性能相关指标
一、简介
性能与可靠性已成为衡量系统质量的核心维度。无论是支撑高并发交易的电商平台,还是保障毫秒级响应的金融系统,都需要一套科学、全面的指标体系来量化其表现、识别瓶颈并验证稳定性。
本文系统梳理了性能测试与系统可靠性评估中的关键指标,涵盖吞吐能力(如 TPS、QPS)、用户行为(如 UV、PV)、响应效率(如响应时间、错误率)、并发模型、资源消耗,以及高可用性相关指标(如可用性、MTTR、MTBF)。通过理解这些指标的定义、关联与应用场景,团队可更精准地设计压测方案、制定 SLA 标准,并构建真正高性能、高可用、可运维的系统架构。
下面来简单介绍下这些指标:
二、指标
1. TPS(Transactions Per Second)
- 中文名:每秒事务数(*这里的事务不是数据库的事务,而是一件完整的事情,可以通过接口来看,一般一个接口就是这里的一个事务了)
- 定义:系统每秒成功完成的完整业务事务数量。
- 说明:
- “事务”指一个端到端的业务操作(如登录、下单、支付)。
- 一个事务可能包含多个请求(API 调用、数据库操作等)。
- 示例:电商系统每秒成功处理 300 笔订单 → TPS = 300。
2. QPS(Queries Per Second)
- 中文名:每秒查询数 / 每秒请求数
- 定义:系统每秒处理的请求数量(通常指 HTTP 请求或数据库查询)。
- 说明:
- 更偏向技术层面,衡量服务器处理能力。
- 与 TPS 的关系:QPS ≥ TPS × 平均每个事务的请求数。
- 示例:一个用户搜索商品触发 1 个请求,则 5000 用户/秒搜索 → QPS ≈ 5000。
3. 吞吐量(Throughput)
- 定义:单位时间内系统处理的数据量或请求数。
- 表现形式:
- 可以是 QPS 或 TPS(最常见)
- 也可以是 字节数/秒(如网络带宽场景:MB/s)
- 说明:
- 吞吐量是衡量系统整体处理能力的核心指标。
- 在 JMeter、LoadRunner 等工具中,“Throughput” 默认通常指 请求数/秒(即 QPS)。
- 示例:API 网关每秒处理 8000 个请求 → 吞吐量 = 8000 req/s。
4. 并发数(Concurrency / Concurrent Users)
- 中文名:并发用户数 / 并发请求数
- 定义:同一时刻向系统发起请求的用户或线程数量。
- 关键点:
- ≠ 在线用户数(Online Users),而是“正在操作”的用户。
- 可通过压力测试工具(如 JMeter 的线程组)模拟。
- 公式估算(简易模型):(响应时间单位为 ms)
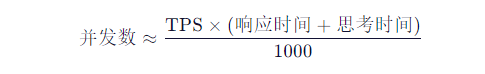
- 示例:系统 TPS=200,平均响应时间=200ms,用户操作间隔(思考时间)=800ms →
并发数 ≈ 200 × (200 + 800) / 1000 = 200 用户
5. UV(Unique Visitors)
- 中文名:独立访客数
- 定义:在指定时间段内访问系统的不重复用户数量(通常基于 IP 或用户 ID 去重)。
- 说明:
- 属于运营/流量统计指标,但在容量规划中用于估算潜在负载。
- 与 PV、并发数需结合用户行为模型换算。
- 示例:某 App 一天有 50 万独立用户打开 → UV = 500,000。
6. PV(Page Views)
- 中文名:页面浏览量
- 定义:用户访问页面的总次数(每次刷新都计为一次)。
- 与 UV 关系:PV ≥ UV;平均每个用户访问页数 = PV / UV。
- 示例:UV=10 万,PV=30 万 → 平均每人看 3 个页面。
7. 响应时间(Response Time)
- 定义:从客户端发出请求到收到完整响应所经历的时间。
- 常用统计值:
- 平均响应时间(Avg RT)
- P90/P95/P99 响应时间:表示 90%/95%/99% 的请求在此时间内完成。
- 示例:P95 = 400ms → 95% 的用户请求在 400ms 内返回。
8. 错误率(Error Rate)
- 定义:失败请求占总请求的比例。
- 计算公式:

- 性能测试目标:通常要求 < 0.1% ~ 1%,视业务重要性而定。
- 失败类型:HTTP 5xx、超时、连接拒绝等。
9. 资源利用率(Resource Utilization)
系统硬件或中间件资源的使用程度:
- CPU 使用率(建议峰值 < 75%)
- 内存使用量(避免频繁 GC 或 OOM)
- 磁盘 I/O(IOPS、吞吐)
- 网络带宽(Mbps)
辅助定位性能瓶颈(如 CPU 打满导致 TPS 下降)。
当 TPS/QPS 上升但响应时间急剧增加时,往往是因为某项资源达到瓶颈(如 CPU 100%)。
