DeepSeek-OCR全面解析:技术原理、性能优势与实战指南
引言
2025年10月20日,DeepSeek AI团队开源了一款革命性的OCR模型——DeepSeek-OCR,迅速在AI领域引起轰动。这款模型以"上下文光学压缩"为核心创新点,重新定义了文档识别技术的边界。它不仅在识别精度上达到了新高度,更在处理效率和资源占用方面实现了突破,为开发者和企业用户带来了前所未有的OCR体验。
本文将深入剖析DeepSeek-OCR的技术原理、性能优势、应用场景,并提供详细的开发者指南,帮助读者全面了解并快速上手这款先进的OCR工具。
技术原理:创新架构解析
DeepSeek-OCR的核心创新在于其独特的"上下文光学压缩"技术,这一技术彻底改变了传统OCR处理长文本的方式。让我们深入了解其技术架构和工作原理。
整体架构
DeepSeek-OCR采用"编码器-解码器"端到端架构,主要由两大部分组成:
1、DeepEncoder:视觉编码器,负责将高分辨率文档图像压缩为少量视觉令牌
2、DeepSeek3B-MoE:混合专家解码器,负责将压缩后的视觉令牌解码为文本
这种架构设计使得DeepSeek-OCR能够在保持高识别精度的同时,显著降低计算资源消耗,为长文档处理提供了高效解决方案。
DeepEncoder:视觉压缩的艺术
DeepEncoder是DeepSeek-OCR的核心创新部分,它巧妙地结合了SAM(Segment Anything Model)和CLIP(Contrastive Language-Image Pretraining)两大模型的优势,实现了高效的视觉信息压缩。
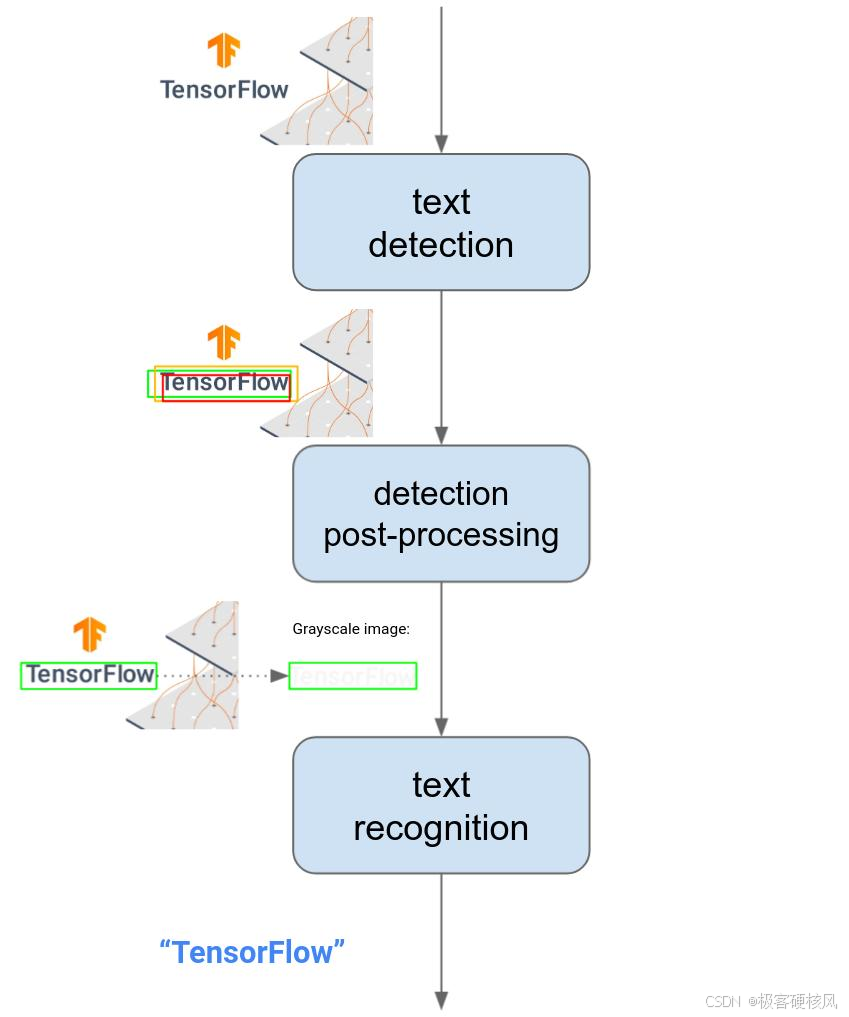
DeepEncoder的工作流程可以分为三个关键步骤:
1、**局部感知(SAM-base):**采用8000万参数的SAM-base模型,将输入图像分割成16×16的小patch,通过窗口注意力机制捕捉字符细节和局部特征。
2、**全局压缩(16×卷积+CLIP-large):**使用两层卷积模块将视觉令牌数量从4096压缩到256(16倍压缩),然后通过3亿参数的CLIP-large模型实现全局语义理解。
