顶刊【遥感舰船目标检测】【TGRS】CM-YOLO:基于上下文调制表征学习的船舶检测方法
CM-YOLO: Context Modulated Representation Learning for Ship Detection
CM-YOLO:基于上下文调制表征学习的船舶检测方法
TGRS-2025

0.论文摘要
摘要—船舶检测在军事和民用领域均具有重要应用价值。现有方法主要关注显著的海上船舶,对易与复杂背景混淆的近岸船舶关注不足。利用位置、形状等上下文信息可提升复杂环境下的船舶检测与分类性能。本文提出一种基于上下文调制表征学习的检测方法CM-YOLO,其采用包含骨干网络、颈部网络和检测头的经典检测器设计框架,输入图像依次通过这三个组件获得检测结果。该方法专门针对复杂场景的船舶检测进行优化:首先提出双路径上下文增强颈部网络(DCEN),在路径增强特征金字塔网络基础上构建双路径上下文增强(DCE)模块,通过融合高层语义信息增强特征表征能力,在通道和空间维度捕获长程依赖关系的同时抑制无关特征;其次提出多上下文增强(MCB)检测头,通过多组大核卷积灵活调整感受野,为不同尺度船舶提取相关上下文,从而提升复杂环境下多尺度船舶的检测能力。我们在Seaships7000、ShipRSImageNet、DIOR-ship和HRSC2016四个常用船舶数据集上进行实验,结果表明CM-YOLO相比现有领先方法具有更优性能。
索引术语— 大核卷积,多尺度特征融合,船舶检测。
1.引言
船舶检测旨在精准定位并识别给定图像或视频中的船只,以保障相应水域的安全。通过监测近岸船舶,能够准确快速地提升航道利用效率和港口管理水平[1]、[2]、[3]。然而海岸天气的快速变化、复杂的岸线背景等因素,给船舶检测的准确性带来了显著挑战[4]、[5]。因此,设计精确且鲁棒的船舶检测算法至关重要。
近年来,随着深度学习的复兴,船舶检测领域取得了显著进展[6]、[7]、[8]。大多数船舶检测算法[9]、[10]、[11]通过将通用目标检测架构进行针对性改造来实现。例如Yang等[12]设计了坐标注意力模块,通过两个一维全局池化操作将二维空间分解为垂直和水平方向,使通用目标检测器能生成具有位置和方向感知的特征图,从而提升船舶目标的识别与区分能力。Yu等[13]为RetinaNet[14]设计了新型数据预处理模块,通过构建分类网络判断图像块中是否存在船舶,有效减少了空白区域导致的误检。Li等[15]基于Faster R-CNN[16]开发了空间频率特征融合网络,将傅里叶变换生成的频域特征与CNN提取的空域特征相结合,提升了复杂背景SAR图像中的船舶检测性能。
这些研究推动了船舶检测的发展,但需要指出的是,船舶检测常面临更复杂的场景:前述方法仅在简单环境中有效,缺乏足够的普适性。现有方法更关注显著目标的检测,例如近海环境中的大型船舶。然而在近岸区域,由于背景复杂,多尺度船舶的检测难度显著增加。船舶检测常处于高度复杂的环境中,海岸线会带来严重干扰:船舶在视觉上可能与背景中的杂物相似,难以与周边建筑物等元素区分;某些情况下船舶甚至会与背景特征重叠,进一步增加检测难度。如图1所示,集装箱可能同时出现在岸上和船舶上,当仅使用有限的局部信息时,区分它们将变得异常困难。
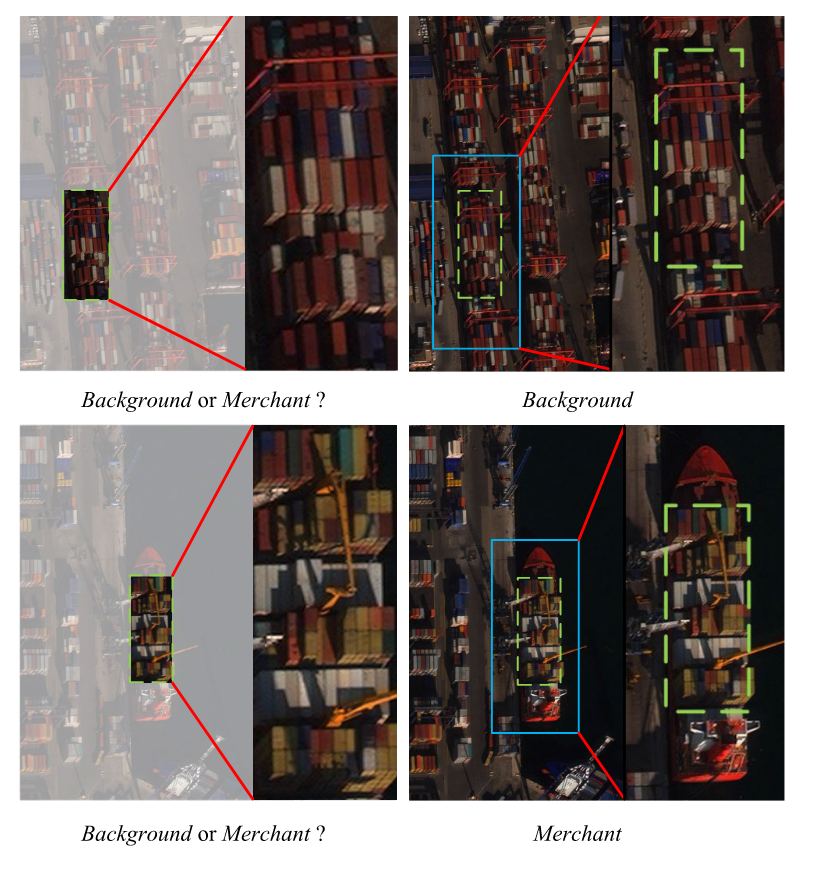
图1. 上下文信息对船舶检测的影响。不同的上下文信息会导致检测结果存在差异。上图误导模型将目标误判为背景,而下图则正确识别出集装箱船。
网络中较大的感受野通常与捕捉更全面的上下文信息能力相关[17]、[18]、[19]、[20]、[21]、[22],这在上下文信息起关键作用的船舶检测任务中尤为重要。当感受野过小时,模型可能难以获取足够的上下文信息[23]、[24],导致无法准确区分船舶与噪声。现有方法更侧重于检测远海大型船舶,而近岸船舶由于海岸线的干扰效应,其检测性能受限。为解决船舶与背景混淆的问题,受大核卷积在上下文信息学习中的成功启发[25]、[26]、[27]、[28],我们采用大核卷积来扩展模型的感受野。这种方法能在丰富的上下文信息中调制特征,从而实现复杂场景下的船舶检测。
本文提出了一种新颖的船舶检测模型——基于上下文调制表征学习的检测模型(CM-YOLO)。为平衡速度与精度,CM-YOLO选择YOLOX[29]作为基础检测框架,包含骨干网络、颈部网络和检测头三部分。输入图像依次通过骨干网络、颈部网络和检测头生成检测结果。为增强上下文信息提取能力,我们提出双路径上下文增强颈部网络(DCEN),该结构在路径增强特征金字塔网络基础上引入双路径上下文增强模块(DCE)。通过DCE模块,CM-YOLO能自适应调整特征学习,在空间和通道维度捕获长程依赖关系。此外,为缓解颈部网络中不同分辨率特征图简单相加导致的语义鸿沟,我们提出多上下文增强检测头(MCB)来提升船舶检测的尺度感知能力。MCB采用多组大核卷积提取不同尺度船舶所需的上下文信息,使模型获得更大感受野。在Seaships7000、HRSC2016和ShipRSImageNet数据集上的大量实验表明:相比原始YOLOX,CM-YOLO在可接受的速度损失下实现了更高精度,同时减少了参数量和浮点运算量(FLOPs)。实验结果证明CM-YOLO具有显著竞争力,能在各类复杂环境中保持稳定优异的检测性能。
我们的主要贡献可概括如下:
1)提出新型DCE模块,能够在通道和空间维度同时建模长程依赖关系,并利用上下文信息增强高层语义特征表征;
2)设计具有多尺度大核卷积的MCB检测头,能针对不同尺寸船舶选择必要的空间上下文信息,从而提升特征尺度感知能力;
3)构建端到端的CM-YOLO模型,显著增强船舶检测任务中的特征判别能力。该模型在复杂场景下仍保持优异性能,超越了现有最先进方法。
本文其余部分组织结构如下。第二章介绍船舶检测和大核模型的相关研究工作。第三章阐述CM-YOLO模型的整体结构及所提方法的具体实现细节。第四章展示实验结果分析。第五章总结本文的研究内容。
2.相关工作
A. 船舶检测
随着CNN在目标检测中的成功应用,基于CNN的船舶检测也受到了广泛关注。当前船舶检测通常采用通用目标检测框架进行特征提取,并针对船舶的特性对网络进行改进。为了进一步分析船舶检测的进展,根据方法的核心侧重点可将其大致分为两类:多尺度特征融合和基于注意力的特征增强。
基于多尺度特征融合的方法旨在应对不同尺度船舶带来的检测挑战。这类方法通常采用不同尺寸的卷积核或融合全局与局部特征,以实现更有效的特征表征。例如,Pan等[11]提出的SRT-Net通过集成散射区域拓扑结构金字塔与船舶显著性增强,利用图卷积网络捕获跨区域特征相似性,并引入像素级分类任务优化船舶轮廓,从而提升检测性能。Zhang与Wu[30]设计了高效感受野特征提取主干网络,嵌入多通道注意力机制突出船舶特征,通过不同尺寸卷积生成多尺度特征,再与跨通道特征融合以增强多尺度船舶检测能力。Ren等[31]基于RetinaNet[14]提出显著性引导的特征融合网络,通过金字塔结构预测不同分辨率的显著性图,再将显著性感知特征与底层特征重新整合,从而为小目标船舶提供更精细的信息。Fan等[32]提出的CSDP模块通过多次大核卷积扩大感受野,并采用逐点卷积混合通道位置信息,有效降低了遥感图像中小尺寸船舶的漏检率。Lin等[33]设计的DCEA模块通过融合局部细粒度信息与全局语义信息,缓解了遥感图像中船舶形变导致的误检问题,显著提升了多尺度船舶(尤其是非常规形状目标)的检测性能。Shen等[34]基于FCOS构建了四阶段分层结构,通过逐级分解大核卷积使模型能自适应选择符合船舶特性的卷积核,在增强多尺度船舶特征表征的同时提升了检测性能。
与多尺度特征融合不同,基于注意力的特征增强旨在通过利用注意力机制强化船舶特征表示,抑制背景特征,从而提升检测精度。围绕这一思路已发展出诸多研究:Tang等[35]针对近岸区域船舶误检问题,提出基于BiFormer的自适应特征识别方法,将BiFormer嵌入ELAN结构以充分利用船舶目标的独特性特征。Hao与Zhang[36]基于YOLOX提出轻量化增强特征提取模块,通过结合空洞卷积与高效通道注意力来捕获船舶周围的多尺度上下文信息,从而提升多尺度船舶检测性能。Tang等[37]提出面向多尺度感受野卷积块的注意力机制,利用多组卷积结构提取不同层级的感受野,捕获对检测结果至关重要的特征图区域,从而增强模型学习船舶与背景关系的能力。Yin等[38]提出基于YOLOv5的LHAB-GhostCNN船舶检测算法,集成两个ghost 模块与两条差异化路径来生成不同分辨率的特征,有效辅助资源受限平台在海洋环境中进行船舶检测。Chen等[39]针对复杂场景多尺度船舶检测改进FPN,提出整合混洗注意力与空洞空间金字塔池化的SAS-FPN,减少小尺寸船舶的特征损失并增强模型对多尺度船舶的检测性能。代表性工作是3WM-AugNet[40],其设计多粒度特征增强模块来有效利用对船舶检测至关重要的多尺度特征,通过整合高低层特征增强FPN中的特征融合,促进信息从下层向上层传递的同时保留对船舶精准检测关键的粒度特征。与上述方法不同,我们的方法旨在探索不同尺度船舶的上下文信息,通过提供环境线索辅助船舶识别,从而提升复杂环境中尺度差异显著船舶的检测性能。
