论文阅读笔记——Janus,Janus Pro
Janus
Janus 论文
- 理解任务(VQA)需要高层语义特征如物体类别、关系(信息压缩)
- 生成任务依赖细粒度细节如局部纹理,去模拟数据的分布(信息扩展)
- 单一编码器无法同时满足两种要求,导致性能受限(尤其在理解任务)
Janus 的创新点在于通过视觉编码解耦同时优化多模态理解和生成任务,理解上采用 SigLIP 提取全局语义特征,生成上用 VQ-GAN,保留局部细节信息。

| 任务类型 | 编码方法 | 特征 |
|---|---|---|
| 纯文本理解 | LLM 内置的文本分词器 | 文本->离散ID->LLM词嵌入特征 |
| 多模态理解 | SigLIP 编码器 | 图像->SigLIP->展平1D->Adapter 映射 |
| 视觉生成 | VQ-GAN 编码器 | 图像->VQ 离散 ID 序列->展平1D->Adapter 映射 Codebook |

- Stage 1:训练 Adapter 与图像头,让视觉和文本在 Embedding Space 上建立联系,数据上 1.25M 来自 ShareGPT4V 的 image-text pair 标注( < i m a g e > < t e x t > <image><text> <image><text>),1.2M ImageNet-1K 图片用于生成( < c a t e g o r y _ n a m e > < i m a g e > <category\_name><image> <category_name><image>)。
- Stage 2:训练除 Encoder 之外的所有部分,视频生成上分两步。第一步(前 66.67% step)用 ImageNet-1k,类别作为 prompt,让模型学习像素级依赖关系;第二部加入文本-图像数据,提升复杂语义对齐能力。数据包括 DeepSeek-LLM 的纯文本数据、WikiHow 和 WIT 文本-图像数据集、对 COCO 等数据集用开源大模型 Image caption 数据(QA 对形式)、DeepSeek-VL 表格数据( < q u e s t i o n > < a n s w e r > <question><answer> <question><answer>)、LAION 和 Conceptual 等视觉生成数据,比例上为 3:2:2:1:2。(类似 PixArt)
- Stage 3:使用指令微调数据对预训练模型进行微调,以增强其遵循指令和对话能力。(KaTeX parse error: Undefined control sequence: \textbackslash at position 22: …Input Message> \̲t̲e̲x̲t̲b̲a̲c̲k̲s̲l̲a̲s̲h̲ ̲n Assistant:<Re…)