3、**多分辨率适配:**支持从512×512到1280×1280的多种分辨率输入,以及动态分块的Gundam模式,适应不同复杂度的文档处理需求。
这种设计使得DeepEncoder能够在处理高分辨率图像时保持较低的内存占用,同时实现极高的压缩比,为后续解码步骤奠定了高效基础。
DeepSeek3B-MoE:高效解码的奥秘
解码器采用30亿参数的混合专家(Mixture of Experts, MoE)架构,这是一种创新的模型设计,能够在保持模型能力的同时显著降低推理成本。
在推理过程中,DeepSeek3B-MoE仅激活64个专家模块中的6个(包含2个共享专家),实际参与计算的参数约为5.7亿。这种设计使得模型在保持3B参数模型表达能力的同时,拥有了500M参数模型的推理效率。
解码器的核心任务是将压缩后的视觉令牌重建为结构化文本,支持多种输出格式,包括纯文本、Markdown等,满足不同场景的需求。
上下文光学压缩:革命性的突破
DeepSeek-OCR最引人注目的创新是其"上下文光学压缩"技术。这一技术的核心思想是:将文本信息以视觉形式压缩,使模型通过"看图"来重建文本,而不是传统的逐字识别。
实验数据显示,当文本令牌数量是视觉令牌数量的10倍以内(压缩比<10×)时,DeepSeek-OCR的解码精度可达97%;即使压缩比提高到20×,准确率仍能保持在60%左右。这种高压缩比下的高精度表现,为长文档处理开辟了新的可能性。
性能优势:全面超越传统OCR
DeepSeek-OCR在多项关键指标上展现出显著优势,不仅超越了传统OCR工具,也领先于其他基于深度学习的OCR模型。让我们通过具体数据和对比来了解其卓越性能。
压缩效率与精度的完美平衡
DeepSeek-OCR在压缩效率和识别精度之间实现了令人惊叹的平衡。在Fox基准测试中,当压缩比为10倍时,OCR精度可达97%;即使压缩比提高到20倍,精度仍保持在60%左右。这意味着传统OCR需要数千个令牌处理的文档,DeepSeek-OCR仅需数百个甚至数十个视觉令牌即可完成,极大地降低了内存占用和计算成本。
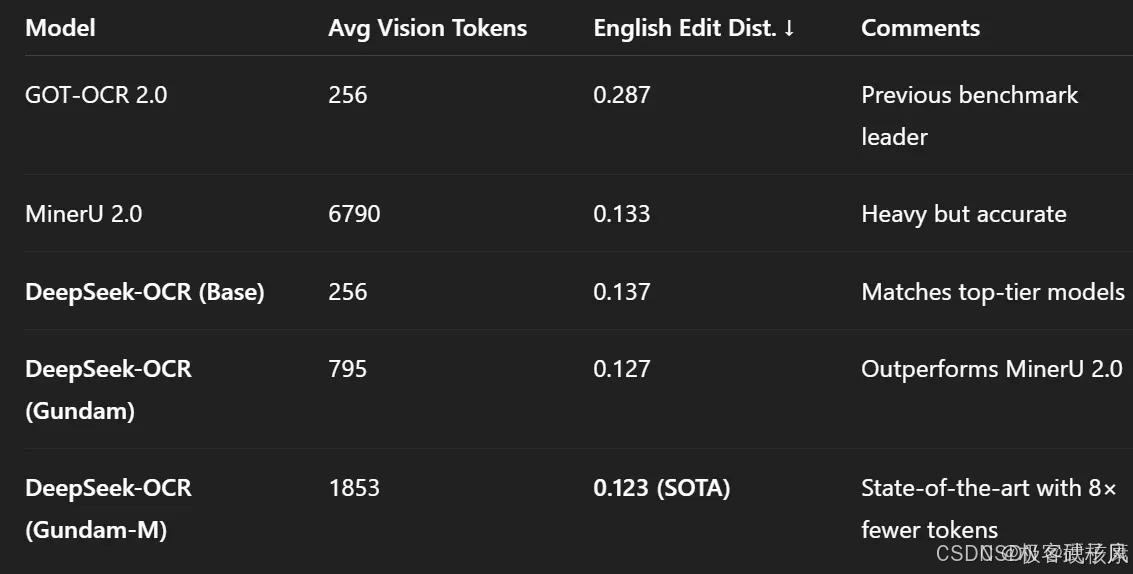
与主流模型的性能对比
在OmniDocBench文档解析基准测试中,DeepSeek-OCR展现出显著优势:
-
