Swin Transformer(Swin-T)
目录
引言
整体框架
移位窗口
模型变体
代码实现
Transformer是Microsoft Research Asia在2021年的论文
《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》中提出的。这是一个层级式的Transformer,且通过移动窗口实现全局注意力,使得Transformer可以像卷积神经网络一样,可以实现层级式的多尺度的特征提取,代替CNN,成为计算机视觉的通用骨干。
引言
因为本身Transformer的提出是用于NLP模型,要想实现在视觉上的应用会带来两个挑战:视觉实体的尺度十分不同(在照片中近大远小,房屋比人的尺寸大);还有像素很高的图像,转为序列是很长的,如果要套用transformer的话,就需要切片。而Swin Transformer的解决思想是用移动窗口的方式,实现在小窗口内进行transformer,而且相邻窗口有交互,构建分层特征映射,实现了全局的尺度。Swin Transformer的Swin就是Shifted windows(移动窗口)。下图就与Vision Transform(ViT)的对比。
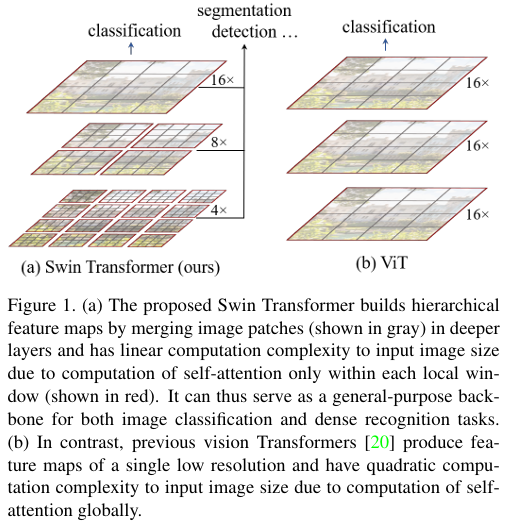
ViT虽然可以实现全局自注意力,但是对于多尺度就相对弱了,原因是在对图像进行16x16的分割为图像块时,大尺度图片的图像块序列还是很长,计算复杂度很大。不像ViT一样对于整图计算自注意力,SwinT吸取了卷积网络的特性,在小的窗口(红色框)内计算自注意力。每个窗口的patch(灰色小框)是固定的,小窗口的计算复杂度是固定的,因此整个图的计算复杂度是根据图的尺寸线性变化。而ViT则是平方变化的。层级式特征则是通过patch merge实现,小patch合并为大的patch。
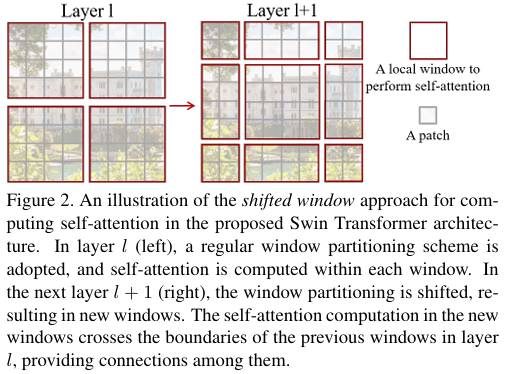
SwinT设计的关键是在连续的自注意力层之间的窗口移动,如图2所示。前一层与后一层的窗口有重叠,整体移动了两个patch,增加了交互,增强了模型的建模能力。SwinT在图像分类、目标检测和语义分割任务上都取得较好的性能。
整体框架
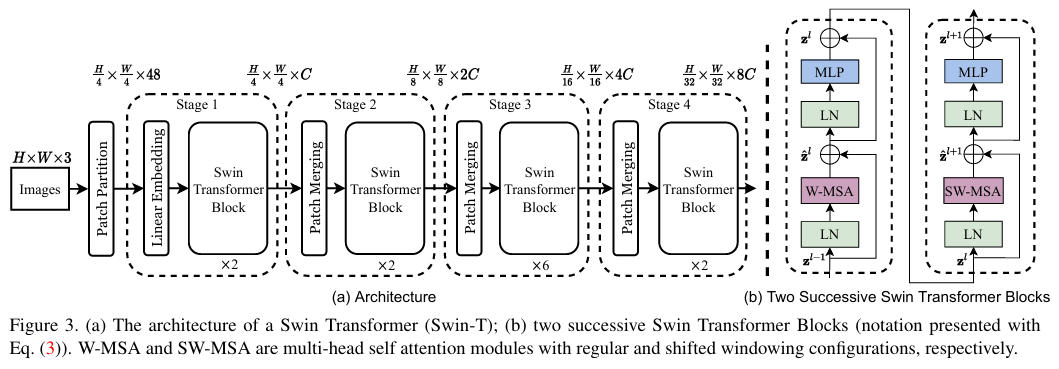