10. 可用性(Availability)
- 定义:系统在指定时间段内可正常提供服务的时间比例。
- 计算公式:

- 行业标准(SLA):
- 99%(“两个九”)→ 年宕机 ≈ 3.65 天
- 99.9%(“三个九”)→ 年宕机 ≈ 8.76 小时
- 99.99%(“四个九”)→ 年宕机 ≈ 52.6 分钟
- 示例:金融系统要求可用性 ≥ 99.99%。
11. 平均修复时间(MTTR, Mean Time To Repair)
- 定义:系统发生故障后,从故障发生到完全恢复所需的平均时间。
- 组成:包括故障检测、定位、修复、验证时间。
- 目标:越短越好,高可用系统通常要求 MTTR < 30 分钟。
- 优化方向:自动化告警、自愈机制、应急预案。
12. 平均无故障时间(MTBF, Mean Time Between Failures)
- 定义:系统两次故障之间的平均正常运行时间。
- 意义:衡量系统稳定性和可靠性。MTBF 越长,系统越可靠。
- 与可用性关系:
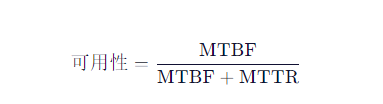
- 示例:若 MTBF = 1000 小时,MTTR = 1 小时 → 可用性 ≈ 99.9%。
13、 2-3-5响应时间标准
业界广泛采用 “2-3-5 响应时间标准” 作为参考基准:
- ≤ 2 秒:用户感觉流畅,体验优秀;
- 2~5 秒:用户可接受,但感知明显延迟;
- > 5 秒:用户易流失,满意度显著下降。
三、综合应用场景示例
某银行手机 App 核心转账接口:
- SLA 要求:可用性 ≥ 99.99%
- 压测结果:
- TPS = 1200
- QPS = 2400(每笔转账调用 2 个 API)
- 平均响应时间 = 120ms,P99 = 380ms
- 错误率 = 0.02%
- 并发用户数 = 300
- 运维指标:
- 过去一年 MTBF = 2000 小时
- 平均 MTTR = 18 分钟
- 实际可用性 = 99.992%
四、总结:
在现代软件系统中,性能测试已不仅是“压测工具跑个数”,而是贯穿开发、测试、运维全生命周期的质量保障体系。我们需要从多个维度综合评估系统表现:
- 业务视角:关注 TPS、响应时间、错误率,确保用户体验;
- 技术视角:关注 QPS、吞吐量、并发数,验证系统承载能力;
- 运营视角:关注 UV、PV,支撑容量规划与成本控制;
- 运维视角:关注可用性、MTTR、MTBF,保障系统长期稳定可靠;
- 资源视角:监控 CPU、内存等,快速定位瓶颈。
只有将这些指标有机结合,并设定合理的基线与告警策略,才能构建真正高性能、高可用、高可靠的系统。
| 指标 | 全称 / 中文名 | 定义 | 单位 | 典型用途 |
|---|---|---|---|---|
| TPS | Transactions Per Second 每秒事务数 | 每秒完成的完整业务事务数 | 事务/秒 | 业务处理能力评估 |
| QPS | Queries Per Second 每秒请求数 | 每秒处理的单次请求数量 | 请求/秒 | 技术吞吐能力衡量 |
| 吞吐量 | Throughput | 单位时间处理的工作量 | req/s、事务/s、MB/s | 系统整体容量评估 |
| 并发数 | Concurrency 并发用户数 | 同一时刻活跃操作用户数 | 用户数 / 线程数 | 压力测试负载建模 |
| UV | Unique Visitors 独立访客数 | 去重后的访问用户总数 | 人数 | 用户规模与容量规划 |
| PV | Page Views 页面浏览量 | 页面被访问总次数 | 次 | 流量与请求量估算 |
| 响应时间 | Response Time | 请求到响应的耗时 | 毫秒(ms) | 用户体验衡量 |
| 错误率 | Error Rate | 失败请求占比 | 百分比(%) | 系统稳定性评估 |
| 可用性 | Availability | 系统可服务时间占比 | 百分比(%) | SLA 达标与可靠性 |
| MTTR | Mean Time To Repair 平均修复时间 | 故障后恢复所需平均时间 | 分钟 / 小时 | 运维响应效率 |
| MTBF | Mean Time Between Failures 平均无故障时间 | 两次故障间的平均运行时间 | 小时 | 系统长期稳定性 |
| 资源利用率 | Resource Utilization | CPU/内存/磁盘/网络使用情况 | %、MB、IOPS 等 | 性能瓶颈分析 |
在实际项目中,应根据业务类型(如金融、电商、IoT、SaaS)选择关键指标组合,建立监控看板,并结合自动化测试与告警机制,实现“可观测、可度量、可优化”的系统质量闭环。