容器云质量加固方案
一 背景
随着集团业务容器化比例越来越高,360容器云平台目前管理的公共和托管集群已超 50+, 独享集群 100+ 的规模,单集群节点数500+,预计后续随业务发展,会有更多的集群和节点增加至集群中。所以团队和技术方面的管理需要进行加固,以降低容器云的整体风险。
当前的问题和挑战
基础设施层
集群技术不统一
公司内部容器建设已经经历了较长时间的分支发展,在基础设施上缺乏技术统一性,各集群k8s版本不同、第三方依赖具有差异化、拓扑复杂、权限问题严重等,是公司内部的k8s集群质量侧的极大隐患。技术更迭速度快
云原生的组件技术发展速度和更迭频率是相对传统软件要高很多,新技术产品的稳定性无法得到保障;同时版本的升级工作量较大,不同集群中适配异常概率较高;同时频繁的版本升级容易触发运维变更风险。核心组件待优化
容器体量扩张对容器平台核心组件的承载能力提出了高要求对组件的优化已经刻不容缓,目前集团内部出现的故障,有部分是和组件的承载能力相关,需要进行优化。
集群重要组件耦合
部分监控、日志、原地升级等组件部署在集群中,当集群大范围不可用时,会出现部分系统组件不可用的情况,导致集群处于无法自恢复的状态,其他重要组件需要评估在集群不同状态下是否可以提供正常服务。
运维风险
变更/发布风险:
变更和发布目前大部分的工作还是由运维人员手动进行,其中各集群的配置不同、灰度的步进大小设置、作用域等都由运维人员人工确认,具有较大的出错风险。运行时风险:
随着集群运行时间累积,会有大量的不可控因素在集群内部叠加,如不进行及时的解除,会由量变到质变的转换,形成大的故障,日常的巡检、故障排查依赖于运维人员的专家经验,具有不确定性。
人员风险
当前平台的运行依赖大量的专家经验,专家经验并没有固化到平台,另外人员的互备机制在当前人力缺乏的情况下实施的并不完善,人员离职或请假对故障处理和排查造成极大的隐患。
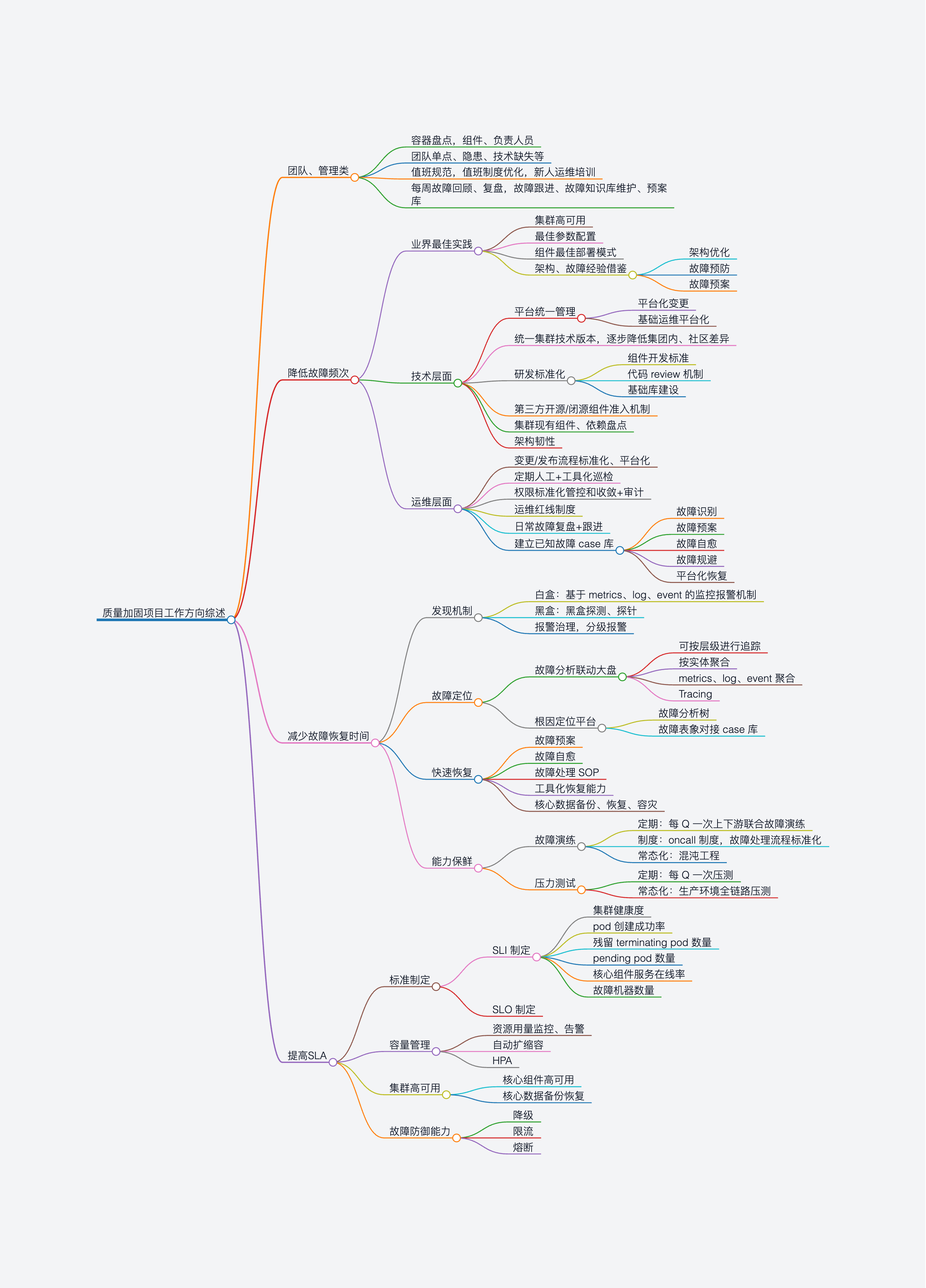
二 质量加固总体方案
质量提升方向
根据当前的质量加固目标,将从三个方向进行细致的优化提升。
