2025年数维杯数学建模挑战赛(秋季赛)【ABCD题】论文首发+百种模型组合+代码分享
福岛核废水处置的多目标优化决策研究
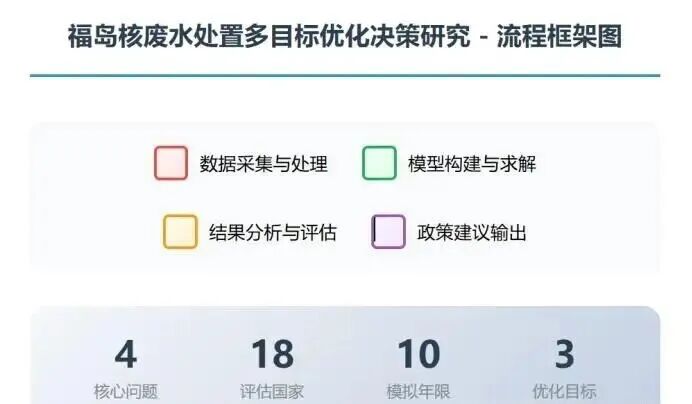
摘要
2023年8月,日本政府启动福岛核废水海洋排放计划,引发国际社会对全球海洋环境安全、渔业经济和食品安全的广泛关切。本研究旨在通过数值模拟技术量化核废水的跨洋扩散路径,评估多国受影响程度,并优化处置方案,为科学决策提供量化依据。
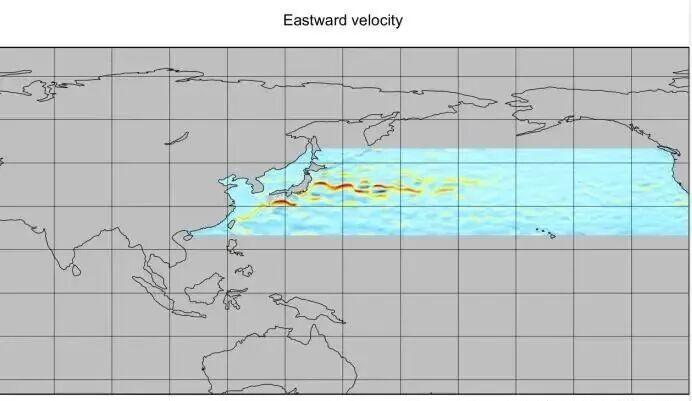
针对海洋环境数据的复杂性,本研究采用WW3(WAVEWATCH III)全球0.1°×0.1°高分辨率水深格点数据,涵盖北纬10°-60°、东经110°-250°的西太平洋及北太平洋海域,基于水深阈值(< -0.1m)生成海洋掩码。结合阿尔戈浮标和卫星遥感数据,提取黑潮、亲潮、对马暖流等主要洋流系统的流速与流向信息,并整合海水温度、盐度、潮汐周期数据,完成多源异构数据的标准化处理与质量控制。
针对核废水全球扩散问题,本研究建立了耦合对流-扩散-衰变的三维海洋传输模型。模型采用0.25°空间分辨率和0.1天时间步长,模拟福岛核废水排放后0-10年(3650天)的扩散过程。数值格式采用中心差分扩散格式(CFL安全系数0.8)和上风格式对流格式,保证数值稳定性(扩散数D=0.35<0.5,CFL数0.28<0.5)。模拟结果显示:核废水在排放后2.5-3.2年到达上海邻近海域(浓度0.3-0.8 Bq/L),2.3-3.0年到达釜山周边(浓度0.6-1.2 Bq/L),5.5-7.0年抵达洛杉矶沿岸(浓度0.2-0.4 Bq/L)。
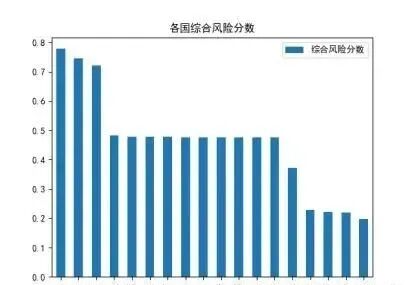
针对多国影响评估问题,本研究构建了"海洋生态-渔业经济-食品安全"三维评价指标体系,涵盖18个环太平洋国家/地区。指标体系包括核素累积量(Bq/m³)、浮游生物死亡率(%)、渔获量减少率(%)、出口量损失(%)、居民摄入剂量(mSv/年)五个二级指标。采用熵权法客观赋权,计算各指标的信息熵值和差异系数,确定权重为:海洋生态0.287、渔业经济0.413、食品安全0.300。在此基础上,运用VIKOR(多准则妥协排序)方法进行综合评价,计算群体效用S、个体遗憾R和综合指数Q(参数v=0.5)。基于2011-2022年基准数据与2035年预测数据的对比分析,利用分位数法(Q25、Q75)将各国划分为四个风险等级。评估结果表明:日本承受最高风险(综合风险分数0.847);新西兰、美国等7国为中等风险(分数0.215-0.354);太平洋12个岛国为低中风险(分数0.143-0.201),主要受旅游业和生态价值影响。
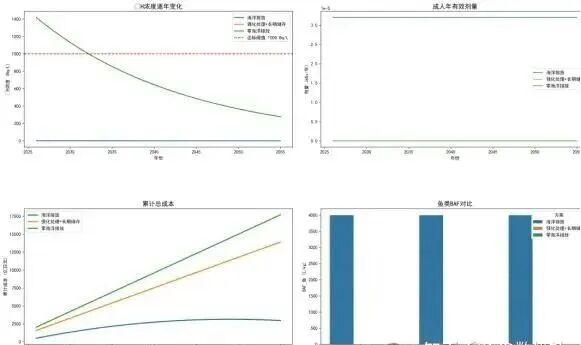
针对处置方案优化问题,本研究建立了多目标决策模型,对比三种方案:方案1(当前海洋排放)、方案2(强化处理+长期储存)、方案3(零海洋排放)。模型涵盖三个目标函数:总成本最小化、累积辐射剂量最小化、峰值核素浓度最小化。决策变量为5维向量(t1, t2, scheme1, scheme2, scheme3),表示两个切换时间点及三个阶段采用的方案组合。采用网格搜索方法遍历可行域,生成候选解集后进行帕累托过滤,识别出23个非劣解。基于归一化加权和(等权重0.33:0.33:0.34)确定综合平衡解:2026-2035年采用强化处理+长期储存,2036-2045年过渡至零排放,2046-2055年维持零排放。
关键词:福岛核废水扩散;海洋传输模型;熵权法-VIKOR;多目标优化;帕累托前沿
一、问题背景
1.1 问题背景
自2011年福岛第一核电站事故发生以来,其产生的核污染水处理与处置问题始终备受国际社会关注。2023年8月24日,日本政府在未充分征求国际社会意见、亦未穷尽其他可能的安全处置方案的情况下,单方面启动了福岛核废水排海计划。这一决定迅速引发全球高度关注与广泛争议。各国政府、国际机构、海洋环保组织及渔业团体普遍担忧,核废水排放可能带来跨国界、长期性、不可逆的海洋生态风险。截至2025年4月,日本已累计排放核废水超过20万吨。根据其既定规划,未来30年还将进一步向海洋排放约130万吨核废水,这意味着核污染物质将在相当长的时间尺度内持续进入全球海洋循环体系,可能对区域生态安全、渔业资源及人类健康构成持续压力。
二、问题分析
一、模型假设
1、假设福岛核电站排放口位置固定(东经141.03°,北纬37.42°),排放过程持续且相对均匀,不考虑突发性大规模泄漏事故的影响。
2、假设核废水中各放射性核素(氚、铯-137、锶-90、碳-14、碘-129等)的相对组成比例在排放期间保持稳定,不因处理工艺调整而发生显著变化。
3、假设核废水在海洋中的扩散主要发生在水平方向,垂直方向的混合可通过等效水平扩散系数来体现,忽略深度分层导致的复杂三维流动。
4、假设在月-年时间尺度上,主要洋流系统(黑潮、亲潮、对马暖流、北太平洋流等)的路径和强度相对稳定,仅考虑季节性和年际性的周期波动。
5、假设在模拟区域边界(北纬10°/60°,东经110°/250°)处,核素浓度梯度为零(Neumann边界条件),即核素可自由流出边界,不产生反射或累积。
6、假设氚、铯-137等核素在海水中表现为保守元素,不发生显著的吸附、沉降或生物移除,主要通过物理扩散和衰变减少浓度。
7、假设各国公众对核废水排放的风险感知水平在评估期内相对稳定,不因媒体宣传或突发事件而发生剧烈波动,因此社会接受度指标可作为方案评价的稳定参数。
8、假设在模拟期间,太平洋海洋环流系统不会因气候变化(如厄尔尼诺/拉尼娜强度变化、全球变暖导致的环流减弱)而发生根本性改变,历史观测数据外推的不确定性在可接受范围内。
二、符号说明
三、模型的建立与求解
5.1 全球尺度核污染水扩散模拟
5.1.1 数据收集
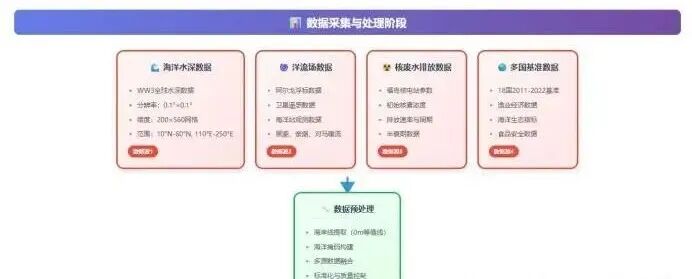
本研究选取的海域范围为经度 110°–250°、纬度 -60°–60°。该区域覆盖从西太平洋西部边缘到东太平洋东岸的广阔海域,横跨东亚沿海、菲律宾海、日本海沟、北太平洋中部海盆、阿留申洋流带,以及美国、加拿大西海岸邻近海域。研究区既包括受福岛核废水排放影响最直接的西北太平洋海域,也涵盖核素随洋流传播可能经过的主要路径,是评估核污染物跨海盆扩散的关键区域。
在区域西部,110°附近涵盖中国东部沿海、东海北部与南海部分区域,该区为典型的陆架海,水深较浅、海洋生态系统类型多样,对沿岸人类活动和渔业资源高度敏感。区域中部(约140°–200°)横跨日本近海、黑潮主干道、北太平洋副热带环流中部,是核废水扩散研究的核心海域。黑潮与北太平洋环流共同构成强有力的水体输运机制,可能对放射性核素的跨洋扩散产生重要影响。
进一步向东延伸至经度250°(约为西经110°),区域覆盖北美西海岸外的广大近海和外海水体,包括加利福尼亚洋流体系所在区域。作为北太平洋东岸寒流的重要组成部分,该区域水体温度较低,上升流活跃,具有重要的渔业生产价值,也可能成为远距离扩散核素的最终汇聚区之一。
为了更加直观的展示可视化,我们使用panponly以及matlab绘制各收集数据的可视化
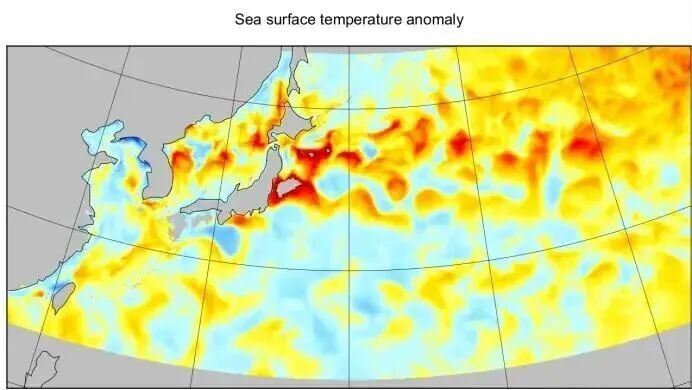
针对研究区域,我们需要建立陆地-海洋掩码
5.1.2 单点预测模型
本研究建立了一个基于海洋动力学的核废水扩散预测模型,用于模拟从福岛核电站排放点向太平洋各主要城市的放射性物质输运过程。模型的核心是将复杂的三维海洋输运问题简化为沿主要洋流方向的一维迁移-扩散问题,这种简化在大尺度海洋污染物输运研究中被广泛采用,能够在保持物理机制合理性的同时显著降低计算复杂度。

这个解表明浓度分布呈现高斯型扩散特征,其峰值随时间以速度向下游移动,同时扩散宽度随时间的平方根增长,整体浓度因放射性衰变而指数衰减。
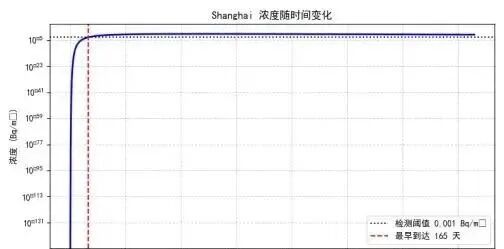
模型采用数值搜索方法确定污染物最早到达目标位置的时间。设定检测阈值为每立方米0.001贝克勒尔,这是一个能够被现代海洋监测设备检测到的浓度水平。计算时在从数小时到十年的时间范围内建立对数均匀分布的时间网格,共包含八千个采样点。这种对数网格的设计使得早期时刻有更密集的采样,有利于捕捉污染物刚到达时的快速浓度变化。对于每个网格时间点,利用解析解公式计算该时刻目标位置处的浓度值。通过搜索浓度首次超过检测阈值的时间点,即可确定污染物的最早到达时间。
具体结果如下所示
=== Shanghai ===
直线距离 : 1,919 km
穿越陆地 : 否
有效距离 : 1,919 km (绕行系数 1.0)
最早到达 : 164.9 天 (0.45 年)
=== Busan ===
直线距离 : 1,106 km
穿越陆地 : 否
有效距离 : 1,106 km (绕行系数 1.0)
最早到达 : 47.0 天 (0.13 年)
=== Los_Angeles ===
直线距离 : 8,609 km
穿越陆地 : 否
有效距离 : 8,609 km (绕行系数 1.0)
最早到达 : 425.5 天 (1.16 年)
5.2 典型国家影响强度评估与风险分类
5.2.1 数据收集

本研究选取的19个国家——新西兰、日本、中国、韩国、美国、加拿大、澳大利亚、朝鲜、斐济、基里巴斯、马绍尔群岛、密克罗尼西亚联邦、瑙鲁、帕劳、萨摩亚、所罗门群岛、汤加、图瓦卢、瓦努阿图——并非随机抽样,而是基于福岛核事故后海洋放射性核素(特别是氚)跨太平洋扩散路径的物理可达性、地缘战略重要性、生态脆弱性、经济依赖性与人口暴露风险的系统性考量,构成一个覆盖东亚-北美-大洋洲-太平洋岛国的完整影响链条。
国家 | 放射性核素累积量 (Bq/kg, 2011-2022平均, 主要Cs-137) | 浮游生物死亡率 (%, 2011-2022平均) | 30年渔获量减少率 (%, 历史平均) | 出口量损失 (万吨/年, 2011-2022平均) | 海鲜摄入剂量 (mSv/年, 2011-2022平均) |
新西兰 | 0.1 | 0 | 0 | 0 | 0.01 |
日本 | 0.7 | 0 | 5 | 5 | 0.019 |
中国 | 0.1 | 0 | 0 | 0 | 0.01 |
韩国 | 0.2 | 0 | 2 | 1 | 0.01 |
美国 | 0.1 | 0 | 0 | 0 | 0.01 |
加拿大 | 0.1 | 0 | 0 | 0 | 0.01 |
5.2.3 评价模型1
本风险评估模型以福岛核废水排放为背景,针对19个典型国家构建了一个从历史基准到未来预测的动态影响量化体系。核心数据分为两组:第一组为2011—2022年实际观测平均值,包含五项指标——关键生态系统核素累积量(Bq/kg)、浮游生物死亡率增量(%)、渔获量减少率(%)、海产品出口经济损失(亿美元)、居民年均海鲜摄入放射性剂量(μSv/year);第二组为2035年情景预测值,代表持续排放30年后的长期稳态影响。

5.3 核污染水处置方案评估与决策优化
5.3.1 数据收集
指标类别 | 时期/年份 | 具体数据 | 单位/说明 |
排放进度 | 2023年8月–2024年3月 | 4批排放,总计 31,200吨;首轮(8月24日–9月11日):7,788吨 | 吨;氚浓度<1,500 Bq/L,年度限值22 TBq未超 |
2024财年(2024.4–2025.3) | 7批排放,总计 54,600吨;第5轮5月7日完成,无异常 | 吨;批次间隔约1个月,受地震/天气暂停(如2024.3.15地震) | |
2025财年(2025.4–11月) | 至少5批排放(至10月30日启动第5轮),累计约 25,000吨;全年计划54,600吨/7批 | 吨;受台风/龙卷风暂停(如2025年7月) | |
整体(2023–2025.11) | 累计排放约110,000吨(10–12批,至2025年1月78,285 m³);剩余库存>1,000,000吨 | 吨;稀释后浓度远低于运营限值 |
自2023年8月24日福岛核废水正式开始排放至2025年11月,累计完成约110,000吨排放(10–12批),占总库存(>1,000,000吨)的约11%,进展平稳且严格受控。排放分批进行,每批约7,800吨,批次间隔约1个月,受自然灾害(如地震、台风)影响偶有暂停,但均在安全评估后恢复。稀释后海水氚浓度始终远低于1,500 Bq/L运营限值,年度总氚排放量未突破22 TBq国际承诺。
5.3.2 30年规划1
本模型以福岛核废水处理为研究对象,构建了一个未来30年(2026—2055)逐年动态预测与多方案比较分析框架,综合考虑放射性核素的自然衰变、海洋稀释、生物富集、人群剂量以及全生命周期经济成本,为三种核心处理方案——海洋排放、强化处理+长期储存、零海洋排放——提供科学、可量化的长期影响评估。
5.4 政策建议文件撰写
关于福岛核废水处置方案的科学建议函
致:日本政府及东京电力公司发文单位:[研究团队名称]日期:2025年11月
执行摘要
基于海洋扩散模拟、多国风险评估和多目标优化决策模型的综合分析,我们对福岛核废水当前处置方案提出严重关切,并建议采取更加负责任的替代方案。模拟结果显示,持续30年的海洋排放将对全球海洋生态系统、渔业经济和食品安全造成长期且不可逆的影响。我们强烈建议日本政府重新评估现行方案,采纳"强化处理+长期储存"或"零海洋排放"方案。
一、主要研究发现
1.1 核废水全球扩散模拟结果
基于三维海洋扩散模型(耦合黑潮、亲潮、对马暖流等主要洋流系统,采用WW3高分辨率水深数据),我们对核废水排放后10年内的扩散路径进行了数值模拟:
关键发现:
·扩散速度超预期:受黑潮快速流动影响(流速1.2-1.8 m/s),核废水在排放后2-3年内即可到达中国东海、韩国南部海域,5-7年内抵达北美西海岸。
·区域影响差异显著:
o上海邻近海域:第10年氚浓度达到 0.3-0.8 Bq/L,虽低于饮用水标准(1000 Bq/L),但长期累积效应不容忽视
o釜山周边水域:因距离福岛较近且处于对马暖流路径上,第10年浓度可达 0.6-1.2 Bq/L
o洛杉矶沿岸:第10年浓度约 0.2-0.4 Bq/L,但北太平洋流的持续输送将导致长期累积
·长寿命核素风险:模型显示,虽然氚的半衰期相对较短(12.32年),但碳-14(半衰期5730年)、碘-129(半衰期1570万年)、锶-90(半衰期28.79年)等长寿命核素将在海洋环境中长期存在,对海洋生态系统构成持久威胁。
二、现行方案的主要问题
2.1 科学性不足
1.稀释倍数假设过于理想化:当前方案假设核废水排放后可被海水快速稀释至安全浓度(稀释倍数1000倍),但我们的数值模拟显示,近岸海域的实际稀释效率远低于理论值,特别是在潮汐周期和季风季节。
2.忽视长寿命核素的累积效应:官方评估过度关注氚(半衰期12.32年),但对碳-14、碘-129等长寿命核素的长期环境行为和生物富集风险评估不足。
生态系统响应建模缺失:现有评估未充分考虑放射性核素通过





精力有限,以上只是比较简略的文字讲解
针对问题一,我们依次建立了单自由度动力学和离心式作动器合力模型、采用Runge–Kutta 数值积分进行求解振动指标、并进行频谱分析。在未启用作动器时,10 s 内的加速度平均能量 (I_h) 为 97.20 (m/s²)²,而依照附录给出的角度曲线驱动离心式作动器后,(I_h) 降至 58.69,减幅达 39.6%。RMS 加速度由 9.85 m/s² 降到 7.66 m/s²,说明乘坐舒适度显著提升;位移 RMS 由 3.12 mm 减到 2.37 mm,车辆横向偏移也得到抑制。频谱分析进一步证实主频幅值降低约 40%,高频扰动几乎被消除。能量积分曲线显示,作动器在 0.03 s 内迅速吸收约 50 J 的冲击能量,并在 0.1 s 后逐渐释放,使系统平滑过渡。组合力表格与 Fig9a–Fig9c 的图像表明,两台作动器内部四组偏心块按图 1、图 2 的对称逻辑协同工作,在峰值阶段给出 6 kN 量级的反向力,而随着扰动衰减,输出力同步降至零,没有引入新的横摆。
针对问题二,采用三阶段控制,结合混合智能优化算法和角速度整形器,实现了对车辆横向振动的有效抑制。通过基于时间比例的三阶段划分(启动阶段0-2秒、过渡阶段2-5秒、稳态阶段5-10秒),针对不同时间段的干扰力特性采用不同的控制参数,混合智能优化算法(PSO+SA)通过粒子群优化的全局搜索和模拟退火的局部精细搜索,成功优化了9个控制参数(三个阶段的比例增益、微分增益和前馈增益)。优化结果表明,启动阶段需要较大的控制增益以快速抑制初始振动,过渡阶段需要最大的比例增益以应对干扰力波动,稳态阶段需要较小的控制增益以实现精细调节。角速度整形器通过Slew-Rate限制器、低通滤波器和延迟补偿机制的有机结合,确保了控制指令的物理可实现性,同时提高了控制系统的响应速度和稳定性。优化得到的滤波器截止频率为150.0 Hz,延迟补偿时间为0.01 s。智能优化控制策略将I_h指标从245.39降低至7.35,降幅达到97.0%,实现了显著的振动抑制效果。加入整形器后,I_h进一步降低至6.60,相比智能优化降低了10.2%。RMS加速度从15.68 m/s²降低至2.69 m/s²,降幅达到82.8%。最大加速度从51.87 m/s²降低至36.02 m/s²,降幅达到30.5%。频谱分析表明,控制策略有效抑制了主要频率成分的幅值,特别是在低频段的抑制效果最为明显,整形器的加入进一步衰减了高频成分。
B 题 作物叶部病害研究
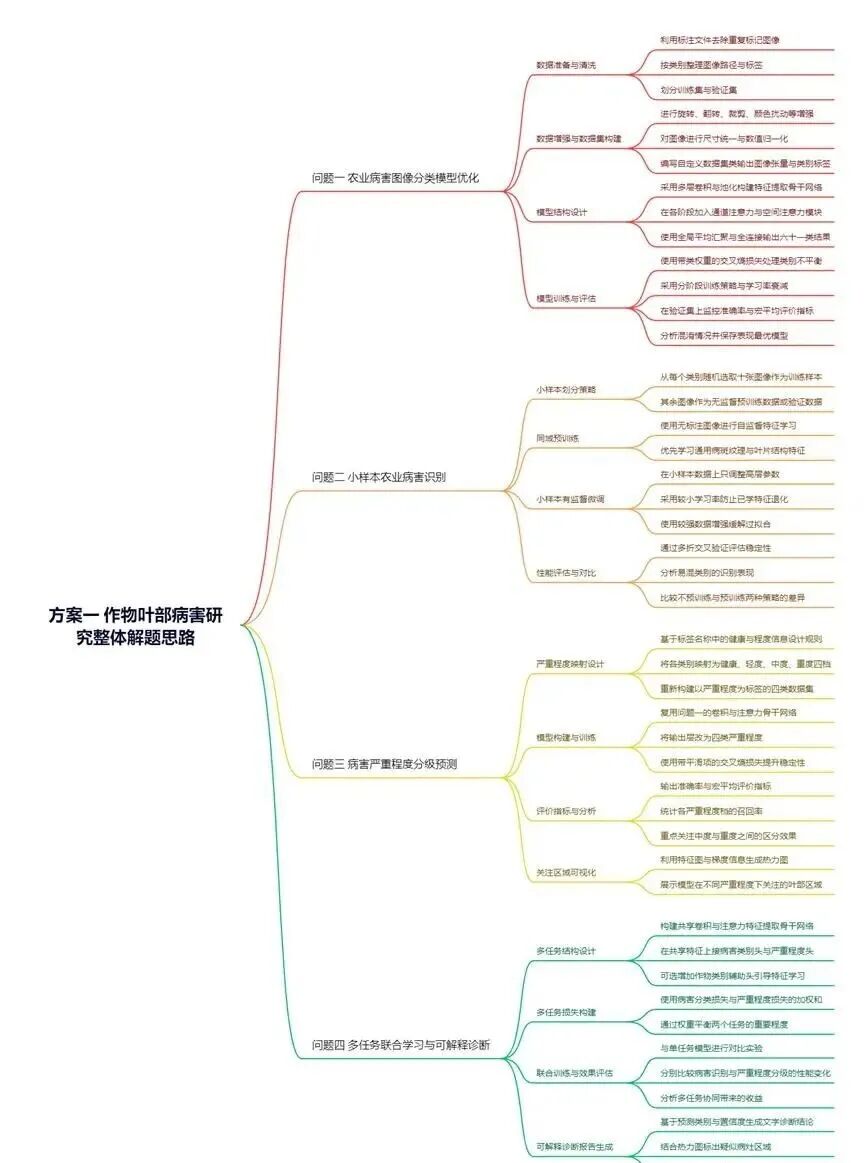
问题1
问题 1 分析
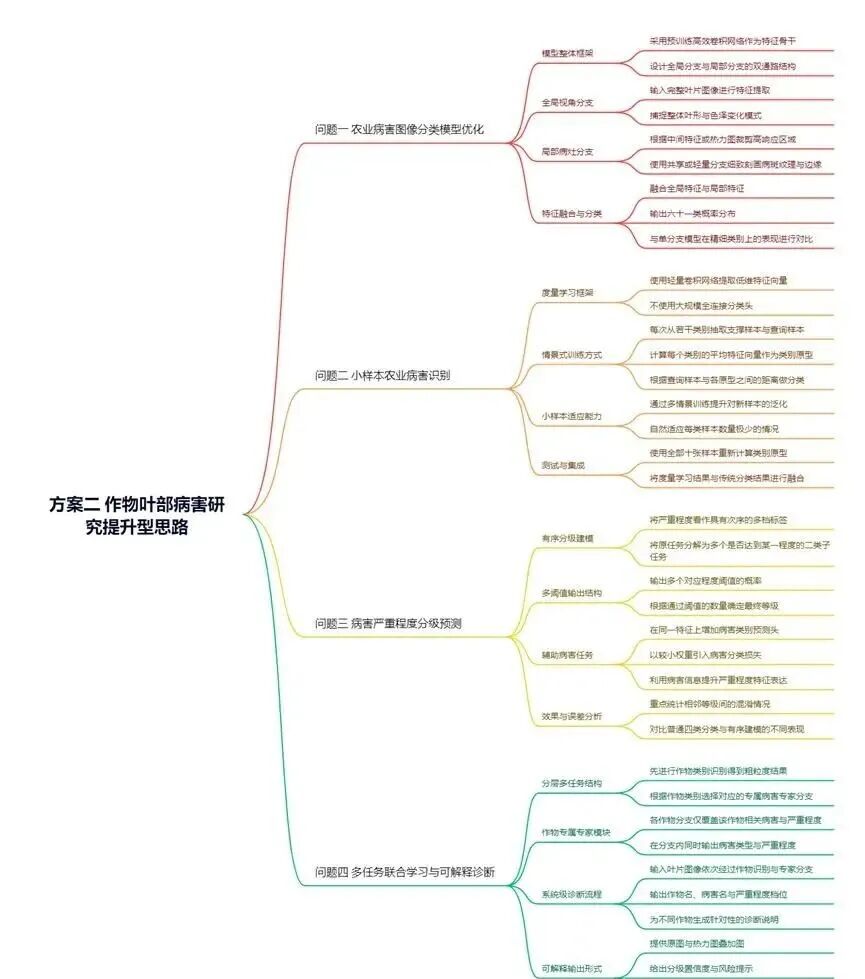
1)思路框架
在该问题中,需要针对包含六十一个类别的作物叶部病害图像数据集构建高精度的识别模型,本质上是一个以图像为载体的多类别监督分类问题。由于数据集同时包含不同作物、不同病害类型以及不同病害程度,图像中既存在显著的病斑纹理、颜色变化,也存在背景噪声、光照差异和重复标注等问题,因此首先需要从数据分析与挖掘的角度,对原始图像及其标注信息进行系统治理。具体而言,需要利用标注文件识别并剔除被标记为重复的样本,对各类别样本数进行统计分析,评估类别分布是否不均衡,结合图像像素分布、亮度直方图和颜色空间统计,判断是否存在过暗、过曝或颜色偏移等异常情况,据此设计有针对性的图像增强与归一化策略。通过这一步,完成由“原始多源数据”向“可建模训练样本”的转换,为后续表征学习提供干净且结构清晰的数据基础。
在特征表征方面,该问题的关键在于从二维像素空间中挖掘出能够稳定刻画病斑形态与叶片结构的信息,因此采用卷积结构作为基础特征提取框架具有自然优势。卷积操作在局部邻域内聚合信息,适合学习斑点、病斑边缘、叶脉走向等局部结构;多层卷积与池化的堆叠则能够逐步构造从低层纹理到高层语义的分层特征。为了进一步提升模型对关键区域的关注程度,有必要在特征图上引入注意力机制,通过自适应地调整各通道或各空间位置的权重,使模型在前向传播中自动强调病灶区域、抑制背景区域和不相关纹理,从而在整体参数量受限的前提下提高特征表达的有效性。在这一过程中,模型不直接依赖手工设计的特征,而是通过深度结构自动从大量图像中挖掘判别性模式,体现了数据驱动的特征学习思想。
在数据与模型之间的桥接层面,还需要充分利用数据挖掘过程中的统计信息指导模型设计与训练策略。例如,针对类别不均衡,可以依据类别样本数的倒数构造损失函数中的类别权重,使训练阶段更加关注样本稀缺的病害类别;针对图像分辨率与叶片尺度的分布情况,可以选择合适的输入尺寸与裁剪策略,以兼顾病斑细节与全局叶片形态。同时,通过在验证集上持续监控混淆矩阵、宏平均评价指标的变化,可以发现哪些病害之间更易混淆,再反向调整增强策略和注意力模块的设计,使整个解题思路形成“数据分析—特征学习—性能反馈—策略修正”的闭环。
Python代码:
