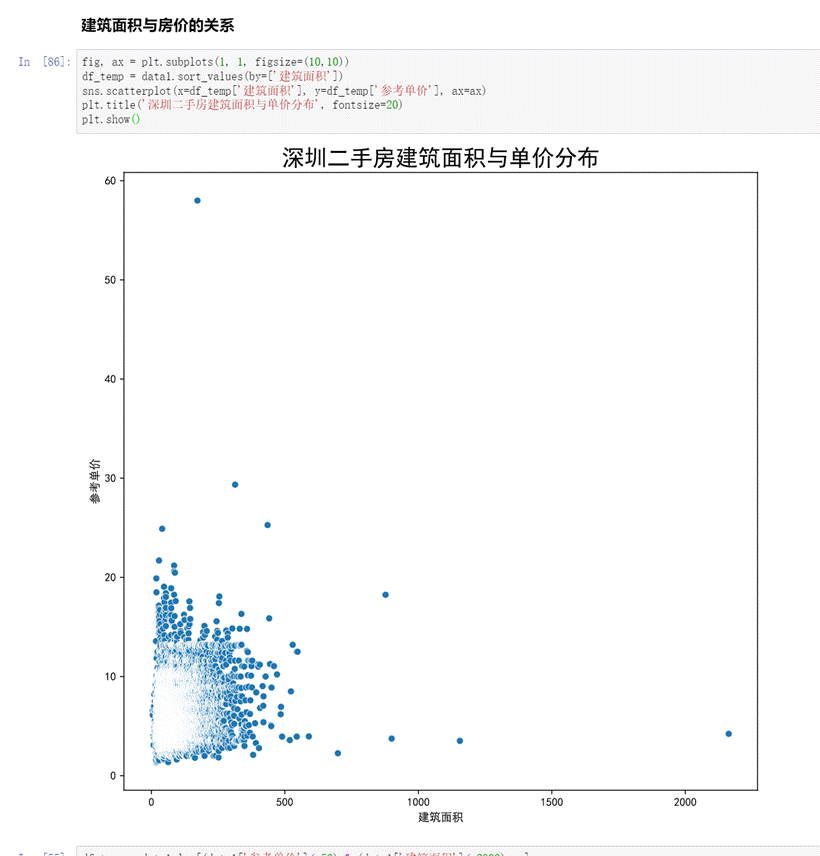
图27 房屋面积对参考单价的影响散点图
由上图看出全部数据的散点图分布较乱,看不到明显的规律。结合前面行政区划对房价的分析,猜想10个行政区内房价应该存在不同的分布规律,因此有必要区分各个行政区划:

图28 区分各个行政区划
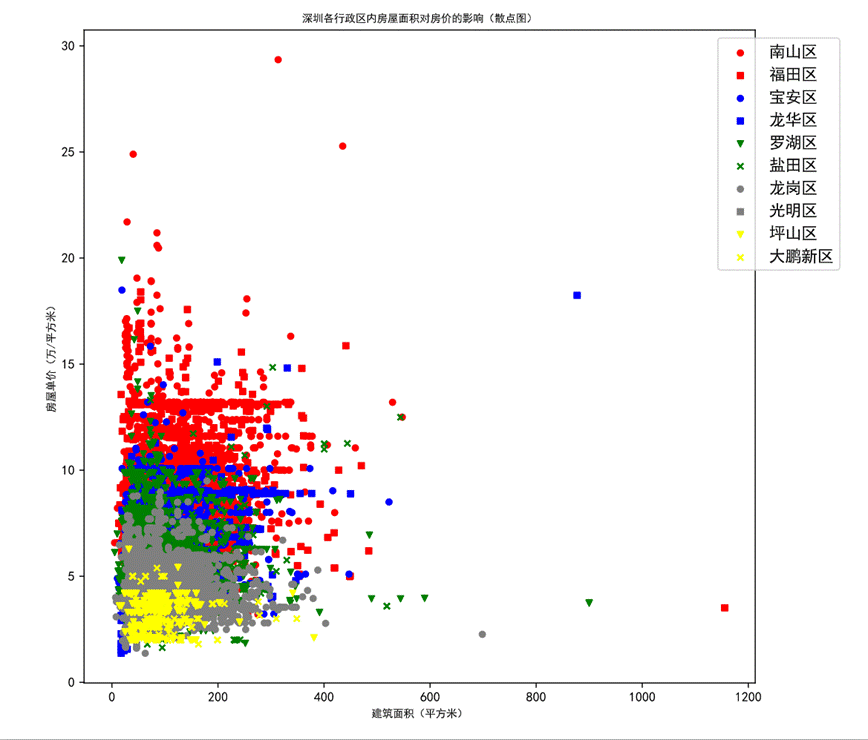
图29 深圳各行政区内房屋面积对房价的影响(散点图)
为了更好地体现各行政区划房价分布的区别,将作图范围缩小,仍包含绝大部分数据。
图例按照各行政区划平均房价的顺序排列,红色为价格第一梯队,蓝色为价格第二梯队,绿色为价格第三梯队,灰色为价格第四梯队,黄色为价格第五梯队。每个梯度包含两个行政区划。从散点图中可以明显观察到第一梯队的红色散点相对偏向左上方,第二梯队蓝色相比于第一梯度整体向下偏移,以此类推各个梯队相比于上一梯队整体向下偏移。
③为了更明显地比较各行政区房屋面积对房价影响规律,对各区的散点进行最小二乘线性拟合。
导入优化模块,作线性拟合:
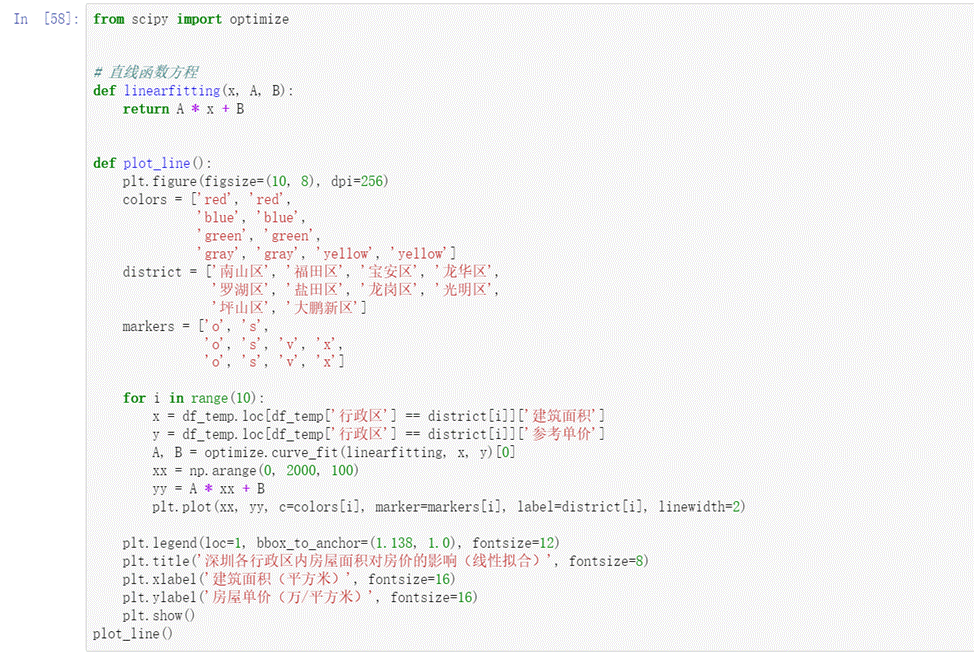
图30 线性拟合代码
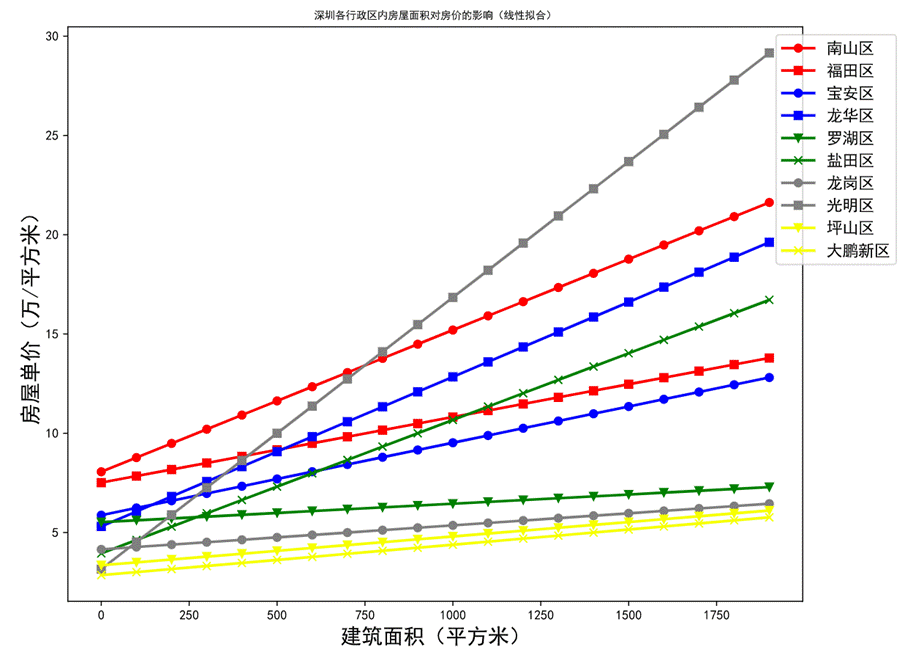
图31 线性拟合结果图
从线性拟合结果上来看,房屋单价随房屋面积的变化规律与预期相符合,即平均房价越高的行政区划,其房屋单价随房屋面积变化的回归线越偏向左上方。仅光明区和盐田区存在例外,其回归线的斜率较高。
房屋面积小时其房屋单价较低,符合预期;但随着房屋面积增大,特别是超过200平方米后其房屋单价急剧上升。探讨后认为,造成这种情况的主要原因是样本量较少,导致一部分异常数据会显著改变线性拟合的结果。
- 所在楼层对房价的影响
通过绘制三幅子图分别是深圳二手房所在楼层的占比情况(饼图)、各个行政区划的中高楼层数量堆叠图和各行政区划低中高楼层的参考单价柱状图来分析。
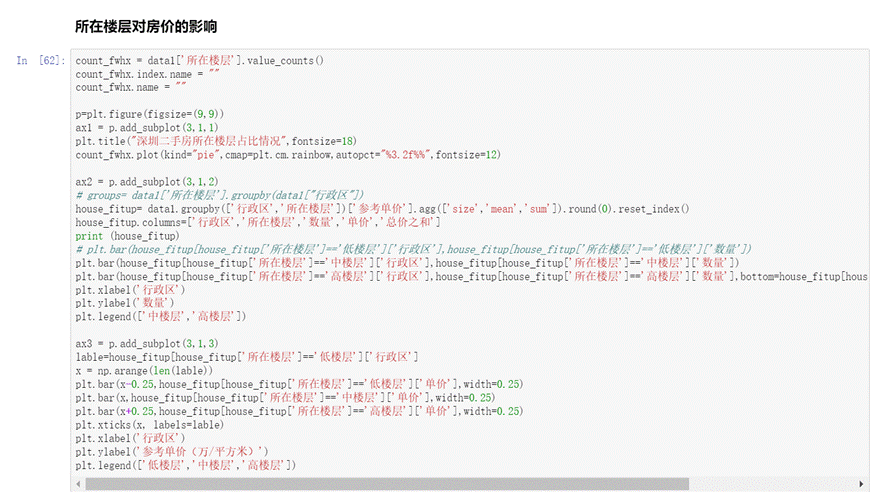
图32 所在楼层对房价的影响代码
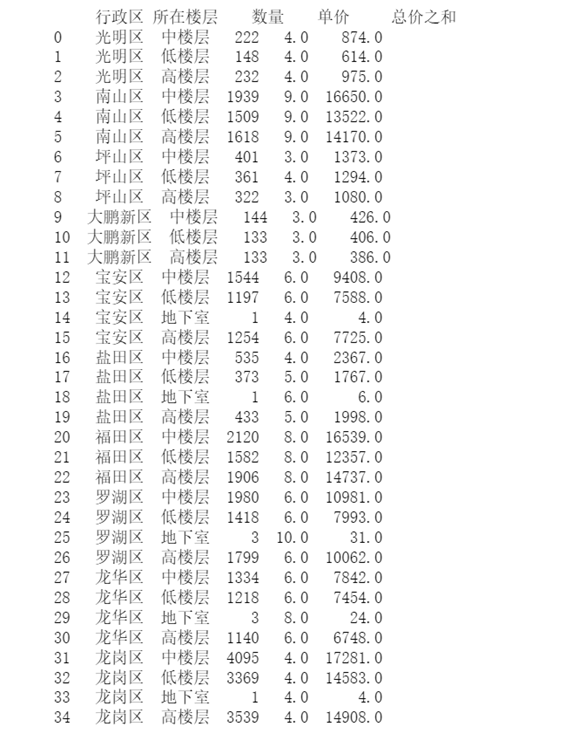
图33 所在楼层对房价的影响结果
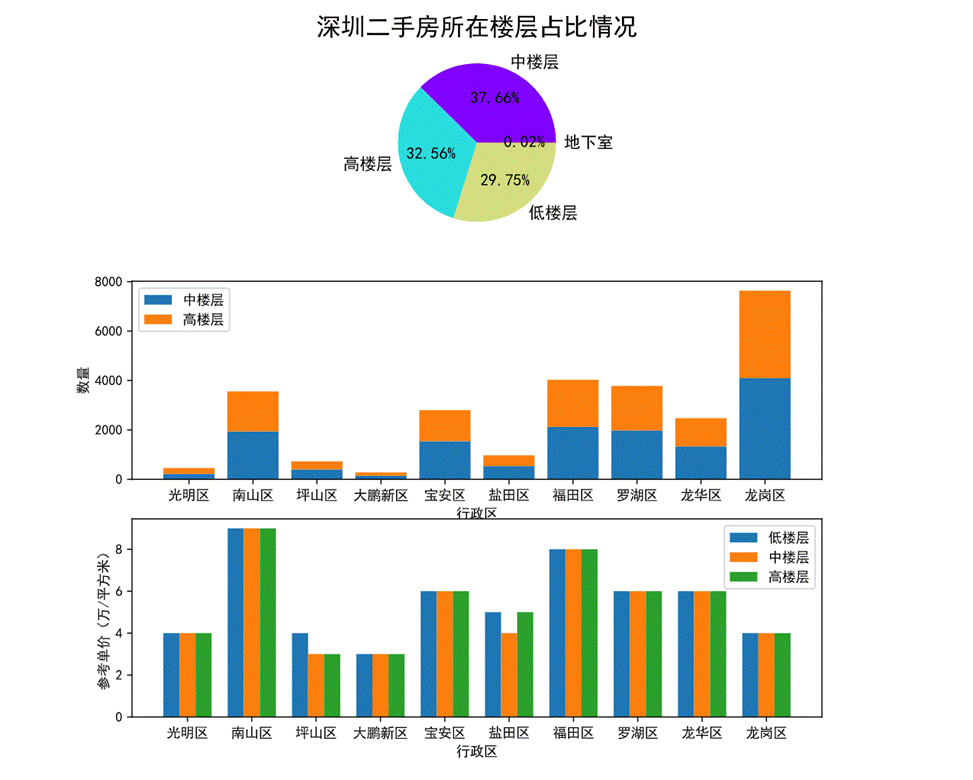
图34 所在楼层对房价的影响可视化
首先通过第一幅饼图可以看出,深圳二手房所在楼层的占比情况,中层占比最高达37.66%其次是高楼层占32.56%、低楼层占29.75%,最后地下室占0.02%。
通过第二幅堆叠图可以看出各行政区划中高楼层的占比情况及数量,基本上是各占一半。
第三幅柱状图可以看出低中高楼层在各个行政区划的参考单价,其中南山区三种楼层的单价相近且最高,大鹏新区的三种楼层单价相近且最低。只有坪山区和盐田区的三种楼层间的单价不太一致。
- 户型结构对房价的影响
通过绘制两幅子图分别是深圳二手房户型结构的占比情况(饼图)、各行政区划不同户型结构的参考单价柱状图来分析。

