Redis_11_类型补充+命令补充+RESP
之前我们已经介绍过了Redis常用的类型:String、LIst、Hash、Set、Zset,这些类型应用广泛,频繁使用。
实际上,Redis的类型总共有10种: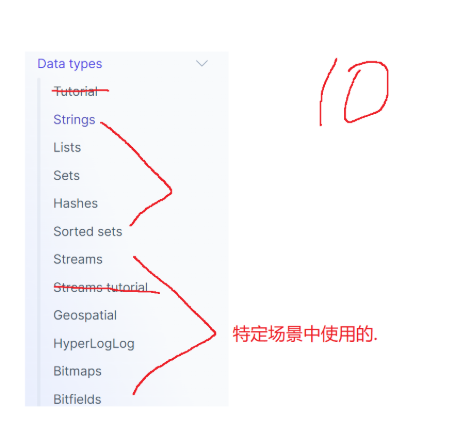
类型补充
下面的类型使用较少,因此我们大概讲一下使用场景,需要使用的时候再去翻阅文档即可。
Stream

官方文档的意思就是stream类型可以用来模拟实现这种事件传播的机制~~
将简单点,stream就是一个队列(阻塞队列),是redis作为一个消息队列的重要支撑,属于是List blpop/brpop的升级版本。
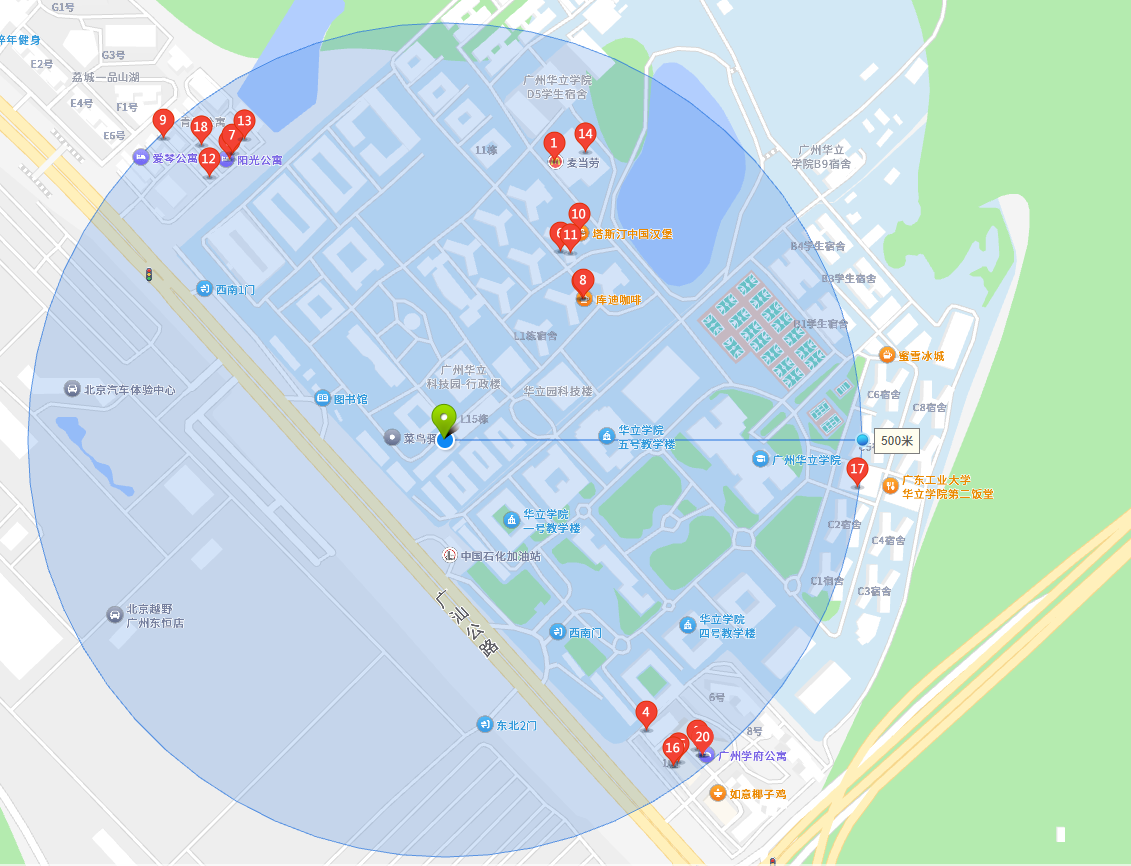
Redis geospatial

这个类型主要用来存储坐标(经纬度),存储一些点之后,就可以让用户给定一个坐标,去从工程存储的点里进行查找(按照半径,矩形区域~)
这个功能在“地图”应用非常重要~~
比如搜索当前地区美食: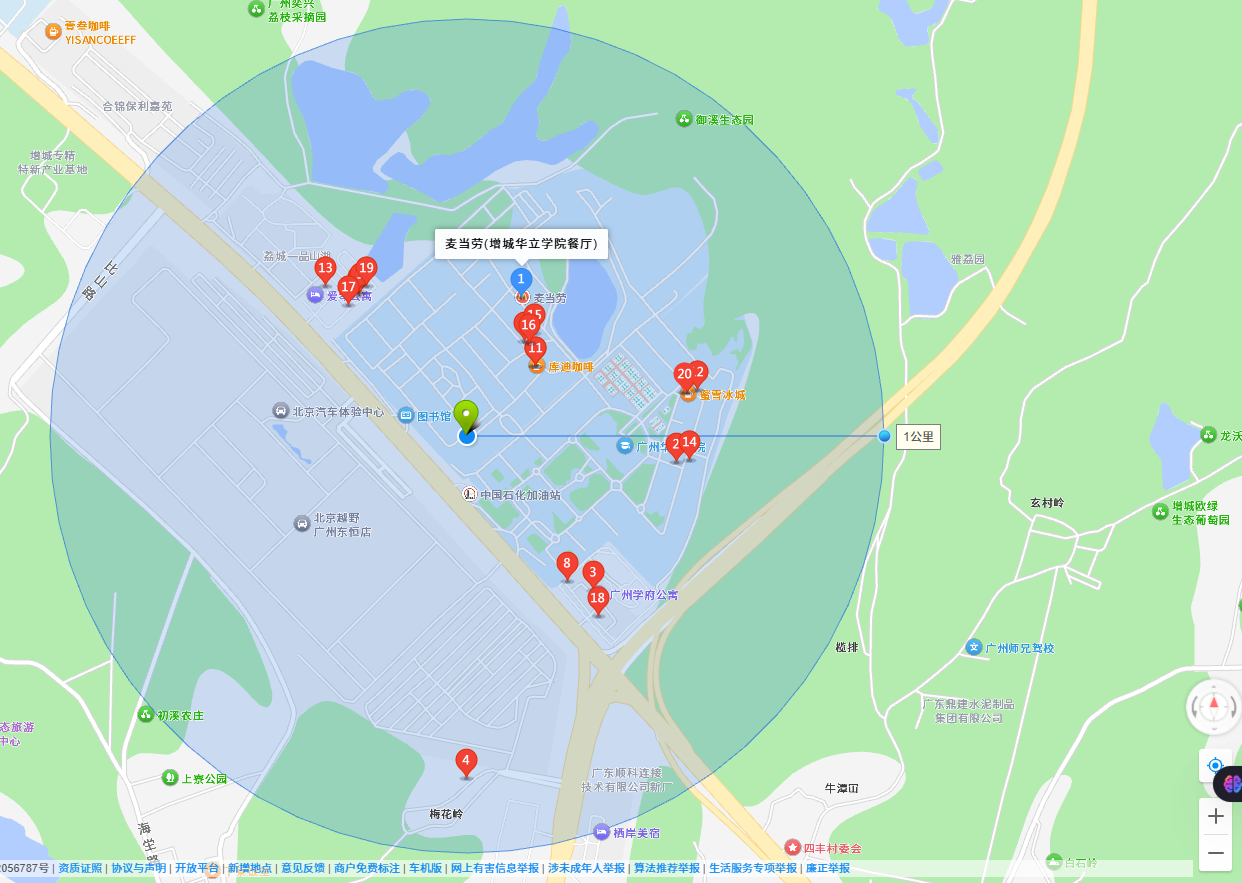
Redis HyperLogLog
这个类型的应用场景只有一个,估算集合中的元素个数。
我们之前讲过,Set有一个应用场景,统计服务器的UV(用户的访问次数)使用Set当然可以统计UV,但是最大的问题在于,如果UV数据量非常大,Set就会消耗很多的内存空间~~
就阿佘存储userId每个userId按照8个字节算~~
1亿UV就需要消耗8亿字节~~
那有人可能就会觉得,才0.8GB而已啊又不多,就拿集合存不是也行吗?
问题是HyperLogLog可以最多使用12KB空间实现上述效果~~
之所以Set需要消耗这么大的空间,是因为Set需要存储每个元素;而HyperLogLog不需要存储元素的内容,但是能够记录“元素的特征”,从而在新增元素的时候,就能知道当前新增的元素是一个已经存在的元素,还是一个崭新的、第一次出现的元素,它的主要功能是用来计数(记录出当前集合中有多少个不同的严肃,但是不能告诉你这些元素是啥~~)
Redis bitmaps
这个类型叫做位图,主要作用是使用bit位来表示整数。
位图本质上还是一个集合,属于是Set针对整数的特化版本~~
主要作用也是为了节省空间。
咦?那不是和HypeLogLog一样吗?而且HypeLogLog更省空间呢?
不同的是bitmap这里存储元素了!!它既可以存储数字,也可以存储字符串;而HypeLogLog不存储元素内容,只是计数效果~~
而且HypeLogLog存储元素的时候,提取特征的过程是不可逆的!!(信息量丢失了)就像猪肉能给它做成火腿肠,但是火腿肠还原不回猪肉了……
Redis bitfields
它和我们C语言中位域的概念非常相似:
bitfield可以理解成一串二进制序列(字节数组),同时可以把这个字节数组中的某几个位,赋予特定含义,并且可以进行读取/修改/算术运算相关操作~~
位域这个东西,相比与之前的String/hash来说,目的仍然是节省空间。
这个东西主要应用场景:记录补刀数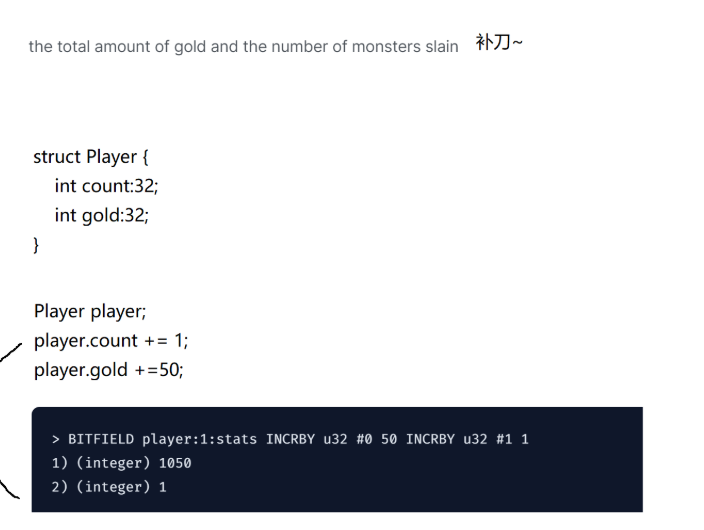
渐进式遍历
scan
我们之前知道keys这个命令会一次性把整个redis中所有key都获取到,keys*(这个操作比较危险可能会一下子得到太多的key,阻塞redis服务器!)
通过渐进式遍历,就可以躲到,既能够获取到所有的key,同时又不会卡死服务器。此处的渐进式遍历指的是:不是一个命令,把所有的key都拿到。而是每执行一次命令,只获取到其中的一小部分~~这样的话保证当前这一次操作不会太卡~~
要想的到所有的key就需要多次遍历,多次执行渐进式遍历命令~~
渐进式命令其实是一组命令,这一组命令的使用方法是一样的~~
其中的代表命令是scan:
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]ps:这里的pattern和keys命令是一样的;count指的是光标,限制这一次遍历能够获取到多少个元素,默认是10;type指定当前要查询的key对应的value的类型。
这里count与MySQL中的limit不一样,MySQL中的limit是精确的,而这里的count只是给redis服务器的一个提示/建议,写入的count和实际返回的key的个数不一定是完全相同的,但是不会差很多~~
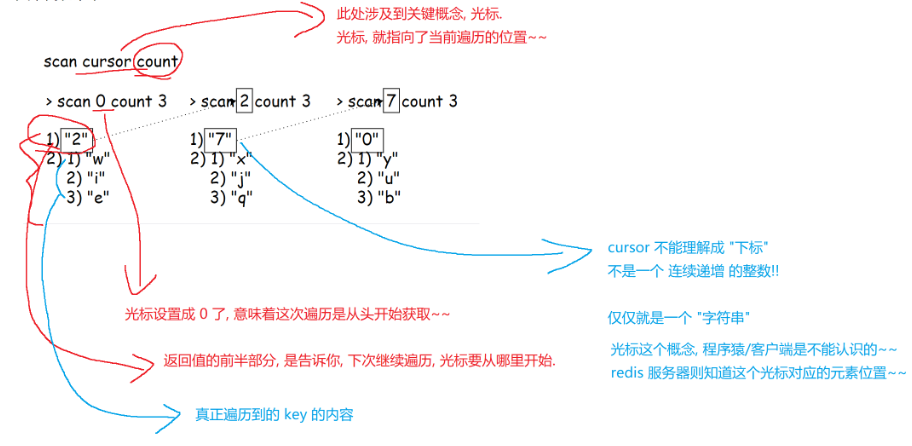

count这里的数字,不是说每次遍历都得设置成一样的~~
这里的渐进式遍历,在遍历过程中,不会在服务器这边存储任何的状态信息。此处的遍历是随时可以终止的~~不会对服务器产生任何的副作用~~
那么什么教服务器不会存储状态信息呢?
比如我去餐馆吃饭,都已经吃饱了,还有一些菜还没上来。
此时我就去结账并且问老板还有一些菜没上,能不能退了~~
老板就会赶紧跑到后厨,看了之后,对我说:“菜已经在做了,退不了了~~”
餐馆就相当于服务器,而我就是客户端,我点了很多菜,餐馆就得一样一样做好上来,相当于在遍历很多的key,我遍历了一半之后,我想取消,发现取消不了,服务器这里保存了状态(服务器就已经把菜做上了)
如果我想强行取消,此时服务器的状态仍然保存着,此时就会对服务器的运行造成一定的影响~~
相比之下,redis则没有采取这样的设定!!redis的服务器是不保留任何状态的,遍历时可以随时中断的~~
相当于去超市买东西,扫了一半,你突然说,后面的你不要了,你想直接走,也是可以的~~
此处还需要注意:渐进式遍历scan虽然解决了阻塞的问题,但如果在遍历期间键有所变化(增加、修改、删除),可能会导致遍历时键重复遍历或者遗漏,这点务必在实际开发中考虑~~
数据库管理命令
mysql中有一个重要的概念,database。一个mysql服务器上可以有很多个database,一个database上可以有很多个表。
在前面的学习中,感觉上来就是key value~~
其实redis也是有database这样的概念的,只不过不像MySQL那样随意~~
redis中的database是现成的,咱们用户不能创建新的数据库,也不能删除已有的数据库。
默认redis给我们提供了16个数据库0-15,这16个数据库中的数据库是隔离的(相互之间不会有影响)默认情况下使用的就是0号。
select
使用这个命令来切换到目标数据库。
SELECT index比如:
在0号数据库中,设置一个key为123,此时能够正常获取到key
此时,我们切换到1号数据库中:
此时,再尝试获取,就获取不到了:
dbsize
这个命令可以获取到当前数据库中键值对的个数。
DBSIZE

flushdb
清空当前数据库。
FLUSHDB [ASYNC | SYNC]ps:这里的async是异步处理,sync是同步处理。
flushall
清空所有数据库。
FLUSHALL这个我们之前讲过,就不做过多赘述。
Redis客户端介绍
前面学习的主要是各种redis的基本操作/命令。都是在redis命令行客户端,手动执行的。
我们之前讲过:更多的时候,操作redis是使用redis的api,来定制化redis客户端程序,进一步操作redis服务器的。
就像以前学习MySQL的时候,也会涉及到,关于使用idea来操作MySQL服务器:Mybatis/JDBC/
那我们前面学过的redis命令是不是就没有价值了呢?
当然不是的!!redis命令相当于使用代码来执行了~~
RESP
为什么我们能编写出一个自定义的redis客户端呢?
这是因为Redis公开了它们的自定义协议!!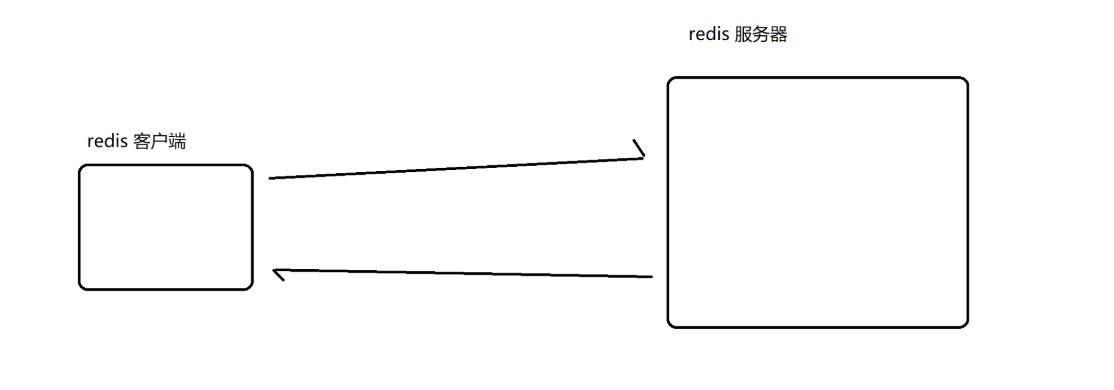
在网络通信的过程中,会用到很多的“协议”。
应用层:一般是自定义协议,但是业界也有很多成熟的应用层协议,HTTP等……Redis此处应用层协议就是自定义的协议~~
传输层:TCP/UDP协议
网络层:IP协议
数据链路层:以太网
物理层
这后续的几个协议都是固定好的,是在系统内核或驱动程序中实现的~~咱们程序员只能选择,不能修改~~
客户端按照这里的应用层协议(传输层还是基于TCP),发送请求,服务器按照这个协议进行解析,再按照这个协议构造响应,客户端再解析这个响应,之所以上述通信能够完成,是因为开发客户端的人和开发服务器的人都清楚地知道协议的细节~~
而Redis的自定义协议就是RESP协议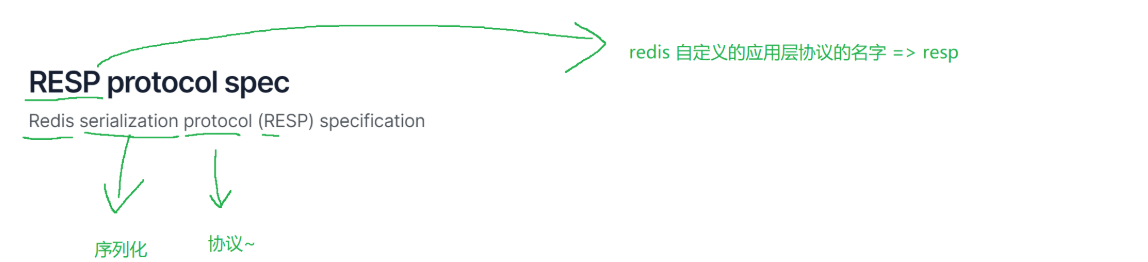
详解
resp协议的优点:
1、简单好实现。
2、快速进行解析
3、肉眼可读
特点:
1、传输层基于TCP但是又和TCP没有强耦合
2、请求和响应之间的通信模型是一问一答的模式~~(客户端给服务器发一个请求,服务器就返回一个响应)
在响应中不同的类型,返回的格式也是不同的: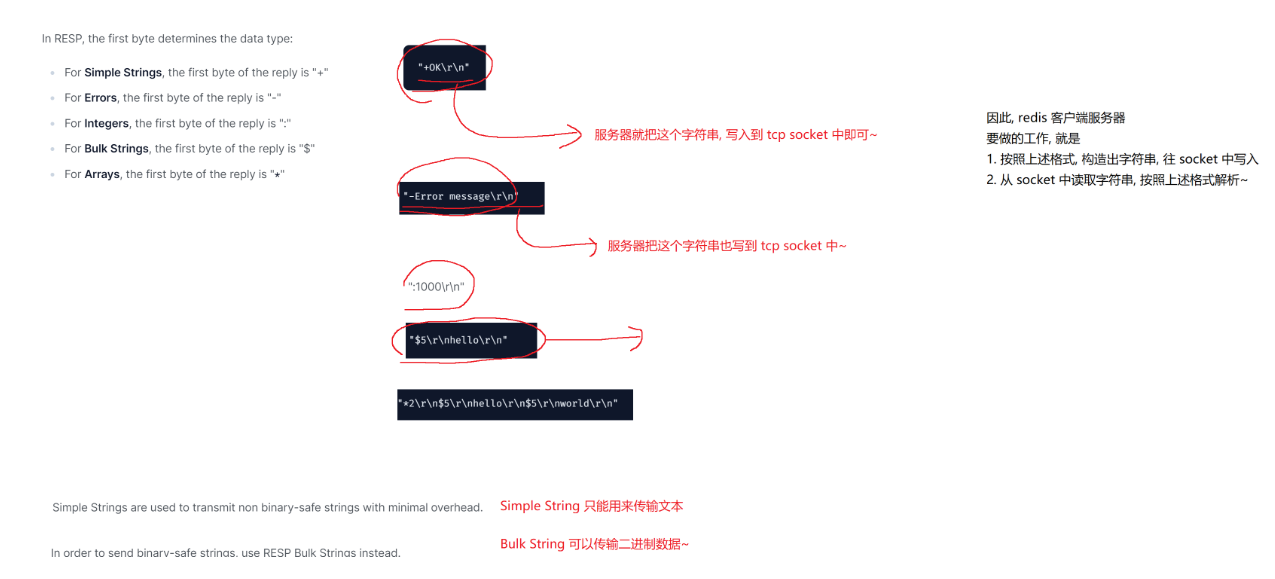
那一会我们写代码,真的需要按照上述的协议,解析/构造字符串吗?
不用~~这套协议公开已久~~已经有很多的大佬实现了这套协议的解析/构造~~只需要使用这些大佬们提供的库,就可以简单方便地来实现完成和redis服务器通信的操作了