基于 PyTorch + BERT 意图识别与模型微调
意图识别(Intent Detection)是自然语言处理(Natural Language Processing,NLP)的一个子模块。意图识别说大白话就是:能够理解提炼用户输入的内容最终目的、意图是什么,能够从用户的自然语言中理解他到底想要做什么!所以通常我们会先进行意图分类定义,就那绩效业务来说,一般会定义:
- 发起考核任务 ——> create_task
- 创建考核方案 ——> create_plan
- 查看考核评分 ——> query_score
- 进行任务归档 ——> task_archive
当用户输入:发起张三2026年全年的绩效考核任务,就能把该内容理解为【发起考核任务】——> create_task;将2026年1月份任务就行归档,就理解为【进行任务归档】——> task_archive。
了解了意图识别概念后,接下里先了解一个概念叫做【槽位slot】,槽位是意图识别中的:参数、信息点,是实现具体操作所需的关键数据。还是用上面的案例举例,发起张三2026年全年的绩效考核任务,那么意图和槽位分别是:
- 意图:发起考核任务 ——> create_task
- 槽位:员工名 ——> 张三;时间 ——> 2026年全年;
理解了意图识别和槽位,接下来使用 Pytorch + Bert 实现一个意图识别的代码案例,首先引入pip依赖:
pip install torch transformers datasets scikit-learn numpy
意图识别、模型微调代码如下:
import torch
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
from datasets import Dataset
import numpy as np
from sklearn.metrics import accuracy_score, precision_recall_fscore_support# --------------------------
# 1. 数据准备
# --------------------------
texts = ["我想发起一个考核任务", "启动新的绩效任务", "我要创建任务", "发起考核任务", "新建任务", "我要开始任务", "创建新的考核任务", "帮我发起任务","帮我创建考核方案", "新增考核方案", "我要制定考核计划", "创建考核模板", "我要新增方案", "帮我设计考核方案", "制定新的考核方案", "建立考核方案","我想查看我的考核评分", "查看考核结果", "查询我的绩效", "能不能查一下我的评分", "帮我看考核成绩", "获取考核分数", "查一下我的考核评分", "查询成绩","请将这个任务归档", "归档已完成的任务", "任务完成后归档", "把任务存档", "完成任务归档", "整理任务归档", "归档考核任务", "任务处理完毕归档"
]labels = ["create_task","create_task","create_task","create_task","create_task","create_task","create_task","create_task","create_plan","create_plan","create_plan","create_plan","create_plan","create_plan","create_plan","create_plan","query_score","query_score","query_score","query_score","query_score","query_score","query_score","query_score","task_archive","task_archive","task_archive","task_archive","task_archive","task_archive","task_archive","task_archive"
]label2id = {label: idx for idx, label in enumerate(sorted(set(labels)))}
id2label = {idx: label for label, idx in label2id.items()}
numeric_labels = [label2id[label] for label in labels]dataset = Dataset.from_dict({"text": texts,"label": numeric_labels
})# 划分训练/验证集
train_test = dataset.train_test_split(test_size=0.2, shuffle=True, seed=42)
train_dataset = train_test["train"]
eval_dataset = train_test["test"]# --------------------------