图35 户型结构对房价的影响
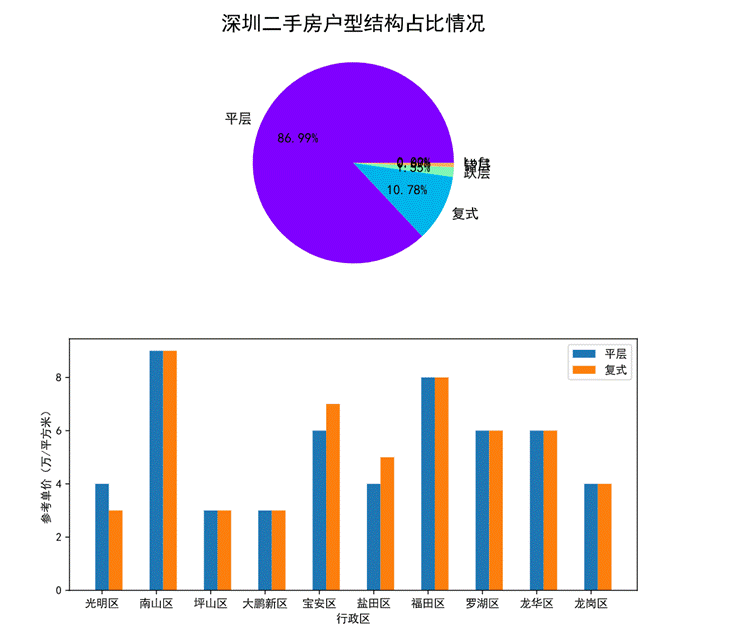
图36 户型结构对房价的影响可视化
通过第一幅饼图可以看出深圳二手房户型结构的整体占比情况,平层结构的存量居多,和第二名复式结构的比例大概是8:1,最后是错层和跃层占比较低。这个数据也和现有普通开发商楼盘对应的户型结构比例相近,因此我们主要分析平层和复式结构对房价的影响。
第二幅柱状图可以看出平层和复式在各个行政区划的参考单价,其中南山区两种结构户型单价相近且最高,大鹏新区和坪山区的两种结构户型单价相近且最低。只有光明区、宝安区、盐田区的三种楼层间的单价不太一致。此外还可以看出除了光明区 其他几个区大多数都是复式价格大于平层。
- 建筑类型对房价的影响
通过绘制三幅子图分别是深圳二手房建筑类型的占比情况(饼图)、各个行政区划的板塔结合和塔楼的数量堆叠图和各行政区划建筑类型的参考单价柱状图来分析。

图37 建筑类型对房价的影响
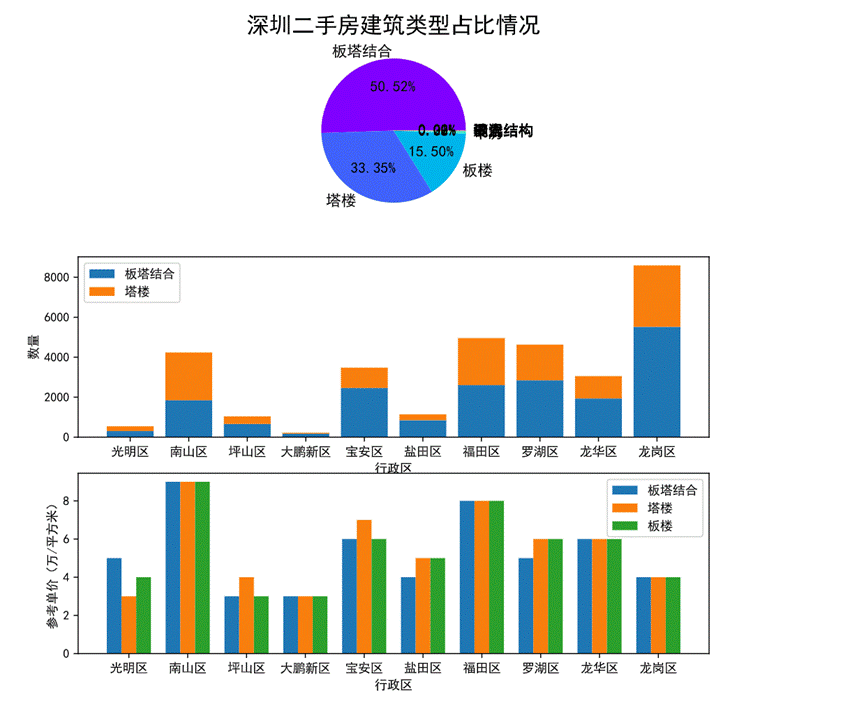
图38 建筑类型对房价的影响可视化
首先通过第一幅饼图可以看出,深圳二手房建筑类型整体的占比情况,板塔结合占比最高达50.52%其次是塔楼占33.35%、板楼占15.5%,平房、钢混结构、混合结构等几种占比较低。
通过第二幅堆叠图可以看出各行政区划中板塔结合和板楼两种建筑类型的占比情况及数量。只有南山区的塔楼建筑类型比板塔结合类型多。
第三幅柱状图可以看出板塔结合、塔楼、板楼三中建筑类型在各个行政区划的参考单价,其中南山区三种建筑类型的单价相近且最高,大鹏新区的三种建筑类型单价相近且最低。
- 建筑结构对房价的影响
通过绘制三幅子图分别是深圳二手房建筑结构的占比情况(饼图)、各个行政区划的钢混结构和框架结构的堆叠图和各行政区划不同建筑结构的参考单价柱状图来分析。

