【maxENT】最大熵模型(Maximum Entropy Model)介绍与使用(maxENT软件)
文章目录
- 一、模型
- 1.1 最大熵原理
- 1.2 模型特点
- 1.3 熵的定义
- 1.4 约束条件
- 1.5 最优化问题
- 1.6模型求解
- 1.61 拉格朗日函数
- 1.62 解的形式
- 1.63 IIS优化算法
- 二、软件安装
- 三、数据准备
- 3.1 ✅ 物种的点位数据
- 3.2 ✅环境变量
- 3.3 注意事项
- 四、软件使用
- 五、软件参数
一、模型
🟢 第一节简单看一下就行了,写论文别参考本文,去看文献。后面的内容看仔细点
1.1 最大熵原理
最大熵模型(Maximum Entropy Model)源于信息论中的最大熵原理,由E.T. Jaynes于1957年提出。该原理指出:在已知部分约束条件下,最合理的概率分布是满足这些约束条件下熵最大的分布。这种分布对未知信息不做任何主观假设,保持最大的不确定性。
例如预测天气时,若已知下雨概率为0.3,则晴天概率应设为0.7才能保持最大不确定性,而非主观猜测其他可能性。
1.2 模型特点
- 特征灵活:允许任意形式的特征函数组合
- 无偏性:避免引入未经验证的假设
- 概率输出:直接输出条件概率P(Y|X)
- 兼容性:可与其他模型联合使用
1.3 熵的定义
对于离散随机变量Y,熵的数学表达式为:
H
(
Y
)
=
−
∑
y
P
(
y
)
log
P
(
y
)
H(Y) = -\sum_{y} P(y)\log P(y)
H(Y)=−y∑P(y)logP(y)
条件熵表达式:
H
(
Y
∣
X
)
=
−
∑
x
,
y
P
(
x
)
P
(
y
∣
x
)
log
P
(
y
∣
x
)
H(Y|X) = -\sum_{x,y} P(x)P(y|x)\log P(y|x)
H(Y∣X)=−x,y∑P(x)P(y∣x)logP(y∣x)
1.4 约束条件
假设有n个特征函数
f
i
(
x
,
y
)
f_i(x,y)
fi(x,y),每个特征对应的期望约束为:
E
P
(
f
i
)
=
E
P
~
(
f
i
)
E_P(f_i) = E_{\widetilde{P}}(f_i)
EP(fi)=EP
(fi)
其中:
- 经验期望: E P ~ ( f i ) = ∑ x , y P ~ ( x , y ) f i ( x , y ) E_{\widetilde{P}}(f_i) = \sum_{x,y} \widetilde{P}(x,y)f_i(x,y) EP (fi)=∑x,yP (x,y)fi(x,y)
- 模型期望: E P ( f i ) = ∑ x , y P ~ ( x ) P ( y ∣ x ) f i ( x , y ) E_{P}(f_i) = \sum_{x,y} \widetilde{P}(x)P(y|x)f_i(x,y) EP(fi)=∑x,yP (x)P(y∣x)fi(x,y)
1.5 最优化问题
建立约束最优化模型:
max
P
∈
C
H
(
P
)
=
−
∑
x
,
y
P
~
(
x
)
P
(
y
∣
x
)
log
P
(
y
∣
x
)
\max_{P \in \mathcal{C}} H(P) = -\sum_{x,y} \widetilde{P}(x)P(y|x)\log P(y|x)
P∈CmaxH(P)=−x,y∑P
(x)P(y∣x)logP(y∣x)
s
.
t
.
E
P
(
f
i
)
=
E
P
~
(
f
i
)
i
=
1
,
2
,
.
.
.
