使用 GPUStack 纳管摩尔线程 GPU 进行大语言模型和文生图模型的推理
什么是 GPUStack?
GPUStack 是一个用于运行 AI 模型的开源 GPU 集群管理器。
核心特性
- 广泛的硬件兼容性:支持管理 Apple Mac、Windows PC 和 Linux 服务器上不同品牌的 GPU。
- 广泛的模型支持:从大语言模型 LLM、多模态模型 VLM 到 Diffusion 扩散模型、STT 与 TTS 语音模型、文本嵌入和重排序模型的广泛支持。
- 异构 GPU 支持与扩展:轻松添加异构 GPU 资源,按需扩展算力规模。
- 分布式推理:支持单机多卡并行和多机多卡并行推理。
- 多推理后端支持:支持 llama-box(基于 llama.cpp 和 stable-diffusion.cpp)、vox-box 和 vLLM 作为推理后端(后面两个推理后端对摩尔线程 GPU 的支持还在适配中)。
- 轻量级 Python 包:最小的依赖和操作开销。
- OpenAI 兼容 API:提供兼容 OpenAI 标准的 API 服务。
- 用户和 API 密钥管理:简化用户和 API 密钥的管理流程。
- GPU 指标监控:实时监控 GPU 性能和利用率。
- Token 使用和速率统计:有效跟踪 token 使用情况,并管理速率限制。
使用 GPUStack 纳管摩尔线程 GPU 进行大语言模型和文生图模型的推理
准备工作
