Kafka客户端参数(一)
本文为个人学习笔记整理,仅供交流参考,非专业教学资料,内容请自行甄别。
文章目录
- 概述
- 一、消费者分组消费机制
- 二、生产者拦截器机制
- 三、消息序列化机制
- 四、消息分区路由机制
概述
在Kafka的客户端中,无论是消费者还是生产者,都有很多的参数,无论是通过Properties去put,还是整合Spring Boot在配置文件中配置,都需要对重要的参数进行理解。
一、消费者分组消费机制
首先看一下源码中的解释:

GROUP_ID_CONFIG参数,代表着标识此消费者所属的消费者组的唯一字符串。如果消费者使用subscribe(topic)或基于kafka的offset管理策略来使用组管理功能,则需要此属性。该参数的含义:
- 每个消费者组在 Kafka 集群中必须有唯一的 group.id。不同组的消费者相互独立,互不干扰。例如,若两个消费者实例使用相同的 group.id,它们会被视为同一组的成员,共同消费主题的分区;而不同 group.id 的消费者组可以各自完整地消费同一主题的所有消息,实现类似 “广播” 的效果。
- 它也是offset管理的核心参数。Kafka服务端通过 group.id 在内部主题 __consumer_offsets 中存储每个分区的Offset。消费者重启或故障恢复时,会根据 group.id 读取最后提交的 Offset,确保从断点继续消费,避免消息丢失或重复。
在上一篇中有提到过,为了减少Kafka服务器偏移量管理的复杂度,故将偏移量的提交操作,交给客户端自己去处理。但是因为客户端的不确定性,所以服务器还是保有了兜底方案,即自动提交,需要在消费者进行设置enable.auto.commit=true。设置了该参数,消费者定期自动提交 Offset,依赖 group.id 定位存储位置。但是若未配置 group.id,自动提交会因无法定位消费者组而报错
二、生产者拦截器机制
如果希望生产者在将消息发送到Kafka之前 ,能对消息进行一些特殊处理,也就是实现拦截器的效果,可以使用配置INTERCEPTOR_CLASSES_CONFIG

自定义一个类,实现ProducerInterceptor接口:
public class MyProducerInterceptor implements ProducerInterceptor {/*** 发送消息时触发** @param record the record from client or the record returned by the previous interceptor in the chain of interceptors.* @return*/@Overridepublic ProducerRecord onSend(ProducerRecord record) {return record;}/*** 收到服务器响应触发*/@Overridepublic void onAcknowledgement(RecordMetadata metadata, Exception exception) {}/*** 连接关闭时触发*/@Overridepublic void close() {}/*** 配置项处理** @param configs*/@Overridepublic void configure(Map<String, ?> configs) {System.out.println("配置项处理");for (Map.Entry<String, ?> stringEntry : configs.entrySet()) {String key = stringEntry.getKey();Object value = stringEntry.getValue();System.out.println(key + ":" + value);}}
}
在生产者的配置中指定。或者配置文件中指定
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, "com.ragdollcat.mykafkademo.producer.MyProducerInterceptor");
三、消息序列化机制
无论是对象,还是基本类型,在客户端到服务端之间的流转,都是通过二进制流的方式。所以对于消息需要进行序列化(生产者)和反序列化(消费者)的处理。
生产者的序列化参数,实现Serializer接口可以自定义序列化机制。

消费者的反序列化参数,实现Deserializer接口可以自定义反序列化机制。

序列化和反序列化参数,都有key和value两种:
- key的作用是
决定消息的分区分配(Hash (key) → 分区),是可选的,如果为 null,此时消息随机分配Partition。 - value是
存储实际业务数据的值,序列化和反序列化的格式必须一模一样,不能序列化使用JDK自带的,反序列化使用JSON。
对于String类型,还可以用getBytes方法转换为byte数组,如果是java bean 就需要自己定义序列化和反序列化的策略:
假设我有一个实体类,具有以下三个属性:
public class Order {private Long orderId;private String fundName;private int total;}
生产者端自定义序列化:
public class MySerializer implements Serializer<Order> {/*** Convert {@code data} into a byte array.** @param topic topic associated with data* @param data typed data* @return serialized bytes*/@Overridepublic byte[] serialize(String topic, Order data) {//效率更高的自定义序列化byte[] nameBytes = data.getFundName().getBytes(StandardCharsets.UTF_8);//id: long 8byte + 4: int name的长度 + name:string 不定长 + sex: int 4byteint cap = 8 + 4 + nameBytes.length + 4;ByteBuffer byteBuffer = ByteBuffer.allocate(cap);byteBuffer.putLong(data.getOrderId());byteBuffer.putInt(nameBytes.length);byteBuffer.put(nameBytes);byteBuffer.putInt(data.getTotal());return byteBuffer.array();}
}
消费者端定义反序列化:
public class MyDeserializer implements Deserializer<Order> {/*** Deserialize a record value from a byte array into a value or object.** @param topic topic associated with the data* @param data serialized bytes; may be null; implementations are recommended to handle null by returning a value or null rather than throwing an exception.* @return deserialized typed data; may be null*/@Overridepublic Order deserialize(String topic, byte[] data) {//自定义序列化ByteBuffer dataBuffer = ByteBuffer.allocate(data.length);dataBuffer.put(data);dataBuffer.flip();long id = dataBuffer.getLong();int fundName = dataBuffer.getInt();String name = new String(dataBuffer.get(data, 12, fundName).array(), StandardCharsets.UTF_8).trim();int total = dataBuffer.getInt();return new Order(id, name, total);}
}
最后还要在消费者和生产者方进行注册(原有key的序列化不需要改动):
//消费者
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "com.ragdollcat.mykafkademo.consumer.MyDeserializer");
//生产者
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "com.ragdollcat.mykafkademo.producer.MySerializer");
也可以使用JsonSerializer序列化机制,更加简单。但是如果追求极致的性能,还是建议自定义序列化和反序列化机制,因为JSON序列化成的字符串,有{}和""符号,对于传输性能也是有损耗的。
四、消息分区路由机制
在消息序列化机制中,有提到过,生产者和消费者,key的作用是决定消息的分区分配(Hash (key) → 分区),是可选的,如果为 null,此时消息随机分配Partition,那么是如何指定的呢?
在生产者端有一个参数,可以通过自定义类实现Partitioner接口,指定生产者将消息发送到哪一个Partitioner:

