李宏毅NLP-14-NLP任务
NLP任务
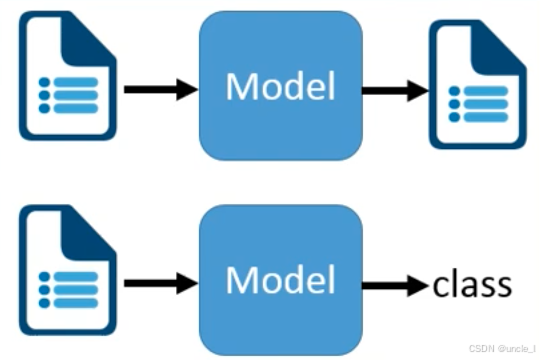
文本生成任务
- 输入:一段文本(如文档、句子)。
- 模型:生成式语言模型(如 GPT 系列、BERT+Decoder 架构)。
- 输出:一段新的文本。
- 典型场景:
- 机器翻译(如将中文文档转为英文文档);
- 文本摘要(输入长文档,输出简短摘要);
- 对话生成(输入用户问题,输出回答文本)。
文本分类任务
- 输入:一段文本(如新闻、评论)。
- 模型:分类式语言模型(如 BERT、TextCNN)。
- 输出:一个类别标签(如 “正面 / 负面情绪”“体育 / 财经领域”)。
- 典型场景:
- 情感分析(判断用户评论是 “积极” 还是 “消极”);
- 垃圾邮件识别(区分 “正常邮件” 和 “垃圾邮件”);
- 意图识别(在智能客服中判断用户意图是 “查询订单” 还是 “投诉”)。
这两种任务是 NLP 的基础方向:文本生成聚焦 “创造新文本”,文本分类聚焦 “给文本贴标签”,二者分别支撑了创作、分析类的众多实际应用。
分类任务
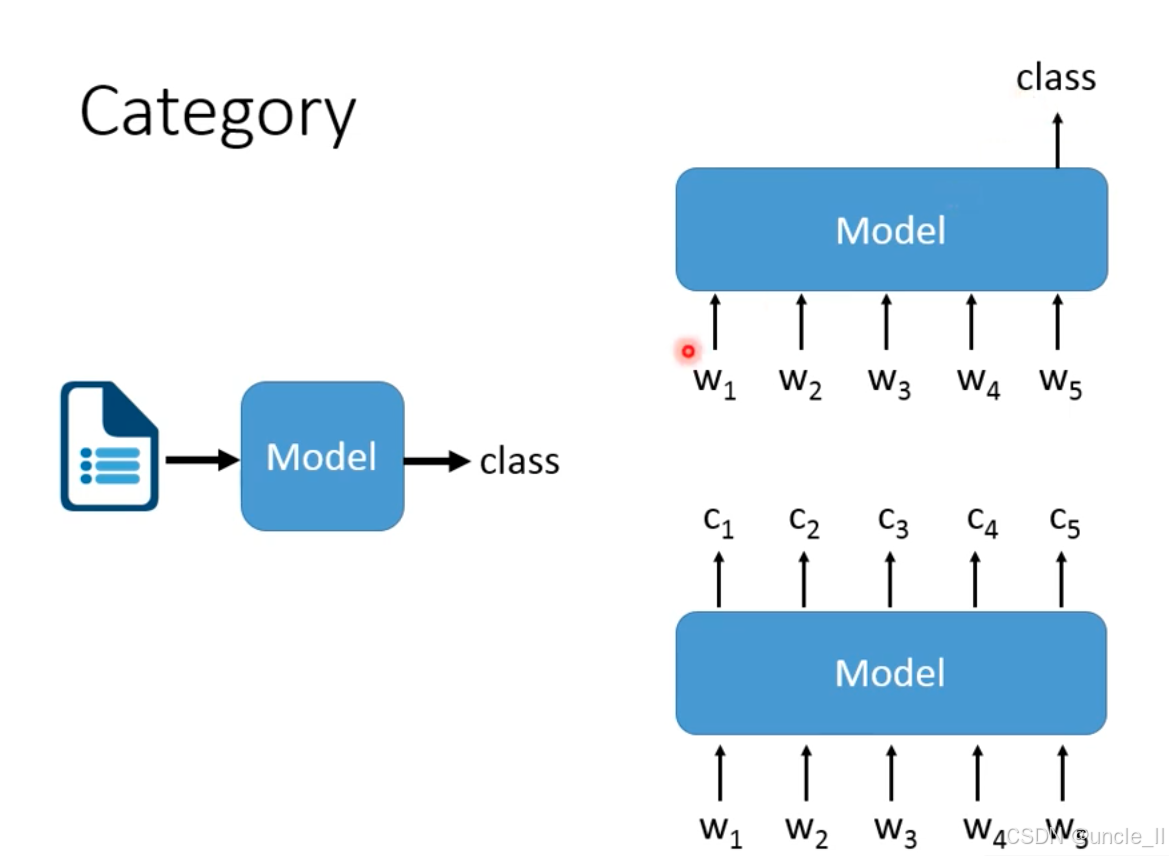
单类别分类
- 每个文本样本仅属于一个类别。
- 流程特征:模型输入一段文本后,输出唯一的类别标签
多类别分类
- 每个文本样本可以同时属于多个类别。
- 流程特征:模型输入一段文本后,输出多个类别标签
文本到文本
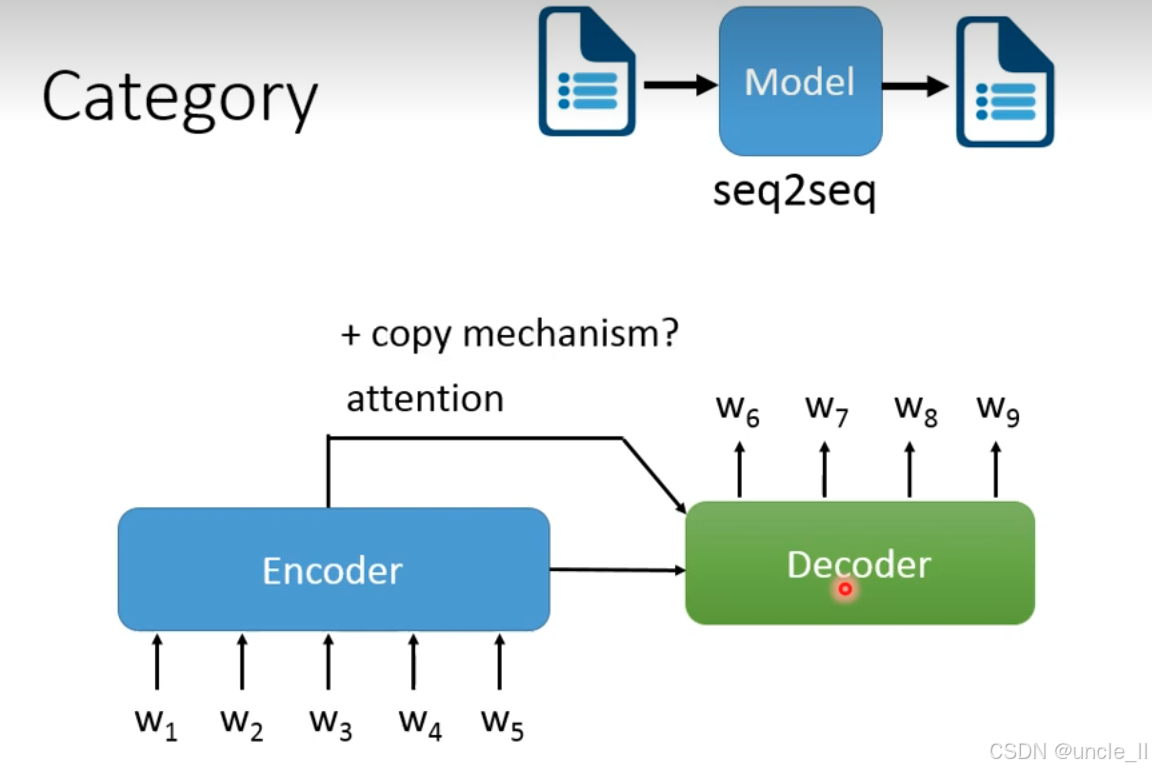
序列到序列(Seq2Seq)模型专门用于 “输入文字→输出文字” 的 NLP 任务(如机器翻译、文本摘要、对话生成等)。
- 输入:一段文本(如英文句子、长文档、用户问题)。
- Model:Seq2Seq 模型,负责将输入文本理解后生成目标文本。
- 输出:一段新文本(如对应的中文翻译、摘要、回答)。
- 典型场景:
- 机器翻译(输入 “Hello”→输出 “你好”);
- 文本摘要(输入长新闻→输出简短摘要);
- 对话生成(输入 “今天天气怎么样?”→输出 “今天晴天,气温 25℃”)。
Seq2Seq 由 编码器(Encoder)、解码器(Decoder)、注意力机制(Attention)、复制机制(Copy Mechanism 组成:
- 编码器(Encoder):
- 输入:
w₁~w₅(输入文本的词序列,如 “机器学习很有趣”)。 - 作用:将输入序列编码为语义向量(隐藏状态),捕捉输入文本的整体含义。
- 常见实现:RNN、LSTM、Transformer 的 Encoder 层。
- 输入:
- 解码器(Decoder):
- 输出:
w₆~w₉(生成的目标文本词序列,如 “Machine learning is interesting”)。 - 作用:基于编码器的语义向量,逐词生成输出文本。
- 常见实现:RNN、LSTM、Transformer 的 Decoder 层。
- 输出:
- 注意力机制(Attention):
- 作用:让解码器在生成每个词时,动态关注编码器中 “最相关的输入部分”(比如翻译 “学习” 时,重点关注输入的 “学习” 对应的编码)。
- 价值:解决传统 Seq2Seq “长文本信息丢失” 的问题,大幅提升生成精度(如长句翻译、复杂摘要)。
- 复制机制(Copy Mechanism):
- 作用:允许解码器直接复制输入中的词(如文本摘要中保留 “人工智能” 这类专业术语)。
- 适用场景:需要保留输入中关键信息的任务(如问答系统中复制问题里的实体 “北京” 来生成 “北京的天气是…”)。
Seq2Seq 是 “输入文字→输出文字” 类 NLP 任务的基石架构,后续的 Transformer、BERT 等大模型,本质上也是在这个框架上的升级(如用自注意力替代 RNN,增强长距离依赖建模能力)。它的灵活性使其能适配翻译、摘要、对话、语法纠错等数十种文本生成任务,是 NLP 中 “文本到文本” 场景的核心技术。
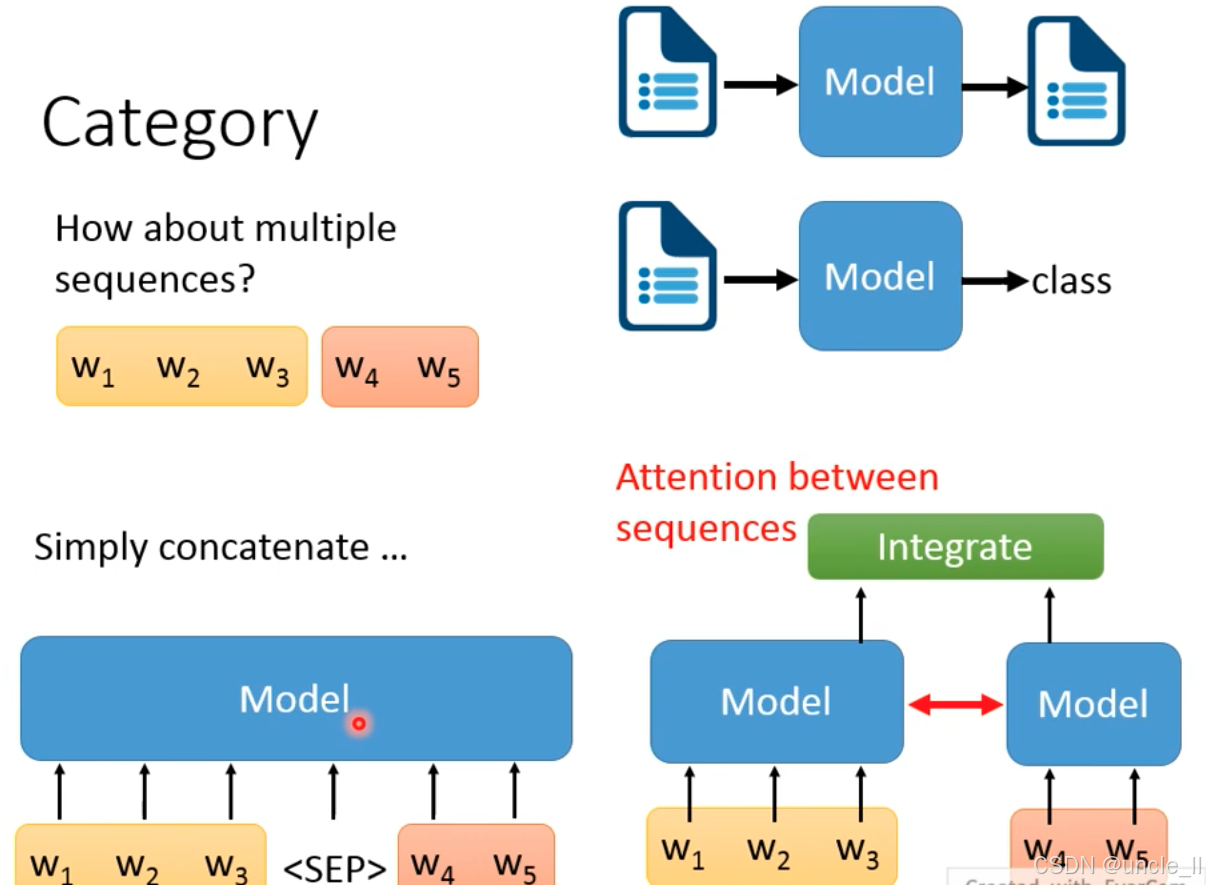
NLP 中多个输入文本处理的两种核心策略,适用于文本匹配、多文档理解、自然语言推理等场景
简单拼接(Simply concatenate)
- 处理逻辑:将多个文本序列(如
w₁w₂w₃和w₄w₅)通过分隔符(如<SEP>)拼接成一个长序列,再输入模型统一处理。 - 典型场景:
- 文本匹配(如判断 “句子 A” 和 “句子 B” 是否语义相关,输入为
句子A <SEP> 句子B); - 多文档摘要的初步整合(将多篇文档拼接后输入模型)。
- 文本匹配(如判断 “句子 A” 和 “句子 B” 是否语义相关,输入为
- 优点:实现简单,适配现有单序列模型(如 BERT 的句子对输入就是这种逻辑,用
[SEP]分隔)。 - 缺点:模型难以显式区分不同序列的边界,长序列时易出现信息稀释(比如第二篇文档的关键信息被第一篇淹没)。
序列间注意力整合(Attention between sequences)
- 处理逻辑:对每个文本序列单独编码(两个Model分别处理
w₁w₂w₃和w₄w₅),再通过序列间注意力(Attention) 深度整合它们的语义交互,最终由Integrate模块输出结果。 - 典型场景:
- 自然语言推理(判断前提句和假设句的逻辑关系,如蕴含/矛盾);
- 多轮对话理解(整合多轮用户输入和历史回复的语义);
- 多文档问答(从多篇文档中交叉检索信息回答问题)。
- 核心优势:通过显式的序列间注意力,模型能精准捕捉不同文本间的语义关联(比如在推理任务中,明确前提中的鸟会飞 和假设中的企鹅会飞的矛盾关系),避免信息稀释,是当前处理多序列任务的主流优化方向。
| 策略 | 适用场景 | 典型模型 / 任务示例 | |
|---|---|---|---|
| 简单拼接 | 序列间交互弱、对效率要求高 | BERT 的句子对分类(如 QQP 任务) | |
| 序列间注意力整合 | 序列间交互强、需深度语义关联 | 自然语言推理模型(如 DeBERTa) | 多轮对话系统 |
简单拼接是入门级方案,而序列间注意力整合通过显式建模多序列的交互,能更好地处理复杂的多文本理解任务,是工业级 NLP 系统中处理多输入文本的核心技术思路。
任务汇总
