Java【缓存设计】定时任务+分布式锁实战:Redis vs Redisson实现状态自动扭转以及全量刷新预热机制

目录
1. 前言
插播一条消息~
2. 正文
2.1 缓存存在的价值与策略
2.2 定时任务实现状态扭转
2.2.1 Redis 原生命令 + Lua脚本实现分布式锁
2.2.2 Redisson框架实现高级分布式锁
2.3 RabbitMQ异步解耦:全局缓存更新策略
2.4 全量刷新缓存预热机制
3. 小结
1. 前言
现代租房系统动辄百万房源、千万用户,每天面临着海量的查询请求(如条件筛选、价格区间统计)和频繁的状态变更(如出租到期、用户信息更新)。如果每次请求都直接打到数据库,不仅响应慢,还极易引发DB瓶颈甚至宕机。
为此,我们必须引入缓存层——Redis作为工业级分布式缓存中间件,凭借其高性能、丰富数据结构、原子操作与持久化能力,成为我们的首选。但“用Redis并不等于正确使用Redis”。如何规避典型陷阱?如何保证缓存与数据库的一致性?如何在多节点部署下安全执行定时任务?这些问题才是真正的挑战。
本文将基于真实的租房系统场景,带你彻底解决这类问题。我们会重点剖析:
- 如何用定时任务批量处理状态扭转
- 在分布式环境下如何用分布式锁避免重复执行
- Redis原生方案 vs Redisson框架的优劣对比
Feast不止于理论,我会手把手带你写出生产可用的代码,并分享实际开发中的坑点应对方案。
插播一条消息~
🔍十年经验淬炼 · 系统化AI学习平台推荐
系统化学习AI平台![]() https://www.captainbed.cn/scy/
https://www.captainbed.cn/scy/
- 📚 完整知识体系:从数学基础 → 工业级项目(人脸识别/自动驾驶/GANs),内容由浅入深
- 💻 实战为王:每小节配套可运行代码案例(提供完整源码)
- 🎯 零基础友好:用生活案例讲解算法,无需担心数学/编程基础
🚀 特别适合
- 想系统补强AI知识的开发者
- 转型人工智能领域的从业者
- 需要项目经验的学生
2. 正文
2.1 缓存存在的价值与策略
在深入定时任务之前,我们先快速回顾下缓存的核心知识,这对理解整体架构很重要。
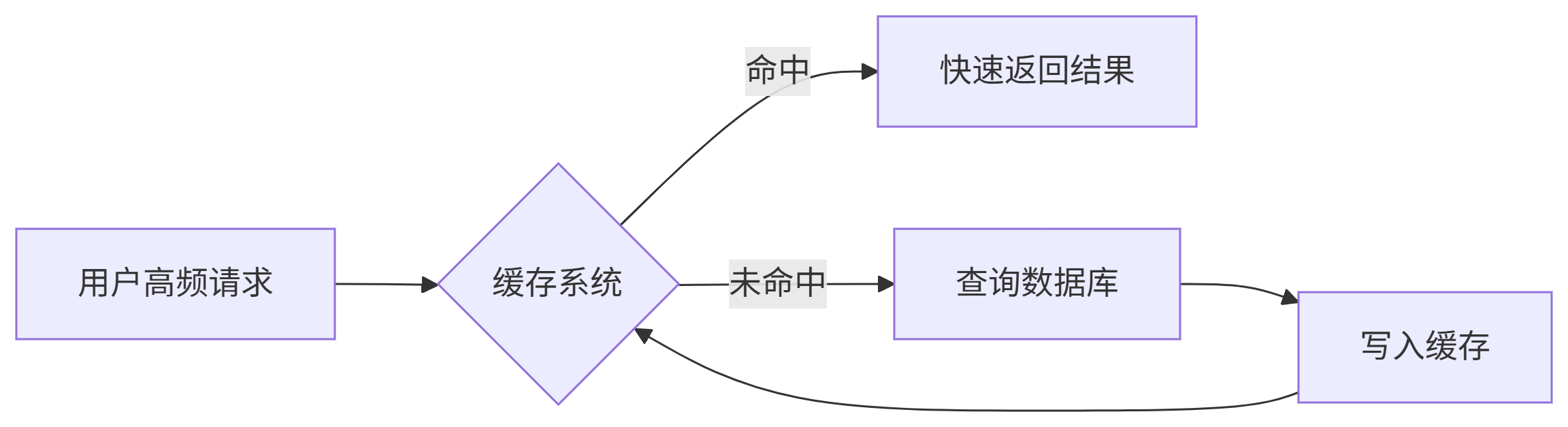
缓存策略三大核心
- 读取缓存:先查缓存,命中则返回,未命中查DB并回写缓存
- 写入缓存:更新DB后,删除或更新对应缓存(怕大家凌乱,具体可以看下文)
- 失效策略:给缓存设置合理的过期时间,避免永久存储脏数据
缓存数据类型
- 热点数据:用户信息、配置信息等高频访问数据
- 复杂查询结果:如价格区间统计、多表关联查询结果
- 会话信息:用户登录Token、个性化设置等
缓存架构选择
对于分布式系统,我们选择Redis分布式缓存,主要原因:
- 跨服务共享数据
- 高性能读写能力
- 丰富的数据结构支持
- 持久化与高可用保障
数据一致性保障
Redis作为缓存,MySQL作为持久化存储,我们需要保障两者数据的一致性,常用策略:
| 策略 | 优点 | 缺点 | 适用场景 |
| 先更新DB,后删除缓存 | 简单、高效 | 可能短暂不一致 | 读多写少场景 |
| 先删除缓存,后更新DB | 减少不一致时间 | 删除后更新前可能有脏数据 | 写多读少场景 |
| 异步同步 | 性能最好 | 实现复杂,可能丢失数据 | 最终一致性要求场景 |
缓存加载策略
- 全量加载:启动时加载所有数据,适合数据量小场景(就是这个例子😁)
- 增量加载:按需加载,节省内存但首次访问慢
- 定时加载:定期刷新,适合数据变更不频繁场景
缓存高并发三大经典问题
这是面试官最爱问的问题,也是线上事故的高发地带。我们逐个击破:
| 问题 | 定义 | 缓解措施 |
| 缓存穿透 | 查询不存在的数据(既无缓存也无DB),导致大量请求直达DB | 1. 对空结果也缓存(带短TTL) |
| 缓存击穿 | 热点Key到期瞬间大量并发读,均未命中缓存 | 互斥锁(mutex lock):仅一个线程查DB并回填,其余阻塞或降级 |
| 缓存雪崩 | 大片缓存Key同时过期(或Redis宕机),瞬间涌入巨大流量冲垮DB | 1. 设置随机TTL避免集体失效 |
现在我们对缓存有了基本认知,接下来进入正题:如何用定时任务+分布式锁解决房源状态同步问题。
2.2 定时任务实现状态扭转
背景说明
租房系统中,房源有三种核心状态:
- 可出租(UP)
- 已出租(RENTING)
- 已下线(DOWN)
房东签署租赁合约后,房源状态变为【出租中】(RENTING)。合约到期时间明确(例:2025-06-01 00:00:00),系统需在该时刻后将其自动改为【待上线】(UP),释放给新租客。
但不能让前端或管理员手动改!原因如下:
- 租赁合同可能几千条并发结束;
- 时间精确性要求高(零点整切换);
- 若忘记操作会导致房源长期挂失无法上架;
所以——引入每日凌晨批量校验 + 更正状态是刚需动作。
业务代码实现
先看基础版的业务逻辑代码,后面我们再给这个代码加"分布式锁"的保护壳:
// 查询全部已出租房源
List<HouseStatus> rentHouseStatusList = houseStatusMapper.selectList(new LambdaQueryWrapper<HouseStatus>().eq(HouseStatus::getStatus, HouseStatusEnum.RENTING.name())
);// 过滤需要扭转状态的房源列表(出租到期时间)
List<HouseStatus> needChangeHouseStatusList = rentHouseStatusList.stream().filter(houseStatus -> null != houseStatus.getRentEndTime()&& 0 > TimestampUtil.calculateDifferenceMillis(TimestampUtil.getCurrentSeconds(), houseStatus.getRentEndTime())).collect(Collectors.toList());// 批量更新房源状态
for (HouseStatus housestatus:needChangeHouseStatusList) {HouseStatusEditReqDTO houseStatusEditReqDTO = new HouseStatusEditReqDTO();housestatus.setHouseId(housestatus.getHouseId());houseStatusEditReqDTO.setStatus(HouseStatusEnum.UP.name());editStatus(houseStatusEditReqDTO);
}这段代码在单机环境下运行没问题,但在分布式部署时就会出现重复执行的问题。
假设我们部署了3个实例,那么零点时分:
- 实例1执行任务,更新了100条房源状态
- 实例2执行同样任务,又更新了相同的100条房源
- 实例3也执行了相同任务...
