构建企业级机器学习平台:基于Ray和DeepSpeed的半导体AI实践
1.机器学习平台简介
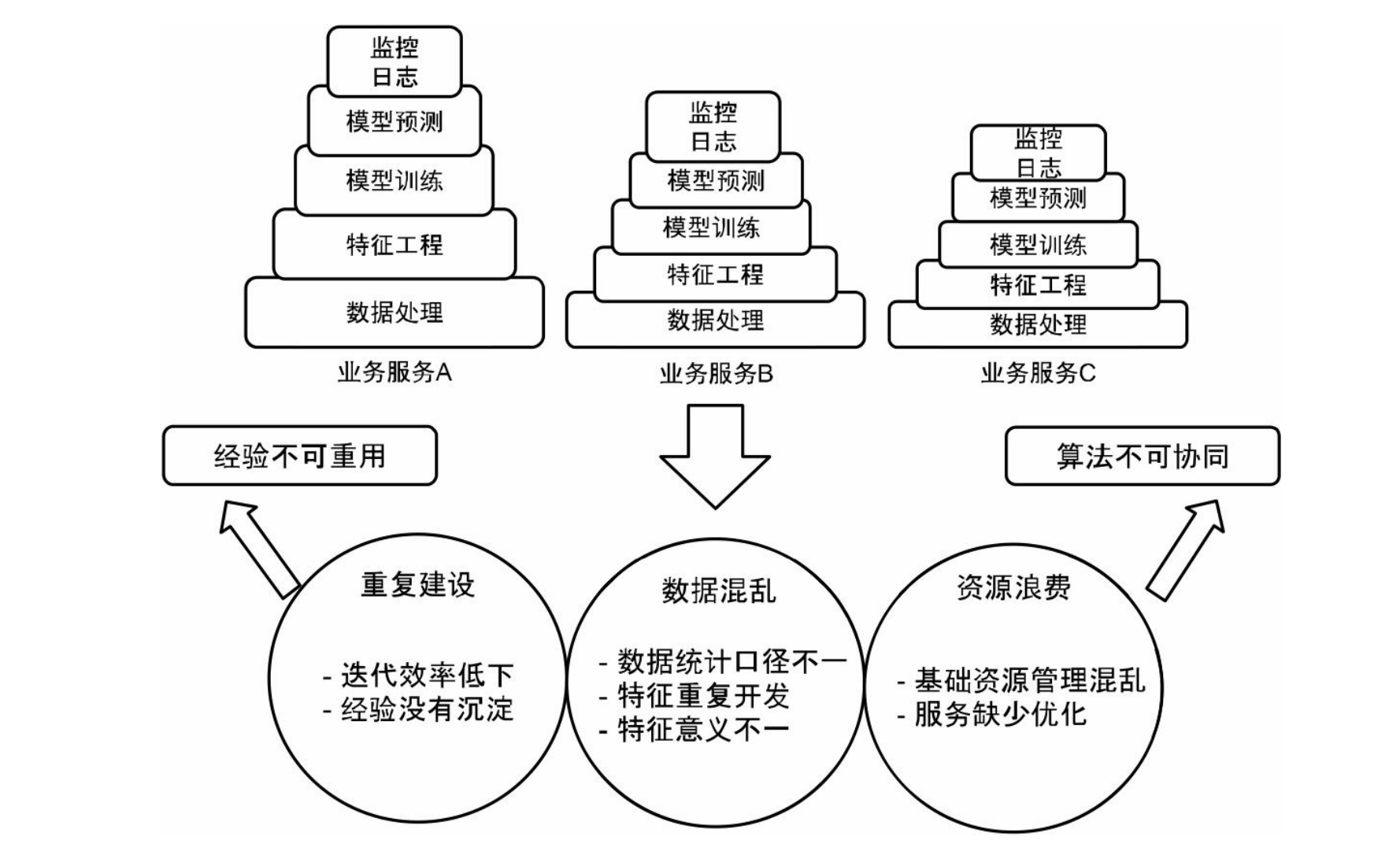
1.1单业务线开发阶段
1.2 平台化建设阶段
- 可复用:平台需要对数据处理、特征工程、特征重要性分析、常见算法模型和一致
- 性校验等核心功能进行组件化封装。
- 标准化:平台需要提供统一的代码规范、协作机制、模型管理、上线流程、监控报
- 警规则和在线实验流程。
- 角色化:平台需要高效地支持不同角色和不同团队的工作方式与功能诉求。
- 自动化:平台需要支持周期性运行、自动化迭代、例行回归测试等常见功能。
- 智能化:平台需要提供自动调参等辅助工具。
- 抽象化:平台需要在屏蔽底层物理细节的基础上来进行统一的资源管理和调度。
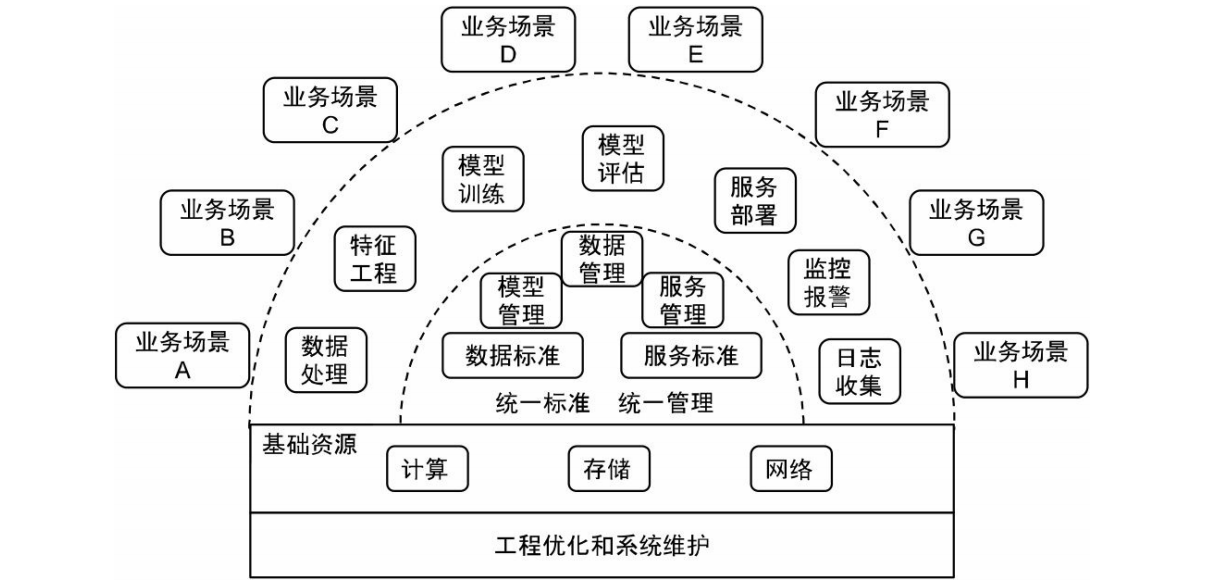
1.3 业界案例
- Google TFX:TFX将机器学习的基本工作流抽象为数据管理、模型训练、模型验证 和部署上线。它的核心组件包括 Data Analysis、Data Transformation、Data Validation、 Trainer、Model Evaluation and Validation、Model Serving、Job Management、Pipeline Monitoring、Logging、Storage、Visualization、A/B Testing。TFX对数据管理和数据验证 非常重视,它认为数据问题和软件问题一样都会严重影响模型效果。
- Facebook FBLearner:FBLearner 具有与 TFX 十分接近的功能和构成,它也非常重 视对数据和特征的管理。特别地,它利用 Feature Store 实现了特征的存储、管理和共享。 同时,FBLearner 也提供了完整的工作流程调度和模型部署方案。
