缓存更新策略
有两种策略
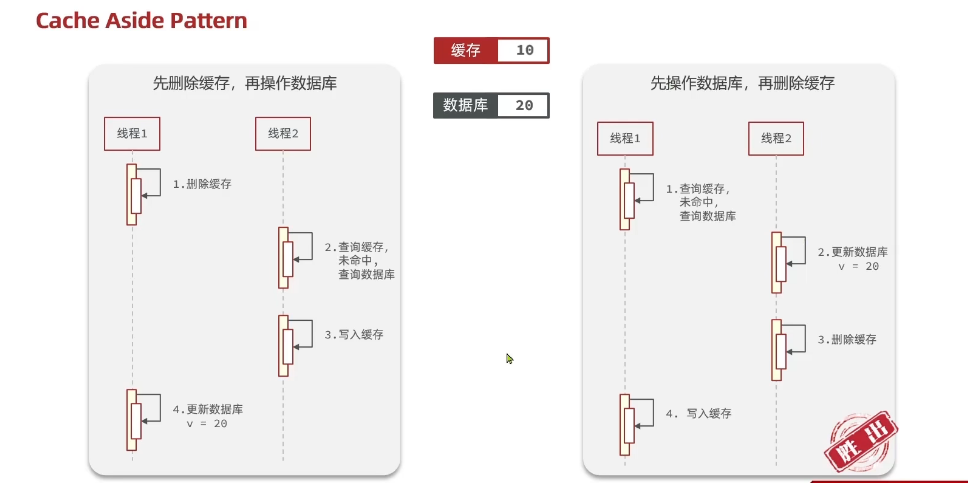
1.先删除缓存,再操作数据库(有缺点)
正常:线程1先删除缓存,然后线程1更新数据库
异常情况:线程1删除缓存之后,再线程1更新数据库之前,线程2查询缓存,因为缓存已经被删除,未命中,然后查询数据库,写入缓存。之后线程1执行了更新数据库的操作,此时发生了数据库与缓存不一致问题、
发生情况:高 因为查询数据库是比较慢的
2.先操作数据库,再删除缓存。
正常:线程1查询缓存,未命中,查询数据库,然后写入缓存
异常情况:线程1查询缓存,未命中,查询数据库,此时线程2进行了更新数据库的操作,然后把缓存删除,然后线程1写入缓存。此时发生了数据库与缓存不一致问题
发生情况:低 因为 查询缓存之后写入缓存是毫秒级别,数据库查询很慢,发生情况很低
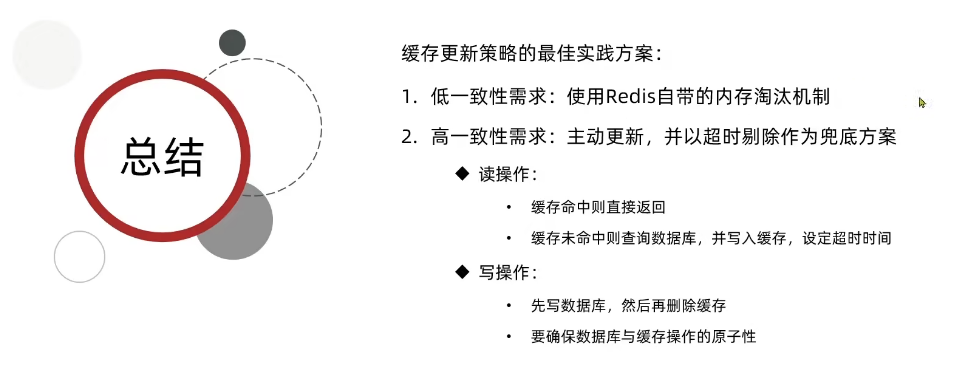
1. 低一致性需求:使用Redis自带的内存淘汰机制
生活化类比:
像图书馆书架满了,按“最近最少借阅”自动下架旧书,腾出空间放新书。不需要手动管理,系统自动淘汰。
专业解释:
Redis 内存满时,按配置策略(如 LRU)自动淘汰旧数据。适合对实时性要求不高的场景,如热点数据、统计数据。
2. 高一致性需求:主动更新 + 超时剔除
生活化类比:
像银行账户余额,必须准确。查询时先看“小本子”(缓存),有就直接用;没有就去查“总账”(数据库),查到后记到“小本子”并标注过期时间。更新时先改“总账”,再撕掉“小本子”上旧记录,保证两个操作同时完成。
专业解释:
读操作(Cache-Aside):
- 缓存命中:直接返回缓存数据
- 缓存未命中:查数据库,写入缓存并设置过期时间(TTL)
写操作(Write-Through/Write-Behind):
- 先写数据库,再删除缓存(避免先删缓存再写库导致短暂不一致)
- 保证数据库写与缓存删除的原子性(事务或分布式锁),确保一致性
核心要点:
- 低一致性:依赖自动淘汰,简单但可能读到旧数据
- 高一致性:主动更新 + 超时兜底,保证准确性,但实现更复杂