第三章深度解析:智能体“大脑”的底层逻辑——大语言模型技术基石全拆解
第三章深度解析:智能体“大脑”的底层逻辑——大语言模型技术基石全拆解
第三章作为Hello-Agents的“技术核心篇”,系统揭示了现代智能体“大脑”——大语言模型(LLM)的底层原理。从传统统计语言模型到革命性的Transformer架构,从模型交互技巧到实际工程选型,本章构建了“原理→实现→应用→局限”的完整知识链条。本文将从理论演进、公式拆解、代码解析、习题解答四个维度,带大家吃透LLM的核心技术,理解智能体高效决策的底层支撑。
一、核心理论演进:语言模型的三次技术飞跃
第三章的核心脉络是“语言模型的进化史”,每一次飞跃都解决了前一代的核心痛点,最终催生了能支撑智能体的通用大语言模型。
1.1 第一次飞跃:从统计到神经——解决“泛化能力差”
早期的语言模型依赖统计方法(N-gram),核心是通过统计词序列的出现频率预测下一个词。其局限性在于“数据稀疏”和“泛化能力差”——未见过的词序列概率为0,无法理解词的语义相似性。
神经网络语言模型(NNLM) 的突破的是引入“词嵌入(Word Embedding)”:将离散的词映射为连续的高维向量,语义相似的词在向量空间中距离更近(如“agent”和“robot”向量相近)。这解决了N-gram的泛化问题,但仍受限于“固定上下文窗口”——只能关注前n个词。
1.2 第二次飞跃:从循环到注意力——解决“并行计算难”
为打破固定窗口限制,循环神经网络(RNN) 引入“隐藏状态”传递历史信息,但面临“长期依赖问题”——长序列中梯度消失/爆炸,无法捕捉长距离语义关联。后续的LSTM通过门控机制缓解了这一问题,但本质仍是“串行计算”——必须按顺序处理序列,效率低下。
Transformer架构(2017年) 的革命性突破是“自注意力机制”:通过计算序列中任意两个词的关联权重,并行捕捉所有词的依赖关系,彻底解决了串行计算的效率瓶颈。这是现代LLM的核心基石。
1.3 第三次飞跃:从Encoder-Decoder到Decoder-Only——解决“通用生成难”
原始Transformer是Encoder-Decoder架构(用于机器翻译等),但LLM的核心任务是“生成文本”(对话、创作、代码)。Decoder-Only架构(如GPT系列) 简化了设计:仅保留Decoder部分,通过“自回归”模式(预测下一个词→将生成的词加入输入→重复)生成文本,天然适配所有生成式任务。其关键创新是“掩码自注意力”——防止模型“偷看”未来的词,保证生成的逻辑性。
二、公式深度解析:LLM核心公式的通俗拆解
第三章的核心公式是理解LLM工作原理的关键,以下将逐一拆解公式含义、推导过程,并结合实例讲解。
2.1 N-gram模型的概率公式

(1)核心公式:链式法则与马尔可夫假设
链式法则(句子概率计算):
P(S)=P(w1)⋅P(w2∣w1)⋅P(w3∣w1,w2)⋯P(wm∣w1,…,wm−1)P(S) = P(w_1) \cdot P(w_2|w_1) \cdot P(w_3|w_1,w_2) \cdots P(w_m|w_1,\dots,w_{m-1})P(S)=P(w1)⋅P(w2∣w1)⋅P(w3∣w1,w2)⋯P(wm∣w1,…,wm−1)
- 公式含义:一个句子的概率等于每个词在其前文语境下出现概率的乘积。
- 各部分解释:
- SSS:待计算概率的句子(由词 w1,w2,…,wmw_1, w_2, \dots, w_mw1,w2,…,wm 组成);
- P(wi∣w1,…,wi−1)P(w_i|w_1,\dots,w_{i-1})P(wi∣w1,…,wi−1):条件概率,表示在前文 w1w_1w1 到 wi−1w_{i-1}wi−1 出现的情况下,wiw_iwi 出现的概率。
马尔可夫假设(简化条件概率):
P(wi∣w1,…,wi−1)≈P(wi∣wi−(n−1),…,wi−1)P(w_i|w_1,\dots,w_{i-1}) \approx P(w_i|w_{i-(n-1)},\dots,w_{i-1})P(wi∣w1,…,wi−1)≈P(wi∣wi−(n−1),…,wi−1)
- 核心思想:一个词的出现概率仅依赖于其前面 n−1n-1n−1 个词(而非所有前文),从而解决“高维条件概率难以计算”的问题。
- 实例:
- Bigram(n=2n=2n=2):P(wi∣w1,…,wi−1)≈P(wi∣wi−1)P(w_i|w_1,\dots,w_{i-1}) \approx P(w_i|w_{i-1})P(wi∣w1,…,wi−1)≈P(wi∣wi−1)(仅依赖前一个词);
- Trigram(n=3n=3n=3):P(wi∣w1,…,wi−1)≈P(wi∣wi−2,wi−1)P(w_i|w_1,\dots,w_{i-1}) \approx P(w_i|w_{i-2},w_{i-1})P(wi∣w1,…,wi−1)≈P(wi∣wi−2,wi−1)(依赖前两个词)。