图39 建筑结构对房价的影响
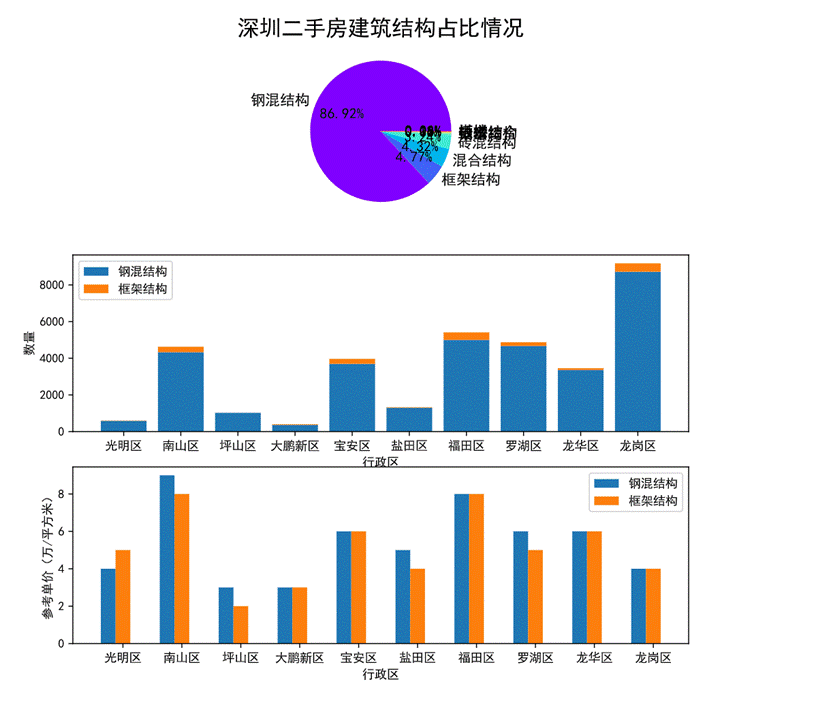
图40 建筑结构对房价的影响可视化
第一幅饼图可以看出,深圳二手房建筑结构整体的占比情况,钢混结构占比最高达86.92%其次是框架结构占4.77%,这个数据也和现有建筑对使用的建筑结构相近。因此我们主要分析钢混结构和框架结构对房价的影响。
通过第二幅堆叠图可以看出各行政区划中钢混结构和框架结构两种建筑结构的占比情况及数量,可以看出各个行政区划的建筑结构基本上都是钢混结构。
第三幅柱状图可以看出钢混结构、框架结构这两种建筑结构在各个行政区划的参考单价,其中钢混结构在南山区的参考单价最高,框架结构在南山区和福田区的参考单价相近且最高。此外只有光明区的钢混结构单价高于框架结构单价。
- 抵押信息对房价的影响
通过绘制三幅子图分别是深圳二手房抵押信息的占比情况(饼图)、各个行政区划有无抵押的堆叠图和各行政区划有无抵押的参考单价柱状图来分析。

图41 抵押信息对房价的影响
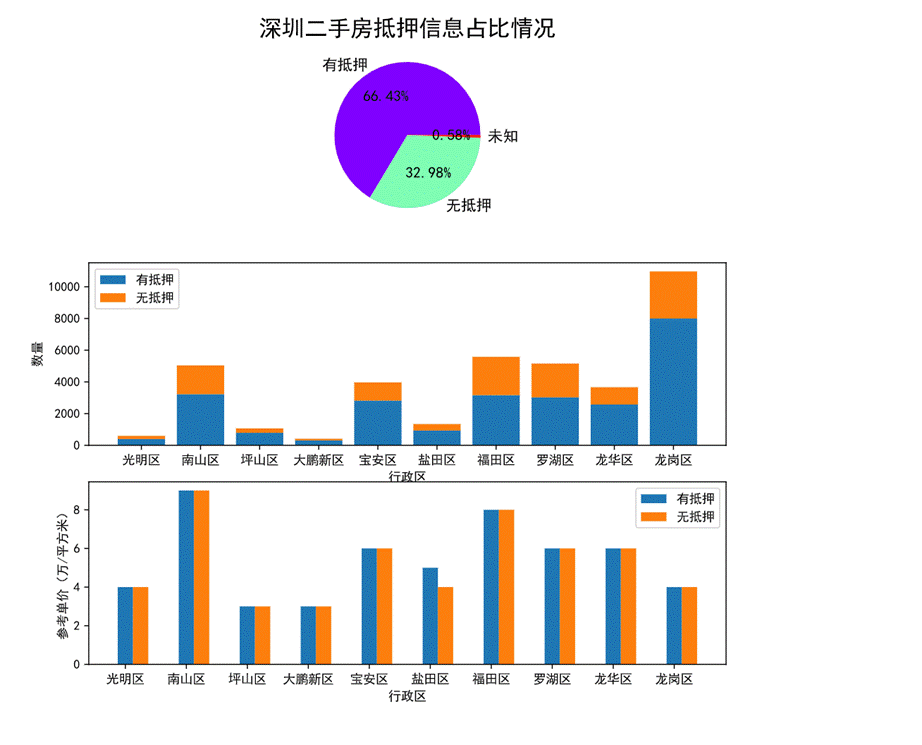
图42 抵押信息对房价的影响可视化
第一幅饼图可以看出有抵押的二手房是无抵押的两倍,基本上每个房源都有明确的是否抵押信息。
第二幅堆叠图可以看出福田区的无抵押的房源占比相比于其他行政划区而言最高。
第三幅柱状图可以看出,只有盐田区的有抵押房源单价高于无抵押的房源单价,其余行政划区有无抵押的房源单价均相近。
- 房屋年限对房价的影响
通过绘制三幅子图分别是深圳二手房房屋年限的占比情况(饼图)、各个行政区划有房屋年限堆叠图和各行政区划有房屋年限的参考单价柱状图来分析。

