【数据集分享】汽车价格预测数据集
该数据集由作者:Rehan Liaqat 更新于一个月前,是用于汽车价格预测的结构化数据集,
包含市场上单个汽车的消费者导向记录,每一行对应一辆车,涵盖Car ID(唯一标识)、品牌、型号、年份、发动机规格、燃油类型、变速箱类型、里程数、车况等特征及作为目标变量的市场价格;
数据集具有可直接应用、精简聚焦、用途多样、适合演示教学的优势,可用性评分为10.00,采用ODC Public Domain Dedication and Licence(PDDL)许可,无预期更新频率,标签为“Beginner”,
数据文件“car_price_prediction_.csv”大小为160.09 kB,可用于探索性数据分析、特征工程和监督学习等任务。
源地址:https://www.kaggle.com/datasets/rehan497/car-price-prediction-dataset
本数据集采用 ODC PDDL 公共领域许可,允许自由分享、使用及修改(许可详情见:https://opendatacommons.org/licenses/pddl/1-0/)
一、数据集
1.1 数据集基础信息
| 信息类别 | 具体内容 | 关键说明 |
|---|---|---|
| 数据集创建/更新者 | Rehan Liaqat | 明确数据集的归属主体 |
| 数据文件详情 | 文件名:car_price_prediction_.csv;文件大小:160.09 kB | 展示数据存储形式及规模,小体积便于快速处理 |
| 可用性评分 | 10.00 | 满分评分,表明数据集质量高、易用性强 |
| 许可类型 | ODC Public Domain Dedication and Licence(PDDL) | 属于公共领域许可,允许自由使用、分享和修改 |
| 预期更新频率 | Never | 数据集为静态数据,后续不会定期或不定期更新 |
| 标签 | Beginner | 适合初学者用于学习和实践相关数据分析、机器学习任务 |
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns# 设置中文字体
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 1. 加载数据
df = pd.read_csv('car_price_prediction.csv')# 2. 查看数据基本信息
print("数据集形状:", df.shape)
print("\n前5行数据:")
print(df.head())
print("\n数据类型信息:")
print(df.dtypes)# 3. 数据质量检查
print("\n缺失值统计:")
print(df.isnull().sum())
print("\n重复值统计:", df.duplicated().sum())# 4. 描述性统计
print("\n数值型变量统计描述:")
print(df.describe().round(2))# 5. 分类变量分析
print("\n分类变量类别分布:")
categorical_cols = ['Brand', 'Fuel Type', 'Transmission', 'Condition']
for col in categorical_cols:print(f"\n{col} 分布:")print(df[col].value_counts())print(f"唯一值数量:{df[col].nunique()}")
以下是整理后的表格形式数据分析结果:
1. 数据集基本信息
| 项目 | 详情 |
|---|---|
| 数据集形状 | (2500, 10) |
| 记录数 | 2500条 |
| 特征数 | 10个 |
| 缺失值 | 无 |
| 重复值 | 无 |
2. 数据类型分布
| 特征名称 | 数据类型 |
|---|---|
| Car ID | int64 |
| Brand | object |
| Year | int64 |
| Engine Size | float64 |
| Fuel Type | object |
| Transmission | object |
| Mileage | int64 |
| Condition | object |
| Price | float64 |
| Model | object |
3. 数值型变量统计描述
| 统计量 | Car ID | Year | Engine Size | Mileage | Price |
|---|---|---|---|---|---|
| count | 2500.00 | 2500.00 | 2500.00 | 2500.00 | 2500.00 |
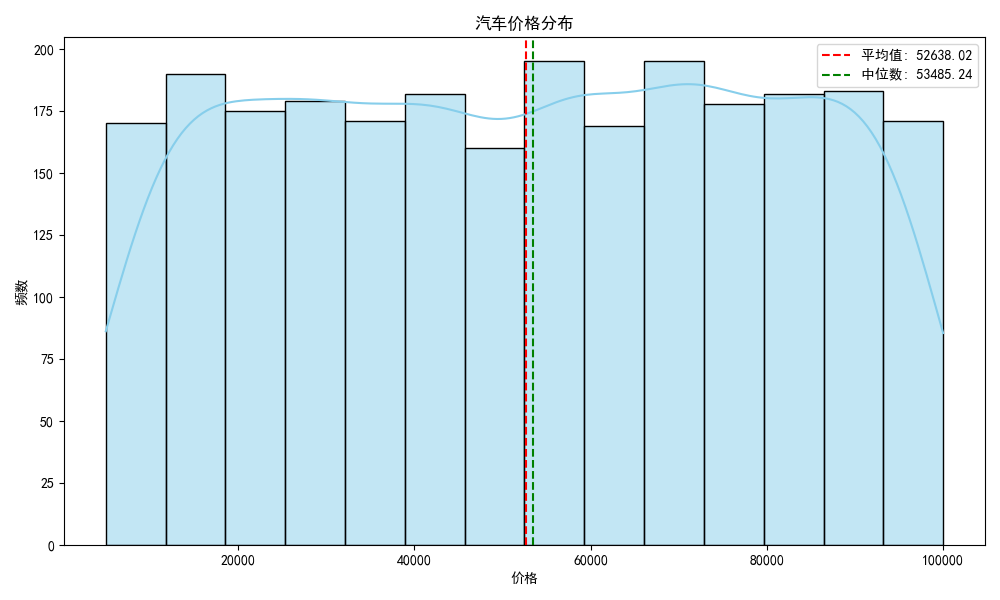
| mean | 1250.50 | 2011.63 | 3.47 | 149749.84 | 52638.02 |
| std | 721.83 | 6.99 | 1.43 | 87919.95 | 27295.83 |
| min | 1.00 | 2000.00 | 1.00 | 15.00 | 5011.27 |
| 25% | 625.75 | 2005.00 | 2.20 | 71831.50 | 28908.48 |
| 50% | 1250.50 | 2012.00 | 3.40 | 149085.00 | 53485.24 |
| 75% | 1875.25 | 2018.00 | 4.70 | 225990.50 | 75838.53 |
| max | 2500.00 | 2023.00 | 6.00 | 299967.00 | 99982.59 |
count(计数):该变量的有效记录数量,反映数据的完整性。
mean(均值):所有数值的算术平均值,体现数据的集中趋势。
std(标准差):衡量数值的离散程度,标准差越大,数据波动越明显。
min(最小值):变量的最小取值。
25%(第一四分位数):将数据从小到大排序后,位于 25% 位置的数值。
50%(中位数):将数据从小到大排序后,位于中间位置的数值,反映数据的中间水平。
75%(第三四分位数):将数据从小到大排序后,位于 75% 位置的数值。
max(最大值):变量的最大取值。
# 6. 价格分布分析
plt.figure(figsize=(10, 6))
sns.histplot(df['Price'], kde=True, color='skyblue')
plt.axvline(df['Price'].mean(), color='red', linestyle='--', label=f'平均值: {df["Price"].mean():.2f}')
plt.axvline(df['Price'].median(), color='green', linestyle='--', label=f'中位数: {df["Price"].median():.2f}')
plt.title('汽车价格分布')
plt.xlabel('价格')
plt.ylabel('频数')
plt.legend()
plt.tight_layout()
plt.show()
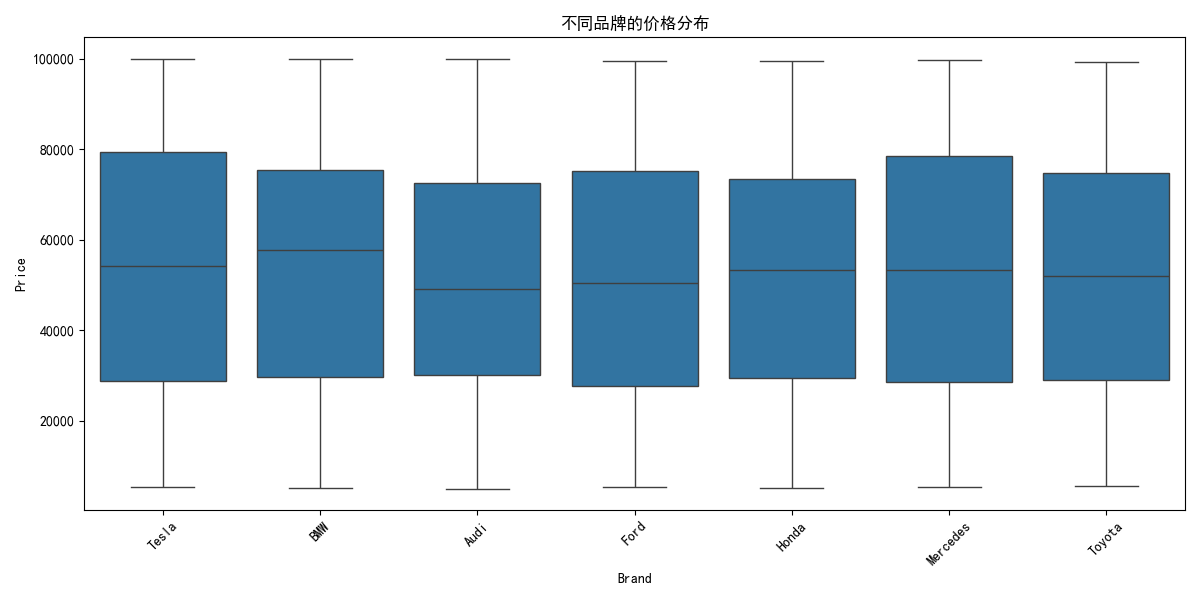
# 7. 品牌与价格关系
plt.figure(figsize=(12, 6))
sns.boxplot(x='Brand', y='Price', data=df)
plt.title('不同品牌的价格分布')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
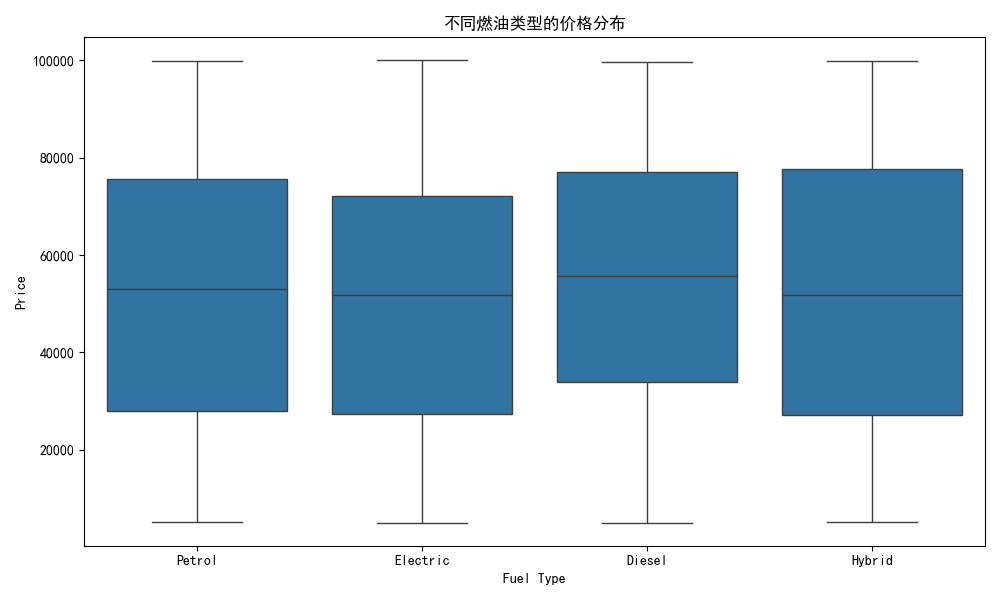
# 8. 燃油类型与价格关系
plt.figure(figsize=(10, 6))
sns.boxplot(x='Fuel Type', y='Price', data=df)
plt.title('不同燃油类型的价格分布')
plt.tight_layout()
plt.show()
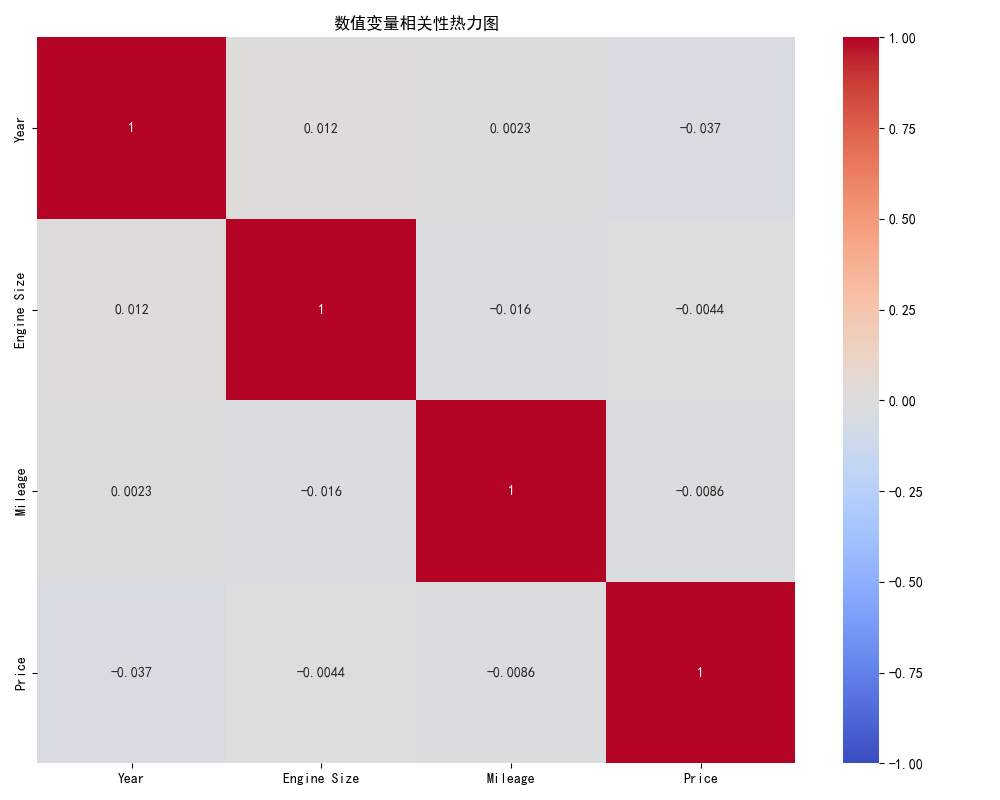
# 9. 相关性分析
plt.figure(figsize=(10, 8))
numeric_cols = ['Year', 'Engine Size', 'Mileage', 'Price']
corr_matrix = df[numeric_cols].corr()
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('数值变量相关性热力图')
plt.tight_layout()
plt.show()
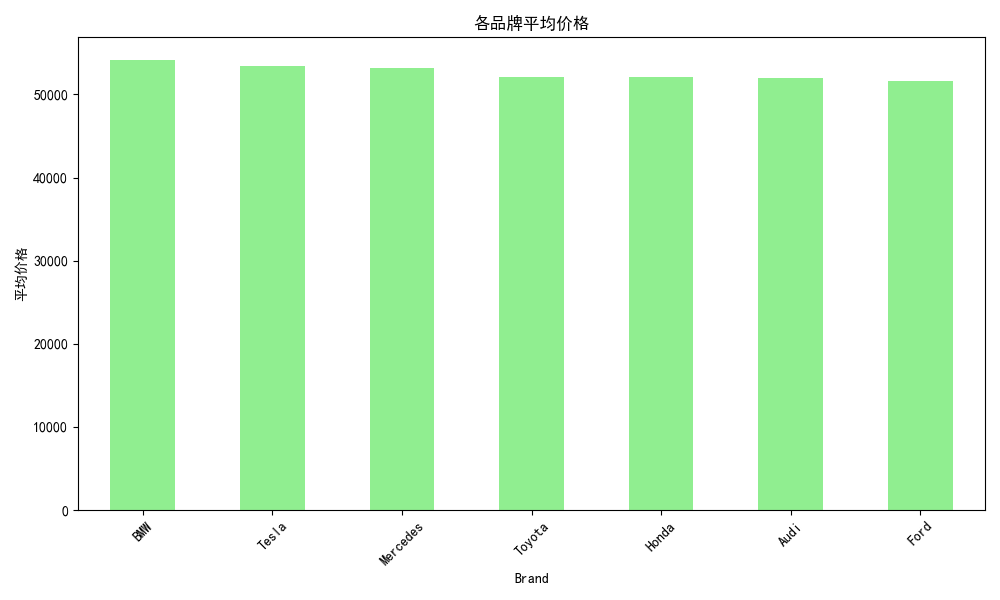
# 10. 各品牌平均价格
brand_mean_price = df.groupby('Brand')['Price'].mean().sort_values(ascending=False)
plt.figure(figsize=(10, 6))
brand_mean_price.plot(kind='bar', color='lightgreen')
plt.title('各品牌平均价格')
plt.ylabel('平均价格')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()