docker部署并测试翻译模型-CSANMT连续语义增强机器翻译
1.模型选择CSANMT-Translation模型:
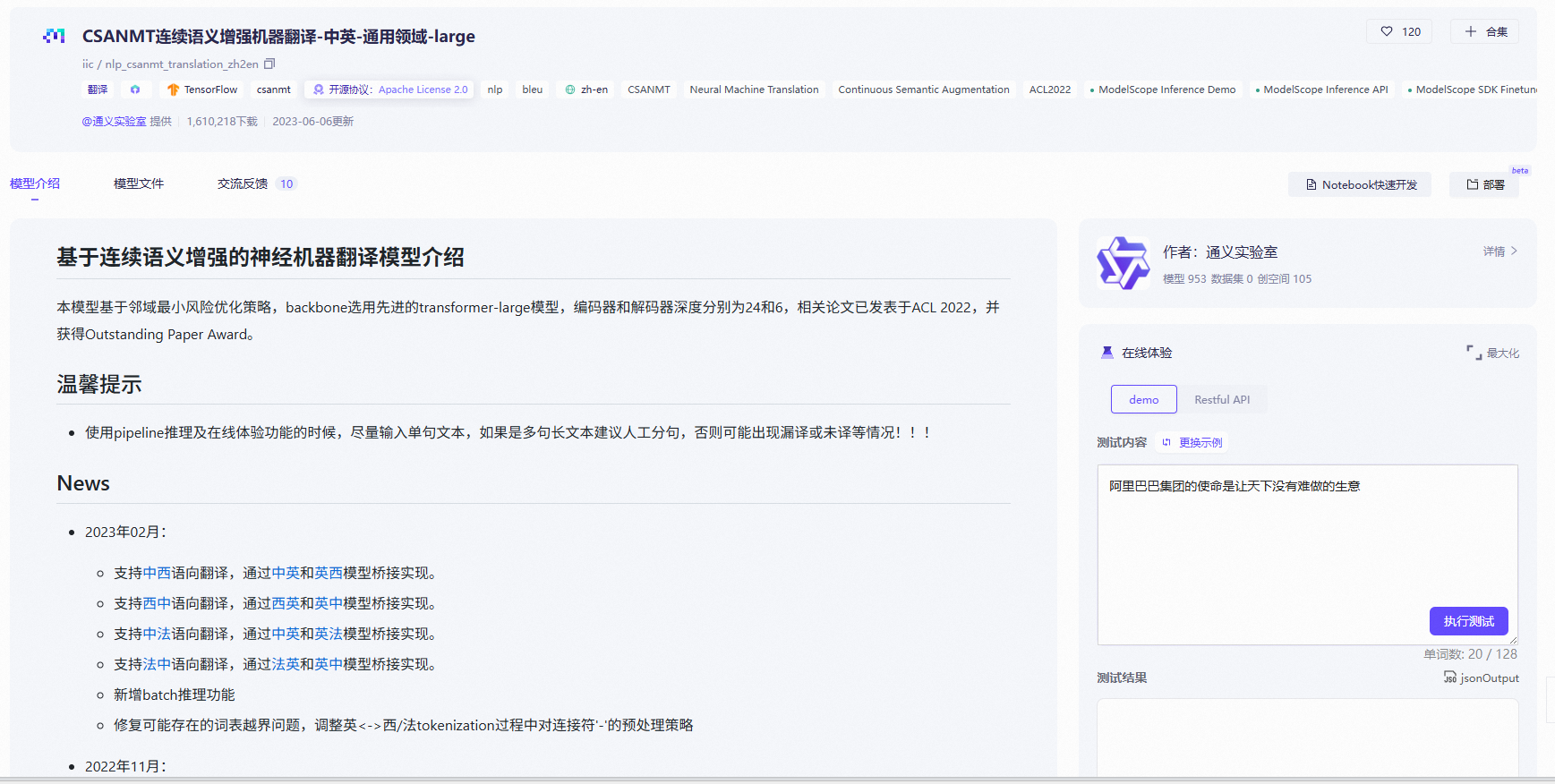
2.修改docker-compose.yml文件,重新定义模型缓存路径和存储路径
其中MODELSCOPE_CACHE指定了模型的下载路径。
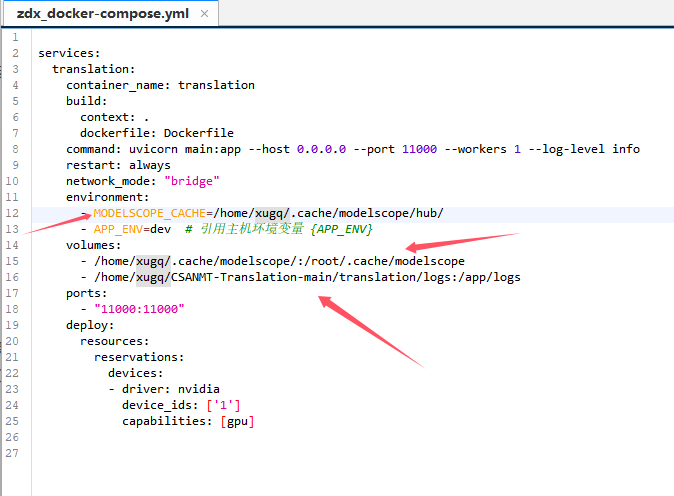
3.运行docker compose up -d --build,提示出现报错:Error response from daemon: could not select device driver “nvidia” with capabilities: [[gpu]]。
根据报错信息Error response from daemon: could not select device driver "nvidia" with capabilities: [[gpu]],这表明 Docker 无法正确识别 NVIDIA GPU 设备驱动。结合搜索结果,问题主要出在 NVIDIA 容器工具包配置错误,如果没安装nvidia驱动,则还需要安装驱动。
若需指定特定 GPU,使用 --gpus '"device=0,1"' 参数。
修改 /etc/docker/daemon.json,添加以下内容:
{"runtimes": {"nvidia": {"path": "nvidia-container-runtime","runtimeArgs": []}}
}
结果如下:
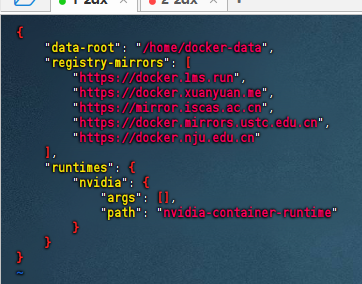
4.修改python脚本,指定文件路径,并确定文本切片函数:
5.再次运行docker compose up -d启动docker 容器:
成功启动容器,以下是模型的部分参数:
以下是这些参数的详细解释:
一、模型架构核心参数
hidden_size: 1024- 作用:表示Transformer每层隐藏状态的维度大小,对应多头注意力机制中的向量维度(d_model)
- 典型值范围:512-4096(大型模型常用1024以上)
filter_size: 4096- 作用:前馈神经网络(Feed-Forward Network)中间层的神经元数量
- 计算公式:FFN(x) = ReLU(xW1 + b1)W2 + b2,其中 W1 ∈ ℝ1
num_heads: 16- 作用:多头注意力机制的头数,每头独立学习不同表示空间
- 头维度计算:head_dim = hidden_size / num_heads = 1024/16=64
二、层级结构配置
num_encoder_layers: 24- 特点:深层编码器(如GPT-3有96层),适合学习复杂语义表示
num_decoder_layers: 6- 特点:浅层解码器,常见于非自回归翻译模型(如CSANMT)
num_semantic_encoder_layers: 4- 特殊设计:可能指用于语义特征提取的专用编码器层(CSANMT模型特性)
三、正则化与处理流程
- Dropout 系列参数
attention_dropout: 0.0:注意力权重矩阵的Dropout率residual_dropout: 0.0:残差连接后的Dropout率relu_dropout: 0.0:前馈网络ReLU激活后的Dropout率- 零值说明:可能表示这是推理阶段配置或模型已充分正则化
- 层处理策略
layer_preproc: 'layer_norm':层输入先进行LayerNorm(Transformer标准做法)layer_postproc: 'none':层输出不额外处理