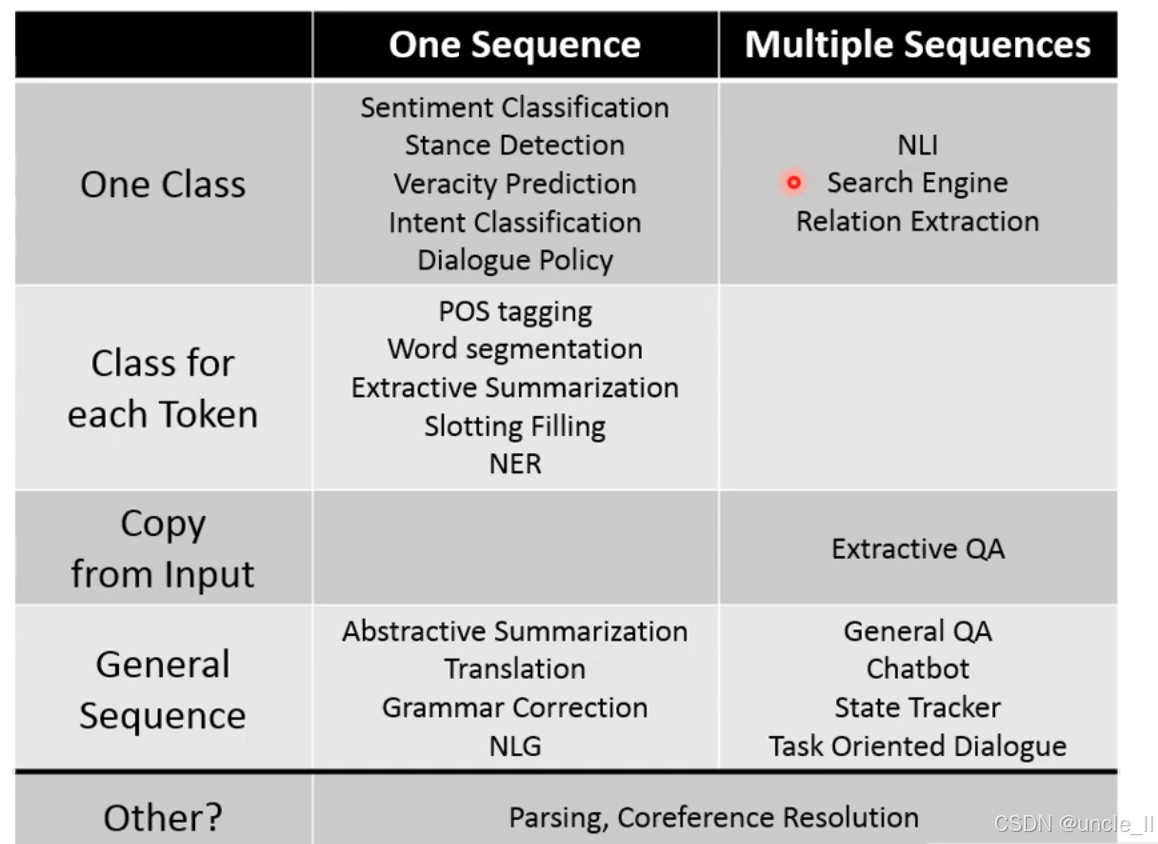
NLP 任务的二维分类体系,以 输入序列数量(列:单序列 / 多序列)和输出类型(行) 为维度,系统梳理了主流 NLP 任务的归属:
列:输入序列数量
- One Sequence:模型仅输入一个文本序列(如单句、单篇文档)。
- Multiple Sequences:模型输入多个文本序列(如问题 + 文档,前提 + 假设,多轮对话历史 等)。
行:输出类型
-
1. One Class(输出 一个类别)
-
One Sequence:输入单序列,输出一个类别标签。
- 情感分类(判断文本 正面 / 负面)、立场检测(判断对话题的 支持 / 反对)、真实性预测(判断文本 真实 / 虚假)、意图分类(如智能客服判断用户 查询订单 / 投诉)、对话策略(对话系统中决策下一步动作)。
-
Multiple Sequences:输入多序列,输出一个类别 / 关系。
- NLI(自然语言推理,输入 前提 + 假设,判断 蕴含 / 矛盾 / 中立)、搜索引擎(输入 查询 + 多个文档,判断文档与查询的 相关性)、关系抽取(输入 两个实体的上下文,抽取 属于 / 关联于 等关系)。
-
-
- Class for each Token(每个词元输出一个类别,即 序列标注)
-
One Sequence:对输入序列的每个词元(Token)单独打标签。
- POS tagging(词性标注,如给 苹果 标 名词)、Word segmentation(分词,如中文分词,给 我爱吃苹果 标 我 / 爱 / 吃 / 苹果 的边界)、Extractive Summarization(抽取式摘要,给每个句子标 是否属于摘要句)、Slotting Filling(槽填充,对话系统中给 明天飞北京的明天标时间槽、北京标地点槽)、NER(命名实体识别,给马云创立阿里的马云标人名、阿里标机构名)。
-
Multiple Sequences:该类任务通常基于单序列,多序列场景下较少见,故此处空白。
-
- Copy from Input(输出是 从输入中直接复制内容)
-
One Sequence:无典型任务。
-
Multiple Sequences:输入多序列,输出从其中一个序列复制片段。
- Extractive QA(抽取式问答,如输入 问题 + 文档,从文档中复制答案片段,如 中国首都的答案 北京 直接来自文档)。
-
4. General Sequence(生成任意新序列,即生成式任务)
-
One Sequence:输入单序列,生成全新序列。
- 抽象式摘要(输入长文档,生成浓缩且改写的摘要)、翻译(输入英文,生成中文)、语法纠错(输入 我昨天吃了苹果,生成 我昨天吃了苹果。)、NLG(自然语言生成,如输入角色:小明,场景:学校,生成小明在学校里认真听课。)。
-
Multiple Sequences:输入多序列,生成新序列。
- General QA(通用问答,如结合多文档 + 问题生成答案)、Chatbot(聊天机器人,多轮对话中结合历史回复 + 当前问题 生成回答)、State Tracker(状态追踪,对话中整合多轮输入生成当前状态描述)、Task Oriented Dialogue(任务导向对话,如 订机票 场景中,多轮交互后生成 订单确认 文本)。
-
5. Other(其他特殊任务)
- One Sequence:不属于以上四类的任务。
- Parsing(句法分析,分析句子的 主谓宾结构)、Coreference Resolution(共指消解,判断 他马云 是否指向同一实体)。
POS Tagging 词性标注
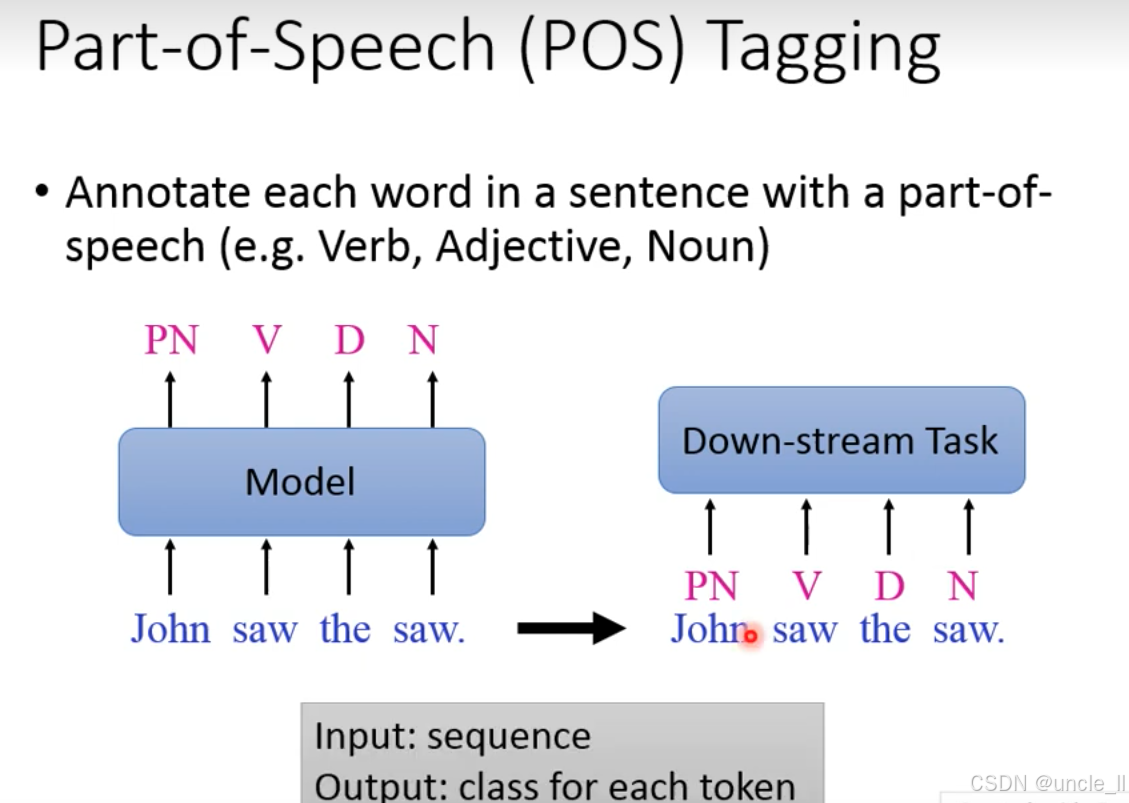
词性标注是自然语言处理(NLP)的基础序列标注任务,目标是为句子中的每个单词标注其语法类别(如动词、形容词、名词、代词等)。例如图中句子 “John saw the saw.”:
- John 被标注为 PN(Personal Pronoun,人称代词);
- 第一个 saw 被标注为 V(Verb,动词,意为 “看见”);
- the 被标注为 D(Determiner,限定词,如冠词);
- 第二个
saw被标注为N(Noun,名词,意为 “锯子”)。
这一案例也体现了词性标注对多义词歧义消解的作用(同一个词saw因语法角色不同被标注为动词和名词)。
- 输入输出:输入是词序列(如 “John saw the saw”),输出是每个词对应的词性类别(即 “每个 token 的 class”),属于典型的序列标注任务。
- 模型(Model):负责学习词→词性的映射关系,经典模型包括隐马尔可夫模型(HMM)、条件随机场(CRF),现代方案多基于 Transformer(如 BERT + 线性层)。
简言之,词性标注是 NLP理解语言语法结构” 的第一步,通过给每个词赋予语法身份,为后续复杂的语义理解、任务决策提供关键支撑。
但是如果你的下游任务模型足够强,可能已经包含了词性标注的能力,不需要做词性标注了。
Word Segmentation 分词
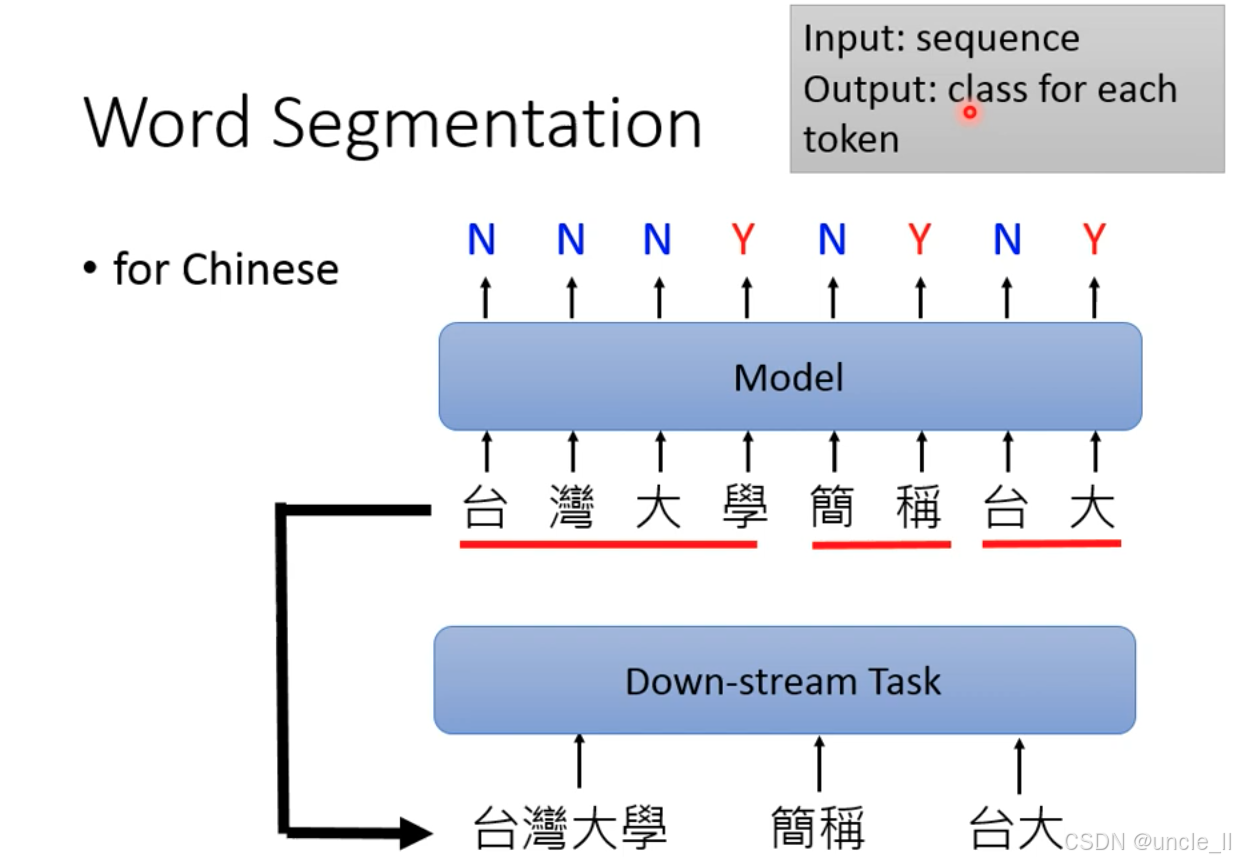
与英文不同,中文句子是连续的字符序列,因此需先通过分词将字符切分为有意义的词语(如 “台灣大學”“簡稱”“台大”),才能支撑后续的语义理解、句法分析等 NLP 任务。
- 输入:连续的中文字符序列(如 “台灣大學簡稱台大”)。
- 模型(Model):对每个字符进行序列标注,判断其是否为 “分词边界”
N:表示该字符不是分词结束位置,需与后续字符合并;Y:表示该字符是分词结束位置,在此处断开。
- 下游任务(Down-stream Task):基于分词结果,开展更复杂的 NLP 任务(如词性标注、命名实体识别、文本分类等)。
中文分词是序列标注任务的典型应用,模型需学习 “字符→分词边界” 的映射关系。经典方法包括基于词典的规则匹配(如结巴分词)、基于统计的隐马尔可夫模型,现代方案多采用 Transformer(如 BERT)+ 条件随机场(CRF)的架构,以提升歧义场景的分词精度(如 “乒乓球 / 拍卖 / 卖得 / 好” vs “乒乓 / 球拍 / 拍卖 / 得好”)。
Parsing 句法分析
