日志根因分析:Elastic Observability 的异常检测与日志分类功能
作者:来自 Elastic Bahubali Shetti

Elastic Observability 不仅提供日志聚合、指标分析、APM 和分布式追踪,Elastic 的机器学习能力还能帮助分析问题的根因,让你将时间专注于最重要的任务。
随着越来越多的应用程序迁移到云端,收集的遥测数据(日志、指标、追踪)也越来越多,这些数据有助于提升应用性能、运营效率和业务 KPI。然而,面对如此海量的数据,分析变得极其繁琐且耗时。传统的告警和简单模式匹配方法(如可视化或关键词搜索等)已无法满足 IT 运维团队和 SRE 的需求,就像在大海捞针一样困难。
在本文中,我们将介绍 Elastic 在 IT 运维人工智能(AIOps)和机器学习(ML)方面的一些能力,帮助进行根因分析。
Elastic 的机器学习功能将通过提供异常检测来帮助您调查性能问题,并通过时间序列分析和日志异常值检测来精准定位潜在的根本原因。这些功能将帮助您缩短在大海捞针的时间。
Elastic 平台让你能快速开始使用机器学习,无需数据科学团队或自行设计系统架构,也无需将数据迁移到第三方框架中进行模型训练。
Elastic 预置了适用于可观测性和安全场景的机器学习模型。如果这些模型无法很好地适应你的数据,Elastic 工具内的向导可以引导你通过几个简单步骤配置自定义异常检测并用监督学习训练模型。
为了帮助你快速上手,Elastic Observability 内置了多项关键功能来辅助分析,无需手动运行 ML 模型,从而减少日志分析所需的时间和精力。