# 2. 分词
# --------------------------
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")def tokenize(examples):return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=32)train_dataset = train_dataset.map(tokenize, batched=True)
eval_dataset = eval_dataset.map(tokenize, batched=True)train_dataset.set_format(type="torch", columns=["input_ids","attention_mask","label"])
eval_dataset.set_format(type="torch", columns=["input_ids","attention_mask","label"])# --------------------------
# 3. 加载 Bert 模型
# --------------------------
model = BertForSequenceClassification.from_pretrained("bert-base-chinese",num_labels=len(label2id),id2label=id2label,label2id=label2id
)# --------------------------
# 4. 训练参数
# --------------------------
training_args = TrainingArguments(output_dir="./bert_intent_model",evaluation_strategy="epoch",save_strategy="epoch",learning_rate=2e-5,per_device_train_batch_size=8,per_device_eval_batch_size=8,num_train_epochs=15,weight_decay=0.01,logging_dir="./logs",logging_steps=10,load_best_model_at_end=True,metric_for_best_model="accuracy",no_cuda=True
)# --------------------------
# 5. 指标函数
# --------------------------
def compute_metrics(eval_pred):logits, labels = eval_predpreds = np.argmax(logits, axis=-1)precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average="weighted")acc = accuracy_score(labels, preds)return {"accuracy": acc, "precision": precision, "recall": recall, "f1": f1}# --------------------------
# 6. Trainer
# --------------------------
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,compute_metrics=compute_metrics
)# --------------------------
# 7. 训练
# --------------------------
trainer.train()
trainer.save_model("./bert_intent_model")# --------------------------
# 8. 推理函数
# --------------------------
def predict_intent(text):inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=32)with torch.no_grad():outputs = model(**inputs)pred = torch.argmax(outputs.logits, dim=1).item()return id2label[pred]# --------------------------
# 9. 测试 demo
# --------------------------
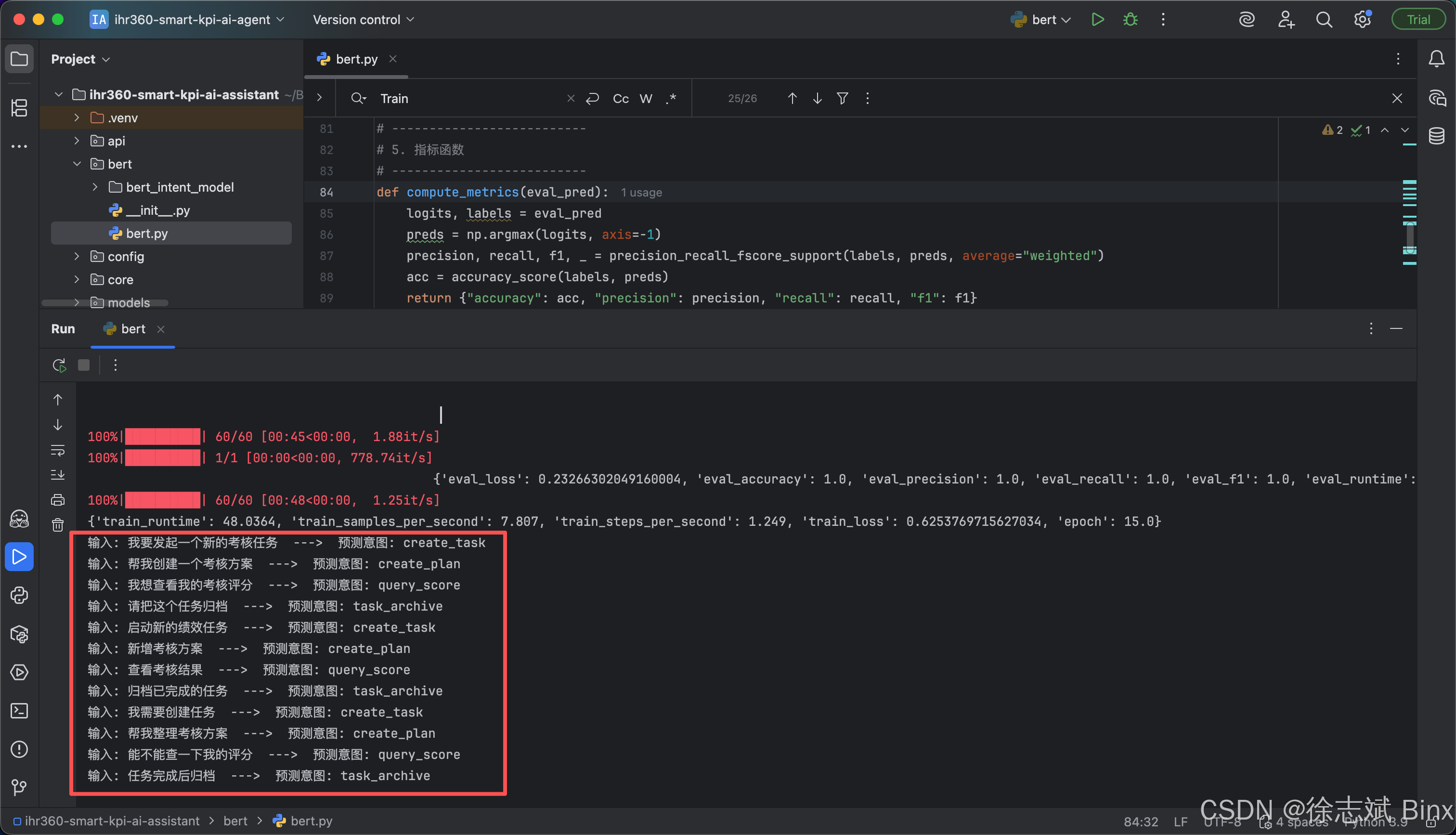
test_texts = ["我要发起一个新的考核任务","帮我创建一个考核方案","我想查看我的考核评分","请把这个任务归档","启动新的绩效任务","新增考核方案","查看考核结果","归档已完成的任务","我需要创建任务","帮我整理考核方案","能不能查一下我的评分","任务完成后归档"
]for text in test_texts:intent = predict_intent(text)print(f"输入: {text} ---> 预测意图: {intent}")
最终测试结果: