Oracle RAC 再遇 MTU 坑:cssd 无法启动!
前言
最近部署了一套 Oracle 19C RAC 环境,安装完成后关机打包发往异地机房。上架后发现其中一个节点无法正常启动,集群卡在 cssd 资源启动阶段。心跳网络采用光纤连接,通过交换机的独立 VLAN,节点间可以正常 ping 通,但是 RAC 只能单节点运行。经过深入分析,最终定位到是 MTU 配置问题导致的故障。
本文记录详细的问题分析过程和解决方案。
问题现象
Oracle RAC 中一个节点启动失败,集群状态显示:
[root@orcl02:/root]# crsctl stat res -t -init
--------------------------------------------------------------------------------
Name Target State Server State details
--------------------------------------------------------------------------------
Cluster Resources
--------------------------------------------------------------------------------
ora.asm1 ONLINE OFFLINE STABLE
ora.cluster_interconnect.haip1 ONLINE OFFLINE STABLE
ora.crf1 ONLINE ONLINE orcl02 STABLE
ora.crsd1 ONLINE OFFLINE STABLE
ora.cssd1 ONLINE OFFLINE orcl02 STARTING
ora.cssdmonitor1 ONLINE ONLINE orcl02 STABLE
ora.ctssd1 ONLINE OFFLINE STABLE
ora.diskmon1 OFFLINE OFFLINE STABLE
ora.drivers.acfs1 ONLINE ONLINE orcl02 STABLE
ora.evmd1 ONLINE INTERMEDIATE orcl02 STABLE
ora.gipcd1 ONLINE ONLINE orcl02 STABLE
ora.gpnpd1 ONLINE ONLINE orcl02 STABLE
ora.mdnsd1 ONLINE ONLINE orcl02 STABLE
ora.storage1 ONLINE OFFLINE STABLE
集群在 cssd 资源启动阶段 HANG 住。
检查 CRS 日志 ($ORACLE_BASE/diag/crs/orcl02/crs/trace/alert.log):
2025-11-11 12:21:57.020 [GIPCD(127382)]CRS-7517: The Oracle Grid Interprocess Communication (GIPC) failed to identify the Fast Node Death Detection (FNDD).2025-11-11 12:23:07.241 [OCSSD(130761)]CRS-1621: The IPMI configuration data for this node stored in the Oracle registry is incomplete; details at (:CSSNK00002:) in /u01/app/grid/diag/crs/orcl02/crs/trace/ocssd.trc
2025-11-11 12:23:07.241 [OCSSD(130761)]CRS-1617: The information required to do node kill for node orcl02 is incomplete; details at (:CSSNM00004:) in /u01/app/grid/diag/crs/orcl02/crs/trace/ocssd.trc
2025-11-11 12:23:37.324 [OCSSD(130761)]CRS-7500: The Oracle Grid Infrastructure process 'ocssd' failed to establish Oracle Grid Interprocess Communication (GIPC) high availability connection with remote node 'orcl01'.2025-11-11 12:28:39.020 [OCSSD(130761)]CRS-7500: The Oracle Grid Infrastructure process 'ocssd' failed to establish Oracle Grid Interprocess Communication (GIPC) high availability connection with remote node 'orcl01'.2025-11-11 12:32:58.470 [OCSSD(130761)]CRS-1609: This node is unable to communicate with other nodes in the cluster and is going down to preserve cluster integrity; details at (:CSSNM00086:) in /u01/app/grid/diag/crs/orcl02/crs/trace/ocssd.trc.
2025-11-11 12:32:58.469 [CSSDAGENT(130651)]CRS-5818: Aborted command 'start' for resource 'ora.cssd'. Details at (:CRSAGF00113:) {0:5:4} in /u01/app/grid/diag/crs/orcl02/crs/trace/ohasd_cssdagent_root.trc.
2025-11-11 12:32:58.506 [OHASD(126708)]CRS-2757: Command 'Start' timed out waiting for response from the resource 'ora.cssd'. Details at (:CRSPE00221:) {0:5:4} in /u01/app/grid/diag/crs/orcl02/crs/trace/ohasd.trc.
2025-11-11 12:32:59.470 [OCSSD(130761)]CRS-1656: The CSS daemon is terminating due to a fatal error; Details at (:CSSSC00012:) in /u01/app/grid/diag/crs/orcl02/crs/trace/ocssd.trc
2025-11-11 12:32:59.470 [OCSSD(130761)]CRS-1603: CSSD on node orcl02 has been shut down.
2025-11-11 12:33:00.151 [OCSSD(130761)]CRS-1609: This node is unable to communicate with other nodes in the cluster and is going down to preserve cluster integrity; details at (:CSSNM00086:) in /u01/app/grid/diag/crs/orcl02/crs/trace/ocssd.trc.
2025-11-11T12:33:04.480316+08:00
Errors in file /u01/app/grid/diag/crs/orcl02/crs/trace/ocssd.trc (incident=17):
CRS-8503 [] [] [] [] [] [] [] [] [] [] [] []
Incident details in: /u01/app/grid/diag/crs/orcl02/crs/incident/incdir_17/ocssd_i17.trc2025-11-11 12:33:04.471 [OCSSD(130761)]CRS-8503: Oracle Clusterware process OCSSD with operating system process ID 130761 experienced fatal signal or exception code 6.
日志明确显示节点 orcl02 无法与节点 orcl01 建立 GIPC 高可用连接。
进一步分析 cssd 日志 ($ORACLE_BASE/diag/crs/orcl02/crs/trace/ocssd.trc):
2025-11-11 13:07:10.563 : CSSD:909854464: [ INFO] clssnmvDHBValidateNCopy: node 1, orcl01, has a disk HB, but no network HB, DHB has rcfg 658329638, wrtcnt, 36406, LATS 5334194, lastSeqNo 36403, uniqueness 1762834827, timestamp 1762837626/5323124
2025-11-11 13:07:10.564 : CSSD:897136384: [ INFO] clssscSelect: gipcwait returned with status gipcretTimeout (16)
日志表明心跳网络存在通信问题。
问题分析
初步排查
首先检查基础网络连通性:
[root@orcl02:/tmp/mcasttest]# ping orcl01-priv
PING orcl01-priv (1.1.1.1) 56(84) bytes of data.
64 bytes from orcl01-priv (1.1.1.1): icmp_seq=1 ttl=64 time=0.053 ms
64 bytes from orcl01-priv (1.1.1.1): icmp_seq=2 ttl=64 time=0.044 ms
64 bytes from orcl01-priv (1.1.1.1): icmp_seq=3 ttl=64 time=0.116 ms
心跳 IP 可以正常 ping 通,防火墙已关闭。
MOS 文档参考
查询 MOS 文档,发现类似案例:OCI DBCS : Failed to start CRS on first RAC node - (GIPC) failed to identify the Fast Node Death Detection (FNDD). (Doc ID 2969313.1)

该案例指出问题根源在于节点间 MTU 配置不一致:

MTU 配置检查
检查两个节点的 MTU 配置:
## 节点1
[root@orcl01:/home/grid]# ifconfig bond1|grep mtu
bond1: flags=5187<UP,BROADCAST,RUNNING,MASTER,MULTICAST> mtu 9000## 节点2
[root@orcl02:/home/grid]$ ifconfig bond1|grep mtu
bond1: flags=5187<UP,BROADCAST,RUNNING,MASTER,MULTICAST> mtu 9000
节点间的 MTU 配置一致,均为 9000。
CVU 检测
使用 Oracle Cluster Verification Utility (CVU) 验证一下 RAC 集群节点间的网络连通性:
[grid@orcl01:/home/grid]$ cluvfy comp nodecon -n all -verbosePerforming following verification checks ...Node Connectivity ...Hosts File ...Node Name Status ------------------------------------ ------------------------orcl01 passed orcl02 passed Hosts File ...PASSEDInterface information for node "orcl02"Name IP Address Subnet Gateway Def. Gateway HW Address MTU ------ --------------- --------------- --------------- --------------- ----------------- ------bond0 192.168.6.206 192.168.6.0 0.0.0.0 192.168.6.1 8C:84:74:75:EF:00 1500 bond1 1.1.1.2 1.1.1.0 0.0.0.0 192.168.6.1 8C:84:74:DA:B8:E0 9000 Interface information for node "orcl01"Name IP Address Subnet Gateway Def. Gateway HW Address MTU ------ --------------- --------------- --------------- --------------- ----------------- ------bond0 192.168.6.205 192.168.6.0 0.0.0.0 192.168.6.1 8C:84:74:75:F2:00 1500 bond0 192.168.6.207 192.168.6.0 0.0.0.0 192.168.6.1 8C:84:74:75:F2:00 1500 bond0 192.168.6.209 192.168.6.0 0.0.0.0 192.168.6.1 8C:84:74:75:F2:00 1500 bond0 192.168.6.208 192.168.6.0 0.0.0.0 192.168.6.1 8C:84:74:75:F2:00 1500 bond1 1.1.1.1 1.1.1.0 0.0.0.0 192.168.6.1 8C:84:74:DA:D3:10 9000 Check: MTU consistency on the private interfaces of subnet "1.1.1.0"Node Name IP Address Subnet MTU ---------------- ------------ ------------ ------------ ----------------orcl02 bond1 1.1.1.2 1.1.1.0 9000 orcl01 bond1 1.1.1.1 1.1.1.0 9000 Check: MTU consistency of the subnet "192.168.6.0".Node Name IP Address Subnet MTU ---------------- ------------ ------------ ------------ ----------------orcl02 bond0 192.168.6.206 192.168.6.0 1500 orcl01 bond0 192.168.6.205 192.168.6.0 1500 orcl01 bond0 192.168.6.207 192.168.6.0 1500 orcl01 bond0 192.168.6.209 192.168.6.0 1500 orcl01 bond0 192.168.6.208 192.168.6.0 1500 Source Destination Connected? ------------------------------ ------------------------------ ----------------orcl01[bond0:192.168.6.205] orcl02[bond0:192.168.6.206] yes orcl01[bond0:192.168.6.205] orcl01[bond0:192.168.6.207] yes orcl01[bond0:192.168.6.205] orcl01[bond0:192.168.6.209] yes orcl01[bond0:192.168.6.205] orcl01[bond0:192.168.6.208] yes orcl02[bond0:192.168.6.206] orcl01[bond0:192.168.6.207] yes orcl02[bond0:192.168.6.206] orcl01[bond0:192.168.6.209] yes orcl02[bond0:192.168.6.206] orcl01[bond0:192.168.6.208] yes orcl01[bond0:192.168.6.207] orcl01[bond0:192.168.6.209] yes orcl01[bond0:192.168.6.207] orcl01[bond0:192.168.6.208] yes orcl01[bond0:192.168.6.209] orcl01[bond0:192.168.6.208] yes Source Destination Connected? ------------------------------ ------------------------------ ----------------orcl01[bond1:1.1.1.1] orcl02[bond1:1.1.1.2] yes Check that maximum (MTU) size packet goes through subnet ...FAILED (PRVG-12885, PRVG-12884, PRVG-2043)subnet mask consistency for subnet "192.168.6.0" ...PASSEDsubnet mask consistency for subnet "1.1.1.0" ...PASSEDNode Connectivity ...FAILED (PRVG-12885, PRVG-12884, PRVG-2043)Multicast or broadcast check ...
Checking subnet "1.1.1.0" for multicast communication with multicast group "224.0.0.251"Multicast or broadcast check ...PASSEDVerification of node connectivity was unsuccessful on all the specified nodes. Failures were encountered during execution of CVU verification request "node connectivity".Node Connectivity ...FAILEDCheck that maximum (MTU) size packet goes through subnet ...FAILEDPRVG-12885 : ICMP packet of MTU size "9000" does not go through subnet"1.1.1.0".PRVG-12884 : Maximum (MTU) size packet check failed on subnets "1.1.1.0"orcl01: PRVG-2043 : Command "/bin/ping 1.1.1.2 -c 1 -w 3 -M do -s8972 " failed on node "orcl01" and produced the followingoutput:PING 1.1.1.2 (1.1.1.2) 8972(9000) bytes of data.--- 1.1.1.2 ping statistics ---3 packets transmitted, 0 received, 100% packet loss, time2074msCVU operation performed: node connectivity
Date: Nov 11, 2025 1:10:21 PM
CVU version: 19.28.0.0.0 (070125x8664)
Clusterware version: 19.0.0.0.0
CVU home: /u01/app/19.3.0/grid
Grid home: /u01/app/19.3.0/grid
User: grid
Operating system: Linux4.18.0-553.el8_10.x86_64
CVU 检测发现 MTU 为 9000 的数据包无法通过子网:
Node Connectivity ...FAILEDCheck that maximum (MTU) size packet goes through subnet ...FAILEDPRVG-12885 : ICMP packet of MTU size "9000" does not go through subnet"1.1.1.0".PRVG-12884 : Maximum (MTU) size packet check failed on subnets "1.1.1.0"orcl01: PRVG-2043 : Command "/bin/ping 1.1.1.2 -c 1 -w 3 -M do -s8972 " failed on node "orcl01" and produced the followingoutput:PING 1.1.1.2 (1.1.1.2) 8972(9000) bytes of data.--- 1.1.1.2 ping statistics ---3 packets transmitted, 0 received, 100% packet loss, time2074ms
MTU 测试验证
使用 /bin/ping 1.1.1.2 -c 1 -w 3 -M do -s 8972 进行 MTU 大小测试:
# 测试 9000 MTU - 失败
[grid@orcl01:/home/grid]$ ping 1.1.1.2 -c 3 -M do -s 8972
PING 1.1.1.2 (1.1.1.2) 8972(9000) bytes of data.
^C
--- 1.1.1.2 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 1021ms# 测试 1500 MTU - 成功
[grid@orcl01:/home/grid]$ ping 1.1.1.2 -c 3 -M do -s 1472
PING 1.1.1.2 (1.1.1.2) 1472(1500) bytes of data.
1480 bytes from 1.1.1.2: icmp_seq=1 ttl=64 time=0.177 ms
1480 bytes from 1.1.1.2: icmp_seq=2 ttl=64 time=0.127 ms
^C
--- 1.1.1.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1032ms
rtt min/avg/max/mdev = 0.127/0.152/0.177/0.025 ms
测试结果表明:MTU 1500 通信正常,但 MTU 9000 出现 100% 丢包。经与网络工程师确认,交换机未配置 Jumbo Frame 支持,破案了!
解决方案
交换机配置
要求网络工程师在交换机上启用 Jumbo Frame 支持,配置 MTU 大于 9000。交换机配置完成后,重新测试:
[grid@orcl01:/home/grid]$ /bin/ping 1.1.1.2 -c 1 -w 3 -M do -s 8972
PING 1.1.1.2 (1.1.1.2) 8972(9000) bytes of data.
8980 bytes from 1.1.1.2: icmp_seq=1 ttl=64 time=0.232 ms--- 1.1.1.2 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.232/0.232/0.232/0.000 ms
MTU 9000 通信测试成功。
重启集群服务
重启两个节点的集群服务:
crsctl stop crs -f
crsctl start crs
检查集群状态:
[root@orcl01:/soft]# crsctl stat res -t
--------------------------------------------------------------------------------
Name Target State Server State details
--------------------------------------------------------------------------------
Local Resources
--------------------------------------------------------------------------------
ora.LISTENER.lsnrONLINE ONLINE orcl01 STABLEONLINE ONLINE orcl02 STABLE
ora.chadONLINE ONLINE orcl01 STABLEONLINE ONLINE orcl02 STABLE
ora.net1.networkONLINE ONLINE orcl01 STABLEONLINE ONLINE orcl02 STABLE
ora.onsONLINE ONLINE orcl01 STABLEONLINE ONLINE orcl02 STABLE
ora.proxy_advmOFFLINE OFFLINE orcl01 STABLEOFFLINE OFFLINE orcl02 STABLE
--------------------------------------------------------------------------------
Cluster Resources
--------------------------------------------------------------------------------
ora.ARCH.dg(ora.asmgroup)1 ONLINE ONLINE orcl01 STABLE2 ONLINE ONLINE orcl02 STABLE
ora.ASMNET1LSNR_ASM.lsnr(ora.asmgroup)1 ONLINE ONLINE orcl01 STABLE2 ONLINE ONLINE orcl02 STABLE
ora.DATA.dg(ora.asmgroup)1 ONLINE ONLINE orcl01 STABLE2 ONLINE ONLINE orcl02 STABLE
ora.LISTENER_SCAN1.lsnr1 ONLINE ONLINE orcl02 STABLE
ora.OCR.dg(ora.asmgroup)1 ONLINE ONLINE orcl01 STABLE2 ONLINE ONLINE orcl02 STABLE
ora.asm(ora.asmgroup)1 ONLINE ONLINE orcl01 Started,STABLE2 ONLINE ONLINE orcl02 Started,STABLE
ora.asmnet1.asmnetwork(ora.asmgroup)1 ONLINE ONLINE orcl01 STABLE2 ONLINE ONLINE orcl02 STABLE
ora.cvu1 ONLINE ONLINE orcl02 STABLE
ora.orcl.db1 ONLINE ONLINE orcl01 Open,HOME=/u01/app/oracle/product/19.3.0/db,STABLE2 ONLINE ONLINE orcl02 Open,HOME=/u01/app/oracle/product/19.3.0/db,STABLE
ora.qosmserver1 ONLINE ONLINE orcl02 STABLE
ora.scan1.vip1 ONLINE ONLINE orcl02 STABLE
ora.orcl01.vip1 ONLINE ONLINE orcl01 STABLE
ora.orcl02.vip1 ONLINE ONLINE orcl02 STABLE
--------------------------------------------------------------------------------
集群所有资源正常启动,问题解决。
MTU 配置原理
心跳网卡的 MTU 默认是 1500,交换机的默认 MTU 是 1500,当在系统层面修改网卡配置 MTU 为 9000 之后,交换机没有配置,这时候就会无法进行通信,100% 丢包。
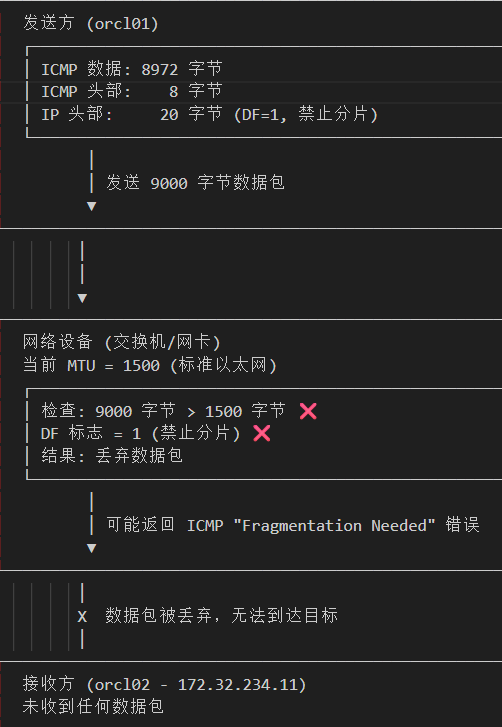
为什么 Oracle 建议配置心跳网卡 MTU 为 9000?
可以参考 MOS 文档:Recommendation for the Real Application Cluster Interconnect and Jumbo Frames (Doc ID 341788.1)
配置巨型帧的优势:
- 减少协议开销:降低 TCP、UDP 和以太网头部开销
- 提升吞吐量:避免数据包分片,提高传输效率
- 降低延迟:减少缓冲区传输次数,缩短 Oracle 块传输延迟
- CPU 优化:在 CPU 受限场景中显著提升性能

修改私网 MTU 配置可参考 MOS 文档:如何在 oracle 集群环境下修改私网信息 (Doc ID 2103317.1)。
写在最后
本次故障的根本原因是端到端的 MTU 配置不一致。虽然节点操作系统层面配置了 9000 字节的 MTU,但中间网络设备的 MTU 仍保持默认的 1500 字节,导致大数据包传输失败。