这不仅浪费资源,更可能导致业务逻辑错误!
解决方案:分布式锁
我们需要一种机制确保同一时间只有一个实例能执行任务,这就是分布式锁的核心价值。
下面我们分别用两种方式实现分布式锁。
2.2.1 Redis 原生命令 + Lua脚本实现分布式锁
这是最经典的实现方式。优势在于无外部依赖升级成本低,劣势为需自行处理超时续期和死锁检测逻辑。
完整实现代码
// 定时任务实现扭转房源状态
// 每日零点开始执行定时任务
@Scheduled(cron = "0 0 0 * * ?")
public void scheduledHouseStatus(){log.info("开始执行房源状态扭转任务");// 加redis分布式锁,锁的value来判断所是否为当前线程所有String value = UUID.randomUUID().toString();try {Boolean lock = redisService.setCacheObjectIfAbsent(LOCK_KEY, value, 180L, TimeUnit.SECONDS);if(Boolean.TRUE.equals( lock)){// 业务代码(上面2.2节的代码)doHouseStatusChangeBusiness();}else{// 获取锁失败,跳过执行log.info("定时任务被其他实例执行");}} finally {// 解锁,只能解锁自己redisService.cad(LOCK_KEY, value);}
}关键方法解析
加锁方法:使用Redis的SETNX命令(SET if Not exists)
/*** 缓存String数据,如果该键不存在则存储,并设置数据有效时间,若已存在则不存储。** @param key 缓存的键值* @param value 缓存的值* @param timeout 时间* @param timeUnit 时间单位* @param <T> 对象类型* @return 是否缓存了对象 如果key已经存在,则返回false,否则返回true*/
public <T> Boolean setCacheObjectIfAbsent(final String key, final T value, final long timeout, final TimeUnit timeUnit) {return redisTemplate.opsForValue().setIfAbsent(key, value, timeout, timeUnit);
}解锁方法:使用Lua脚本保证原子性
/*** 删除指定值对应的 Redis 中的键值(compare and delete)** @param key 缓存key* @param value value* @return 是否完成了比较并删除*/
public boolean cad(String key, String value) {if (key.contains(StringUtils.SPACE) || value.contains(StringUtils.SPACE)) {return false;}String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";// 通过lua脚本原子验证令牌和删除令牌Long result = (Long) redisTemplate.execute(new DefaultRedisScript<>(script, Long.class),Collections.singletonList(key),value);return !Objects.equals(result, 0L);
}为什么需要Lua脚本?
简单用get+del两步操作不是原子性的,期间可能发生:
- 实例A检查value匹配,准备执行del
- 锁过期,实例B获得了锁
- 实例A执行del,误删了实例B的锁
Lua脚本保证判断和删除在同一次原子操作中完成。
2.2.2 Redisson框架实现高级分布式锁
为什么选择Redisson?
虽然Redis原生方案能 work,但需要考虑太多细节:
- 锁过期时间设置多少合适?
- 如何处理锁续期问题?
- 怎样避免误删其他实例的锁?