图43 房屋年限对房价的影响
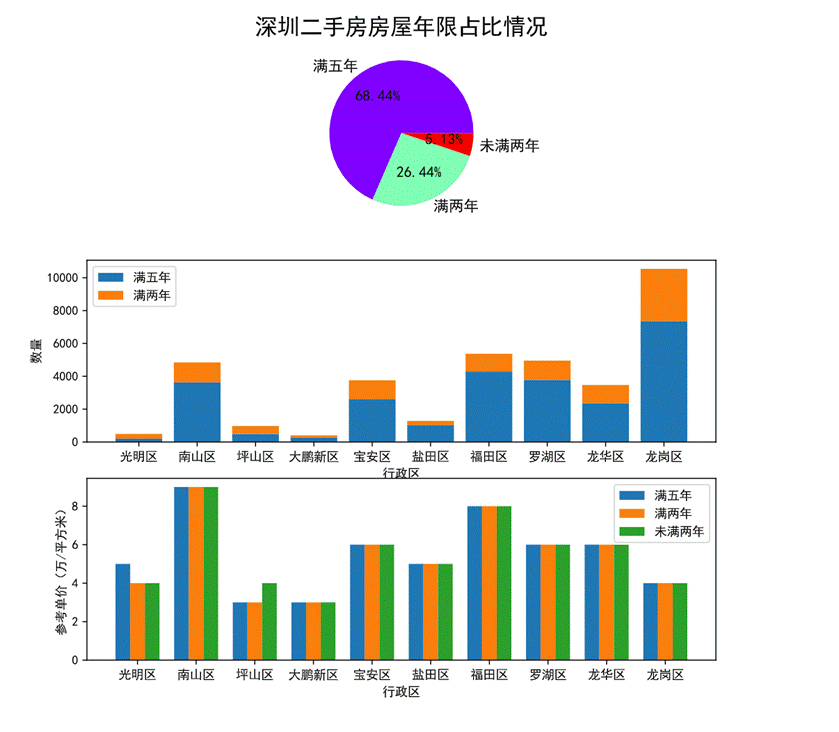
图44 房屋年限对房价的影响可视化
通过第一幅饼图可以看出深圳二手房的房屋年限已满五年的占比达68.44%超过整体房源的一半,其次是满两年的占整体的26.44%,未满两年的仅占5.13%。
第二幅堆叠图展现了各个行政区划房屋年限满五年和满两年的占比及数量。其中盐田区房源满五年的占比最高。可以看出盐田区相比于其他行政区划旧楼要多一点。
第三幅柱状图展现了各个行政区划不同房屋年限的参考单价,其中南山区不论房屋年限多少参考单价都相近且最高,光明区满五年的参考单价比其他两种高,坪山区未满两年的房屋单价比其他两种高。
- 装修情况对房价的影响
通过绘制三幅子图分别是深圳二手房装修情况的占比情况(饼图)、各个行政区划有装修情况堆叠图和各行政区划有装修情况的参考单价柱状图来分析。
图45 装修情况对房价的影响
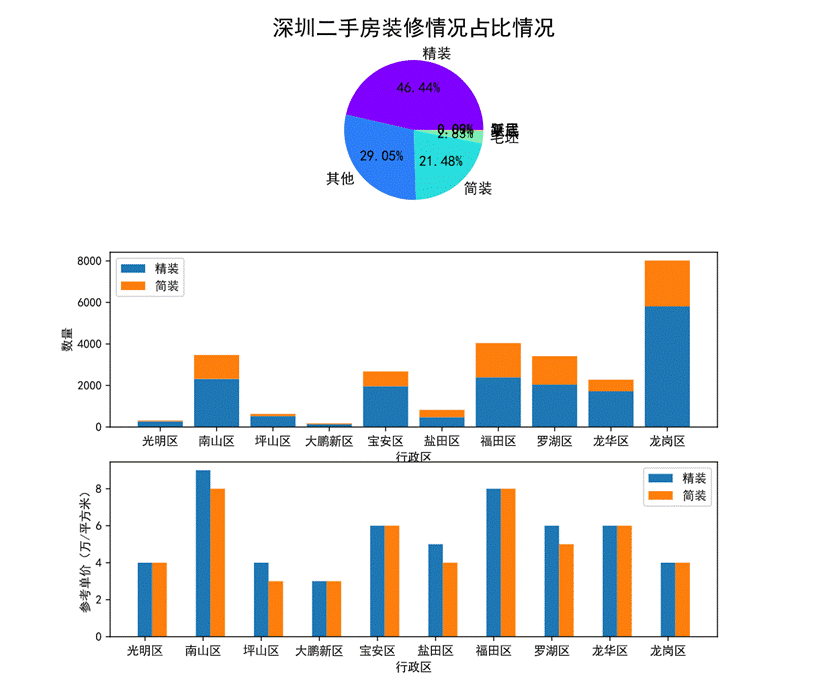
图46 装修情况对房价的影响可视化
第一幅饼图展现了深圳二手房装修情况的占比,精装房源将近占整体的一半(46.44%),有29.05%的房源并未说明装修情况,21.48%的房源是简装。
第二幅堆叠图展现了各行政区划精装和简装的房源数量及占比,其中光明区的房源基本都是精装,福田区简装的房源占福田区整体房源比例最大。
第三幅柱状图可以看出各个行政区划简装和精装的参考单价,南山区的精装参考单价最高,对于简装的单价福田区和南山区相近且最高。
- 配备电梯对房价的影响
通过绘制三幅子图分别是深圳二手房是否配备电梯的占比情况(饼图)、各个行政区划是否配备电梯情况的堆叠图和各行政区划是否配备电梯的参考单价柱状图来分析。