,
n
s.t.\quad E_P(f_i) = E_{\widetilde{P}}(f_i) \quad i=1,2,...,n
s.t.EP(fi)=EP
(fi)i=1,2,...,n
∑
y
P
(
y
∣
x
)
=
1
\sum_y P(y|x) = 1
y∑P(y∣x)=1
1.6模型求解
1.61 拉格朗日函数
引入拉格朗日乘子
λ
i
\lambda_i
λi,构造:
L
(
P
,
λ
)
=
−
H
(
P
)
+
∑
i
=
1
n
λ
i
(
E
P
(
f
i
)
−
E
P
~
(
f
i
)
)
+
λ
0
(
∑
y
P
(
y
∣
x
)
−
1
)
L(P,\lambda) = -H(P) + \sum_{i=1}^n \lambda_i(E_P(f_i) - E_{\widetilde{P}}(f_i)) + \lambda_0(\sum_y P(y|x)-1)
L(P,λ)=−H(P)+i=1∑nλi(EP(fi)−EP
(fi))+λ0(y∑P(y∣x)−1)
1.62 解的形式
通过变分法求得最优解:
P
λ
(
y
∣
x
)
=
1
Z
λ
(
x
)
exp
(
∑
i
=
1
n
λ
i
f
i
(
x
,
y
)
)
P_\lambda(y|x) = \frac{1}{Z_\lambda(x)}\exp\left(\sum_{i=1}^n \lambda_i f_i(x,y)\right)
Pλ(y∣x)=Zλ(x)1exp(i=1∑nλifi(x,y))
其中归一化因子:
Z
λ
(
x
)
=
∑
y
exp
(
∑
i
=
1
n
λ
i
f
i
(
x
,
y
)
)
Z_\lambda(x) = \sum_y \exp\left(\sum_{i=1}^n \lambda_i f_i(x,y)\right)
Zλ(x)=y∑exp(i=1∑nλifi(x,y))
1.63 IIS优化算法
改进的迭代缩放算法步骤:
- 初始化 λ i = 0 \lambda_i=0 λi=0
- 对每个特征
f
i
f_i
fi:
- 计算 δ i \delta_i δi使下界函数最大
- 更新 λ i ← λ i + δ i \lambda_i \leftarrow \lambda_i + \delta_i λi←λi+δi
- 重复直到收敛
更新公式推导:
δ
i
=
1
C
log
E
P
~
(
f
i
)
E
P
(
f
i
)
\delta_i = \frac{1}{C}\log \frac{E_{\widetilde{P}}(f_i)}{E_P(f_i)}
δi=C1logEP(fi)EP
(fi)
其中
C
C
C是特征总数
二、软件安装
✅ (1)Java安装
maxENT软件是java编写的,所以先安装java环境。
链接:https://www.java.com/en/download/manual.jsp
下载安装即可:第三个即可(其它也行)
java被Oracle收购了的,所以去Oracle下载安装也是一样的。
安装后命令行输入java看看有没有输出:这个安装应该是不用手动添加环境变量的。
✅ (2)maxENT软件安装
链接:https://biodiversityinformatics.amnh.org/open_source/maxent/
选择不提供信息直接下载即可
下载后解压即可,不用安装。
三、数据准备
3.1 ✅ 物种的点位数据
数据结构:三列:物种名称、经度、纬度
列名应该没有限制,安装这个顺序就行了,比如我是:species、x、y。
网站:https://www.gbif.org/
这个算是民间数据了,大多来自iNaturallist这些网站。你也可以使用你自己实地考察获得的点位数据。
搜索物种名称,结果右边:xxx occurrences ,就是出现的点位。
点进去选择下载:
一般选择第一个即可:
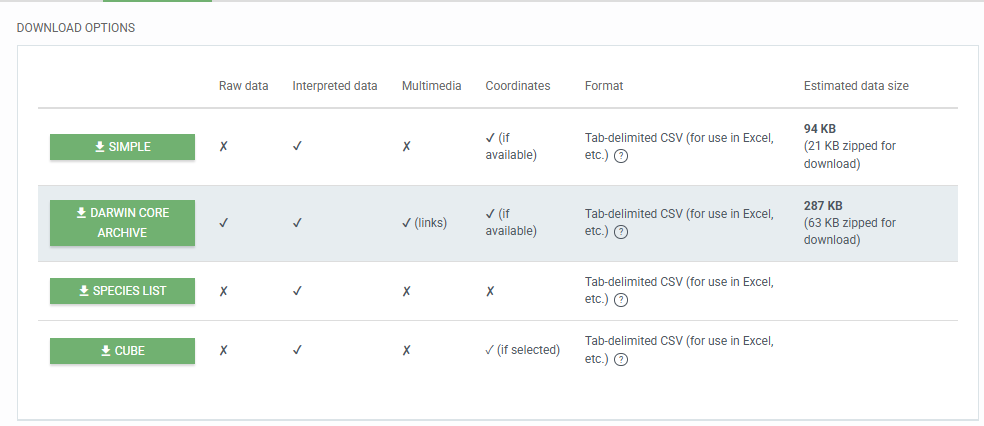
下载的CSV文件是空格分隔的CSV文件:右键用记事本打开显示的好看一点,excel可能不太容易看。
比如我用notepad ++ 打开:数据有几十列呢

一般只要几列即可,比如:species、 decimalLatitude、decimalLongitude、year就够了(maxENT只要前面3个)。
我用matlab提取的,参考代码:
clear
clc
%% 10列是物种,16列是国家2字母代码,22,23列是纬度、经度,33列是年份
% data = readtable('源文件\藏羚羊.csv',VariableNamingRule='preserve');
% data = data(:,[16,22,23,33]);
% data = data(strcmp(data.countryCode,'CN'),:);
% data = rmmissing(data);
% fprintf('藏羚羊:%d个有效数据.\n',length(data.countryCode));
% writetable(data,'藏羚羊点位.csv');
%%
% 设置路径和文件参数
sourceDir = '源文件'; % 原始数据文件夹
outputDir = './'; % 输出文件夹
targetColumns = [10,16, 22, 23, 33]; % 需保留的列索引
countryFilter = 'CN'; % 筛选的国家代码
% 获取所有CSV文件列表
fileList = dir(fullfile(sourceDir, '*.csv'));
% 遍历处理每个文件
for i = 1:length(fileList)
% 跳过已处理的“点位”文件(避免重复处理)
if contains(fileList(i).name, '点位'), continue; end
% 读取数据
filePath = fullfile(sourceDir, fileList(i).name);
data = readtable(filePath, 'VariableNamingRule', 'preserve');
% 检查列索引是否合法
if max(targetColumns) > width(data)
fprintf('文件 %s 列数不足,跳过处理.\n', fileList(i).name);
continue;
end
% 选择指定列
data = data(:, targetColumns);
% 筛选国家代码(列名为'countryCode')
if ~any(strcmp(data.Properties.VariableNames, 'countryCode'))
fprintf('文件 %s 缺少 countryCode 列,跳过处理.\n', fileList(i).name);
continue;
end
data = data(strcmp(data.countryCode, countryFilter), :);
% 删除缺失值
data = rmmissing(data);
% 年份降序
data = sortrows(data,"year","descend");
% 去掉国家代码
data = data(:,[1,3,4,5]);
% 生成输出文件名
