Flink原理与实战(java版)#第2章 Flink的入门(第一节大数据架构的演变)
电子书 Flink原理与实战(java版)专栏文章入口:电子书 Flink原理与实战(java版)- 目录结构
文章目录
- 第2章 Flink的入门
- 2.1 大数据架构的演变
- 2.1.1 传统数据架构
- 2.1.2 离线/实时大数据技术架构
- 2.1.3 Lambda架构
- 2.1.4 Kappa架构
- 2.1.5 Unifield架构
第2章 Flink的入门
2.1 大数据架构的演变
2.1.1 传统数据架构
企业将各种应用程序用于日常业务活动,例如企业资源计划(ERP)系统、客户关系管理(CRM)软件和Web应用程序等。大量的数据被存储在各种事务数据库系统中,为了实现业务系统数据的隔离,通常会创建不同的数据库。对于业务运营来说,只需要事务型数据就可以满足需求,但对于业务经营分析来说,往往需要将各种数据进行汇总,然后进行综合分析。
通常会使用ETL(提取-转换-加载)工具,将数据汇总到数据仓库中,在数据仓库上执行定期报告、查询和即席查询。这两种查询都是通过批处理方式在数据仓库中进行计算。如图2-1所示。
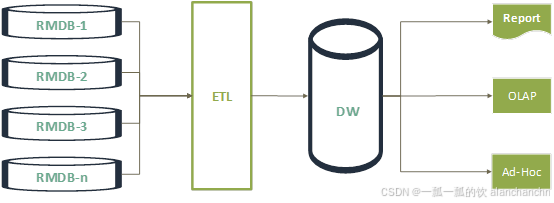
图2-1
2.1.2 离线/实时大数据技术架构
随着业务复杂性的增加以及数据量和数据类型的多样化,数据分析的需求已经超越了传统的结构化分析,传统的数据架构已经难以满足不断增长的业务需求。在这些场景中,结构化数据通常存储在关系型数据库中,而非结构化或半结构化数据(如日志文件、网页点击日志、应用埋点日志等)则被写入Hadoop的分布式文件系统(HDFS)、Amazon S3、阿里云OSS或其他批量数据存储系统(如Apache HBase)。存储在这些系统中的数据可以通过SQL-on-Hadoop引擎进行查询和处理,例如使用Apache Hive、Apache Drill或Apache Impala等工具。这些工具支持对大规模数据集进行类SQL查询,使得数据分析更加灵活和强大。
一个典型的离线大数据架构可能包括以下几个关键组件:
- 数据源:产生数据的系统或平台,如网站、应用程序、传感器等。
- 数据收集:用于收集和传输数据的系统,如Apache Flume、Kafka等。
- 数据存储:分布式文件系统(如HDFS)或对象存储(如S3、OSS)。
- 数据处理:用于批量处理数据的系统,如Apache Hadoop MapReduce、Apache Spark等。
- 数据查询和分析:SQL-on-Hadoop工具,如Apache Hive、Apache Impala等。
