【动态高斯重建】论文集合:从4DGT到OMG4、4DSioMo
文章目录
- 一、4DGT:单目视频的 4DGS Transformer
- 摘要
- 1.前馈动态高斯预测(Feed-Forward Dynamic Gaussian Prediction)
- 2.Multi-level Pixel & Token Density Control (多层像素/token密度控制)
- 三、训练
- 四、实现细节
- 五、实验
- 二、OMG4:优化最小4D高斯泼溅
- 摘要
- 1、预备知识
- 2、高斯采样
- 3、高斯剪枝
- 4、高斯融合
- 5. 属性压缩
- 6.实验结果
- 三、4DSiOMo:异步采集的高速场景4D重建
- 1.准备知识: 4D Gaussian Splatting
- 2. 异步捕获方案
- 3.Artifact-fix (专修复伪影的)视频扩散模型
- 4.扩散先验的4D重建
- 5.实验
一、4DGT:单目视频的 4DGS Transformer

标题:4DGT: Learning a 4D Gaussian Transformer Using Real-World Monocular Videos
来源:Meta 现实实验室;浙江大学
项目主页:https://4dgt.github.io
摘要
4DGT——基于Gaussian Splating的 4D Transformer,专为动态场景重建设计,其训练数据完全来自真实场景的单目posed视频。通过将4DGS作为归纳偏置,该模型成功融合静态与动态元素,能够建模具有不同物体生命周期的复杂时变环境。我们在训练中创新性地引入密度控制策略,使4DGT既能处理更长的时空输入数据,又能在运行时保持高效渲染。模型采用滚动窗口方式处理64帧连续posed画面,持续预测场景中的4DGS。与基于优化的方法不同,4DGT采用纯前馈推理架构,将重建时间从数小时缩短至数秒,并能有效扩展到长视频序列。仅需在大规模单目posed视频数据集上训练,4DGT在真实场景视频中显著超越传统高斯网络,并在跨域视频中达到与优化方法相当的精度水平。
1.前馈动态高斯预测(Feed-Forward Dynamic Gaussian Prediction)
输入编码。输入单目视频,提取一组带有相机校准参数PiP_iPi和时间戳TiT_iTi的图像帧IiI_iIi,表示为 {Ii∈RH×W×3,Pi∈RH×W×6,Ti∈RH×W×1∣i=1⋅⋅⋅NI_i∈R^{H×W×3},P_i∈R^{H×W×6},T_i∈R^{H×W×1}|i=1···NIi∈RH×W×3,Pi∈RH×W×6,Ti∈RH×W×1∣i=1⋅⋅⋅N},PiP_iPi表示Plücker坐标。我们将这些帧转换为图像patch:{Ii,j∈Rp×p×3∣j=1⋅⋅⋅HW/p2I_{i,j}∈R^{p×p×3}|j=1···HW/p^2Ii,j∈Rp×p×3∣j=1⋅⋅⋅HW/p2}、{Ti,jT_{i,j}Ti,j}和{Pi,jP_{i,j}Pi,j},ppp 为 patch size。
特征融合。用预训练的DINOv2图像编码器提取C维高阶特征 Fi,j∈RCF_{i,j}∈R^CFi,j∈RC,将其与时间编码Ti,jT_{i,j}Ti,j、空间编码Pi,jP_{i,j}Pi,j以及输入的RGB图像$I_{i,j}拼接,形成Transformer输入:
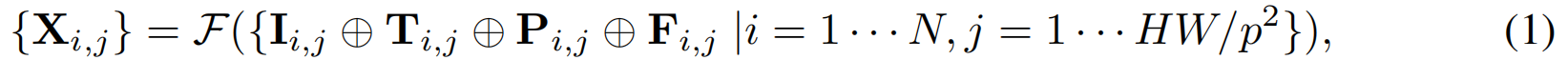
FFF表示all-to-all self-attention 自注意力transformer。与ViT不同(仅使用静态LRMs作为输入),4DGT同时采用带时间戳的Plucker射线和DINO特征作为输入。
动态高斯。为表征几何形态,采用 由中心点x∈R3x∈R^3x∈R3、尺度s∈R2s∈R^2s∈R2、不透明度o∈R1o∈R^1o∈R1及方向q∈R4q∈R^4q∈R4(四元数)定义的2DGS ,比3DGS能更精准地预测几何形态。
为表征运动状态,为动态GS定义四个时间属性:时间中心c∈R1c∈R^1c∈R1、life-span(寿命)l∈R1l∈R^1l∈R1、速度v∈R3v∈R^3v∈R3 以及角速度ω∈R3ω∈R^3ω∈R3 (作为angle-axis)。我们根据特定时间戳 tst_sts ,来计算特定高斯点 g=g=g={x,s,q,o,c,l,v,ωx,s,q,o,c,l,v,ωx,s,q,o,c,l,v,ω}的不透明度、位置和方向偏移量[63]。具体而言,寿命lll用于影响高斯点随时间变化的不透明度 ooo。

otho_{th}oth是寿命边界处的不透明度系数,σσσ是时间域高斯的标准差。直观来说,高斯会在时间轴中心保持完全不透明,沿时间轴方向则以高斯分布形式逐渐变淡。在时间中心c的 l/2l/2l/2处,该点的不透明度会通过乘以较小的系数otho_{th}oth变小(实验中为0.05)。
每个高斯的位置和方向会根据速度 vvv和角速度ωωω进行调整,以适应运动状态:

其中ϕϕϕ表示将角度轴表示转换为四元数,在时间戳tst_sts处用光栅化器来渲染 2DGS(xts,sts,qts,otsx_{ts},s_{ts},q_{ts},o_{ts}xts,sts,qts,ots).
动态高斯解码。给定像素对齐特征{xi,j},用一个transformer来解码每帧的像素对齐4DGS:
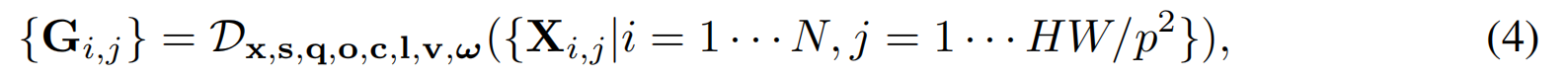
其中Dx,s,q,o,c,l,v,ωD_{x,s,q,o,c,l,v,ω}Dx,s,q,o,c,l,v,ω表示基于MLP的解码器头,用于生成完整的动态高斯参数集合{Gi,jG_{i,j}Gi,j}。
提出的4DGS模型能统一预测静态与动态元素的外观及几何属性。对于静态场景,该网络可学习预测具有长寿命(l→∞,v→0,ω→0)的高斯;而对于存在遮挡的复杂动态运动场景,它则能预测具有短寿命(l→0)的瞬态动态物体。
2.Multi-level Pixel & Token Density Control (多层像素/token密度控制)
虽然像素级对齐的高斯曾是早期研究[Gs-lrm,Long-lrm]的常用方案,但在处理需要密集长期采样才能有效捕捉运动的视频帧时存在明显短板。若简单地进行时空采样,将面临两大核心问题:首先,对齐高斯数量的增加会拖累优化和渲染性能,导致训练效果欠佳且动态区域细节模糊;其次,输入token数量的激增会大幅增加计算成本,最终造成模型训练不足。
两阶段训练。首先,从零开始对粗采样低分辨率图像进行训练直至收敛。在第二阶段,受3DGS[19]启发,我们提出通过以下方式过滤像素对齐高斯:基于直方图对每个图像块进行低透明度预测的剪枝处理,并通过增加token数量来预测更多时空分布的高斯。此外,我们引入多层级时空注意力机制,进一步降低自注意力层的计算成本。
patch内剪枝。粗分辨率训练后,由于每个图像patch的激活高斯直方图中,仅有少数通道被激活,所以使用激活通道,仅解码少量高斯。具体而言,对于每个高斯参数块 Gi,jG_{i,j}Gi,j,我们计算其不透明度值 oi,j=o_{i,j}=oi,j={oi,j,k∣k=1⋅⋅⋅p2o_{i,j,k}|k=1···p^2oi,j,k∣k=1⋅⋅⋅p2}的标准差:
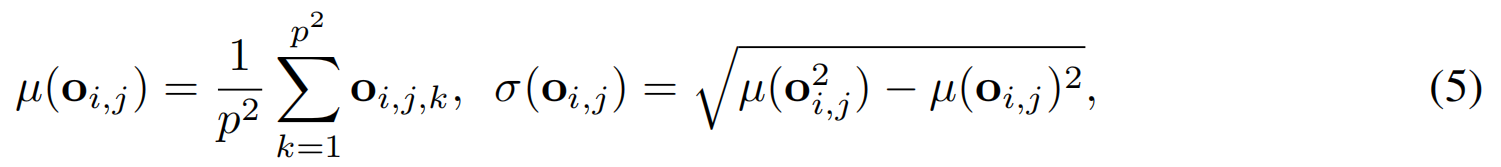
当像素 kkk 的数值超过标准差1个单位时,该像素即被视为激活 :
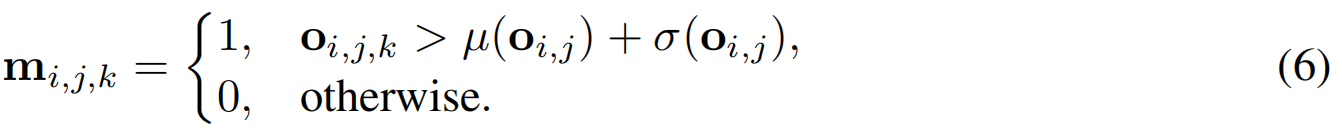
kkk表示patch的索引,mi,j,km_{i,j,k}mi,j,k表示像素是否被激活。patch输出的激活掩码 mi,jm_{i,j}mi,j={mi,j,k∣k=1⋅⋅⋅p2mi,j,k|k=1···p^2mi,j,k∣k=1⋅⋅⋅p2}的直方图 hi,jh_{i,j}hi,j为