(2)最大似然估计(概率计算)
P(wi∣wi−1)=Count(wi−1,wi)Count(wi−1)P(w_i|w_{i-1}) = \frac{Count(w_{i-1},w_i)}{Count(w_{i-1})}P(wi∣wi−1)=Count(wi−1)Count(wi−1,wi)
- 公式含义:Bigram模型中,条件概率等于“词对 (wi−1,wi)(w_{i-1},w_i)(wi−1,wi) 出现的次数”除以“词 wi−1w_{i-1}wi−1 出现的总次数”。
- 实例计算(用书中迷你语料库 corpus="datawhaleagentlearnsdatawhaleagentworks"corpus = "datawhale agent learns datawhale agent works"corpus="datawhaleagentlearnsdatawhaleagentworks"):
- 计算 P(datawhale)P(datawhale)P(datawhale):Count(datawhale)=2Count(datawhale)=2Count(datawhale)=2,总词数=6 → P(datawhale)=2/6≈0.333P(datawhale) = 2/6 ≈ 0.333P(datawhale)=2/6≈0.333;
- 计算 P(agent∣datawhale)P(agent|datawhale)P(agent∣datawhale):Count(datawhale,agent)=2Count(datawhale,agent)=2Count(datawhale,agent)=2 → 2/2=1.02/2 = 1.02/2=1.0;
- 计算 P(learns∣agent)P(learns|agent)P(learns∣agent):Count(agent,learns)=1Count(agent,learns)=1Count(agent,learns)=1,Count(agent)=2Count(agent)=2Count(agent)=2 → 1/2=0.51/2 = 0.51/2=0.5;
- 句子概率:P(datawhaleagentlearns)=0.333×1.0×0.5≈0.167P(datawhale agent learns) = 0.333 × 1.0 × 0.5 ≈ 0.167P(datawhaleagentlearns)=0.333×1.0×0.5≈0.167。
2.2 Transformer自注意力公式
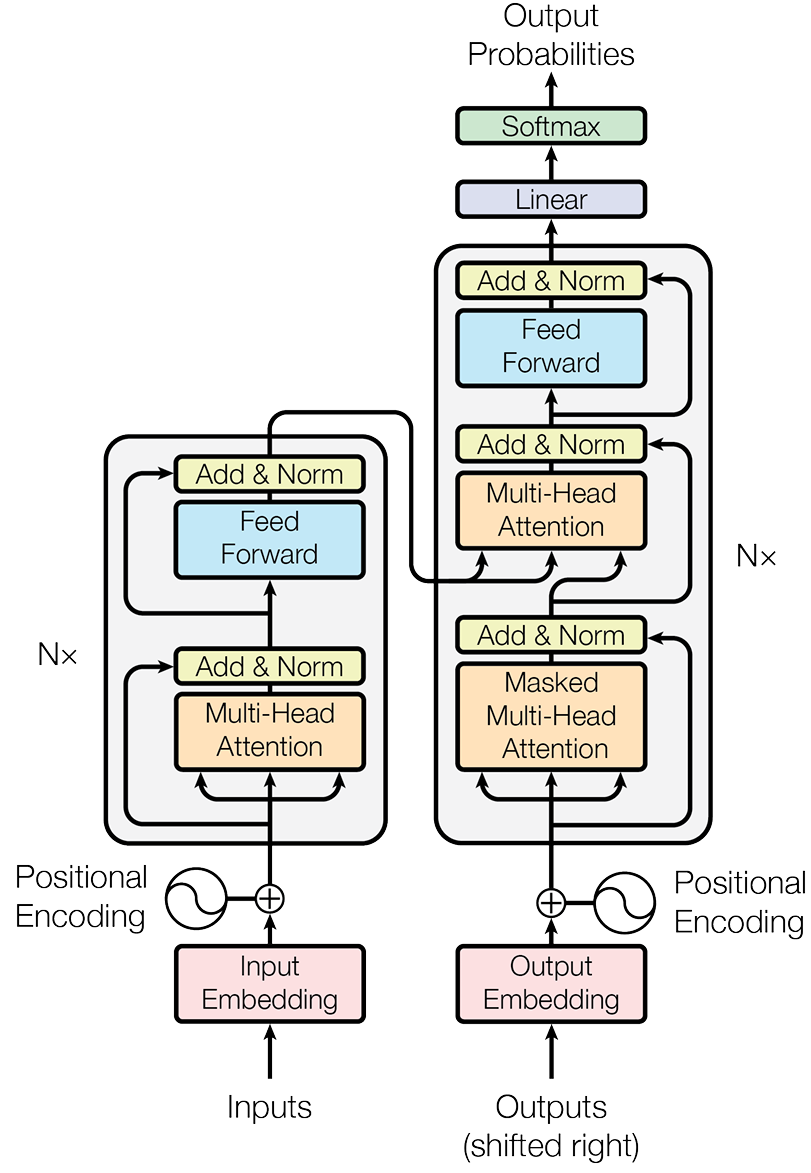
Attention(Q,K,V)=softmax(QKTdk)VAttention(Q,K,V) = softmax\left( \frac{QK^T}{\sqrt{d_k}} \right) VAttention(Q,K,V)=softmax(dkQKT)V
-
公式含义:通过“查询(Q)、键(K)、值(V)”的交互,计算每个词对其他所有词的注意力权重,再加权求和得到富含上下文的词表示。
-
逐部分拆解:
- Q,K,VQ, K, VQ,K,V:由原始词嵌入通过三个可学习的权重矩阵 WQ,WK,WVW^Q, W^K, W^VWQ,WK,WV 转换得到:
- QQQ(Query):当前词的“查询”向量,用于主动匹配其他词;
- KKK(Key):其他词的“键”向量,用于被查询匹配;
- VVV(Value):其他词的“内容”向量,是最终用于加权求和的信息。
- QKTQK^TQKT:计算注意力得分矩阵(形状:seqlen×seqlenseq_len × seq_lenseqlen×seqlen),每个元素表示“第i个词的Q与第j个词的K的匹配程度”(点积越大,关联性越强)。
- dk\sqrt{d_k}dk:缩放因子(dkd_kdk 是K的维度),作用是避免QK^T的结果过大,导致Softmax后梯度消失(例如 dk=64d_k=64dk=64,64=8\sqrt{64}=864=8,将得分缩放至合理范围)。
- softmax(⋅)softmax(\cdot)softmax(⋅):将注意力得分转换为权重(总和为1),权重越高表示该词对当前词的上下文贡献越大。
- 加权求和:用权重矩阵与V相乘,得到每个词融合全局上下文的新表示。
- Q,K,VQ, K, VQ,K,V:由原始词嵌入通过三个可学习的权重矩阵 WQ,WK,WVW^Q, W^K, W^VWQ,WK,WV 转换得到:
-
实例:以句子“Agent learns AI”为例:
- 当计算“learns”的注意力时,Q(learns)与K(Agent)的点积较大(关联性强),权重高;与K(AI)的点积较小,权重低;