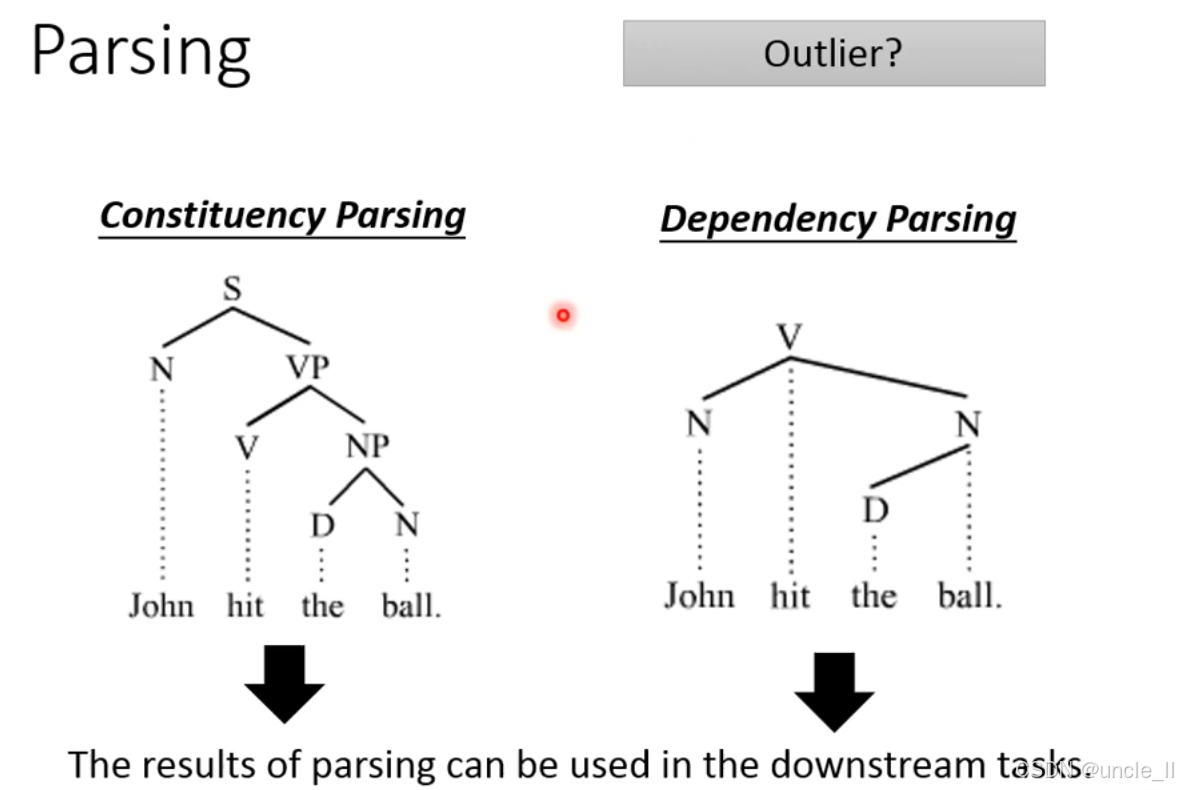
句法分析任务的两种核心类型:短语结构分析(Constituency Parsing和依存分析(Dependency Parsing),它们是 NLP 中理解句子语法结构的关键任务。
短语结构分析(Constituency Parsing)
- 核心逻辑:将句子分解为层次化的短语结构树,通过 “父节点 - 子节点” 的层级关系,展示句子的短语组成(如 “句子→名词短语 + 动词短语”)。
- 示例解析:以句子“John hit the ball.”为例,结构树中:
S(Sentence,句子)是根节点;S分为N(Noun Phrase,名词短语,即 “John”)和VP(Verb Phrase,动词短语);VP又分为V(Verb,动词 “hit”)和NP(Noun Phrase,名词短语 “the ball”);NP再分为D(Determiner,限定词 “the”)和N(Noun,名词 “ball”)。
- 价值:清晰呈现句子的短语层级结构,为句法规则、语义角色分析等任务提供基础。
依存分析(Dependency Parsing)
- 核心逻辑:聚焦词与词之间的直接语义依赖关系,用有向边表示支配词 - 从属词的关系(如动词支配主语、宾语),不强调层次结构,更关注语义关联。
- 示例解析:同样以“John hit the ball.”为例:
- 动词
hit是核心支配词; John是hit的主语(名词依赖于动词);ball是hit的宾语(名词依赖于动词);the是ball的限定词(限定词依赖于名词)。
- 动词
- 价值:直接体现词的语义依存关系,更贴合 “谁对谁做了什么” 的语义理解,是机器翻译、问答系统等任务的核心支撑。
两种 Parsing 的结果均可用于下游 NLP 任务(如语义角色标注、情感分析、机器翻译),帮助模型明确句子的语法结构和语义逻辑,是实现深度语言理解的关键环节。
Coreference Resolution 指代消解

指代消解是自然语言处理(NLP)的关键任务,目标是确定文本中哪些表达指向同一个现实世界实体。例如,文本中 “Paul Allen”“He”“Paul” 可能指代同一人,需将它们关联起来。
文本:
- “Paul Allen was born on January 21, 1953. He attended Lakeside School, where he befriended Bill Gates. Paul and Bill used a teletype terminal at their high school, Lakeside, to develop their programming skills…”
指代关系拆解:
- “He”(第二句)→ 指代 Paul Allen;
- 第二个 “he”(第二句)→ 指代 Paul Allen;
- “Paul”(第三句)→ 指代 Paul Allen;
- “their”(第三句)→ 指代 Paul 和 Bill;
- “Lakeside”(第三句)→ 指代 Lakeside School(第二句的名词短语)。
指代消解是文本语义理解的基石,直接影响多个下游任务的性能:
- 问答系统:用户问 “他在哪里上学?”,需通过指代消解确定 “他” 指 Paul Allen,才能回答 “Lakeside School”;
- 信息抽取:抽取 “Paul Allen 的教育经历” 时,需将 “Lakeside School” 与 “他” 的上学行为关联;
- 文本摘要:生成摘要时,需明确代词指代,避免语义模糊(如将 “He attended…” 简化为 “Paul Allen attended…”);
- 机器翻译:需根据指代关系调整译文的代词 / 名词使用,保证译文逻辑连贯。
简言之,指代消解通过理清实体的指代关系,让机器真正理解文本中谁做了什么,是实现深度语言理解的关键环节。
Summarization 摘要

抽取式摘要是文本摘要的一种类型,核心是从原始文档中直接抽取关键句子 / 短语,拼接成摘要(不进行内容改写)。
- 输入(Input):原始文档(
document),由多个句子(如Sentence 1、Sentence 2等)组成。 - 模型决策:算法识别文档中最具信息量、最能代表主旨的句子(如图中的
Sentence 2和Sentence 4)。 - 输出(Output):将抽取的关键句直接拼接,形成
summary(摘要)。
属于序列标注任务,对文档中的每个句子(或词元)判断 “是否属于摘要”,最终将被标注为属于摘要的句子拼接输出。
- 优点:忠实于原文,避免生成错误;
- 缺点:可能存在句子拼接不流畅的问题;
- 应用:常作为新闻摘要、学术论文摘要的基础方案,也可与生成式摘要结合,提升摘要的流畅性与信息量。
简言之,抽取式摘要通过直接抽取原文关键句的方式,在保证内容真实性的前提下,实现文档的高效浓缩。
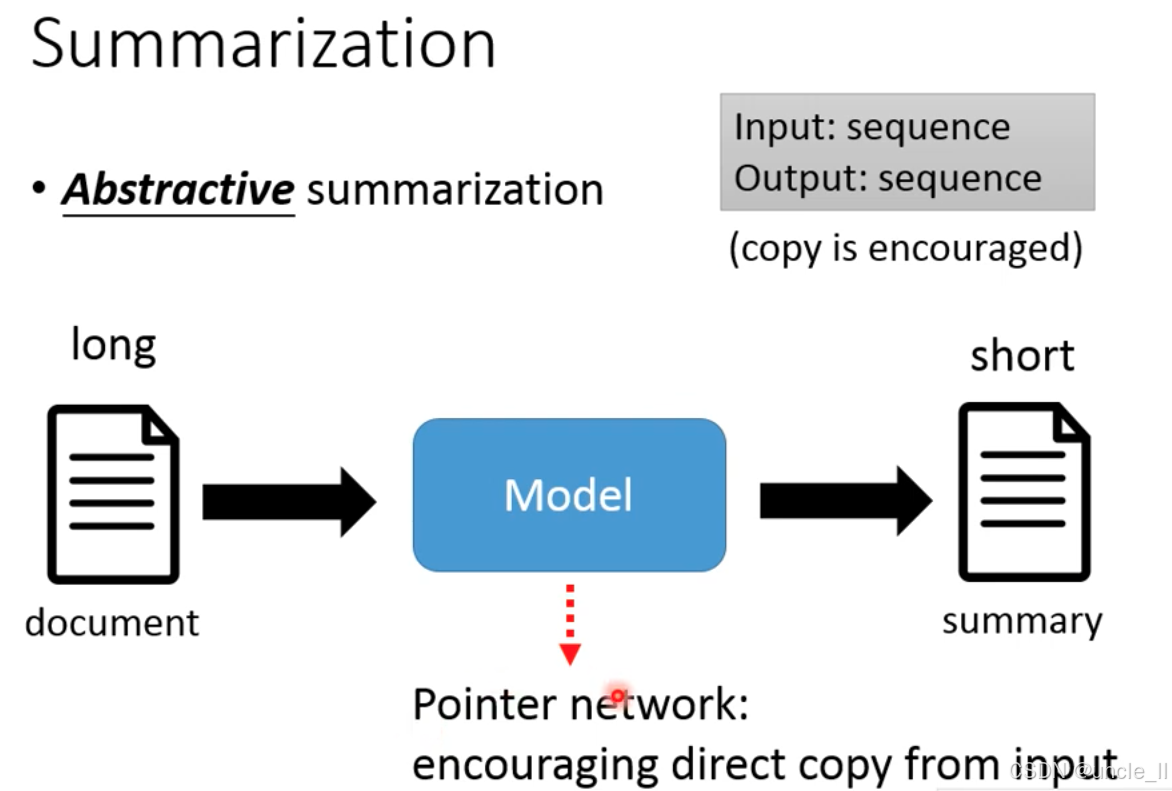
抽象式摘要是输入长文本(sequence)、输出短摘要(sequence) 的生成式任务,模型需理解原文语义并生成全新的浓缩文本。该架构鼓励从输入中直接复制关键信息,以平衡生成灵活性和信息准确性。
指针网络Pointer Network是实现精准复制的核心技术:
-
它让模型在生成摘要时,能**指向输入文本中的特定词 / 短语 **,直接复制到输出中(如专业术语、核心实体、关键动词等)。
-
解决痛点:避免抽象式摘要常见的生成错误(如编造不存在的信息、术语拼写错误),同时保留生成式摘要 重组语义、提升流畅性的优势。
-
输入:长文档(
document); -
模型:集成指针网络的 Seq2Seq 模型(如 BART、T5 的改进版),同时具备理解原文→生成新文本→复制关键信息的能力;
-
输出:短摘要(
summary),其中关键实体、术语直接从原文复制,其余部分由模型生成,兼顾准确性和流畅性。
Machine Translation 机器翻译
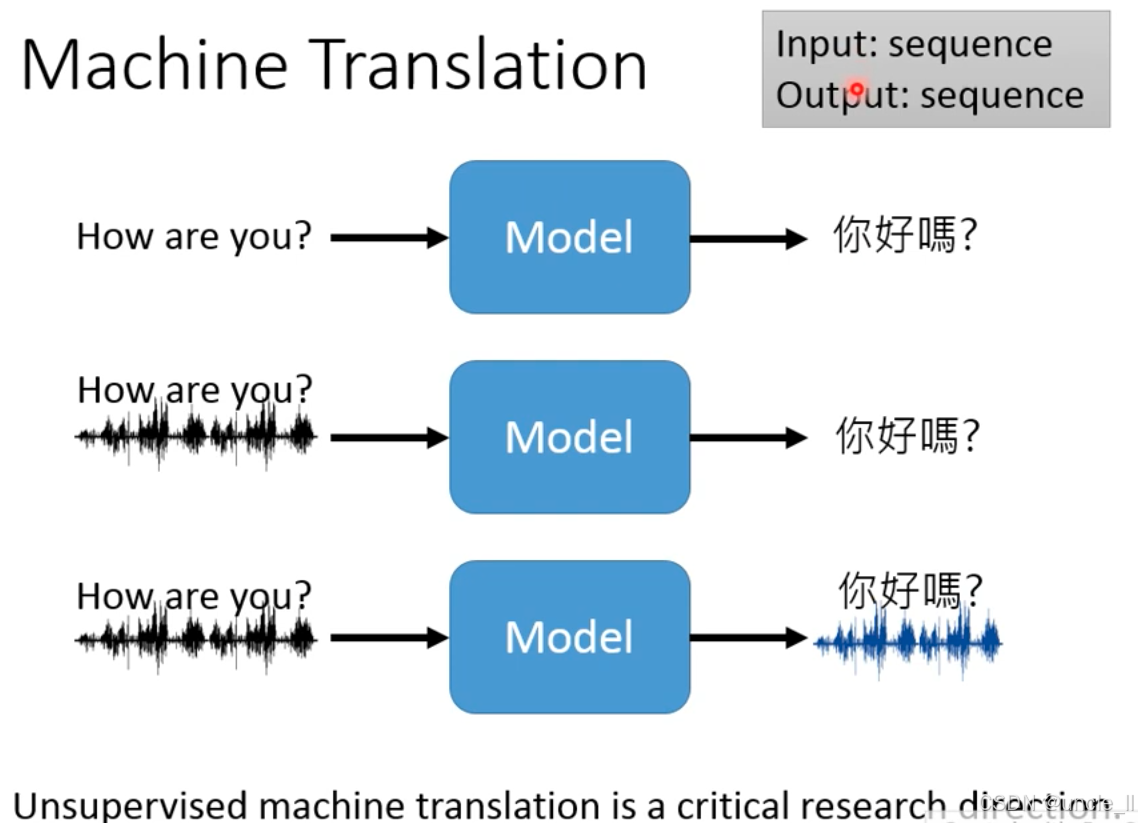
机器翻译(Machine Translation 的不同技术形态:
-
文本到文本的机器翻译
-
输入:英文文本 “How are you?”
-
模型:传统机器翻译模型(如 Transformer 架构)
-
输出:中文文本 “你好嗎?”
-
场景:这是最常见的机器翻译形式,如谷歌翻译、百度翻译的核心逻辑 —— 直接对文本进行跨语言转换。
-
-
语音到文本的机器翻译
-
输入:英文语音(波形图)+ 对应文本 “How are you?”
-
模型:融合 “语音识别(ASR)+ 机器翻译” 的多模块系统
-
输出:中文文本 “你好嗎?”
-
场景:适用于 “语音输入、文本输出” 的翻译需求,比如实时语音翻译软件(先把语音转成文本,再翻译文本)。
-
-
语音到语音的机器翻译
-
输入:英文语音(波形图)+ 对应文本 “How are you?”
-
模型:融合语音识别(ASR)+ 机器翻译 + 语音合成(TTS)的端到端系统
-
输出:中文语音(波形图)+ 对应文本 “你好嗎?”
-
场景:适用于语音输入、语音输出的实时翻译需求,比如同声传译 AI 设备(直接把语音翻译成目标语言的语音,同时输出文本辅助理解)。
-
传统机器翻译依赖大量 “平行语料”(如英文 - 中文的对齐句子对),但小语种或小众领域的平行语料稀缺。无监督机器翻译试图不依赖平行语料,通过自监督学习、跨语言语义对齐等方法,让模型自主学习翻译规则,解决语料不足的痛点。
Grammer Error Correction 语法纠错
 语法纠错(Grammar Error Correction, GEC)是 **“输入错误序列→输出正确序列” 的生成式任务 **:
语法纠错(Grammar Error Correction, GEC)是 **“输入错误序列→输出正确序列” 的生成式任务 **:
- 输入:存在语法错误的文本(如 I are good.);
- 模型:通过深度学习模型(如 Seq2Seq 架构、基于 Transformer 的模型)理解错误并生成修正后的文本;
- 输出:语法正确的文本(如I am good.)。
该任务属于 序列到序列(Sequence-to-Sequence) 类型,且鼓励复制正确部分(即模型优先保留原文中正确的词,仅修正错误部分)。
表格通过两个例子详细展示了语法错误的 “类型 - 修正方式”:
Example 1
-
错误输入(x):“Bolt can have run race”
-
正确输出(y):“Bolt could have run the race”
-
错误差异(diff)与修正类型(e):
(I,can,could)→ 替换(R, Replace):将 “can” 替换为 “could”(I,run,the)→添加(A, Add):在 “run” 后添加 “the”;
- 其余 “C” 表示正确(Correct),无需修改。
语法纠错是 **“错误识别 + 错误修正” 的复合任务 **,模型需同时判断哪里错了和怎么改。主流技术基于 Seq2Seq 架构(如 BART、T5 的微调版),并通过复制机制保留原文正确部分,仅对错误词进行替换、添加或删除,以保证修正的准确性和流畅性。核心挑战是平衡错误识别的精度和修正后的流畅性。
Sentiment Classification 情感识别

情感分类的目标是判断一段文本的情感倾向(如正面、负面、中性)。 “Input: sequence;Output: class”,明确输入是文本序列,输出是情感类别。
属于文本分类任务,模型需学习文本→情感类别的映射关系。主流方案基于深度学习(如 BERT、TextCNN),核心挑战是处理语义转折、情感极性词的权重判断(如 “虽然… 但…” 结构中,后段往往是情感重点)。
情感分类是 NLP 中分析文本喜怒哀乐的基础任务,广泛应用于舆情分析、产品评论挖掘等场景,其核心是让模型理解文本的情感倾向并输出对应类别。
Stance Detection 立场检测

立场检测是自然语言处理中的分类任务,目标是判断一段回复文本对源文本的立场倾向。其技术形态为:
- 输入:两个序列(源文本 + 回复文本);
- 输出:一个类别(如支持、否定、询问、中立等)。
主流系统采用 SDQC 标签集 对立场分类:
- Support(支持):回复赞同源文本的观点;
- Denying(否定):回复反对 / 否定源文本的观点;
- Querying(询问):回复对源文本的观点提出疑问;
- Commenting(评论 / 中立):回复仅为客观评论,无明确立场倾向。
立场检测常用于真实性预测(Veracity Prediction)—— 通过分析不同立场的回复分布(如大量否定立场的回复),可辅助判断源信息的可信度(如谣言识别、新闻真实性分析)。
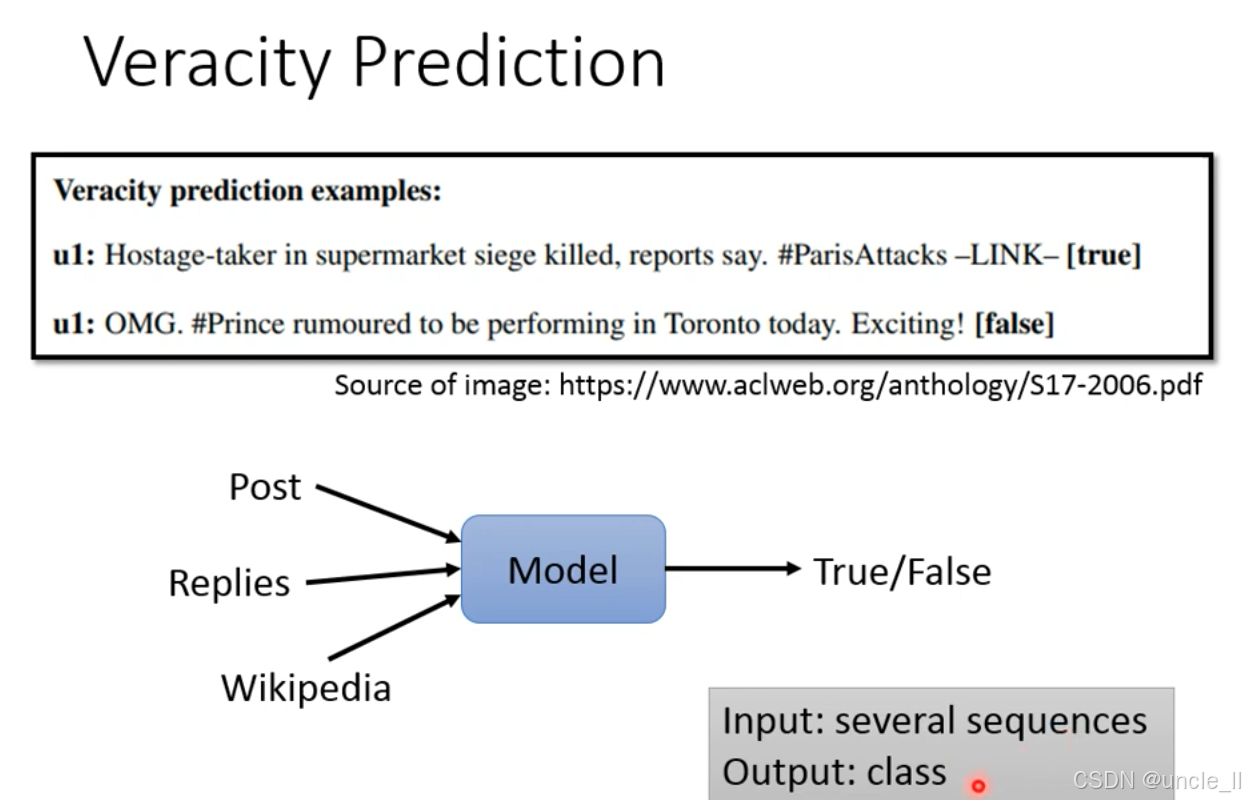
真实性预测的目标是判断信息的真假属性(如新闻、传闻是否真实)。输入是多个文本序列,输出是真实(True)或虚假(False) 的类别。
模型(Model)的输入包含多个序列:
Post:待判断的源信息(如社交平台帖子、新闻稿);Replies:用户对该信息的回复(可辅助判断立场、可信度,如大量质疑的回复可能暗示信息虚假);Wikipedia:外部知识(如百科条目、权威数据库,用于交叉验证信息真实性)。
模型通过整合这些多源信息,最终输出True/False 的类别判断。
该任务广泛用于谣言检测、假新闻识别等场景,是社交媒体舆情治理、信息可信度评估的关键技术,核心是通过多维度文本信息的融合,提升真假判断的准确性。
简言之,立场检测聚焦回复对源文本的态度判断,是社交舆情分析、信息真实性验证等场景的关键技术,核心是通过双序列输入→单类别输出的分类逻辑,捕捉文本间的立场关联。
Natural Language Inference(NLI) 自然语言推理
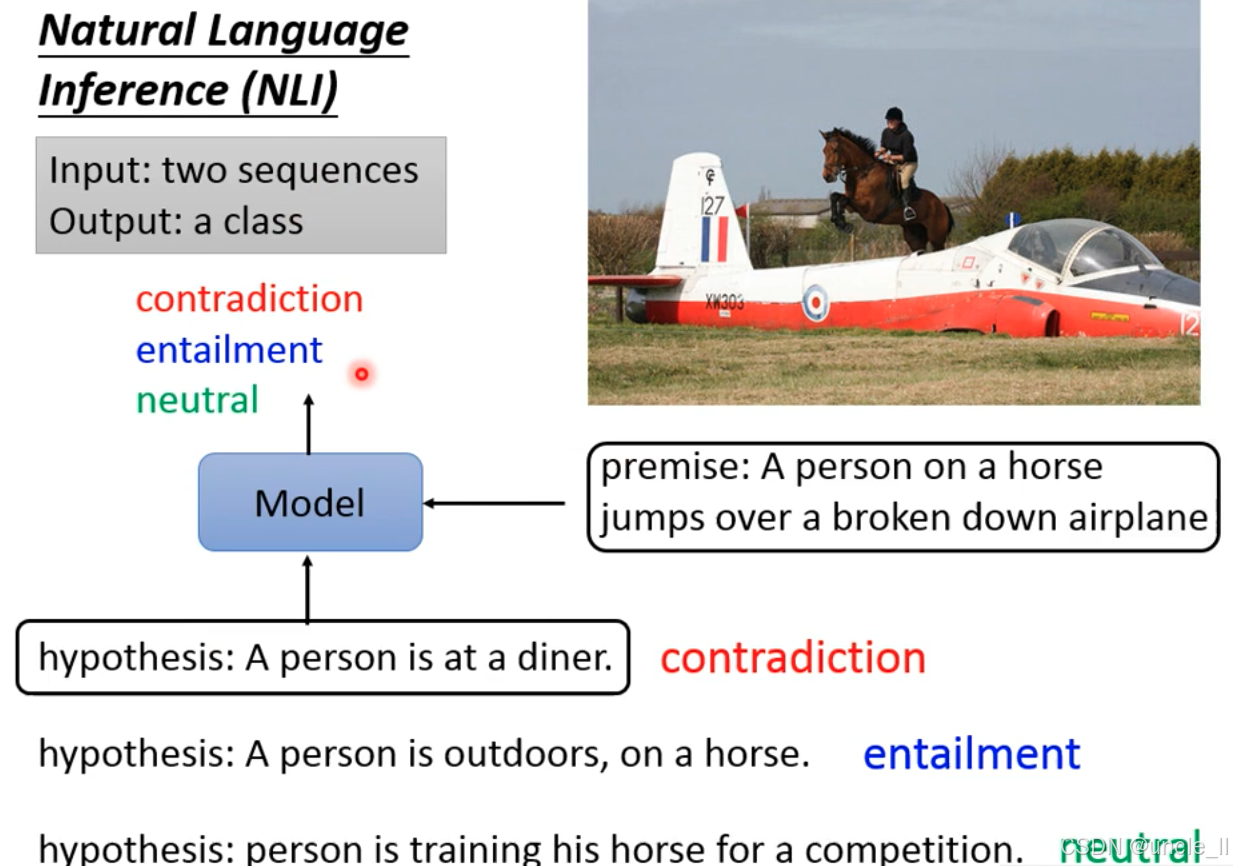
自然语言推理的目标是判断前提(Premise)和假设(Hypothesis)之间的逻辑关系,输出三类标签之一:
-
矛盾(Contradiction):假设与前提逻辑冲突;
-
蕴含(Entailment):假设可由前提必然推导得出;
-
中立(Neutral):假设与前提无明确逻辑关联(既不矛盾也不蕴含)。
-
前提(Premise):一个人骑马跳过一架故障的飞机 ;
-
假设1:一个人在餐厅→与前提场景完全冲突,属于矛盾(Contradiction);
-
假设2:一个人在户外骑马→前提场景必然包含户外骑马的信息,属于蕴含(Entailment);
-
假设3:一个人在训练马参加比赛→前提未提及训练或比赛,属于中立(Neutral)。
NLI是测试模型逻辑推理能力的关键任务,输入为两个序列(前提+假设),输出为一个类别(矛盾/蕴含/中立)。主流模型基于Transformer架构(如BERT、RoBERTa),通过学习文本间的语义关联,实现逻辑关系的分类。
Search Engine 搜索引擎
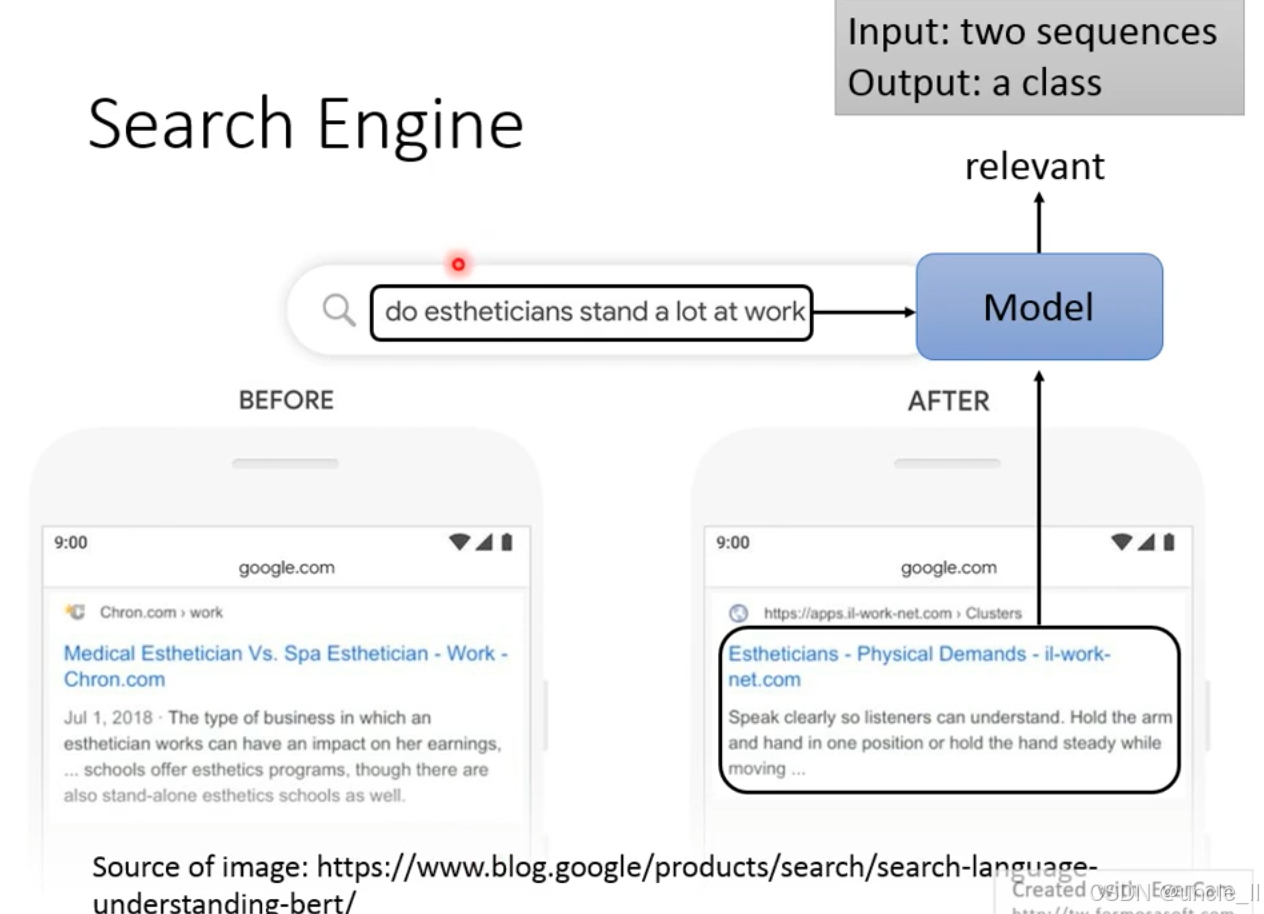
搜索引擎中的语义相关性判断任务双序列输入→类别输出:
- 输入:两个文本序列——用户查询(如美容师工作中经常站立吗?)+搜索结果文档;
- 输出:一个类别——relevant(相关)或不相关,用于判断文档是否匹配查询的语义需求。
对比google使用bert模型优化前后的搜索结果:
- 优化前(BEFORE):返回的文档仅提及美容师的职业类型、薪资影响,与是否常站立的查询语义关联弱;
- 优化后(AFTER):返回的文档明确涉及Physical Demands(身体需求),与standalot的查询高度相关,被模型判定为relevant。
模型需学习查询文本→文档文本的语义关联程度,输出相关/不相关的分类结果。这是搜索引擎精准召回的核心环节,直接影响搜索结果的质量。
Question Answering 问答系统
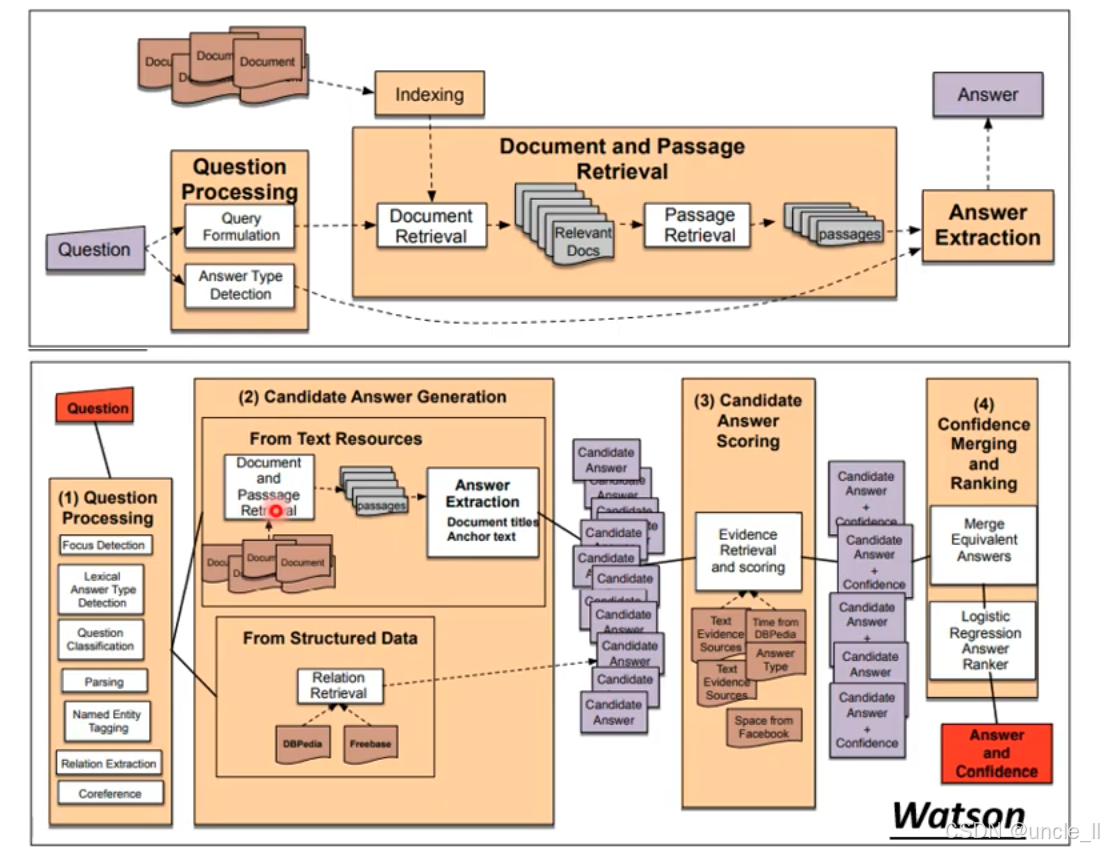
智能问答系统 “理解问题→检索信息→生成答案→评分排序” 的技术链条
早期通用问答流程
- **Question Processing(问题处理):**对用户问题进行解析,包括
Query Formulation(生成查询语句)和Answer Type Detection(判断答案类型,如 “人名”“时间” 等)。 - Indexing + Document and Passage Retrieval(索引与文档段落检索):
- 先对海量文档建立索引;
- 再通过
Document Retrieval筛选出与问题相关的文档(Relevant Docs); - 最后通过
Passage Retrieval从相关文档中提取更细粒度的段落(passages)。
- Answer Extraction(答案提取):从检索到的段落中提取最终答案。
IBM Watson 的问答流程被拆解为 4 个核心阶段,体现了其多源信息融合 + 置信度排序的技术特色:
- Question Processing(问题处理):
- 对问题进行多维度解析,包括
Focus Detection(聚焦问题核心)、Lexical Answer Type Detection(词汇级答案类型判断)、Question Classification(问题分类)、Parsing(句法分析)、Named Entity Tagging(命名实体识别)、Relation Extraction(关系抽取)、Coreference(指代消解)。
- 对问题进行多维度解析,包括
- Candidate Answer Generation(候选答案生成):
- 从文本资源(
From Text Resources)中,通过Document and Passage Retrieval和Answer Extraction生成候选答案; - 从结构化数据(
From Structured Data)中,通过Relation Retrieval(如从 DBpedia、Freebase 等知识库中检索关系)生成候选答案。
- 从文本资源(
- Candidate Answer Scoring(候选答案评分):
- 通过
Evidence Retrieval and scoring,从多源证据(如文本、DBpedia、Facebook 等)中为每个候选答案打分,同时计算置信度(Confidence)。
- 通过
- Confidence Merging and Ranking(置信度融合与排序):
Merge Equivalent Answers:合并语义等价的答案;Logistic Regression Answer Ranker:通过逻辑回归对答案进行最终排序;- 输出
Answer and Confidence:同时给出答案和其置信度。
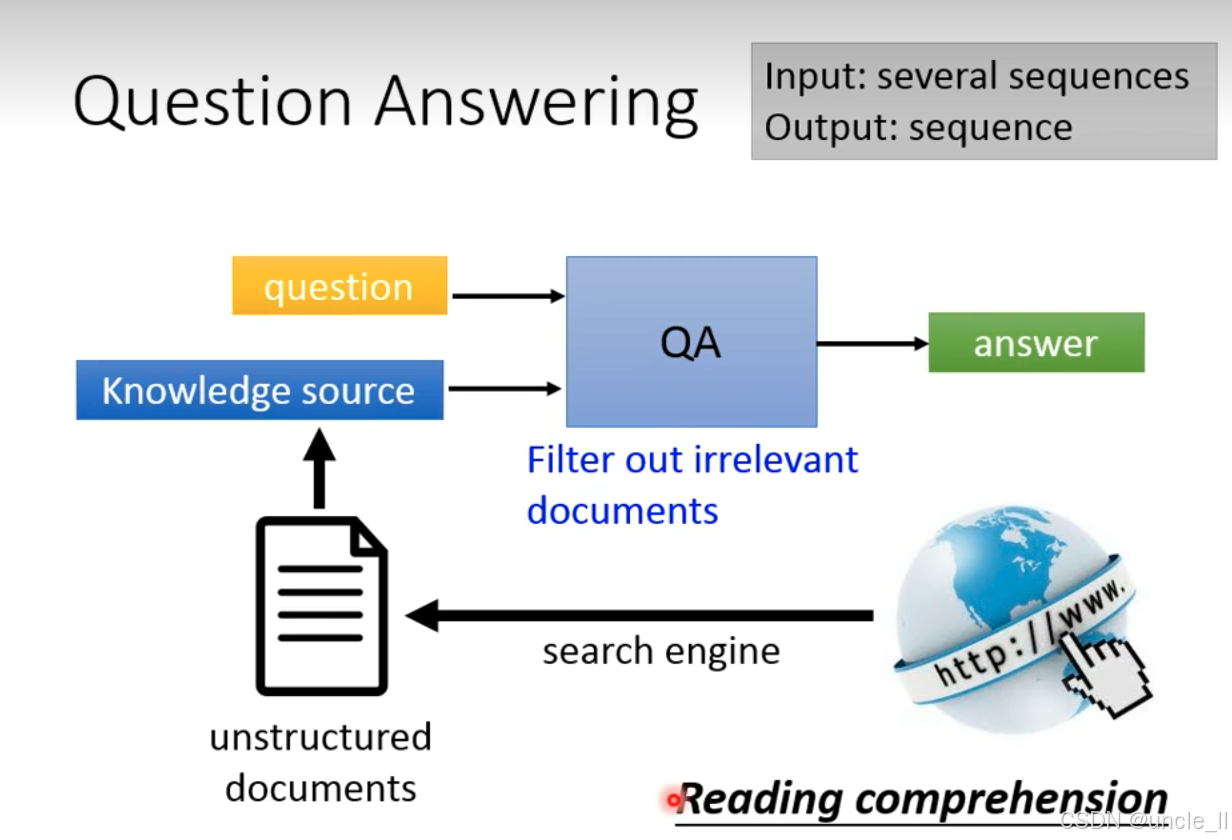
问答系统(Question Answering, QA)
- 输入:多个序列(
question用户问题 +Knowledge source知识源); - 输出:一个序列(
answer答案); - 核心能力:阅读理解(Reading comprehension) —— 模型需像人类一样理解问题和文档,从中提取答案。
-
知识源获取:
从海量 非结构化文档(unstructured documents) 中,通过