Partitioner有三个默认的实现类:

生产者一般使用的最多的是RoundRobinPartitioner策略,即负载均衡。
在消费者端,也可以指定从分区读取的策略:
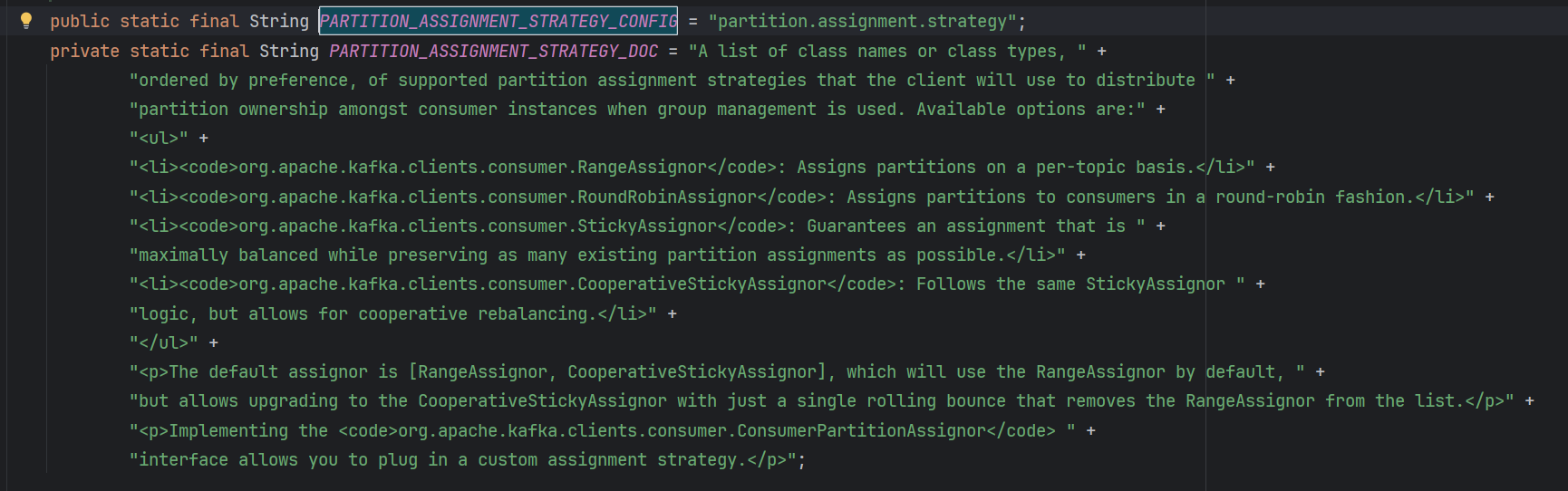
可选项有:
- RangeAssignor:按Topic分配分区,也是默认的方式。比如一个Topic有10个Partition,一个消费者组下有10个消费者。则0~3给第一个消费者,4 ~ 6给第二个消费者,7 ~9给第三个消费者。
- RoundRobinAssignor:以负载均衡的方式分区,如0,3,6给第一个消费者,1,4,7给第二个消费者,2,5,8给第三个消费者。
- StickyAssignor:粘性分区策略,为了解决以上两种分区策略的痛点,
RangeAssignor可能存在的问题是,5 个分区分给 2 个消费者,可能一个分 3 个、一个分 2 个。如果是RoundRobinAssignor策略,在新增或者下线一个消费者的情况下,所有的分区都会换消费者,也就是再平衡。StickyAssignor的核心目标是,在发生再平衡时,尽可能不去修改原有的分配,以最小的改动达成目的。