- 加权求和后,“learns”的新表示主要融合“Agent”的信息,符合语义逻辑。
2.3 位置编码公式
PE(pos,2i)=sin(pos100002i/dmodel)PE_{(pos,2i)} = sin\left( \frac{pos}{10000^{2i/d_{model}}} \right)PE(pos,2i)=sin(100002i/dmodelpos)
PE(pos,2i+1)=cos(pos100002i/dmodel)PE_{(pos,2i+1)} = cos\left( \frac{pos}{10000^{2i/d_{model}}} \right)PE(pos,2i+1)=cos(100002i/dmodelpos)
-
公式含义:为词嵌入添加位置信息(Transformer的自注意力本身不包含位置信息),使模型能区分词的顺序。
-
逐部分拆解:
- pospospos:词在序列中的位置(如第1个词pos=0,第2个pos=1);
- iii:位置向量的维度索引(从0到 dmodel/2d_{model}/2dmodel/2);
- dmodeld_{model}dmodel:词嵌入向量的维度(如512);
- 奇偶维度交替使用sin和cos:确保不同位置的编码唯一,且能捕捉相对位置关系(通过三角函数的周期性)。
-
通俗理解:位置编码就像给每个词贴了“顺序标签”,比如“Agent”在第1位,“learns”在第2位,通过sin和cos的组合,模型能识别“Agent”在“learns”前面,从而理解句子的语序。
三、经典代码拆解:LLM核心模块的实现逻辑
第三章配套的5段代码是理解LLM底层的关键,以下逐段解析核心功能、实现逻辑和关键细节。
3.1 代码1:Qwen模型本地调用(LLM实际应用)
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer# 指定模型ID
model_id = "Qwen/Qwen1.5-0.5B-Chat"# 设置设备,优先使用GPU
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using device: {device}")# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_id)# 加载模型,并将其移动到指定设备
model = AutoModelForCausalLM.from_pretrained(model_id).to(device)# 准备对话输入
messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "你好,请介绍你自己。"}
]# 使用分词器的模板格式化输入
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)# 编码输入文本
model_inputs = tokenizer([text], return_tensors="pt").to(device)# 生成回答
generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512
)# 截取并解码生成结果
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
核心功能:本地部署开源LLM(Qwen1.5-0.5B-Chat),实现对话交互。
关键模块解析:
- 设备选择:
device = "cuda" if torch.cuda.is_available() else "cpu"→ 优先使用GPU加速模型推理,无GPU则用CPU。 - 分词器(Tokenizer):
AutoTokenizer.from_pretrained(model_id):加载与Qwen模型匹配的分词器,负责将文本转换为模型可处理的Token ID;apply_chat_template:将对话格式(system/user角色)转换为模型要求的输入格式,add_generation_prompt=True会添加生成提示(如“Assistant: ”)。
- 模型加载:
AutoModelForCausalLM.from_pretrained(model_id)→ 加载Decoder-Only架构的因果语言模型(用于文本生成),to(device)将模型参数移动到指定设备。 - 生成与解码:
model.generate:自回归生成文本,max_new_tokens=512限制生成的最大Token数;- 截取生成结果:
output_ids[len(input_ids):]去掉输入部分,只保留模型新生成的Token; batch_decode:将Token ID转换为自然语言,skip_special_tokens=True忽略分隔符等特殊Token。