B. 大核卷积网络
大核卷积能够扩大模型的感受野,使其比小核卷积学习更多特征表示,从而更好地理解船舶上下文[41]、[42]、[43]。例如,Peng等人[44]提出采用(1, k)和(k, 1)两种一维大卷积组合提取特征,将卷积核尺寸增至15,在分割任务中实现了性能提升。Ding等人[27]提出的RepLKNet摒弃了一系列小核,直接将卷积核尺寸增大至(31×31),在ImageNet上达到了与Swin Transformer相当的性能。虽然这些算法确实提升了性能,但代价是显著增加了计算开销,削弱了大卷积核的优势。因此,一系列研究开始探索如何在增大核尺寸的同时避免过高计算成本。Azad等人[45]提出可变形大核注意力机制,通过整数偏移量自由调整采样网格实现形变,在扩大感受野的同时规避计算开销。Guo等人[46]提出的视觉注意力网络(VAN)通过将大核卷积分解为深度卷积、深度扩张卷积和逐点卷积,有效减少了参数量和计算量。采用简单线性注意力机制的VAN在同等规模下超越了ViT和CNN。Lau等人[47]提出大核可分离注意力,将深度卷积层的二维卷积核分解为级联的水平与垂直卷积核,显著降低了计算复杂度。不同于上述方法,我们采用多尺度深度卷积,使模型能从多尺度信息中学习适应不同尺寸船舶的特征。此外,我们在颈部引入大核卷积以增强尺度感知能力,从而有效检测多尺度船舶目标。
3.方法
A. 概述
CM-YOLO的框架如图2所示。该模型由三部分组成:骨干网络(backbone)、颈部网络(neck)和检测头(detection head)。给定输入图像 X ∈ R H × W × 3 X ∈ \mathbb{R}^{H×W×3} X∈RH×W×3,骨干网络首先处理输入图像并提取多层级特征 F i ∈ R H i × W i × C i F_i ∈ \mathbb{R}^{H_i ×W_i ×C_i} Fi∈RHi×Wi×Ci(i = 1, 2, 3)。随后,颈部网络采用金字塔结构对这些特征进行多尺度融合,得到 F ^ i ∈ R H i × W i × C i \hat{F}_i ∈\mathbb{R}^{H_i ×W_i ×C_i} F^i∈RHi×Wi×Ci(i = 1, 2, 3)。该结构基于路径增强特征金字塔网络[48],并引入了本文提出的DCE模块。DCE用于提取上下文信息以调整高语义特征 F 3 F_3 F3的表征,从而过滤掉对船舶响应微弱的特征。最终,颈部网络输出的精炼特征 F ^ i ∈ R H i × W i × C i \hat{F}_i ∈\mathbb{R}^{H_i ×W_i ×C_i} F^i∈RHi×Wi×Ci(i = 1, 2, 3)将由检测头进行目标定位与分类。针对多尺度船舶可能存在的场景,为增强检测头的尺度感知能力,我们提出了MCB检测头。其中的多尺度模块进一步优化所需特征,并基于这些特征生成最终输出 D i ∈ R ( 类别 , x , y , w , h ) D_i ∈ \mathbb{R}^{(类别,x,y,w,h)} Di∈R(类别,x,y,w,h)(i = 1, 2, …)。下文将详细阐述所提出的DCE和MCB模块。
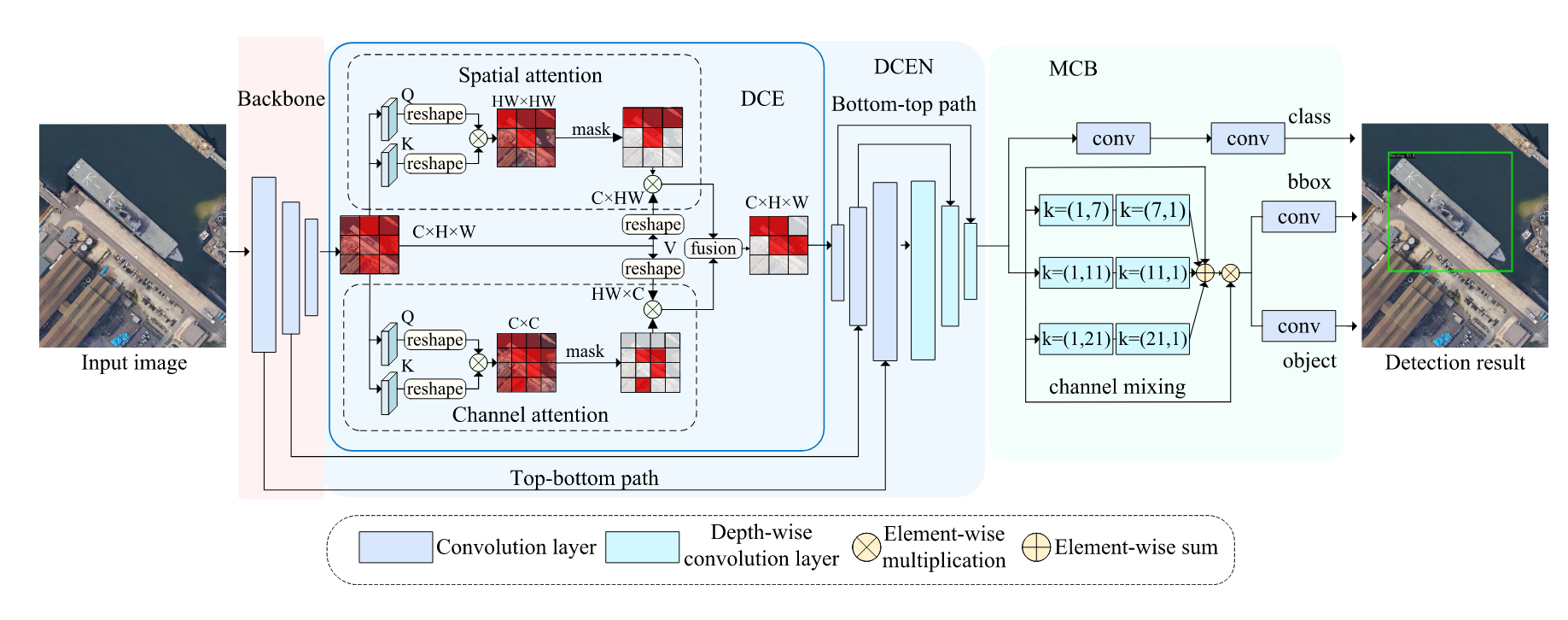
B. DCE模块
为充分提取船舶周围的丰富上下文信息并保留潜在船舶区域,我们提出了DCE模块。如图2所示,DCE由两个并行分支组成:通道注意力分支和空间注意力分支。在空间注意力方面,我们首先对特征进行重塑操作,通过矩阵乘法计算空间维度的自相似性,从而捕捉场景的全局信息。同时为降低背景干扰,我们在空间特征上施加掩膜操作,过滤低响应特征以提高计算效率。对于通道注意力,我们在重塑后的特征上计算通道维度的自相似性,同样采用掩膜操作过滤通道维度中的无关特征。通过结合空间注意力和通道注意力,DCE能够从通道和空间两个维度提取船舶的上下文信息,增强有助于检测的特征。DCE增强网络对最可能检测船舶关注度的过程可分为三个步骤。
首先,为生成 Q Q Q、 K K K和 V V V,需对主干网络提取的深层特征 F 3 F_3 F3进行层归一化处理。随后,应用 1 × 1 1×1 1×1卷积层建模像素级的跨通道上下文信息。接着执行 3 × 3 3×3 3×3深度可分离卷积层操作。该方法通过聚合跨通道信息来增强 Q Q Q、 K K K和 V V V中的局部细节特征。
Q , K , V = f d w c o n v 3 × 3 ( f c o n v 1 × 1 ( F ) ) ( 1 ) Q,K,V=f_{\mathrm{dwconv}}^{3\times3}\left(f_{\mathrm{conv}}^{1\times1}(F)\right)\quad(1) Q,K,V=fdwconv3×3(fconv1×1(F))(1)
其中 { Q , K , V } ∈ R H × W × C \{Q, K, V\} ∈ \mathbb{R}^{H×W×C} {Q,K,V}∈RH×W×C, f d w c o n v 3 × 3 ( ⋅ ) f^{3×3}_{dwconv}(·) fdwconv3×3(⋅)表示 3 × 3 3×3 3×3深度可分离卷积层, f c o n v 1 × 1 ( ⋅ ) f^{1×1}_{conv}(·) fconv1×1(⋅)表示1×1卷积层。
其次,我们需要计算 Q − K Q-K Q−K对的相似度以获取注意力矩阵 M M M。仅保留矩阵 M M M中响应值超过特定阈值的元素,因为这些元素通常携带检测任务中更为关键的信息。在进行矩阵乘法前,我们将 Q Q Q和 K K K重塑为 R C × N \mathbb{R}^{C×N} RC×N的维度,其中 N = H × W N=H×W N=H×W表示特征图上的像素数量。为了分别在通道和空间维度上提取信息,通道注意力分支和空间注意力分支中的注意力矩阵 M M M维度分别为 M c h a n n e l ∈ R C × C M^{channel}∈\mathbb{R}^{C×C} Mchannel∈RC×C和 M s p a t i a l ∈ R N × N M^{spatial}∈\mathbb{R}^{N×N} Mspatial∈RN×N。接着,为确保网络聚焦于潜在目标对象可能存在的区域,我们引入自适应选择机制来筛选注意力矩阵中得分最高的前 k k k组元素。该机制保留相对重要的元素,同时抑制相关性较低的元素以提升计算效率。在top-k机制中, k k k是控制矩阵 M M M稀疏度的可学习参数。通过scatter函数将小于前 k k k得分的元素置零,确保其不参与后续计算。该top-k机制的数学表达如下:
f t o p − k ( F i j ) = { F i j , F i j > t k 0 , e l s e w i s e ( 2 ) f_{\mathrm{top-}k}(F_{ij})=\begin{cases}F_{ij},&F_{ij}>t_k\\0,&\mathrm{elsewise}&\end{cases}\quad(2) ftop−k(Fij)={Fij,0,Fij>tkelsewise(2)
其中 F i j F_{ij} Fij表示输入矩阵第 i i i行第 j j j列的元素, t k t_k tk代表注意力矩阵 M M M第 j j j列行中第 k k k大的值。该符号标注了参与计算的矩阵元素具体位置。第三步中,注意力矩阵 M M M在通道注意力分支和空间注意力分支中分别独立经过top-k机制处理,生成新的注意力矩阵 M ^ c h a n n e l ∈ R C × C \hat{M}^{channel} ∈ \mathbb{R}^{C×C} M^channel∈RC×C和 M ^ s p a t i a l ∈ R N × N \hat{M}^{spatial} ∈ \mathbb{R}^{N×N} M^spatial∈RN×N,其表达式为:
M
^
s
p
a
t
i
a
l
=
f
t
o
p
−
k
(
M
s
p
a
t
i
a
l
)
(
3
)
\hat{M}_{\mathrm{spatial}}=f_{\mathrm{top-}k}(M_{\mathrm{spatial}})\quad\mathrm{(3)}
M^spatial=ftop−k(Mspatial)(3)
M
^
c
h
a
n
n
e
l
=
f
t
o
p
−
k
(
M
c
h
a
n
n
e
l
)
.