图47 配备电梯对房价的影响
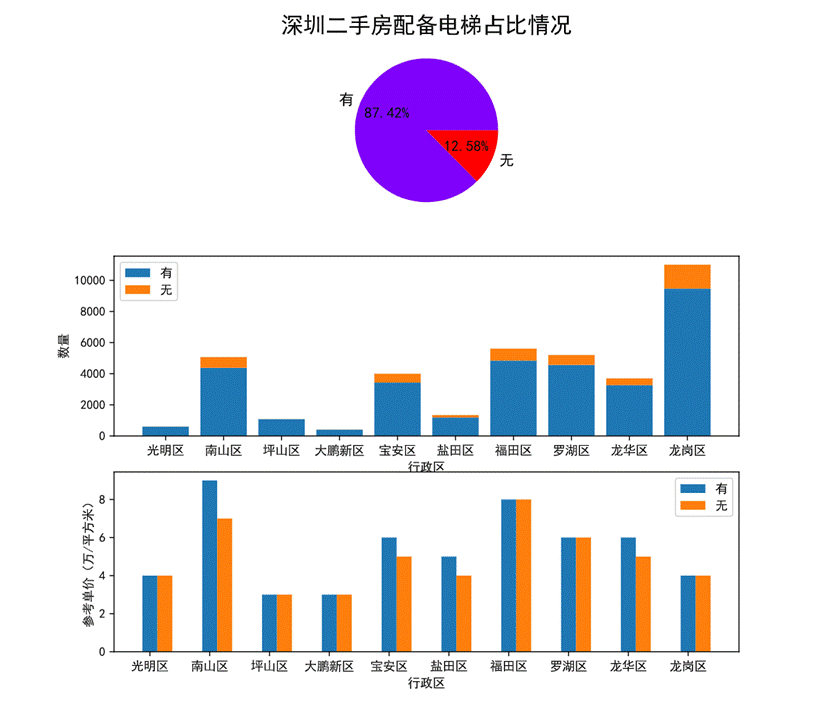
图48 配备电梯对房价的影响可视化
第一幅饼图展示了深圳二手房是否配备电梯的比例情况,可以看出大部分房源都是配备了电梯的,与没有配备电梯相比接近9:1的比例。
第二幅图堆叠图可以看出各个行政区划是否配置电梯的数量及比例,光明区、坪山区、大鹏新区的房源基本上都有电梯。
第三幅图柱状图展示了各个行政区划是否配置电梯的参考单价,南山区两者的参考单价悬殊较高可以看出南山区配置了电梯的房源的参考价格高于其他所有地区的价格,属于繁华地段。
- 深圳二手房房屋户型占比情况
绘制饼图如下所示。

图49 深圳二手房房屋户型占比情况
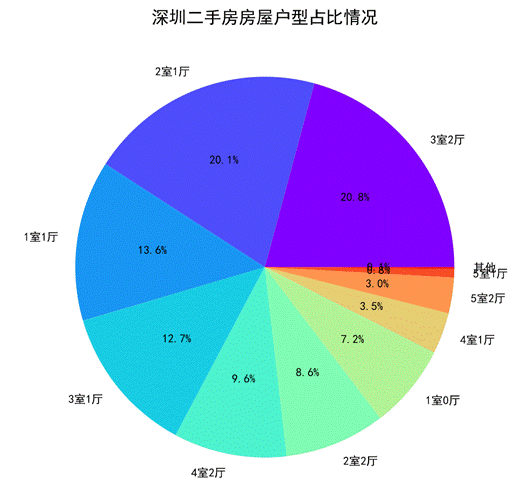
图50 深圳二手房房屋户型占比饼图
通过饼图展示的深圳二手房房屋户型占比情况可以看出,2室1厅和3室2厅这种房源比较普遍,也比较符合当下的社会需求。5室1厅和5室2厅的房源较少,这种户型可能不太适用。
- 深圳二手房所在楼层占比情况
绘制柱状图如下。

图51 二手房所在楼层数量分布
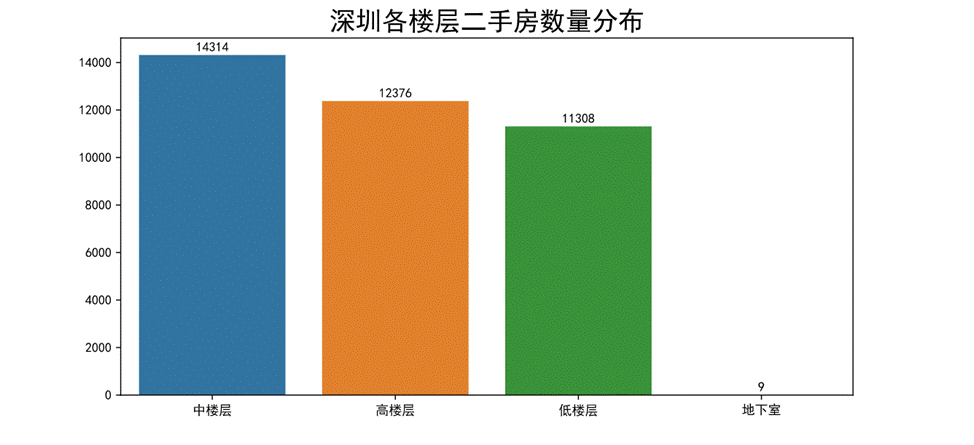
图52 二手房所在楼层数量分布柱状图
通过柱状图可以看出深圳二手房楼层为中楼层的房源数目较多,高楼层和低楼层的房源数目相差不大,地下室的数目极少几乎没有这种房源。
- 深圳二手房房屋朝向分布情况
绘制柱状图如下。

图53 二手房房屋朝向的占比情况
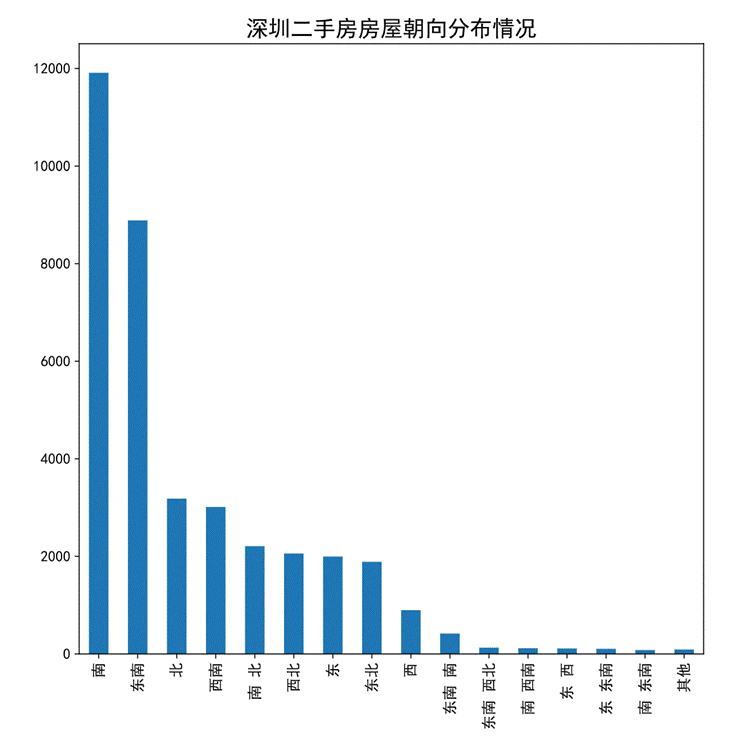
图54 二手房所在楼层占比情况柱状图
通过柱状图可以看出,房屋朝向为南的数目最多,其次为东南朝向,朝向为北和朝向为西南的房源数目相近,朝向为南北、西北、东、东北的数目相近,纵观整个图以指数递减的趋势。
- 深圳各区域二手房平均单价