以下代码运行在 x86 架构的 Ubuntu 20.04/22.04 系统。
配置容器运行时
请参考以下链接安装和配置容器运行时。
- 安装 Docker: Docker 安装指南
- 安装 MTT S80/S3000/S4000 驱动 (当前为 rc3.1.1): MUSA SDK 下载
- 安装 MT Container Toolkit (当前为 v1.9.0): MT CloudNative Toolkits 下载
检查容器运行时配置是否正确,确认输出的默认运行时为 mthreads。
$ (cd /usr/bin/musa && sudo ./docker setup $PWD)
$ docker info | grep mthreadsRuntimes: mthreads mthreads-experimental runcDefault Runtime: mthreads
通过 Docker 运行 GPUStack
$ docker run --pull always -d --name gpustack \--restart=unless-stopped \--network=host \--ipc=host \-v gpustack-data:/var/lib/gpustack \gpustack/gpustack:v0.6.0-musa
通过上述步骤,您将运行一个名为 gpustack 的容器,此容器使用主机网络模式并通过 80 端口来提供 WebUI 服务。您可以通过浏览器访问 http://localhost 来查看 GPUStack 的界面。
获取首次登录的密码
$ docker exec -it gpustack bash
# cat /var/lib/gpustack/initial_admin_password
登录 GPUStack
在浏览器中访问 http://localhost,输入用户名 admin 和上一步获取的密码进行登录。
查看摩尔线程 GPU 资源
点击侧边栏中的 Resources 选项,您将看到 GPUStack 管理的所有 Worker 节点信息。
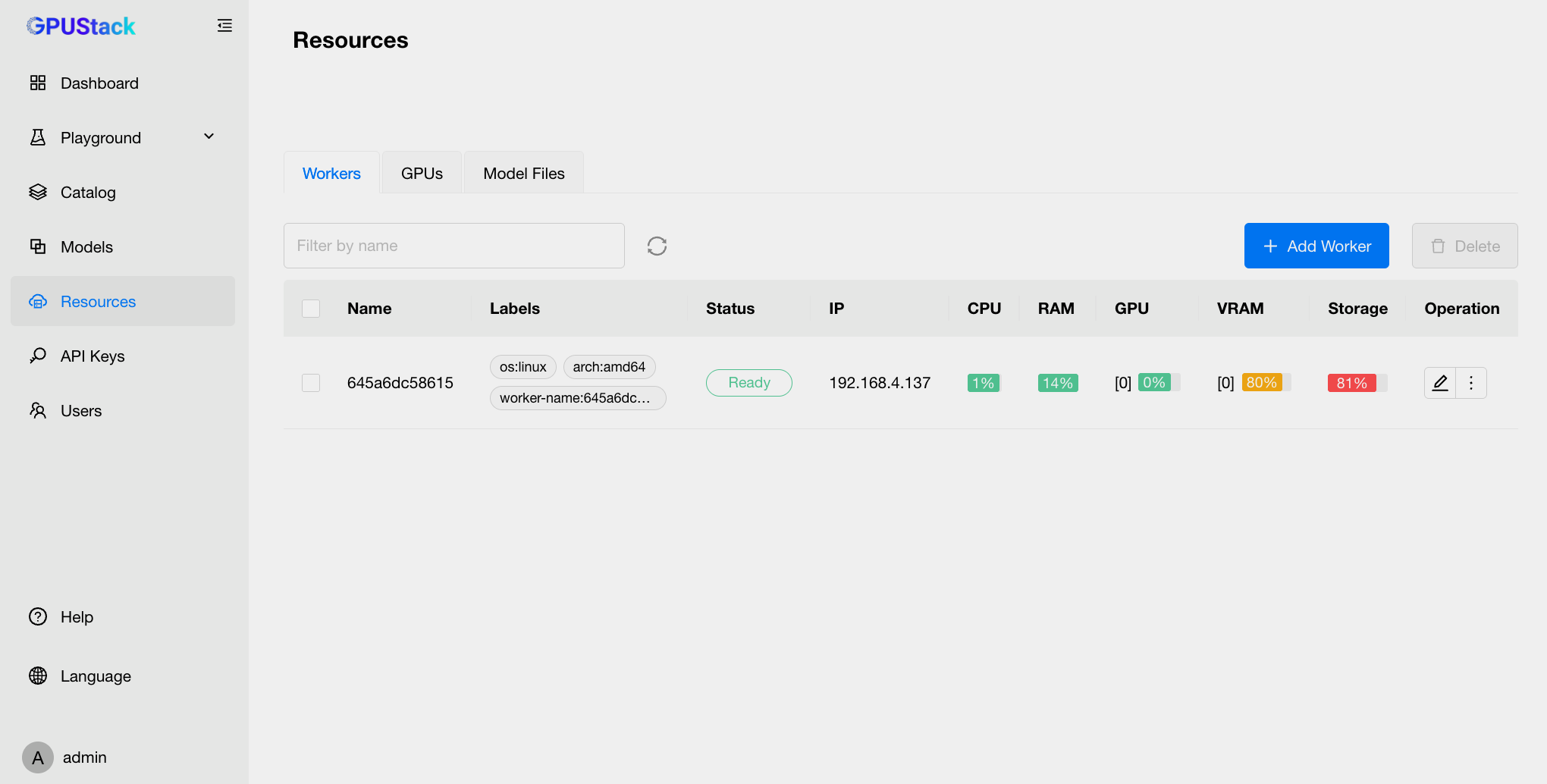
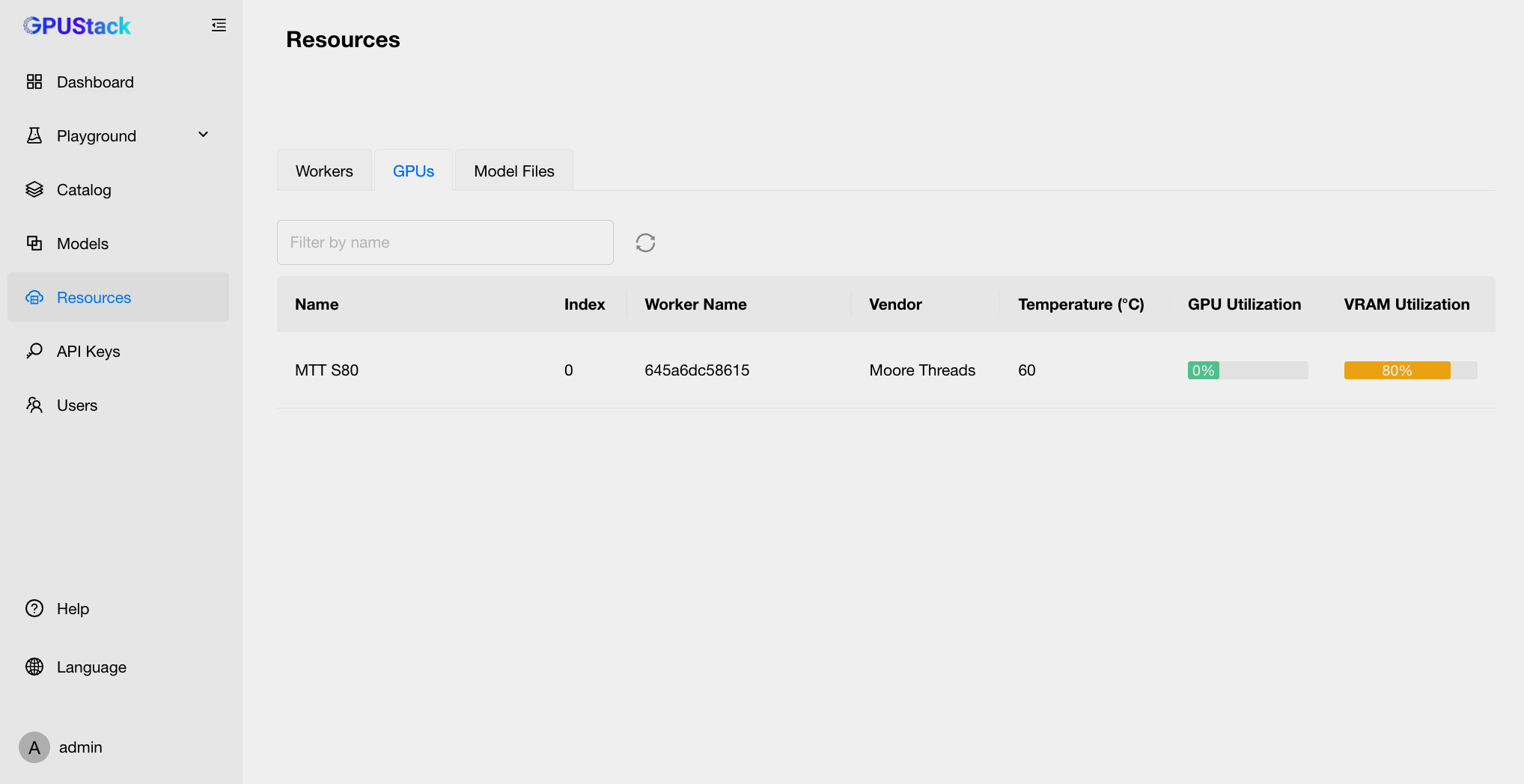