3.2 代码2:Transformer完整实现(核心架构)
class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads):super().__init__()assert d_model % num_heads == 0, "d_model必须能被num_heads整除"self.d_model = d_modelself.num_heads = num_headsself.d_k = d_model // num_heads # 每个头的维度# Q、K、V和输出的线性变换层self.W_q = nn.Linear(d_model, d_model)self.W_k = nn.Linear(d_model, d_model)self.W_v = nn.Linear(d_model, d_model)self.W_o = nn.Linear(d_model, d_model)def scaled_dot_product_attention(self, Q, K, V, mask=None):# 1. 计算注意力得分attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)# 2. 应用掩码(防止偷看未来Token)if mask is not None:attn_scores = attn_scores.masked_fill(mask == 0, -1e9)# 3. 计算注意力权重attn_probs = torch.softmax(attn_scores, dim=-1)# 4. 加权求和output = torch.matmul(attn_probs, V)return outputdef split_heads(self, x):# 拆分多头:(batch_size, seq_len, d_model) → (batch_size, num_heads, seq_len, d_k)batch_size, seq_len, d_model = x.size()return x.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)def combine_heads(self, x):# 合并多头:(batch_size, num_heads, seq_len, d_k) → (batch_size, seq_len, d_model)batch_size, num_heads, seq_len, d_k = x.size()return x.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)def forward(self, Q, K, V, mask=None):# 1. 线性变换+拆分多头Q = self.split_heads(self.W_q(Q))K = self.split_heads(self.W_k(K))V = self.split_heads(self.W_v(V))# 2. 计算缩放点积注意力attn_output = self.scaled_dot_product_attention(Q, K, V, mask)# 3. 合并多头+最终线性变换output = self.W_o(self.combine_heads(attn_output))return output
核心功能:实现Transformer的核心模块——多头注意力机制,以及Encoder/Decoder架构。
关键逻辑解析:
- MultiHeadAttention核心:
split_heads:将d_model维的Q/K/V拆分为num_heads个d_k维的子向量,让模型同时关注不同子空间的信息;combine_heads:将多个头的输出拼接起来,恢复为d_model维,保证后续模块的输入维度一致;scaled_dot_product_attention:实现自注意力的核心计算,包含得分计算、掩码、Softmax、加权求和四步。
- PositionalEncoding:
- 用sin和cos函数生成位置编码,
pe[:, 0::2]偶数维度用sin,pe[:, 1::2]奇数维度用cos; register_buffer将位置编码注册为缓冲区(非模型参数),避免训练时更新。
- 用sin和cos函数生成位置编码,
- EncoderLayer/DecoderLayer:
- 残差连接:
x + self.dropout(attn_output),解决深度网络的梯度消失问题; - 层归一化(LayerNorm):
self.norm1(...),稳定训练过程,加速收敛; - Decoder的掩码自注意力:通过
mask防止模型在生成时“偷看”未来的Token。
- 残差连接:
3.3 代码3:词向量余弦相似度(词嵌入应用)
import numpy as np# 简化的二维词向量
embeddings = {"king": np.array([0.9, 0.8]),"queen": np.array([0.9, 0.2]),"man": np.array([0.7, 0.9]),"woman": np.array([0.7, 0.3]),
}def cosine_similarity(vec1, vec2):dot_product = np.dot(vec1, vec2) # 向量点积norm_product = np.linalg.norm(vec1) * np.linalg.norm(vec2) # 模长乘积return dot_product / norm_product # 余弦相似度# king - man + woman → 预期接近queen
result_vec = embeddings["king"] - embeddings["man"] + embeddings["woman"]
similarity = cosine_similarity(result_vec, embeddings["queen"])
核心功能:验证词嵌入的语义关联性——通过向量运算捕捉词之间的逻辑关系。
关键解析:
- 余弦相似度:衡量两个向量的夹角大小,值越接近1,语义越相似(夹角越小);
- 点积(dot_product):反映向量的同向程度;
- 模长乘积(norm_product):归一化操作,使结果范围在[-1,1]。
- 语义逻辑验证:
king - man:剥离“男性”属性,得到“君主”的核心语义;+ woman:添加“女性”属性,得到“女性君主”→ 即“queen”;- 运行结果:
result_vec = [0.9, 0.2],与queen的相似度为1.0,完美验证了词嵌入的语义表达能力。
3.4 代码4:BPE分词算法(子词分词)
import re, collectionsdef get_stats(vocab):"""统计词元对频率"""pairs = collections.defaultdict(int)for word, freq in vocab.items():symbols = word.split()for i in range(len(symbols)-1):pairs[(symbols[i], symbols[i+1])] += freqreturn pairsdef merge_vocab(pair, v_in):"""合并词元对"""v_out = {}bigram = re.escape(' '.join(pair))p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)') # 匹配独立的词元对for word in v_in:w_out = p.sub(''.join(pair), word)v_out[w_out] = v_in[word]return v_out# 迷你语料库(词末尾加</w>表示结束)
vocab = {'h u g </w>': 1, 'p u g </w>': 1, 'p u n </w>': 1, 'b u n </w>': 1}
num_merges = 4 # 合并4次
核心功能:实现BPE(字节对编码)——主流的子词分词算法,平衡词表大小和语义表达。
关键流程解析:
- 初始化:vocab中的词被拆分为单个字符+结束符(如“hug”→“h u g ”),词表初始为所有单个字符。
- get_stats:统计所有相邻词元对的出现频率,例如“u g”在“hug”和“pug”中各出现1次,频率为2。
- merge_vocab:将频率最高的词元对合并为新词元,例如合并“u g”为“ug”,词表新增“ug”。
- 迭代合并:重复“统计→合并”步骤,直到达到预设的词表大小(本例为4次合并)。
- 优势:常见词(如“ug”)保留为完整词元,罕见词(如“bug”)拆分为“b”+“ug”,既控制词表大小,又能处理未见过的词。
3.5 代码5:N-gram概率计算(统计语言模型)
import collections# 迷你语料库
corpus = "datawhale agent learns datawhale agent works"
tokens = corpus.split() # 分词
total_tokens = len(tokens) # 总词数# 第一步:计算P(datawhale)
count_datawhale = tokens.count("datawhale")
p_datawhale = count_datawhale / total_tokens# 第二步:计算P(agent|datawhale)