图55 二手房平均单价
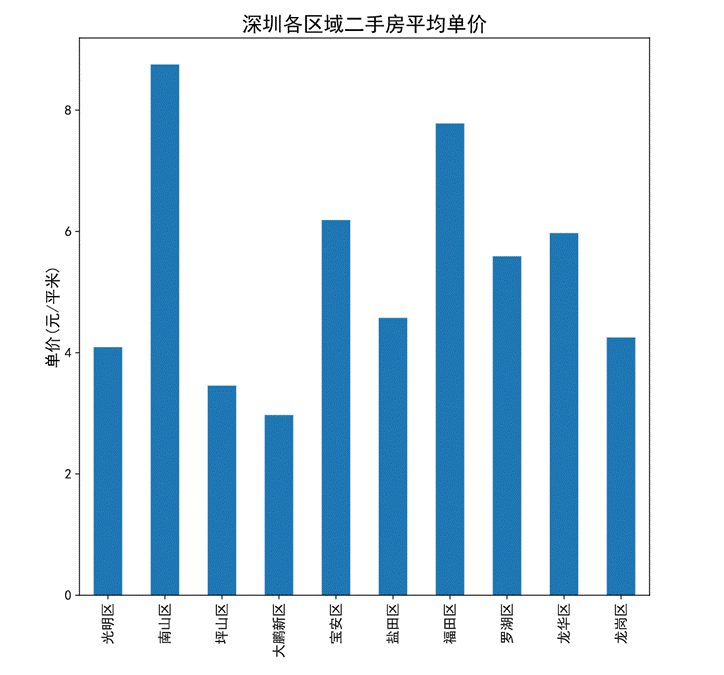
图56 二手房平均单价柱状图
通过柱状图可以看出深圳二手房的单价从高到底依次是南山区,福田区,宝安区,龙华区,罗湖区,盐田区,龙岗区,光明区,坪山区最后是大鹏新区。可以看出南山区较为繁华房价较高,与大鹏新区相比单价差距较大。
- 结论
上述探索式分析主要从七大方面来展开,分别是整体房价分析、地理因素对房价的影响、房屋类型(再细分为建筑面积、所在楼层、户型结构、建筑结构、建筑类型、抵押信息、房屋年限、装修情况、配备电梯九大因素)对房价的影响,以及深圳二手房房屋户型占比情况、朝向分布情况、所在楼层分布情况、平均房价占比情况。
整体房价分析得出深圳二手房的最高价格超过50万元/平方米,最低价格不高于2万元/平方米,差距极大,房价的平均数和中位数均在5-6万元/平方米。
通过探讨九种不同房屋类型因素对房价的影响,南山区的参考单价无论在是何种因素下都位列第一,属于繁华地段。相反,大鹏新区的参考单价基本上均是最低。总的来说对房价影响较大的因素有六个分别是行政区、建筑面积、户型结构、装修情况、配备电梯、建筑结构。
对于户型而言,2室1厅和3室2厅这种房源比较普遍,也比较符合当下的社会需求。5室1厅和5室2厅的房源较少,可能不太适用。因此通过满足不同个人或家庭对于户型的需求,对于房屋均价较高的深圳而言,2室1厅足够满足大部分家庭的需要,因此较受欢迎。
对于朝向而言,房屋朝向为南的数目最多,其次为东南朝向。根据历史情况而言,从古至今,坐北朝南都是公认的最好的朝向,朝南房间明亮一些,干燥些,朝北的房子阴暗潮湿一点,因此房屋朝向为南的房屋数目最多,也比较随主流。
对于二手房楼层而言,中楼层的房源数目较多,高楼层和低楼层的房源数目相差不大。在现实生活中,如果楼层过高,停水停电会很麻烦,太低会很潮湿,终日见不到阳光。
对于平均单价而言,从高到底依次是南山区,福田区,宝安区,龙华区,罗湖区,盐田区,龙岗区,光明区,坪山区最后是大鹏新区。
四、数据分析模型
- 结合分析的目标,拟采用哪一种模型(如聚类、分类、回归)开展分析
综合考虑多个因素对房价的影响,并建立预测模型。通过对数据进行一系列的分析,选择对房价有明显影响的6个因素(行政区、建筑面积、户型结构、装修情况、配备电梯、建筑结构)。
因为预测目标—房价是一个连续变量,所以本实验中的房价预测属于一个回归问题。
常见的机器学习回归模型有线性回归、K近邻、支持向量机、回归树和随机森林等。本次实验选用三类模型分别是线性回归、支持向量机和随机森林来进行对房价的预测。
- 模型评估
选用的模型是线性回归、支持向量机和随机森林三种模型。在训练模型和预测完成后,需要对模型的预测效果进行评价。常用的评价指标有:平均绝对误差(mean_absolute_error)、均方误差(mean_squared_error)、中位数绝对误差(median_absolute_error)、解释方差得分(explained_variance_score)以及R方得分(r2_score)。
本次实验使用均方误差和R方得分两个指标,期望均方误差尽量低,R方得分尽量高。
- 可视化结果
- 对数据进行了一系列的分析,所选的因素均对房价有明显影响,并且所有数据不存在缺失现象。但行政区划为文字,所以需要使用one-hot编码,one-hot编码是将定类的非数值型类型量化的一种方法,在pandas中使get_dummies() 方法实现。

图57 one-hot编码
使用one-hot编码修改特征“行政区”、“户型结构”、“装修情况”、“配备电梯”、“建筑结构”后结果如下:
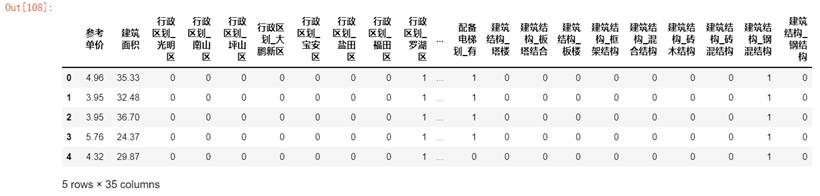
图58 编码结果
绘制热力图结果如下所示。