以下是一些内置机器学习功能的简介:
异常检测:Elastic Observability 启用后(参考文档),会实时建模你的时间序列数据的正常行为,学习趋势、周期性等,从而自动检测异常,简化根因分析并减少误报。异常检测在 Elasticsearch 中运行并可随之扩展,并配有直观的用户界面。
日志分类:借助异常检测,Elastic 能快速识别日志事件中的模式。日志分类视图会基于日志消息和格式对其进行分组,避免你手动分析,让你能更快采取行动。
高延迟或出错的事务:Elastic Observability 的 APM 功能可以帮助你发现导致事务延迟的关键属性,并识别哪些属性最能区分成功和失败的事务。相关功能概览见:Elastic Observability 中的 APM 相关性分析:自动识别慢速或失败事务的可能原因。
AIOps Labs:AIOps Labs 使用高级统计方法提供两个主要功能:
-
日志突增检测器:帮助识别日志速率上升的原因。通过分析流程视图,你可以轻松发现和调查异常突增的根本原因。它会展示指定数据视图的日志速率直方图,并找出日志中跨字段、值的突变背后可能的原因。
-
日志模式分析:帮助你在非结构化日志中发现模式,便于更高效地分析数据。它会对选定字段执行分类分析,基于数据创建类别,并展示各类别的分布图和匹配该类别的示例文档。
在本文中,我们将基于 Google 开发并由 OpenTelemetry 改进的流行应用 “Hipster Shop” 演示异常检测和日志分类。
有关高延迟分析功能的概览请参阅此处,AIOps Labs 的概览请见此处。
