王树森深度强化学习 DRL(六)连续控制 DDPG + 随机策略
【王树森】深度强化学习(DRL) 连续控制 -- B站
github - ddpg 代码
1. 离散控制与连续控制区别
之前的问题:像超级玛丽,动作空间只有三种动作,DQN的输出维度为 3 。
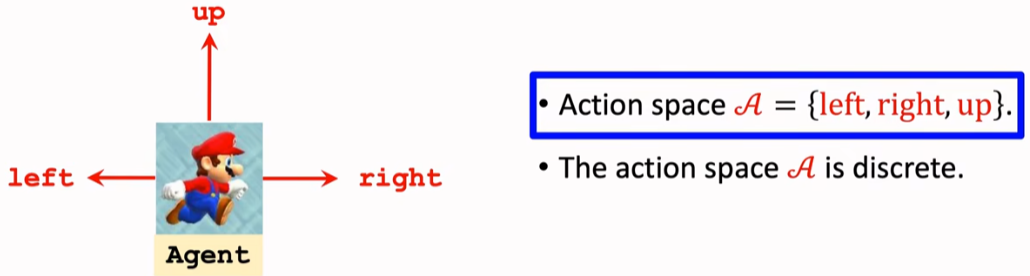
像机械臂控制问题,两个自由度对应两个维度的角度,
但角度是一个连续的量(连续动作空间)。

想法1:连续量离散化:划分小间隔为一个单位。
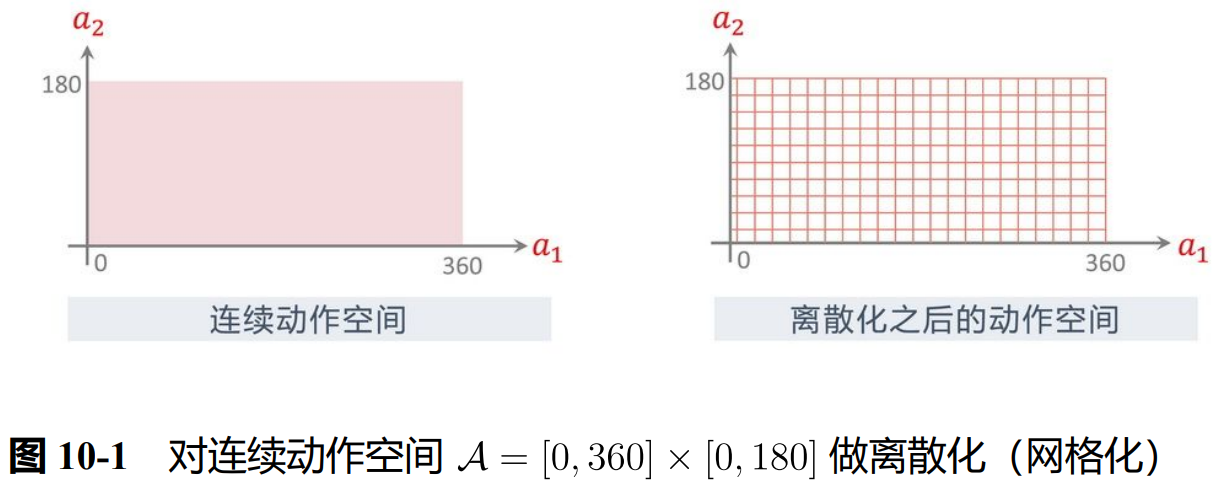
(但这么操作 会随着维度升高而指数爆炸)
2. Deterministic Policy Gradient (DDPG) 深度确定性策略梯度
https://arxiv.org/pdf/1509.02971
属于一种 actor-critic 方法,策略网络直接输出连续动作的确定性取值
(而非离散动作的概率分布),突破了传统强化学习在连续动作空间的局限。
TD 算法更新价值网络,下一步的 a' 由策略网络得到。
同价值学习部分优化手段(使用目标网络、经验回放、多步TD损失)

使得 q 打分更高,训练策略网络;链式法则 q -> a -> θ
代码实现的时候:损失设置为 q(s,π(s)) 的相反数。
actor_loss = -self.critic(s, self.actor(s)).mean()
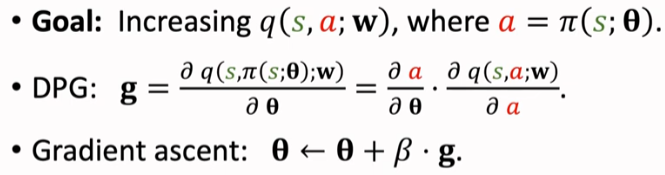
伪代码:先把目标网络参数设置为 = 主网络,后续每一次的循环中
π(s) + 扰动 -> 动作 a -> (s,a,r,s') 存入经验回放;
经验回放取一个 Batch;价值网络和策略网络更新;目标网络软更新

3. 随机策略连续控制
用正态分布的概率密度函数 作为策略函数进行抽样:
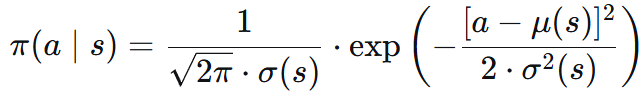
因为标准差 σ 必须非负,如果把 σ 作为优化变量,那么优化模型有约束条件,给求解造成困难。
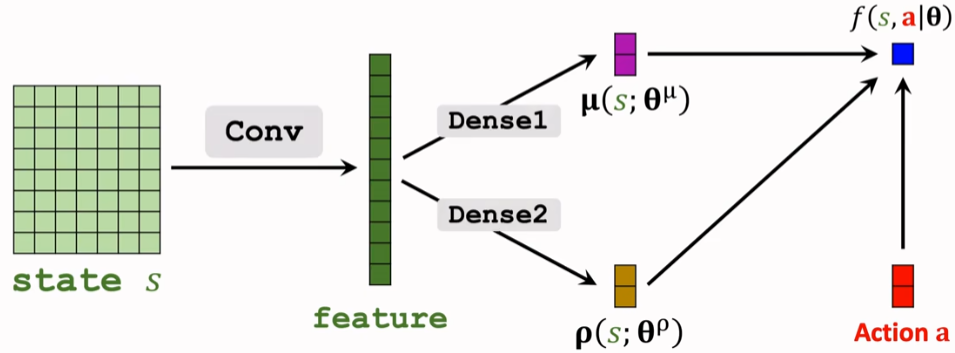
于是我们用 方差对数 ρ = ln(σ²) 和 均值 μ,并且拿神经网络拟合。
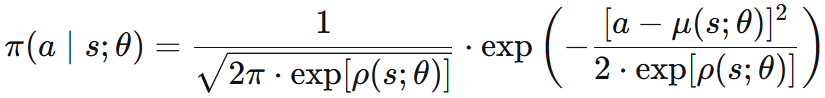
辅助网络 f() = ln π() + C
![]()
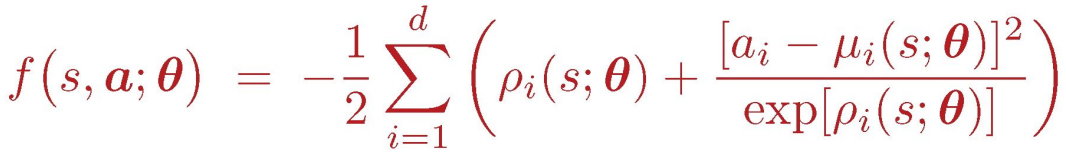
故随机策略梯度可写为:
![]()
再使用 REINFORCE 或 actor-critic 的方法训练。
4. 倒立摆代码实践 stable-baselines3
https://stable-baselines3.readthedocs.io/en/v2.7.0/modules/ddpg.html
环境的目标:将倒立摆从随机位置摆动到竖直向上(倒立)的状态,并尽可能地保持住。
奖励在每个时间步的计算公式如下:
reward = -(θ² + 0.1 * θ'² + 0.001 * τ²)
θ: 摆杆角度与竖直向上位置的偏差
θ': 摆杆的角速度。 τ: 施加在摆杆铰链上的扭矩(动作)。
理想稳定状态:角度偏差小,角速度小,尽量少施加外力。
最后返回 200 步的总奖励值,reward 越接近 0 表现越好。
Policy 网络参数:
MlpPolicy:状态观测空间是向量的环境;多层感知机策略;Pendulum-v1, CartPole 经典控制
CnnPolicy:状态观测空间是图像的环境;卷积神经网络策略;Atari 游戏,机器人视觉导航
MultiInputPolicy:同时接收图像和向量信息的环境
# pip install stable-baselines3
import gymnasium as gym
import numpy as np
from stable_baselines3 import DDPG
from stable_baselines3.common.noise import NormalActionNoise# 1. 创建训练环境:关闭渲染,提升训练效率
env_train = gym.make("Pendulum-v1", render_mode=None)# 创建DDPG需要的动作噪声
n_actions = env_train.action_space.shape[-1]
action_noise = NormalActionNoise(mean=np.zeros(n_actions), sigma=0.1 * np.ones(n_actions))# 初始化DDPG模型,传入训练环境
model = DDPG("MlpPolicy", env_train, action_noise=action_noise, verbose=1)print("开始训练(无可视化)...")
model.learn(total_timesteps=10000, log_interval=10) # 10000步训练,10个episode输出一次日志
model.save("ddpg_pendulum")
# 关闭训练环境,释放资源
env_train.close()日志输出示例:
| rollout/ | |
| ep_len_mean | 200 | # 平均每个episode长度 = 200步
| ep_rew_mean | -649 | # 平均每个episode总奖励 = -649(默认是最近100个episode平均)| time/ | |
| episodes | 30 | # 已完成的episode总数
| fps | 192 | # 每秒处理的帧数/步数
| time_elapsed | 31 | # 已训练时间(秒)
| total_timesteps | 6000 | # 总训练步数 = 30 episodes × 200步| train/ | |
| actor_loss | 62.7 | # Actor网络损失值
| critic_loss | 1 | # Critic网络损失值
| learning_rate | 0.001 | # 学习率
| n_updates | 5899 | # 网络参数更新次数2. 测试阶段:创建支持 human 渲染的环境
print("开始测试(启用可视化)...")
env_test = gym.make("Pendulum-v1", render_mode="human")
# 加载训练好的模型
model = DDPG.load("ddpg_pendulum")for test_ep in range(5):obs, _ = env_test.reset()test_reward = 0done = Falsewhile not done:# 确定性预测(关闭噪声,使动作更稳定)action, _states = model.predict(obs, deterministic=True)# 与测试环境交互obs, reward, terminated, truncated, info = env_test.step(action)test_reward += rewarddone = terminated or truncatedprint(f"测试轮{test_ep + 1} 总奖励:{test_reward:.1f}")# 关闭测试环境
env_test.close()plus:使用 callback 追踪 episode 和日志里的两个网络损失。
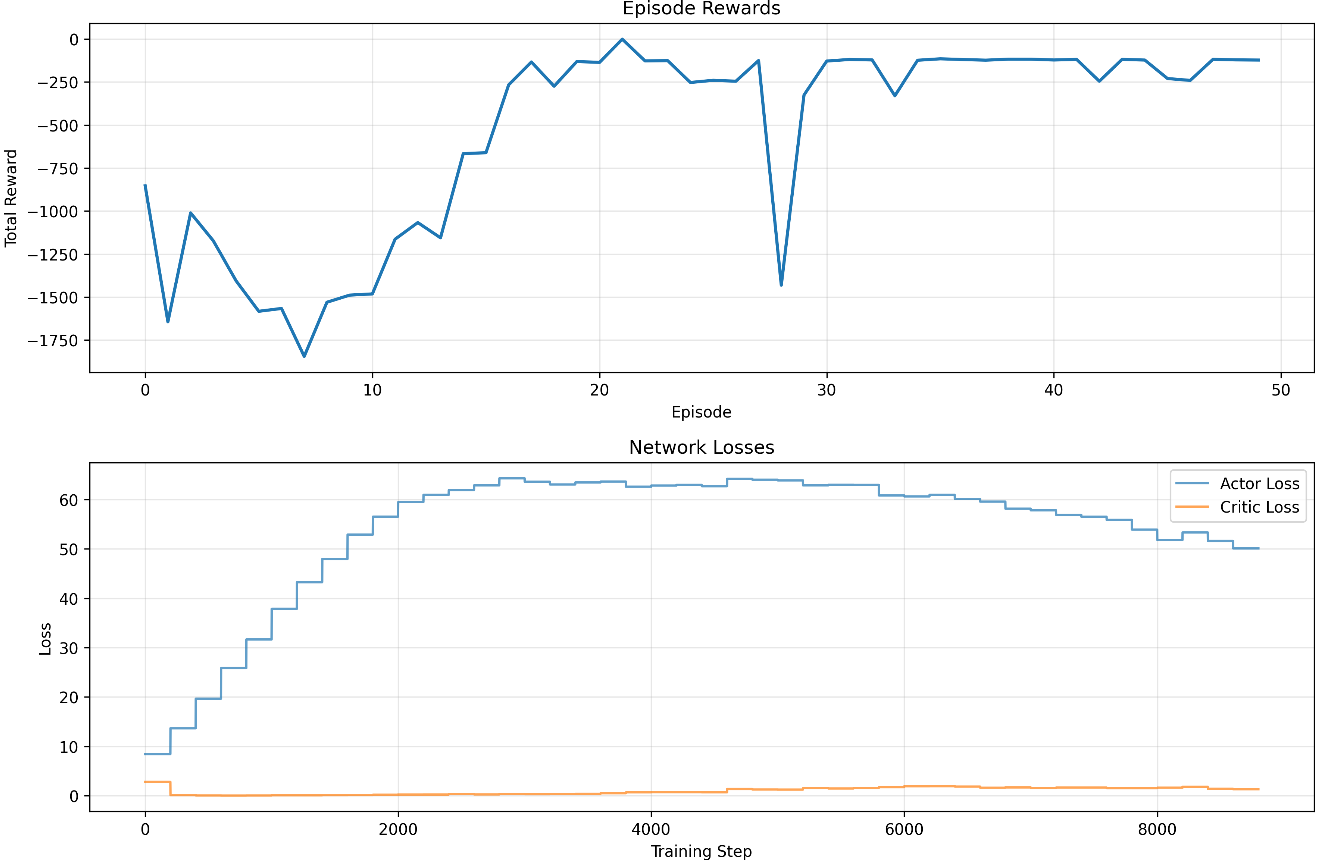
from stable_baselines3.common.callbacks import BaseCallbackclass SimpleTrainingCallback(BaseCallback):def __init__(self, verbose: int = 0):super().__init__(verbose)self.episode_rewards = [] # 每个episode的总奖励self.actor_losses = [] # Actor网络损失self.critic_losses = [] # Critic网络损失self.current_episode_reward = 0 # 当前episode累计奖励def _on_step(self) -> bool:# 累加当前episode的奖励self.current_episode_reward += self.locals['rewards'][0]# 记录网络损失(如果有)log_data = self.logger.name_to_valueif "train/actor_loss" in log_data:self.actor_losses.append(log_data["train/actor_loss"])if "train/critic_loss" in log_data:self.critic_losses.append(log_data["train/critic_loss"])# episode结束 记录总的奖励if self.locals.get('dones', [False])[0]:self.episode_rewards.append(self.current_episode_reward)self.current_episode_reward = 0return Truecallback = SimpleTrainingCallback()model = DDPG("MlpPolicy",env,action_noise=action_noise,verbose=1,learning_starts=1000,train_freq=(1, "episode"))并画出奖励和网络损失的折线图。发现 30 个 episode 后 reward就比较稳定。
5. 手搓 DDPG
1. 超参数设置上和原论文一致
import torch
# 训练相关
EPISODES = 100 # 总训练轮数
MAX_STEPS = 200 # 每轮最大步数
BATCH_SIZE = 64 # 批量采样大小
GAMMA = 0.99 # 折扣因子(未来奖励权重)# 网络更新相关
TAU = 0.005 # 目标网络软更新系数(tau越小更新越平滑)
LR_ACTOR = 1e-4 # 演员网络学习率
LR_CRITIC = 1e-3 # 评论员网络学习率# 经验回放
BUFFER_SIZE = 10000 # 经验缓冲区最大容量# 噪声探索
NOISE_SCALE = 0.1 # 高斯噪声强度(平衡探索与利用)
SEED = 42# 设备配置(自动识别GPU/CPU)
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"2. 经验回放 类似之前 dqn
from collections import deque
import randomclass ReplayBuffer:def __init__(self, buffer_size):self.buffer = deque(maxlen=buffer_size) # 固定容量,超容自动丢弃旧数据def add(self, s, a, r, s_next, done):self.buffer.append((s, a, r, s_next, done))def sample_batch(self, batch_size):"""随机采样批量经验"""if len(self.buffer) < batch_size:return None # 样本不足时返回Nonereturn random.sample(self.buffer, batch_size)def __len__(self):return len(self.buffer)3. net 的隐藏层维度均为 400、300
Actor 网络,输出动作值:输出值先用 激活函数 tanh 放缩到 [-1,1]
再乘以 action_bound 到 [-2,2];对输出层进行 [ -3e-3, 3e-3 ] 的初始化。
class Actor(nn.Module):def __init__(self, state_dim, action_dim, action_bound):super(Actor, self).__init__()self.action_bound = action_bound# 网络结构self.fc1 = nn.Linear(state_dim, 400)self.fc2 = nn.Linear(400, 300)self.fc3 = nn.Linear(300, action_dim)# 正交初始化nn.init.orthogonal_(self.fc1.weight, gain=nn.init.calculate_gain('relu'))nn.init.constant_(self.fc1.bias, 0.0)nn.init.orthogonal_(self.fc2.weight, gain=nn.init.calculate_gain('relu'))nn.init.constant_(self.fc2.bias, 0.0)# 输出层:小权重初始化,确保初始动作接近0nn.init.uniform_(self.fc3.weight, -3e-3, 3e-3)nn.init.uniform_(self.fc3.bias, -3e-3, 3e-3)def forward(self, x):x = torch.relu(self.fc1(x))x = torch.relu(self.fc2(x))x = torch.tanh(self.fc3(x)) # 放缩到[-1,1]return x * self.action_boundCritic 网络,输入(s,a) 输出打分值
class Critic(nn.Module):def __init__(self, state_dim, action_dim):super(Critic, self).__init__()# 网络结构self.fc1 = nn.Linear(state_dim + action_dim, 400)self.fc2 = nn.Linear(400, 300)self.fc3 = nn.Linear(300, 1)# 正交初始化nn.init.orthogonal_(self.fc1.weight, gain=nn.init.calculate_gain('relu'))nn.init.constant_(self.fc1.bias, 0.0)nn.init.orthogonal_(self.fc2.weight, gain=nn.init.calculate_gain('relu'))nn.init.constant_(self.fc2.bias, 0.0)# 输出层:小权重初始化nn.init.uniform_(self.fc3.weight, -3e-3, 3e-3)nn.init.uniform_(self.fc3.bias, -3e-3, 3e-3)def forward(self, s, a):x = torch.cat([s, a], dim=1)x = torch.relu(self.fc1(x))x = torch.relu(self.fc2(x))return self.fc3(x)4. 主函数为了可复现性,设定随机种子。
包含训练 + reward&网络损失可视化 + 参数保存 + 参数导入测试。
import randomdef set_seed(seed=42):"""设置所有随机种子以确保结果可重复"""# Python随机种子random.seed(seed)# Numpy随机种子np.random.seed(seed)# PyTorch随机种子torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed) # 如果使用多GPU# PyTorch确定性设置torch.backends.cudnn.deterministic = Truetorch.backends.cudnn.benchmark = False5. DDPG 智能体
包含初始化、动作选择、更新、软更新
5.1 初始化 Actor & Critic 网络,经验回放,目标网络 = 主网络
class DDPGAgent:def __init__(self, state_dim, action_dim, action_bound):# 1. 初始化 Actorself.actor = Actor(state_dim, action_dim, action_bound).to(HyperParams.DEVICE)self.actor_target = Actor(state_dim, action_dim, action_bound).to(HyperParams.DEVICE)self.actor_optim = optim.Adam(self.actor.parameters(), lr=HyperParams.LR_ACTOR)# 2. 初始化 Criticself.critic = Critic(state_dim, action_dim).to(HyperParams.DEVICE)self.critic_target = Critic(state_dim, action_dim).to(HyperParams.DEVICE)self.critic_optim = optim.Adam(self.critic.parameters(), lr=HyperParams.LR_CRITIC)# 3. 初始化经验回放缓冲区self.replay_buffer = ReplayBuffer(HyperParams.BUFFER_SIZE)# 4. 目标网络参数初始化self.soft_update(tau=1.0) # 初始化目标网络等于主网络self.actor_losses = []self.critic_losses = []5.2 软更新目标网络
def soft_update(self, tau=HyperParams.TAU):"""软更新目标网络:target = tau*main + (1-tau)*target"""# Actor 网络软更新for main_param, target_param in zip(self.actor.parameters(), self.actor_target.parameters()):target_param.data.copy_(tau * main_param.data + (1 - tau) * target_param.data)# Critic 网络软更新for main_param, target_param in zip(self.critic.parameters(), self.critic_target.parameters()):target_param.data.copy_(tau * main_param.data + (1 - tau) * target_param.data)5.3 s->a 不进行梯度更新,先转为 eval 评估模式 + with torch.no_grad();