[~, baseName, ~] = fileparts(fileList(i).name);
outputFile = fullfile(outputDir, [baseName '_点位.csv']);
% 保存结果
writetable(data, outputFile);
fprintf('文件 %s 处理完成,有效数据量: %d\n', fileList(i).name, height(data));
end
disp('全部文件处理完毕!');
数据的坐标是十进制的,这是ok的。如果你的数据的经纬度是度分秒这种,需要自己转换为十进制。自己问AI写两行代码就行了。
3.2 ✅环境变量
即影响物种分布的相关环境变量,如:气温、降水、高程、坡度、到水源距离等等。
自己找吧,比如:
国家地球系统科学数据中心:www.geodata.cn
资源环境科学数据平台:www.resdc.cn
国家生态科学数据中心:https://www.nesdc.org.cn/
也可以TB买,但是要注意它数据的来源、年份,因为你论文要写数据来源的。
有的数据可以Google搜英文名称:在zenodo、figshare上可能会搜到。
搜数据注意:地点、年份、分辨率
如:中国30米年最大NDVI数据集
最后这些数据栅格的参数要一致:分辨率、坐标系、行列数
我用的是ArcGIS Pro。
行列数一致可以使用:复制栅格,关键设置捕捉栅格和范围,这样就可以与参考的那个栅格完全对齐了。
ArcGIS 有个SDM工具箱:http://www.sdmtoolbox.org/,可以按文件夹批量处理栅格。
3.3 注意事项
另外要注意的是:maxENT需要使用ASCII格式的环境数据,即栅格转ASCII。 ArcGIS的工具箱和SDM Tool都有这个功能。
ASCII格式的文件体积会变大非常多,1GB变成5GB这种。
所以要注意你的栅格的数据类型,最好用整型存储。小数的话可以乘以10000(4位小数的经度)保存为整型。
这个不展开了,数据类型是基础知识。
如果你给你的栅格添加了投影坐标系,那你的点位数据的经纬度也要转为投影的坐标,而不是地理坐标系的经纬度坐标。
四、软件使用
解压maxENT后,会看到:
- maxent.bat
- maxent.jar
- maxent.sh
这三个都可以启动软件。
Windows通常使用bat启动即可。
右键以任意文本编辑器打开bat脚本:可以看到
java -mx512m -jar maxent.jar
@if errorlevel 1 pause
512m就是java虚拟机可以使用的最大内存,你可以改的大一些。
然后双击bat或者jar即可打开软件。
如果你安装了shell终端比如git的,也可以使用那个shell脚本运行软件。
前面说了:maxENT使用的环境变量是ASCII格式的,文件很大,如果你使用的是高分辨率的栅格,如30米,那ASCII格式的文件可能会达到几十GB、几百GB,我猜你的电脑内存是没那么大的,程序运行不了的。
如果你的栅格是1km这种很低的分辨率应该不会有这种困惑。
这时候可以使用R语言实现maxENT模型,支持栅格输入,分块处理。后面写文章,在我主页搜索即可。
五、软件参数
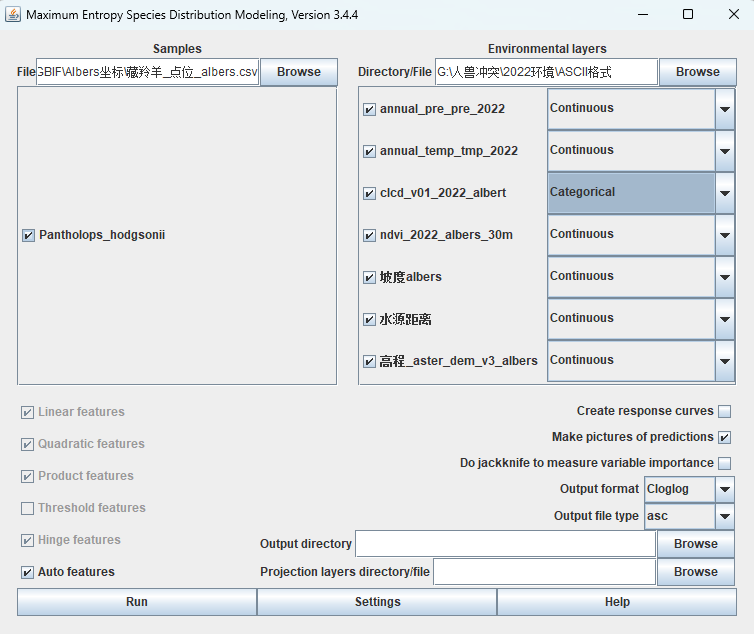
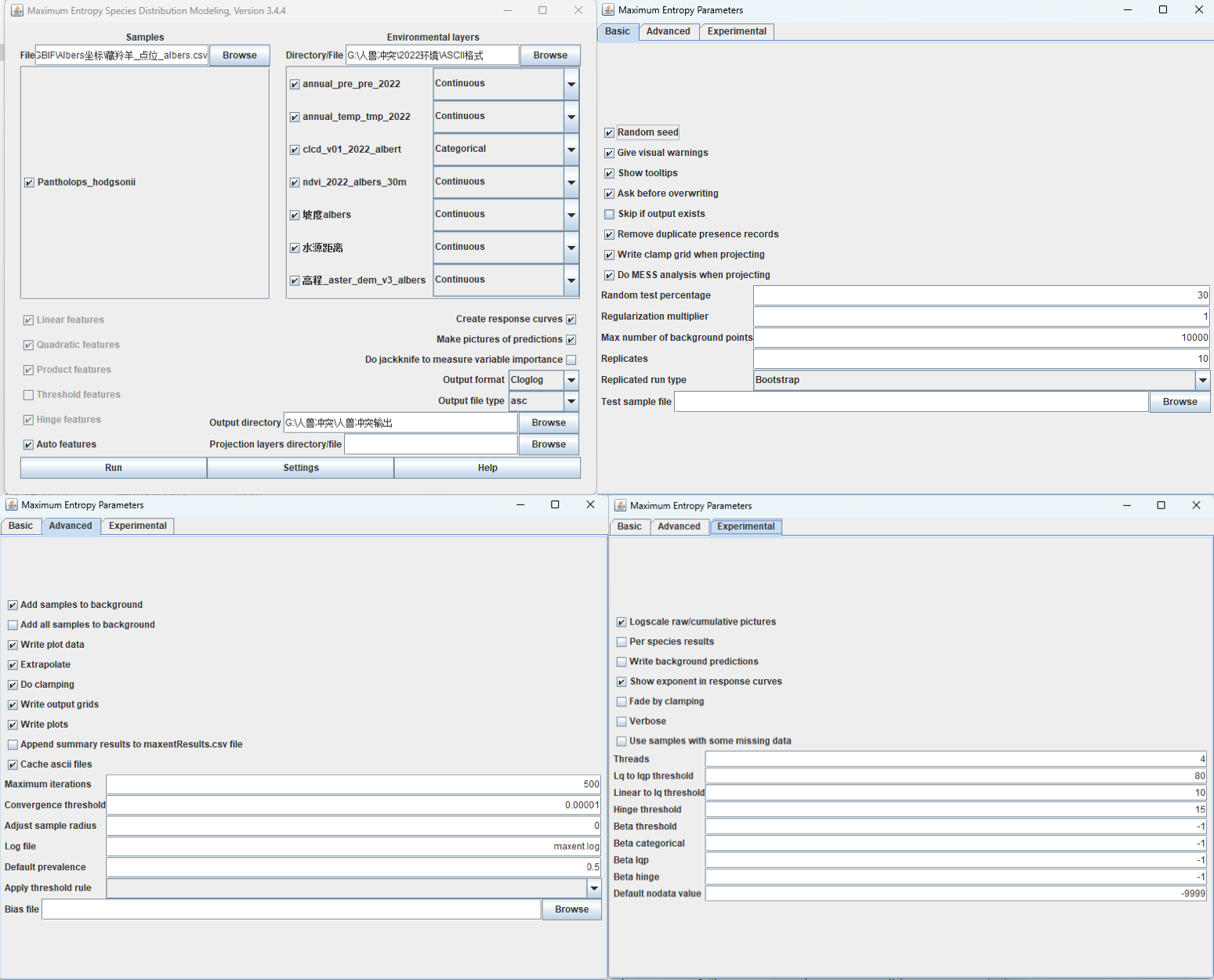
左边是物种的csv文件,可以把多种物种放在一个csv文件里面,3列:species,经度,纬度。(列名应该没有要求,我是species,x, y)
右边是环境的ascii文件的文件夹,土地利用是分类变量。
Output Folder是输出文件的保存位置。