(
4
)
\hat{M}_{\mathrm{channel}}=f_{\mathrm{top-}k}(M_{\mathrm{channel}}).\quad\mathrm{(4)}
M^channel=ftop−k(Mchannel).(4)
随后,经过一个softmax层并与重塑后的矩阵
V
∈
R
C
×
N
V∈\mathbb{R}^{C×N}
V∈RC×N相乘后,得到两组输出
Y
c
h
a
n
n
e
l
∈
R
H
×
W
×
C
Y^{channel}∈\mathbb{R}^{H×W×C}
Ychannel∈RH×W×C和
Y
s
p
a
t
i
a
l
∈
R
H
×
W
×
C
Y^{spatial}∈\mathbb{R}^{H×W×C}
Yspatial∈RH×W×C。为了无缝融合像素级的跨通道上下文信息和空间长程上下文信息,我们将二者拼接后通过逐点卷积运算得到DCE模块的最终输出。上述过程可通过如下数学表达式表示:
D
C
E
(
Q
,
K
,
V
)
=
f
c
o
n
v
1
×
1
(
C
(
Y
c
h
a
n
n
e
l
,
Y
s
p
a
t
i
a
l
)
)
(
5
)
\mathrm{DCE}(Q,K,V)=f_{\mathrm{conv}}^{1\times1}(\mathbb{C}(Y^{\mathrm{channel}},Y^{\mathrm{spatial}}))\quad(5)
DCE(Q,K,V)=fconv1×1(C(Ychannel,Yspatial))(5)
其中
f
c
o
n
v
1
×
1
f_{\mathrm{conv}}^{1\times1}
fconv1×1表示逐点卷积,
C
(
⋅
)
\mathbb{C}(·)
C(⋅)代表拼接操作,
Y
c
h
a
n
n
e
l
Y^{\mathrm{channel}}
Ychannel和
Y
s
p
a
t
i
a
l
Y^{\mathrm{spatial}}
Yspatial可定义为
Y
s
p
a
t
i
a
l
=
exp
(
M
^
i
j
s
p
a
t
i
a
l
)
∑
i
,
j
exp
(
M
^
i
j
s
p
a
t
i
a
l
)
V
s
p
a
t
i
a
l
(
6
)
Y^{\mathrm{spatial}}=\frac{\exp\left(\hat{M}_{ij}^{\mathrm{spatial}}\right)}{\sum_{i,j}\exp\left(\hat{M}_{ij}^{\mathrm{spatial}}\right)}V^{\mathrm{spatial}}\quad\mathrm{(6)}
Yspatial=∑i,jexp(M^ijspatial)exp(M^ijspatial)Vspatial(6)
Y
c
h
a
n
n
e
l
=
exp
(
M
^
i
j
c
h
a
n
n
e
l
)
∑
i
,
j
exp
(
M
^
i
j
c
h
a
n
n
e
l
)
V
c
h
a
n
n
e
l
.
(
7
)
Y^{\mathrm{channel}}=\frac{\exp\left(\hat{M}{ij}^{\mathrm{channel}}\right)}{\sum{i,j}\exp\left(\hat{M}{ij}^{\mathrm{channel}}\right)}V^{\mathrm{channel}}.\quad\mathrm{(7)}
Ychannel=∑i,jexp(M^ijchannel)exp(M^ijchannel)Vchannel.(7)
应用DCE后,精炼的特征图获得了全局感受野,并选择性聚合了像素级跨通道上下文和空间长程上下文。该方法增强了特征图间的语义依赖性,同时提升了特征判别力。
C. MCB检测头
浅层特征具有更高的分辨率和丰富的空间信息,但由于感受野较小,缺乏语义深度。相比之下,深层特征能提供更多语义信息,但分辨率降低导致空间定位精度不足。然而,在颈部结构中简单叠加这些特征会产生语义鸿沟,引发特征混淆问题。为解决该问题并同时增强检测头在复杂场景中对不同尺寸船舶的尺度感知能力,我们提出了多尺度上下文模块(MCB)。该模块包含定位分支和分类分支,分别处理标签预测任务和位置预测任务。通过利用独立通道图间的多尺度上下文关系,我们能够强化空间信息并增强特定语义的特征表示。与原始检测头使用两个3×3卷积层(CBS)进行信息聚合不同,MCB采用大核卷积对不同尺度的特征图进行空间选择,如图3所示。
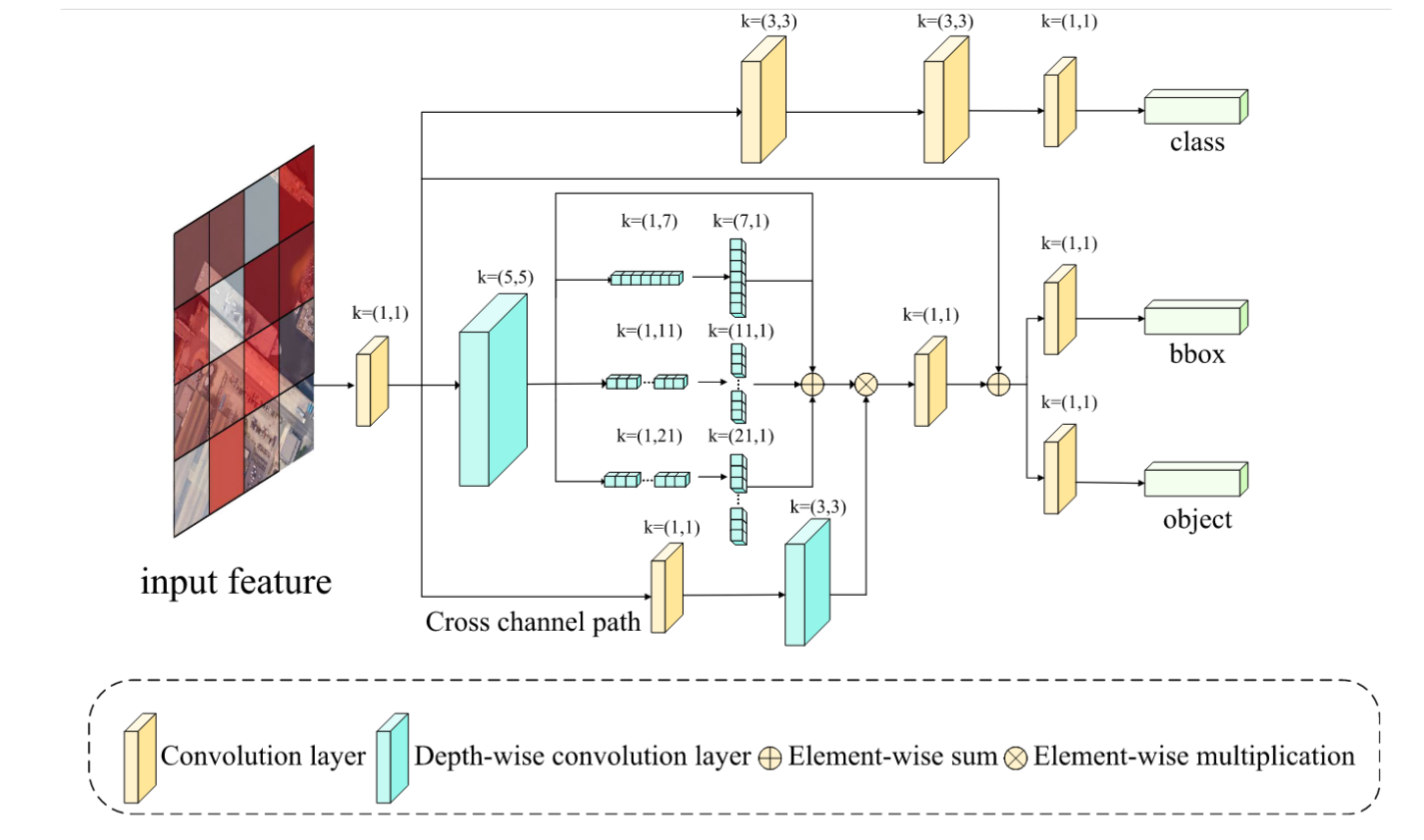
图3. MCB检测头框架。输入特征将由两个独立分支处理:分类分支生成分类结果,定位分支通过大核卷积增强尺度感知能力以获取定位结果,并判断目标物体是否为船舶。
具体而言,MCB的分类分支由两个3×3卷积层和一个1×1卷积层组成,其结构可表示为:
M
C
B
c
l
s
(
Y
)
=
f
c
o
n
v
1
×
1
(
f
c
o
n
v
3
×
3
(
f
c
o
n
v
3
×
3
(
Y
)
)
)
.
\mathrm{MCB}_{\mathrm{cls}}(Y)=f_{\mathrm{conv}}^{1\times1}\left(f_{\mathrm{conv}}^{3\times3}\left(f_{\mathrm{conv}}^{3\times3}(Y)\right)\right).
MCBcls(Y)=fconv1×1(fconv3×3(fconv3×3(Y))).
在定位分支中,MCB首先采用 5 × 5 5×5 5×5深度可分离卷积层对输入特征 Y i Y_i Yi进行局部特征聚合,随后通过三个深度可分离卷积分支来捕获多尺度信息。每个分支由一系列 ( 1 , k ) (1, k) (1,k)和 ( k , 1 ) (k, 1) (k,1)形式的卷积组成 ( k = 7 、 11 、 21 ) (k=7、11、21) (k=7、11、21),以轻量级方式实现 ( k , k ) (k, k) (k,k)卷积效果,同时能有效提取形状类似矩形的舰船特征。
B r a n c h i k ( Y ) = f d w c o n v k × 1 ( f d w c o n v 1 × k ( Y ) ) ( i = 1 , 2 , 3 , k = 7 , 11 , 21 ) ( 9 ) \begin{aligned}\mathrm{Branch}_{i}^{k}(Y)&=f_{\mathrm{dwconv}}^{k\times1}\left(f_{\mathrm{dwconv}}^{1\times k}(Y)\right)\\&(i=1,2,3,k=7,11,21)\quad(9)\end{aligned} Branchik(Y)=fdwconvk×1(fdwconv1×k(Y))(i=1,2,3,k=7,11,21)(9)
其中 B r a n c h i k ( ⋅ ) , i ∈ { 0 , 1 , 2 , 3 } \mathrm{Branch}_{i}^{k}(·), i ∈ \{0, 1, 2, 3\} Branchik(⋅),i∈{0,1,2,3}表示第 i i i个分支, B r a n c h 0 Branch_0 Branch0代表恒等连接。其余三个分支由一系列条纹卷积组成,其形式为 ( 1 , k ) (1, k) (1,k)和 ( k , 1 ) (k, 1) (k,1),其中 k = 7 , 11 , 21 k = 7, 11, 21 k=7,11,21。
与此同时,受[49]启发,通道信息与空间信息分别聚焦于“是什么”和“在哪里”,二者可并行融合。因此, Y i Y_i Yi还经过通道混合处理,包含一个 1 × 1 1×1 1×1卷积层和随后的 3 × 3 3×3 3×3深度可分离卷积层,显式建模通道间的相互依赖关系。随后,通道混合的输出与多尺度分支的输出进行逐元素相乘,在保留通道上下文的同时有效提取空间关系。数学上,MCB中的定位分支可表示为:
M
C
B
i
o
u
(
Y
)
=
f
c
o
n
v
1
×
1
(
Y
+
f
c
o
n
v
1
×
1
(
∑
i
=
0
3
B
r
a
n
c
h
i
k
(
f
d
w
c
o
n
v
5
×
5
(
Y
)
)
)
⊗
f
d
w
c
o
n
v
3
×
3
(
f
c
o
n
v
1
×
1
(
Y
)
)
)
(
10
)
\mathrm{MCB}_{\mathrm{iou}}(Y)=f_{\mathrm{conv}}^{1\times1}\left(Y+f_{\mathrm{conv}}^{1\times1}\left(\sum_{i=0}^{3}\mathrm{Branch}_{i}^{k}\left(f_{\mathrm{dwconv}}^{5\times5}(Y)\right)\right)\otimes f_{\mathrm{dwconv}}^{3\times3}\left(f_{\mathrm{conv}}^{1\times1}(Y)\right)\right)\quad\mathrm{(10)}
MCBiou(Y)=fconv1×1(Y+fconv1×1(i=0∑3Branchik(fdwconv5×5(Y)))⊗fdwconv3×3(fconv1×1(Y)))(10)
其中
M
C
B
i
o
u
(
⋅
)
MCBiou(·)
MCBiou(⋅)表示定位分支,
f
c
o
n
v
1
×
1
(
⋅
)
f_{\mathrm{conv}}^{1\times1}(·)
fconv1×1(⋅)代表逐点卷积,
f
d
w
c
o
n
v
5
×
5
(
⋅
)
f_{\mathrm{dwconv}}^{5\times5}(·)
fdwconv5×5(⋅)是
5
×
5
5×5
5×5深度可分离卷积,
f
c
o
n
v
3
×
3
(
⋅
)
f_{\mathrm{conv}}^{3\times3}(·)
fconv3×3(⋅)为
3
×
3
3×3
3×3卷积,
⨂
\bigotimes
⨂表示逐元素乘法运算。最终经过MCB处理的
1
×
1
1×1
1×1卷积后获得定位结果,该结果与分类分支输出相结合,生成CM-YOLO的最终输出,记为
D
i
∈
R
(
类别
,
x
,
y
,
w
,
h
)
(
i
=
1
,
2
,
.