search engine(搜索引擎)筛选相关内容,过程中会Filter out irrelevant documents(过滤无关文档),最终形成Knowledge source(与问题相关的知识源)。 -
问答推理:
将
question(用户问题)和Knowledge source(筛选后的知识源)输入QA模型,模型基于阅读理解能力,从知识源中提取与问题匹配的答案(answer)。
该流程体现了问答系统 检索 + 理解 + 生成 的核心逻辑:先通过搜索引擎从非结构化文档中检索相关信息,再由 QA 模型理解问题 - 知识源的语义关联,最终生成精准答案。这是 NLP 在信息获取场景的典型应用,广泛支撑智能助手、知识库问答等产品。
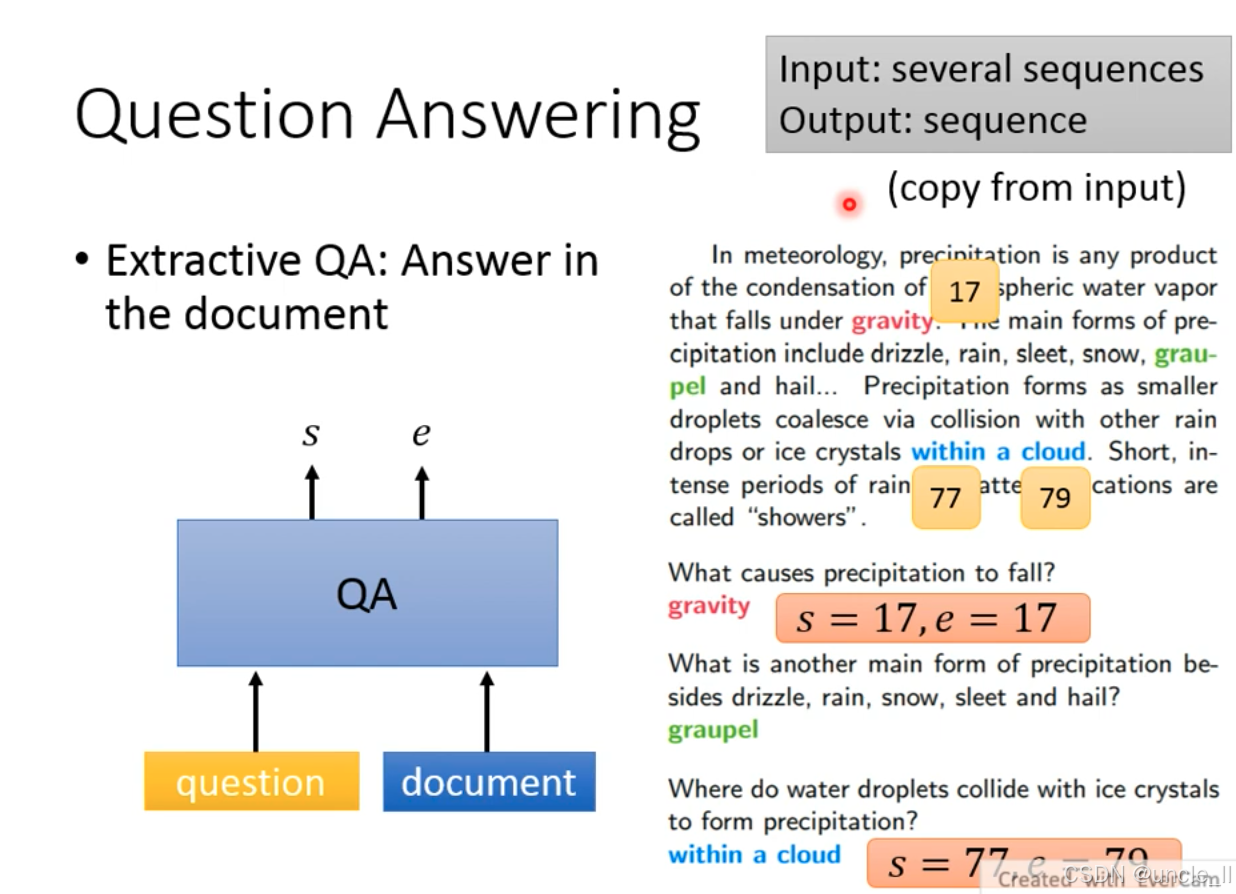
抽取式问答(Extractive QA) 的核心逻辑,属于问答系统中从文档直接抽取答案的典型任务
- 输入:多个序列(
question用户问题 +document参考文档); - 输出:一个序列(
answer答案),且答案直接从输入文档中复制(标注 “copy from input”); - 技术本质:序列标注任务—— 模型需定位答案在文档中的起始位置(s)和 结束位置(e),抽取连续的词作为答案。
以气象学文本为例:
- 问题 “What causes precipitation to fall?” → 文档中对应 “that falls under gravity”,模型定位到
gravity的位置(s=17, e=17),直接抽取该词作为答案; - 问题 “What is another main form of precipitation besides drizzle, rain, snow, sleet and hail?” → 文档中提到 “graupel”,模型抽取该词作为答案;
- 问题 “Where do water droplets collide with ice crystals to form precipitation?” → 文档中对应 “within a cloud”,模型抽取该短语作为答案。
抽取式问答的优势是答案保真度高(直接来自文档,避免生成错误),是阅读理解类问答任务的基础方案(如 SQuAD 数据集的核心任务就是抽取式问答)。技术上通过定位答案边界(s 和 e)实现,属于 NLP 中文本匹配 + 序列标注的复合任务。
Dialogue 对话
- chatting:尬聊
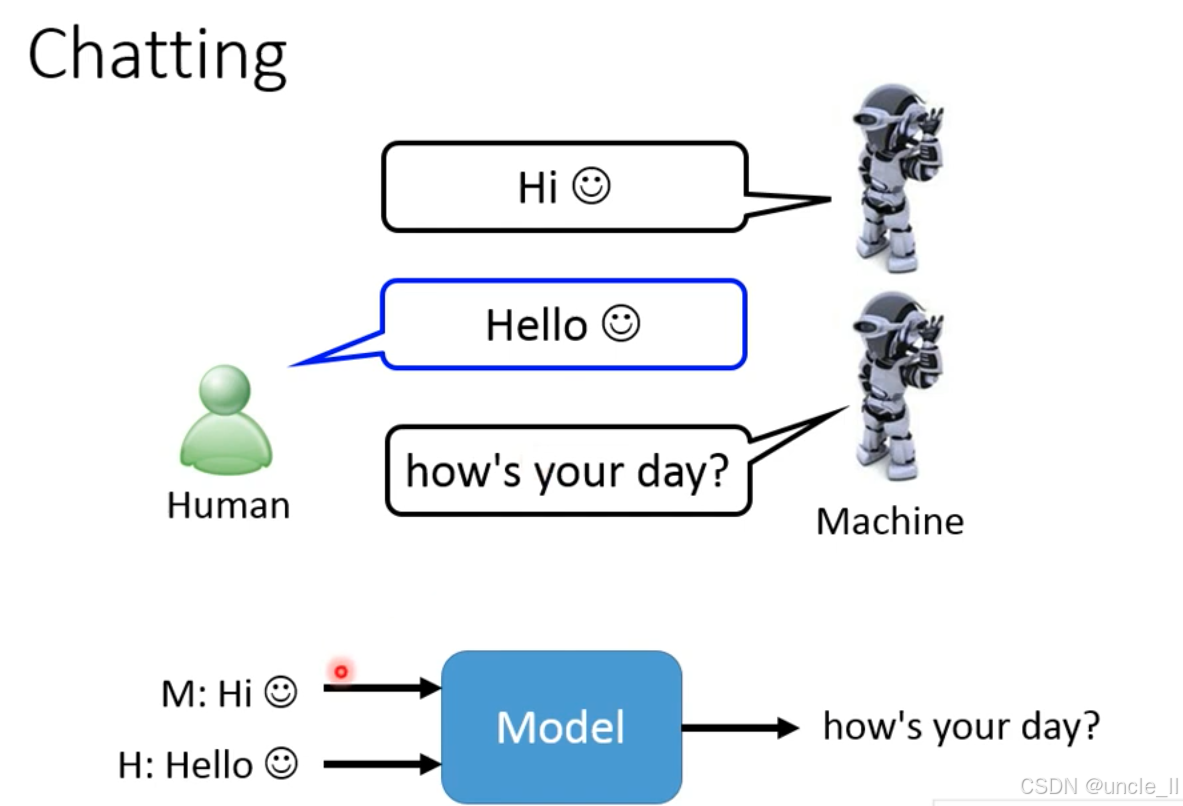
聊天机器人(对话系统) 的核心交互逻辑,属于自然语言处理中多序列输入→序列输出的对话生成任务:
- 交互场景:机器(Machine)先发起对话Hi 😊,人类(Human)回复Hello 😊,机器接着生成下一轮回复 how’s your day?,模拟自然的人机聊天流程。
- 技术流程:模型的输入是历史对话序列(机器的 Hi 😊+ 人类的Hello 😊),输出是下一轮回复序列(how’s your day?)。
- 任务本质:属于上下文感知的序列生成任务,模型需理解对话的历史语境,生成连贯、符合人类交流习惯的回复,实现人机之间的自然语言交互(如闲聊、任务导向对话等场景)。
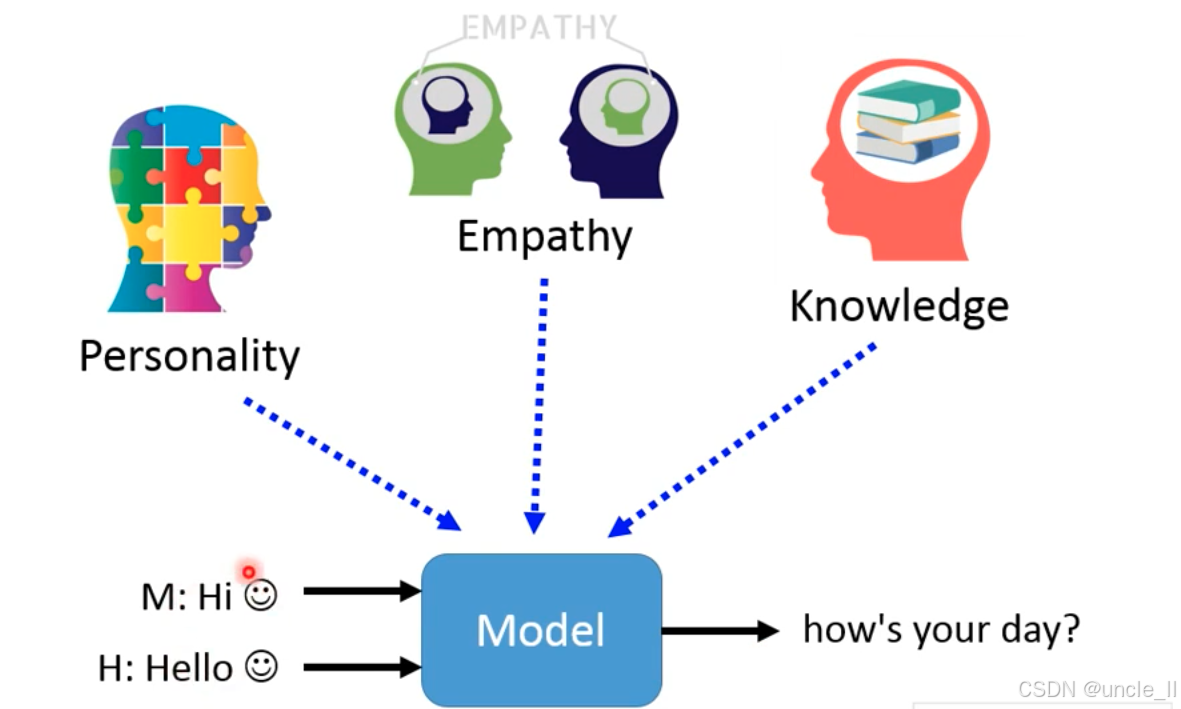
高阶聊天机器人(对话系统)的设计逻辑,核心是在基础交互之上,融入人格、共情、知识三大维度,让对话更具人性化和实用性:
- Personality(人格):对话系统需具备独特性格(如活泼、沉稳等),使回复风格统一且有辨识度。
- Empathy(共情):系统要理解并回应人类情绪(如用户表达失落时,能给出关怀性回复)。
- Knowledge(知识):系统需具备领域知识或常识,确保回复准确、有信息量(如回答科普问题、生活常识等)。
模型(Model)接收历史对话序列(机器的 “Hi 😊” + 人类的 “Hello 😊”),并融合人格、共情、知识三大要素,最终生成自然连贯的下一轮回复(如 “how’s your day?”)。
- Task-oriented 任务导向型对话:核心是围绕完成特定任务展开的多轮交互
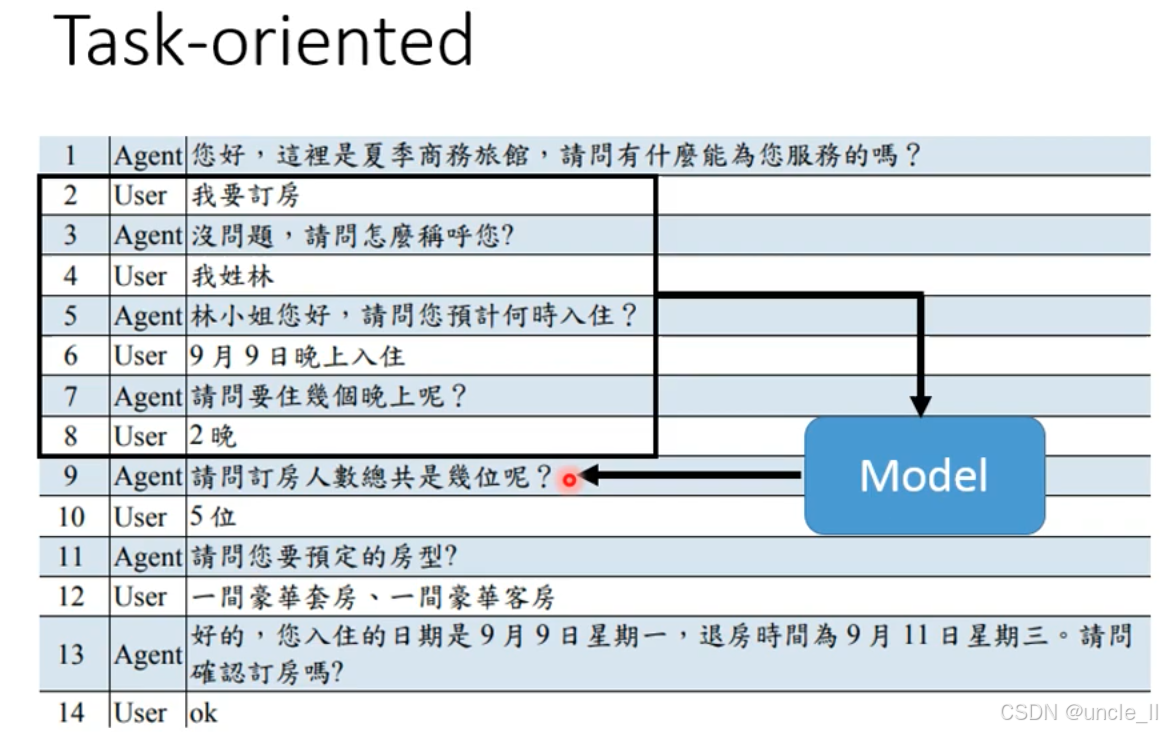
对话通过多轮交互收集关键信息(槽位),逐步推进任务:
- 意图识别:用户(第 2 轮)明确 “我要订房”,Agent 识别任务意图后,开始收集订房所需的核心信息;
- 槽位填充:Agent 依次询问并收集:
- 用户姓名(第 3-4 轮);
- 入住时间(第 5-6 轮);
- 住宿晚数(第 7-8 轮);
- 订房人数(第 9-10 轮);
- 房型(第 11-12 轮);
- 信息确认:Agent 整理所有信息(入住 / 退房时间、房型等),请用户最终确认(第 13-14 轮),完成订房任务。
- 目标明确:以完成特定任务(如订房、订票、查询)为核心,交互围绕任务需求展开;
- 槽位驱动:需收集任务相关的关键信息(如姓名、时间、人数、房型等槽位),信息收集完整后任务才能完成;
- 多轮引导:通过系统的主动询问,引导用户补充信息,形成提问 - 回答的交互闭环。
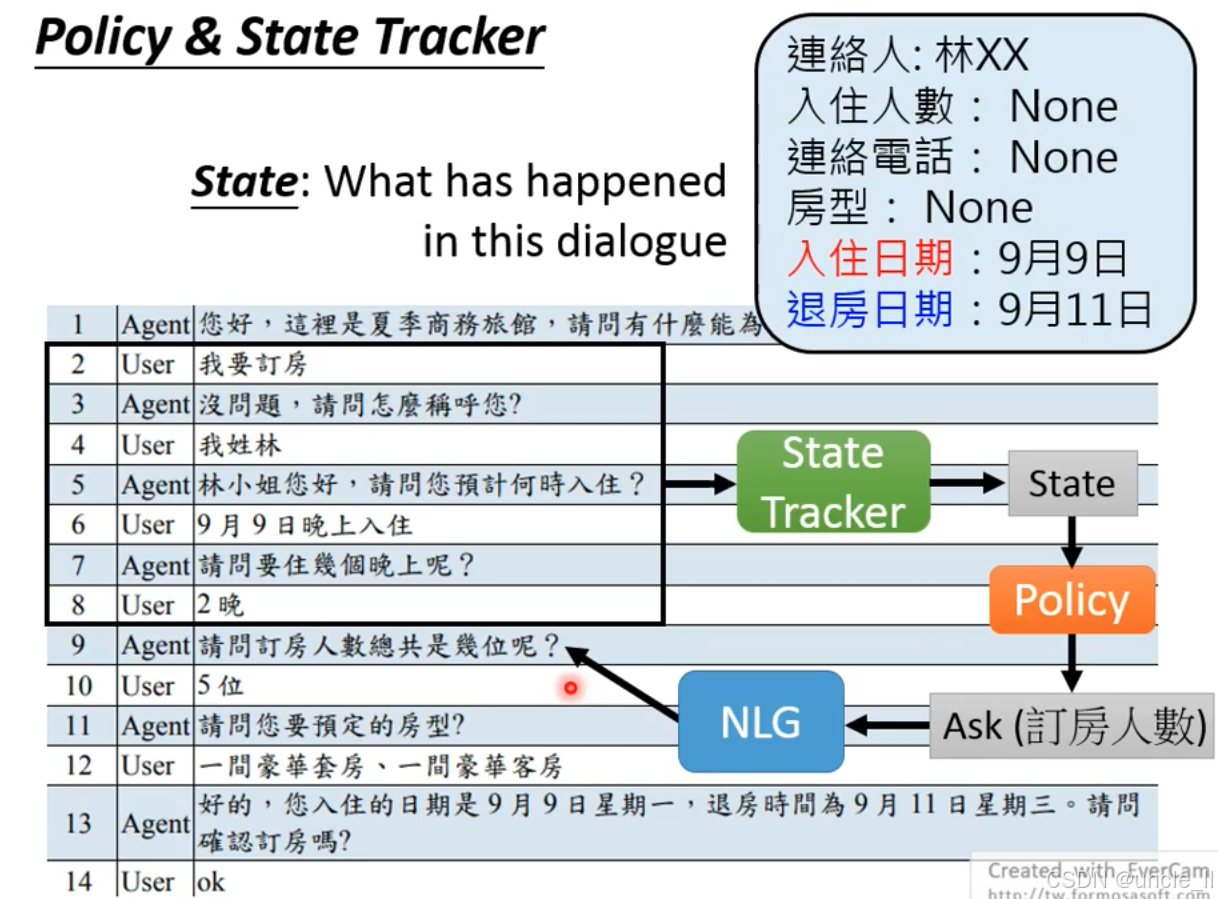
对话系统的记忆 - 决策逻辑:状态追踪器记录对话进度(已收集 / 未收集的信息),为策略模块提供依据,确保系统高效完成订房等特定任务。
这类对话系统广泛应用于智能客服、语音助手等场景(如订机票、查快递、酒店预订),核心价值是通过高效的多轮交互,精准完成用户的任务需求。
Natural Language Understanding NLU