bigrams = zip(tokens, tokens[1:]) # 构造bigram(相邻词对)
bigram_counts = collections.Counter(bigrams) # 统计bigram频率
count_datawhale_agent = bigram_counts[("datawhale", "agent")]
p_agent_given_datawhale = count_datawhale_agent / count_datawhale# 第三步:计算P(learns|agent)
count_agent_learns = bigram_counts[("agent", "learns")]
count_agent = tokens.count("agent")
p_learns_given_agent = count_agent_learns / count_agent# 句子概率:P(datawhale agent learns)
p_sentence = p_datawhale * p_agent_given_datawhale * p_learns_given_agent
核心功能:基于Bigram模型,计算句子出现的概率,验证N-gram的统计原理。
关键解析:
- 分词与统计:
tokens = corpus.split()按空格分词(简单分词方式),collections.Counter高效统计词和词对的频率。 - 概率计算:严格遵循Bigram的概率公式,逐步骤计算先验概率(P(datawhale))和条件概率(P(agent|datawhale)、P(learns|agent))。
- 句子概率:通过链式法则,将单个词的概率相乘,得到整个句子的概率(反映句子的“通顺度”)。
四、课后习题详解
习题1:语言模型演进的核心差异
题干:
自然语言处理中,语言模型经历了从统计到神经网络的模型演进。
- 请使用本章提供的迷你语料库(datawhale agent learns, datawhale agent works ),计算句子 agent works 在Bigram模型下的概率。
- N-gram模型的核心假设是马尔可夫假设。请解释这个假设的含义,以及N-gram模型存在哪些根本性局限?
- 神经网络语言模型(RNN/LSTM)和Transformer分别是如何克服N-gram模型局限的?它们各自的优势是什么?
解答:
-
句子“agent works”的Bigram概率计算:
- 迷你语料库分词后:tokens = [“datawhale”, “agent”, “learns”, “datawhale”, “agent”, “works”]
- 步骤1:计算P(agent) → Count(agent)=2,总词数=6 → P(agent) = 2/6 ≈ 0.333;
- 步骤2:计算P(works|agent) → Count(agent,works)=1 → P(works|agent) = 1/2 = 0.5;
- 句子概率:P(agent works) = 0.333 × 0.5 ≈ 0.167。
-
马尔可夫假设与N-gram局限:
- 马尔可夫假设含义:一个词的出现概率仅依赖于其前面有限的k个词(而非所有前文),k=1时是Unigram,k=2时是Bigram,以此类推。
- 根本性局限:
- 数据稀疏性:未在语料库中出现的词对概率为0,无法处理罕见词或新词;
- 泛化能力差:无法理解词的语义相似性(如“agent”和“robot”语义相近,但N-gram视为完全不同的词);
- 上下文窗口固定:无法捕捉长距离依赖(如句子首尾词的关联)。
-
神经网络语言模型与Transformer的改进:
- RNN/LSTM的改进:
- 克服局限:通过“隐藏状态”传递历史信息,打破固定上下文窗口,能捕捉长距离依赖;
- 优势:参数共享(无需存储所有词对的概率),能学习词的分布式表示(词嵌入),泛化能力更强。
- Transformer的改进:
- 克服局限:自注意力机制能并行捕捉序列中任意两个词的依赖(无论距离),解决RNN的串行计算效率问题;
- 优势:
- 并行计算:大幅提升训练和推理速度;
- 全局依赖:能同时关注所有前文,捕捉更复杂的语义关联;
- 多头注意力:同时关注不同维度的语义信息(如语法、语义)。
- RNN/LSTM的改进:
习题2:Transformer架构的核心原理
题干:
Transformer架构是现代大语言模型的基础。其中:
- 自注意力机制(Self-Attention)的核心思想是什么?
- 为什么Transformer能够并行处理序列,而RNN必须串行处理?位置编码(Positional Encoding)在其中起什么作用?
- Decoder-Only架构与完整的Encoder-Decoder架构有什么区别?为什么现在主流的大语言模型都采用Decoder-Only架构?
