【ASR论文】Zipformer:更快、更强的语音识别编码器 | 小米公司
Zipformer:更快、更强的语音识别编码器
论文标题:Zipformer: A Faster and Better Encoder for Automatic Speech Recognition
发表会议:ICLR 2024
作者单位:小米公司(Xiaomi Corp.)
开源地址:https://github.com/k2-fsa/icefall
引言:为什么需要 Zipformer?
在端到端自动语音识别(ASR)系统中,编码器结构是决定性能的关键。自 Conformer(2020)提出以来,它凭借融合 Transformer 的全局建模能力和 CNN 的局部感知能力,成为 ASR 领域的事实标准。
然而,Conformer 仍存在以下问题:
- 计算和内存开销大;
- 训练收敛慢;
- 在开源复现中难以达到原论文报告的性能(尤其在 LibriSpeech 上)。
为解决这些问题,小米团队提出了 Zipformer —— 一个更快、更省内存、性能更强的新一代 ASR 编码器。
核心创新点概览
Zipformer 并非单一改进,而是从模型架构、归一化方式、激活函数、优化器四个维度进行系统性创新:
| 维度 | 技术 | 目标 |
|---|---|---|
| 架构 | U-Net 式多尺度下采样 + 注意力权重复用 | 提升效率与建模能力 |
| 归一化 | BiasNorm(替代 LayerNorm) | 保留序列长度信息,避免“死模块” |
| 激活函数 | SwooshR / SwooshL(替代 Swish) | 改善负输入梯度,支持“常关”行为 |
| 优化器 | ScaledAdam(改进 Adam) | 加速收敛,显式学习参数尺度 |
1. 架构设计:U-Net 式多分辨率编码器
传统 Conformer 的局限
- 所有层以固定帧率(如 25Hz)处理序列 → 计算冗余。
Zipformer 的解决方案
- 采用类似U-Net 的编码器结构,包含 6 个堆叠(stacks):
- 帧率变化:
50Hz → 25Hz → 12.5Hz → 6.25Hz → 12.5Hz → 25Hz - 中间层大幅下采样(最低至 6.25Hz),减少计算量;
- 后续层通过上采样恢复分辨率,并融合多尺度信息。
- 帧率变化:
- 每个 stack 使用不同嵌入维度(中间更大),提升表达能力。
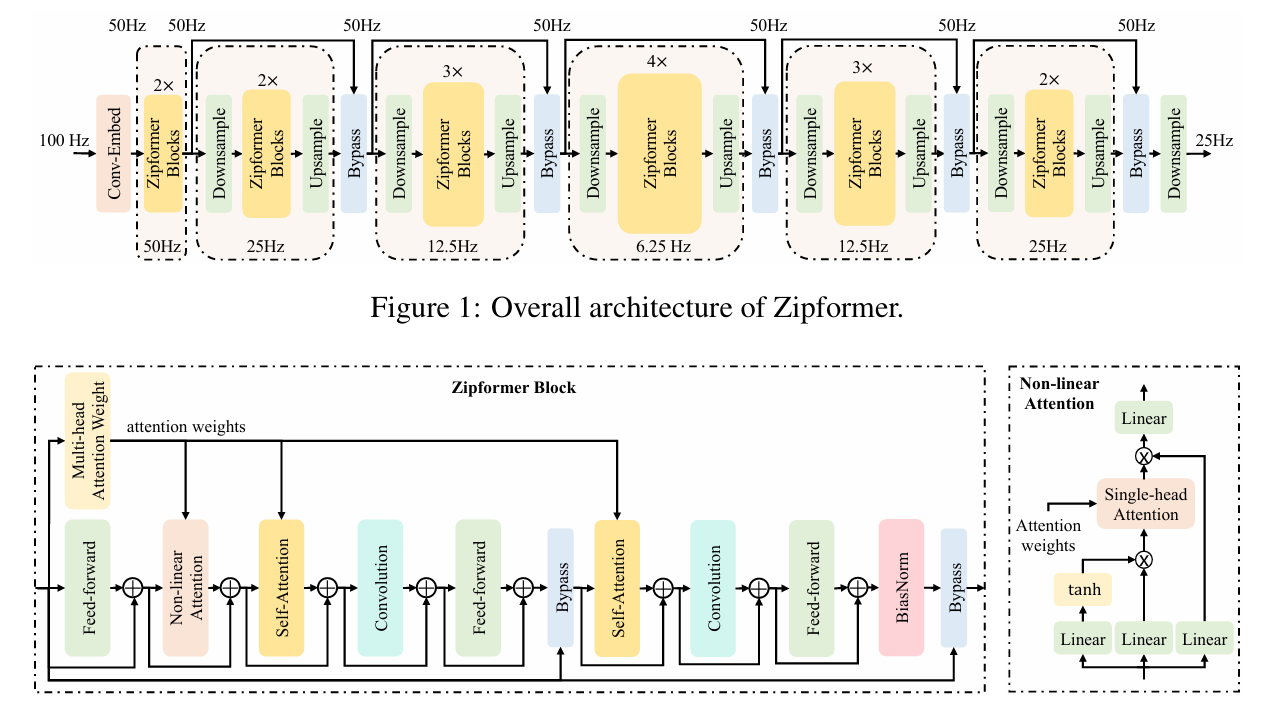
✅ 优势:在降低 FLOPs 的同时,增强对长时依赖的建模。
2. Zipformer Block:注意力权重复用 + 非线性注意力
Conformer Block 回顾
- 结构:FFN → MHSA → Conv → FFN
- MHSA 计算复杂度高(O(T2))
Zipformer Block 创新
- 拆分 MHSA为两个模块:
MHAW(Multi-Head Attention Weights):仅计算注意力权重;SA(Self-Attention):使用预计算权重聚合特征。
- 复用权重:一个
MHAW输出供 两个 SA 模块 + 一个 NLA 模块使用 → 节省 50% 注意力计算。 - 新增Non-Linear Attention (NLA)模块:
- 利用 tanh 和逐元素乘法引入非线性;
- 更充分地利用注意力权重捕捉全局信息。
✅ 效果:Block 深度翻倍但计算量更低,性能更强。
3. 归一化:BiasNorm 替代 LayerNorm
LayerNorm 的问题
- 完全去除向量长度信息 → 模型需用“大常数通道”绕过归一化;
- 可能导致某些模块输出趋近于 0(“死模块”),且难以恢复。
BiasNorm 设计
公式:
BiasNorm(x)=RMS(x−b)x⋅exp(γ)
- b:可学习的通道偏置 → 保留长度信息;
- exp(γ):始终为正的缩放因子 → 避免梯度震荡;
- 无需减均值(除非后接非线性)。
✅ 优势:简化训练动态,提升稳定性与性能。
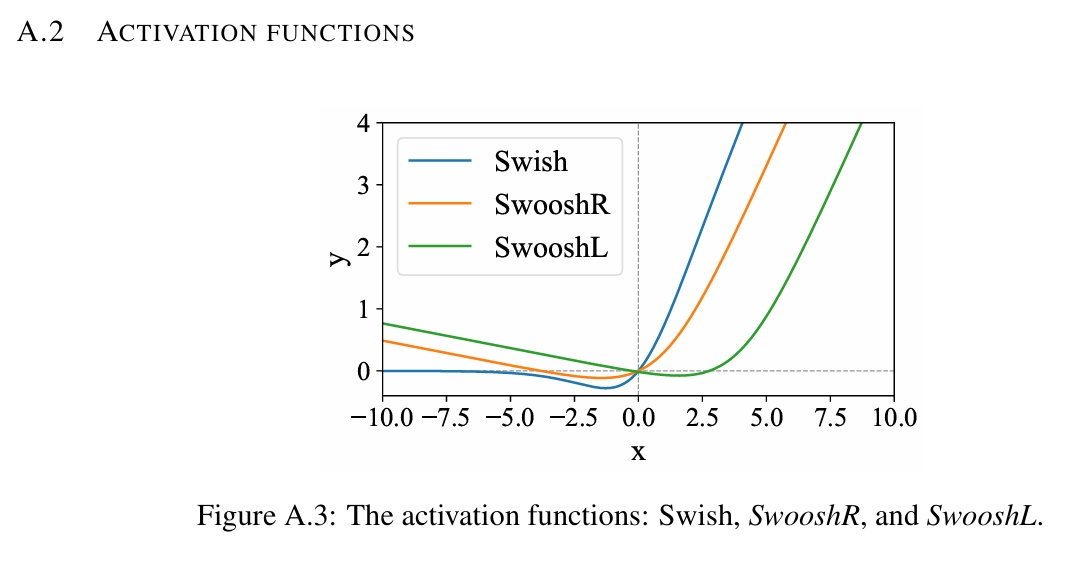
4. 激活函数:SwooshR 与 SwooshL
动机
- Swish 在负区梯度趋近于 0 → 容易陷入“全负输入”陷阱;
- 某些模块(如带 bypass 的 FFN)需支持“默认关闭”行为。
新激活函数
-
SwooshR:用于常规模块(如卷积)
1SwooshR(x) = log(1 + exp(x - 1)) - 0.08*x - 0.313261687 -
SwooshL:用于“常关”模块(如带 bypass 的 FFN/ConvNeXt)
- 相当于 SwooshR 右移,零点在 x≈4
✅ 特点:负区有非零斜率,避免梯度消失;支持模块灵活开关。
5. 优化器:ScaledAdam
Adam 的局限
- 更新量与参数尺度无关 → 大参数更新相对太小,小参数更新相对太大;
- 难以直接学习参数的绝对尺度。
ScaledAdam 改进
-
缩放更新量:
Δt′=−α**t⋅r**t−1⋅v**t+ϵmt
其中
r**t−1=RMS(θ**t−1)
→ 保持相对变化一致。
-
显式学习参数尺度:
- 将 θ=r⋅θ′ 分解;
- 对 r 单独计算梯度并更新;
- 等价于增加一个沿 θ 方向的更新项。
✅ 效果:收敛更快,性能更好,且可大幅减少归一化层。
配套学习率调度:Eden Schedule(无长 warmup,适应 batch size 变化)。
实验结果:全面超越 SOTA
数据集
- LibriSpeech(英文,1000h)
- Aishell-1(中文,170h)
- WenetSpeech(中文,10000+h)
关键结果(LibriSpeech test-clean / test-other WER%)
| 模型 | 参数量 (M) | FLOPs | WER (%) |
|---|---|---|---|
| Conformer-L (原论文) | 118.8 | – | 2.1 / 4.3 |
| Conformer-L (复现) | 122.5 | 294.2 | 2.46 / 5.55 |
| Zipformer-L | 148.4 | 107.7 | 2.06 / 4.63 |
| Zipformer-L*(A100×8, 170 epoch) | 148.4 | 107.7 | 2.00 / 4.38 |
🎯 Zipformer-L* 是首个在开源复现中逼近原版 Conformer 性能的模型!
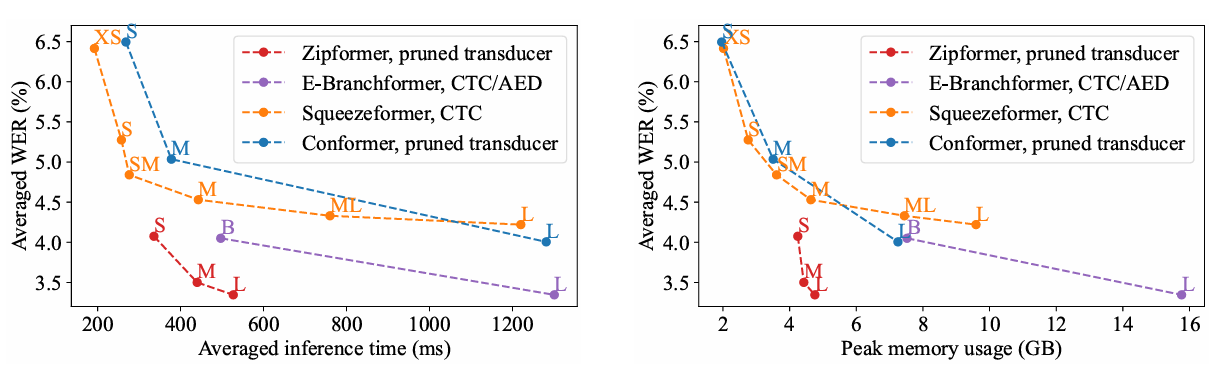
效率对比(V100 GPU, 30s 音频 batch=30)
- 推理速度:Zipformer-L 比 Conformer-L 快 >50%
- 峰值内存:显著低于同类大模型
消融实验:各组件贡献
以 Zipformer-M 为基线(WER: 2.21 / 4.79):
| 修改 | test-clean / test-other |
|---|---|
| 移除下采样结构 | 2.23 / 5.09 ↑ |
| 用 LayerNorm 替代 BiasNorm | 2.29 / 4.97 ↑ |
| 全部使用 SwooshR(不用 SwooshL) | 2.32 / 5.21 ↑ |
| 使用 Swish | 2.27 / 5.37 ↑ |
| 使用 Adam 优化器 | 2.38 / 5.51 ↑ |
✅ 所有创新组件均带来显著收益。
总结与启示
Zipformer 展示了如何通过系统级协同设计(架构 + 优化 + 正则)突破现有 ASR 模型瓶颈:
- 多尺度建模是提升效率与性能的有效路径;
- 简化归一化 + 定制激活函数可改善训练动态;
- 优化器创新(如 ScaledAdam)能释放模型潜力,甚至减少对复杂归一化的依赖。
💡 未来方向:该范式或可推广至其他序列建模任务(如语音合成、语音翻译)。
推荐阅读:如果你正在训练 Conformer 类模型遇到收敛慢、显存爆、复现难等问题,Zipformer 的代码与设计思想值得深入研究!