.
.
)
D_i ∈ \mathbb{R}^{(类别,x,y,w,h)}(i = 1, 2, ...)
Di∈R(类别,x,y,w,h)(i=1,2,...)。
该设计提供了多级感受野,可提升检测性能。通过MCB模块,CM-YOLO能够融合更高级的语义特征,并减少近岸和内陆干扰导致的误报。
D.损失函数
CM-YOLO的损失函数主要由三部分组成:边界框损失、分类损失和置信度损失。其表达式为
L
=
λ
1
L
c
l
s
+
λ
2
L
r
e
g
+
λ
3
L
o
b
j
\mathcal{L}=\lambda_1\mathcal{L}_{\mathrm{cls}}+\lambda_2\mathcal{L}_{\mathrm{reg}}+\lambda_3\mathcal{L}_{\mathrm{obj}}
L=λ1Lcls+λ2Lreg+λ3Lobj
其中 L c l s \mathcal{L}_{cls} Lcls表示分类损失, L r e g \mathcal{L}_{reg} Lreg代表边界框损失, L o b j \mathcal{L}_{obj} Lobj对应置信度损失。权重系数 λ 1 λ_1 λ1、 λ 2 λ_2 λ2和 λ 3 λ_3 λ3分别分配给分类损失、边界框损失和置信度损失。通过实验对比,我们将 λ 1 λ_1 λ1设为1, λ 2 λ_2 λ2设为5, λ 3 λ_3 λ3设为1。
对于
L
r
e
g
\mathcal{L}_{reg}
Lreg,我们采用交并比(IoU)损失来优化预测边界框与真实边界框之间的差异。
L
r
e
g
=
L
I
O
U
=
−
ln
(
∣
A
∩
B
A
∪
B
∣
)
\mathcal{L}_{\mathrm{reg}}=\mathcal{L}_{\mathrm{IOU}}=-\ln\left(\left|\frac{A\cap B}{A\cup B}\right|\right)
Lreg=LIOU=−ln(
A∪BA∩B
)
其中A代表预测边界框,B表示真实标注框。符号 ∩ ∩ ∩和 ∪ ∪ ∪分别表示预测框与真实框的交集区域和并集区域面积。
对于
L
c
l
s
\mathcal{L}_{cls}
Lcls和
L
o
b
j
\mathcal{L}_{obj}
Lobj,我们选用交叉熵损失函数。该函数是多分类任务中常用的评估指标,用于衡量预测结果与真实标签之间的差异。交叉熵损失的计算公式如下:
L
o
b
j
=
1
N
∑
i
L
i
(
13
)
=
1
N
∑
i
=
1
N
−
[
y
i
log
(
p
i
)
+
(
1
−
y
i
)
log
(
1
−
p
i
)
]
\begin{gathered}\mathcal{L}_{\mathrm{obj}}=\frac{1}{N}\sum_i\mathcal{L}_i\begin{pmatrix}13\end{pmatrix}\\=\frac{1}{N}\sum_{i=1}^N-[y_i\log(p_i)+(1-y_i)\log(1-p_i)]\end{gathered}
Lobj=N1i∑Li(13)=N1i=1∑N−[yilog(pi)+(1−yi)log(1−pi)]
L
c
l
s
=
1
N
S
∑
i
L
i
=
−
1
N
S
∑
i
=
1
N
S
∑
c
=
1
K
y
i
c
log
(
p
i
c
)
\mathcal{L}_{\mathrm{cls}}=\frac{1}{N_S}\sum_i\mathcal{L}_i=-\frac{1}{N_S}\sum_{i=1}^{N_S}\sum_{c=1}^Ky_{ic}\log(p_{ic})
Lcls=NS1i∑Li=−NS1i=1∑NSc=1∑Kyiclog(pic)
其中
N
S
N_S
NS为待预测样本总数,
K
K
K为类别总数。在
L
o
b
j
\mathcal{L}_{obj}
Lobj损失函数中,
p
i
p_i
pi表示样本包含物体的概率,
y
i
y_i
yi为样本是否包含物体的真实标签;而在
L
c
l
s
\mathcal{L}_{cls}
Lcls损失函数中,
p
i
p_i
pi代表预测属于某类别的概率,
y
i
y_i
yi表示样本是否属于特定类别的真实标签。
4.实验
A. 数据集与指标
为验证所提方法的有效性,我们使用Seaships7000[50]、HRSC2016[51]、DIOR-ship[52]和ShipRSImageNet[53]数据集开展了大量实验。Seaships7000[50]包含从海岸监控视频中选取的7000帧图像,每张图像分辨率为1920×1080。该数据集由1750张训练集图像、1750张验证集图像和3500张测试集图像组成,共分为六类船舶:散货船、集装箱船、杂货船、通用货船、渔船和客船。Seaships7000通过多角度拍摄、复杂背景及多变天气条件,提供了贴近真实场景的船舶检测环境。
ShipRSImageNet[53]是一个专为舰船检测设计的大规模细粒度遥感光学数据集,包含3435张高分辨率图像,共计17573个舰船实例。该数据集根据粒度将检测任务划分为四个层级:0级仅区分舰船与码头;1级将舰船分为军舰、商船和其他船舶三类;2级和3级则进一步细分为25类和50类。由于ShipRSImageNet尚未公开测试集,我们使用训练集中的2198张图像进行训练,并采用验证集中的550张图像进行测试。
HRSC2016数据集[51]专注于遥感舰船检测,包含1061张航拍图像,尺寸范围从300×300到1500×900不等。该数据集由436张训练图像、181张验证图像和444张测试图像组成。
DIOR[52]是一个面向光学遥感图像目标检测的大规模公开基准数据集,涵盖20个类别。其中DIOR-ship是从“船舶”类别中专门选取的子集,包含650张训练图像、652张验证图像和1400张测试图像。