- 阿里巴巴 PAI 平台:PAI 平台提供了一套从数据上传、数据预处理、特征工程、模 型训练、模型评估到模型发布的一站式服务。它还提供了多种建模方式来满足不同的业务 需求,以便降低机器学习建模任务的技术门槛。其中,PAI-Studio 提供了可视化建模的操 作界面,用户通过组件拖曳即可形成建模任务的流程图;PAI-DSW 提供了基于 Notebook 的交互式研发环境;PAI-AutoLearning 和 PAI-EAS 则分别提供了自动化建模和模型在线 部署等功能。
- 第四范式先知平台:先知平台是一个商业化的一站式机器学习平台。它除了提供基 于组件拖曳的用户操作界面,还提供了诸如数据接入、数据管理、模型管理、模型部署和 AB实验等周边服务。为了进一步提高模型迭代效率,它提供了自动调参和自动特征工程 等辅助功能。
2.项目背景与目标
2.1 项目背景
半导体生产涉及海量数据,包括设备传感器时序日志、工艺参数记录以及MES/SPC缺陷数据。随着产线规模扩大,传统方法难以处理Billion级参数模型,面临数据处理瓶颈、模型精度不足和资源利用低效等问题。我们旨在构建一个统一的平台,打通从数据导入到模型上线的全流程,实现弹性调度和能力复用。
2.2 核心目标
- 实现平台化设计,支持PB级数据处理和50节点分布式训练,GPU利用率达90%以上,自动化率98%。
- 缩短训练周期从数周至数天,提升模型精度25%,降低算力成本30%。
- 扩展到预测维护和工艺优化等场景,支持多框架兼容。
3.总体架构设计
整体架构基于“六大中心”拆分,底层统一运行在Kubernetes集群之上,强调算法与数据能力的有机整合。通过统一规划和建设,将传统数据处理升华为智能体系,支持从大数据的线下(offline)处理过渡到近线(near-line)半实时模型更新,再到在线(online)实时服务,形成全景式解决方案。
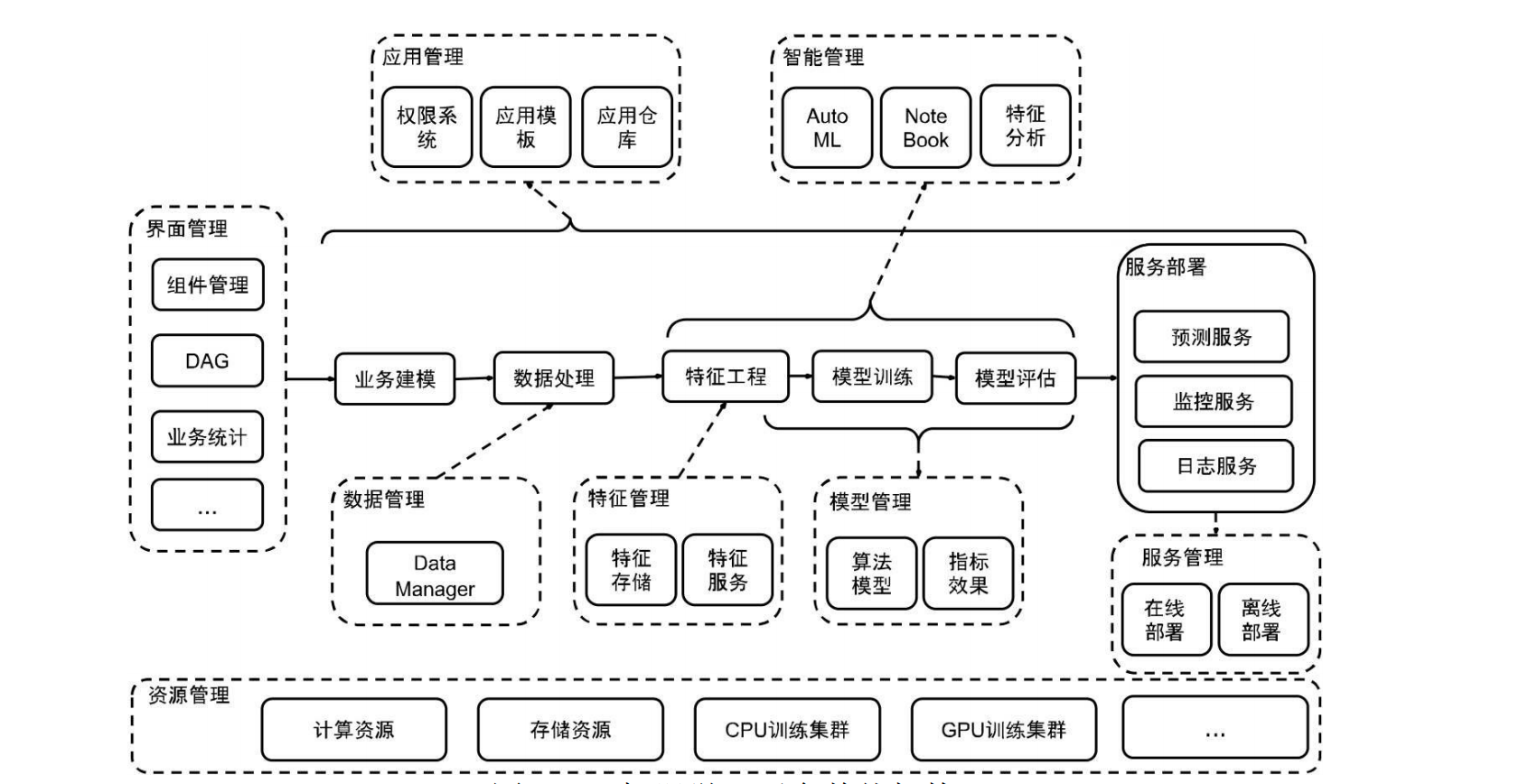
3.1 分层架构
- 基础设施层:Kubernetes集群 + GPU节点 + 分布式存储(对象存储或HDFS/Lakehouse)。这一层提供可靠、可扩展的计算基础,确保大规模数据的处理、建模和预测,支持弹性资源调度和异构设备兼容。
- 计算引擎层:
- Ray集群(Ray Head + Ray Workers,部署在K8s上),作为分布式执行引擎,支持数百节点弹性扩展和动态资源分配。
- DeepSpeed(集成在训练脚本中,负责大模型训练优化),利用ZeRO优化减少GPU内存占用50%,加速训练速度2-3倍。
- Spark / Flink(用于批量数据处理与特征工程,可与Ray配合),处理TB/PB级数据,支持批处理和流式任务。
- 平台能力层(六大中心):
- 数据中心:特征管理/样本管理、数据版本与血缘,确保离线/在线一致性。
- 调度中心:工作流引擎(Ray Workflows / Argo / Airflow),编排端到端ML管道。
- 模型中心:模型组、模型实例、版本与上线管理,支持全生命周期治理。
- 智能中心:超参搜索、自动调参、实验管理,提升建模效率。
- 管理中心:项目、资源配额、权限与审计,支撑多团队协作。
- 用户界面中心:统一Web控制台,面向多角色用户,提供可视化操作。
3.2 架构风格
- 数据平台负责“数据中台能力”(采集、存储、基础清洗),聚焦海量数据的飞速积累和共享复用。
- 机器学习平台负责“算法中台能力”(特征、训练、模型、实验),通过算法挖掘数据内在规律,充分发挥数据潜在价值。 两者通过标准化接口与存储层对接,实现数据智能的深度融合,形成可靠、可延展、易用的中台体系,为前台业务智能化改造赋能。
4.六大中心设计与实现
4.1 数据中心
目标:统一管理半导体良率相关的数据、特征和样本,保证离线/在线特征一致性,为训练和推理提供标准化数据输入。这一中心将大数据处理与机器学习紧密结合,支持从线下批处理到近线半实时更新的全景解析。
- 数据模型与规范化视图
- 统一设计“良率建模数据模型”,抽象出核心实体:晶圆 / 批次 / 工艺步骤 / 设备 / 传感器 / 缺陷标签 / 检测结果等,确保数据整合和技术沉淀。
- 在数据平台上构建规范化基础表和视图,例如:fact_yield_record(良率与缺陷记录)、dim_equipment(设备维度)、fact_sensor_timeseries(传感器时序数据)。
- 针对机器学习任务,构建标准训练视图:ml_semiconductor_yield_feature_base(按批次/晶圆分区),支持数据共享和通用能力复用。
- 特征工程与特征服务
- 批处理侧:使用Spark / Flink + Ray Datasets,对TB/PB级数据进行并行特征构造,包括时间窗口聚合特征(如过去1/8/24小时的统计)、工艺参数归一化、离散特征编码、设备健康与工艺稳定性指标。输出训练特征表(ml_yield_features_train)和预测特征表(ml_yield_features_infer),保证在线可拉取,支持半实时更新。
- 在线侧预留:设计Feature Service的接口规范(如REST/gRPC),按主键(批次/设备/工艺段)返回与离线一致的特征向量,实现实时服务响应。
- 数据与特征元数据管理
- feature_meta:记录特征名称、数据类型、业务含义、所属模型组、上线状态,支持版本管理和血缘追溯。
- dataset_meta:记录数据集版本、时间范围、过滤规则、样本量、正负样本比等,确保数据智能的普惠应用。
- 与模型中心联动,实现“模型–特征–数据集”的全链路追溯,提升决策效率。
4.2 调度中心
目标:通过统一工作流调度,将“数据准备→特征工程→训练→评估→上线”编排为标准化DAG,支持多引擎、多任务、多业务线。这一中心强调从理论到实践的兼顾,结合一线企业经验,确保系统的高可用性和容错。
- 工作流引擎选型
- 基于已有Kubernetes基础,采用组合方式:日志清洗/批处理使用Spark/Flink(已有数据平台生态);端到端ML Pipeline优先选用Ray Workflows(紧密集成Ray集群),或使用Argo/Airflow统一编排异构任务,支持跨语言和多系统协作。
- 标准化Pipeline设计
- 以“良率模型训练”为例,定义标准DAG:
- node1_data_check:数据质量检查(缺失值、极值、样本量),确保数据可靠。
- node2_feature_build:特征工程(Ray / Spark任务),处理海量数据积累。
- node3_train:分布式训练(Ray Train + DeepSpeed),支持Billion级参数。
- node4_eval:模型评估(多指标计算、按产线/工艺维度分解),提供效果分析。
- node5_register:模型注册到模型中心,实现能力共享。
- node6_deploy:触发上线流程或灰度发布,支持快速迭代。
- 每个节点包装为“组件”,统一暴露接口:submit() / checkStatus() / getInputs() / getOutputs() / cleanUp(),便于复用和扩展。
- 以“良率模型训练”为例,定义标准DAG:
- 资源与容错管理
- 由Ray与Kubernetes共同管理资源:Ray集群声明GPU/CPU资源分配策略,Kubernetes根据Pod资源请求自动调度到GPU节点,支持弹性扩展。
- 工作流引擎支持:失败重试策略、超时自动告警、节点级checkpoint(避免失败后全流程重跑),确保实用化和大规模应用。
4.3 模型中心
目标:沉淀所有模型资产,对模型进行全生命周期管理(训练、评估、上线、回滚),为业务提供稳定可控的模型服务。这一中心算法与工程并重,结合实践案例,确保理论与实践兼顾。
- 模型组与模型实例
- 引入MLflow / 自研Model Registry:模型组(Model Group)如yield_defect_detection;模型实例(Model Instance)包含代码版本 / 超参配置 / DeepSpeed配置、训练数据集版本(指向dataset_meta)、特征版本(指向feature_meta)、离线评估指标(AUC、F1、召回、TopK良率提升等)。
- 一致性验证
- 建立统一“验证环境”:使用与生产一致的Feature Service与推理服务(Ray Serve / Triton),选取一批固定的“回放样本”进行离–在线一致性对比。
- 模型中心记录:一致性误差分布、是否满足上线阈值(例如:误差率 < 0.5%),支持智能化改造。
- 上线与回滚策略
- 模型中心提供接口:promote(model_instance_id, traffic_ratio)(灰度发布至一定流量)、rollback(target_model_instance_id)(一键回滚到指定版本)。
- 与调度中心及在线服务联动:更新在线推理服务加载的模型版本、更新AB实验配置(新旧模型分流),实现快速试错和决策。