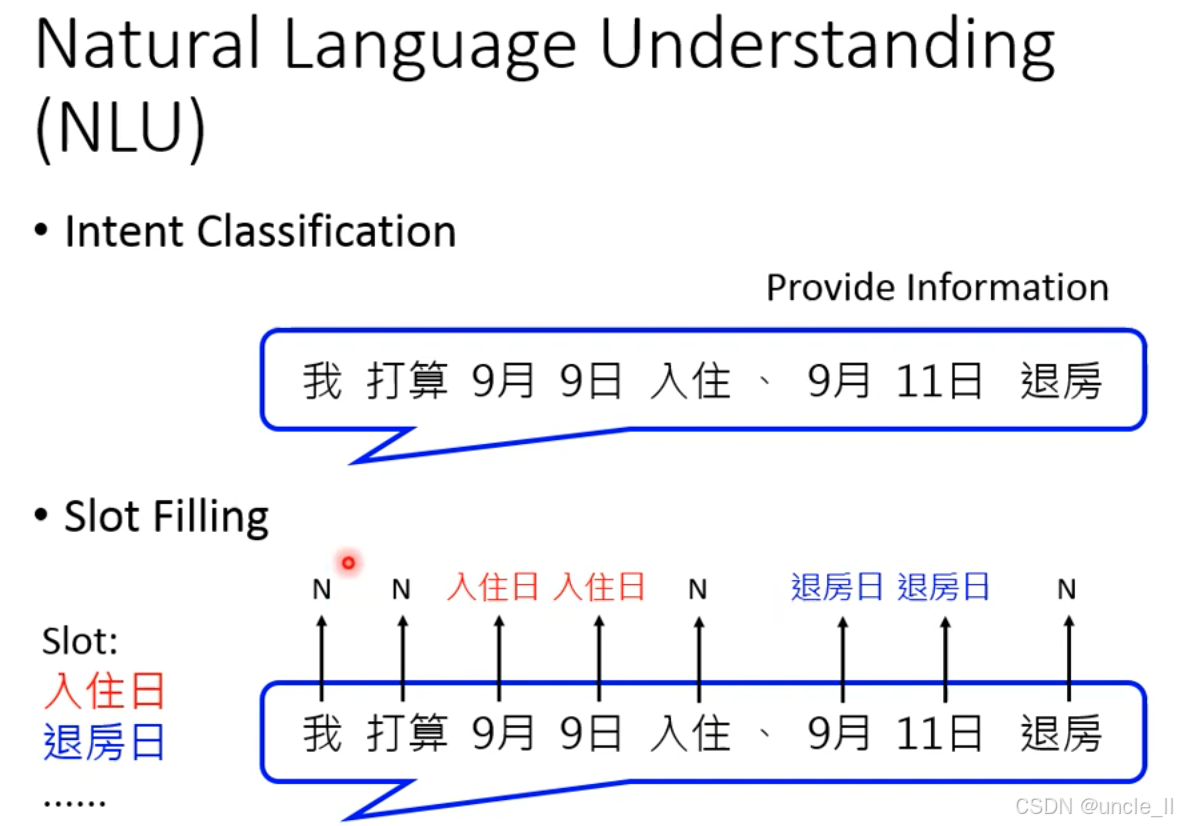
NLU 是对话系统(尤其是任务导向型对话)的理解中枢:通过意图分类明确用户目的,通过槽填充提取关键信息,为后续的对话策略决策任务执行提供精准的语义理解基础。
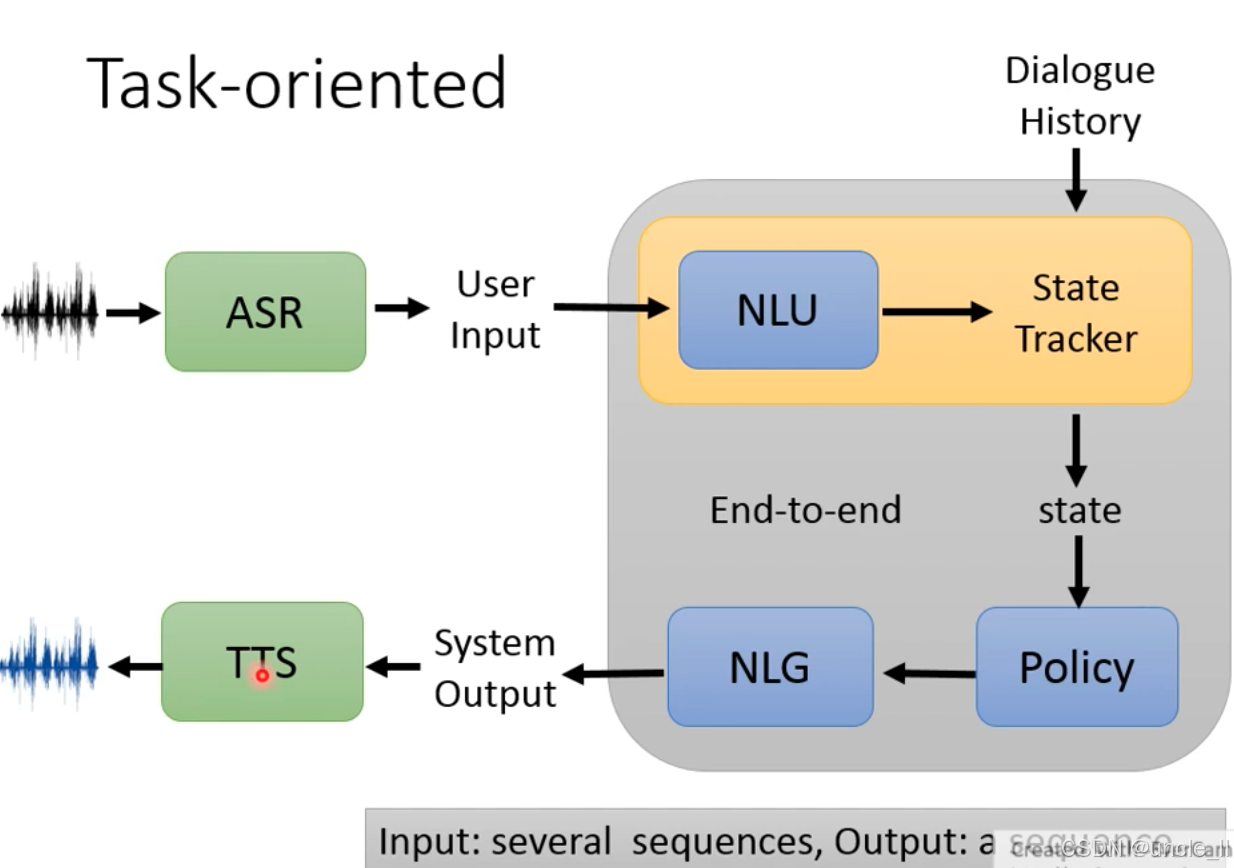
任务导向型对话系统的完整技术架构,清晰呈现了从用户语音输入到系统语音输出的全流程模块协作,以下是分层解析:
- 语音输入与识别
- 模块:ASR(Automatic Speech Recognition,自动语音识别)
- 作用:将用户的语音输入(波形图)转换为文本形式的 User Input,实现 “让系统听懂语音” 的第一步。
2. 自然语言理解与状态管理(NLU + State Tracker)
-
NLU(Natural Language Understanding,自然语言理解:解析 User Input 的意图(用户想做什么)和槽位(关键信息,如订房的时间、人数等),为后续决策提供语义基础。
-
State Tracker(状态追踪器):结合Dialogue History(对话历史)和 NLU 的输出,实时跟踪对话的状态
(已收集信息、缺失信息、任务进度等)。
3. 对话策略与回复生成(Policy + NLG)
- Policy(策略模块):根据当前
state(状态)决定下一步行动(如继续询问缺失信息、确认任务完成等),生成对话策略。 - NLG(Natural Language Generation,自然语言生成):依据 Policy 的决策,生成文本形式的 System Output(系统回复)。
4. 语音输出(TTS)
- 模块:TTS(Text-to-Speech,语音合成)
- 作用:将 System Output 的文本转换为语音输出(波形图),让用户 “听到” 系统的回复,完成交互闭环。
这是一个端到端(End-to-end)的任务导向对话流程:用户语音 → ASR 转文字 → NLU 理解 → 状态追踪 → 策略决策 → NLG 生成回复 → TTS 转语音 → 用户接收。输入是多个序列(语音、对话历史等),输出是一个序列(系统的语音回复)。该架构广泛应用于智能客服、语音助手等场景(如订酒店、查航班),核心是通过多模块协作,高效完成用户的任务需求。
Knowledge Graph
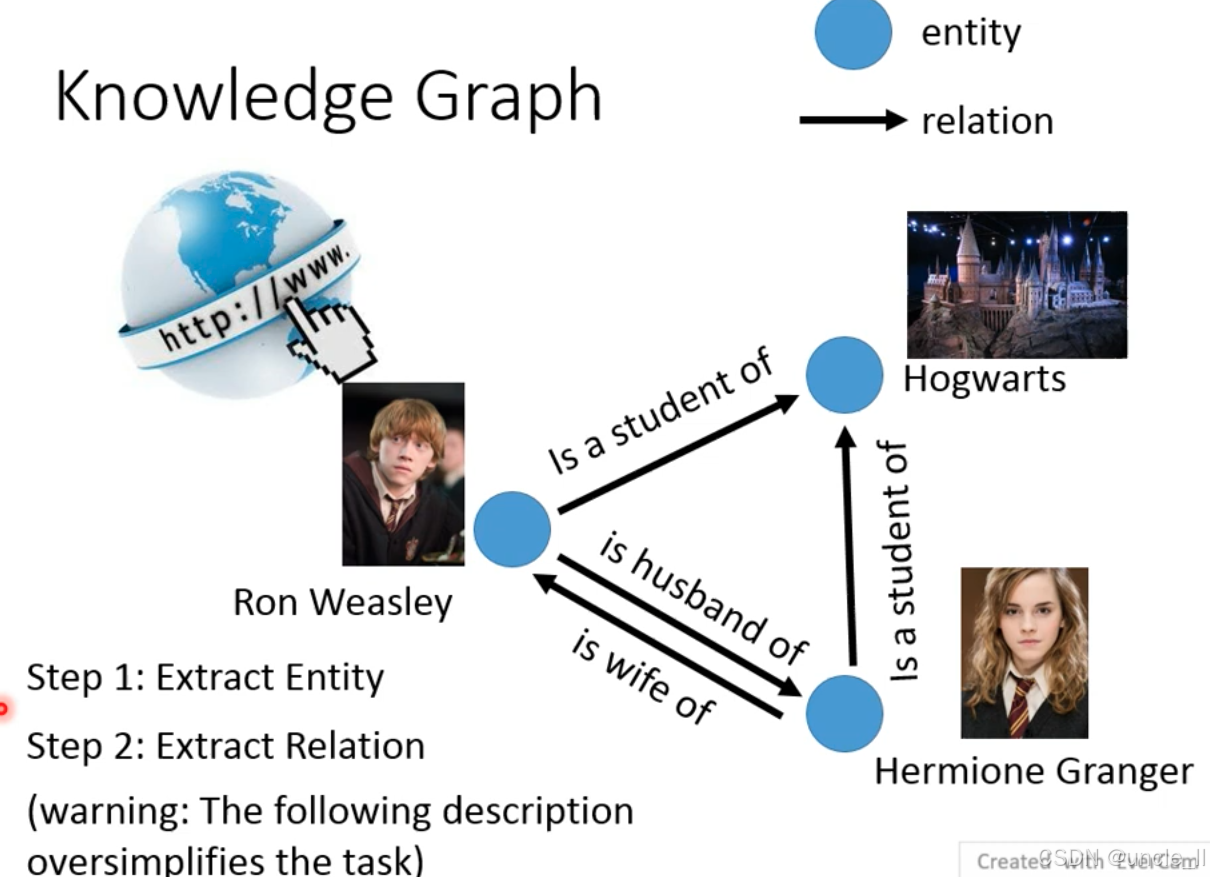
知识图谱(Knowledge Graph)的构建流程,以《哈利・波特》的角色关系为例,拆解为两个核心步骤,以下是详细解析:
-
Step 1: Extract Entity(提取实体)
从网络等信息源中识别出知识图谱的节点(实体)。图中示例的实体包括:
Ron Weasley(罗恩・韦斯莱)、Hogwarts(霍格沃茨魔法学校)、Hermione Granger(赫敏・格兰杰)。 -
Step 2: Extract Relation(提取关系)
识别实体之间的 边(语义关联)。图中示例的关系包括:
Is a student of(是…… 的学生)、is husband of/is wife of(婚姻关系)。
实际知识图谱构建更复杂。其核心价值是将零散的信息组织成 实体 - 关系 - 实体的结构化网络,让机器能理解并推理现实世界的语义关联,广泛应用于智能问答、搜索引擎、知识推理等领域。
Name Entity Recognition NER 命名实体识别

命名实体识别是自然语言处理中的序列标注任务:
- 输入:文本序列(如句子 “Harry Potter is a student of Hogwarts and lived on Privet Drive.”);
- 输出:每个词(token)的实体类别(如人物、组织、地点等)。
以《哈利・波特》的句子为例:
Harry Potter(红色标注)→ 属于people(人物) 类别;Hogwarts(绿色标注)→ 属于organizations(组织) 类别;Privet Drive(紫色标注)→ 属于places(地点) 类别。
NER 的核心是识别文本中具有特定意义的实体,与词性标注(POS tagging),槽填充的技术形态类似(都是对词进行类别标注)。它是知识图谱构建、信息抽取、智能问答等任务的基础技术(只有先识别出实体,才能进一步分析实体间的关系)。
Relation Extraction 关系抽取
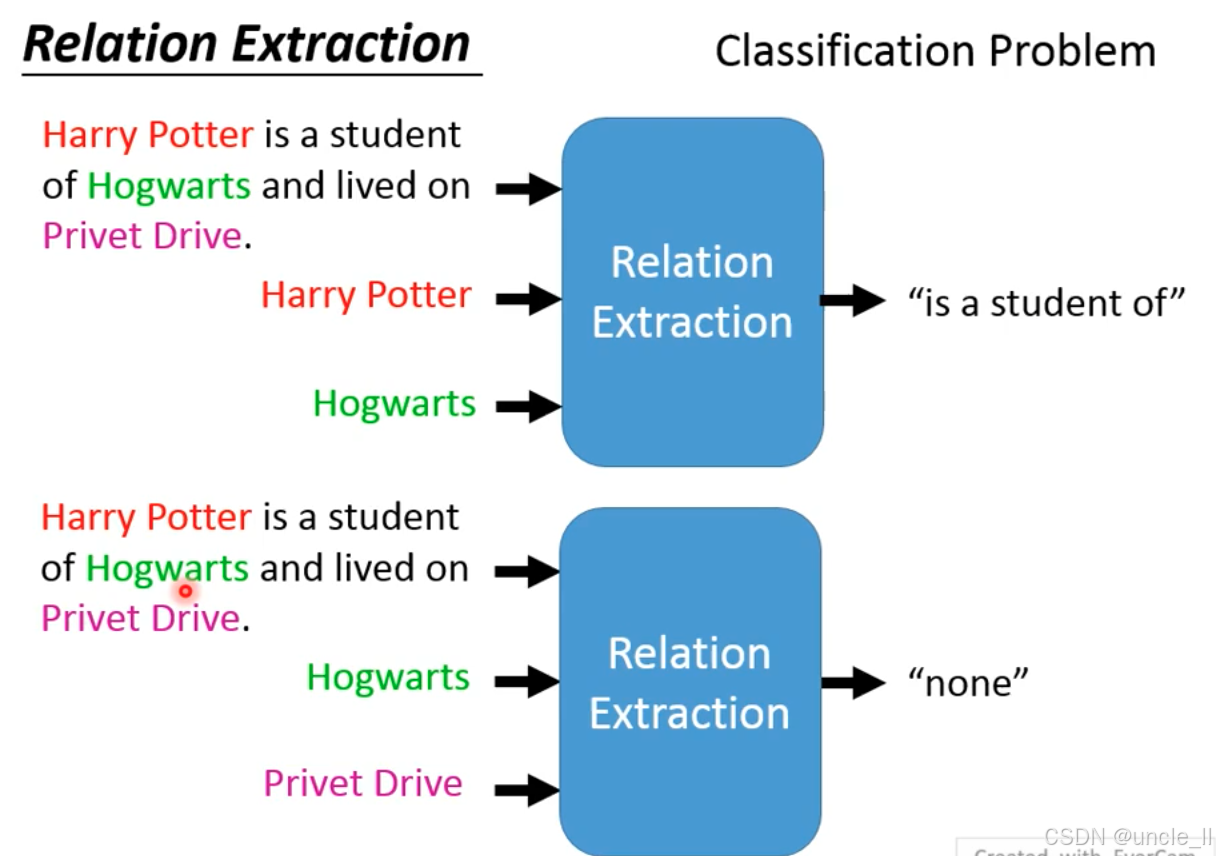
关系抽取的目标是判断两个实体之间的语义关系,输出具体关系类型或无关系(none)。
以《哈利・波特》的句子为例:
- 上图:输入实体
Harry Potter(红色)和Hogwarts(绿色),模型输出关系 “is a student of”(表示 “是…… 的学生”); - 下图:输入实体
Hogwarts(绿色)和Privet Drive(紫色),模型输出 “none”(表示两者无明确语义关系)。
关系抽取是**实体对→关系类别的分类问题 **:给定两个实体,模型需判断它们之间是否存在预定义的语义关系(如 师生,居住,所属等),是知识图谱构建、信息抽取的核心技术之一(只有明确实体间的关系,才能构建结构化的知识网络)。
GLUE

通用语言理解评估基准(General Language Understanding Evaluation, GLUE)的构成,它是自然语言处理(NLP)领域用于衡量模型通用语言理解能力的重要基准集合,包含多个子任务数据集:
- CoLA(Corpus of Linguistic Acceptability):判断句子的语法可接受性(单句分类任务)。