后续训练中则从直方图hi,jh_{i,j}hi,j中选取S通道作为patch输出。这种做法相当于将每个补丁的高斯分布数量削减了S/p2S/p^2S/p2倍,效仿了3DGS的剪枝策略。针对这种基于直方图的剪枝策略,我们通过补充材料中的可视化图表,对其与替代方案进行了更深入的对比分析
稠密化。预测的高斯数量会随着时空token输入的增加而自然增长,无论是单帧分辨率还是时间帧数的提升。训练的第二阶段,分别将空间分辨率和时间分辨率提升为RsRsRs和RtRtRt倍。结合稠密化与剪枝策略,相较于第一阶段,最终生成的高斯数量将增加Rs2⋅Rt⋅S/p2R_s^2·R_t·S/p^2Rs2⋅Rt⋅S/p2倍。我们在所有实验中选择Rs=2、Rt=4、S=10、p=14的参数组合,这使得最终生成的高斯数量仅占原始数量的80%,同时将时空采样率提升了16倍。
多level的时空注意力机制。自注意力模块F参与的patch数量会按Rs2⋅RtR_s^2·R_tRs2⋅Rt倍数增长,这将显著拖慢模型优化和推理速度。为缓解这一问题,我们 通过更改时间跨度和空间分辨率 ,构建 temporal level-of-detail 注意力以降低计算成本,并保持处理长时间窗口能力:将NNN 帧输入划分为最高level的M个trunk。这种划分把注意力限制在了时间窗口上,将计算nnn个token的运算复杂度降至 O(n2/M)O(n²/M)O(n2/M)。对于每个level lll,空间分辨率降低2的 lll 次方倍,同时将时间跨度增加2倍。实验中采用层级L=3和M=4的配置,这使得计算成本大约降低了一半。
三、训练
损失函数与正则化。我们使用单目视频中连续W=128帧的片段训练4DGT模型,并以每8帧为输入子采样,最终得到N=16帧输入数据。值得注意的是,在第二阶段训练中,我们将输入帧数提升至N=64。通过获取每个输入帧的高斯参数集合 {Gi,jG_{i,j}Gi,j}后,将其渲染为W=128帧图像用于自监督学习,并计算MSE损失。此外,我们还引入了其他损失提升视觉效果:
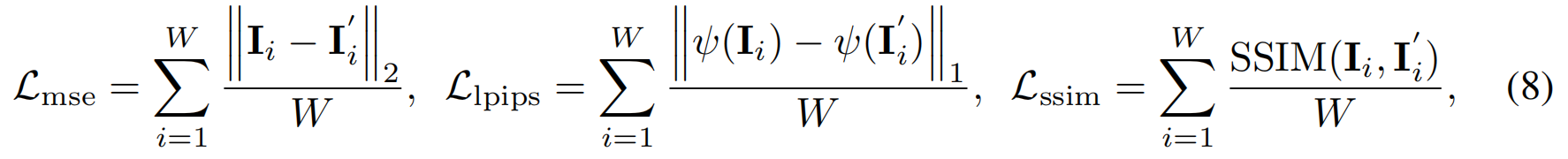
正则化鼓励将点设置为静态并延长生命周期:

专家指导。在几何预测训练中采用单目专家模型:用DepthAnythingV2[62]和StableNormal[64]工具,从所有W帧中提取深度图 DiD_iDi和法线图 NiN_iNi,作为伪监督信号(渲染采用2DGS光栅化器):