相比手动封装Lua,使用成熟的第三方库无疑开发效率更高,并天然提供watch-dog自动续期、公平锁/红锁选举算法等能力。
Redisson帮我们封装了这些复杂性,提供了更健壮的分布式锁实现。
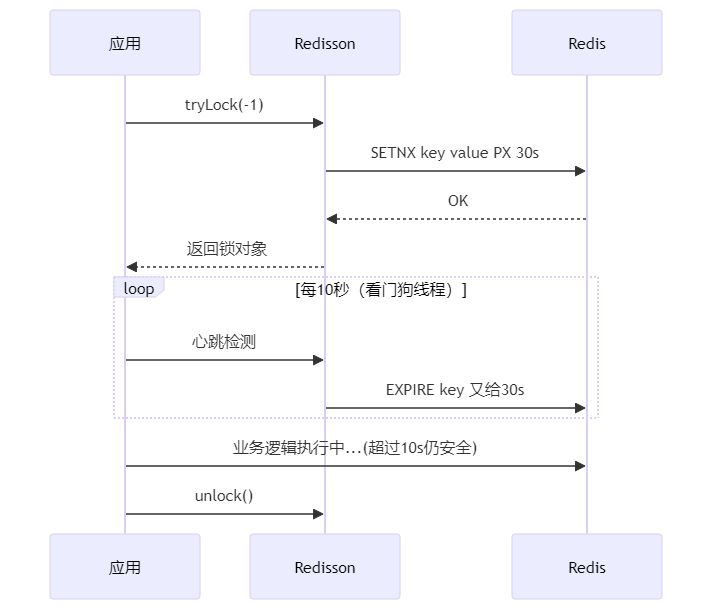
完整实现代码
@Scheduled(cron = "0 0 0 * * ?")
public void scheduledHouseStatus2(){log.info("开始执行房源状态扭转任务");// 加redisson分布式锁RLock lock = redissonLockService.acquire(LOCK_KEY, -1);if(null == lock){log.info("定时任务被其他实例执行");return;}try {// 业务代码doHouseStatusChangeBusiness();} finally {if(lock.isLocked() && lock.isHeldByCurrentThread()){redissonLockService.releaseLock(lock);}}
}Redisson锁服务封装
@Slf4j
@RequiredArgsConstructor
public class RedissonLockService {/*** redis操作客户端*/private final RedissonClient redissonClient;/*** 获取锁** @param lockKey 锁的key,唯一标识,建议模块名+唯一键* @param expire 超时时间,单位毫秒,传入-1自动续期* @return 获取到的RLock实例,为null则获取失败*/public RLock acquire(String lockKey, long expire) {try {final RLock lockInstance = redissonClient.getLock(lockKey);// 注意:如果tryLock指定了leaseTime>0就不会续期。参考 RedissonLock类的tryAcquireAsync方法的实现lockInstance.lock(expire, TimeUnit.MILLISECONDS);return lockInstance;} catch (Exception e) {return null;}}/*** 释放锁。注意:必须和获取锁在一个线程中** @param lockInstance 锁的实例,acquire返回的* @return 释放成功返回true,否则返回false*/public boolean releaseLock(RLock lockInstance) {if (lockInstance.isHeldByCurrentThread()) {lockInstance.unlock();return true;}return false;}
}两种方案对比
| 特性 | Redis原生实现 | Redisson实现 |
| 实现复杂度 | 高,需自己处理各种边界情况 | 低,API简单易用 |
| 锁续期 | 需手动实现 | 内置看门狗自动续期 |
| 可重入性 | 需手动实现 | 内置支持 |
| 公平锁 | 不支持 | 支持 |
| 性能 | 略高(无额外开销) | 略低(有额外功能开销) |
| 可靠性 | 依赖自己实现细节 | 久经生产环境考验 |
生产环境建议:除非有极致性能要求,否则推荐使用Redisson
2.3 RabbitMQ异步解耦:全局缓存更新策略
前面提到的是被动定期轮询修正状态的做法,然而现实中很多变化其实是由其他事件主动驱动发生的 —— 如房东上传新版身份证扫描件(认证级别提高) ⇒ 展示徽章样式改变;亦或者用户停用了某个优惠券模板 ⇒ 旗下已发布的房源应同步关闭特惠标……
这些变更并非周期规律发生,也不能等到第二天凌晨统一处理。于是我们借助事件驱动思维,通过发布订阅模式将跨模块间的耦合解开,实现高效灵活的消息通知机制。
这里使用RabbitMQ实现异步解耦:
@Component
@Slf4j
@RabbitListener(bindings = {@QueueBinding(value = @Queue,exchange = @Exchange(value = RabbitConfig.EXCHANGE_NAME, type = ExchangeTypes.FANOUT))
})