- 使用 CE Loss,生成任务仅计算图像 token 的 loss,理解任务仅计算文本 token 的 loss。
- 使用 CFG, l g = l u + s ( l c − l u ) , s = 5 l_g=l_u+s(l_c-l_u)\qquad , s=5 lg=lu+s(lc−lu),s=5 其中 l c l_c lc 为条件 logit, l u l_u lu 为无条件 logit。训练时,以 10% 概率用空 token 替换。
- 训练在 8 卡 A100 16节点集群,耗时 7 天。
实验结果
多模态理解
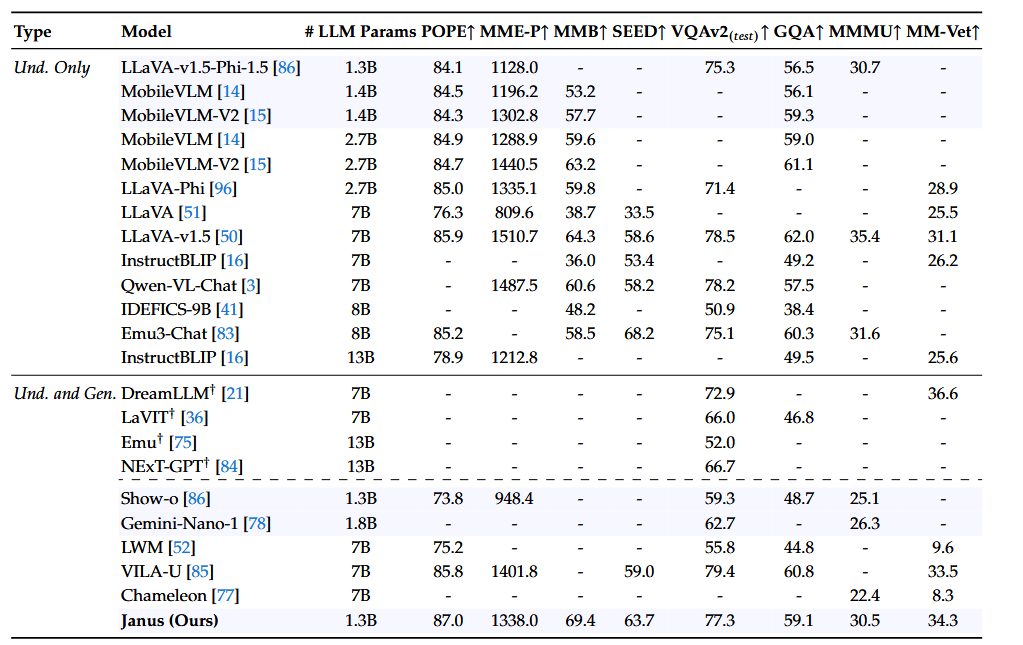
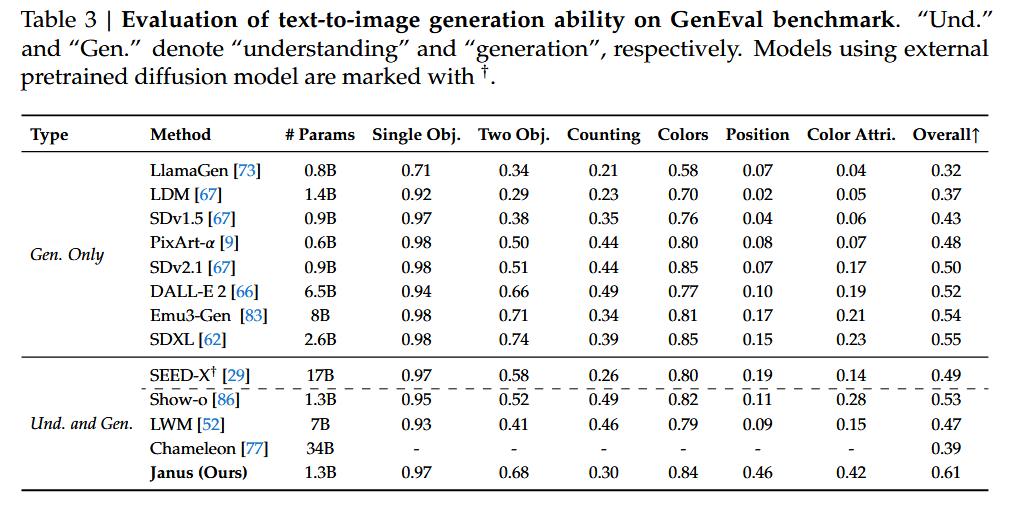
图片生成

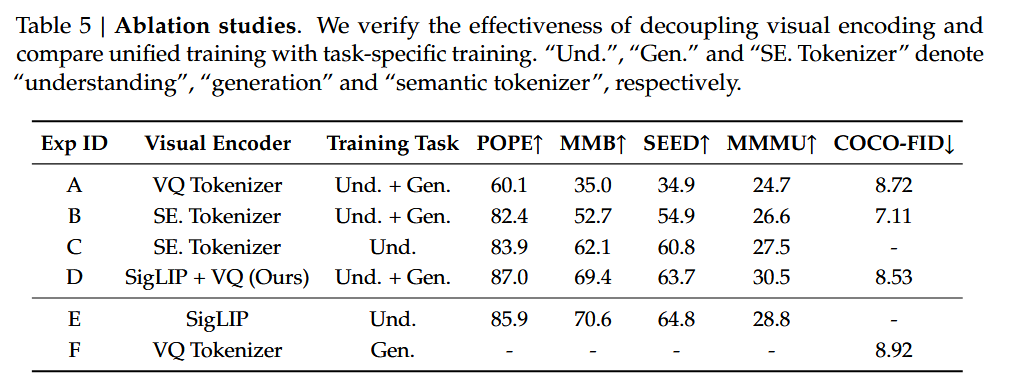
消融实验
Janus Pro
Janus Pro 论文
主要改进在于训练策略、数据、模型大小。
