C++主流日志库深度剖析:从原理到选型的全维度指南
在C++开发的全生命周期中,日志系统是不可或缺的"基础设施"。它不仅是程序运行状态的"黑匣子",记录着函数调用链路、数据流转轨迹和异常堆栈信息,更是调试排障的"显微镜"、线上监控的"预警器"和问题溯源的"证据链"。无论是开发阶段定位偶现的内存泄漏,还是生产环境排查分布式系统的跨节点调用异常,一套优秀的日志系统都能让开发者事半功倍。
然而,C++生态中的日志库琳琅满目,从轻量到头重、从高性能到高定制,不同库的设计哲学和适用场景差异巨大。新手常陷入"选哪个都怕错"的困境,老手也可能在性能优化或定制化需求中栽跟头。本文将跳出"简单罗列功能"的浅层框架,从技术原理、核心特性、性能基准、实战适配等维度,对主流日志库进行深度拆解,并通过对比表格和选型流程图,帮你精准匹配项目需求。
一、日志库的核心技术指标:先明确评价标准
在深入分析具体库之前,我们需要建立一套统一的评价体系。一个成熟的日志系统,需在以下6个核心维度达到平衡:
性能表现:包括吞吐量(每秒可记录日志条数)、延迟(单条日志从生成到写入的耗时)和并发安全性(多线程场景下的性能衰减率),这是高并发服务的核心诉求。
功能完备性:涵盖日志分级(如DEBUG/INFO/WARN/ERROR/FATAL)、输出目标(控制台/文件/网络/数据库)、滚动策略(按大小/时间/日期滚动)、格式化能力(自定义字段、时间戳精度)等基础功能。
可靠性:关键指标为"崩溃安全性"——程序发生段错误、断言失败等致命错误时,能否确保已生成的日志不丢失;以及"写入可靠性"——面对磁盘满、网络中断等异常时的降级策略。
易用性:包括集成成本(是否需编译、依赖是否复杂)、API设计(是否直观、学习成本高低)、配置方式(代码硬编码/配置文件/动态调整)。
定制化能力:支持自定义日志属性(如线程ID、进程ID、模块名)、过滤规则(如按模块/级别/关键词过滤)、输出格式(如JSON/XML/自定义格式)的灵活度。
资源开销:包括内存占用(尤其是嵌入式场景)、编译时间(头文件数量、模板复杂度)、二进制体积(静态链接后的增量)。
后续对各日志库的分析,均围绕以上维度展开,确保评价的客观性和针对性。
二、主流日志库深度解析:原理、特性与坑点
C++生态的日志库可大致分为"轻量高性能型""工业级稳定型""高度定制型""极简嵌入式型"四大类。下面选取8个最具代表性的库,从技术内核到实战表现进行全方位拆解。
1. spdlog:高性能领域的"六边形战士"
spdlog是近年来C++社区最受欢迎的日志库之一,以"高性能+易集成+全功能"的组合拳脱颖而出,GitHub星标量超20k,被无数开源项目和商业产品采用。其核心设计理念是"用现代C++特性实现无锁并发,兼顾性能与易用性"。
核心技术原理
spdlog的高性能源于三大设计:
无锁队列+异步写入:采用单生产者-多消费者(SPMC)无锁队列,日志生成线程将日志事件放入队列后立即返回,由独立的写入线程异步写入目标,避免了多线程场景下的锁竞争开销。
格式化预优化:基于fmt库(C++20标准格式化库的参考实现)实现高效格式化,支持编译期格式字符串检查,减少运行时解析开销;同时支持缓存常用格式化结果(如固定模块名、线程ID)。
惰性初始化+资源复用:日志器(logger)采用惰性初始化机制,避免启动时的性能损耗;文件写入句柄、缓冲区等资源复用,减少系统调用次数。
核心特性详解
极致易用:纯头文件库(需C++11及以上),无需编译链接,直接包含头文件即可使用;API设计简洁直观,一行代码即可初始化日志器,支持链式调用配置。
#include "spdlog/spdlog.h"
#include "spdlog/sinks/basic_file_sink.h"int main() {// 初始化文件日志器,支持按大小滚动auto file_logger = spdlog::basic_logger_mt("file_logger", "app.log");// 配置日志级别、格式file_logger->set_level(spdlog::level::debug);file_logger->set_pattern("[%Y-%m-%d %H:%M:%S.%e] [%t] [%l] %v");// 记录日志file_logger->debug("User {} logged in", "admin");return 0;
}全场景输出:支持控制台、普通文件、滚动文件(按大小/时间/日期)、系统日志(syslog)、Windows事件日志等多种输出目标;支持多sink组合(如同时输出到控制台和文件)。
精细控制:支持5级日志分级(trace/debug/info/warn/error/critical);支持按日志器名称、级别进行过滤;支持自定义sink(如对接ELK日志系统)。
性能基准与坑点
在Intel i7-12700H处理器、16GB内存、NVMe固态硬盘环境下,单线程异步写入场景下,spdlog的吞吐量可达150万条/秒,延迟约0.6微秒;多线程(8线程)场景下吞吐量约120万条/秒,性能衰减率仅20%,远超传统同步日志库。
需注意的坑点:1)异步模式下,程序异常退出可能导致队列中未写入的日志丢失,需结合spdlog::shutdown()手动释放资源;2)纯头文件特性导致编译时间略长,大型项目可通过预编译头优化;3)不支持极端资源受限的嵌入式环境(如RAM<1MB的场景)。
适用场景
绝大多数现代C++项目,尤其是高性能服务器(如Web服务器、游戏服务器)、桌面应用、中间件等对性能和开发效率有要求的场景;不推荐用于RAM<1MB的嵌入式设备。
2. glog:谷歌背书的工业级稳定之选
glog(Google Logging Library)是谷歌开源的日志库,诞生于2006年,在谷歌内部经过Search、Android等核心产品的十余年验证,以"稳定性强、诊断能力突出"著称,GitHub星标超8k。其设计理念是"为大型分布式系统提供可靠的日志记录与故障诊断能力"。
核心技术原理
glog的核心优势在于故障诊断的工程化设计:
崩溃时堆栈捕获:通过注册信号处理器(如SIGSEGV、SIGABRT),在程序崩溃时自动捕获堆栈信息、线程状态、系统信息,并写入日志文件,无需依赖gdb即可定位崩溃点。
分级日志与触发机制:除常规日志级别外,提供
VLOG( verbose log)分级调试日志,可通过命令行参数动态调整调试日志级别;CHECK系列宏替代assert,支持自定义错误信息,且在Release模式下不失效。日志轮转策略:自动按日志大小(默认1GB)和时间(默认每天)轮转,保留历史日志(默认保留30天),避免单个日志文件过大。
核心特性详解
强大的诊断能力:
CHECK_EQ(a, b) << "a must equal b"在a≠b时触发崩溃并记录日志;LOG_EVERY_N(INFO, 100)每100次调用记录一次日志,方便高频场景调试。全局配置灵活:支持通过命令行参数(如
--minloglevel=2设置最小日志级别为WARN)、环境变量(如GLOG_log_dir指定日志目录)或代码API配置,适配不同部署环境。跨平台兼容:完美支持Linux、Windows、macOS等主流系统,兼容32/64位架构,适配谷歌内部复杂的跨平台场景。
性能基准与坑点
glog默认采用同步写入模式,单线程吞吐量约30万条/秒,延迟约3微秒;多线程场景下因锁竞争,吞吐量降至15万条/秒左右,性能弱于spdlog。需注意的坑点:1)原生不支持异步写入,高并发场景需自行封装线程池;2)配置依赖全局变量,多模块集成时可能存在配置冲突;3)编译时需依赖gflags库(谷歌的命令行参数解析库),集成成本略高于纯头文件库。
适用场景
大型分布式系统、后台服务、企业级应用等对稳定性和故障诊断能力要求极高的场景;尤其适合需要长期运行、崩溃后需快速溯源的服务(如数据库中间件、分布式存储)。
3. Boost.Log:定制化需求的"瑞士军刀"
Boost.Log是Boost库家族的日志组件,以"模块化、高定制化"闻名,是C++生态中功能最全面的日志库之一。其设计理念是"提供一套日志系统的构建框架,而非现成的开箱即用方案",GitHub星标超3k(含Boost整体仓库)。
核心技术原理
Boost.Log的强大源于其彻底的模块化设计,核心分为5大模块:
日志记录器模块:负责生成日志事件,支持多日志器、日志属性(如线程ID、进程ID、模块名)自定义。
过滤模块:基于属性进行复杂过滤,支持逻辑表达式(如"模块为'network'且级别为ERROR")、动态调整过滤规则。
格式化模块:支持自定义日志格式,可输出为文本、JSON、XML等格式,支持属性值的转换与拼接。
输出模块:负责将格式化后的日志写入目标,支持文件、控制台、网络等,支持自定义输出策略。
核心模块:负责模块间的调度与协同,支持异步日志、线程安全等基础能力。
核心特性详解
极致定制化:可自定义日志属性(如添加"用户ID""请求ID"等业务属性),支持基于属性的细粒度过滤(如仅记录用户ID为10086的ERROR日志);支持自定义格式化器(如将日志输出为JSON格式便于ELK分析)。
异步与并发:支持异步日志模式,通过线程池处理日志写入,可配置线程池大小、队列容量等参数;多线程场景下通过细粒度锁保证线程安全,性能优于glog。
Boost生态集成:与Boost其他组件(如Boost.DateTime、Boost.Thread)深度集成,可直接使用Boost的数据类型作为日志属性。
性能基准与坑点
异步模式下,单线程吞吐量约80万条/秒,延迟约1.2微秒;多线程(8线程)吞吐量约60万条/秒,性能介于spdlog和glog之间。需注意的坑点:1)学习曲线极其陡峭,文档庞大且晦涩,熟练掌握需1-2周时间;2)依赖Boost库,会显著增加项目的编译时间(大型项目编译时间可能增加50%)和二进制体积(静态链接后体积增加5-10MB);3)API设计复杂,简单场景下"杀鸡用牛刀"。
适用场景
需要构建高度定制化日志系统的企业级应用(如金融核心系统、电信级设备);已重度依赖Boost库的项目;需要复杂日志过滤、格式化或输出策略的场景。
4. log4cpp:Java生态迁移者的首选
log4cpp是一款模仿Java界经典日志库Log4j设计的C++日志库,诞生于2001年,是C++生态中最早的成熟日志库之一,以"配置灵活、设计成熟"著称,GitHub星标超1.5k。其设计理念是"通过配置文件解耦日志行为与业务代码"。
核心技术原理
log4cpp的核心架构完全复刻Log4j,采用"日志器(Logger)- 附加器(Appender)- 布局(Layout)"三层架构:
日志器(Logger):负责接收业务代码的日志请求,按层级(如root.logger > module.logger)继承配置。
附加器(Appender):负责将日志输出到指定目标,支持文件、控制台、syslog等,可多个Appender组合使用。
布局(Layout):负责格式化日志内容,支持PatternLayout(自定义格式字符串)、SimpleLayout(简单格式)等。
核心特性详解
配置文件驱动:支持XML、Properties两种格式的配置文件,可在不修改代码的情况下调整日志级别、输出目标、格式等(如通过修改配置文件将日志从控制台切换到文件)。
成熟的滚动策略:支持按文件大小、时间、日期滚动,支持设置滚动文件的最大数量和保留时间,适配长期运行的服务。
Java生态兼容:日志配置风格与Log4j完全一致,便于Java/C++混合开发的团队统一日志规范。
性能基准与坑点
log4cpp采用同步写入模式,且内部锁机制较为粗放,单线程吞吐量仅约10万条/秒,延迟约10微秒;多线程场景下吞吐量降至5万条/秒以下,性能是其最大短板。需注意的坑点:1)依赖较多(如log4j、pthread等),编译和部署复杂;2)不支持异步写入,高并发场景下会成为性能瓶颈;3)维护频率较低,部分新特性(如JSON格式化)需自行开发。
适用场景
传统企业级应用(如管理系统、CRM系统);Java/C++混合开发的项目,需统一日志配置风格;对性能要求不高,但需灵活调整日志行为的场景。
5. 特色日志库:小众但精准适配场景
除了上述4个主流库,还有一些小众但在特定场景下表现卓越的日志库,它们在某一维度做到了极致,成为细分场景的"最优解"。
plog:嵌入式与小型项目的"轻骑兵"
plog是一款超轻量级日志库,核心代码仅800余行,GitHub星标超3k。其设计理念是"极简集成、极小开销"。核心特性:1)纯头文件库,无任何外部依赖,支持C++11及以上;2)编译速度极快(大型项目编译时间增加<1%);3)支持基本日志分级和文件输出;4)内存占用极低(运行时内存<100KB)。性能:单线程吞吐量约20万条/秒,不支持异步。适用场景:RAM<10MB的嵌入式系统、小型工具、快速原型开发。
G3log:崩溃安全的"最后防线"
G3log是一款专注于"崩溃安全"的异步日志库,GitHub星标超4k。其核心设计是"确保崩溃前的日志不丢失":通过将日志事件写入内存队列后,异步写入磁盘,同时注册信号处理器,在程序崩溃时阻塞信号处理流程,确保队列中所有日志都写入磁盘后再退出。核心特性:1)崩溃时自动捕获堆栈信息;2)支持日志轮转和自定义格式;3)跨平台兼容。性能:单线程吞吐量约60万条/秒。适用场景:长时运行的服务(如服务器、监控系统)、对日志完整性要求极高的场景(如金融交易系统)。
NanoLog:纳秒级延迟的"性能怪兽"
NanoLog是一款专为"极致低延迟"设计的日志库,GitHub星标超1.5k。其设计理念是"通过预编译优化和内存预分配,实现纳秒级日志延迟"。核心技术:1)编译期解析日志格式字符串,生成专用格式化代码,避免运行时解析开销;2)预分配内存池存储日志事件,减少内存分配开销;3)异步写入且无锁设计。性能:单线程延迟可低至10纳秒,吞吐量达200万条/秒。缺点:不支持日志分级,功能简单。适用场景:高频交易系统、实时数据处理系统等对延迟要求极高的场景。
zlog:C语言生态的"高性能选择"
zlog是一款C语言编写的高性能日志库,可无缝适配C++项目,GitHub星标超3k。其核心特性:1)支持异步写入和无锁并发;2)通过配置文件设置日志策略;3)内存占用低,支持嵌入式系统。性能:单线程吞吐量约100万条/秒。适用场景:C/C++混合开发的项目、嵌入式Linux系统。
三、全维度对比:一张表格看清差异
为了更直观地展示各日志库的差异,我们从核心指标、适用场景等10个维度进行量化对比(评分采用1-5分,5分为最优):
日志库 | 吞吐量(分) | 延迟(分) | 崩溃安全性(分) | 易用性(分) | 定制化(分) | 资源开销(分) | 依赖复杂度(分) | 社区活跃度(分) | 核心优势 | 适用场景 |
|---|---|---|---|---|---|---|---|---|---|---|
spdlog | 5 | 5 | 3 | 5 | 4 | 4 | 5 | 5 | 性能与易用平衡 | 高性能服务器、桌面应用、中间件 |
glog | 3 | 3 | 5 | 4 | 3 | 4 | 3 | 5 | 稳定性强、诊断能力突出 | 分布式系统、后台服务、企业级应用 |
Boost.Log | 4 | 4 | 4 | 2 | 5 | 2 | 2 | 4 | 高度定制化、模块化 | 金融核心系统、定制化日志需求场景 |
log4cpp | 2 | 2 | 3 | 3 | 3 | 3 | 2 | 2 | 配置灵活、Java生态兼容 | 传统企业级应用、Java/C++混合开发 |
plog | 2 | 3 | 2 | 5 | 2 | 5 | 5 | 3 | 轻量、编译快 | 嵌入式系统、小型项目、原型开发 |
G3log | 4 | 4 | 5 | 3 | 3 | 3 | 4 | 3 | 崩溃安全、日志不丢失 | 长时运行服务、金融交易系统 |
NanoLog | 5 | 5 | 3 | 2 | 2 | 4 | 4 | 2 | 纳秒级低延迟 | 高频交易、实时数据处理 |
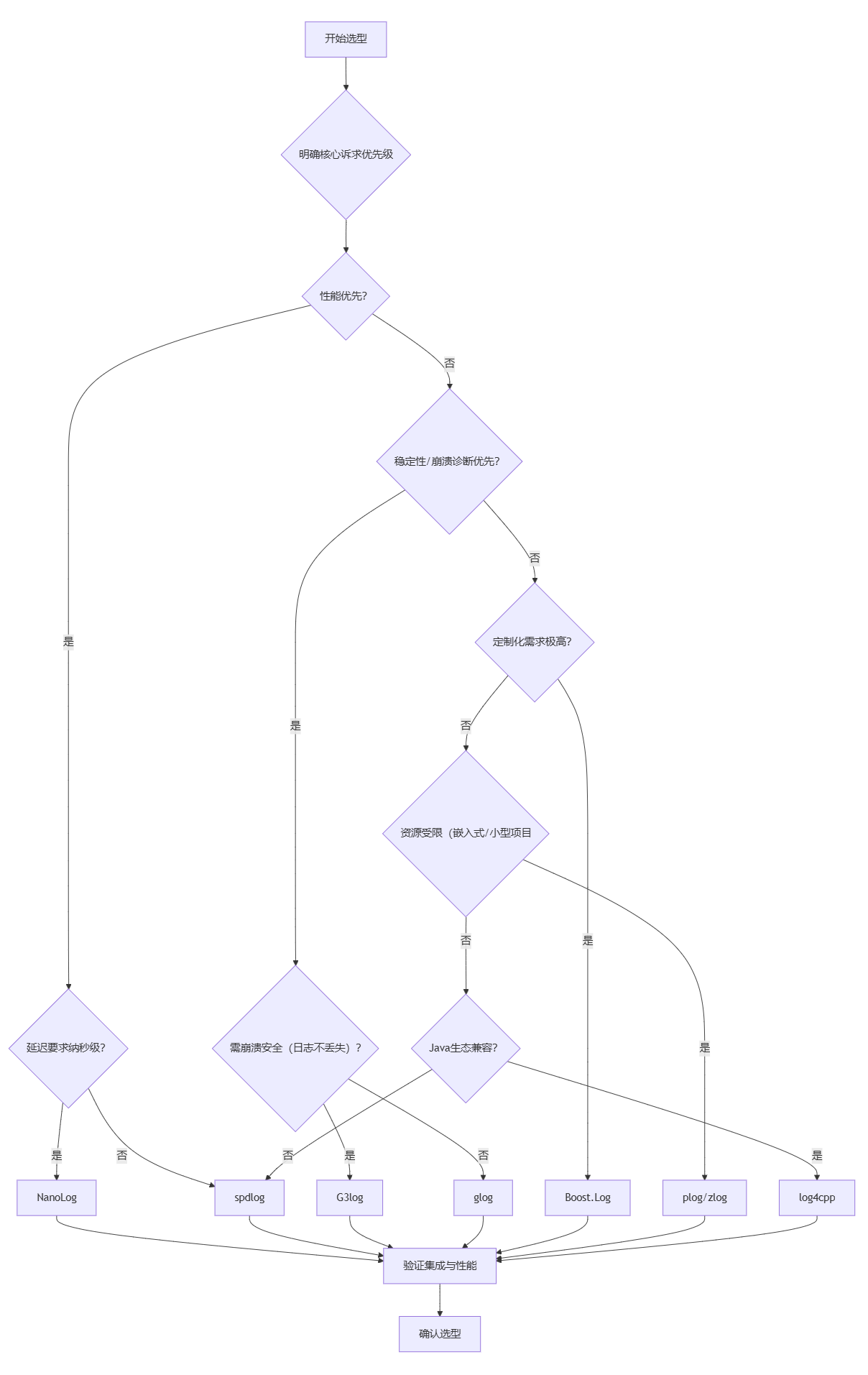
四、选型实战:四步锁定最优解
基于以上分析,我们总结出一套"四步选型法",结合项目需求快速锁定最优日志库。
第一步:明确核心诉求(优先级排序)
首先梳理项目的核心诉求,按优先级排序。常见诉求优先级组合:
高并发服务:性能(吞吐量/延迟)> 易用性 > 定制化
分布式系统:稳定性 > 崩溃诊断 > 性能
嵌入式项目:资源开销 > 易用性 > 基本功能
金融系统:崩溃安全 > 性能 > 定制化
第二步:匹配场景与库的适配性
根据核心诉求,从对比表中筛选出适配的候选库。例如:高并发服务候选库为spdlog、NanoLog;分布式系统候选库为glog、G3log;嵌入式项目候选库为plog、zlog。
第三步:验证集成与性能
对候选库进行小规模验证:1)集成成本验证(是否能快速接入项目,依赖是否冲突);2)性能基准测试(在项目实际场景下测试吞吐量和延迟);3)功能验证(是否满足日志分级、输出目标等核心需求)。
第四步:参考社区与维护性
优先选择社区活跃、维护频率高的库(如spdlog、glog),避免选择长期不更新的库(如log4cpp),降低后续维护风险。
选型流程图
五、总结与未来趋势
没有"最好"的日志库,只有"最适配"的日志库。结合本文分析,给出以下终极建议:
首选推荐:对于90%的现代C++项目,spdlog是最优解——它在性能、易用性、功能完备性之间取得了完美平衡,且社区活跃,维护成本低。
特殊场景:分布式系统选glog,定制化需求选Boost.Log,嵌入式选plog,崩溃安全选G3log,高频交易选NanoLog,Java混合开发选log4cpp。
避坑提醒:避免在高并发场景使用log4cpp;避免在小型项目中使用Boost.Log;避免在嵌入式场景使用spdlog/glog。
展望未来,C++日志库将呈现三大趋势:1)云原生适配:更多库将原生支持云原生场景(如直接对接Prometheus、ELK、云日志服务);2)零成本集成:基于C++20模块特性,减少编译时间和内存开销;3)智能日志:集成日志脱敏、异常检测等智能能力,从"记录日志"向"分析日志"升级。
希望本文能帮你跳出选型困境,让日志系统成为项目开发的"助推器"而非"绊脚石"。如果有特定场景的选型疑问,欢迎在评论区交流!