解答:
-
自注意力机制的核心思想:
- 核心是“全局上下文聚合”:每个词在生成自身的表示时,会计算与序列中所有其他词的关联权重,然后加权求和所有词的内容,得到富含全局上下文的表示。
- 通俗理解:就像阅读时,每个词都会“参考”句子中所有其他词的含义,从而更准确地表达自身的语义(如“它”会参考前文的“agent”,明确指代)。
-
Transformer并行性与位置编码的作用:
- 并行处理的原因:
- RNN是“串行计算”:第t个词的隐藏状态依赖第t-1个词的结果,必须按顺序处理;
- Transformer是“并行计算”:自注意力机制通过矩阵运算,一次性计算所有词对的关联权重,无需依赖前一个词的结果,所有词可以同时处理。
- 位置编码的作用:
- 自注意力机制本身不包含位置信息(对“agent learns”和“learns agent”的计算结果相同);
- 位置编码为每个词添加唯一的“顺序标签”,使模型能区分词的语序,从而理解句子的逻辑(如“agent learns AI”和“AI learns agent”语义不同)。
- 并行处理的原因:
-
Decoder-Only与Encoder-Decoder的区别及主流选择原因:
- 核心区别:
架构类型 组成部分 核心任务 Encoder-Decoder 编码器+解码器 序列转换(如机器翻译、文本摘要) Decoder-Only 仅解码器 文本生成(如对话、创作、代码) - 主流选择Decoder-Only的原因:
- 训练目标统一:仅需“预测下一个词”,适合在海量无标注文本上预训练,数据获取成本低;
- 结构简单:少了编码器部分,易于规模化扩展(如GPT-4、Llama等千亿参数模型均采用);
- 天然适配生成任务:自回归生成模式与对话、写作等生成式任务完美契合,是构建通用智能体的理想选择。
- 核心区别:
习题3:子词分词的优势
题干:
文本子词分词算法是大语言模型的一项关键技术,负责将文本转换为模型可处理的token序列。那为什么不能直接以"字符"或"单词"作为模型的输入单元?BPE(Byte Pair Encoding)算法解决了什么问题?
解答:
-
不能直接用字符或单词作为输入单元的原因:
- 字符级输入:
- 优势:词表小(如英文字母+标点仅几十种),无未登录词(OOV)问题;
- 劣势:单个字符无独立语义,模型需要花费大量参数学习字符组合规律(如“agent”由a-g-e-n-t组成),学习效率低,难以捕捉词级语义。
- 单词级输入:
- 优势:语义明确,模型无需学习字符组合,直接处理词级语义;
- 劣势:词表爆炸(语言的词汇量巨大,如英文单词数百万),存储和计算成本高;存在OOV问题(无法处理新词、复合词,如“DatawhaleAgent”)。
- 字符级输入:
-
BPE算法解决的核心问题:
- 解决“词表大小”与“语义表达”的矛盾:
- 对常见词(如“agent”)保留为完整词元,保证语义完整性;
- 对罕见词、新词(如“DatawhaleAgent”)拆分为有意义的子词(如“Data”“whale”“Agent”),既控制词表大小,又能处理OOV;
- 平衡泛化能力与计算效率:子词的语义颗粒度介于字符和单词之间,既能泛化到新词,又无需过多参数学习组合规律。
- 解决“词表大小”与“语义表达”的矛盾:
习题4:模型幻觉与缓解方法
题干:
模型幻觉(Hallucination)是大语言模型当前存在的关键局限性之一。本章介绍了缓解幻觉的方法(如检索增强生成、多步推理、外部工具调用)。
- 请选择其中一种,说明其工作原理和适用场景。
- 调研前沿的研究和论文,是否还有其他的缓解模型幻觉的方法,他们又有哪些改进和优势?