我们采用以下指标评估模型的性能,包括平均精度(AP)、参数量(Params)、浮点运算次数(FLOPs)和推理时间。AP用于衡量目标检测的准确性,采用COCO标准[54],将IoU阈值分别设定为50%、75%以及50%至95%区间,对应记为mAP50、mAP75和mAP50:95。参数量表示模型参数的总数,FLOPs用于评估计算复杂度,推理时间则用于衡量模型推断速度。
B. 实施细节
本文实验在运行Ubuntu 20.04系统的服务器上进行,硬件配置为AMD EPYC 7543P 32核处理器和24GB内存,显卡采用NVIDIA GeForce RTX 4090 GPU。实验所用框架为PyTorch 1.13.0版本。训练过程中输入尺寸固定为640×640,批量大小设置为4。采用SGD优化器,初始学习率为0.01,学习率更新遵循CosineAnnealing策略[66],动量参数和权重衰减系数分别为0.9和0.0005。所有实验均基于开源目标检测框架mmyolo[67]实现。
C. 与最先进方法的比较
我们将提出的方法与单阶段检测器(包括SSD [56]、YOLOv3 [57]、YOLOv5 [58]、YOLOX [29]、YOLOv9 [59]和YOLOv10 [60])、两阶段检测器(包括Faster R-CNN [16]、Libra R-CNN [55])以及无锚框检测器(如FCOS [61])进行了比较。同时对比的还包括基于Transformer的架构,如DAB-DETR [62]、Deformable DETR [63]、DDQ [64]和DINO [65]。
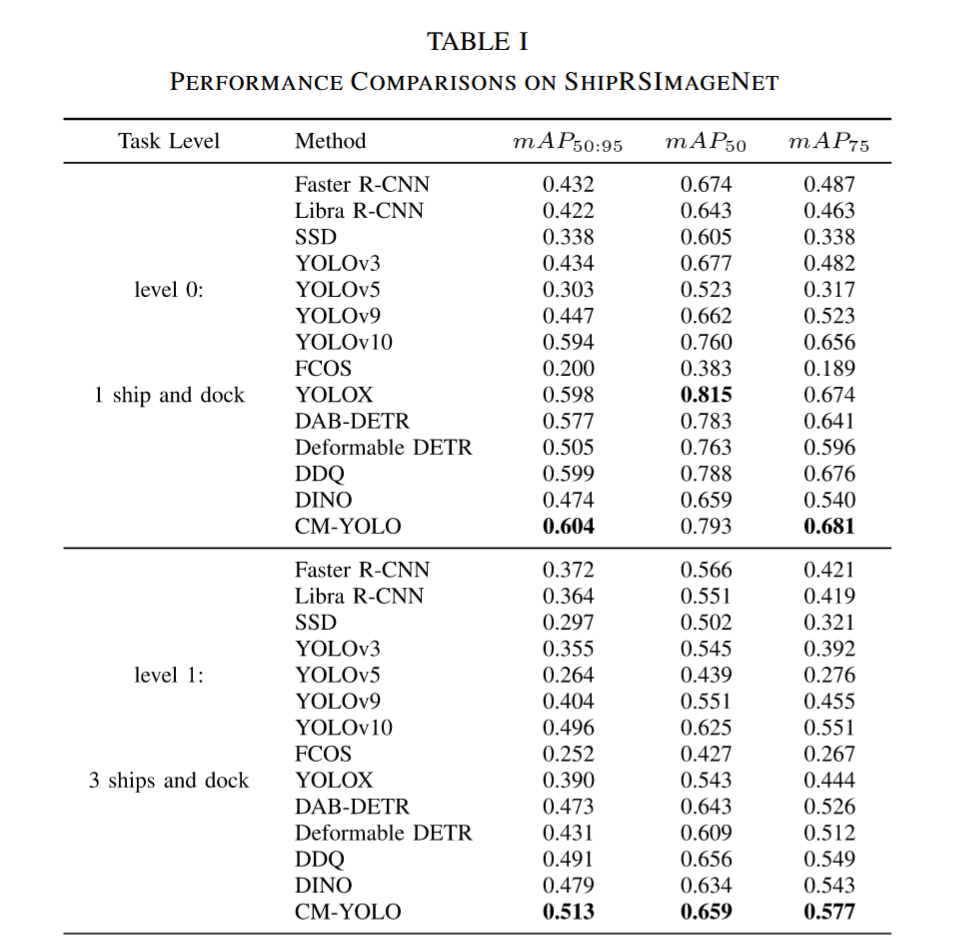
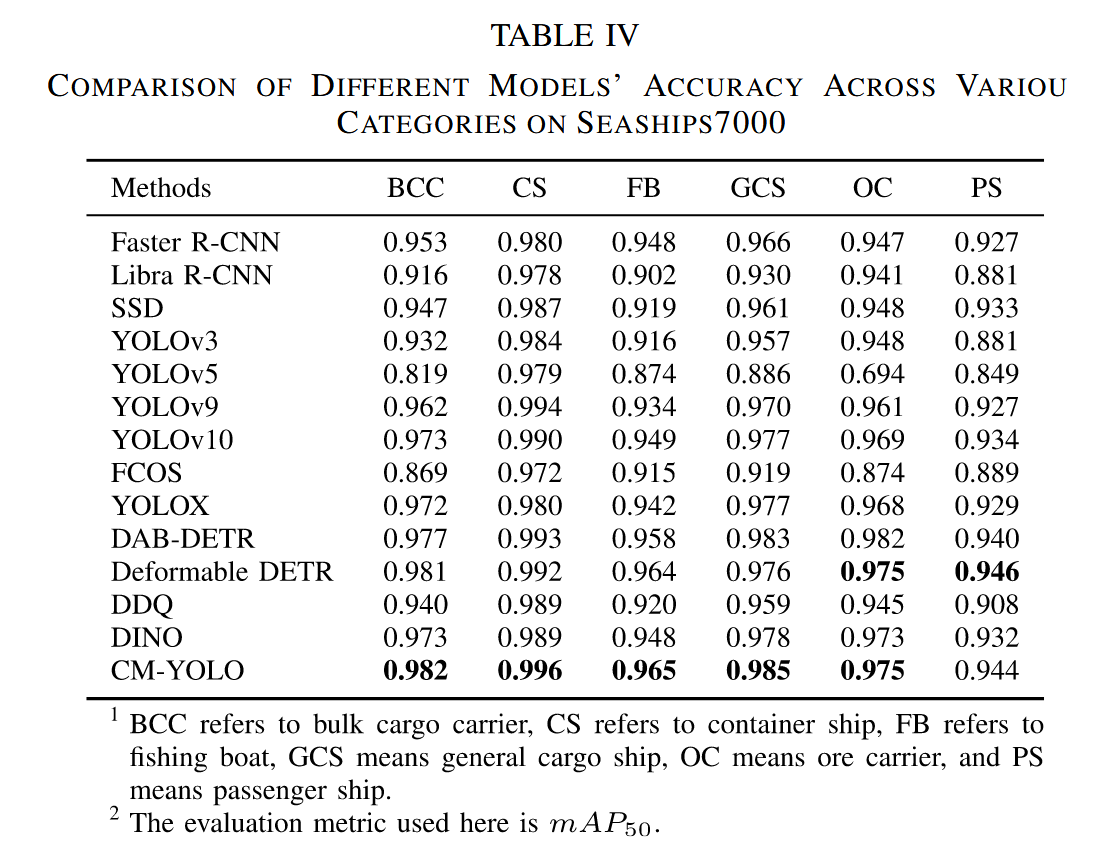
表I展示了不同方法在ShipRSImageNet数据集上的性能对比。值得注意的是,CM-YOLO在四个难度层级上分别取得了60.4%、51.3%、51.5%和60.2%的mAP50:95指标,且在前三个层级均超越所有对比模型,满足复杂场景下的船舶检测需求。特别在层级1中,CM-YOLO以2.2%的优势领先第二名的DDQ模型,相较于两阶段方法Faster R-CNN的优势更达到14.1%。这些结果表明,CM-YOLO在船舶检测任务中展现出优于大型模型的性能。这一优势可能源于Faster R-CNN和Libra R-CNN的局限性——它们的RPN模块容易产生过多与背景相关的冗余候选框,从而影响检测精度。而基于Transformer的方法如DINO和DAB-DETR倾向于建模全局特征,削弱了对船舶目标细粒度局部特征的捕捉能力,导致中小型船舶的检测性能欠佳。总体而言,在大多数场景下,CM-YOLO展现出强劲的竞争力:在检测精度和模型体积方面均优于DAB-DETR、DINO等Transformer方法,相较YOLOv10、YOLOX等CNN方法也具有显著优势。
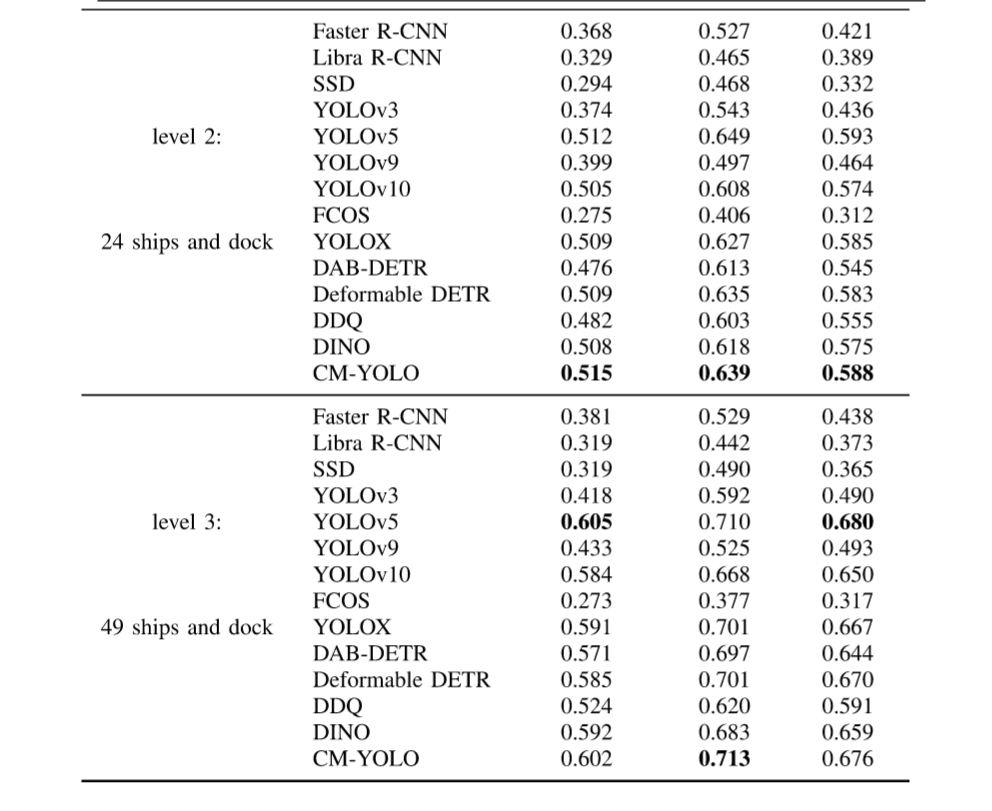
表II展示了HRSC2016数据集的实验结果。该模型在mAP50:95、mAP75和mAP50指标上分别达到61.5%、91.4%和72.5%,超越了所有其他模型。具体而言,在mAP50:95指标上,CM-YOLO以61.5%的表现优于第二名YOLOv5的60.4%(领先1.1%),并大幅超越当前最先进的YOLOv10模型(58.4%)3.1%。虽然YOLOv10同样对最低分辨率特征应用了部分自注意力机制来提取上下文信息,但由于其仅提取部分特征,难以适应复杂环境下的船舶检测任务。此外,本方法的检测头相比YOLO系列具有更强大的尺度感知能力。尽管DDQ在mAP50指标上仅落后CM-YOLO 0.6%,但CM-YOLO在mAP75和mAP50:95指标上分别领先DDQ达12.2%和6.7%。这表明CM-YOLO能够在更严格的IoU阈值下实现更精确的船舶定位,而非仅依赖粗略的边界框重叠。此外,在HRSC2016这类小规模数据集上,CM-YOLO相比大型模型展现出更好的收敛性,进一步凸显了其在资源受限场景下的适应性和鲁棒性。
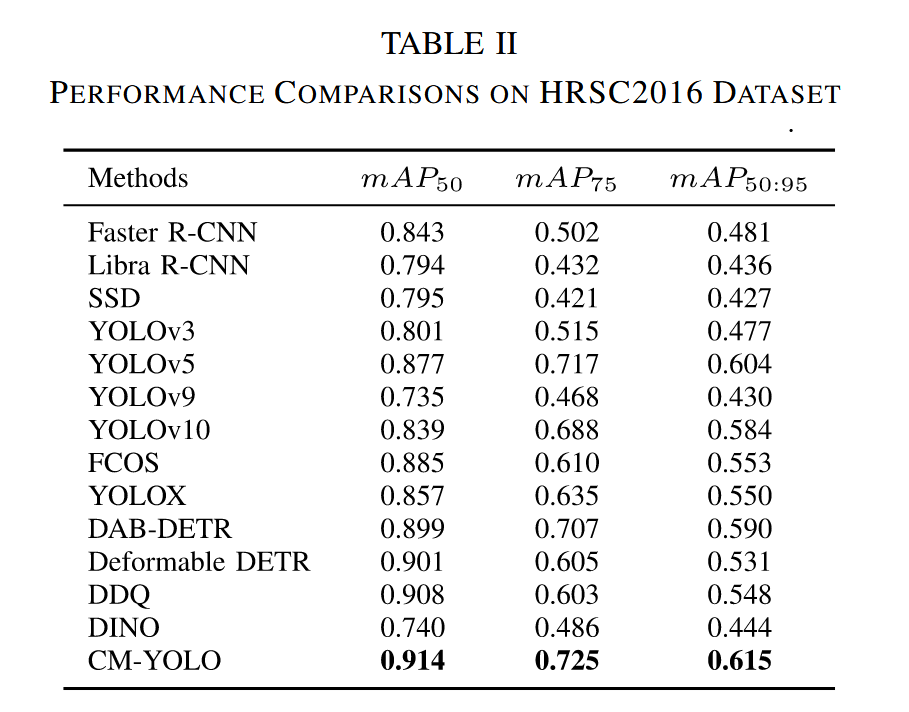
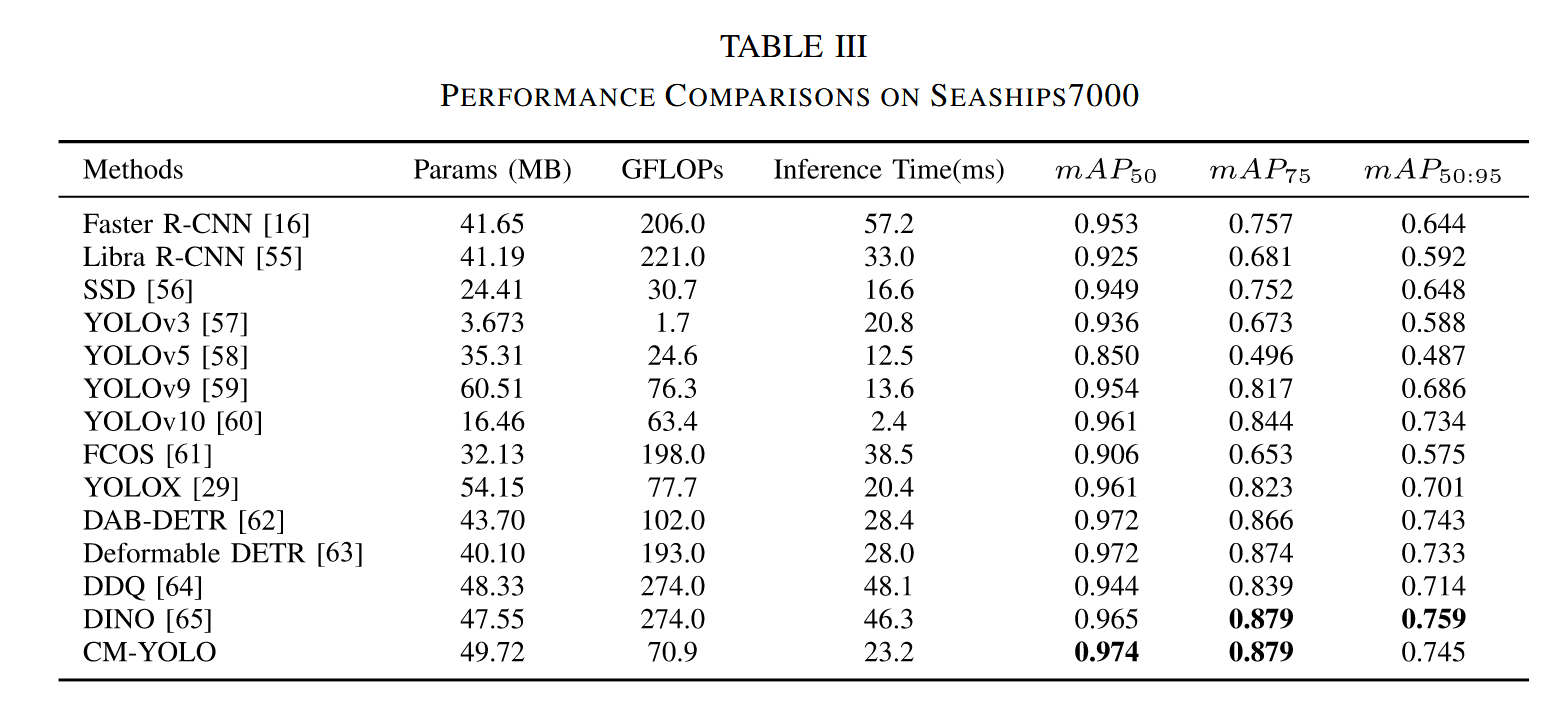
Seaships7000数据集上的详细实验结果如表III所示,最佳结果已用加粗标出。如表III所示,我们提出的方法以97.4%的mAP50和87.9%的mAP75取得最高分,较基线提升4.4%,这归功于DCE和MCB模块能捕获多层级和长距离语义信息,使其更适配Seaships7000中的多层级船舶目标。表IV展示了不同模型在Seaships7000各船舶类别上的检测结果,CM-YOLO在全部六类船舶上的检测准确率均超过94%。数据同时显示DAB-DETR、Deformable DETR和DDQ的FLOPs均超过100G,推理时长超过28毫秒。其中DDQ达到227 GFLOPs和48.1毫秒的推理时长,分别是CM-YOLO的三倍和两倍,表明这三个模型具有足够复杂的架构和强大的学习能力。此外,三者的mAP50:95指标分别为74.3%、73.3%和71.4%,均超过71%。得益于YOLO架构与DCE强大远程建模能力的结合,虽然CM-YOLO在精度上未展现显著优势——仅比表现最佳的DAB-DETR高出0.2%,但展现出明显的资源节约和部署优势,更符合实时性要求。
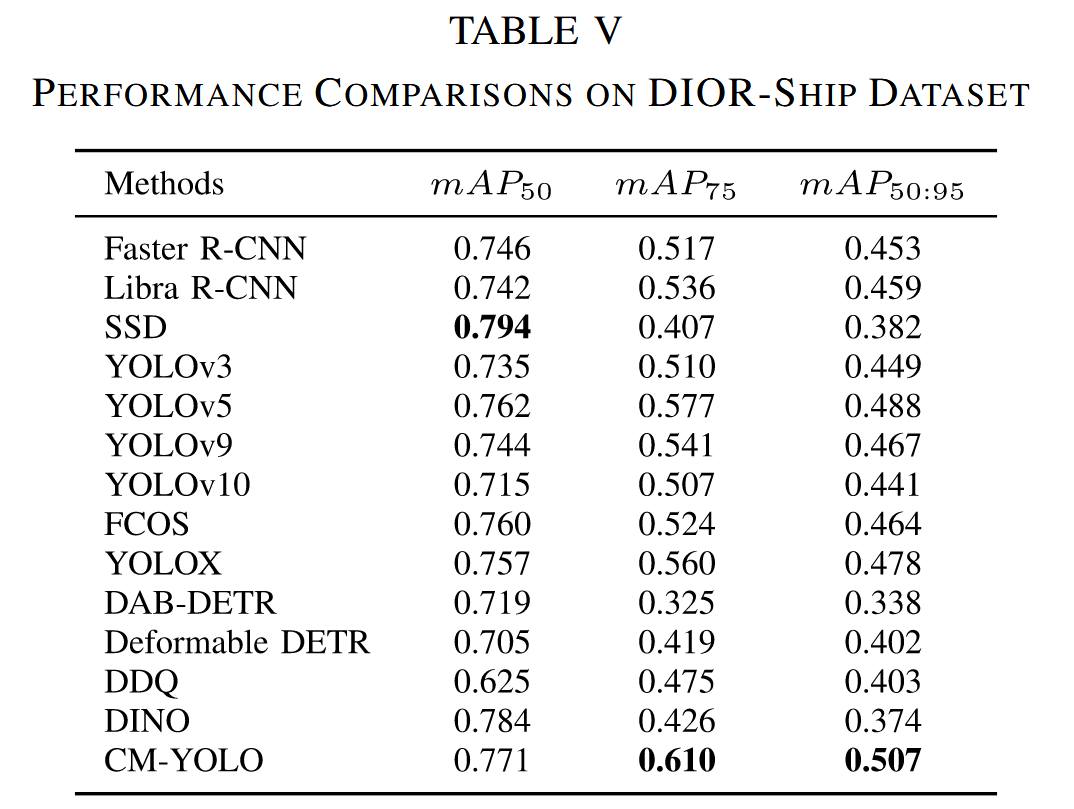
表V展示了在DIOR-ship数据集上的对比结果,该数据集是从大规模遥感数据集DIOR中分离出的舰船类别独立子集。DIOR-ship有效验证了CM-YOLO在更复杂环境下舰船检测的泛化能力。虽然DINO(78.4%)和DAB-DETR(71.9%)在mAP50指标上与CM-YOLO表现相当,但CM-YOLO(50.7%)在mAP50:95指标上分别以13.3%和16.9%的显著优势超越二者。这些结果表明,CM-YOLO在小规模数据集上展现出更强的适应性和泛化能力,使其更适用于复杂环境下的舰船检测任务。
我们探究了损失函数中系数的设置,具体结果可见表VI。共考虑了七种常用权重系数配置,包括默认设置(第一行)、增强分类损失(第二行)、增强边界框损失(第三行)、增强置信度损失(第四行)、减弱分类损失(第五行)、减弱边界框损失(第六行)以及减弱置信度损失(第七行)。实验表明,采用第三行的边界框损失、分类损失和置信度损失权重配置时检测性能最佳。因此,我们最终设定 λ 1 λ_1 λ1为1、 λ 2 λ_2 λ2为5、 λ 3 λ_3 λ3为1。

为进一步展示本方法相较于现有技术的优势,我们在Seaships7000和ShipRSImageNet数据集上分别进行了可视化对比实验,结果如图4和图5所示。
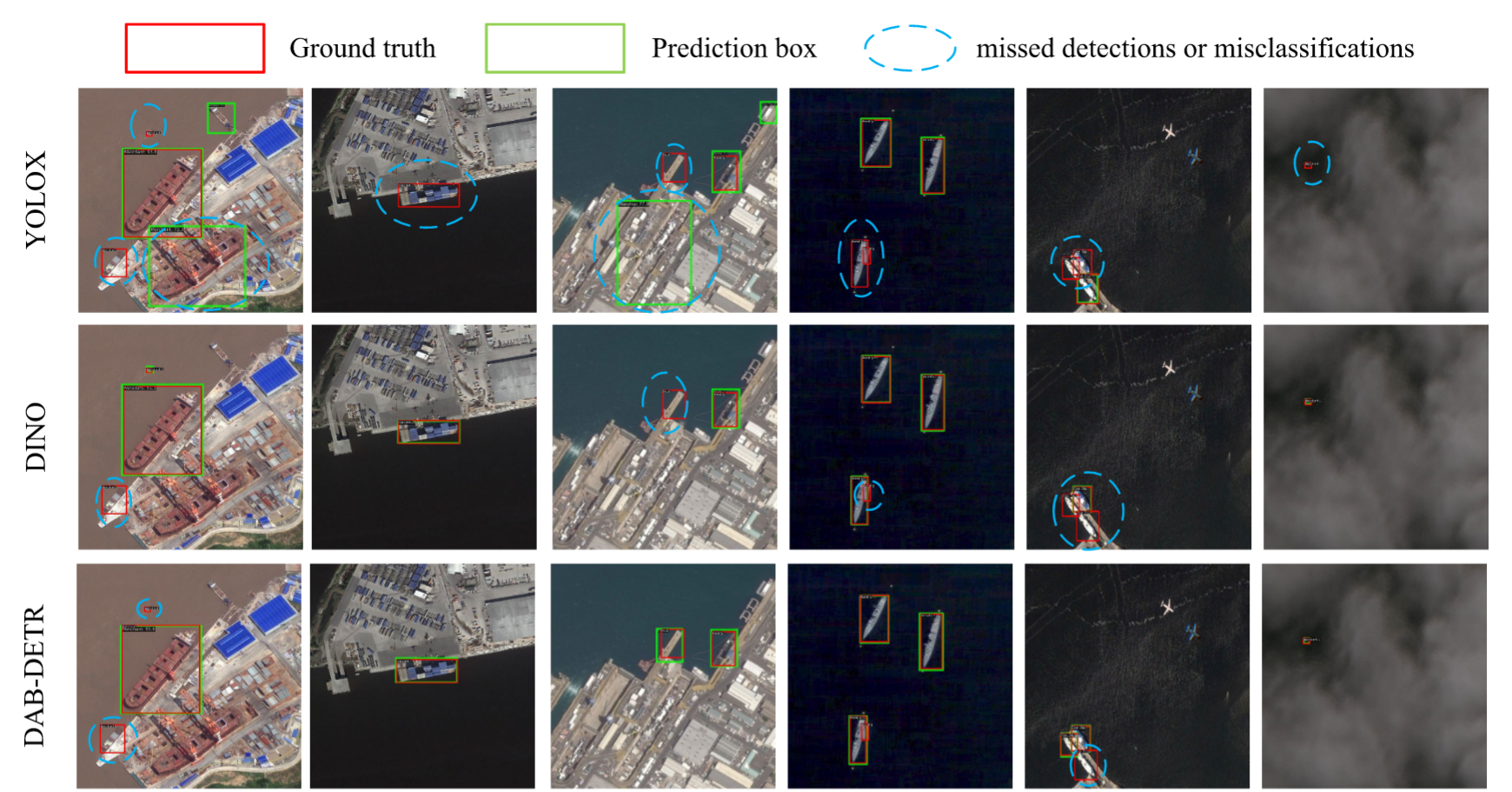

图4. ShipRSImageNet验证集一级难度的定性对比结果。红色边界框代表真实标注框,绿色边界框表示预测框,蓝色曲线框则用于突出漏检和误检目标。此处我们设定阈值为0.5以过滤低置信度的预测边界框。


图5. 不同船舶检测方法在Seaships7000数据集上的检测结果。红色边界框表示真实标注框,绿色边界框表示预测框,蓝色曲线框则用于突出漏检和误检情况。
为比较各类船舶检测算法的性能,我们可视化了几种主流算法的检测结果并评估其漏检率与误检率。通过对比凸显了本文提出的CM-YOLO算法的优势。我们从数据集中随机选取六种典型场景的检测结果,涵盖近岸区域、夜间环境、雾天等复杂背景。可以看出在第一、四、五列中,YOLOX不仅漏检了小型船舶,还在第一和第三列中将近岸背景误判为船舶;第四列图像中DINO仅检测出三艘聚集船舶中的一艘,SSD漏检一艘,YOLOv5则完全未检出。图4展示了CM-YOLO在ShipRSImageNet数据集上的检测效果,表明该算法在遥感船舶数据集中保持竞争力。在浓雾、夜间及各类复杂背景干扰条件下,CM-YOLO相较基线模型显著降低了漏检数量。
图5展示了在Seaships7000数据集上的检测结果。如图5所示,除CM-YOLO外,YOLOX、DINO、DAB-DETR、SSD和YOLOv5在船舶被遮挡或处于不利朝向时均无法有效检测。具体而言:第一列中两艘船舶并行航行时,YOLOX、DINO、DAB-DETR、SSD和YOLOv5都仅检测到后方的通用货船,而漏检了前方的散货船;第二列五艘由远及近的船舶场景中,除CM-YOLO外所有方法都漏检了1-4艘船舶;第三列当前船遮挡后船时,YOLOX和DINO仅检测到前船,SSD和YOLOv5同时漏检两船,而DAB-DETR与CM-YOLO虽然后船检测框存在偏移,但正确识别出双船场景并完成分类;第四列夜间场景表明YOLOX和YOLOv5在暗光条件下性能较差,缺乏鲁棒性。相比之下,CM-YOLO展现出对环境变化的适应能力,在这三种场景中均表现出色。
为进一步验证CM-YOLO的有效性,我们在ShipRSImageNet数据集上对本方法的Grad-CAM热力图进行了可视化。该热力图通过颜色深浅(红色越深表示关注度越高)直观展示图像各区域对预测结果的贡献程度。如图6所示代表性结果充分证明:CM-YOLO能准确识别并定位船舶目标。观察可见,相较于基线模型,CM-YOLO更聚焦于待检测船舶区域,同时对非船舶区域的无关环境信息关注度显著降低。此外,该方法能精准区分特征相似的船舶与近岸干扰物,并有效抑制对背景区域的注意力。

图6. YOLOX与CM-YOLO的Grad-CAM[68]可视化结果对比。如图所示,CM-YOLO能基于上下文信息准确区分目标区域是船舶还是背景。
D.消融实验
为分析CM-YOLO中各组件的贡献,我们在基线模型上逐步引入MCB和DCE模块以验证其有效性。实验选用YOLOX作为基线模型,测试各模块对检测精度的提升效果。消融实验在Seaships7000数据集上进行,表VII展示了各模块增减对评估指标的影响。
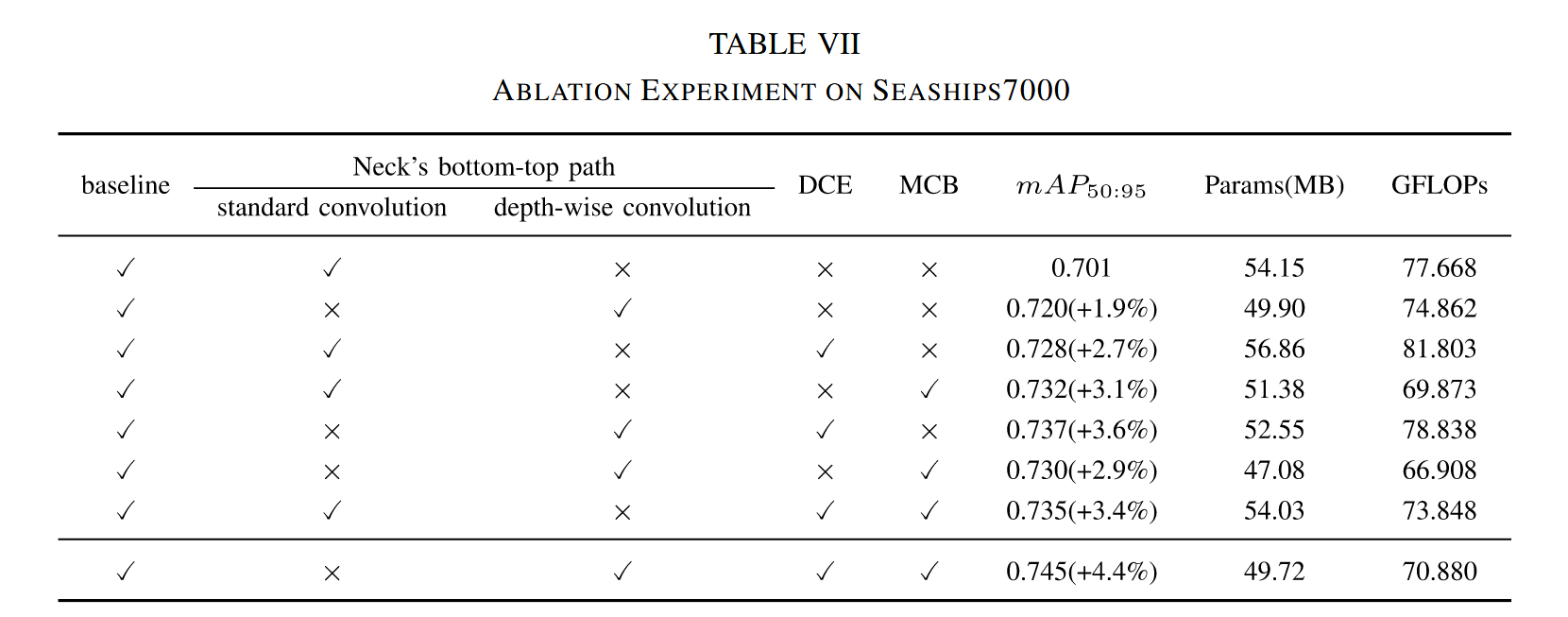
- DCE:如表VII所示,引入DCE显著提升了模型的检测精度,mAP50:95从70.1%提升至72.8%,增幅达2.7%。这表明DCE能有效利用船舶的上下文信息,帮助模型更好地识别船舶。但引入DCE也导致参数量增加2.71M、计算量增加4.135G。为提升模型效率并降低部署难度,我们将颈部自上而下路径中的标准卷积替换为深度可分离卷积。该改动能在保持低维特征的同时学习更多高维特征,确保语义信息在传递过程中得以保留。实验表明,同时引入DCE和深度可分离卷积可使mAP50:95提升3.6%,参数量减少1.6M。
2)MCB模块:当将MCB模块与原始检测头对比时,准确率从70.1%提升至73.2%,增幅达3.1%。该模块通过提供多层级感受野,有效提升了不同尺寸船舶的检测精度。MCB在利用大核卷积丰富检测头上下文信息的同时,由于采用大核深度可分离卷积,参数量减少2.77M,计算量降低7.795G,实现了精度提升。在基线模型中同时加入MCB和DCE模块时,mAP50:95指标提升3.4%,且未增加模型参数量与复杂度,充分证明了我们提出模块的有效性。
5.结论
