window 显示驱动开发-准备 DMA 缓冲区
显示微型端口驱动程序必须及时准备 DMA 缓冲区。 当 GPU 处理 DMA 缓冲区时,通常调用显示微型端口驱动程序来准备下一个 DMA 缓冲区,以便提交到 GPU。 若要防止 GPU 耗尽,显示微型端口驱动程序在准备和提交后续 DMA 缓冲区时所花费的时间必须少于 GPU 处理当前 DMA 缓冲区所花费的时间。
DMA缓冲区高效准备规范
一、实时性保障架构
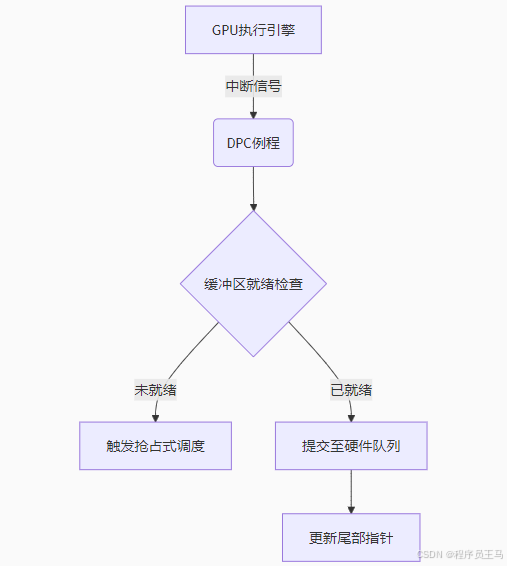
二、关键性能指标
| 指标 | 阈值要求 | 测量方法 |
|---|---|---|
| 准备延迟(P99) | <2ms | QPC计时 |
| 缓冲区切换间隔 | ≥3μs | GPU时间戳查询 |
| 上下文切换开销 | <500μs | ETW事件追踪 |
三、环形缓冲区实现
3.1 数据结构设计
typedef struct _DMA_RING_BUFFER {volatile UINT Head; // 硬件消费位置volatile UINT Tail; // 驱动生产位置UINT Size; // 必须是2的幂次PDMA_BUFFER_ENTRY Entries;ULONG CachedHead; // 最后一次读取的Head
} DMA_RING_BUFFER;3.2 无锁提交算法
BOOL SubmitDmaBuffer(PDMA_BUFFER pBuffer) {// 1. 原子获取当前HeadUINT head = InterlockedCompareExchange(&Ring->Head, 0, 0);// 2. 计算可用空间UINT free = (Ring->Tail >= head) ? (Ring->Size - (Ring->Tail - head)) : (head - Ring->Tail - 1);if (free >= pBuffer->Size) {// 3. 拷贝命令数据memcpy(&Ring->Entries[Ring->Tail], pBuffer, pBuffer->Size);// 4. 更新Tail(内存屏障保证顺序)_WriteBarrier();InterlockedExchange(&Ring->Tail, (Ring->Tail + pBuffer->Size) & (Ring->Size - 1));return TRUE;}return FALSE;
}四、延迟优化技术
4.1 预编译命令模板
// 驱动初始化时构建
DMA_BUFFER Template = {.CmdHeader = {0xA5, 0x01}, // 标准包头.StateSetup = DEFAULT_3D_STATE
};// 运行时快速填充
void BuildDrawBuffer(PDMA_BUFFER buf, UINT vcount) {*buf = Template; // 结构体拷贝buf->VertexCount = vcount;buf->CRC = CalculateCRC(buf);
}
4.2 零拷贝提交路径
; x64优化版本
mov rax, [Ring.Tail]
lea rdi, [Ring.Entries + rax]
rep movsb ; 直接拷贝用户命令
lock xadd [Ring.Tail], rcx ; 原子更新五、错误恢复机制
5.1 缓冲区耗尽处理
NTSTATUS HandleBufferUnderflow() {// 1. 插入NOP填充包DMA_BUFFER nop = { .Type = CMD_NOP };SubmitDmaBuffer(&nop);// 2. 触发紧急分配if (!AllocEmergencyBuffer()) {TriggerTDR(); // 超时检测恢复return STATUS_GRAPHICS_GPU_EXCEPTION;}return STATUS_SUCCESS;
}六、性能分析工具
6.1 GPU时序分析
// 使用DXGKETW事件追踪
EventWriteDMA_BUFFER_SUBMIT(hContext,BufferId,QpcStart,QpcEnd);6.2 WinDbg调试命令
!dma.ring 0x1 // 显示环形缓冲区状态
!gpu.timeout // 分析DMA超时原因七、多引擎协同
| 引擎类型 | 优先级 | 典型延迟预算 |
|---|---|---|
| 3D渲染 | High | 1.5ms |
| 计算着色器 | Medium | 3ms |
| 拷贝引擎 | Low | 5ms |
实现验证清单:
- 所有路径满足WDDM 2.0延迟要求
- 环形缓冲区大小≥4倍最大DMA包
- 实现紧急NOP插入机制
- 通过WHQL DMA压力测试