图3(a)所示的流程图,首先将图片切割patch,每个patch为4*4作为一个token, 例如224*224*3切割完成后为56*56*48(48=4*4*3),就是有56*56个token,每个token的维度为48。再经过Stage1中的Linear映射后,56*56*48变为56*56*C(C=96),每一个token的维度变为96。再经过Stage1中的SwinT层,此层对小窗口进行Transformer,窗口大小为7*7patchs/tokens,也就是序列长度为49=7*7。SwinT层对应图3(b),包含两个模块,W-MSA和SW-MSA是多头自注意模块,分别具有一般窗口和移位的窗口配置,计算公式为:

SwinT层不改变维度,56*56*96,再经过Stage2,下图对应Stage2中patch Merging的过程:
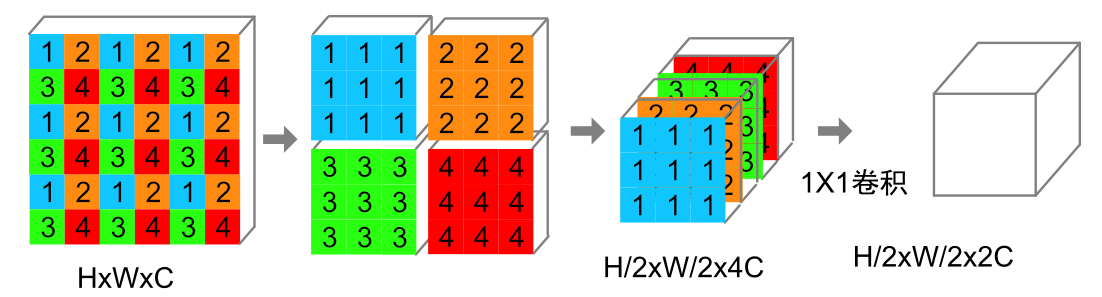
56*56*96经过Patch merging后为28*28*192(HW变为原先的1/2,4C通过1*1卷积降维为2C),再经过SwinT后维度不变为28*28*192。同Stage2,经过Stage3后为14*14*384,经过Stage4后为7*7*768。
移位窗口
在图2的移动窗口的过程中会出现一种问题,就是移位后窗口中的Patch数量是不一致的,如果强行填充0来保持一致,实质上还是增加了计算的复杂度(比如图2中从4个窗口变成9个)。怎么解决呢?SwinT的解决方式是循环移位如下图所示:
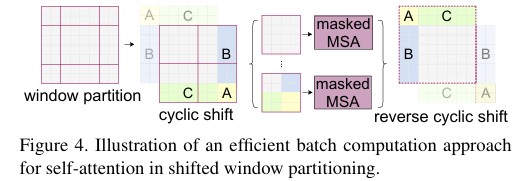
经过循环移位后进行切割的窗口数量是不变的。再经过mask的方式来限制不相邻块之间的transformer计算,因为不相邻的块不应该计算注意力。最后再还原回去。
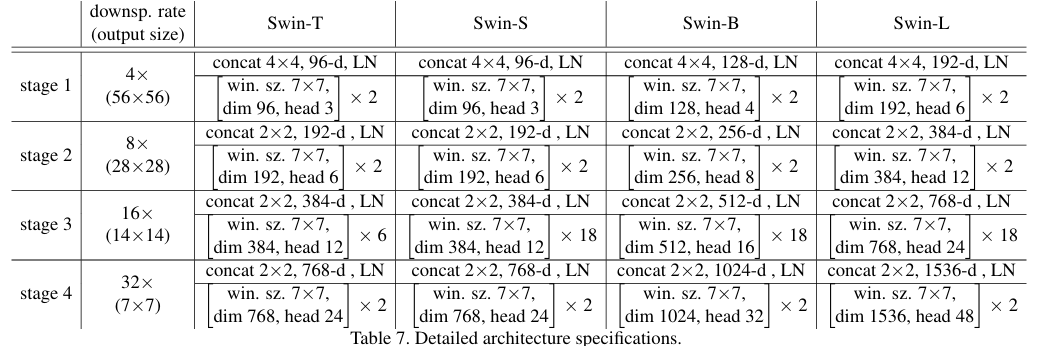
模型变体

 代码实现
代码实现
microsoft/Swin-Transformer: This is an official implementation for "Swin Transformer: Hierarchical Vision Transformer using Shifted Windows".![]() https://github.com/microsoft/Swin-Transformer
https://github.com/microsoft/Swin-Transformer