本文提出了一种新颖的端到端船舶检测方法CM-YOLO。针对复杂场景下船舶检测效果不佳的挑战,我们提出了集成新型DCE和MCB模块的DCEN结构。在DCEN中,DCE模块用于在多尺度特征融合前,从最低分辨率特征中提取全局上下文信息。该模块能够捕获空间和通道维度的长程依赖关系,在消除无关背景噪声的同时保留最显著的特征。在检测头部分,MCB模块可有效提取多尺度信息,增强检测头在复杂环境中对船舶尺寸的感知能力。得益于这两个模块,CM-YOLO具备强大的特征表征能力,在复杂背景下仍保持鲁棒性。在Seaships7000、ShipRSImageNet、DIOR-ship和HRSC2016数据集上的大量实验表明,本方法取得了优异的性能表现。
尽管CM-YOLO能够利用场景中的上下文信息更好地检测船舶,但如图7所示,在处理外观相似的船舶(如军舰和商船)时,我们的方法仍难以准确识别正确的船舶类别。因此,在未来的研究中,我们可以通过增强方法学习船舶类别的细粒度表征,进一步提升船舶检测性能。此外,CM-YOLO采用全监督训练方式,当出现新的船舶类别时,模型需要重新训练,这限制了该方法在实际场景中的应用。为解决这一问题,未来我们将把方法扩展至开放世界或开放词汇检测范式,以增强模型的泛化能力。
6.引用文献
- [1] K. Jin, Y. Chen, B. Xu, J. Yin, X. Wang, and J. Yang, “A patchto-pixel convolutional neural network for small ship detection with PolSAR images,” IEEE Trans. Geosci. Remote Sens., vol. 58, no. 9, pp. 6623–6638, Sep. 2020.
- [2] X. Leng, K. Ji, S. Zhou, and X. Xing, “Ship detection based on complex signal kurtosis in single-channel SAR imagery,” IEEE Trans. Geosci. Remote Sens., vol. 57, no. 9, pp. 6447–6461, Sep. 2019.
- [3] S. Chen, X. Cui, X. Wang, and S. Xiao, “Speckle-free SAR image ship detection,” IEEE Trans. Image Process., vol. 30, pp. 5969–5983, 2021.
- [4] B. Li, X. Xie, X. Wei, and W. Tang, “Ship detection and classification from optical remote sensing images: A survey,” Chin. J. Aeronaut., vol. 34, no. 3, pp. 145–163, Mar. 2021.
- [5] M. Yasir et al., “Ship detection based on deep learning using SAR imagery: A systematic literature review,” Soft Comput., vol. 27, no. 1, pp. 63–84, Jan. 2023.
- [6] J. Li, C. Xu, H. Su, L. Gao, and T. Wang, “Deep learning for SAR ship detection: Past, present and future,” Remote Sens., vol. 14, no. 11, p. 2712, Jun. 2022.
- [7] R. W. Liu, W. Yuan, X. Chen, and Y. Lu, “An enhanced CNN-enabled learning method for promoting ship detection in maritime surveillance system,” Ocean Eng., vol. 235, Sep. 2021, Art. no. 109435.
- [8] L. Min, Z. Fan, S. Wang, F. Dou, X. Li, and B. Wang, “Adaptive fusion learning for compositional zero-shot recognition,” IEEE Trans. Multimedia, early access, Dec. 25, 2024, doi: 10.1109/TMM.2024.3521852.
- [9] Z. Cui, X. Wang, N. Liu, Z. Cao, and J. Yang, “Ship detection in largescale SAR images via spatial shuffle-group enhance attention,” IEEE Trans. Geosci. Remote Sens., vol. 59, no. 1, pp. 379–391, Jan. 2020.
- [10] Q. Hu, S. Hu, and S. Liu, “BANet: A balance attention network for anchor-free ship detection in SAR images,” IEEE Trans. Geosci. Remote Sens., vol. 60, 2022, Art. no. 5222212.
- [11] D. Pan et al., “SRT-net: Scattering region topology network for oriented ship detection in large-scale SAR images,” IEEE Trans. Geosci. Remote Sens., vol. 62, 2024, Art. no. 5202318.