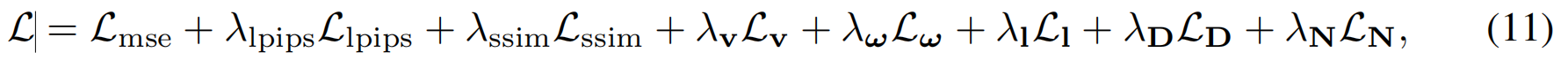
实验均采用统一参数设置:λlpips=2.0、λssim=0.2、λv=1.0、λω=1.0、λl=1.0、λD=0.1、λN=0.01λlpips=2.0、λ_{ssim}=0.2、λ_v=1.0、λ_ω=1.0、λ_l=1.0、λ_D=0.1、λ_N=0.01λlpips=2.0、λssim=0.2、λv=1.0、λω=1.0、λl=1.0、λD=0.1、λN=0.01。在训练的前2500次迭代中,正则化损失函数的权重系数均采用线性热身策略,从初始值逐步调整至最终设定值。
四、实现细节
架构设计。 采用改进版 VisionTransformer(ViT)架构[7]构建融合网络F。具体而言,该网络包含12层全连接自注意力机制,每层配置16个头,每个头的隐藏维度为96,全连接层的隐藏通道宽度扩大至4倍。由于Plucker坐标[P]和时间戳[T]已提供像素的四维空间位置信息,因此无需额外嵌入位置信息。在第二阶段训练中启用多级时空注意力模块时,我们将第一阶段的Transformer权重复制l次并独立训练。第l个Transformer负责处理第l级时空注意力,通过1个分类标记实现不同层级间的跨层信息传递。对于MLP解码器D,我们采用2个全连接层,每个通道的隐藏维度为256。Transformer模块F和G均采用ReLU激活函数[13],并使用层归一化[1]作为归一化函数。同时,我们禁用了所有层的偏置参数。
训练与推理。PyTorch框架[38]中,采用FlashAttentionV3[44]进行高效注意力机制优化,并使用GSplat光栅化器[65]进行高斯优化。优化器选用AdamW[27],学习率设为5e−4,权重衰减为0.05。第二阶段训练将学习率调整为1e−5。此外,我们采用线性热身策略在前2500步逐步提升学习率,后续步骤则采用余弦衰减调度[26]。在第二阶段训练中,我们通过调整图像的长宽比和视场角来增强输入输出数据。具体而言,从[1/3,3/1]的均匀分布中随机采样长宽比,视场角则在原始图像的[30%,100%]范围内选取。第一阶段训练使用64个批次大小,重建模型迭代10万次;第二阶段迭代3万次。在64块Nvidia H100显卡支持下,第一阶段训练耗时约9天,第二阶段约6天。所有推理速度实验均使用单块80G A100显卡进行。
五、实验
训练数据集。以下为经过高精度校准的真实世界单目视频:
- Project Aria 数据集(带闭环轨迹):EgoExo4D[12]、Nymeria[29]、Hot3D[2]和Aria日常活动(AEA)[28];
- 带COLMAP相机参数的视频数据:Epic-Fields[48,6]和Cop3D[45];
- 带ARKit相机位置姿的手机视频:ARKitTrack
验证数据集。采用ADT[34]数据集提供的合成渲染数据(包含深度基准值)。跨域泛化能力的验证,使用DyCheck[11](DyC)数据集和TUM-SLAM[47](TUM)的动态场景进行新视角合成评估。此外,我们从EgoExo4D、AEA和Hot3D数据集中划分出测试集,称为Aria测试集。
指标说明。视觉效果对比了PSNR和LPIPS[68]指标在新视角和时间渲染结果上的表现。几何精度评估则采用深度视差(Depth RMSE)[62]和法线角误差[64]作为对比标准。此外,我们还通过光流和运动分割技术,对二维渲染的运动轨迹进行了定性对比。所有对比实验均基于单目视频的128帧子序列进行,其中64帧作为输入数据,剩余64帧用于测试,图像分辨率统一调整为504×504像素或相近像素数,以确保对比结果的可比性(特殊情况除外)。针对DyCheck[11]数据集,我们特别在测试视角相机上进行了渲染效果对比,该数据集展示了极端视角合成的信号特征。
基准:
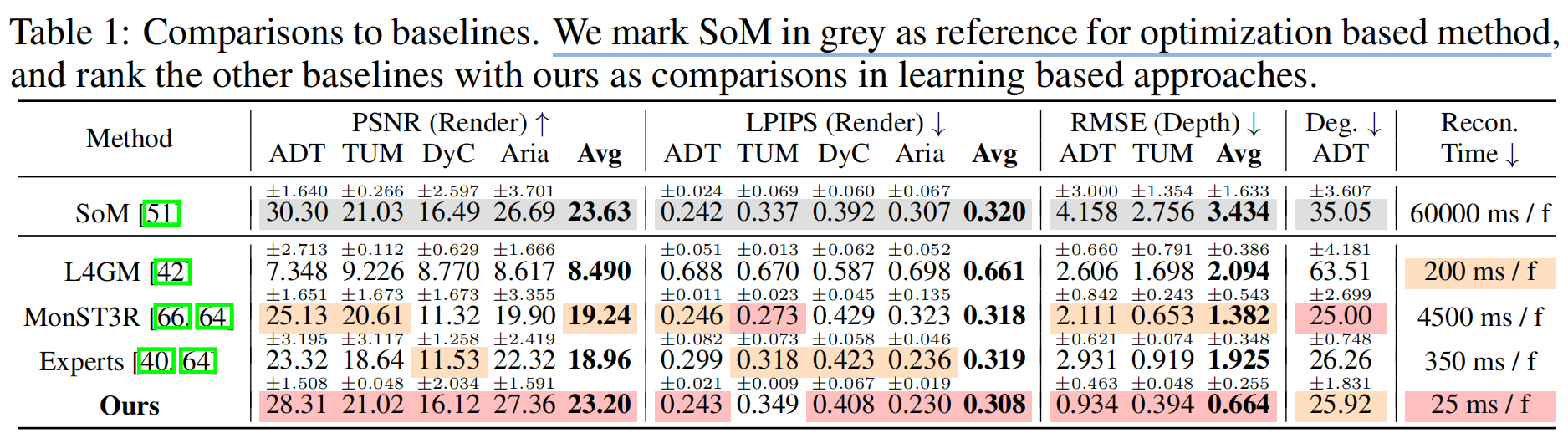
- 1.L4GM:能泛化到真实世界视频的4D高斯模型(基于合成数据),借鉴了ImageDream[50]的多视角扩散先验。
- 2.Static-LRM:我们参照[67]在与4DGT相同的现实数据集上训练了静态场景LRM。我们采用2DGS而非3DGS作为表征方式,这与我们的方法更相似,但进一步建模了动态内容。
- 3.Expert monocular models:我们在相同设置下比较了训练过程中使用的每个专家模型,包括与UniDepth[39]度量尺度对齐的DepthAnythingV2[62]以及由StableNormal[64]提供的法线。在新视角评估中,我们使用最近的深度和法线帧进行图像反投影。
- 4.MonST3R[66]:我们与动态点表征方法[66]进行对比,该方法突出了使用4DGS的表征差异。我们使用官方实现的相机姿态作为输入,并采用PyTorch3D[41]进行法线估计。
- 5.Shape of Motion(SoM)[51]:我们采用SoM作为顶级场景级优化方法的参考,以评估最佳动态重建质量。我们遵循SoM的指导手动分割动态部分,这需要输入掩码、深度和跟踪等专家模型,而我们并未使用这些模型。我们还计入了预处理时间以进行时间对比。
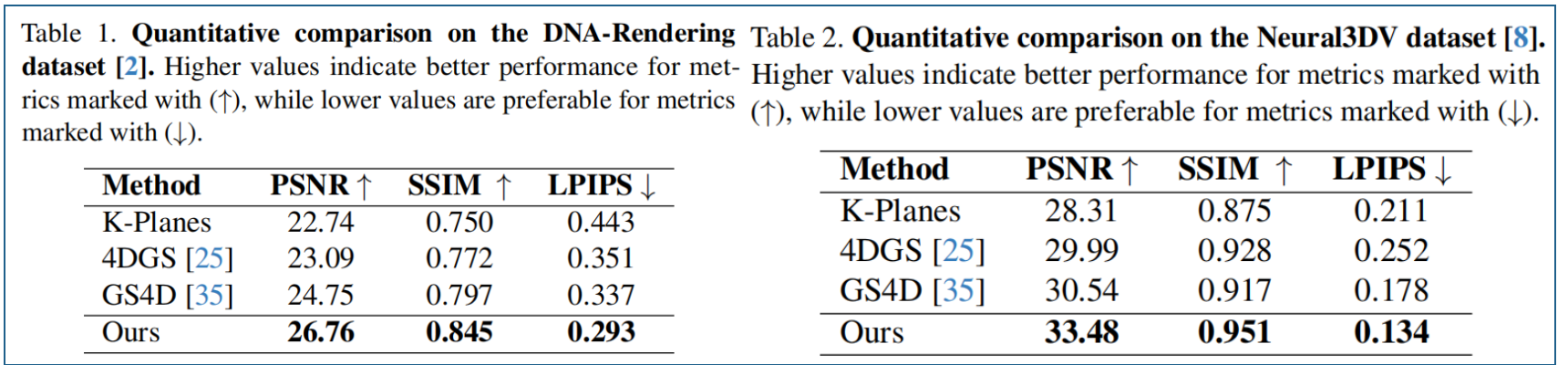
表1和图3基准模型对比结果。相较于同样基于训练好的Transformer预测动态高斯分布的L4GM,4DGT在真实场景中的泛化能力表现更为出色。我们发现静态场景下静态LRM能提供可靠的基准模型,但在存在动态运动时会失效,而4DGT在静态和动态场景中均能表现出色。表2c中的动态区域数据进一步验证了这一结论。在基于度量标准的评估中,4DGT预测的几何结构在世界坐标系下的稳定性优于专家模型。相较于基于优化的SoM方法,4DGT在视图合成和几何预测方面质量相当,同时运行速度提升三个数量级,这使其在实际处理长时长视频时更具优势。


二、OMG4:优化最小4D高斯泼溅
标题:OPTIMIZED MINIMAL 4D GAUSSIAN SPLATTING
来源:1.Yonsei University 2.Seoul National University 3.POSTECH 4.Sungkyunkwan University
项目主页:https://minshirley.github.io/OMG4/
摘要
4DGS技术作为动态场景呈现的新范式崭露头角,能够实时渲染包含复杂运动的场景。然而,该技术面临存储开销过大的主要挑战,因为需要存储数百万个高斯点才能实现高保真重建。尽管已有诸多研究试图缓解这一内存负担,但它们在压缩比或视觉质量方面仍存在局限。本研究提出OMG4(优化最小四维高斯)框架,通过构建精简的高斯点集合来忠实呈现四维高斯模型。我们的方法分三个阶段逐步剪枝高斯点:(1)Gaussian Sampling,筛选对重建保真度至关重要的原始点,(2)Gaussian Pruning 消除冗余,(3)Gaussian Merging,融合特征相似的高斯基元。此外,我们整合了隐式外观压缩技术,并将子向量量化(SVQ)推广至四维表示,进一步在保持质量的同时缩减存储空间。在标准基准数据集上的大量实验表明,OMG4显著优于当前最先进方法,模型体积缩减超60%且保持重建质量。这些成果使OMG4成为紧凑型四维场景呈现的重要突破,为广泛应用场景开辟了新可能。
1、预备知识
我们的框架主要基于Real-Time4DGS(Yang等人,2024)1,该方法将动态场景建模为四维体,通过四维均值、各向异性四维协方差、不透明度参数及球谐函数(SH)系数等参数进行定义。渲染时,四维高斯分布会在时间戳t处进行条件化处理,从而生成三维位置和协方差矩阵。
预训练的Real-Time4DGS模型的高斯分布集合记作 P=P=P={(xi,fi,ai)(x_i,f_i,a_i)(xi,fi,ai)}i=1N^N _{i=1}i=1N,其中xix_ixi表示空间均值(µ1:3µ_{1:3}µ1:3),fi∈R3f_i∈R^3fi∈R3为SH系数的零阶项,aia_iai则包含不透明度、缩放比例和旋转等各原始属性的剩余参数。
2、高斯采样
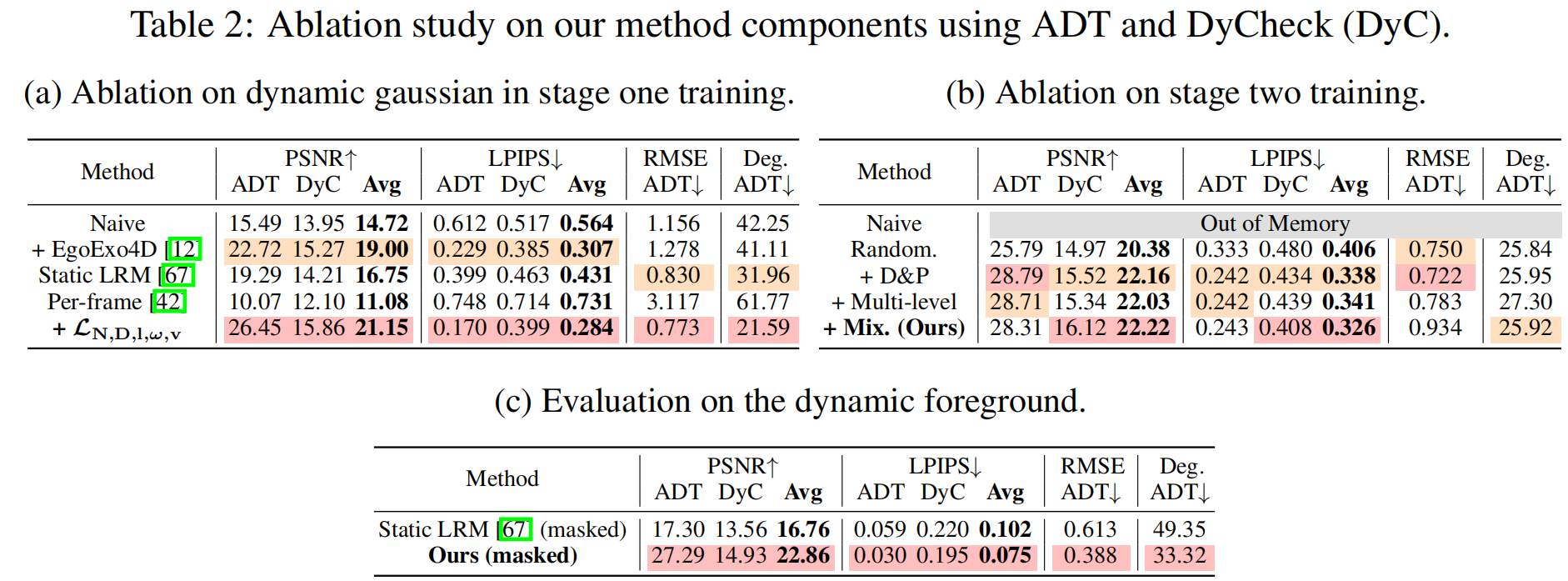
许多高斯基元对重建质量的贡献微乎其微,但这一难题仍未得到彻底解决。本节提出静态-动态评分(SD-Score),通过结合静态评分和动态评分来量化每个高斯的贡献度。 静态区域通常表现为时间维度上持续存在、空间维度上分散分布的高斯,而动态区域则倾向于包含时间维度上短暂存在、空间维度上集中分布的高斯分布。基于这些特性,我们的方法能够识别出显著的高斯(如图3所示),仅保留预训练Real-Time4DGS模型(Yang等人,2024)中20%的高斯即可实现场景重建,且质量损失可忽略不计。
SD分数。本文提出的静态-动态分数(SD分数)用于计算高斯的重要性,其定义如下:
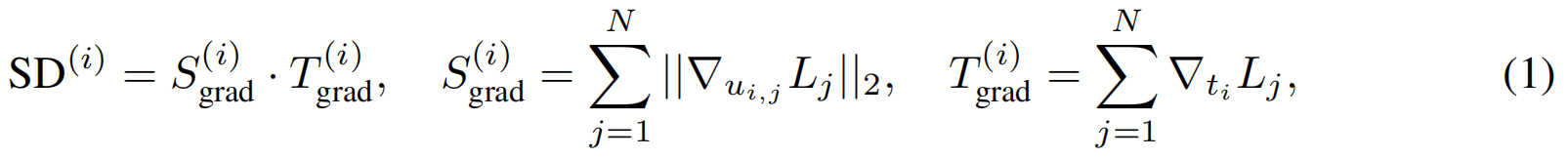
NNN表示输入图像数量,iii为高斯索引,LjL_jLj是输入图像jjj的重构损失,ui,j∈R2u_{i,j}∈R^2ui,j∈R2表示第iii个高斯函数在第jjj幅图像中的二维投影坐标,ti∈Rt_i∈Rti∈R为第iii个高斯函数的时间坐标。
静态评分。第iii个高斯的静态评分Sgrad(i)S_{grad}^{(i)}Sgrad(i)定义为所有时间步长 视图空间梯度的累积值,反映该高斯投影在渲染中的整体敏感度 。在静态区域中,高斯虽然存在时间跨度长但分布稀疏(即单位面积内分布数量较少),因此即使微小的位置扰动也能影响多个时间步长的渲染损失,从而获得更高的静态评分。相比之下,动态区域的高斯分布通常仅在特定时间步长活跃且空间分布密集(例如单位面积内分布数量较多)。因此,单个高斯位置变化对整体重建损失的影响会被稀释,导致静态评分较低
动态评分。第iii个高斯分布的动态评分Tgrad(i)T_{grad}^{(i)}Tgrad(i)是时间梯度的总和,用于衡量重建损失对各高斯时间坐标的敏感度。动态评分较高的高斯通常意味着它们在表征动态区域时起着关键作用,因为这些区域对时间变化敏感,能够捕捉物体的运动轨迹。我们采用带符号的时间梯度而非其绝对值来捕捉一致的时间趋势,这样可以避免给频繁翻转符号(即闪烁)的高斯分配高分,从而增强评分的鲁棒性。

SD分数结合了静态和动态分数,可以对每个高斯的整体贡献进行平衡评估。随后,我们以τGSτ_{GS}τGS的采样率对具有高SD值的高斯采样,形成一组采样高斯PGSP_{GS}PGS,并对其进行TGST_{GS}TGS次迭代。
3、高斯剪枝
虽然具有SD分数的第一个高斯采样阶段产生了一组关键高斯基元,PGSP_{GS}PGS,但它可能仍然包括冗余高斯。高斯剪枝通过消除第一阶段后剩余的多余高斯来进一步细化集合。
图4展示了由SgradS_{grad}Sgrad和TgradT_{grad}Tgrad定义的空间区域,其中曲线Tgrad=c/SgradT_{grad}=c/S_{grad}Tgrad=c/Sgrad表示第一阶段高斯采样阶段的筛选边界 。在该空间内,我们识别出可能冗余的高斯,实证分析表明,同时满足Sgrad(i)S_{grad}(i)Sgrad(i)和Tgrad(i)T_{grad}(i)Tgrad(i)值较小的分布可以过滤掉(图4中的灰色区域)。评分阈值设定如下:
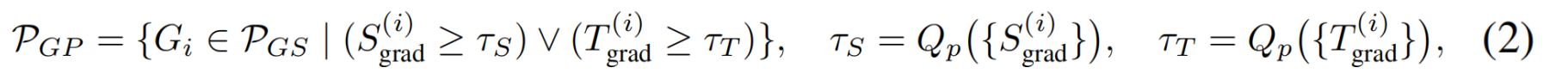

τSτ_SτS和τTτ_TτT分别表示阈值,Qp(⋅)Q_p(·)Qp(⋅)反映高斯相对分布的p分位数。如图4,剪枝后的集合PGPP_{GP}PGP仍能保留场景的精细细节(通过优化迭代TGPT_{GP}TGP个 iter)
理论上来说,采样和剪枝本可以整合为单一流程,但是实验表明,用两个阶段分开处理效果更佳(见5.2节消融实验)。 我们推测这种优势源于两个阶段之间的中间优化过程——该过程能进一步优化表征结构,最终形成更紧凑的集合
4、高斯融合
前两个阶段(采样和剪枝)单独评估每个高斯的重要性;为进一步减少冗余,高斯融合将高度相似的高斯聚类,融合为单一的代表性高斯基元。
高斯聚类。我们定义相似度评分来量化高斯分布间的相似性并识别聚类。首先将空间划分为4D grid,计算同一 grid cell 内高斯之间的相似度评分。这种时空网格结构能将具有时间邻近性的高斯分布归为同一组,既避免了时间不匹配的高斯分布合并,又保持了时间一致性,同时降低了计算复杂度。我们定义两个高斯分布之间的相似度评分 S(Gi,Gj)S(G_i,G_j)S(Gi,Gj)为空间邻近性与外观相似性的总和:
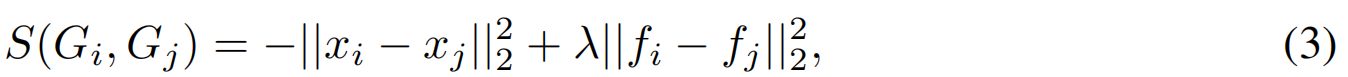
其中λλλ为固定平衡权重,xi∈R3x_i∈R^3xi∈R3表示位置坐标,fi∈R3f_i∈R^3fi∈R3为高斯基元GiG_iGi的第零阶球谐函数系数(可以理解为RGB颜色)。相似度分数阈值设为τsimτ_{sim}τsim,分数越高,表明空间外观相似度越大,构建高斯聚类 CiC_iCi:

其中PiP_iPi表示时空grid cell内,包含高斯GiG_iGi的高斯索引集合。去重处理消除重复簇,并剔除子集簇,最终得到最大簇集合C=C=C={CqC_qCq}q=1NC^{N_C}_{q=1}q=1NC。未被任何簇包含的高斯基元则作为孤立元素保留。
高斯融合。在每个聚类中,位置和外观属性分别分配可学习的 wix∈Rw_i^x∈Rwix∈R 和wif∈Rw_i^f∈Rwif∈R。在训练的渲染过程中,聚类CqC_qCq中的所有高斯将被替换为一个代理模型:
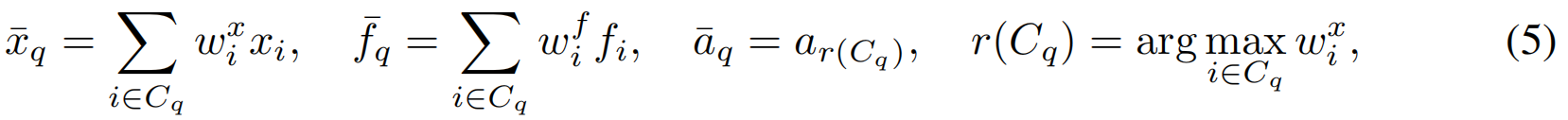
其中权重wix∈Rw_i^x∈Rwix∈R 和$w_i^f∈R 均按簇进行归一化。位置和外观特征则在簇内加权高斯,代表高斯的属性用于计算 aˉq\bar{a}_qaˉq。通过TGMT_{GM}TGM次迭代优化这两个权重,并重复执行M次高斯合并,同时逐步增大grid的尺寸。
5. 属性压缩
针对紧凑型高斯集合,我们沿用了OMG(Lee等人,2025b)的压缩流程:首先使用MLP提取空间特征,随后通过三个小型多层感知机(MLP)分别处理空间特征和位置信息,生成不透明度、静态颜色及视图相关颜色。我们进一步扩展了这些MLP网络,使其同时接收时间坐标,从而实现随时间变化的不透明度和外观效果。
此外,OMG公司推出了子向量量化(SVQ)技术,通过将输入向量分割为子向量并使用小型码本进行量化,展现出高效能与高质量重建的双重优势。本研究将SVQ技术拓展至动态3D场景表征领域。具体而言,为确保稳定性,我们完整保留了4D高斯均值的全精度数据,同时将SVQ应用于其他属性——包括RealTime4DGS(Yang等人,2024)中引入的附加旋转四元数和时间轴缩放参数,用于建模场景运动。然而,同步量化静态与动态属性会导致优化过程不稳定。为此,我们提出分阶段SVQ方案:首先仅对3D属性应用SVQ并优化T3DT_{3D}T3D迭代,随后再对4D属性启用SVQ。这种分阶段方法将时间敏感性和外观敏感性与静态组件解耦,从而实现稳定优化。最后,采用霍夫曼编码(Huffman,1952)结合LZMA压缩(Pavlov)对量化元素进行压缩。
6.实验结果
每个阶段用1000次迭代优化(TGS=TGP=TGM=1000T_{GS}=T_{GP}=T_{GM}=1000TGS=TGP=TGM=1000)。从预训练模型出发,首先进行高斯采样,随后在第1000次迭代时执行高斯剪枝。接着在第2000次和第3000次迭代时分别进行两次高斯合并。合并完成后启动属性压缩。在第4000次迭代时训练多层感知机(MLP),并持续训练至结束。从第9000次迭代开始对3D属性应用降维(SVQ),随后在第10000次迭代时对4D属性应用降维。对于中型模型(ours-M),采样比例设为 τGS=0.2τ_{GS}=0.2τGS=0.2,并采用0.8分位数阈值进行高斯剪枝。我们进行两次高斯合并,每次将空间网格尺寸扩大1.2倍,同时保持时间网格尺寸恒定为2.0。整个数据集采用完全相同的超参数配置。学习率、码本大小等参数均遵循Real-Time4DGS(杨等人,2024)和OMG(李等人,2025b)的研究方案。实验设备为单个英伟达RTX 3090。
数据集为N3DV和MPEG数据集中的Bartender数据2,如表1和图5:基线Real-Time4DGS的模型体积从2GB压缩至约3MB,还提升了PSNR值(31.75对比31.80)。通过略微增加模型体积(从3.61MB增至5.08MB,Ours–L),OMG4甚至超越了基线Real-Time4DGS(Yang等人,2024)的表现。