通过切换 GPUs 选项卡,您可以查看每个 Worker 节点上 GPU 的使用情况和性能指标。
部署模型
点击侧边栏中的 Models 选项,您将看到 GPUStack 管理的所有模型信息。
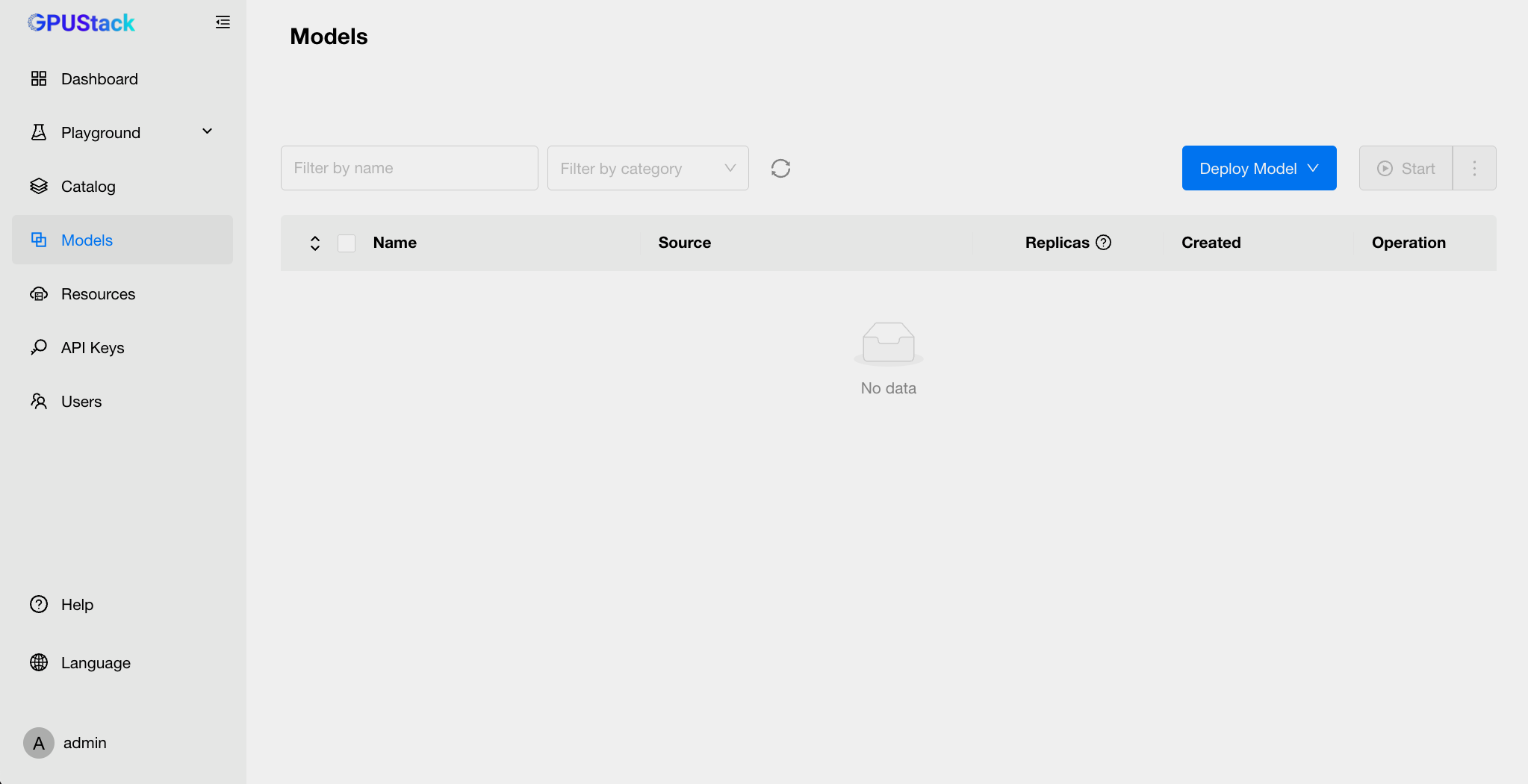
通过点击右上角的 Deploy Model 按钮,您可以创建新的模型(为避免下载模型文件时间过长,此处我们部署两个已经下载好的模型)。
第一个模型是 deepseek-r1_7b_q4_0.gguf,它是将 DeepSeek-R1 Distill Qwen 7B 模型量化为 4-bit 的模型,具有较小的参数量和较快的推理速度。