4.4 智能中心
目标:通过自动调参、实验管理等能力提升建模效率,降低人工试错成本。这一中心聚焦数据智能时代,提供有益启发和针对性经验。
- 自动调参(超参数搜索)
- 基于Ray Tune构建“自动调参组件”:搜索空间包括学习率、batch size、warmup steps、ZeRO stage、offload策略、正则化参数等;搜索算法Bayesian Optimization / ASHA等;目标验证集F1 / 良率预测误差 / 召回在指定区间的良率提升。
- 实验管理
- 在智能中心维护实验列表:关联到模型组 / 模型实例、展示不同超参组合下的指标对比、支持按工艺段、设备、产线维度对实验结果进行drill-down分析。
- 与模型中心联动
- 当自动调参找到最优模型时:将结果注册到模型中心、标记为“推荐版本”,供产品/业务侧评审与上线决策,支持能力提升。
4.5 管理中心
目标:统一管理项目、资源、权限、审计,支撑多团队、多业务线共享平台。这一中心确保中台的可靠性和易用性,支持组织效率提升。
- 项目与配额
- 按业务线/产线/产品线创建项目:每个项目绑定模型组、数据集命名空间;为项目配置GPU/CPU/存储配额及最大并发训练数。
- 权限与审计
- 角色划分:平台管理员 / 数据工程师 / 算法工程师 / 运维 / 业务分析师。
- 定义资源访问权限:数据表 / 特征视图 / 模型 / 实验等。
- 审计功能:记录谁在什么时间上线了什么模型、使用了什么数据,为质量问题与合规审查提供追溯依据。
4.6 用户操作界面中心
目标:提供统一Web控制台,降低使用门槛,支撑跨角色协作。这一中心文笔流畅、视野广阔,便于从业者和学生构建完整知识体系。
核心功能模块:
- Pipeline视图:可视化展示DAG拓扑,支持节点状态查看、重试、跳过、手动触发等操作。
- 训练任务视图:列表展示历史训练任务及状态,查看训练日志(整合Ray Dashboard链接)和关键指标。
- 模型视图:查看模型组与模型实例列表、离线指标、一致性验证结果、上线状态,支持一键灰度发布/回滚的入口。
- 数据与特征视图:展示数据集版本、样本量、标签分布、特征列表、覆盖率、缺失率等基础统计。