下面是AI识别图片给出的解释,不全部正确,参考一下即可。
🔹软件其它选项:
主页:
- 特征类型(左下):线性(Linear)、二次项(Quadratic)、乘积项(Product)、阈值(Threshold)、片段(Hinge),这里使用的是自动选择。
- Create response curves:创建响应曲线。选中此选项后,软件会生成响应曲线,以展示不同环境变量对物种分布的影响。
- Make pictures of predictions:生成预测结果的图片。选中此选项后,软件会生成预测结果的可视化图片,方便查看和分析。
- Do jackknife to measure variable importance:使用Jackknife方法测量变量重要性。选中此选项后,软件会使用Jackknife方法来评估各个环境变量对模型预测结果的重要性。
- Output format:输出格式。选择输出文件的格式,例如Cloglog。
- Output file type:输出文件类型。选择输出文件的类型,例如asc(ASCII文件)。
settings:
-
Basic:
- Random seed:随机种子。选中此选项后,每次运行模型时会使用相同的随机种子,确保结果的可重复性。
- Give visual warnings:给出视觉警告。选中此选项后,软件会在出现警告时显示视觉提示。
- Show tooltips:显示工具提示。选中此选项后,鼠标悬停在界面元素上时会显示工具提示信息。
- Ask before overwriting:覆盖前询问。选中此选项后,软件在覆盖现有文件前会询问用户确认。
- Skip if output exists:如果输出存在则跳过。选中此选项后,如果输出文件已经存在,软件会自动跳过该文件的生成。
- Remove duplicate presence records:移除重复的出现记录。选中此选项后,软件会自动移除重复的物种出现记录。
- Write clamp grid when projecting:投影时写入夹持网格。选中此选项后,软件在进行投影时会生成夹持网格文件。
- Do MESS analysis when projecting:投影时进行MESS分析。选中此选项后,软件在进行投影时会进行MESS(Maxent软件的一种统计分析方法)分析。
- Random test percentage:随机测试百分比。设置用于测试的随机样本的百分比。
- Regularization multiplier:正则化乘数。设置正则化参数的乘数,用于控制模型的复杂度。
- Max number of background points:最大背景点数。设置最大背景点的数量,背景点用于训练模型。
- Replicates:重复次数。设置模型运行的重复次数,用于评估模型的稳定性。
- Replicated run type:重复运行类型。选择重复运行的类型,例如交叉验证(Crossvalidate)。
- Test sample file:测试样本文件。指定用于测试的样本文件。
-
Advanced:
- Add samples to background:将样本添加到背景数据中。选中此选项后,软件会将样本数据添加到背景数据中,以提高模型的准确性
- Add all samples to background:将所有样本添加到背景数据中。选中此选项后,软件会将所有样本数据添加到背景数据中。
- Write plot data:写入绘图数据。选中此选项后,软件会生成绘图所需的数据文件。
- Extrapolate:外推。选中此选项后,软件会在模型预测时进行外推,以覆盖更多的区域。