图59 绘制热力图
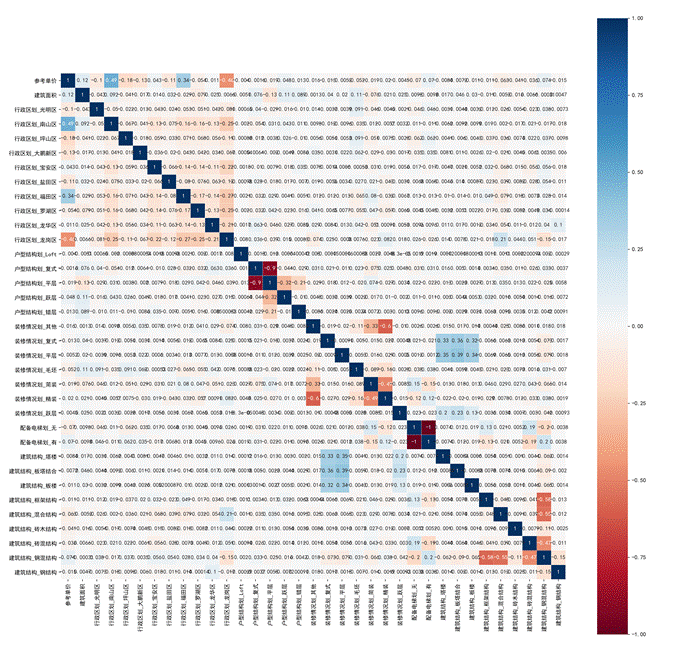
图60 热力图
可以根据颜色观察特征的相关性。颜色偏红或者偏蓝都说明相关系数较大,即两个特征对于目标变量的影响程度相似,也就是说存在严重的重复信息,会造成过拟合现象。通过特征相关性分析,可以找出哪些特征有严重的重叠信息,然后择优选择。
- 确定数据中的特征与标签、数据分割,随机采样25%的数据作为测试样本,其余作为训练样本,最后进行数据标准化处理。

图61 分割及标准化
- 使用线性回归模型预测
图62 线性回归模型预测
- 使用支持向量机模型预测

图63 支持向量机模型预测
- 使用随机森林回归

图64 随机森林回归
- 本实验中调用均方误差MSE和R方得分两个指标,期望均方误差尽量低,R方得分尽量高:
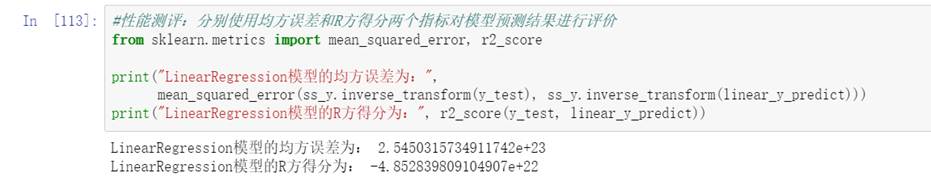
图65 线性回归模型R方

图66 支持向量机模型R方

图67 随机森林模型R方
通过比较三种回归模型的两种评价指标的结果,可以看出,R方得分与均方误差成负相关关系,因此只看一个指标即可。R方得分越高,模型的预测能力越强。则本实验中所用到的回归模型中随机森林回归模型的预测能力最强。
(7)为能更加直观地对比不同模型的预测能力,下面对线性回归模型、支持向量机模型、随机森林回归预测结果进行可视化处理。
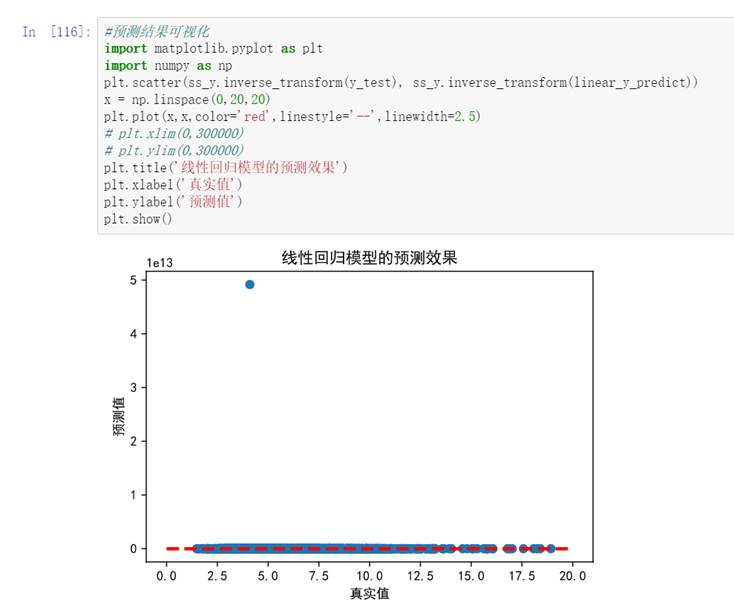
图68 线性回归模型预测效果
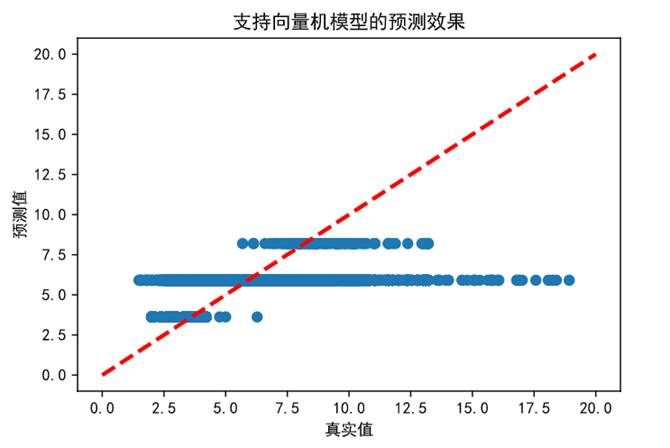
图69 支持向量机模型预测效果
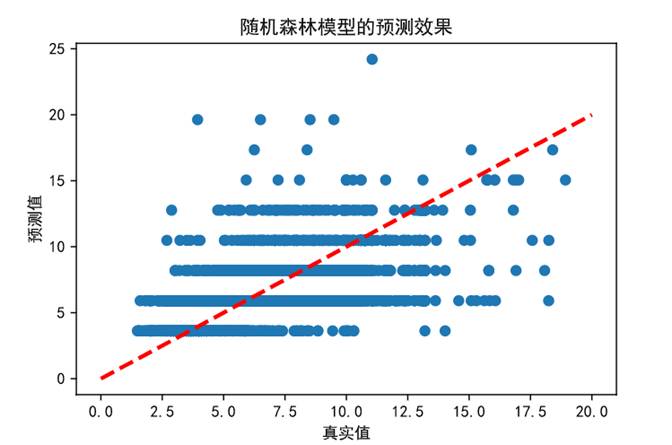
图70 随机森林模型预测效果
上幅图随机森林回归模型在低房价区间预测效果较好,但随着房价超过14万元/平方米后预测值偏低。
五、方案评估
本次课程设计达到了预期的目标,完成了所有设计任务,体现在四个方面分别是明确分析目标与任务、进行数据预处理、数据探索分析(七大方面)、数据分析模型。课程设计可以说是一门课程的总结,设计难度中等,仍存在着一些问题,在爬取数据时,有些数据的字段位置错乱,数量较少,故我们直接将它删除,可能预测结果的准确性会略微降低一点。并且在进行探索分析的时候,有的字段对房价影响不大,有的字段影响较大,对于影响不那么明显的字段我们也选取了来进行预测,可能会出现问题。最后存在的问题是在使用随机森林模型预测的时候R方只有0.3左右,过于低,预测效果很不好,需要进行进一步检查以及优化。