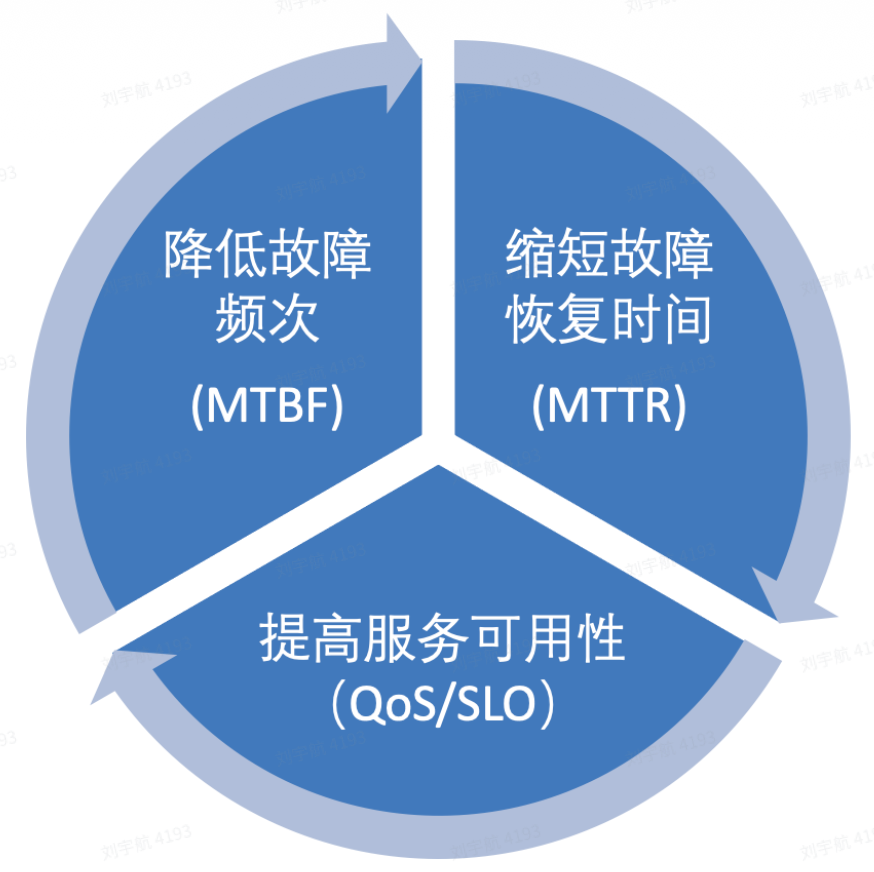
降低故障频次(MTBF)
降低故障次数和频度是对故障的预防方面需要做的努力,通过以下几个方面能够有效对可预测故障的发生进行抑制。
优秀最佳实践学习:通过学习业界优秀最佳实践,能够有效的优化集群参数和配置,提高系统容错性,并对常见故障进行防范。
技术层面:通过统一的平台化管理、降低多集群技术差异、研发标准化、组件准入机制实现技术层面的故障预防,并通过对现有组件的技术和依赖盘点,实现技术上的全面掌控。
运维层面:通过变更/发布标准化平台、定期巡检、权限收敛、红线制度能够有效避免因变更发布造成的集群稳定性问题;每周进行的MIKS航海日志,能够有效的暴露集群出现的问题,并积极跟进解决,防患于未然。
建立故障case知识库:将平台的知识进行沉淀,对故障识别、故障预案、故障自愈提供有效的知识基础,通过将case涉及的问题固化到MIKS平台中,实现专家知识的平台化、工具化。
缩短故障恢复时间(MTTR)
集群运行中,不可避免的会出现意料之外,或case没有覆盖到的故障,这种故障应该是在日常处理中最常见的,所以有效的降低故障时间,尽快恢复集群可用性,是提升容器质量的重中之重。
故障发现:通过白盒的方式对Metrics、log、event的监控进行监测,并根据报警规则进行P0-P2的分级报警;通过黑盒(kubeprobe)的方式进行集群的功能可用性进行探测,并对集群的健康度进行评分。
故障定位:在故障发现后,故障定位需要对异常进行系统性的分析,通过故障分析联动大盘进行故障的追踪和影响面确认。未来可以通过根因定位平台,智能的引导运维人员进行初步的故障分析,缩短故障定位时间。
故障恢复:出现故障并定位后,需要对系统进行快速的恢复,已有的故障预案是加速恢复的重要助力。后续会将故障的预案进行工具化、平台化,将专家能力固化到平台,避免人为操作失误造成故障二次伤害。同时对核心数据进行备份和容灾,并按Q进行故障演练的方式验证备份容灾可靠性。
能力保鲜:随着平台的版本升级和演进,已有的故障预案、工具可能会有不兼容的情况,通过定期故障演练和常态化演练,能够有效的对工具进行测试,并保持故障恢复方案、工具的有效性。