- SST-2(Stanford Sentiment Treebank):情感分类任务,判断句子的情感倾向(正面 / 负面)。
- MRPC(Microsoft Research Paraphrase Corpus):判断两个句子是否为释义(语义等价)。
- QQP(Quora Question Pairs):判断 Quora 平台上的两个问题是否语义等价。
- STS-B(Semantic Textual Similarity Benchmark):评估两个句子的语义相似度(回归任务)。
- MNLI(Multi-Genre Natural Language Inference):多类型自然语言推理,判断句子对的逻辑关系(蕴含、矛盾、中立),覆盖多种文本风格。
- QNLI(Question-answering NLI):基于问答场景的自然语言推理,判断问题与段落是否存在蕴含关系。
- RTE(Recognizing Textual Entailment):识别文本蕴含关系,是 MNLI 的子集,任务更具挑战性。
- WNLI(Winograd NLI):解决代词指代等歧义的自然语言推理,属于常识推理任务。
GLUE 还有中文版本(CLUE),用于评估中文 NLP 模型的通用语言理解能力,是国内 NLP 领域的重要基准。

Super GLUE基准的核心任务与示例,它是自然语言处理(NLP)领域用于评估模型复杂语言理解与推理能力的进阶基准,以下是详细解析:
-
BoolQ:布尔问答任务,给定一段文本(Passage)和问题,回答 “是 / 否”。
示例中,文本介绍 Barq’s 是美国软饮品牌,由可口可乐公司 bottling,问题 “Barq’s root beer 是百事产品吗?” 答案为No。
-
CB:文本蕴含任务,判断 “假设(Hypothesis)” 与 “文本(Text)” 的逻辑关系(蕴含、矛盾、未知)。
示例中,文本讨论雇主支持的儿童保育中心,假设 “他们在引领趋势”,其蕴含关系为Unknown。
-
COPA:因果推理任务,给定 “前提(Premise)”,从两个选项中选正确的 “原因 / 结果”。
示例中,前提是 “身体在草地上投下阴影”,原因是 “太阳升起(Alternative 1)”,因此Correct Alternative 为 1。
-
MultiRC:多选项阅读理解任务,给定段落和问题,判断多个候选答案的真假。
示例中,段落讲述 Susan 办派对,所有朋友最终都到场,问题 “她生病的朋友是否康复?” 因朋友到场,说明康复,故 “ Yes, she was at Susan’s party (T)” 为正确判断。
Super GLUE 是 GLUE 的升级版,聚焦更复杂的语言推理场景(如因果、多轮常识推理、布尔问答等),其网址为https://super.gluebenchmark.com/,是衡量 NLP 模型 “深度理解与推理能力” 的重要参考标准。

DecaNLP(由 Salesforce 提出,网址https://decanlp.com/)的核心概念:它是一个多任务自然语言处理基准,类比田径十项全能(Decathlon),要求同一个模型解决 10 类不同的 NLP 任务,以下是详细解析:
DecaNLP 的设计理念是用一个模型应对多类 NLP 任务,类似于QA问题
-
问答(Question Answering):
问题:“南加州对加州和美国的主要重要性是什么?”
上下文:“Southern California is a major economic center for the state of California and the US…”
答案:
major economic center(直接从上下文中抽取)。 -
机器翻译(Machine Translation):
英文原文:“Most of the planet is ocean water.”
德语翻译:
Der Großteil der Erde ist Meerwasser。 -
文本摘要(Text Summarization):
原文:“Harry Potter star Daniel Radcliffe gains access to a reported £320 million fortune…”
摘要:
Harry Potter star Daniel Radcliffe gets £320M fortune…(提炼核心信息,简化表达)。 -
自然语言推理(Natural Language Inference):
前提(Premise):“Conceptually cream skimming has two basic dimensions – product and geography.”
假设(Hypothesis):“Product and geography are what make cream skimming work.”
推理结果:
Entailment(蕴含,即假设可由前提推导得出)。 -
情感分析(Sentiment Analysis):
句子:“A stirring, funny and finally transporting re-imagining of Beauty and the Beast and 1930s horror film.”
情感判断:
positive(正面)。
DecaNLP 旨在推动多任务学习在 NLP 中的发展—— 通过一个模型同时处理问答、翻译、摘要、推理、情感分析等多类任务,检验模型的通用语言理解与泛化能力,是 NLP 领域探索全能型模型的重要尝试。