- [12] X. Yang, X. Zhang, and N. Wang, “A robust one-stage detector for multiscale ship detection with complex background in massive SAR images,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–12, 2021.
- [13] Y. Yu, X. Yang, J. Li, and X. Gao, “A cascade rotated anchor-aided detector for ship detection in remote sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 60, 2022, Art. no. 5600514.
- [14] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár, “Focal loss for dense object detection,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2017, pp. 2980–2988.
- [15] D. Li, Q. Liang, H. Liu, Q. Liu, H. Liu, and G. Liao, “A novel multidimensional domain deep learning network for SAR ship detection,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–13, 2021.
- [16] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards realtime object detection with region proposal networks,” in Proc. Adv. Neural Inf. Process. Syst., vol. 28, Dec. 2015, pp. 91–99.
- [17] B. Wang, Y. Zhao, and X. Li, “Multiple instance graph learning for weakly supervised remote sensing object detection,” IEEE Trans. Geosci. Remote Sens., vol. 60, 2022, Art. no. 5613112.
- [18] S. Wang, T. Zhou, Y. Lu, and H. Di, “Contextual transformation network for lightweight remote-sensing image super-resolution,” IEEE Trans. Geosci. Remote Sens., vol. 60, 2022, Art. no. 5615313.
- [19] B. Wang, Y. Zhao, L. Yang, T. Long, and X. Li, “Temporal action localization in the deep learning era: A survey,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 4, pp. 2171–2190, Apr. 2024.
- [20] J. Hao et al., “Scale-aware backprojection transformer for single remote sensing image super-resolution,” IEEE Trans. Geosci. Remote Sens., vol. 62, 2024, Art. no. 5649013.
- [21] B. Wang et al., “BEVRefiner: Improving 3D object detection in bird’seye-view via dual refinement,” IEEE Trans. Intell. Transp. Syst., vol. 25, no. 10, pp. 15094–15105, Oct. 2024.
- [22] L. Min, Z. Fan, Q. Lv, M. Reda, L. Shen, and B. Wang, “YOLO-DCTI: Small object detection in remote sensing base on contextual transformer enhancement,” Remote Sens., vol. 15, no. 16, p. 3970, Aug. 2023.
- [23] Q. Hou, C.-Z. Lu, M.-M. Cheng, and J. Feng, “Conv2Former: A simple transformer-style ConvNet for visual recognition,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 12, pp. 8274–8283, Dec. 2024.
- [24] X. Li, W. Wang, X. Hu, and J. Yang, “Selective kernel networks,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 510–519.
- [25] Z. Liu, H. Mao, C.-Y. Wu, C. Feichtenhofer, T. Darrell, and S. Xie, “A ConvNet for the 2020s,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2022, pp. 11976–11986.
- [26] Y. Li, Q. Hou, Z. Zheng, M.-M. Cheng, J. Yang, and X. Li, “Large selective kernel network for remote sensing object detection,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Oct. 2023, pp. 16794–16805.
- [27] X. Ding, X. Zhang, J. Han, and G. Ding, “Scaling up your kernels to 31×31: Revisiting large kernel design in CNNs,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2022, pp. 11963–11975.
- [28] J. Wang, Y. Lu, S. Wang, B. Wang, X. Wang, and T. Long, “Two-stage spatial-frequency joint learning for large-factor remote sensing image super-resolution,” IEEE Trans. Geosci. Remote Sens., vol. 62, 2024, Art. no. 5606813.
- [29] Z. Ge, S. Liu, F. Wang, Z. Li, and J. Sun, “YOLOX: Exceeding YOLO series in 2021,” 2021, arXiv:2107.08430.
- [30] H. Zhang and Y. Wu, “CSEF-net: Cross-scale SAR ship detection network based on efficient receptive field and enhanced hierarchical fusion,” Remote Sens., vol. 16, no. 4, p. 622, Feb. 2024.
- [31] Z. Ren, Y. Tang, Y. Yang, and W. Zhang, “SASOD: Saliency-aware ship object detection in high-resolution optical images,” IEEE Trans. Geosci. Remote Sens., vol. 62, 2024, Art. no. 5611115.
- [32] X. Fan, Z. Hu, Y. Zhao, J. Chen, T. Wei, and Z. Huang, “A small-ship object detection method for satellite remote sensing data,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 17, pp. 11886–11898, 2024.
- [33] H. Lin et al., “DCEA: DETR with concentrated deformable attention for end-to-end ship detection in SAR images,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 17, pp. 17292–17307, 2024.
- [34] J. Shen, L. Bai, Y. Zhang, M. Chowdhuray Momi, S. Quan, and Z. Ye, “ELLK-net: An efficient lightweight large kernel network for SAR ship detection,” IEEE Trans. Geosci. Remote Sens., vol. 62, 2024, Art. no. 5221514.
- [35] X. Tang, J. Zhang, Y. Xia, and H. Xiao, “DBW-YOLO: A high-precision SAR ship detection method for complex environments,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 17, pp. 7029–7039, 2024.
- [36] Y. Hao and Y. Zhang, “A lightweight convolutional neural network for ship target detection in SAR images,” IEEE Trans. Aerosp. Electron. Syst., vol. 60, no. 2, pp. 1882–1898, Apr. 2024.
- [37] H. Tang et al., “A lightweight SAR image ship detection method based on improved convolution and YOLOv7,” Remote Sens., vol. 16, no. 3, p. 486, Jan. 2024.
- [38] Y. Yin, X. Cheng, F. Shi, X. Liu, H. Huo, and S. Chen, “Highorder spatial interactions enhanced lightweight model for optical remote sensing image-based small ship detection,” IEEE Trans. Geosci. Remote Sens., vol. 62, 2024, Art. no. 4201416.
- [39] Z. Chen, C. Liu, V. Filaretov, and D. Yukhimets, “Multi-scale ship detection algorithm based on YOLOV7 for complex scene SAR images,” Remote Sens., vol. 15, no. 8, p. 2071, Apr. 2023.
- [40] L. Ying, D. Miao, and Z. Zhang, “3WM-AugNet: A feature augmentation network for remote sensing ship detection based on three-way decisions and multigranularity,” IEEE Trans. Geosci. Remote Sens., vol. 61, 2023, Art. no. 1001219.
- [41] Y. Bazi, L. Bashmal, M. M. A. Rahhal, R. A. Dayil, and N. A. Ajlan, “Vision transformers for remote sensing image classification,” Remote Sens., vol. 13, no. 3, p. 516, Feb. 2021.
- [42] P. Deng, K. Xu, and H. Huang, “When CNNs meet vision transformer: A joint framework for remote sensing scene classification,” IEEE Geosci. Remote Sens. Lett., vol. 19, pp. 1–5, 2022.
- [43] M. Maaz et al., “EdgeNEXt: Efficiently amalgamated CNN-transformer architecture for mobile vision applications,” in Proc. Eur. Conf. Comput. Vis. Cham, Switzerland: Springer, Oct. 2022, pp. 3–20.
- [44] C. Peng, X. Zhang, G. Yu, G. Luo, and J. Sun, “Large kernel matters—Improve semantic segmentation by global convolutional network,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 4353–4361.
- [45] R. Azad et al., “Beyond self-attention: Deformable large kernel attention for medical image segmentation,” in Proc. IEEE/CVF Winter Conf. Appl. Comput. Vis. (WACV), Jan. 2024, pp. 1287–1297.
- [46] M. H. Guo, C. Z. Lu, Z. N. Liu, M. M. Cheng, and S. M. Hu, “Visual attention network,” Comp. Vis. Media, vol. 9, no. 4, pp. 733–752, Jul. 2023.
- [47] K. W. Lau, L.-M. Po, and Y. A. U. Rehman, “Large separable kernel attention: Rethinking the large kernel attention design in CNN,” Expert Syst. Appl., vol. 236, Feb. 2024, Art. no. 121352.
- [48] S. Liu, L. Qi, H. Qin, J. Shi, and J. Jia, “Path aggregation network for instance segmentation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 8759–8768.
- [49] S. Woo, J. Park, J.-Y. Lee, and I. S. Kweon, “CBAM: Convolutional block attention module,” in Proc. Eur. Conf. Comput. Vis., Sep. 2018, pp. 3–19.
- [50] Z. Shao, W. Wu, Z. Wang, W. Du, and C. Li, “SeaShips: A large-scale precisely annotated dataset for ship detection,” IEEE Trans. Multimedia, vol. 20, no. 10, pp. 2593–2604, Oct. 2018.
- [51] Z. Liu, L. Yuan, L. Weng, and Y. Yang, “A high resolution optical satellite image dataset for ship recognition and some new baselines,” in Proc. Int. Conf. Pattern Recognit. Appl. Methods, vol. 2, 2017, pp. 324–331.
- [52] K. Li, G. Wan, G. Cheng, L. Meng, and J. Han, “Object detection in optical remote sensing images: A survey and a new benchmark,” ISPRS J. Photogramm. Remote Sens., vol. 159, pp. 296–307, Jan. 2020.
- [53] Z. Zhang, L. Zhang, Y. Wang, P. Feng, and R. He, “ShipRSImageNet: A large-scale fine-grained dataset for ship detection in high-resolution optical remote sensing images,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 14, pp. 8458–8472, 2021.
- [54] T. Lin et al., “Microsoft COCO: Common objects in context,” in Proc. Eur. Conf. Comput. Vis., Zurich, Switzerland. Cham, Switzerland: Springer, 2014, pp. 740–755.
- [55] J. Pang, K. Chen, J. Shi, H. Feng, W. Ouyang, and D. Lin, “Libra R-CNN: Towards balanced learning for object detection,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 821–830.
- [56] W. Liu et al., “SSD: Single shot multibox detector,” in Proc. 14th Eur. Conf. Comput. Vis., Amsterdam, The Netherlands. Cham, Switzerland: Springer, Oct. 2016, pp. 21–37.
- [57] J. Redmon and A. Farhadi, “YOLOv3: An incremental improvement,” 2018, arXiv:1804.02767.
- [58] G. Jocher et al., “Ultralytics/YOLOv5: V6.0—YOLOv5n ‘nano’ models, roboflow integration, TensorFlow export, OpenCV DNN support,” Tech. Rep., Oct. 2021, doi: 10.5281/zenodo.5563715.
- [59] C.-Y. Wang, I.-H. Yeh, and H.-Y. M. Liao, “YOLOv9: Learning what you want to learn using programmable gradient information,” 2024, arXiv:2402.13616.
- [60] A. Wang et al., “YOLOv10: Real-time end-to-end object detection,” 2024, arXiv:2405.14458.
- [61] Z. Tian, C. Shen, H. Chen, and T. He, “FCOS: A simple and strong anchor-free object detector,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 4, pp. 1922–1933, Apr. 2020.
- [62] S. Liu et al., “DAB-DETR: Dynamic anchor boxes are better queries for DETR,” 2022, arXiv:2201.12329.
- [63] X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable DETR: Deformable transformers for end-to-end object detection,” 2020, arXiv:2010.04159.
- [64] S. Zhang et al., “Dense distinct query for end-to-end object detection,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2023, pp. 7329–7338.
- [65] H. Zhang et al., “DINO: DETR with improved DeNoising anchor boxes for end-to-end object detection,” in Proc. 11th Int. Conf. Learn. Represent., Jan. 2022, pp. 1–11.
- [66] I. Loshchilov and F. Hutter, “SGDR: Stochastic gradient descent with warm restarts,” 2016, arXiv:1608.03983.
- [67] M. Contributors. (2022). MMYOLO: OpenMMLab YOLO Series Toolbox and Benchmark. [Online]. Available: https://github.com/openmmlab/mmyolo
- [68] R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-CAM: Visual explanations from deep networks via gradient-based localization,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2017, pp. 618–626.