提高服务可用性(QoS/SLO)
通过减少服务不可用时间,在集群高可用、容量管理、故障的防御能力方面进行建设。
SLI标准制定:通过对集群核心指标的设置和考核,确定集群的可用性发展方向
集群高可用:通过集群的高可用配置,在出现局部故障时,能够保障服务高效可用
容量管理:随容器在集团内的高速发展,通过可度量的容量预警和自动化管理能力,保证业务在使用资源时不受集群容量束缚,最快速度交付业务可用资源
故障防御能力:通过降级、熔断、限流能力,在集群发生高并发访问时,能够保障业务请求能够高优先级访问,限制非正常流量,保障业务在集群上的持续可用。
三 具体落地
下面介绍一下容器平台降低故障频次方向,落实到事的具体子项目示例
提升方向 | 分类 1 | 提升内容 | 落地子项目 |
|---|---|---|---|
降低故障频次 | 优秀最佳实践 | 最佳参数配置 |
|
组件最佳部署模式 |
| ||
架构、故障经验借鉴 |
| ||
技术层面 | 统一平台管理 |
| |
统一集群版本 |
| ||
研发标准化 |
| ||
运维层面 | 变更、发布流程化、标准化、平台化 |
| |
定期人工、工具化巡检 |
| ||
权限收敛、审计 |
| ||
运维制度 |
| ||
日常用户反馈复盘 |
|
四 结语
器云平台作为支撑业务创新和快速发展的关键基础设施,其稳定性和可靠性对于整个集团的业务连续性至关重要。面对日益增长的业务需求和不断变化的技术环境,对容器云平台的质量加固工作提出了更高的要求。
在本方案中,我们详细分析了当前平台面临的挑战,并提出了一系列针对性的质量提升措施。通过降低故障频次、缩短故障恢复时间、提高服务可用性等方向的努力,我们旨在构建一个更加健壮、高效和可靠的容器云平台。这些措施不仅能够提升平台的稳定性,还能增强我们对未知风险的应对能力,从而为集团的业务发展提供坚实的技术支撑。
通过团队的共同努力和持续的技术创新,能够实现容器云平台的高质量运行,为集团的长远发展贡献力量。同时,我们也将持续关注行业动态,不断吸收和应用最新的技术成果,以确保我们的平台始终保持行业领先水平。