VSR字幕检测模块PaddleOCR模型升级:从PP-OCRv4到PP-OCRv5(当前最新的PaddleOCR模型)
文章目录
-
-
- 问题描述
- 飞浆OCR新旧模型对比
- 一、VSR项目的字幕检测逻辑
-
- 1. 文本检测算法的位置
- 2. PaddleOCR 模型的位置与加载逻辑
- 3. 文字检测的完整流程
- 总结
- 二、依赖准备
-
- 1. paddlepaddle包
- 2. 文本检测模型下载(最新v5)
- 三、VSR字幕检测模块更新
-
- 1. **修改 `SubtitleDetect` 类的初始化方法(添加控制参数)**
- 2. **替换文本检测模型为 PP-OCRv5(提高检测能力)**
- 3. **修改检测方法,支持返回置信度并添加保存逻辑**
- 4. **在帧检测流程中传入帧号(用于保存命名)**
- 核心改进点总结
-
问题描述
video-subtitle-remover是基于AI的图片/视频硬字幕去除、文本水印去除,无损分辨率生成去字幕、去水印后的图片/视频文件。虽然之前更新了多sub_areas和字幕过滤逻辑(VSR(video-subtitle-remover)字幕修复项目,多区域框选,字幕筛选逻辑功能实现),但是发现还是有一些字幕修复不了。比如:
- 帧间不稳定,字幕时而被消除,时而存在
- 部分艺术字未被消除
而且,我排除了修复工具(LAMA)的问题,在另一个项目WatermarkRemover,提供了区域修复的接口,我注释掉其字幕筛选的逻辑,直接修复固定区域,则不会出现上述问题。
飞浆OCR新旧模型对比
此外,笔者检查了原作者使用的字幕检查模型,发现是两年前更新的(https://github.com/YaoFANGUK/video-subtitle-remover/tree/main/backend/models)…
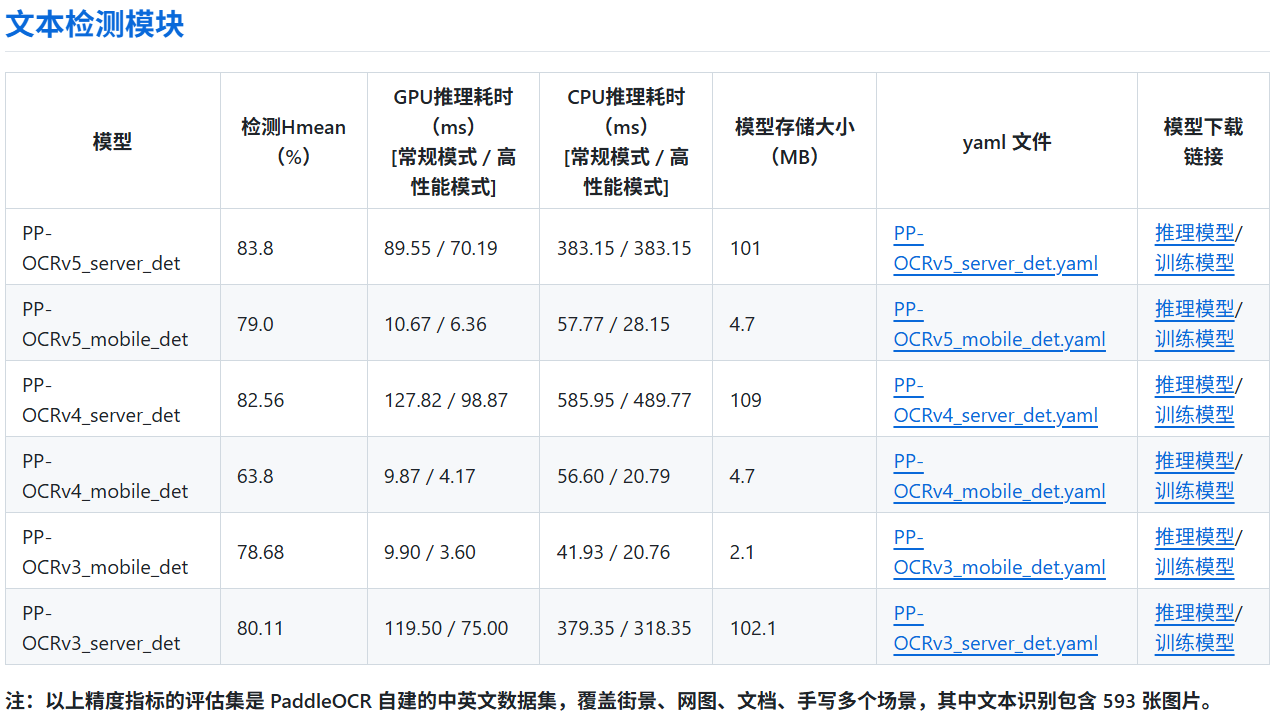
所以我去PaddleOCR查看了官方的更新日志,以及modle_list。

一、VSR项目的字幕检测逻辑
1. 文本检测算法的位置
文本检测的核心逻辑集中在 SubtitleDetect 类中(位于 video-subtitle-remover/backend/main.py),主要通过以下方法实现:
- text_detector 方法:初始化 PaddleOCR 的文本检测器(TextDetector),指定检测算法为 DB(见代码中 args.det_algorithm = 'DB')。
detect_subtitle方法:调用检测器对单帧图像进行文本检测,返回文本框坐标(dt_boxes)。get_coordinates方法:将检测到的文本框坐标转换为统一的矩形区域(xmin, xmax, ymin, ymax),用于后续生成掩码去除字幕。