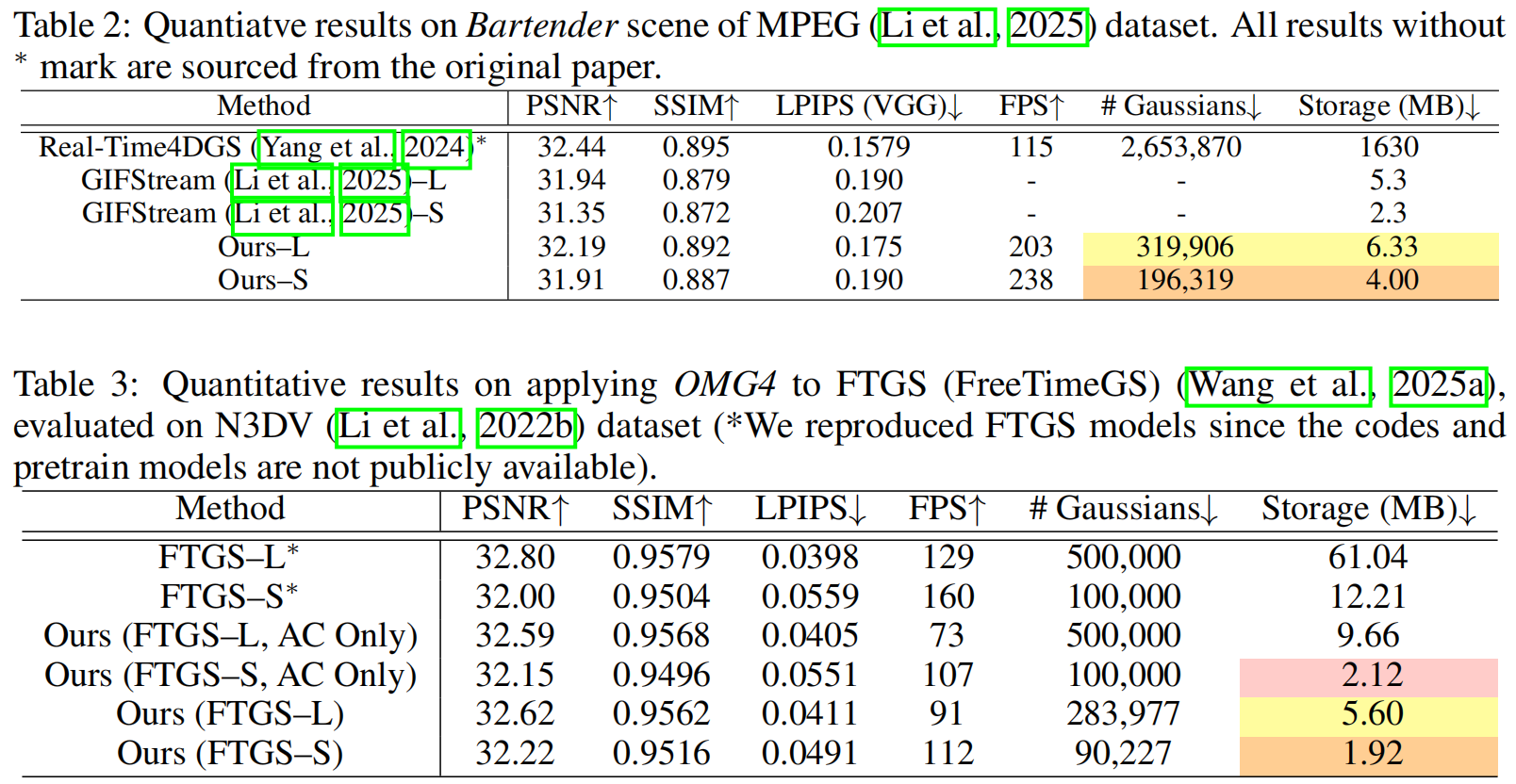
FreeTimeGS原理:

三、4DSiOMo:异步采集的高速场景4D重建
题目:4DSloMo: 4D Reconstruction for High Speed Scene with Asynchronous Capture
来源:上海AI Lab;港中文;港大;NVIDI
项目主页: https://openimaginglab.github.io/4DSloMo
论文: https://arxiv.org/pdf/2507.05163
代码: https://github.com/OpenImagingLab/4DSloMo
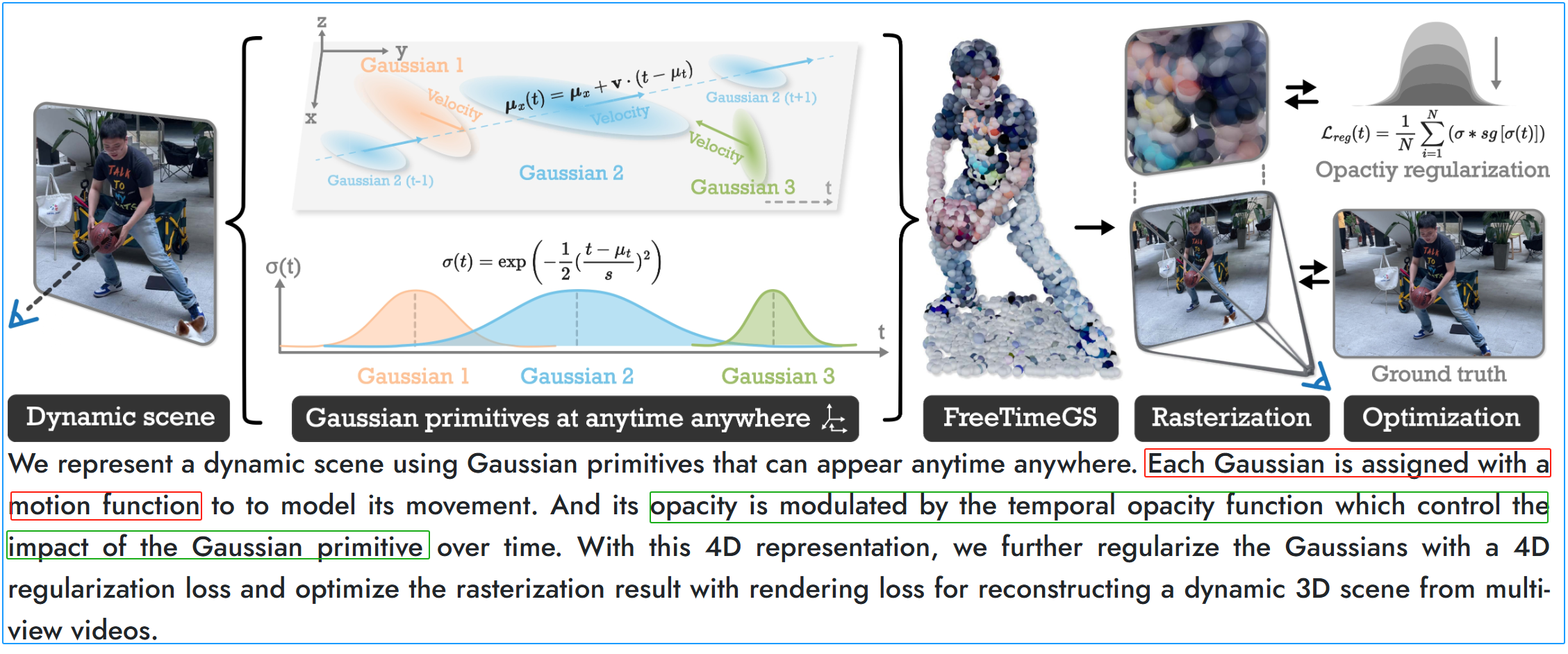
摘要。从多视角视频重建高速动态场景 对高速运动分析和真实感4D重建至关重要。然而,大多数4D捕捉系统仅支持低于30帧/秒的帧率,若直接对低帧率输入进行高速运动的4D重建,可能导致效果欠佳。本研究提出了一种仅使用低帧率摄像机的高速4D捕捉系统,通过创新的捕捉与处理模块实现突破。 在捕捉端,设计了异步捕捉方案,通过错开摄像机启动时间来提升有效帧率 。通过摄像机分组并采用25帧/秒基准帧率,该方法无需专用高速摄像机即可实现100-200帧/秒的等效帧率。在处理端,开发了新型生成模型来消除4D稀疏视角重建产生的伪影 ——由于异步性导致每个时间戳的视角数量减少。具体而言,我们训练了基于视频扩散的伪影修复模型,用于稀疏4D重建,该模型能完善缺失细节、保持时间一致性并提升整体重建质量。实验结果表明,相较于同步捕捉,我们的方法显著提升了高速4D重建效果。
1.准备知识: 4D Gaussian Splatting
用4D高斯散射(4DGS)作为重建的四维表示方法。该方法通过在各向异性三维高斯中引入时间维度 ttt,其由均值向量 µ∈R4µ∈R^4µ∈R4 和协方差矩阵 Σ∈R4×4Σ∈R^{4×4}Σ∈R4×4b定义:

其中 x=(x,y,z,t)x=(x,y,z,t)x=(x,y,z,t),协方差矩阵ΣΣΣ可分解为缩放矩阵SSS和旋转矩阵RRR:Σ=RSSTRTΣ=RSS^TR^TΣ=RSSTRT。其中S=diag(sx,sy,sz,st)S=diag(s_x,s_y,s_z,s_t)S=diag(sx,sy,sz,st) 定义了高斯基元的各向异性缩放,RRR是一个由两个四元数qlq_lql和qrq_rqr参数化的四维旋转矩阵,确保在四维空间中实现有效旋转:R=L(ql)R(qr)R=L(q_l)R(q_r)R=L(ql)R(qr)。 4维欧几里得空间 R4R^4R4中,旋转群是SO(4)SO(4)SO(4),它的通用覆盖是Spin(4):Spin(4)≅S3×S3Spin(4)≅S^3×S^3Spin(4)≅S3×S3。4D 向量 vvv(看作一个纯四元数或实部为 0 的四元数,旋转作用为:v′=qlvqr−1v'=q_{l}vq_r^{−1}v′=qlvqr−1
渲染过程采用3DGS中标准的可微光栅化技术:

其中 pi(u,v,t)p_i(u,v,t)pi(u,v,t)表示第iii个高斯在像素(u,v,t)(u,v,t)(u,v,t)处的概率密度,αiα_iαi代表不透明度,cic_ici是通过四维球谐函数(4DSH)建模的时间依赖性颜色。
2. 异步捕获方案
4D场景拍摄,通常方法[2,8]需要一组不同视角的摄像机集合{PiP_iPi}i=1N^N_{i=1}i=1N,同步拍摄时间来拍摄,如图1(a)。然而对于高速运动场景,这N个摄像机都无法捕捉相邻两帧之间的动态信息。由于摄像机的常规帧率通常不超过30帧/秒,当需要高帧率来重建复杂大范围运动场景时,4D重建技术就可能无法正常运作[1,8,10]。
异步采集方案(采集更密集:使多台摄像机能在不同时间点启动拍摄,如图1(b)所示。具体而言,我们将K台摄像机(图1(b)中的K=2K=2K=2,实验中选择K=4K=4K=4)分成一组,在不同时间点开始拍摄:第 iii 台摄像机在时间戳 ti=i⋅(τ/K)+j⋅τt_i=i·(τ/K)+j·τti=i⋅(τ/K)+j⋅τ 时开始拍摄图像,其中i∈i∈i∈{1,2,...,K1,2,...,K1,2,...,K}表示组内摄像机编号,jjj 代表以25 FPS录制的视频帧数。原本 25 FPS 的系统,通过 K=4K=4K=4 的异步拍摄,相当于在时间轴上每 τ/4τ/4τ/4 秒就有一台相机拍摄一帧,整体系统的时间采样率提高到 K×25=100 FPS
3.Artifact-fix (专修复伪影的)视频扩散模型
虽然异步采集技术能有效提升帧率以捕捉高速运动,但同时也带来了K倍的伪影问题。 具体来说,每次时间戳采集都会使视角数量减少K倍,这导致如图1(c)1(c)1(c)所示的4D重建中出现“漂浮”伪影——这源于稀疏视角重建的固有难题。尽管近期已有部分稀疏视角3D重建方法[4,27-29,36]通过引入图像扩散先验来提升重建质量,但直接套用于4D场景时,由于逐帧独立处理的特性,仍会引发时间一致性问题。
采用预训练的视频扩散模型,通过4D重建数据进行微调以适配我们的任务需求。该模型以包含漂浮伪影的渲染视频Vrender∈RC×T×H×WV_{render}∈ℝ^{C×T×H×W}Vrender∈RC×T×H×W作为输入,生成具有时间连贯性、清晰度的输出视频V^∈RC×T×H×W\hat{V}∈ℝ^{C×T×H×W}V^∈RC×T×H×W

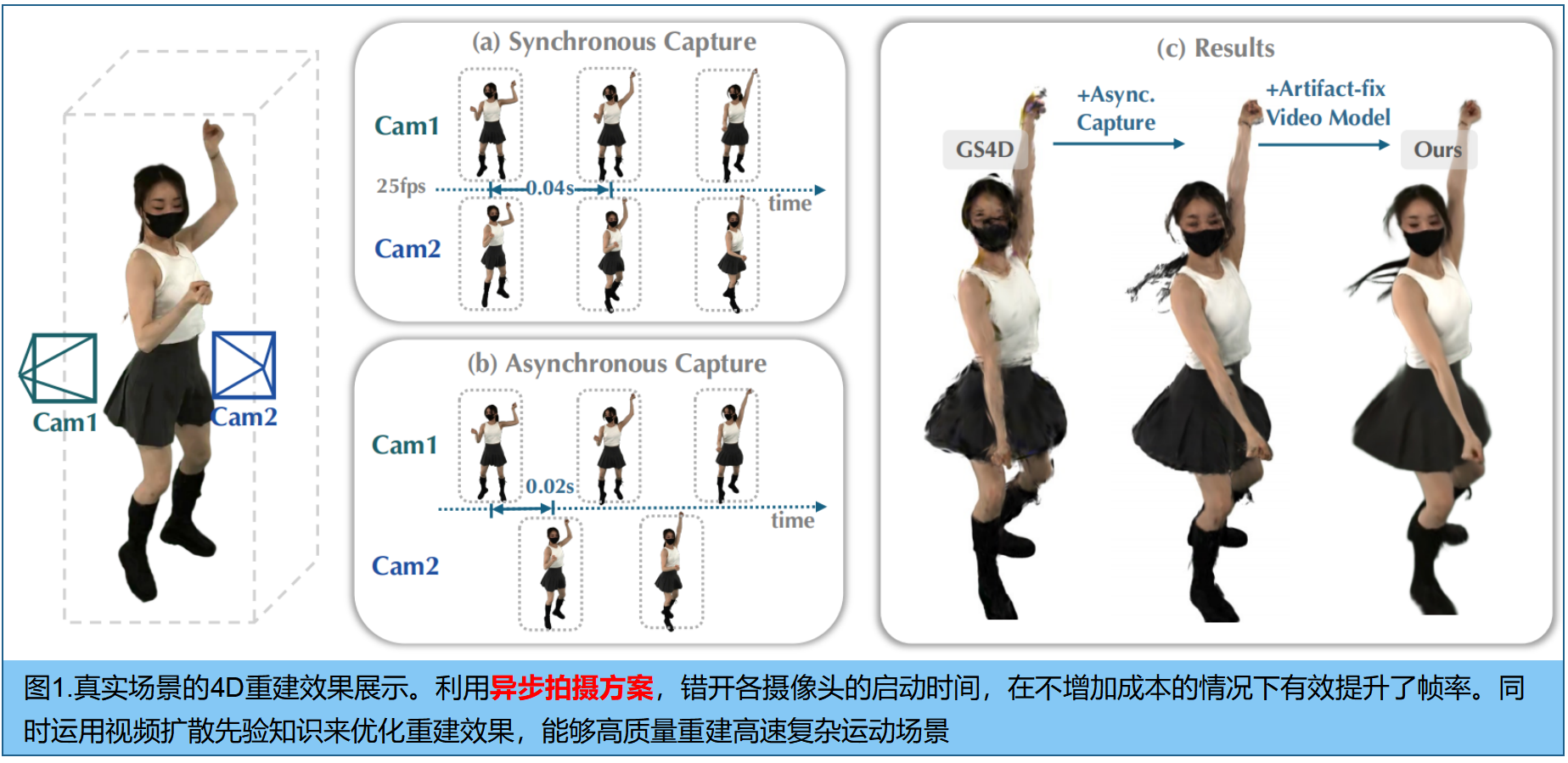
数据整理。首先,构建一个包含视频伪影对及其对应清晰版本作为基准的真实数据集。具体而言,如图2(a)所示,我们沿时间维度对多视角视频进行异步子采样,以训练 4DGS;训好后以原始帧率渲染视频,生成包含伪影的噪声输出。这些渲染视频与对应的清晰视频配对,形成扩散模型微调的训练数据。
微调。利用视频扩散模型Wan2.1 [Wan: Open and advanced large-scale video generative models] ,如图3,使用Wan-VAE E\mathcal{E}E将渲染视频 VrenderV^{render}Vrender和目标视频VtargetV ^{target}Vtarget压缩到潜在空间zrenderz^{render}zrender、ztarget∈Rc×t×h×wz^{target}∈R^{c×t×h×w}ztarget∈Rc×t×h×w中。噪声latent zttargetz^{target}_tzttarget与条件潜在zrenderz^{render}zrender沿通道轴拼接后,再通过Wan2.1的DiT模型处理。为将Wan2.1原有的图像到视频生成设置重新应用于视频增强,我们采用zrenderz^{render}zrender的所有帧作为条件,指导整个序列的伪影修复过程,
微调冻结编码器和解码器,仅对DiT组件应用基于LoRA的微调。训练损失定义为:

4.扩散先验的4D重建
如图2,首先从所有图像中重建初始4DGS。接着,针对每个训练视图,渲染覆盖所有摄像头观测时间戳的高帧率视频 VrenderV^{render}Vrender(稀疏视图重建,存在伪影),能为扩散模型MMM提供关键的空间视角信息和物体运动时序信息。
对渲染视频 VrenderV^{render}Vrender应用Wan-VAE,得到 latent zrender∈Rc×t×h×wz^{render}∈R^{c×t×h×w}zrender∈Rc×t×h×w;将其与同维度噪声沿通道维度拼接,生成更清晰锐利的优化视频V^\hat{V}V^,用于监督渲染过程:
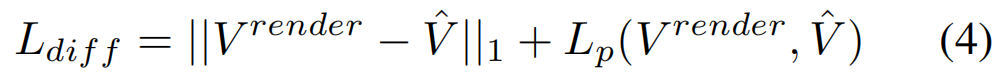
有效性如图 1(c)1(c)1(c),异步捕捉技术能有效恢复快速动态运动。但由于每个时间步长的视角分布本身具有稀疏性,学习到的高斯表示会引入明显伪影。通过应用我们开发的场景级伪影修正扩散模型对高斯表示进行优化,这些伪影可被有效抑制,从而获得更优的最终效果。
5.实验
实施细节。框架如图2,4DGS是底层表示方法。基于Wan-I2V-14B模型构建伪影校正视频扩散模型,注入LoRA层微调DiT主干,其使用DNA-Rendering数据集[1]中的750个噪声-干净视频对进行训练,学习率设为10−4,LoRA秩设为16。训练4DGS了7000次迭代(存在伪影);后续7000次迭代中,优化过程仅使用扩散模型生成的精炼视频进行迭代。
数据集。多视图数据集,包括DNA-Rendering:采用4K和2K双摄像头组合,以15帧/秒的速率捕捉动态人体与物体的10秒片段。为模拟大范围运动,时间采样率降低至原始速率的四分之一。测试集由保留视图的所有帧构成。Neural3DV以30帧/秒的速率拍摄多视图视频,每段持续10秒。我们将其视频采样率降低至原始速率的十二分之一。每个场景中保留一个视图用于测试,其余视图用于训练。通过在现有4D数据集上应用时间降采样技术,我们有效模拟了大范围帧间运动,并在同一场景内生成同步与异步两种采集设置。这种设置使我们能够在大运动条件下直接比较两种采集策略。
伪影修复SVD在DNA-Rendering 数据集上训练,共构建了750组噪声-清晰视频对用于训练,每组分辨率为1024×1024,长度为25帧。
目前尚无异步采集的真实景4D数据集,专门构建了 多视角相机阵列的异步4D重建benchmark(舞蹈、体育运动及快速物体交互,如国际象棋棋子摆动等高速运动场景,重点涵盖非线性运动与大范围运动场景,视频分辨率2048×2248)。如图6所示,该装置由12台以25帧/秒运行的相机组成,所有相机均支持硬件同步触发功能。相机分布在三个不同垂直层级,每层均匀分布四台相机,间距约22.5度。虽然所有12台相机均支持同步触发,但我们通过手动设置不同相机的触发延迟来实现异步采集。通过将相机阵列划分为四组或八组时间组,我们分别实现了100帧/秒和200帧/秒的采集速率
定量实验:
定性实验:
本文真实拍摄数据集的定性分析结果:

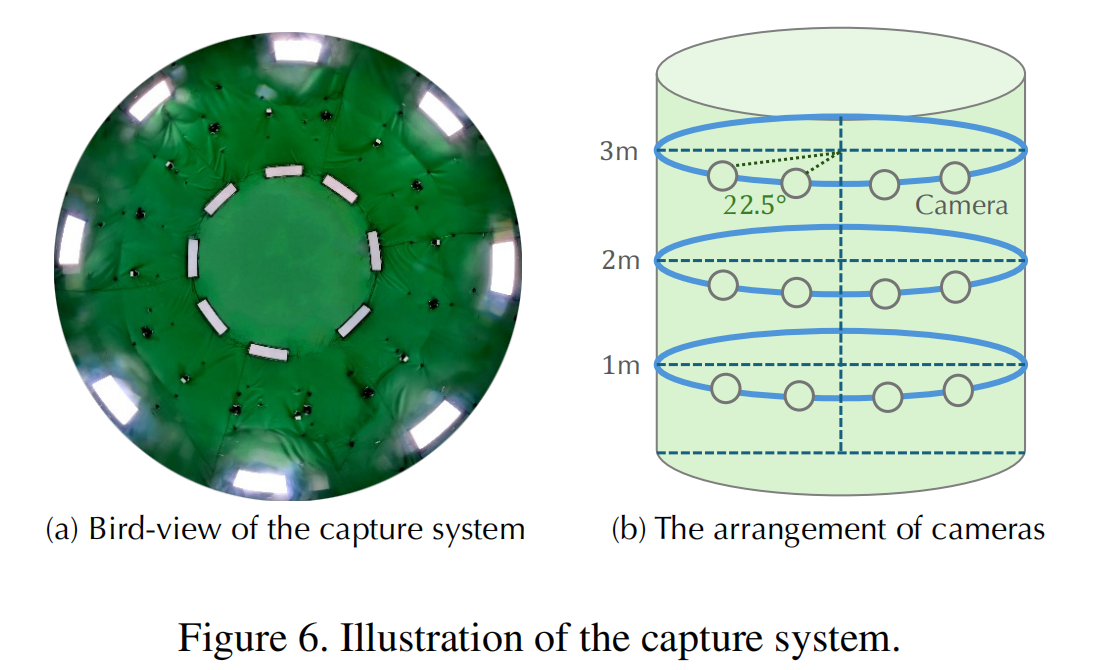
为评估异步采集技术的有效性,我们在DNA渲染数据集上将其与同步采集技术进行对比。定量分析结果详见表3,定性对比结果见图8。同步采集,摄像机的帧率过低,无法捕捉人体快速运动,导致相邻帧之间出现明显位移。此外,4D模型无法沿时间维度进行插值处理以还原合理运动轨迹(图8(b)),即便是采用伪影修正的视频扩散模型也未能生成令人满意的输出(图8©)。相比之下,采用异步采集技术(图8(d))时,虽然因视角稀疏仍存在部分伪影,但重建的运动轨迹更为精确。

SVD的伪影修复效果:对比了使用与未使用SVD的渲染效果,见表3及图8(d)(e)。

对比视频扩散与图像扩散技术。使用ControlNet Tile模块[38]训练了Stable Diffusion 1.5模型。图9展示了两种扩散模型的输出效果。我们发现,除了基础模型能力差异导致的面部生成质量不同外,视频扩散模型在相邻帧的锁骨周围生成了时间上连贯的纹理。相比之下,图像扩散模型由于逐帧随机性,在该区域引入了明显的纹理变化。这种时间不一致性对保持4D重建的平滑运动构成了重大挑战。

5.3.场景级微调伪影修复模型为提升视觉效果:当输入视频复杂时(如图10(b)所示场景中部分区域缺乏纹理而其他区域存在密集伪影),模型可能难以区分需要消除的噪声与需要保留的纹理细节,导致效果欠佳。为此,我们提出场景级微调方案:采用留一法策略(类似文献[Gaussianobject]的方法)从输入视频中构建噪声-干净视频对,并通过少量迭代对模型进行微调。图10©(d)的实验结果表明,场景级微调使模型能够恢复更精细的服饰细节,因为扩散模型通过多视角和时间线索学习4D场景分布。虽然该策略在复杂场景中效果显著,但留一法构建会带来显著的时间开销,因此本研究未将其设为默认参数。
#pic_center =60%x80%
d\sqrt{d}d 18\frac {1}{8}81 xˉ\bar{x}xˉ D^\hat{D}D^ I~\tilde{I}I~ ϵ\epsilonϵ
ϕ\phiϕ ∏\prod∏ abc\sqrt{abc}abc ∑abc\sum{abc}∑abc
/ $$ E\mathcal{E}E