training 模式则引入高斯噪声并裁剪到动作边界
def select_action(self, s, is_training=True):"""选择动作:训练时加噪声探索,测试时纯策略输出"""s_tensor = torch.FloatTensor(s).unsqueeze(0).to(HyperParams.DEVICE)self.actor.eval() # 评估模式with torch.no_grad():action = self.actor(s_tensor).cpu().numpy()[0] # 输出动作self.actor.train() # 恢复训练模式# 训练时添加高斯噪声(探索),并裁剪到动作边界if is_training:noise = np.random.normal(0, HyperParams.NOISE_SCALE, size=action.shape)action = np.clip(action + noise, -action_bound, action_bound)return action5.4 取一个 batch 网络更新
使用 TD 更新 Critic 网络;a' q' 分别由 目标动作网络 和 目标价值网络得到。
def update(self):"""从经验缓冲区采样并训练网络"""# 采样批量经验(样本不足时跳过)batch = self.replay_buffer.sample_batch(HyperParams.BATCH_SIZE)if batch is None:return# 转换批量数据为tensor(适配网络输入)s, a, r, s_next, done = (torch.FloatTensor(np.array(elem)).to(HyperParams.DEVICE) for elem in zip(*batch))r, done = r.unsqueeze(1), done.unsqueeze(1)# -------------------------- 训练critic网络 --------------------------# 计算目标Q值:r + gamma*(1-done)*Q_target(s_next, a_next)a_next = self.actor_target(s_next) # 目标演员输出-next动作q_target = r + HyperParams.GAMMA * (1 - done) * self.critic_target(s_next, a_next)# 计算预测Q值q_pred = self.critic(s, a)# 最小化MSE损失critic_loss = nn.MSELoss()(q_pred, q_target.detach()) # detach冻结目标网络self.critic_losses.append(critic_loss.item())self.critic_optim.zero_grad()critic_loss.backward()self.critic_optim.step()Actor 要使得 q(a) 尽量大,目标函数即为 -q(a)
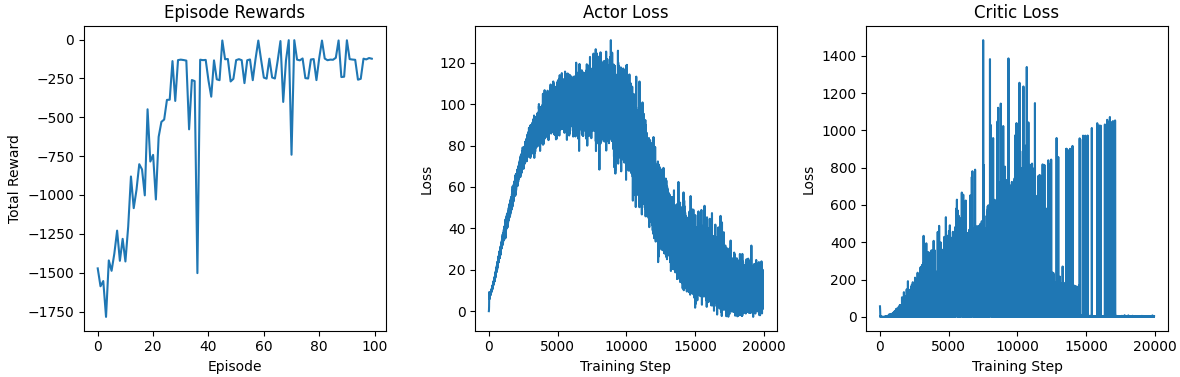
# -------------------------- 训练actor网络 --------------------------# 最大化Q值(策略梯度:通过负号转为梯度上升)actor_loss = -self.critic(s, self.actor(s)).mean()self.actor_losses.append(actor_loss.item())self.actor_optim.zero_grad()actor_loss.backward()self.actor_optim.step()# -------------------------- 软更新目标网络 --------------------------self.soft_update()进行 100 episode 的训练,reward 在 -150 上下: