ServletLess架构简介
ServletLess简介
ServletLess(或称Serverless)架构正在深刻改变我们构建和部署应用的方式,它让你我能更专注于创造价值本身而非底层设施。下面这张表格快速展示了它与传统架构的核心区别,之后我会带你从零搭建一个服务,并探索它与AI结合的强大潜力。
| 特性维度 | 传统服务器架构 (如Servlet) | ServletLess架构 |
| 管理重点 | 需要自行管理服务器、操作系统、运行时环境及扩展性。 | 开发者只关注业务逻辑代码,无需管理服务器。 |
| 扩展性 | 通常需要手动或预配置扩展,响应流量变化较慢。 | 自动、精确的弹性伸缩,根据请求量实时调整。 |
| 计费模式 | 为预留的服务器资源(如CPU、内存)付费,无论使用率。 | 按实际执行资源消耗和次数付费,成本更低。 |
| 高可用性 | 通常需要自行设计和实现故障转移和可用性机制。 | 内置高可用性和容错机制,无需额外工作。 |
| 部署粒度 | 通常部署整个应用程序。 | 部署单个函数(微功能)。 |
🧠 深入理解ServletLess
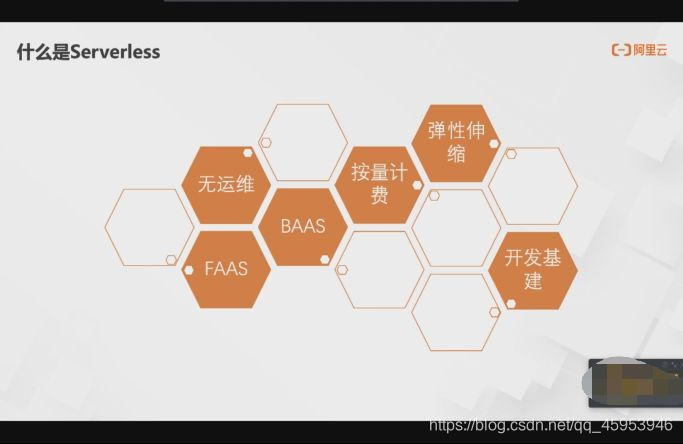
有人把Serverless看作FAAS+BAAS=Serverless
Serverless 是一种云计算模型,让开发者无需管理底层服务器基础设施,而能专注于编写和部署代码。它并非真的没有服务器,而是由云服务商负责服务器的维护、扩展和缩减等工作。这种模式的核心特点是事件驱动、弹性伸缩和按量付费,通常结合了 函数即服务 (FaaS) 和 后端即服务 (BaaS)。
核心理念
- 关注业务逻辑: 将服务器管理、运维等任务交给云服务商,开发者只需编写应用程序代码。
- 抽象化服务器: 对开发者而言,服务器被抽象化,代码不必部署在特定的服务器上,而是通过事件触发来执行。
- 由云厂商负责: 供应商负责置备、维护、扩展和安全更新等工作。
主要组成部分
- FaaS (Function as a Service): 开发者将代码部署为独立的函数,并由云平台根据事件触发来执行。
- BaaS (Backend as a Service): 提供无需自己管理的后端服务,如数据库、身份验证、文件存储等,通过 API 供应用程序调用。
主要优势
- 成本效益高: 只为实际使用的计算资源付费,在没有流量时几乎不产生费用。
- 简化运维: 无需管理服务器,大幅降低了运维成本和人力需求。
- 弹性伸缩: 根据需求自动、快速地扩展或缩减计算资源,保证应用的稳定运行。
- 加速开发: 开发者可以更快地迭代和发布应用,缩短了产品上市时间。
应用模式
- Serverless 架构通常结合使用 FaaS 和 BaaS。
- 当有事件发生时(如用户访问、数据库更新等),会触发相应的函数(FaaS)来执行任务,并将结果存储在服务中(BaaS)。
- 例如,一个电商网站的订单处理流程可以由一个 Serverless 应用程序处理:API 网关接收到订单请求,触发 FaaS 函数,该函数向 BaaS 数据库写入订单信息,并向用户发送通知。
🛠️ 从零搭建ServletLess服务
我们将使用 AWS Lambda和 API Gateway搭建一个简单的图片处理服务。这个服务将在收到图片上传事件时,自动生成一个缩略图。
第一步:准备环境与工具
- AWS账户:拥有一个AWS账户是前提。
- AWS CLI:在本地安装并配置好AWS命令行工具。
- Node.js环境:我们使用JavaScript进行开发。
Serverless Framework:这是一个极佳的自动化部署和管理Serverless应用的工具。通过npm安装:npm install -g serverless。
第二步:编写业务函数
创建项目目录后,编写核心函数代码,保存为 handler.js:
// 引入AWS SDK用于操作S3存储桶
const AWS = require('aws-sdk');
const s3 = new AWS.S3();// 一个简单的图片处理库(示例中使用'sharp',实际部署需在package.json中声明依赖)
const sharp = require('sharp');exports.generateThumbnailHandler = async (event) => {try {// 1. 从事件对象中获取触发函数的事件信息(如图片上传到哪个S3存储桶和对象键)const srcBucket = event.Records[0].s3.bucket.name;const srcKey = decodeURIComponent(event.Records[0].s3.object.key.replace(/\+/g, " "));// 2. 从源S3存储桶获取图片const originalImage = await s3.getObject({ Bucket: srcBucket, Key: srcKey }).promise();// 3. 使用sharp库生成缩略图const thumbnail = await sharp(originalImage.Body).resize(200, 200) // 缩放到200x200.jpeg({ quality: 80 }) // 转换为JPEG格式,质量80%.toBuffer();// 4. 将处理后的缩略图上传到另一个S3存储桶(例如:thumbnails)await s3.putObject({Bucket: 'your-thumbnails-bucket-name', // 请替换为你的目标存储桶名称Key: `resized_${srcKey}`,Body: thumbnail,ContentType: 'image/jpeg'}).promise();console.log('Thumbnail generated successfully!');return { status: 'success' };} catch (error) {console.error('Error processing image:', error);throw error;}
};这个函数展示了Serverless的典型模式:事件触发(S3上传)-> 执行逻辑(图片处理)-> 输出结果(存入新位置)。你无需关心服务器,只需关注 exports出的函数逻辑。
第三步:配置与部署
在项目根目录创建 serverless.yml文件,这是Serverless Framework的部署配置文件:
service: image-thumbnail-generator # 你的服务名称provider:name: awsruntime: nodejs18.x # 使用Node.js 18region: us-east-1 # 选择区域iamRoleStatements:# 授予Lambda函数读写S3存储桶的权限- Effect: AllowAction:- s3:GetObject- s3:PutObjectResource:- arn:aws:s3:::your-source-bucket-name/* # 请替换为你的源图片存储桶ARN- arn:aws:s3:::your-thumbnails-bucket-name/* # 请替换为你的缩略图存储桶ARNfunctions:generateThumbnail:handler: handler.generateThumbnailHandlerevents:# 配置S3事件触发器:当有.jpg文件上传到源存储桶时触发此函数- s3:bucket: your-source-bucket-name # 请替换event: s3:ObjectCreated:*rules:- suffix: .jpgexisting: true # 如果存储桶已存在,则使用已存在的存储桶配置完成后,在终端运行 serverless deploy命令。Serverless Framework会自动打包你的代码、创建所需的AWS资源(如IAM角色)并部署函数。部署成功后,你会获得一个可访问的端点或已配置好的事件触发器。
第四步:测试与调试
本地测试:使用 serverless invoke local -f generateThumbnail --data '{"Records":[{"s3":{...}}]}'进行本地测试
- 云端测试:直接上传一个.jpg图片到你配置的源S3存储桶,然后检查目标存储桶是否生成了缩略图。
- 查看日志:通过AWS控制台或Serverless Framework的
serverless logs -f generateThumbnail命令查看函数执行日志,这是调试的主要方式。
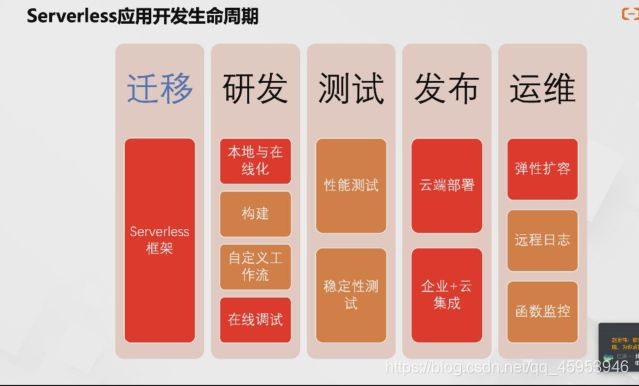
传统应用的生命周期
serverless对传统的方式进行了改良优化,除了测试环节外都有调整,多了一步迁移周期。
🤖 ServletLess与AI的强强联合
ServletLess的事件驱动、按需运行、快速伸缩的特性,与许多AI工作负载的需求完美契合。
异步AI推理任务:对于图片风格迁移、视频分析、文档摘要等不需要实时响应的AI任务,ServletLess是理想选择。你可以将任务放入消息队列(如AWS SQS),由ServletLess函数消费并调用AI模型处理,结果存入数据库。用户无需等待,通过轮询或通知获取结果。这种异步解耦的模式,特别适合处理高并发、波动大的AI任务。
智能聊天机器人:构建一个AI客服机器人。API Gateway接收用户提问,触发一个ServletLess函数。该函数内部调用大语言模型(如通过千帆平台接入文心一言等大模型)的API生成回复。ServletLess的自动伸缩能力可以轻松应对流量的突然高峰。
AI数据处理管道:可以构建一个完整的AI数据处理流水线。例如,一个函数在文件上传时触发,进行数据清洗和标准化;另一个函数调用AI模型进行分析;最后一个函数将结果归档。整个流程可以通过事件驱动串联起来,无需管理任何服务器集群。
成本效益:对于AI推理这类计算密集型任务,如果流量有波动,ServletLess的按需付费模式可以大幅降低成本。你不需要为闲置的GPU服务器付费。
实践建议与总结
从零搭建ServletLess服务的关键在于思维转变:从“部署应用”转向“部署功能”。它的无服务器管理、自动弹性伸缩和按需付费模型,尤其适合事件驱动、流量波动大或需要快速迭代的场景。
当你将ServletLess与AI结合时,它的潜力会得到更大发挥。无论是突发性的AI推理任务,还是构建智能数据处理管道,ServletLess都能让你更专注于算法和业务逻辑创新。
如何把现有的SpringCloud服务改造成ServletLess 服务
将现有的 Spring Cloud 服务改造为 ServletLess (Serverless) 架构,可以让你享受免服务器管理、按需付费和极致弹性伸缩的优势。下面这张图清晰地展示了改造的核心路径、关键决策点以及不同策略的适用场景,你可以用它作为改造的路线图。
三种主要的改造路径,下表详细对比了它们的特点,帮助你根据自身情况做出选择。
| 特性维度 | 策略一:基于Spring Cloud Function | 策略二:完全函数化改造 | 策略三:云平台适配器 |
| 改造程度 | 中等,在现有SpringBoot应用上包装 | 彻底,剥离Spring框架,重写为纯函数 | 最小,依赖云厂商提供的适配组件 |
| 优势 | 兼容现有代码,学习曲线平缓,利于渐进式迁移 | 函数体积更小,冷启动极快,资源利用率最高 | 部署配置简单,可快速利用云平台高级功能 |
| 挑战 | 应用整体打包可能导致冷启动较慢 | 重构工作量巨大,需重写基础设施代码(如数据库连接) | 供应商锁定,迁移到其他平台成本高 |
| 适用场景 | 复杂的业务系统,希望逐步迁移 | 新建的独立微服务或对冷启动有极致要求的场景 | 业务逻辑相对标准,且已决定深度绑定某云厂商 |
🔧 具体改造步骤
以下以策略一(Spring Cloud Function)为例,说明具体改造步骤,这是对现有系统最友好、最常采用的方案。
1. 调整项目依赖
在现有服务的 pom.xml中引入关键依赖,并确保版本兼容性。
<properties><spring-cloud.version>2021.0.8</spring-cloud.version> <!-- 请根据你的Spring Boot版本选择 -->
</properties><dependencies><!-- 核心依赖 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-function-web</artifactId></dependency><!-- 根据你选择的云平台添加适配器,例如AWS --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-function-adapter-aws</artifactId></dependency><!-- 其他原有依赖保持不变 -->
</dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>${spring-cloud.version}</version><type>pom</type><scope>import</scope></dependency></dependencies>
</dependencyManagement>2. 创建函数式端点
将你的业务逻辑包装成 Function,Consumer或 Supplier。
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.function.Function;@Configuration
public class FunctionConfig {// 示例:将一个查询用户信息的服务改造为Function// 假设你原有这样一个Service:userService.findUserById(String id)@Beanpublic Function<String, String> findUserById(UserService userService) {// 这个lambda表达式就是你的业务逻辑return (userId) -> {// 原有服务逻辑在这里被调用User user = userService.findUserById(userId);// 返回结果,例如JSON字符串return objectMapper.writeValueAsString(user);};}
}3. 配置函数触发器
在 application.yml中声明哪个函数被触发以及如何触发。
spring:cloud:function:definition: findUserById # 指定默认执行的函数名stream: # 如果使用事件驱动,可以配置Spring Cloud Streambindings:findUserById-in-0:destination: user-requestsfindUserById-out-0:destination: user-responses4. 创建云平台入口点(以AWS Lambda为例)
这个类负责将云平台的事件(如HTTP请求)传递给你的Spring函数。
import com.amazonaws.services.lambda.runtime.Context;
import com.amazonaws.services.lambda.runtime.RequestHandler;
import org.springframework.cloud.function.adapter.aws.SpringBootRequestHandler;// 这个Handler是部署到AWS Lambda时的入口
// 泛型参数:输入事件类型,输出结果类型
public class MyFunctionHandler extends SpringBootRequestHandler<String, String> {// 内部逻辑由父类处理,它负责启动Spring上下文并调用你的函数
}⚙️ 部署与优化
改造完成后,部署流程和优化技巧至关重要。
- 打包与部署:使用
mvn clean package生成一个 Fat JAR(包含所有依赖的JAR包)。将这个JAR包上传到你所选的Serverless平台(如AWS Lambda,阿里云函数计算),并将Handler设置为你的入口类(如com.example.MyFunctionHandler)。 - 优化冷启动:这是Serverless的关键挑战。
-
- 预留实例:为函数设置预留并发,让平台始终保持一个或多个实例处于活跃状态,彻底消除冷启动。
- 减少依赖:精简JAR包,移除不必要的依赖。
- 使用GraalVM原生镜像:这是终极方案。通过Spring Native项目将应用编译为原生可执行文件,能极大减少启动时间和内存占用。
- 配置监控:利用云平台提供的监控工具(如AWS CloudWatch)来观察函数的执行时间、内存使用、调用次数和错误率,以便进一步调优。
⚠️ 重要注意事项
在改造过程中,请牢记以下几点:
- 无状态设计:Serverless函数本身是无状态的。切勿在函数实例的内存中保存会话(Session)或缓存数据。所有需要持久化的状态必须存入外部存储(如Redis、数据库)。
- 本地开发测试:在部署到云端之前,利用
spring-cloud-starter-function-web在本地启动一个Web端点进行测试。例如,你的findUserById函数会自动暴露为POST /findUserById接口,方便使用Postman测试。 - 版本与兼容性:特别注意Spring Boot、Spring Cloud及各组件间的版本对应关系,不匹配会导致各种奇怪错误。
💎 核心总结
将Spring Cloud服务改造为ServletLess架构,本质上是从部署和运维“应用”转变为部署和运维“业务逻辑”。推荐采用 Spring Cloud Function的方案进行平滑迁移,它平衡了改造成本和Serverless收益。关键在于做好依赖管理、函数定义、冷启动优化和无状态设计。
希望这份详细的指南能帮助你顺利完成架构现代化改造。