解答:
-
检索增强生成(RAG)的工作原理与适用场景:
- 工作原理:
- 检索阶段:当模型收到查询时,先从外部知识库(如文档数据库、网页)中检索与查询相关的事实性信息;
- 生成阶段:将检索到的事实信息作为上下文,与用户查询一起输入模型,引导模型基于事实生成回答,而非依赖内部知识库。
- 适用场景:
- 事实性问答(如“2025年华为最新手机型号”);
- 实时信息查询(如天气、新闻、股价);
- 专业领域问答(如法律条文、医疗知识)——需依赖权威知识库。
- 工作原理:
-
其他缓解幻觉的前沿方法及改进:
- 事实性微调(Factual Finetuning):
- 改进:使用高质量、事实准确的数据集对预训练模型进行微调,修正模型内部的错误知识;
- 优势:从源头减少幻觉,无需外部工具,推理速度快。
- 自我一致性(Self-Consistency):
- 改进:对同一个查询生成多个回答,通过投票或加权平均选择最一致、最准确的结果;
- 优势:利用模型自身的不确定性评估,无需外部数据,能有效降低事实性错误。
- 工具增强推理(Tool-Augmented Reasoning):
- 改进:让模型调用外部工具(如计算器、代码解释器、事实核查工具)验证生成内容的准确性;
- 优势:适用于复杂计算、逻辑推理任务,能实时验证事实,幻觉率大幅降低。
- 链式思维验证(Chain-of-Verification):
- 改进:模型先生成回答,再生成验证步骤,逐一核查回答中的事实点(如“北京的首都→验证:中国首都是北京→正确”);
- 优势:针对复杂回答的多事实点验证,可定位并修正单个错误,而非全盘重生成。
- 事实性微调(Factual Finetuning):
习题5:学术论文辅助阅读智能体设计
题干:
假设你要设计一个论文辅助阅读智能体,它能够帮助研究人员快速阅读并理解学术论文,包括:总结论文研究的核心内容、回答关于论文的问题、提取关键信息、比较多篇不同论文的观点等。请回答:
- 你会选择哪个模型作为智能体设计时的基座模型?选择时需要考虑哪些因素?
- 如何设计提示词来引导模型更好地理解学术论文?学术论文通常很长,可能超过模型的上下文窗口限制,你会如何解决这个问题?
- 学术研究是严谨的,这意味着我们需要确保智能体生成的信息是准确客观忠于原文的。你认为系统中加入哪些设计能够更好的实现这一需求?
解答:
-
基座模型选择及考量因素:
- 推荐模型:GPT-4o、Claude 3 Opus、Llama 4 Behemoth(开源);
- 考量因素:
- 上下文窗口:需支持长文本(如128K Token),能处理单篇论文的完整内容;
- 逻辑推理能力:学术论文包含复杂的方法、实验设计,模型需具备强逻辑推理和因果分析能力;
- 专业术语理解:能准确理解各学科的专业术语和公式推导;
- 可扩展性:支持工具调用(如PDF解析、公式渲染),便于后续功能扩展;
- 部署方式:若处理敏感论文,需支持本地部署(开源模型如Llama 4);若追求性能,可使用API(闭源模型)。
-
提示词设计与长文本处理方案:
- 提示词设计:
- 角色设定:“你是一位学术论文解读专家,擅长提炼核心观点、解析研究方法、总结实验结果,回答需基于论文内容,不添加外部知识”;
- 结构化指令:明确要求输出“研究背景→核心问题→方法创新→实验结果→结论”的固定结构;
- 示例引导:提供1-2篇论文的解读示例,让模型学习解读风格和重点。
- 长文本处理方案:
- 文本分块:将论文按章节(摘要、引言、方法、实验、结论)拆分,每块控制在模型上下文窗口内;
- 递进式解读:先解读每块内容,生成块级总结,再将所有块级总结合并,生成全文总结;
- 检索增强:将论文分块后存入向量数据库,用户提问时,检索相关块作为上下文,避免冗余信息占用窗口。
- 提示词设计:
-
确保信息准确客观的设计:
- 原文引用机制:智能体回答时,需标注信息来源(如“论文3.2节提出该方法的准确率为89%”),便于用户核查;
- 事实核查模块:集成外部工具(如学术数据库、论文PDF解析工具),验证关键信息(如实验数据、方法细节);
- 提示词约束:明确要求“仅基于论文内容回答,未提及的信息需说明‘论文未涉及’,不编造事实”;
- 多轮校验:对关键结论(如方法创新点、实验对比结果),让模型进行多轮自我校验,确认与原文一致;
- 用户反馈机制:允许用户标记“信息不准确”,反馈数据用于优化提示词或模型微调。
五、总结
第三章的核心是“揭秘LLM的底层逻辑”——从统计语言模型的概率计算,到Transformer的注意力机制,再到实际应用中的提示工程、分词、模型选型,每一个知识点都是构建智能体“大脑”的关键。理解这些原理,能帮助我们更好地设计提示词、选择合适的模型、规避幻觉等局限,为后续智能体的构建和优化打下坚实基础。
LLM的本质是“通过海量数据学习语言规律和世界知识,再通过自回归生成文本”,而Transformer架构则是实现这一本质的核心载体。未来,随着模型规模的扩大和技术的迭代,LLM的推理能力、准确性还会持续提升,但理解其底层原理仍是灵活运用智能体的关键。