- 可视化和报告:用于展示分析结果的工具,如Tableau、PowerBI等。
一般的离线数据架构如图2-2所示。
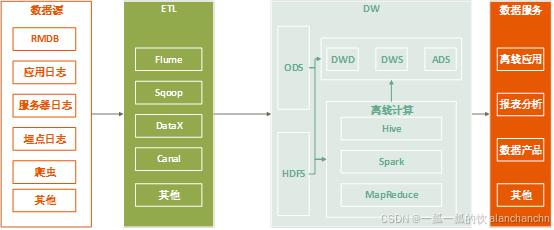
图2-2
在电子商务领域,传统的批处理或离线计算已经无法满足业务发展的需求。以Kafka为代表的消息队列工具和以Storm、Spark Streaming为代表的准实时/实时计算框架的出现,为流式计算提供了强大的支持。流式计算能够实时处理和分析数据,这意味着数据的计算和使用是同步进行的,能够为用户提供更加及时的信息。一般的流式计算数据架构如图2-3所示。
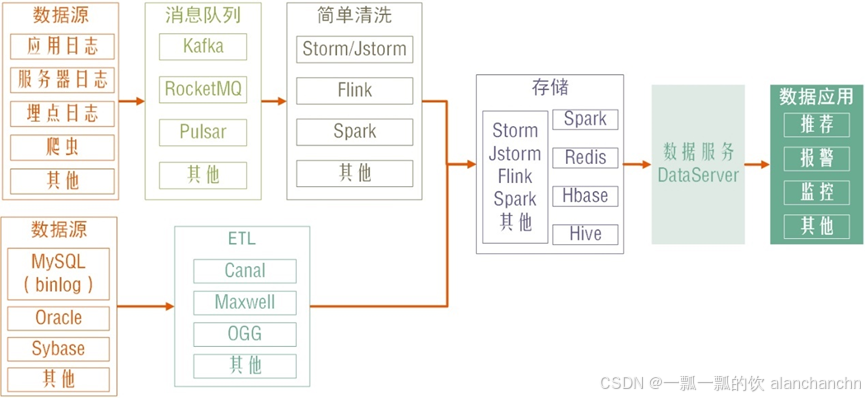
图2-3
2.1.3 Lambda架构
为了在计算实时指标时能够结合历史数据,出现了将离线计算与实时计算架构融合的需求,以便综合提供数据服务。典型的应用场景是这样的:实时数据源通过消息队列技术发送到实时数据处理平台,在那里通过实时计算框架进行处理。同时,离线数据源则通过工具传输到离线数据仓库,在那里通过批处理框架进行计算。接下来,将实时和离线计算的结果汇总合并,这通常发生在一个数据服务层,该层负责将处理后的数据提供给数据应用。这种结合实时和离线处理的架构通常被称为Lambda架构。其典型的数据架构如图2-4所示。
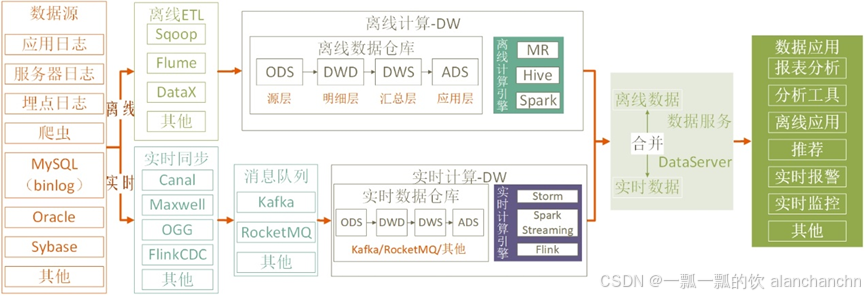
图2-4
2.1.4 Kappa架构
Lambda架构确实满足了实时计算的业务需求,但为了解决Lambda架构中维护两套系统的问题,LinkedIn的Jay Kreps提出了一种新的架构模式——Kappa架构。Kappa架构可以看作是Lambda架构的一种简化形式。在Kappa架构中,实时计算不仅可以即时完成计算任务,还可以像传统离线数据仓库一样进行数据分层,具体取决于所处理指标的复杂度。各层之间通过消息队列进行交互。Kappa 架构如图2-5所示。
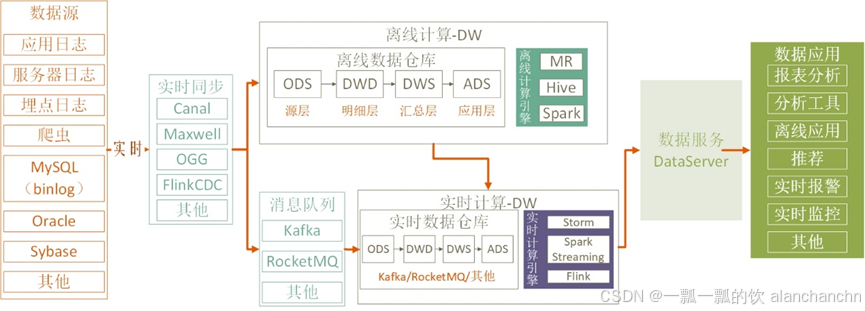
图2-5
2.1.5 Unifield架构
Unifield架构将机器学习与数据处理紧密结合起来。在Lambda架构的基础上进行了升级,Unifield在流处理层中新增了一个专门的机器学习层。在这种架构中,数据首先通过数据通道流入数据湖。接着,在流处理层不仅部署了机器学习模型以实现实时分析,还包含了对这些模型进行持续训练的能力。总的来说,Unifield架构通过将机器学习层集成到流处理层中,不仅能够提供实时的分析能力,还能够实现模型的持续迭代和优化。其典型的数据架构如图2-6所示。
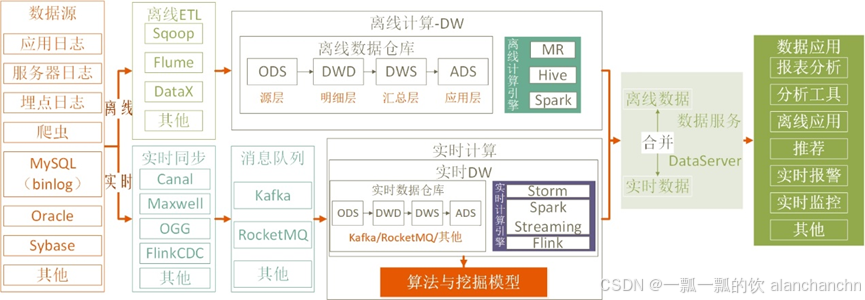
图2-6