本文将通过一个实际场景展示如何使用异常检测和日志分类功能,在 Hipster Shop 应用中帮助识别问题的根因。
前提条件与配置
如果你打算跟随本文操作,以下是我们用于演示的一些组件和配置详情:
-
确保你已在 Elastic Cloud 上拥有账户,并在 AWS 上部署了一个 Stack(部署说明见此)。由于 Elastic Serverless Forwarder 的要求,必须部署在 AWS 上。
-
使用广受欢迎的 Hipster Shop 演示应用的某个版本。该应用最初由 Google 编写,用于展示 Kubernetes,在多个变种中都很常见,例如 OpenTelemetry Demo App。Elastic 版本可以在此处找到。
-
确保你已为应用配置 Elastic APM Agent 或 OpenTelemetry Agent。更多详情请参考以下两篇博客:在 Elastic 中使用 OTel 实现独立性 和 在 Elastic 中实现可观测性与安全性。另外,也可以参考 Elastic 中的 OTel 文档。
-
查看 Elastic Observability 的 APM 功能概览。
-
阅读 Elastic 的日志异常检测文档和日志分类文档。
一旦你使用 APM(Elastic 或 OTel)Agent 对应用进行探针接入,并将指标和日志采集进 Elastic Observability 中,你应该可以看到如下的应用服务拓扑图:
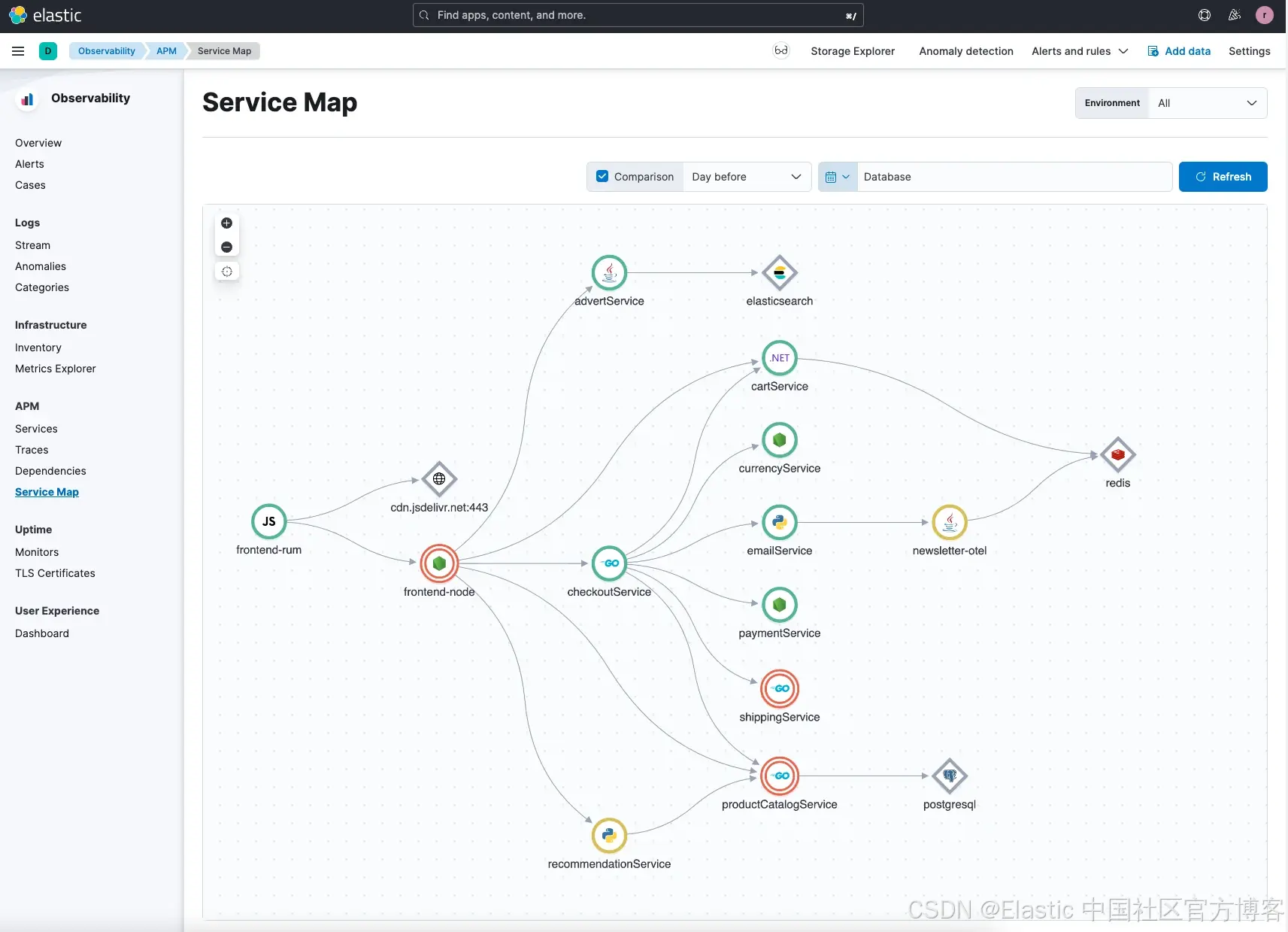
在我们的示例中,我们故意引入了一些问题,以便演示根因分析功能:异常检测和日志分类。根据你加载应用的方式以及引入问题的不同,所产生的异常和日志分类结果可能会有所差异。