- Do clamping:进行夹持。选中此选项后,软件会在模型预测时进行夹持,以限制预测值的范围。
- Write output grids:写入输出网格。选中此选项后,软件会生成输出网格文件。
- Write plots:写入绘图。选中此选项后,软件会生成绘图文件。
- Append summary results to maxentResults.csv file:将摘要结果追加到maxentResults.csv文件中。选中此选项后,软件会将摘要结果追加到指定的CSV文件中。
- Cache ascii files:缓存ASCII文件。选中此选项后,软件会缓存ASCII文件,以提高处理速度。
- Maximum iterations:最大迭代次数。设置模型训练的最大迭代次数。
- Convergence threshold:收敛阈值。设置模型训练的收敛阈值。
- Adjust sample radius:调整样本半径。设置样本半径的调整值。
- Log file:日志文件。指定日志文件的名称。
- Default prevalence:默认流行率。设置模型训练的默认流行率。
- Apply threshold rule:应用阈值规则。选择应用阈值规则的类型。
- Bias file:偏差文件。指定偏差文件的名称。
-
Experimental:
-
Logscale raw/cumulative pictures:对原始/累积图片进行对数缩放。选中此选项后,软件会将原始或累积的图片数据进行对数缩放,以便更好地展示数据的分布情况。
-
Per species results:按物种结果。选中此选项后,软件会为每个物种生成单独的结果文件。
-
Write background predictions:写入背景预测。选中此选项后,软件会生成背景预测结果文件。
-
Show exponent in response curves:在响应曲线中显示指数。选中此选项后,软件会在响应曲线中显示指数值,以便于分析变量对物种分布的影响。
-
Fade by clamping:通过夹持进行淡出。选中此选项后,软件会通过夹持方法对预测结果进行淡出处理。
-
Verbose:详细模式。选中此选项后,软件会输出详细的运行日志信息。
-
Use samples with some missing data:使用带有缺失数据的样本。选中此选项后,软件会使用带有缺失数据的样本进行建模。
-
Threads:线程数。设置软件运行时使用的线程数,增加线程数可以加快计算速度。
-
Lg to lgp threshold:对数到对数概率阈值。设置对数到对数概率的阈值,用于确定物种分布的概率范围。
-
Linear to lg threshold:线性到对数阈值。设置线性到对数的阈值,用于确定物种分布的概率范围。
-
Hinge threshold:铰链阈值。设置铰链阈值,用于确定物种分布的概率范围。
-
Beta threshold:Beta阈值。设置Beta阈值,用于确定物种分布的概率范围。
-
Beta categorical:Beta分类。设置Beta分类阈值,用于确定物种分布的概率范围。
-
Beta lgp:Beta对数概率。设置Beta对数概率阈值,用于确定物种分布的概率范围。
-
Beta hinge:Beta铰链。设置Beta铰链阈值,用于确定物种分布的概率范围。
-
Default nodata value:默认无数据值。设置默认的无数据值,用于处理缺失数据。
-
比如:第三列(最后一张图)那个:Write background predictions选项可以选上,我截图的时候没选择。这个输出数据可以用来自己话ROC曲线。