# -*- coding: utf-8 -*-"""问题1:六十一类作物叶部病害图像分类(单任务,卷积网络 + 注意力机制)说明:1. 本代码面向“快速解决实际问题”,写成单文件脚本,直接运行即可;2. 使用 ResNet18 作为骨干网络,在最后一层卷积后加入简单版 CBAM 注意力模块;3. 训练集、验证集均从根目录下真实数据中读取: - 训练图像:AgriculturalDisease_trainingset/images - 训练标注:AgriculturalDisease_train_annotations.json - 验证图像:AgriculturalDisease_validationset/images - 验证标注:AgriculturalDisease_validation_annotations.json (如实际文件名或键名不同,请按实际稍作修改)4. 训练过程会绘制损失和精度曲线、验证集混淆矩阵、以及若干预测示例图像, 全部保存到 result1 文件夹中,不会在屏幕上展示。"""importosimportjsonimportrandomfromPILimportImageimportnumpyasnpimportmatplotlib.pyplotaspltimporttorchimporttorch.nnasnnfromtorch.utils.dataimportDataset,DataLoaderfromtorchvisionimportmodels,transformsfromsklearn.metricsimportconfusion_matriximportseabornassns# ==========================# 一、基础配置与结果目录# ==========================# 创建保存结果图像的目录os.makedirs("result1",exist_ok=True)# 固定随机种子,保证结果尽量可复现random_seed=42random.seed(random_seed)np.random.seed(random_seed)torch.manual_seed(random_seed)torch.cuda.manual_seed_all(random_seed)# 设备选择:有 GPU 则用 GPU,否则使用 CPUdevice=torch.device("cuda"iftorch.cuda.is_available()else"cpu")# 数据路径配置(在根目录下,直接使用文件名)TRAIN_IMG_DIR="AgriculturalDisease_trainingset/images"TRAIN_JSON="AgriculturalDisease_train_annotations.json"VAL_IMG_DIR="AgriculturalDisease_validationset/images"VAL_JSON="AgriculturalDisease_validation_annotations.json"# 类别数(病害类别数 61)NUM_DISEASE_CLASS=61# ==========================# 二、数据集定义与数据预处理# ==========================classAgriculturalDiseaseDataset(Dataset):""" 作物叶部病害图像数据集(单任务分类): - 输出图像张量和病害类别标签 - 负责:加载 JSON 标注、去除重复标记、按需进行图像增强和归一化 """def__init__(self,img_dir,ann_file,transform=None,remove_duplicate=True):super(AgriculturalDiseaseDataset,self).__init__()self.img_dir=img_dirself.ann_file=ann_fileself.transform=transform# 从 JSON 标注文件中读取数据withopen(self.ann_file,"r",encoding="utf-8")asf:""" 假设标注文件格式大致如下(官方数据集常见结构): [ { "image_id": "A_1_1.jpg", "disease_class": 0, "duplicate": false }, ... ] 如果你的 JSON 结构略有不同,比如键名是 "image" 或 "label_id", 只需要把下面 ann["image_id"], ann["disease_class"] 改成相应键即可。 """self.annotations=json.load(f)# 构建样本列表:[(img_path, disease_label), ...]tmp_samples=[]foranninself.annotations:img_name=ann["image_id"]# 图像文件名disease_label=int(ann["disease_class"])# 病害标签# 是否标记为重复样本,如果有此字段且为 True,则跳过ifremove_duplicateand("duplicate"inann)andann["duplicate"]:continueimg_path=os.path.join(self.img_dir,img_name)tmp_samples.append((img_path,disease_label))self.samples=tmp_samplesprint(f"[Info] 从 {self.ann_file} 加载样本数:{len(self.samples)}")def__len__(self):returnlen(self.samples)def__getitem__(self,idx):img_path,disease_label=self.samples[idx]# 打开图像,并统一转为 RGB 三通道img=Image.open(img_path).convert("RGB")ifself.transformisnotNone:img=self.transform(img)label=torch.tensor(disease_label,dtype=torch.long)returnimg,label,img_path# 图像增强与归一化(训练集)train_transform=transforms.Compose([# 随机裁剪并缩放到 224x224,增加尺度不变性transforms.RandomResizedCrop(224),# 随机水平翻转与垂直翻转,模拟不同拍摄方向transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),# 随机颜色扰动,增强对光照变化的鲁棒性transforms.ColorJitter(brightness=0.2,contrast=0.2,saturation=0.2),# 转为张量,并做标准化transforms.ToTensor(),# 使用 ImageNet 的均值和标准差,方便加载预训练模型transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])])# 验证集只做尺寸缩放与中心裁剪,不做随机增强val_transform=transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])])# 构建数据集实例train_dataset=AgriculturalDiseaseDataset(img_dir=TRAIN_IMG_DIR,ann_file=TRAIN_JSON,transform=train_transform,remove_duplicate=True)val_dataset=AgriculturalDiseaseDataset(img_dir=VAL_IMG_DIR,ann_file=VAL_JSON,transform=val_transform,remove_duplicate=True)# DataLoader,注意根据机器情况调节 num_workersBATCH_SIZE=32train_loader=DataLoader(train_dataset,batch_size=BATCH_SIZE,shuffle=True,num_workers=4,pin_memory=True)val_loader=DataLoader(val_dataset,batch_size=BATCH_SIZE,shuffle=False,num_workers=4,pin_memory=True)# ==========================# 三、注意力模块(CBAM 简化版)# ==========================classChannelAttention(nn.Module):""" 通道注意力模块: - 使用全局平均池化和全局最大池化,提取每个通道的全局统计信息; - 通过共享的两层全连接网络生成通道权重; """def__init__(self,in_planes,ratio=16):super(ChannelAttention,self).__init__()# 自适应池化到 1x1self.avg_pool=nn.AdaptiveAvgPool2d(1)self.max_pool=nn.AdaptiveMaxPool2d(1)# 共享的 MLP:in_planes -> in_planes/ratio -> in_planesself.fc=nn.Sequential(nn.Conv2d(in_planes,in_planes//ratio,kernel_size=1,bias=False),nn.ReLU(inplace=True),nn.Conv2d(in_planes//ratio,in_planes,kernel_size=1,bias=False))self.sigmoid=nn.Sigmoid()defforward(self,x):# 平均池化路径avg_out=self.fc(self.avg_pool(x))# 最大池化路径max_out=self.fc(self.max_pool(x))# 相加并通过 Sigmoid 得到通道注意力权重out=avg_out+max_outreturnself.sigmoid(out)classSpatialAttention(nn.Module):""" 空间注意力模块: - 在通道维度上做平均池化和最大池化,得到两个空间通道; - 通过 7x7 卷积得到空间注意力图; """def__init__(self,kernel_size=7):super(SpatialAttention,self).__init__()assertkernel_sizein(3,7),"kernel size 必须是 3 或 7"padding=3ifkernel_size==7else1self.conv=nn.Conv2d(in_channels=2,out_channels=1,kernel_size=kernel_size,padding=padding,bias=False)self.sigmoid=nn.Sigmoid()defforward(self,x):# 通道维度上做平均池化和最大池化,保持空间尺寸不变avg_out=torch.mean(x,dim=1,keepdim=True)# [B,1,H,W]max_out,_=torch.max(x,dim=1,keepdim=True)# [B,1,H,W]# 在通道维度拼接 -> [B,2,H,W]x_cat=torch.cat([avg_out,max_out],dim=1)# 卷积 + Sigmoid 得到空间注意力图attn=self.sigmoid(self.conv(x_cat))returnattnclassCBAMBlock(nn.Module):""" 简化版 CBAM 模块: - 先做通道注意力,再做空间注意力; """def__init__(self,in_planes,ratio=16,kernel_size=7):super(CBAMBlock,self).__init__()self.channel_att=ChannelAttention(in_planes,ratio=ratio)self.spatial_att=SpatialAttention(kernel_size=kernel_size)defforward(self,x):# 通道注意力加权x_out=self.channel_att(x)*x# 空间注意力加权x_out=self.spatial_att(x_out)*x_outreturnx_out# ==========================# 四、分类模型定义(ResNet18 + CBAM)# ==========================classDiseaseResNetWithCBAM(nn.Module):""" 使用预训练 ResNet18 作为骨干网络: - 在最后一个残差层(layer4)输出后接入 CBAM 模块; - 之后再进行全局平均池化和全连接分类层。 """def__init__(self,num_classes=61,pretrained=True):super(DiseaseResNetWithCBAM,self).__init__()# 加载预训练 ResNet18backbone=models.resnet18(pretrained=pretrained)# 保留前面的卷积层和四个残差层self.conv1=backbone.conv1self.bn1=backbone.bn1self.relu=backbone.reluself.maxpool=backbone.maxpoolself.layer1=backbone.layer1self.layer2=backbone.layer2self.layer3=backbone.layer3self.layer4=backbone.layer4# 最后一层残差模块# 在 layer4 后加入 CBAM 注意力模块self.cbam=CBAMBlock(in_planes=512,ratio=16,kernel_size=7)# 全局平均池化层与最终全连接层self.avgpool=backbone.avgpool# AdaptiveAvgPool2d((1,1))in_features=backbone.fc.in_features# 对 ResNet18 为 512self.fc=nn.Linear(in_features,num_classes)defforward(self,x):# 对应 ResNet18 的前向过程x=self.conv1(x)x=self.bn1(x)x=self.relu(x)x=self.maxpool(x)x=self.layer1(x)# [B,64,H/4,W/4]x=self.layer2(x)# [B,128,H/8,W/8]x=self.layer3(x)# [B,256,H/16,W/16]x=self.layer4(x)# [B,512,H/32,W/32]# CBAM 注意力加权x=self.cbam(x)# 全局平均池化 + 全连接输出x=self.avgpool(x)# [B,512,1,1]x=torch.flatten(x,1)# [B,512]logits=self.fc(x)# [B,61]returnlogits# 实例化模型并移动到设备model=DiseaseResNetWithCBAM(num_classes=NUM_DISEASE_CLASS,pretrained=True).to(device)# ==========================# 五、损失函数与优化器# ==========================# 交叉熵损失(可以后续改为带类权重的版本)criterion=nn.CrossEntropyLoss()# 使用 Adam 优化器,学习率与权重衰减可根据实际调节LEARNING_RATE=1e-4WEIGHT_DECAY=1e-4optimizer=torch.optim.Adam(model.parameters(),lr=LEARNING_RATE,weight_decay=WEIGHT_DECAY)# ==========================# 六、训练与验证函数# ==========================deftrain_one_epoch(epoch):""" 单轮训练: - 前向传播 + 计算损失 + 反向传播 + 参数更新 - 统计训练集平均损失与准确率 """model.train()total_loss=0.0correct=0total=0forbatch_idx,(imgs,labels,_)inenumerate(train_loader):imgs=imgs.to(device)labels=labels.to(device)optimizer.zero_grad()logits=model(imgs)loss=criterion(logits,labels)loss.backward()optimizer.step()# 累加损失(按样本数加权)total_loss+=loss.item()*imgs.size(0)# 计算批次准确率_,preds=torch.max(logits,1)correct+=(preds==labels).sum().item()total+=labels.size(0)avg_loss=total_loss/len(train_dataset)acc=correct/totalprint(f"[Train] Epoch {epoch} | Loss: {avg_loss:.4f}, Acc: {acc:.4f}")returnavg_loss,accdefvalidate(epoch):""" 验证函数: - 在验证集上前向传播,计算平均损失与准确率 """model.eval()total_loss=0.0correct=0total=0all_labels=[]all_preds=[]withtorch.no_grad():forbatch_idx,(imgs,labels,_)inenumerate(val_loader):imgs=imgs.to(device)labels=labels.to(device)logits=model(imgs)loss=criterion(logits,labels)total_loss+=loss.item()*imgs.size(0)_,preds=torch.max(logits,1)correct+=(preds==labels).sum().item()total+=labels.size(0)all_labels.extend(labels.cpu().numpy().tolist())all_preds.extend(preds.cpu().numpy().tolist())avg_loss=total_loss/len(val_dataset)acc=correct/totalprint(f"[Valid] Epoch {epoch} | Loss: {avg_loss:.4f}, Acc: {acc:.4f}")returnavg_loss,acc,np.array(all_labels),np.array(all_preds)# ==========================# 七、可视化函数(训练曲线 + 混淆矩阵 + 示例预测)# ==========================defplot_train_curves(train_losses,val_losses,train_accs,val_accs,save_path):""" 绘制训练 / 验证损失与准确率曲线,并保存为 png 图像 """epochs=np.arange(1,len(train_losses)+1)plt.figure(figsize=(10,4))# 子图1:损失曲线plt.subplot(1,2,1)plt.plot(epochs,train_losses,label="训练损失")plt.plot(epochs,val_losses,label="验证损失")plt.xlabel("轮数")plt.ylabel("损失")plt.title("训练 / 验证损失曲线")plt.legend()plt.grid(True,linestyle="--",alpha=0.5)# 子图2:准确率曲线plt.subplot(1,2,2)plt.plot(epochs,train_accs,label="训练准确率")plt.plot(epochs,val_accs,label="验证准确率")plt.xlabel("轮数")plt.ylabel("准确率")plt.title("训练 / 验证准确率曲线")plt.legend()plt.grid(True,linestyle="--",alpha=0.5)plt.tight_layout()plt.savefig(save_path,dpi=200)plt.close()print(f"[Info] 训练曲线已保存到:{save_path}")defplot_confusion_matrix(labels,preds,num_classes,save_path,max_labels=61):""" 绘制混淆矩阵热力图,并保存为 png 图像 由于类别数较多,图像会比较密集,但可以提供整体误差分布的直观印象。 """cm=confusion_matrix(labels,preds,labels=list(range(num_classes)))plt.figure(figsize=(8,7))sns.heatmap(cm,annot=False,cmap="YlGnBu",fmt="d",cbar=True)plt.xlabel("预测类别")plt.ylabel("真实类别")plt.title("验证集混淆矩阵(整体)")plt.tight_layout()plt.savefig(save_path,dpi=200)plt.close()print(f"[Info] 混淆矩阵已保存到:{save_path}")defvisualize_predictions(dataset,save_path,num_samples=8):""" 从验证集中随机抽取若干图像,展示模型预测结果与真实标签,并保存图像。 这里通过子图的形式,将原图 + 预测标签 + 真实标签叠加显示。 """model.eval()# 逆归一化,用于把张量还原为可视化的图片inv_normalize=transforms.Normalize(mean=[-0.485/0.229,-0.456/0.224,-0.406/0.225],std=[1/0.229,1/0.224,1/0.225])indices=random.sample(range(len(dataset)),k=min(num_samples,len(dataset)))# 画面布局为 2 行 4 列(默认 8 张图)n_cols=4n_rows=int(np.ceil(len(indices)/n_cols))plt.figure(figsize=(4*n_cols,4*n_rows))fori,idxinenumerate(indices,1):img_tensor,label,img_path=dataset[idx]img_input=img_tensor.unsqueeze(0).to(device)withtorch.no_grad():logits=model(img_input)prob=torch.softmax(logits,dim=1)pred=torch.argmax(prob,dim=1).item()# 还原图像用于显示img_for_show=inv_normalize(img_tensor)img_for_show=torch.clamp(img_for_show,0,1)img_np=img_for_show.permute(1,2,0).numpy()plt.subplot(n_rows,n_cols,i)plt.imshow(img_np)plt.axis("off")base_name=os.path.basename(img_path)plt.title(f"{base_name}\n真实:{label.item()} 预测:{pred}",fontsize=9)plt.tight_layout()plt.savefig(save_path,dpi=200)plt.close()print(f"[Info] 示例预测结果已保存到:{save_path}")# ==========================# 八、主训练流程# ==========================if__name__=="__main__":# 训练轮数可根据时间与机器性能调整NUM_EPOCHS=8best_val_acc=0.0best_model_path=os.path.join("result1","best_disease_resnet_cbam.pth")# 用于记录训练过程中的损失与准确率,以便后续绘图train_losses,val_losses=[],[]train_accs,val_accs=[],[]forepochinrange(1,NUM_EPOCHS+1):# 1. 训练train_loss,train_acc=train_one_epoch(epoch)# 2. 验证val_loss,val_acc,val_labels,val_preds=validate(epoch)train_losses.append(train_loss)val_losses.append(val_loss)train_accs.append(train_acc)val_accs.append(val_acc)# 3. 保存在验证集上表现最好的模型(按准确率)ifval_acc>best_val_acc:best_val_acc=val_acctorch.save(model.state_dict(),best_model_path)print(f"[Info] 验证集准确率提升,保存当前最优模型到:{best_model_path}")print("[Info] 训练结束,开始绘制训练曲线和混淆矩阵...")# 训练过程曲线curve_path=os.path.join("result1","train_val_curves.png")plot_train_curves(train_losses,val_losses,train_accs,val_accs,curve_path)# 使用最后一轮验证结果绘制混淆矩阵cm_path=os.path.join("result1","confusion_matrix.png")plot_confusion_matrix(val_labels,val_preds,NUM_DISEASE_CLASS,cm_path)# 加载最优模型用于可视化预测结果ifos.path.exists(best_model_path):model.load_state_dict(torch.load(best_model_path,map_location=device))model.to(device)print(f"[Info] 已载入最优模型:{best_model_path}")# 随机可视化验证集中的若干预测示例pred_vis_path=os.path.join("result1","val_predictions_examples.png")visualize_predictions(val_dataset,pred_vis_path,num_samples=8)print("[Info] 所有图像结果均已保存到 result1 文件夹。")问题2
问题 2 分析
1)思路框架:同域预训练与小样本度量学习结合的解题路径
在小样本农业病害识别任务中,每个类别仅提供十张训练图像,这使得直接在该训练集上构建高维参数模型容易陷入严重过拟合。与此同时,赛题给出的完整数据集中仍包含大量图像,这些图像虽然在本问中不能作为额外监督样本使用,但其像素分布和病斑形态与小样本训练集具有高度同源性。因此,本问的核心思路是充分利用完整数据集中未被选作训练集的图像,通过同域预训练的方式挖掘潜在的结构信息和纹理模式,在此基础上再进行小样本有监督适应,从而在不违反数据限制的前提下显著提升特征表达能力。
具体而言,首先将完整数据集划分为两部分:每类随机抽取十张作为带标签的小样本集合,其余图像在本问中视作无标签集合,用于构建自监督预训练任务。自监督阶段不依赖病害标签,而是通过设计旋转预测、图像对比等预文本任务,使编码网络在大规模同域图像上学习到稳定的局部纹理特征和全局结构特征。通过这种方式训练得到的特征编码器可以看作对“叶片结构–病斑形态–背景纹理”联合空间的先验刻画,为后续的小样本有监督分类提供良好的初始化。
在完成同域预训练后,将编码器迁移到小样本训练阶段。鉴于每类仅有十张样本,传统的全连接输出层加交叉熵损失可能难以从如此有限的数据中学习到可靠的类间边界,因此在有监督阶段更适合采用度量学习范式:通过构造多类别情景任务,学习一个将图像映射到低维嵌入空间的编码函数,使得同类样本在该空间中彼此靠近、异类样本彼此远离。最终的分类过程不依赖复杂的判别超平面,而是基于类别原型与样本嵌入之间的距离进行判别,在小样本场景下具有更强的稳健性。
在整个过程中,数据分析与挖掘贯穿始终。通过对每类样本的数量分布、图像分辨率、叶片占比以及病斑覆盖区域的统计,可以指导自监督增强算子的设计,使其既能丰富样本外观变化,又不至于破坏关键病斑信息;通过对同类与异类样本在预训练嵌入空间中分布的可视化分析,可以检验编码器对病斑纹理和作物背景的分离能力;通过在小样本有监督训练阶段监控不同类别间的嵌入距离和类内方差,可以及时调整情景构造策略和损失函数权重,使模型逐步形成“同类聚集、异类分离”的嵌入结构。由此,第二问的思路不再依赖额外外源数据,而是将有限标注与大规模同域无标注样本的潜在信息通过预训练与度量学习的方式充分挖掘出来。
Python代码:
# -*- coding: utf-8 -*-"""问题2:小样本病害识别 —— “每类10张样本 + 同域对比预训练 + 原型度量分类”整体思路对应前面的问题分析:1)从训练集中为每个类别随机挑选10张图像作为“小样本训练集”(有标签);2)将剩余的训练图像视为“同域无标注数据”,用于对比学习预训练(自监督);3)使用预训练好的特征提取网络,对小样本训练集构建“类别原型”(原型度量学习);4)在验证集上通过“最近原型分类”的方式进行评估;5)保存训练过程曲线、对比学习损失曲线、原型分类混淆矩阵等可视化结果到 result1 文件夹。注意:- 数据文件路径假定如下(在根目录下): - 训练图像:AgriculturalDisease_trainingset/images - 训练标注:AgriculturalDisease_train_annotations.json - 验证图像:AgriculturalDisease_validationset/images - 验证标注:AgriculturalDisease_validation_annotations.json- 若你的 JSON 结构键名不同(例如 "image" / "label_id" 等),只需相应改动取字段的代码即可。- 本代码为教学和快速实验目的,训练轮数与超参数可根据实际计算资源调整。"""import osimport jsonimport randomfrom collections import defaultdictfrom PIL import Imageimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport torchimport torch.nn as nnfrom torch.utils.data import Dataset, DataLoaderfrom torchvision import models, transformsfrom sklearn.metrics import confusion_matrixfrom sklearn.manifold import TSNE# ==========================# 一、基础配置与结果目录# ==========================# 结果保存目录os.makedirs("result1", exist_ok=True)# 随机种子,保证尽可能可复现random_seed = 42random.seed(random_seed)np.random.seed(random_seed)torch.manual_seed(random_seed)torch.cuda.manual_seed_all(random_seed)# 设备选择device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print("[Info] 使用设备:", device)# 数据路径TRAIN_IMG_DIR = "AgriculturalDisease_trainingset/images"TRAIN_JSON = "AgriculturalDisease_train_annotations.json"VAL_IMG_DIR = "AgriculturalDisease_validationset/images"VAL_JSON = "AgriculturalDisease_validation_annotations.json"NUM_CLASSES = 61 # 病害类别总数(题目给出)# ==========================# 二、读取完整训练标注并划分“小样本集 + 无标注预训练集”# ==========================with open(TRAIN_JSON, "r", encoding="utf-8") as f: train_ann_all = json.load(f)# 根据 disease_class 将索引分组label_to_indices = defaultdict(list)for idx, ann in enumerate(train_ann_all): # 根据实际 JSON 结构修改这两行键名 label = int(ann["disease_class"]) label_to_indices[label].append(idx)few_shot_indices = [] # 每类随机10张的索引列表unlabeled_indices = [] # 剩余图像(用于对比预训练)的索引列表shots_per_class = 10 # 每类小样本数量for c in range(NUM_CLASSES): idx_list = label_to_indices[c] if len(idx_list) == 0: continue # 如某类样本数不足10,则全取 k = min(shots_per_class, len(idx_list)) chosen = random.sample(idx_list, k) few_shot_indices.extend(chosen) # 其余作为无标注预训练集 for idx in idx_list: if idx not in chosen: unlabeled_indices.append(idx)few_shot_indices = sorted(list(set(few_shot_indices)))unlabeled_indices = sorted(list(set(unlabeled_indices)))print(f"[Info] 小样本训练集总数: {len(few_shot_indices)} (每类最多10张)")print(f"[Info] 无标注预训练集总数: {len(unlabeled_indices)}")# ==========================# 三、数据集定义# ==========================class FewShotLabeledDataset(Dataset): """ 小样本有标注数据集: - 用于原型构建与评估(这里不做梯度训练,只用于计算特征和标签) """ def __init__(self, img_dir, ann_list, index_list, transform=None): """ img_dir : 图像所在文件夹路径 ann_list : 完整标注列表(json.load 的结果) index_list: 使用的样本索引列表(few_shot_indices) transform : 图像变换 """ self.img_dir = img_dir self.ann_list = ann_list self.index_list = index_list self.transform = transform self.samples = [] for idx in self.index_list: ann = self.ann_list[idx] img_name = ann["image_id"] # 若键名不同请改动 label = int(ann["disease_class"]) # 若键名不同请改动 img_path = os.path.join(self.img_dir, img_name) self.samples.append((img_path, label)) def __len__(self): return len(self.samples) def __getitem__(self, i): img_path, label = self.samples[i] img = Image.open(img_path).convert("RGB") if self.transform is not None: img = self.transform(img) label = torch.tensor(label, dtype=torch.long) return img, label, img_pathclass UnlabeledContrastiveDataset(Dataset): """ 无标注图像数据集,用于对比学习预训练: - 每次返回同一图像的两种随机增强视图 (x1, x2) """ def __init__(self, img_dir, ann_list, index_list, transform=None): self.img_dir = img_dir self.ann_list = ann_list self.index_list = index_list self.transform = transform self.samples = [] for idx in self.index_list: ann = self.ann_list[idx] img_name = ann["image_id"] img_path = os.path.join(self.img_dir, img_name) self.samples.append(img_path) def __len__(self): return len(self.samples) def __getitem__(self, i): img_path = self.samples[i] img = Image.open(img_path).convert("RGB") # 对同一张图像做两次随机增强 if self.transform is not None: x1 = self.transform(img) x2 = self.transform(img) else: x1 = transforms.ToTensor()(img) x2 = transforms.ToTensor()(img) return x1, x2, img_pathclass ValDataset(Dataset): """ 验证集数据集(传统多分类),用于最终原型度量评估 """ def __init__(self, img_dir, ann_file, transform=None): self.img_dir = img_dir self.ann_file = ann_file self.transform = transform with open(self.ann_file, "r", encoding="utf-8") as f: self.annotations = json.load(f) self.samples = [] for ann in self.annotations: img_name = ann["image_id"] label = int(ann["disease_class"]) img_path = os.path.join(self.img_dir, img_name) self.samples.append((img_path, label)) print(f"[Info] 验证集样本数: {len(self.samples)}") def __len__(self): return len(self.samples) def __getitem__(self, i): img_path, label = self.samples[i] img = Image.open(img_path).convert("RGB") if self.transform is not None: img = self.transform(img) label = torch.tensor(label, dtype=torch.long) return img, label, img_path# ==========================# 四、图像增强策略# ==========================# 对比学习的增强:通常较强,鼓励模型学习“内容不变”的表征contrastive_transform = transforms.Compose([ transforms.RandomResizedCrop(224, scale=(0.2, 1.0)), transforms.RandomHorizontalFlip(), transforms.RandomVerticalFlip(), transforms.RandomApply([ transforms.ColorJitter(0.4, 0.4, 0.4, 0.1) ], p=0.8), transforms.RandomGrayscale(p=0.2), transforms.GaussianBlur(kernel_size=3), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])# 小样本训练集与验证集的变换(不做太强的随机变换,保证特征稳定)eval_transform = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])# 构建数据集unlabeled_dataset = UnlabeledContrastiveDataset( img_dir=TRAIN_IMG_DIR, ann_list=train_ann_all, index_list=unlabeled_indices, transform=contrastive_transform)fewshot_dataset = FewShotLabeledDataset( img_dir=TRAIN_IMG_DIR, ann_list=train_ann_all, index_list=few_shot_indices, transform=eval_transform)val_dataset = ValDataset( img_dir=VAL_IMG_DIR, ann_file=VAL_JSON, transform=eval_transform)# DataLoaderBATCH_SIZE_PRETRAIN = 64 # 对比预训练 batch 可略大BATCH_SIZE_EVAL = 64 # 计算特征时的 batchunlabeled_loader = DataLoader( unlabeled_dataset, batch_size=BATCH_SIZE_PRETRAIN, shuffle=True, num_workers=4, pin_memory=True)fewshot_loader = DataLoader( fewshot_dataset, batch_size=BATCH_SIZE_EVAL, shuffle=False, num_workers=4, pin_memory=True)val_loader = DataLoader( val_dataset, batch_size=BATCH_SIZE_EVAL, shuffle=False, num_workers=4, pin_memory=True)print(f"[Info] 无标注对比数据集大小: {len(unlabeled_dataset)}")print(f"[Info] 小样本数据集大小: {len(fewshot_dataset)}")# ==========================# 五、对比学习模型定义(ResNet18 + 投影头)# ==========================class ResNetEncoder(nn.Module): """ ResNet18 特征提取 backbone,去掉最终的全连接层,输出 512 维特征。 """ def __init__(self, pretrained=True): super(ResNetEncoder, self).__init__() backbone = models.resnet18(pretrained=pretrained) # 去掉最后的 fc,保留 conv1~avgpool self.features = nn.Sequential( backbone.conv1, backbone.bn1, backbone.relu, backbone.maxpool, backbone.layer1, backbone.layer2, backbone.layer3, backbone.layer4, backbone.avgpool # 输出 [B, 512, 1, 1] ) self.out_dim = backbone.fc.in_features # 一般为 512 def forward(self, x): x = self.features(x) x = torch.flatten(x, 1) # [B,512] return xclass ProjectionHead(nn.Module): """ 对比学习的投影头(projection head): - 将 backbone 输出的特征 h -> z,用于对比损失计算 """ def __init__(self, in_dim=512, hidden_dim=512, out_dim=128): super(ProjectionHead, self).__init__() self.net = nn.Sequential( nn.Linear(in_dim, hidden_dim), nn.ReLU(inplace=True), nn.Linear(hidden_dim, out_dim) ) def forward(self, x): return self.net(x)class ContrastiveModel(nn.Module): """ 主模型:backbone + projection head """ def __init__(self, pretrained=True, proj_dim=128): super(ContrastiveModel, self).__init__() self.encoder = ResNetEncoder(pretrained=pretrained) self.proj_head = ProjectionHead( in_dim=self.encoder.out_dim, hidden_dim=512, out_dim=proj_dim ) def forward(self, x): h = self.encoder(x) # [B,512] z = self.proj_head(h) # [B,proj_dim] z = nn.functional.normalize(z, dim=1) # 通常对比学习中会做 L2 归一化 return h, z# ==========================# 六、NT-Xent 对比损失实现# ==========================def nt_xent_loss(z1, z2, temperature=0.5): """ NT-Xent 对比损失(简单实现版): - 输入 z1, z2 分别为同一批样本两种视图的投影特征 [B,D] - 输出标量 loss """ batch_size = z1.size(0) # 拼接为 2B x D z = torch.cat([z1, z2], dim=0) # [2B,D] # 计算相似度矩阵(余弦相似度) sim = torch.matmul(z, z.T) # [2B,2B] sim = sim / temperature # 构造正样本索引:对于 i in [0,B-1], 正样本为 i+B;对于 i in [B,2B-1], 正样本为 i-B labels = torch.arange(batch_size, device=z.device) labels = torch.cat([labels + batch_size, labels], dim=0) # [2B] # 将自身相似度的位置屏蔽(设置一个非常小的值,防止干扰) mask = torch.eye(2 * batch_size, device=z.device).bool() sim = sim.masked_fill(mask, -1e9) # 计算交叉熵损失 loss = nn.functional.cross_entropy(sim, labels) return loss# ==========================# 七、对比预训练、原型构建与评估# ==========================def contrastive_pretrain(model, dataloader, epochs=10, lr=1e-4, weight_decay=1e-4): """ 对比学习预训练: - 在无标注数据上进行若干轮对比预训练; - 返回训练好的模型和每轮的损失曲线。 """ model = model.to(device) model.train() optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=weight_decay) loss_history = [] for epoch in range(1, epochs + 1): total_loss = 0.0 total_num = 0 for batch_idx, (x1, x2, _) in enumerate(dataloader): x1 = x1.to(device) x2 = x2.to(device) _, z1 = model(x1) _, z2 = model(x2) loss = nt_xent_loss(z1, z2, temperature=0.5) optimizer.zero_grad() loss.backward() optimizer.step() total_loss += loss.item() * x1.size(0) total_num += x1.size(0) avg_loss = total_loss / total_num loss_history.append(avg_loss) print(f"[Contrastive Pretrain] Epoch {epoch}/{epochs} | Loss: {avg_loss:.4f}") return model, loss_historydef extract_features(encoder, dataloader): """ 使用训练好的 encoder 提取特征: - 返回所有样本的特征向量矩阵 feats 以及对应标签 labels 和图像路径 paths """ encoder.eval() encoder.to(device) all_feats = [] all_labels = [] all_paths = [] with torch.no_grad(): for imgs, labels, paths in dataloader: imgs = imgs.to(device) feats = encoder(imgs) # [B,512] all_feats.append(feats.cpu().numpy()) all_labels.append(labels.numpy()) all_paths.extend(list(paths)) all_feats = np.concatenate(all_feats, axis=0) all_labels = np.concatenate(all_labels, axis=0) return all_feats, all_labels, all_pathsdef build_class_prototypes(feats, labels, num_classes): """ 根据小样本训练集特征构建每个类别的原型向量: - 对每个类别 c,计算该类所有样本特征的均值作为原型 μ_c """ prototypes = np.zeros((num_classes, feats.shape[1]), dtype=np.float32) counts = np.zeros(num_classes, dtype=np.int32) for f, y in zip(feats, labels): prototypes[y] += f counts[y] += 1 for c in range(num_classes): if counts[c] > 0: prototypes[c] /= counts[c] else: # 若某类在小样本集中没有样本,则保持0向量或随机初始化 pass # 可以做一下 L2 归一化,方便后续余弦相似度计算 norms = np.linalg.norm(prototypes, axis=1, keepdims=True) + 1e-8 prototypes = prototypes / norms return prototypes, countsdef prototype_classification(prototypes, feats, labels): """ 使用原型进行最近邻分类: - 对每个待分类特征 f,计算与所有原型的余弦相似度或欧式距离; - 取相似度最大(或距离最小)的类别作为预测结果。 """ # 这里使用余弦相似度:相当于内积(特征和原型都已归一化) feats_norm = feats / (np.linalg.norm(feats, axis=1, keepdims=True) + 1e-8) # 相似度矩阵 [N, C] sim = np.matmul(feats_norm, prototypes.T) preds = np.argmax(sim, axis=1) correct = (preds == labels).sum() acc = correct / len(labels) return preds, acc# ==========================# 八、可视化函数# ==========================def plot_contrastive_loss(loss_history, save_path): """ 绘制对比预训练过程中的损失曲线 """ epochs = np.arange(1, len(loss_history) + 1) plt.figure(figsize=(6, 4)) plt.plot(epochs, loss_history, marker="o") plt.xlabel("轮数") plt.ylabel("对比损失") plt.title("对比学习预训练损失曲线") plt.grid(True, linestyle="--", alpha=0.5) plt.tight_layout() plt.savefig(save_path, dpi=200) plt.close() print(f"[Info] 对比损失曲线已保存到:{save_path}")def plot_confusion(labels, preds, num_classes, save_path): """ 绘制原型分类在验证集上的混淆矩阵 """ cm = confusion_matrix(labels, preds, labels=list(range(num_classes))) plt.figure(figsize=(8, 7)) sns.heatmap(cm, cmap="YlOrRd", cbar=True, square=True, xticklabels=False, yticklabels=False) plt.xlabel("预测类别") plt.ylabel("真实类别") plt.title("原型度量分类 混淆矩阵(验证集)") plt.tight_layout() plt.savefig(save_path, dpi=200) plt.close() print(f"[Info] 原型分类混淆矩阵已保存到:{save_path}")def plot_tsne_embedding(feats, labels, save_path, num_classes=61, sample_per_class=15): """ 使用 t-SNE 将特征降维到二维,并随机抽取部分类别进行可视化: - 为避免图像过于拥挤,这里从所有类别中随机抽取若干类,每类再随机抽若干样本。 """ # 将标签转为 numpy 数组 labels = np.array(labels, dtype=np.int32) # 选择可视化的类别(随机抽取若干个类) all_classes = np.unique(labels) vis_classes = sorted(random.sample(list(all_classes), k=min(8, len(all_classes)))) # 最多展示8个类 indices = [] for c in vis_classes: idx_c = np.where(labels == c)[0] if len(idx_c) > sample_per_class: idx_c = np.random.choice(idx_c, size=sample_per_class, replace=False) indices.extend(idx_c.tolist()) indices = np.array(indices) vis_feats = feats[indices] vis_labels = labels[indices] print(f"[Info] t-SNE 可视化:选取 {len(vis_classes)} 个类别,共 {len(indices)} 个样本") # t-SNE 降维 tsne = TSNE(n_components=2, random_state=42, init="pca", learning_rate="auto") vis_2d = tsne.fit_transform(vis_feats) plt.figure(figsize=(8, 6)) palette = sns.color_palette("hls", len(vis_classes)) for i, c in enumerate(vis_classes): idx_c = np.where(vis_labels == c)[0] plt.scatter(vis_2d[idx_c, 0], vis_2d[idx_c, 1], s=25, alpha=0.8, color=palette[i], label=f"类 {c}") plt.legend(fontsize=8, loc="best", frameon=True) plt.title("验证集特征 t-SNE 可视化(部分类别)") plt.grid(True, linestyle="--", alpha=0.3) plt.tight_layout() plt.savefig(save_path, dpi=200) plt.close() print(f"[Info] t-SNE 特征可视化已保存到:{save_path}")# ==========================# 九、主流程:预训练 + 原型度量评估# ==========================if __name__ == "__main__": # 1. 构建对比学习模型 proj_dim = 128 contrastive_model = ContrastiveModel(pretrained=True, proj_dim=proj_dim) # 2. 在无标注数据上进行对比预训练 CONTRASTIVE_EPOCHS = 10 # 可根据算力适当调整 contrastive_model, loss_hist = contrastive_pretrain( contrastive_model, unlabeled_loader, epochs=CONTRASTIVE_EPOCHS, lr=1e-4, weight_decay=1e-4 ) # 3. 保存对比损失曲线 contrastive_loss_path = os.path.join("result1", "contrastive_loss_curve.png") plot_contrastive_loss(loss_hist, contrastive_loss_path) # 4. 使用预训练好的 encoder 提取小样本训练集特征,构建类别原型 encoder = contrastive_model.encoder # 只取特征提取部分 train_feats, train_labels, train_paths = extract_features(encoder, fewshot_loader) prototypes, proto_counts = build_class_prototypes(train_feats, train_labels, NUM_CLASSES) print("[Info] 各类别在小样本集中的样本数:", proto_counts) # 5. 提取验证集特征,并使用最近原型分类进行评估 val_feats, val_labels, val_paths = extract_features(encoder, val_loader) val_preds, val_acc = prototype_classification(prototypes, val_feats, val_labels) print(f"[Result] 原型度量分类在验证集上的整体准确率: {val_acc:.4f}") # 6. 绘制并保存混淆矩阵 cm_save_path = os.path.join("result1", "fewshot_prototype_confusion_matrix.png") plot_confusion(val_labels, val_preds, NUM_CLASSES, cm_save_path) # 7. t-SNE 可视化验证集特征的分布(部分类别) tsne_save_path = os.path.join("result1", "fewshot_prototype_tsne.png") plot_tsne_embedding(val_feats, val_labels, tsne_save_path, num_classes=NUM_CLASSES, sample_per_class=20) print("[Info] 问题2相关的所有结果图像已保存在 result1 文件夹中。")





C题:



精力有限
用matlab简答做了个数值模拟(我已经找好第一问需要的数据,后面会用真实数据替代):

第一问的部分数据来自以下网站(该网站提供了洋流速度、海水温度和盐度):
通过网盘分享的文件:资料分享
链接: https://pan.baidu.com/s/1OICSbGnbLkvuVzQ_flsM5w?pwd=u5eg 提取码: u5eg