在本次演示中,我们将以 DevOps 或 SRE 的角色来管理生产环境中的这套应用。
根因分析
当应用已正常运行一段时间后,你突然收到通知,提示某些服务状态异常。这种通知可能来自你在 Elastic 中配置的告警规则,也可能来自外部通知平台,或是用户反馈的问题。在这个场景中,我们假设客服接到多位客户投诉,称网站存在问题。
那么,作为 DevOps 或 SRE,你该如何展开调查呢?我们将通过 Elastic 的两种方法来排查问题:
-
异常检测
-
日志分类
虽然我们将这两个功能分别展示,但它们是可以 结合使用 的,也是 Elastic Observability 提供的互补工具,旨在帮助你更高效地定位问题根因。
异常检测中的机器学习
Elastic 会根据历史模式检测异常,并识别这些问题发生的概率。
从 服务拓扑图(Service Map) 开始,你可以看到带有红色圆圈标记的异常。当你选择其中一个异常时,Elastic 会为该异常提供一个评分(score),用于衡量其异常程度。
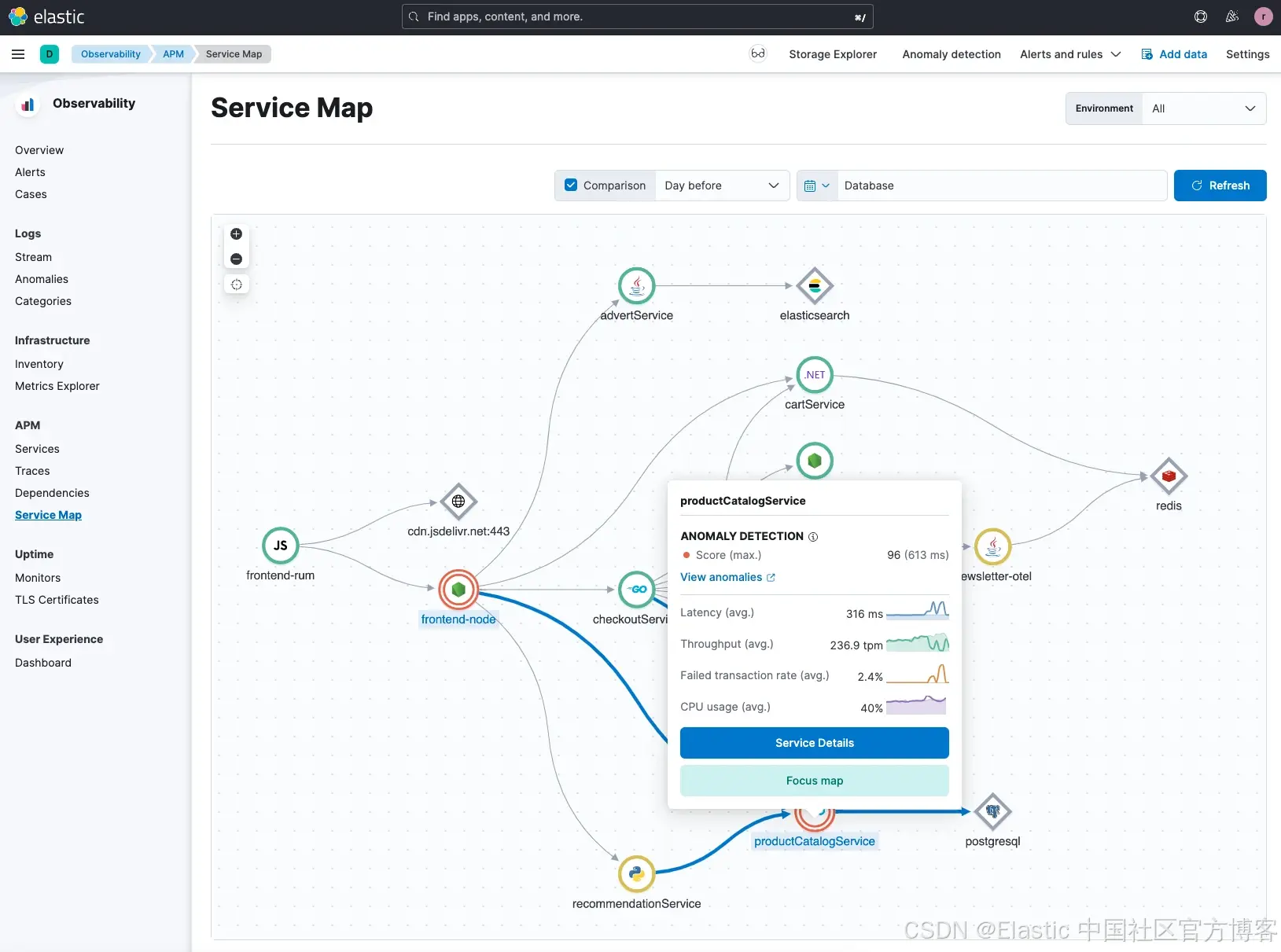
在这个示例中,我们可以看到 Hipster Shop 应用中的 productCatalogService 服务 出现了一个异常,异常评分为 96。异常评分表示该异常相较于历史上检测到的异常的重要程度,分数越高,异常越显著。关于异常检测结果的更多信息可以参考这里。
我们还可以进一步深入查看这个异常,分析其具体细节。
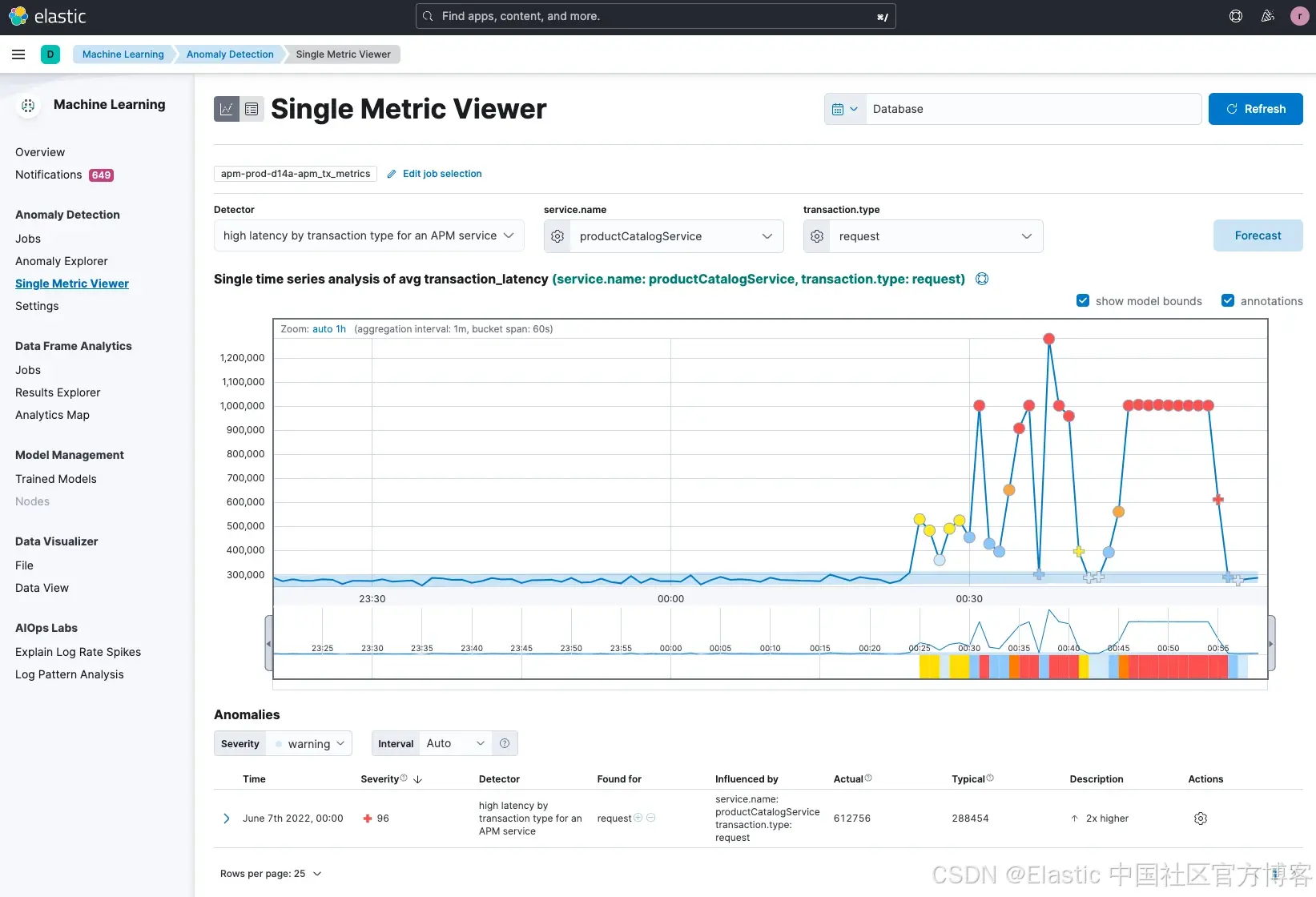
你会看到,productCatalogService 出现了 平均事务延迟时间的严重飙升,这正是服务拓扑图中检测到的异常。Elastic 的机器学习识别出了这个具体的 指标异常(可在 单指标视图 中看到)。很可能客户已经感受到网站变慢,导致公司正在流失潜在交易。
接下来的一个步骤是,从更宏观的角度审查服务拓扑图中其他潜在的异常。你可以使用 Anomaly Explorer(异常浏览器) 来查看所有已被识别出的异常。
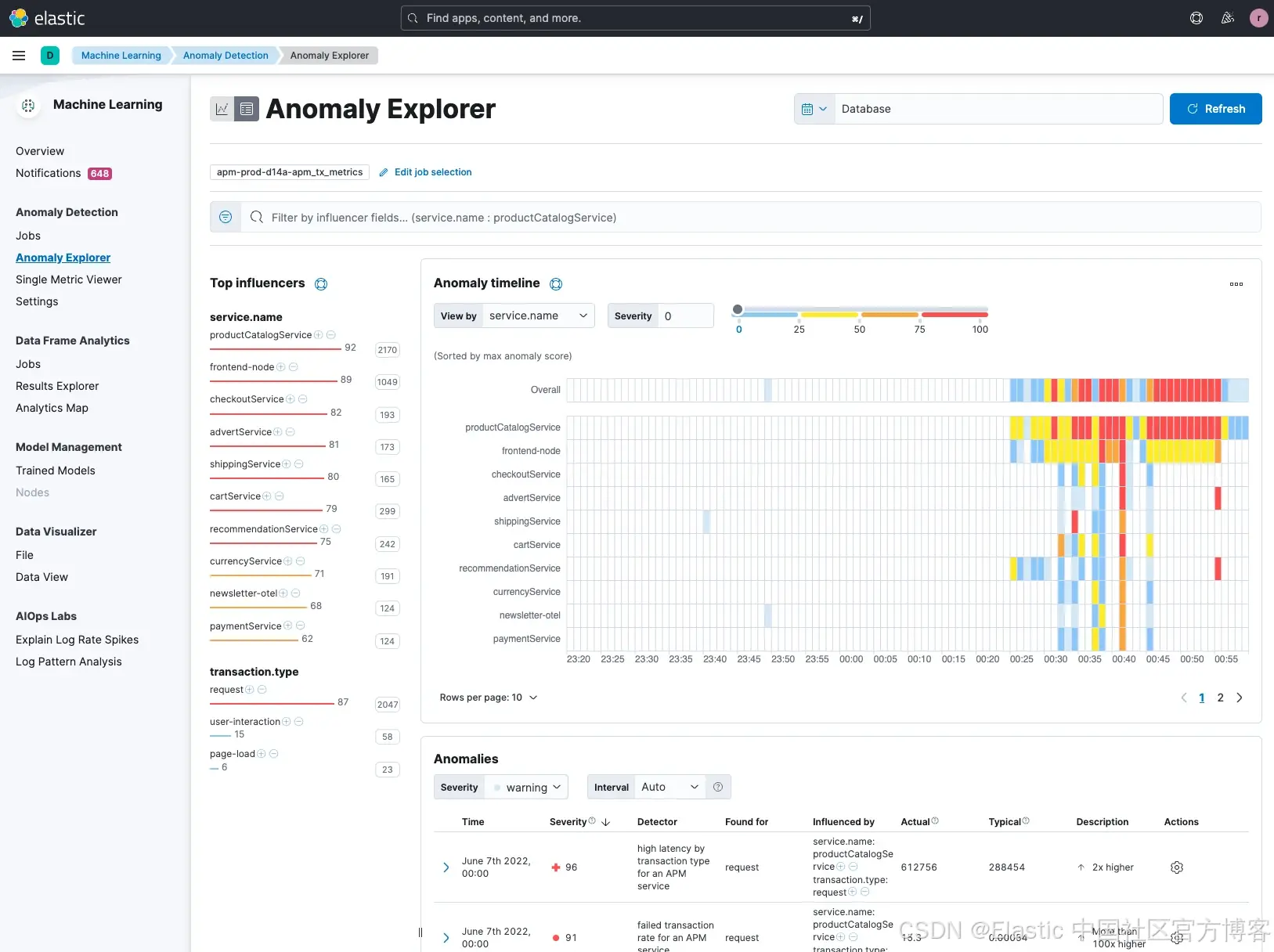
Elastic 检测到多个服务存在异常,其中 productCatalogService 的异常评分最高,此外还有 frontend、checkoutService、advertService 等多个服务也具有较高评分。不过,目前的分析仅基于 单一指标。
Elastic 的机器学习不仅可以检测单一指标,还可以对 各种类型的数据(如 Kubernetes 数据、指标、追踪信息等)进行异常检测。如果我们在 Elastic 中为这些不同数据类型分别创建了 独立的机器学习任务(job),就能对整个系统的运行状态进行更全面的分析,从而更准确地识别导致延迟问题的根本原因。
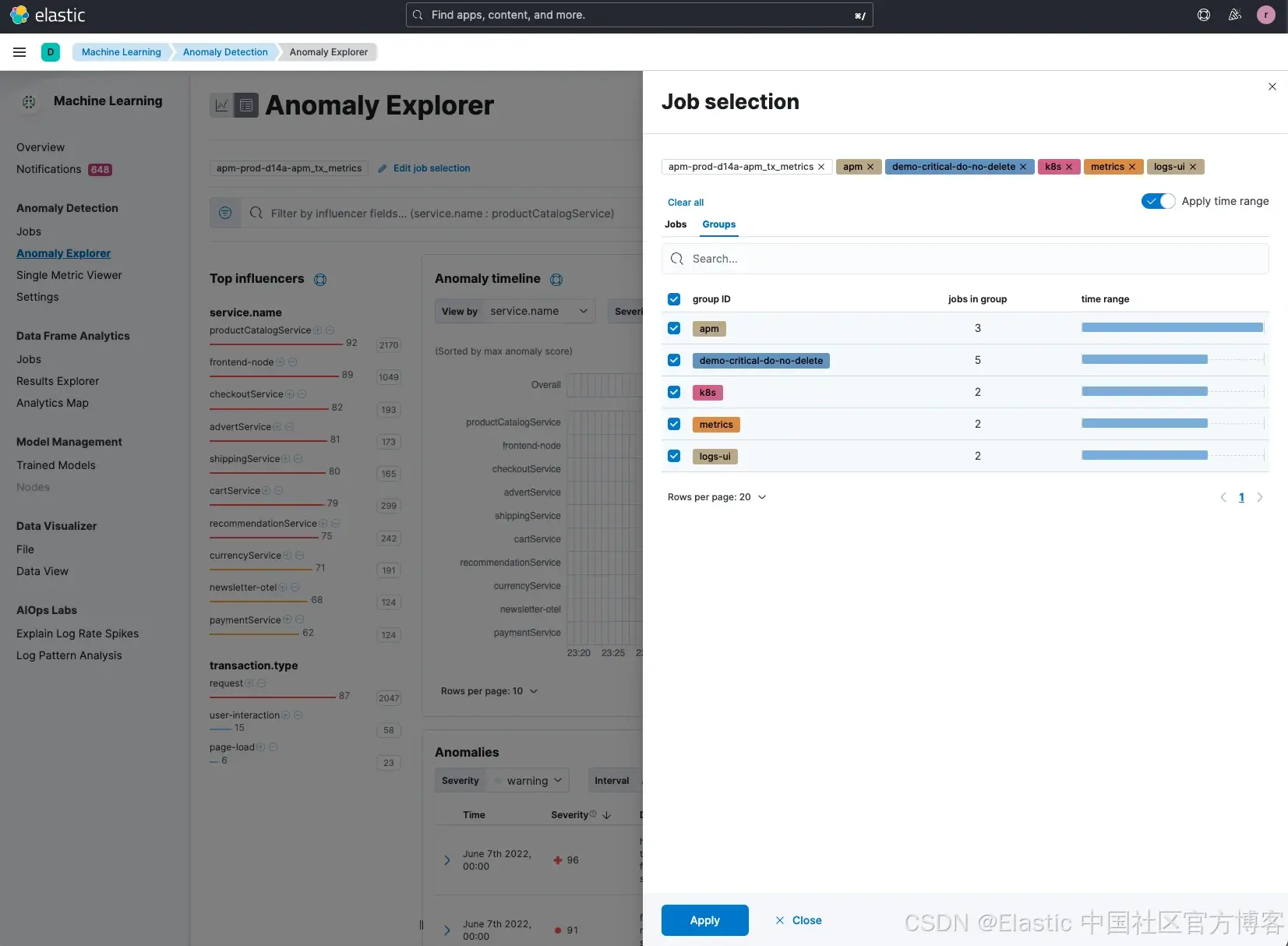
一旦选中了所有潜在的任务,并按 service.name 排序,我们可以看到 productCatalogService 仍然显示出较高的异常影响因子评分。
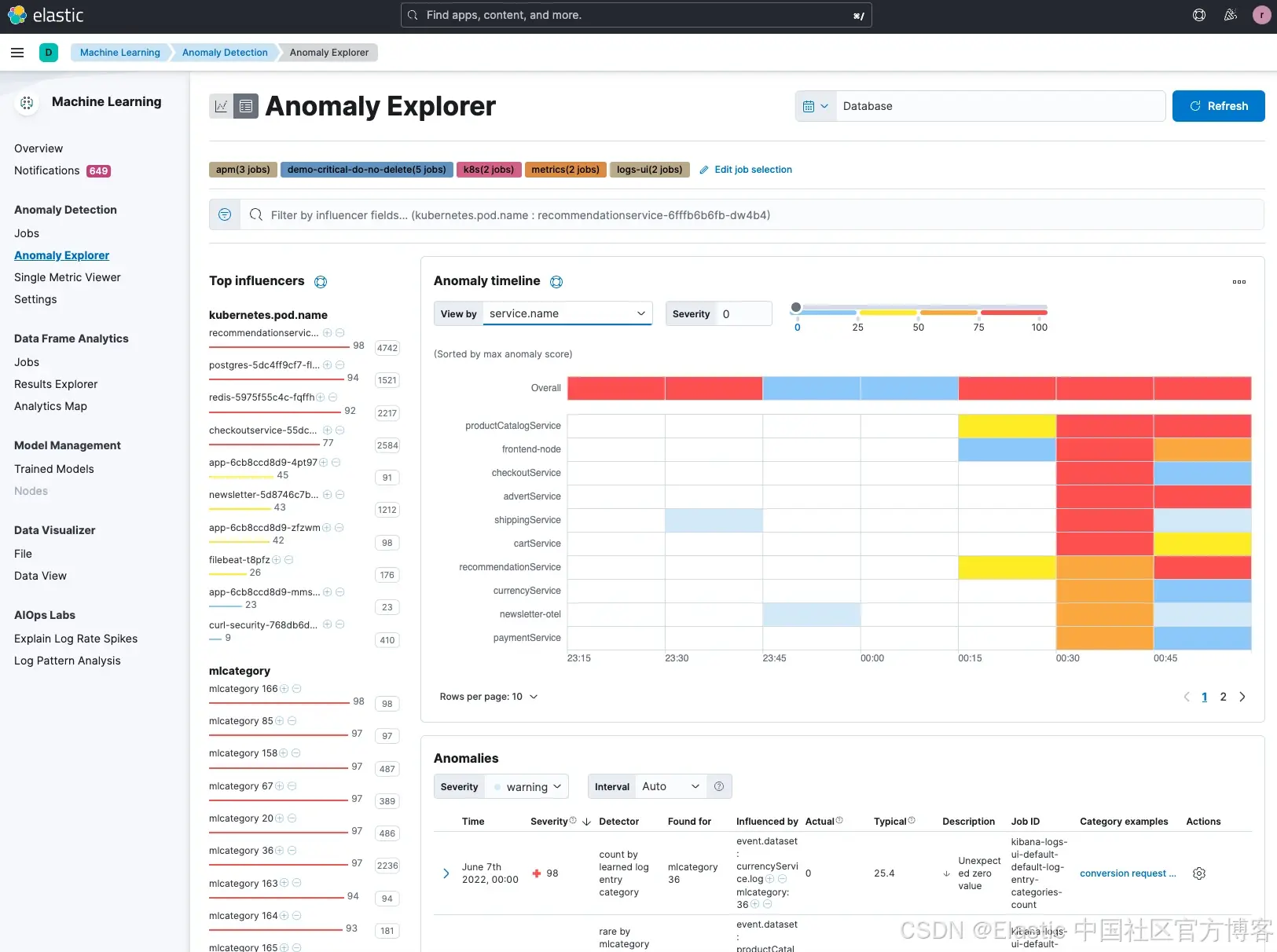
除了图表为我们提供了异常的可视化信息外,我们还可以查看所有潜在的异常。你会注意到,Elastic 还对这些异常进行了分类(参见 category examples 列)。当我们浏览结果时,会注意到其中一个由分类识别出的潜在问题是 postgreSQL,其评分也高达 94。机器学习识别出了一个 “rare mlcategory”,这表示它是极少出现的类型,因此可能是客户所遇问题的潜在原因。
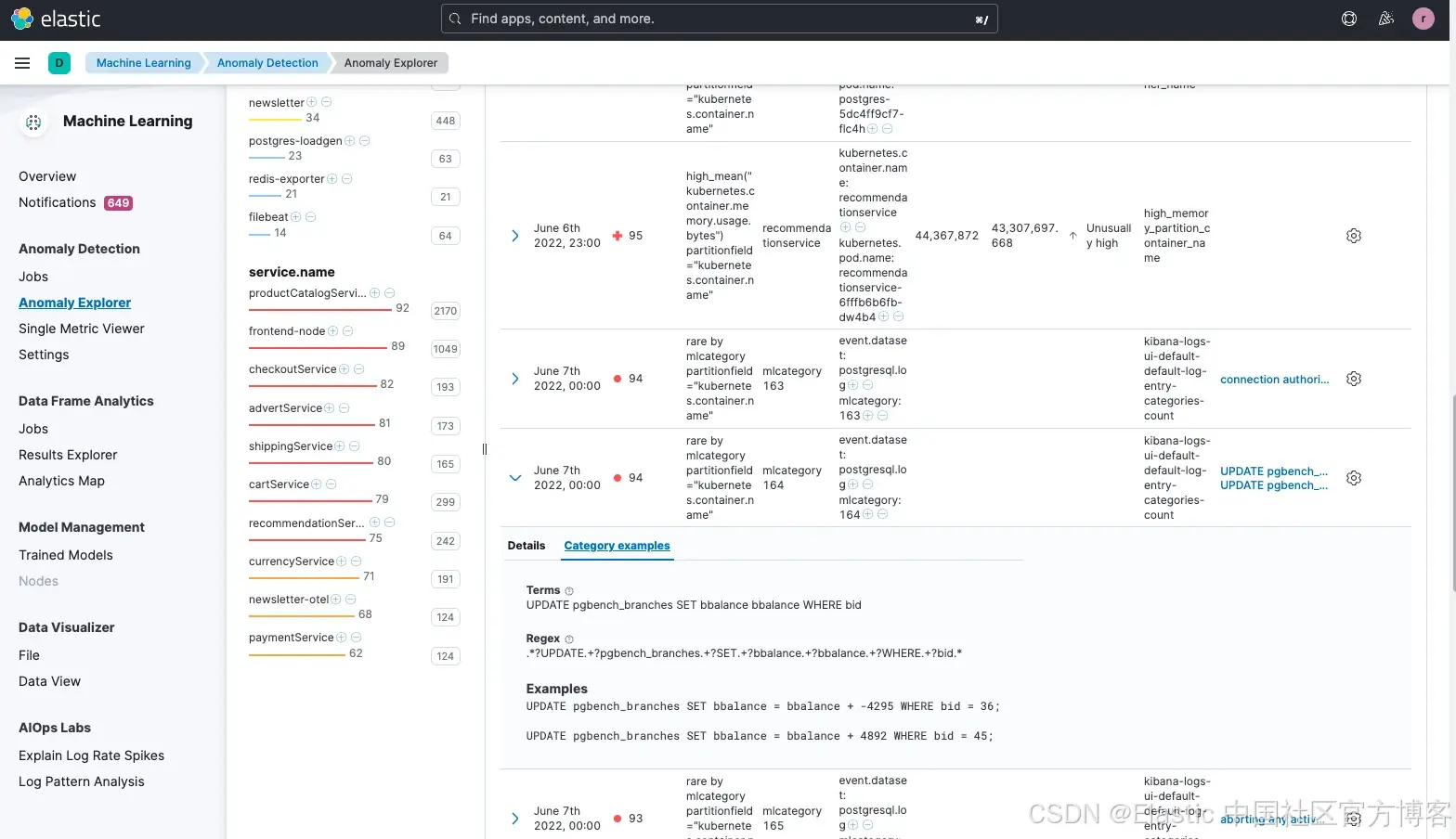
我们还注意到,这个问题可能是由 pgbench 引起的,pgbench 是一个流行的 postgreSQL 工具,用于对数据库进行基准测试。pgbench 会反复执行相同的 SQL 命令序列,可能会在多个并发的数据库会话中运行。虽然 pgbench 确实是个有用的工具,但它不应在生产环境中使用,因为它会对数据库主机造成较大负载,很可能导致网站出现更高的延迟问题。
虽然这可能不是最终的根因,但我们已经较快地识别出了一个高概率的潜在问题。工程师可能本打算在测试环境的数据库上运行 pgbench 来评估性能,而不是在生产环境中运行。
日志分类的机器学习
Elastic Observability 的服务拓扑图检测到了异常,在本次演示中,我们换一种方法,从服务拓扑图中查看服务详情,而不是一开始就直接探索异常。当我们查看 productCatalogService 的服务详情时,看到以下内容:
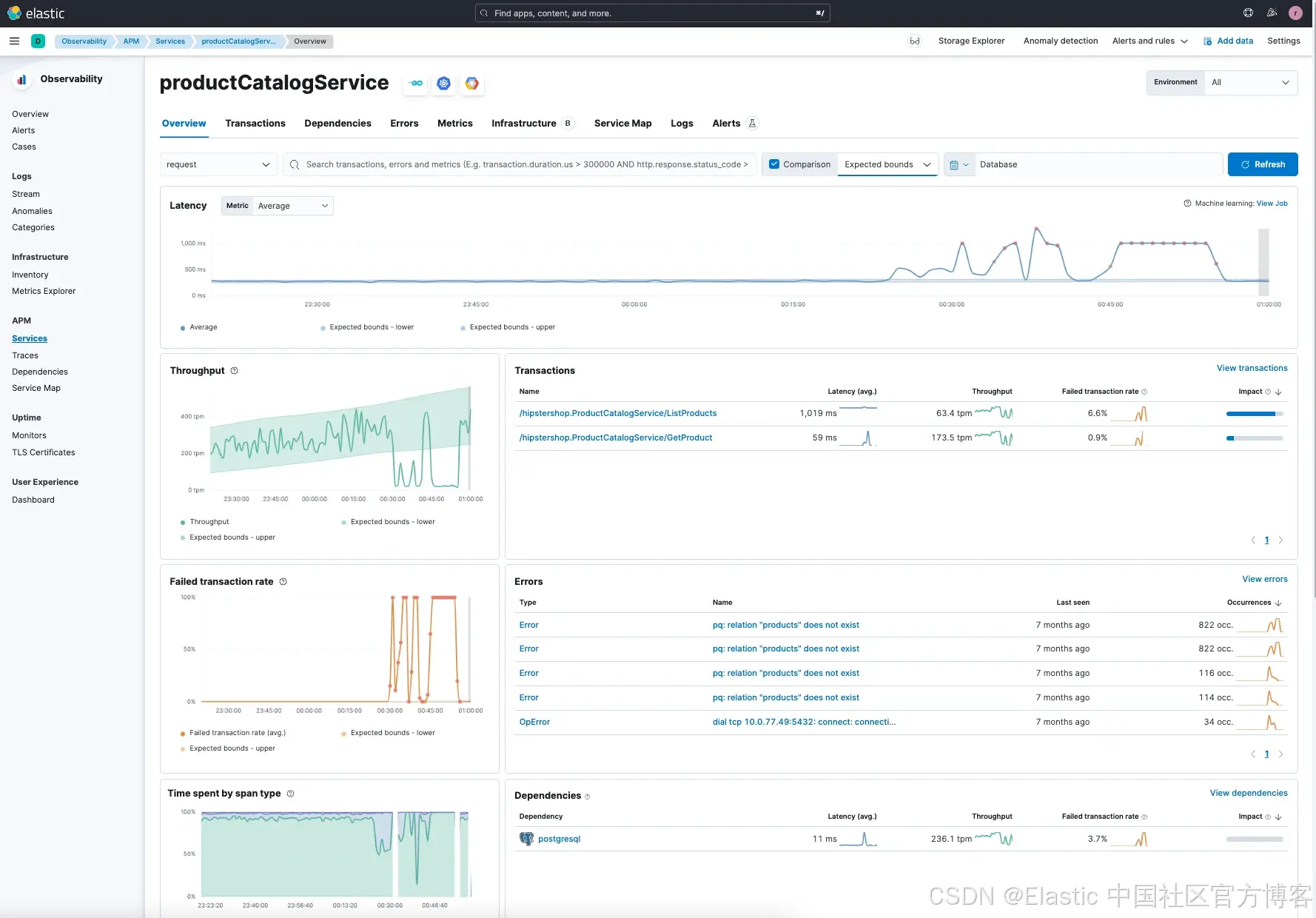
服务详情显示了几个方面:
-
与服务预期范围相比,延迟异常高。我们看到最近延迟明显高于平均值,平均约为 275ms,但有时会超过 1 秒。
