深度学习(第一集)
123
import torch
# 创建一个需要计算梯度的张量
x1 = torch.tensor([2.0], requires_grad=True)
# 定义一个简单的函数 y = x^2
y = x1 ** 4
# 计算梯度
y.backward()
print("x1.grad 的值:", )
# 打印 x1.grad
print("x1.grad 的值:", x1.grad)
# 打印 x1.grad.item()
print("x1.grad.item() 的值:", x1.grad.item())
y.backward()先这样才能运行有一个 x1.grad
x1.grad就是该点的一个导数
import torch
# 模拟模型的输出,假设 batch_size = 3
output = torch.tensor([
[0.1, 0.2, 0.3, 0.4, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1],
[0.8, 0.1, 0.1, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.2, 0.1, 0.1]
])
# 使用 argmax 函数找出每个样本预测的类别
pred = output.argmax(dim=1, keepdim=False)
print("预测结果(类别索引):")
print(pred)
print(output) dim=1就是找到该行最大的
dim=1就是找到该行最大的
import torch
import torch.nn as nn
# 模拟测试数据和模型输出
# 假设 batch_size 为 4,num_classes 为 3
output = torch.tensor([
[0.1, 0.2, 0.7],
[0.8, 0.1, 0.1],
[0.3, 0.6, 0.1],
[0.2, 0.7, 0.1]
], dtype=torch.float32)
target = torch.tensor([2, 0, 1, 1], dtype=torch.long)
# 定义损失函数
criterion = nn.CrossEntropyLoss() #创建了交叉熵损失函数。
print(criterion)
# 初始化测试损失
test_loss = 0
# 计算当前批次的损失
loss = criterion(output, target)
print(loss)
print(f"当前批次的损失值: {loss.item()}")
# 累加损失值
test_loss += loss.item()
print(loss.item())
print(f"累加后的测试损失: {test_loss}")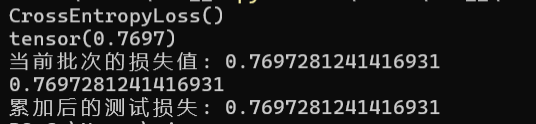
123
import torch
# 模拟模型的预测结果
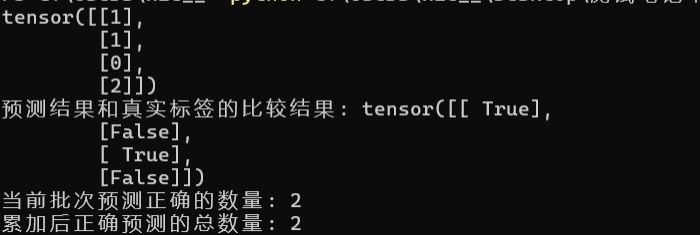
pred = torch.tensor([[1], [2], [0], [1]], dtype=torch.long)
# 模拟真实标签
target = torch.tensor([1, 1, 0, 2], dtype=torch.long)
# 初始化正确预测的数量
correct = 0
# 将 target 调整为和 pred 相同的形状
target_reshaped = target.view_as(pred)
print(target_reshaped)
# 比较预测结果和真实标签
comparison = pred.eq(target_reshaped)
print(f"预测结果和真实标签的比较结果: {comparison}")
# 统计预测正确的数量
correct_count = comparison.sum().item()
print(f"当前批次预测正确的数量: {correct_count}")
# 累加正确预测的数量
correct += correct_count
print(f"累加后正确预测的总数量: {correct}")
123
# 模拟测试集的样本数量
num_samples = 10
# 初始化总损失
test_loss = 0
# 模拟每道题的扣分情况(损失值)
# 这里假设每道题的扣分分别是 1, 2, 0, 3, 1, 0, 2, 1, 0, 2
losses = [1, 2, 0, 3, 1, 0, 2, 1, 0, 2]
# 累加每道题的扣分(损失值)
for loss in losses:
test_loss += loss
# 计算平均损失
test_loss /= num_samples #test_loss = test_loss / num_samples
print(f"总扣分: {sum(losses)}")
print(f"题目总数: {num_samples}")
print(f"平均每道题扣的分数(平均损失): {test_loss}")

123
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的线性模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.linear = nn.Linear(10, 1)
def forward(self, x):
return self.linear(x)
# 创建模型实例
model = SimpleModel()
# 定义学习率
learning_rate = 0.001
# 创建 Adam 优化器
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 模拟输入数据和目标数据
input_data = torch.randn(32, 10)
target = torch.randn(32, 1)
print(input_data)
print(target)
# 定义损失函数
criterion = nn.MSELoss()
# 前向传播
output = model(input_data)
loss = criterion(output, target)
# 打印更新前的参数
print("更新前的参数:")
for name, param in model.named_parameters():
print(name, param.data)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 打印更新后的参数
print("\n更新后的参数:")
for name, param in model.named_parameters():
print(name, param.data)