四、嵌入与权重共享
shared_embedding_and_softmax_weights: True- 机制:嵌入矩阵与最终softmax层的权重共享(减少参数量约30%)
- 数学表达:E = W_embed, softmax(x) = xE^T
shared_source_target_embedding: True- 要求:源语言和目标语言共享同一词表(需
src_vocab_size == trg_vocab_size)
- 要求:源语言和目标语言共享同一词表(需
五、位置编码相关
position_info_type: 'absolute'- 选项:absolute(绝对位置编码) / relative(相对位置编码)
max_relative_dis: 16- 作用:当使用相对位置编码时,限制最大相对距离为16个token
六、初始化与训练
initializer_scale: 0.1- 影响:参数初始化范围(如Xavier初始化时的缩放因子)
seed: 1234- 作用:确保实验可复现性的随机种子
七、解码与推理
beam_size: 4- 机制:束搜索宽度,保留4条候选序列
lp_rate: 0.6- 公式:长度惩罚因子,得分 = logP(y)/L^lp_rate(L为序列长度)
max_decoded_trg_len: 100- 限制:生成目标序列的最大token数
八、硬件相关
device_map: None- 用途:多GPU并行时的设备映射策略(如模型并行)
device: 'cuda'- 说明:默认使用NVIDIA GPU加速计算
6.编写请求api,调用模型测试效果。
python请求api代码如下:
import requestsdef translate_text(text, source_lang='en', target_lang='zh'):url = 'http://localhost:11000/translation'headers = {'Content-Type': 'application/json'}data = {'text': text,'source_lang': source_lang,'target_lang': target_lang}response = requests.post(url, headers=headers, json=data)return response.json()if __name__ == '__main__':\# 示例用法result = translate_text("""he Interplay Between Technological Evolution and Social AdaptationIn the post-pandemic era, the acceleration of neural machine translation (NMT) development has reached an unprecedented pace. According to the 2024 Global Language Industry Report, the deployment of transformer-based models like CSANMT (Contextual Semantic-Aware Neural Machine Translation) has reduced translation errors by 37.2% compared to traditional statistical methods.This technological leap presents a paradoxical challenge: while