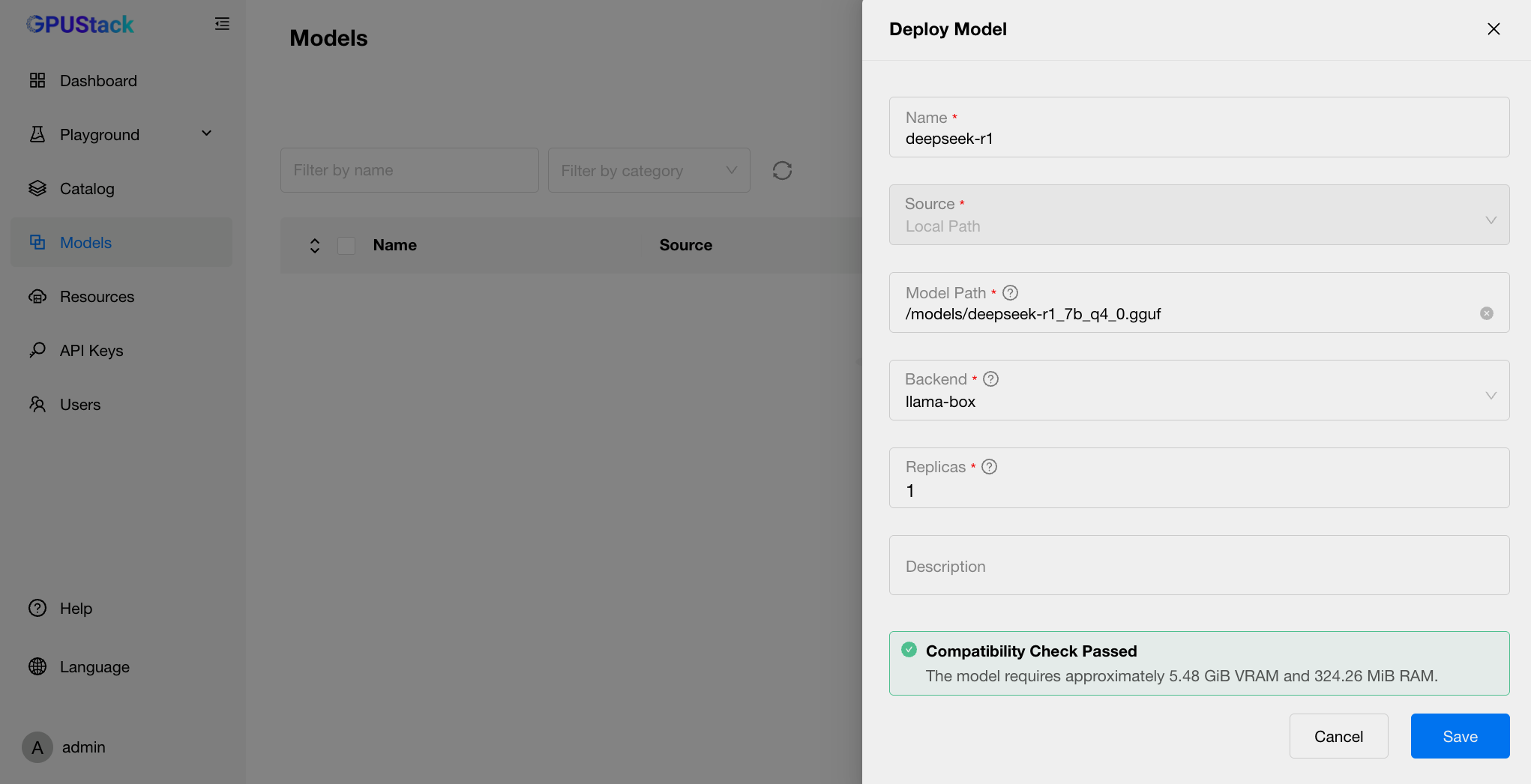
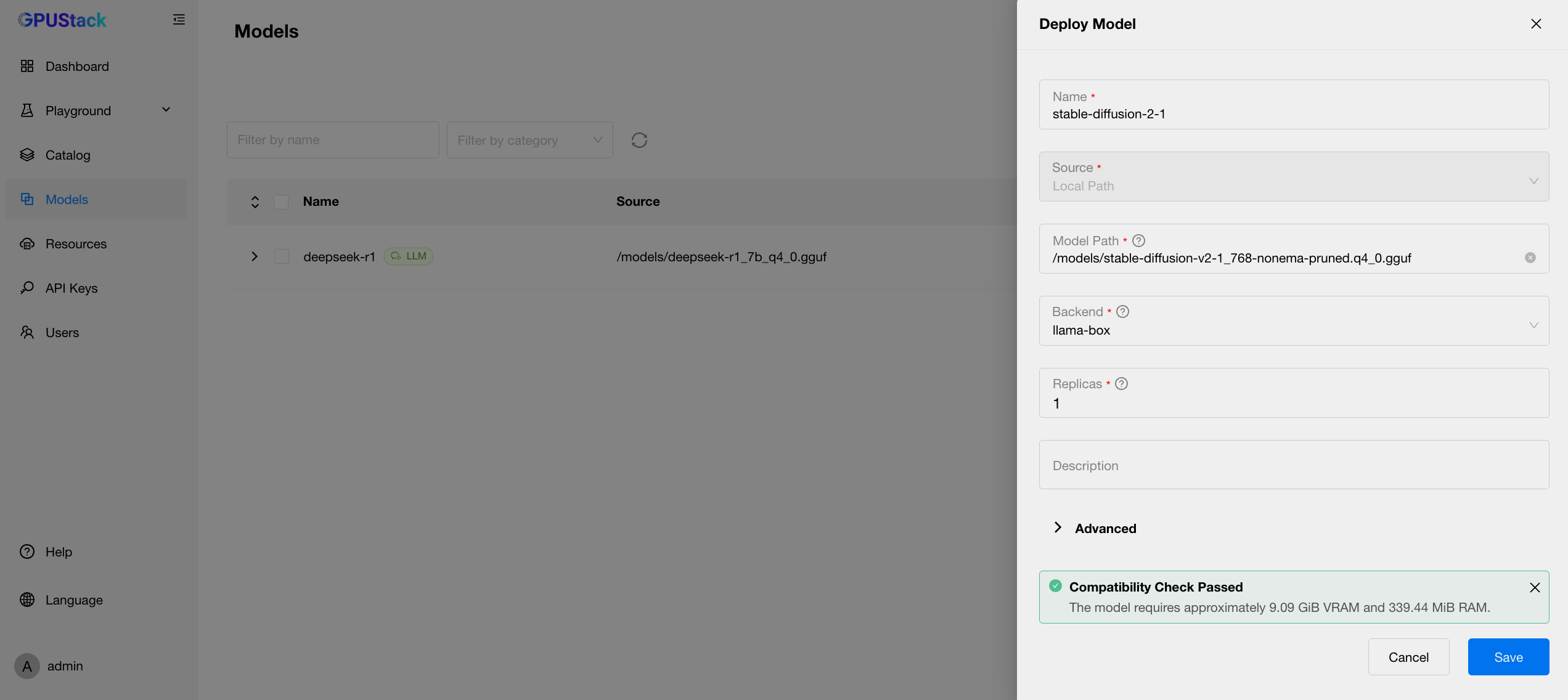
第二个模型是 stable-diffusion-v2-1_768-nonema-pruned.q4_0.gguf,它是将 Stable Diffusion 2.1 模型量化为 4-bit 的模型,具有较小的参数量和较快的推理速度。
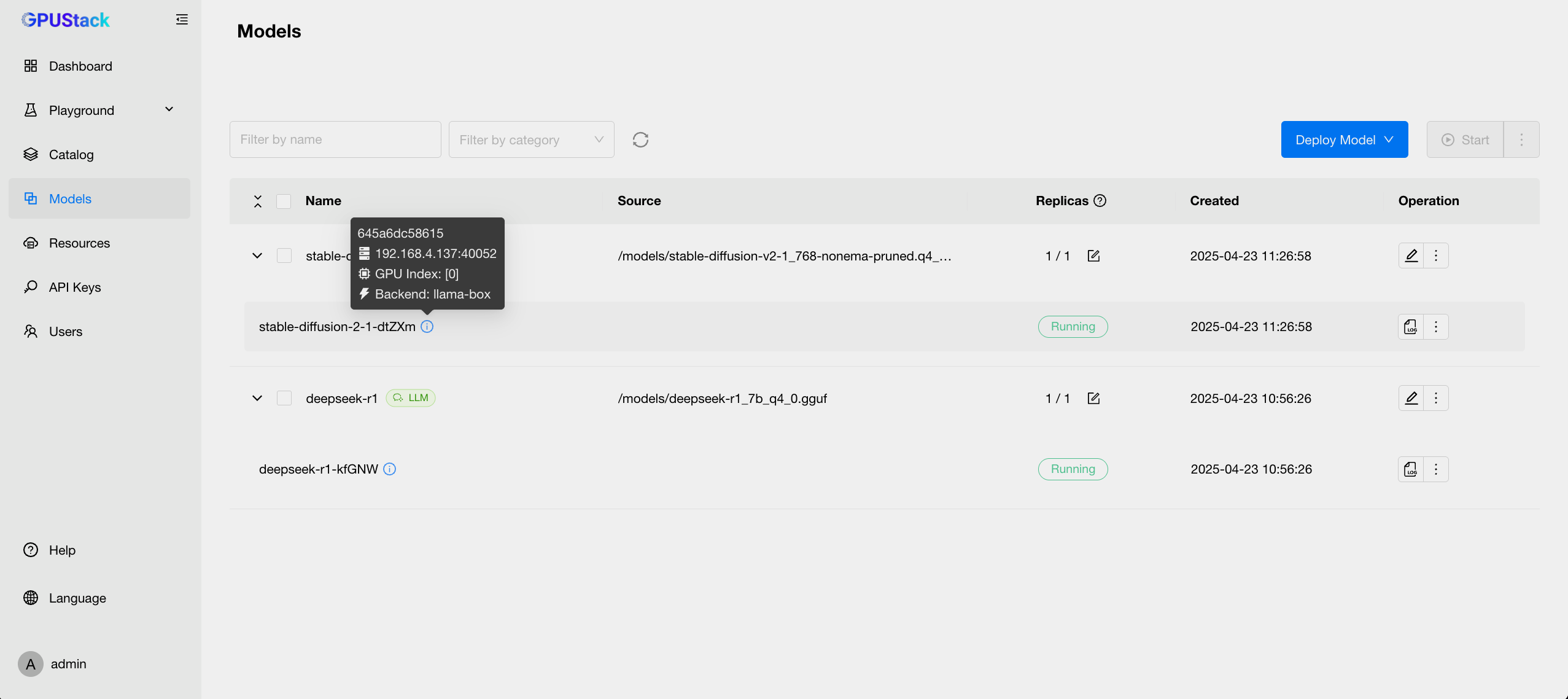
展开模型后,点击 replica 名称旁边的感叹号按钮,在弹出的对话框中,您可以查看模型使用的节点、GPU 和推理后端。
运行模型
点击侧边栏中的 Playground 选项,您将看到 GPUStack 提供了多种模型的推理方式。
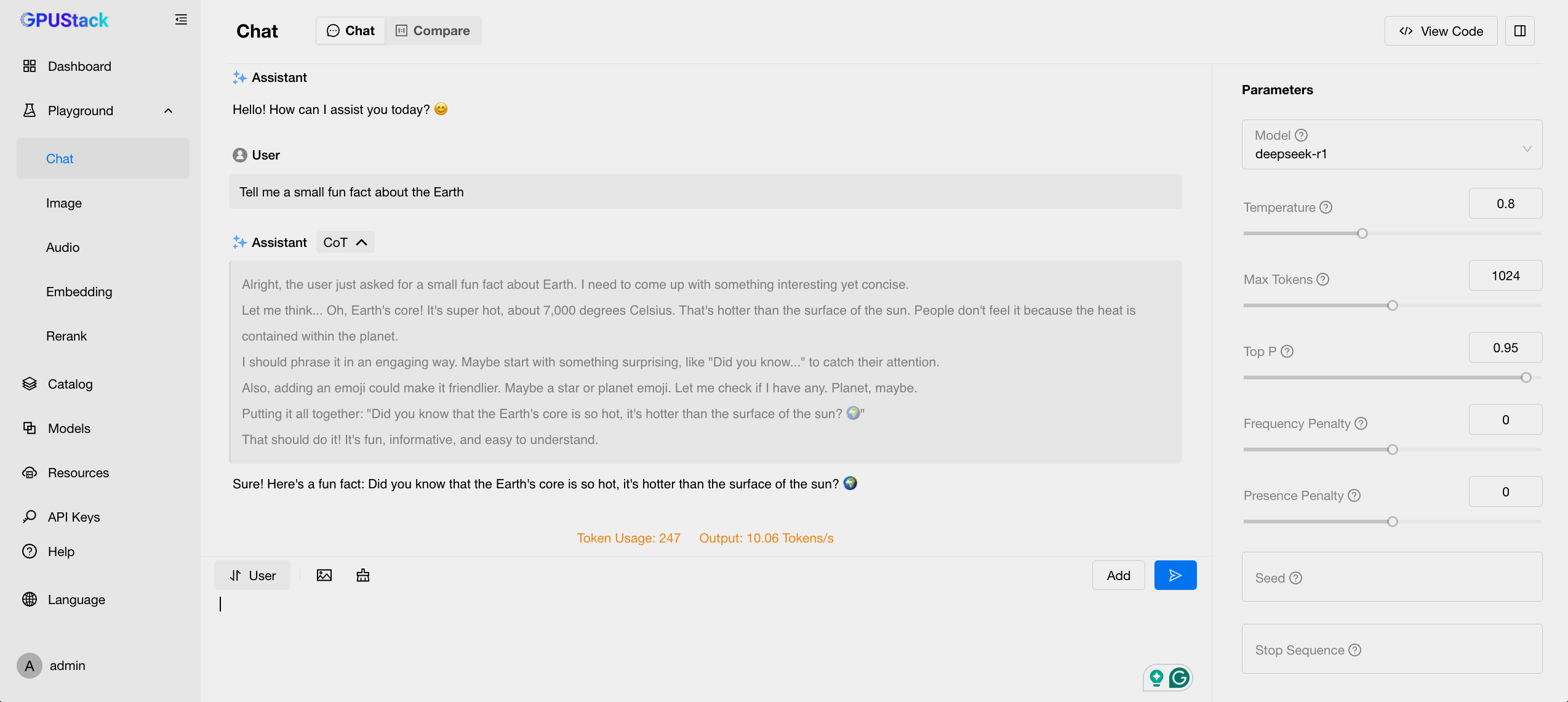
运行大语言模型
点击侧边栏中的 Chat 选项,您可以与刚才部署的 deepseek-r1_7b_q4_0.gguf 模型进行对话。
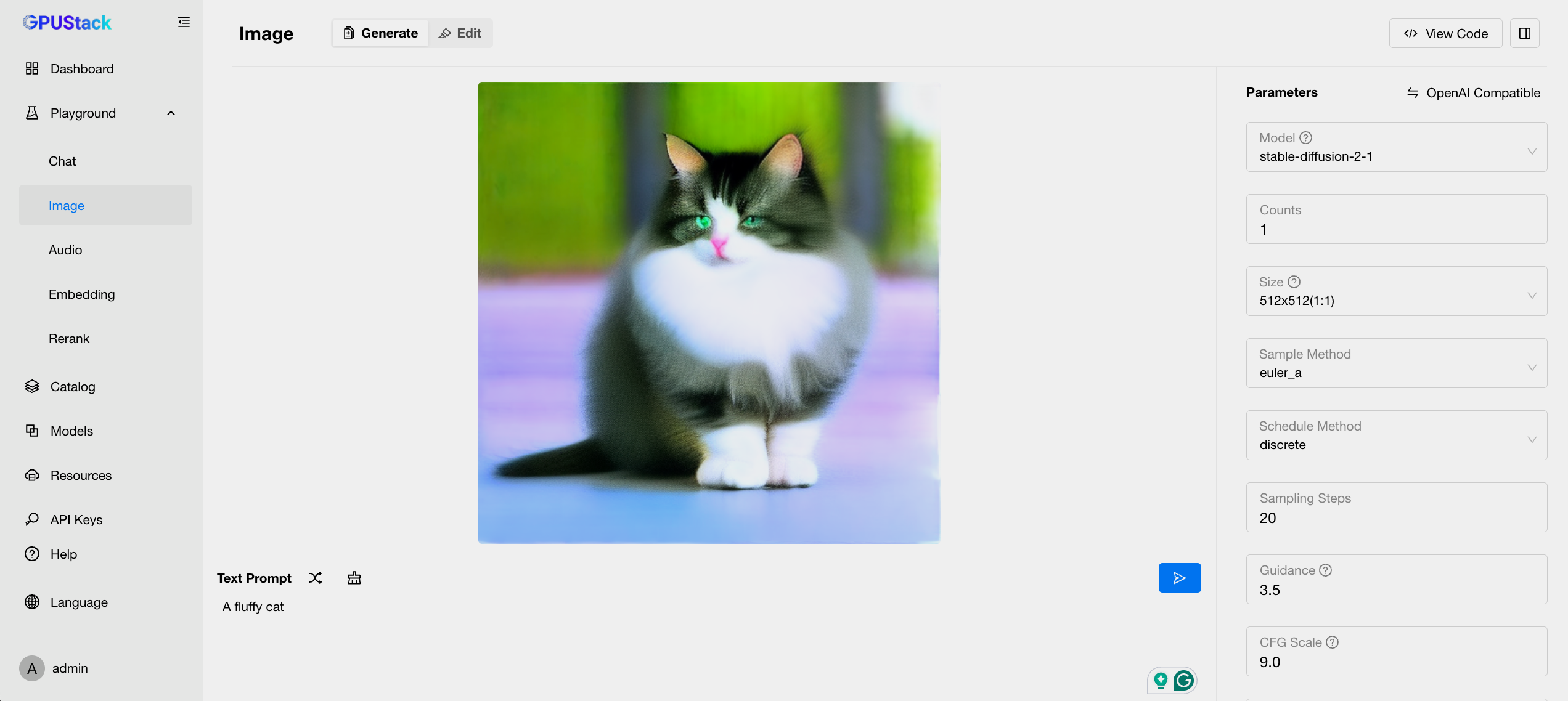
运行文生图模型
点击侧边栏中的 Image 选项,您可以与刚才部署的 stable-diffusion-v2-1_768-nonema-pruned.q4_0.gguf 模型进行文生图的操作。
探索更多模型
点击侧边栏中的 Catalog 选项,您可以查看 GPUStack 支持的更多模型。