2. PaddleOCR 模型的位置与加载逻辑
项目中已内置 PaddleOCR 的检测模型,无需单独下载,模型路径通过配置文件指定:
-
在
backend/config.py中,明确定义了检测模型的路径:DET_MODEL_BASE = os.path.join(BASE_DIR, 'models') DET_MODEL_PATH = os.path.join(DET_MODEL_BASE, MODEL_VERSION, 'ch_det')其中
MODEL_VERSION = 'V4',因此完整路径为backend/models/V4/ch_det。 -
模型文件的完整性检查:代码会自动检测该路径下是否存在完整的模型文件(如
inference.pdiparams),如果不存在,会通过Filesplit合并预分割的小文件生成完整模型(见config.py中的合并逻辑)。这也是你无需手动下载模型的原因——模型文件已拆分后随项目分发,运行时自动合并。
3. 文字检测的完整流程
-
初始化检测器:
SubtitleDetect类在初始化时,通过text_detector方法加载 PaddleOCR 的DB算法模型,支持 ONNX 格式转换(通过convertToOnnxModelIfNeeded方法)以提升推理效率。 -
逐帧检测:在
find_subtitle_frame_no方法中,通过cv2.VideoCapture读取视频帧,调用detect_subtitle逐帧检测文本框,并通过get_coordinates转换为矩形区域。 -
区域过滤与统一:检测到的文本框会根据自定义字幕区域(
sub_area)过滤,并通过unify_regions方法统一连续帧中相似的文本区域,减少帧间波动(避免字幕闪烁)。 -
生成掩码:最终检测到的文本区域会用于生成掩码(
create_mask),配合后续的修复算法(如 STTN、LAMA)去除字幕。
总结
项目通过内置的 PaddleOCR 模型(路径 backend/models/V4/ch_det)和 DB 检测算法实现文字检测,模型文件随项目分发(拆分后自动合并),无需手动下载。核心逻辑在 SubtitleDetect 类中,完成从帧读取、文本检测到区域处理的全流程,为后续字幕去除提供精准的掩码区域。ion模块文档位置
PaddleOCR提供的text_detection模块的文档,包含输入输出参数控制、离线加载模型等
https://github.com/PaddlePaddle/PaddleOCR/blob/main/docs/version3.x/module_usage/text_detection.md