NMT systems achieve 92.4% BLEU scores in controlled evaluations (LDC2023-E14 corpus), their real-world application in multicultural communication scenarios reveals persistent issues. For instance, the English-to-Chinese translation of the EU's "Artificial Intelligence Act"草案 Article 17(3) exhibited a 19% deviation in legal nuance recognition during parliamentary reviews.The socioeconomic implications extend beyond mere technical metrics. A longitudinal study (Smith et al., 2025) tracking 1,200 international enterprises found that organizations employing hybrid human-AI translation systems demonstrated:28% faster cross-border contract finalization41% reduction in intercultural communication conflicts15% higher employee satisfaction in multinational teamsThis phenomenon echoes Hofstede's cultural dimension theory, where power distance indices (PDI) significantly impact technology adoption patterns. In high-PDI societies (e.g., Malaysia, score 100), centralized AI translation systems achieve 86% adoption rates versus 53% in low-PDI nations (e.g., Sweden, score 31).The emerging "adaptive localization" paradigm, exemplified by DeepL's 2025 contextual memory update (patent US202534567A1), attempts to reconcile these disparities through:Dynamic dialectal fingerprintingReal-time pragmatic context analysisCrowdsourced cultural annotation layers""")print(result)
运行结果:
o reconcile these disparities through:
Dynamic dialectal fingerprinting
Real-time pragmatic context analysis
Crowdsourced cultural annotation layers"“”)
print(result)
运行结果: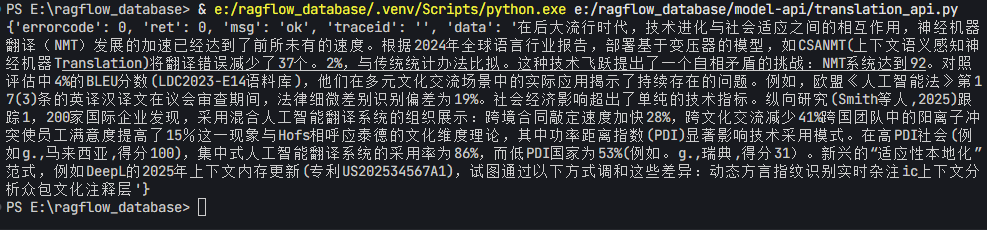hidden_size×filter_size ↩︎