public class EditAppUserMessageReceiver {@Autowiredprivate IHouseService houseService;@RabbitHandlerpublic void process(AppUserDTO appUserDTO){if(null == appUserDTO || null == appUserDTO.getUserId()){log.error("用户信息为空");return;}log.info("MQ成功收到消息,message:{}", JsonUtil.obj2String(appUserDTO));try {List<Long> houseIds = houseService.listByUserId(appUserDTO.getUserId());for (Long houseId : houseIds){houseService.cacheHouse(houseId);}} catch (Exception e) {log.error("处理用户更新时,更新房源缓存异常,appUserDTO:{}",JsonUtil.obj2String(appUserDTO), e);}}
}关键设计要点:
- 使用发布/订阅模式(Fanout Exchange):一个用户消息需要被多个服务消费
- 异步处理:避免同步调用阻塞主流程
- 异常处理:保证消息消费的可靠性
2.4 全量刷新缓存预热机制
有时候我们会遇见这种情况:
- 新机房裁撤上线后首次查询极其缓慢?
- 系统重启导致缓存全部清空前端访问出现短暂瘫痪?
上述就是典型的“缓存完全miss冷启动”效应,尤其对搜索筛选类接口打击巨大。为了避免首波冲击压垮DB集群,我们必须建立全量Warmup Preload Script在服务上线前提前准备好关键路径上的热点数据。
最后我们看下如何做全量缓存刷新,这是在系统启动或数据大规模变更时使用的策略:
public void refreshHouseIds() {// 查询全量城市列表(2级城市)List<SysRegion> sysRegions = regionMapper.selectList(new LambdaQueryWrapper<SysRegion>().eq(SysRegion::getLevel, 2));for(SysRegion sysRegion: sysRegions){// 删除当前城市下所有的房源列表redisLong cityId = sysRegion.getId();redisService.removeForAllList(CITY_HOUSE_PREFIX + cityId);// 查询当前城市下所有的房源列表mysqlList<CityHouse> cityHouses = cityHouseMapper.selectList(new LambdaQueryWrapper<CityHouse>().eq(CityHouse::getCityId, cityId));// 新增当前城市下所有的房源列表映射redisif(!CollectionUtils.isEmpty(cityHouses)){redisService.setCacheList(CITY_HOUSE_PREFIX + cityId,cityHouses.stream().map(CityHouse::getHouseId).distinct().collect(Collectors.toList()));}// 更新房源列表详细信息(redis)for(CityHouse cityHouse : cityHouses){cacheHouse(cityHouse.getHouseId());}}
}优化建议:
- 分页处理:如果数据量很大,需要分页处理避免内存溢出
- 异步执行:全量刷新耗时较长,应该异步执行并提供进度查询
- 灰度发布:先刷新部分数据,验证无误后再全量刷新
3. 小结
通过本文的实战讲解,我们完整掌握了:
✅ 核心解决方案
- 定时任务调度:使用Spring Schedule实现定时状态检查
- 分布式锁保障:Redis原生 vs Redisson两种实现方案
- 消息队列解耦:RabbitMQ处理用户信息变更事件
- 缓存全量刷新:系统启动或数据迁移时的缓存初始化
✅ 技术选型推荐
- 中小项目:直接使用Redisson,避免重复造轮子
- 极致性能场景:可考虑Redis原生方案,但要做好充分测试
- 高可用要求:Redis集群模式+Sentinel保障可用性
希望本文能帮你彻底解决分布式环境下的定时任务同步问题。如果有任何疑问或建议,欢迎在评论区交流讨论!