- 资源/监控视图:聚合展示GPU/CPU利用率、任务队列长度、失败率等。
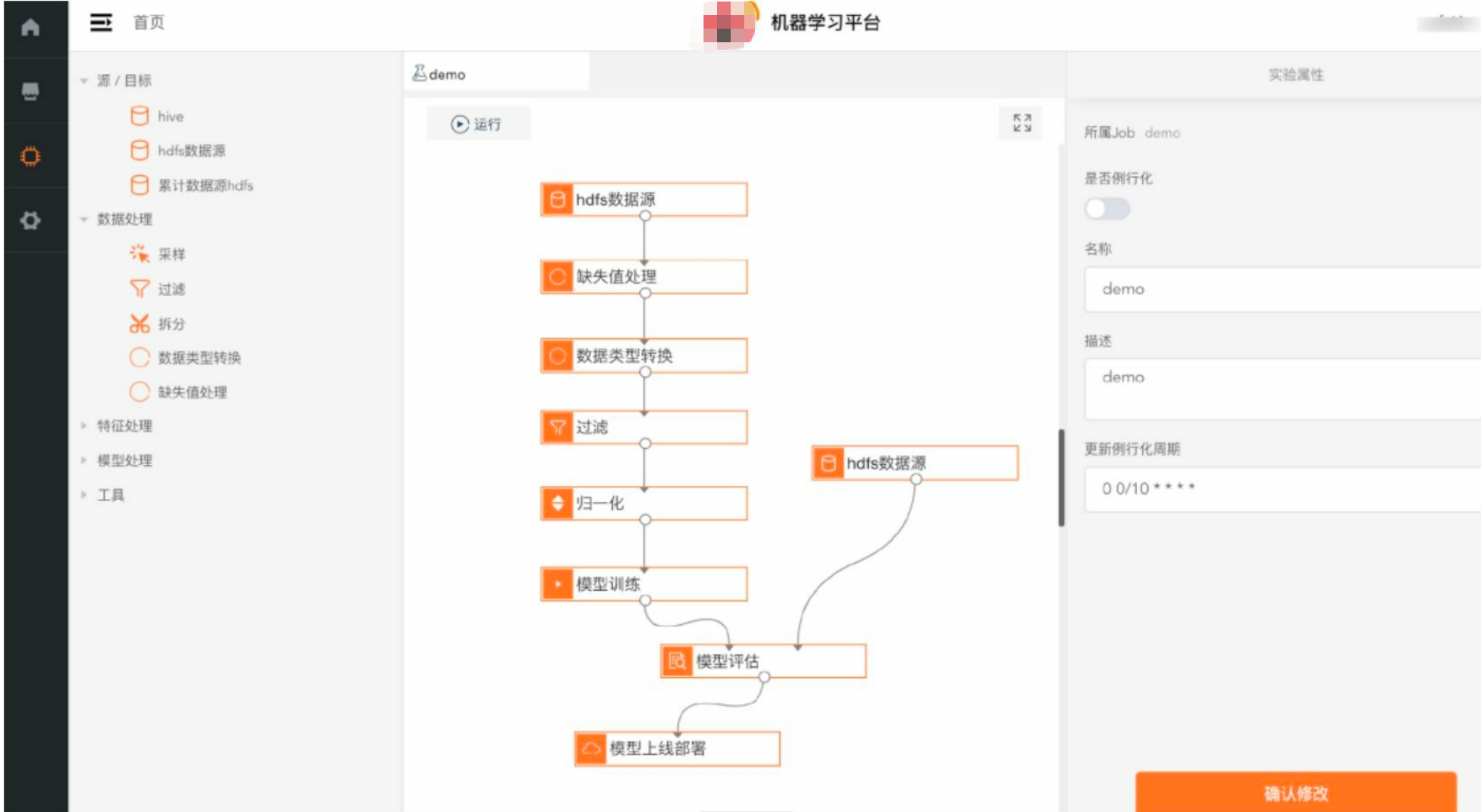
5. 核心技术实现(Ray + DeepSpeed)
5.1 Ray集群部署
- 在K8s上使用RayCluster CRD部署:1个Ray Head Pod(包含Dashboard)、~50个Ray Worker Pod(每Pod 1–4个GPU)。
- 通过NVIDIA Device Plugin管理GPU,Ray感知GPU资源情况并调度训练任务,支持大规模并行。
5.2 DeepSpeed分布式训练
- 模型采用PyTorch + DeepSpeed:启用ZeRO Stage-2/3,结合CPU Offload减少GPU显存占用50%+;启用混合精度训练(FP16/BF16)提高训练吞吐。
- 利用Ray Train / Ray Actors启动分布式训练进程:在50节点上并发训练,模型参数可达Billion级别。
- 训练周期从原本“数周”缩短到“数天”,GPU利用率稳定在90%+,体现算法与工程并重。
5.3 监控与告警
- 集成Prometheus + Grafana与Ray Dashboard:节点级别的CPU/GPU/内存指标、训练级别的loss/精度/学习率曲线。
- 告警策略:GPU使用率长时间过低 → 提示调优数据加载/并行策略;loss长时间不下降或发散 → 提醒调参或回滚到稳定版本,支持实时反馈。
6. 效果与收益
6.1 性能与成本
- 支持PB级半导体生产数据的特征处理与训练,训练自动化率约98%,资源有效利用率约92%。
- 训练周期从数周缩短至数天,训练算力成本下降约30%,实现数据智能的变革能力。
6.2 模型效果
- 良率预测场景下,核心模型精度提升约25%。
- 实现从“规则 + 小样本模型”向“大数据 + 大模型”的平滑迁移,支持业务智能化升级。
6.3 平台能力
- 将Ray + DeepSpeed能力沉淀为公司AI Infra核心能力。
- 多个业务线可复用数据中心 / 调度中心 / 模型中心能力,降低新增项目成本,提供高度借鉴性经验。