- Stage 1:Janus 的 Stage 1 训练步数较少,仅建立初步视觉-语言关联,Janus Pro 大幅增加训练步数。作者发现不更新 LLM 参数下,模型已经能建模像素依赖关系,可以减少后续对低质量类别标签(ImageNet短文本)的依赖。
- Stage 2:移除 Janus 中 ImageNet 数据,使用高质量文本-图像数据(避免冗余的像素依赖学习)增强开放域生成能力。
- Stage 3:多模态数据由 Janus 的 7:3:10 调整至 5:1:4(与MetaMorph类似,同样数据量下,增加理解任务数据对生成任务的提升 > 增加生成任务数据对生成任务的提升)
数据规模上,增加约 900 万的多模态理解数据,新增 MEME 理解数据、中文对话数据以及对话体验优化数据集。生成任务引入合成数据,大概 70M,真实数据和合成数据将近1:1。
模型大小由 Janus 的 1.5B 提升至 7B,多模态任务损失收敛速度提升 40%,证明了 Scaling Law。
实验结果
多模态理解
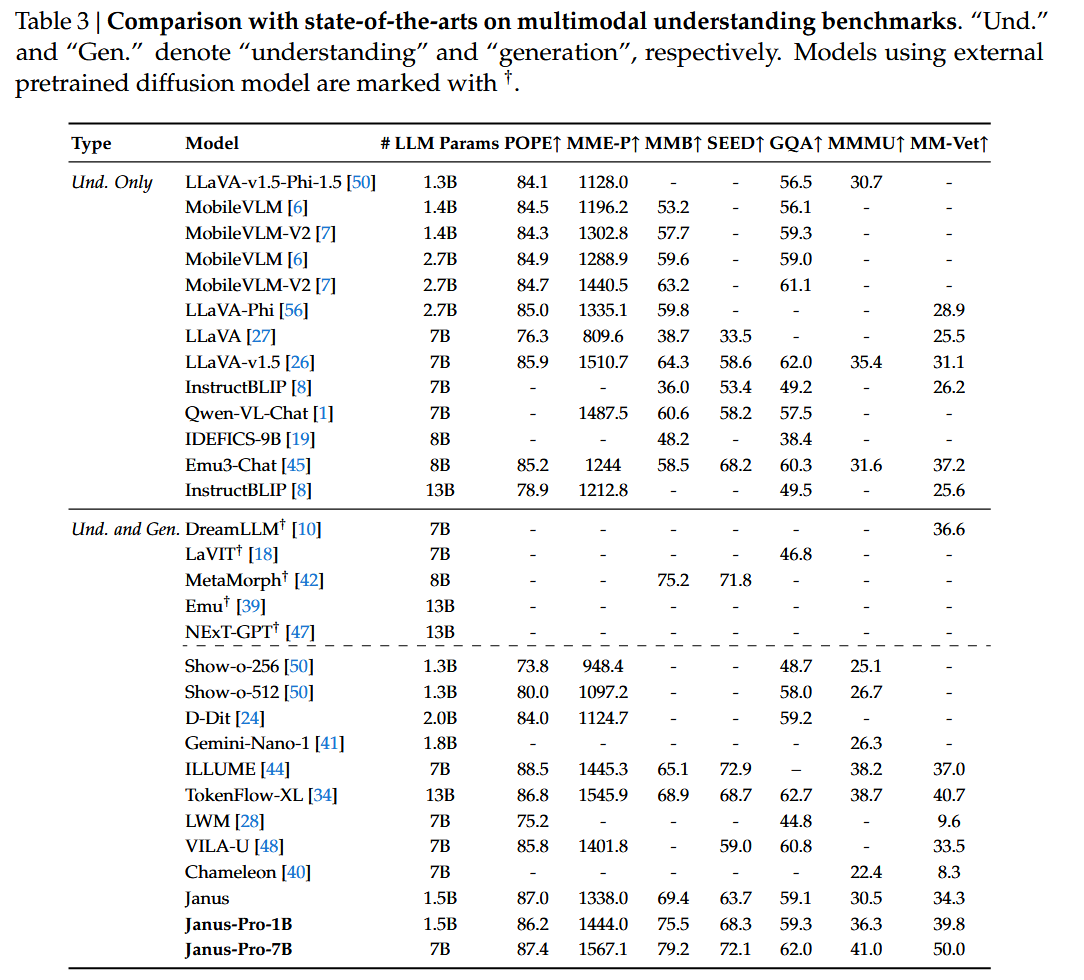
图片生成
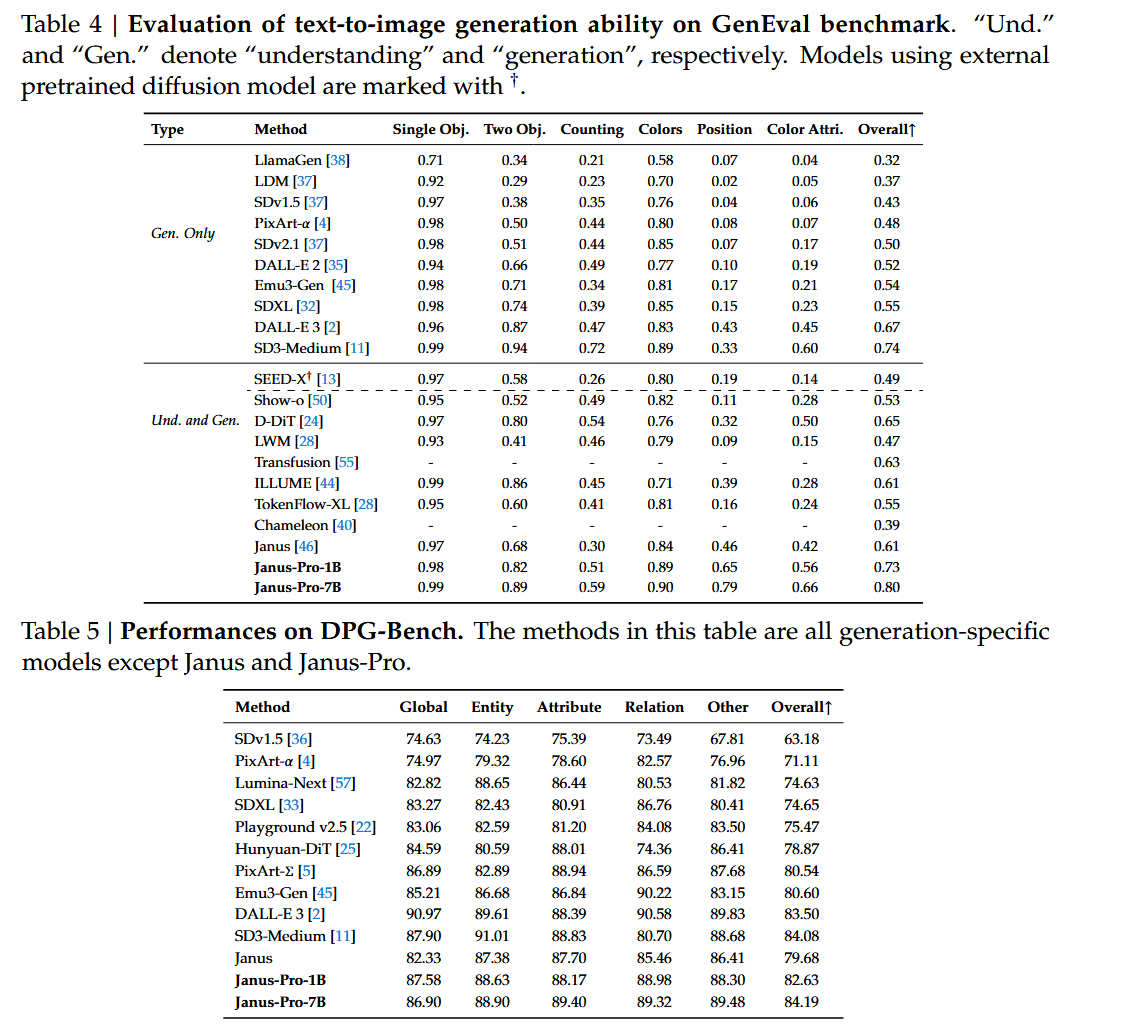
总结:Janus 和 Janus Pro 在理解生成任务上迈出了很好的一步,在单独的多模态理解任务上可能还是比不过 InternVL2.5,但他的工作还是很有意义的。