-
在高延迟的同一时间段内,失败率也很高(左下角图表 “Failed transaction rate”)。
-
事务中,特别是
/ListProduct请求延迟异常高,且失败率也高。 -
productCatalogService依赖于 postgreSQL。 -
错误全部与 postgreSQL 相关。
-
我们可以选择在 Elastic 中深入日志分析,或者使用一种更便捷的功能快速定位日志。
如果我们在 Elastic Observability 的日志分类(Categories)中搜索 postgresql.log 来帮助识别可能导致错误的 postgresql 日志,会发现 Elastic 的机器学习已自动对 postgresql 日志进行了分类。
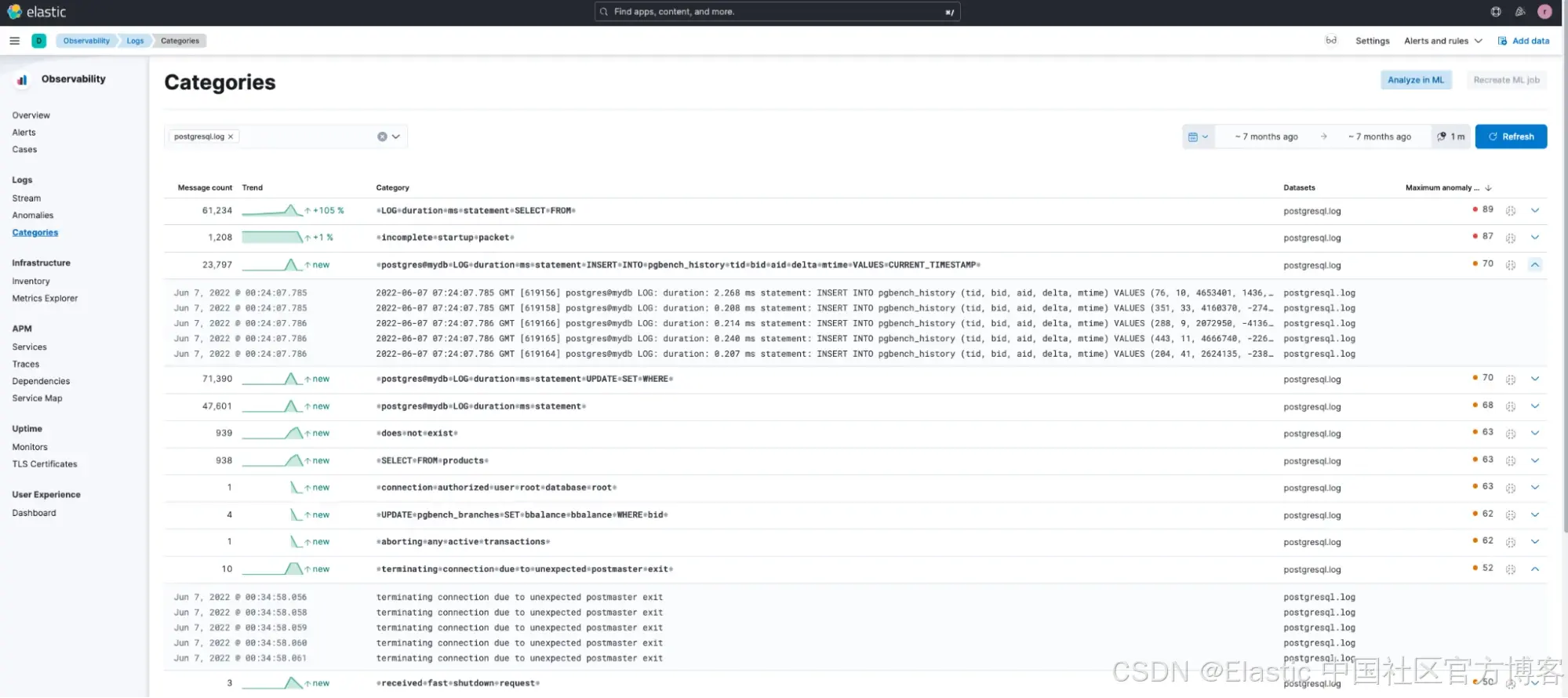
我们注意到另外两点:
-
有一个高频分类(消息数为 23,797,异常评分高达 70)与 pgbench 相关(这在生产环境中很少见)。因此,我们在分类中进一步搜索所有与 pgbench 相关的日志。
-
发现一个关于连接终止的异常问题(消息数较少)。
-
在调查第二个严重错误时,我们可以在分类中看到该错误发生前后的日志。
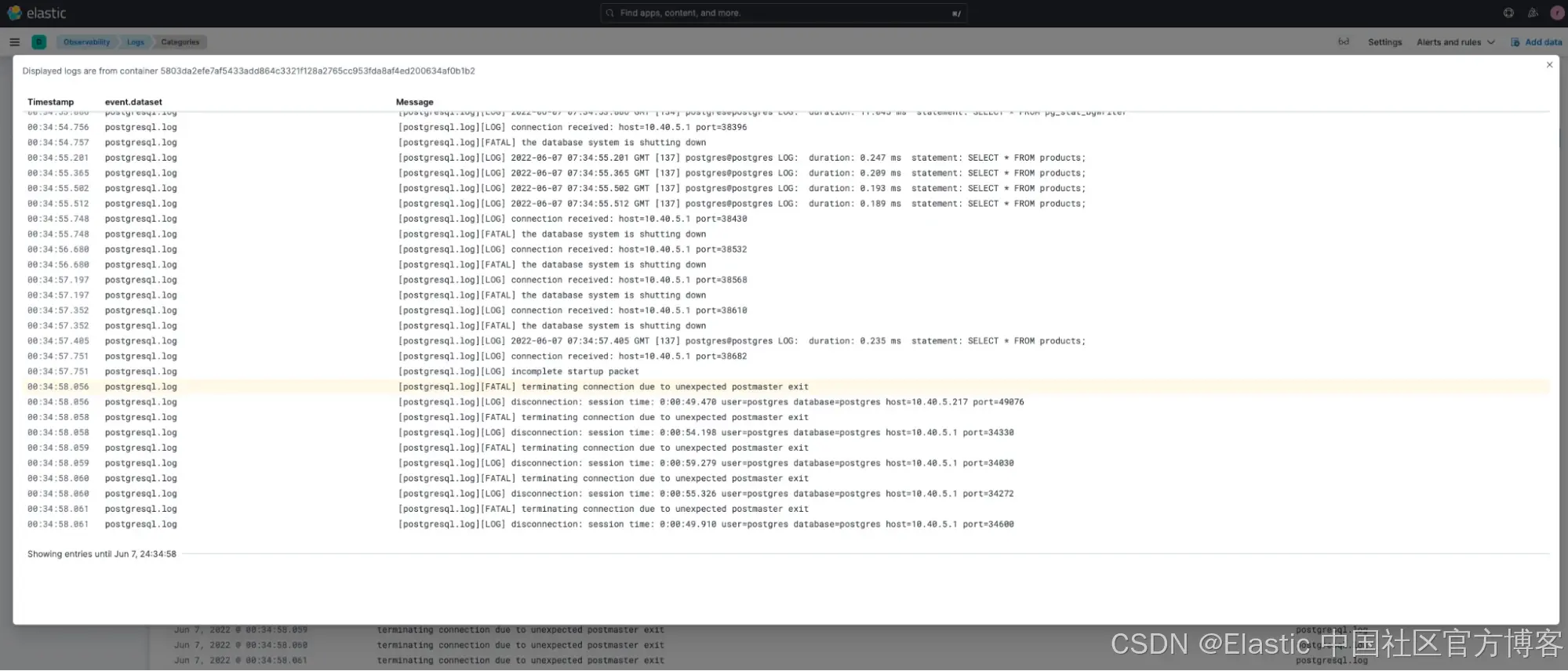
这个故障排查显示 postgreSQL 出现了致命错误(FATAL error),数据库在错误发生前已关闭,所有连接被终止。鉴于我们发现的这两个直接问题,可以判断有人运行了 pgbench,可能导致数据库过载,进而引发客户看到的延迟问题。
接下来的步骤可以是调查异常检测结果,或者与开发人员合作,检查代码,确认 pgbench 是否被包含在部署配置中。
结论
希望你已经了解 Elastic Observability 如何帮助你更快地识别并接近问题的根本原因,而无需费力地寻找“干草堆中的针”。下面是本篇博客的快速总结和你所学内容:
-
Elastic Observability 提供了多种能力,帮助你减少定位根因的时间,提升平均修复时间(MTTR)甚至平均检测时间(MTTD)。
-
本文重点介绍了以下两项主要能力:
-
异常检测:开启后(参见文档),Elastic Observability 会持续建模你的时间序列数据的正常行为 —— 学习趋势、周期性等 —— 实时识别异常,简化根因分析,减少误报。异常检测在 Elasticsearch 中运行并可扩展,且配备直观的用户界面。
-
日志分类:结合异常检测,Elastic 快速识别日志事件中的模式。日志分类视图会根据日志消息和格式自动分组,无需手动识别相似日志,方便你更快采取行动。
-
-
你已经了解如何轻松使用 Elastic Observability 的日志分类和异常检测功能,无需理解底层机器学习原理,也无需复杂设置。
准备好开始了吗?注册 Elastic Cloud,试用上述介绍的功能和能力吧。
原文:Root cause analysis with logs: Elastic Observability's anomaly detection and log categorization — Elastic Observability Labs