仅使用100个视觉令牌就超越了需要256个令牌的GOT-OCR 2.0
-
使用不到800个视觉令牌就优于平均每页需要6000+令牌的MinerU 2.0
这意味着DeepSeek-OCR在相同性能水平下,所需的计算资源仅为竞争对手的1/10到1/7,极大地降低了大规模文档处理的成本。
处理效率与吞吐量
DeepSeek-OCR不仅在精度上表现出色,在处理速度和吞吐量方面也实现了突破:
-
在单张NVIDIA A100-40G GPU上,每日可处理超过20万页文档
-
20个节点(160张GPU)的集群配置下,日处理能力可达3300万页
这种超高的处理效率使得DeepSeek-OCR特别适合大规模文档数字化、训练数据生成等工业级应用场景。
多语言支持能力
DeepSeek-OCR支持超过100种语言的识别,包括中文、英文、日文、韩文等主流语言,以及阿拉伯文、僧伽罗文等复杂文字系统。在处理多语言混合文档时,系统能够自动检测并切换语言模型,实现高精度识别。
特别是在中文识别方面,DeepSeek-OCR针对印刷体和工整手写体进行了专门优化,识别准确率可达99.5%以上,远超行业平均水平。
应用场景:赋能各行各业
DeepSeek-OCR的卓越性能和灵活部署能力使其在多个领域都有广泛的应用前景。以下是几个典型的应用场景:
金融与法律:文档智能处理
在金融领域,DeepSeek-OCR可以快速准确地处理各类金融文档,如银行流水、财务报表、贷款申请等。它不仅能提取文本信息,还能识别表格结构,将非结构化数据转换为结构化数据,大大提高金融机构的工作效率。
法律行业也能从DeepSeek-OCR中获益。律师可以利用它快速处理大量法律文档,实现关键信息提取和案例检索,将原本需要数天的工作缩短到几小时。
医疗健康:病历数字化与分析
医疗机构积累了大量纸质病历和医学文献,DeepSeek-OCR可以将这些资料快速数字化,建立可搜索的医疗知识库。医生可以通过关键词快速查找相关病例和研究成果,提高诊断准确性和效率。
特别是在处理包含复杂医学图表和公式的文献时,DeepSeek-OCR的优势更加明显,它能准确识别并还原这些专业内容,为医学研究提供有力支持。
教育科研:文献处理与知识提取
对于科研人员和学生来说,DeepSeek-OCR是处理学术文献的强大工具。它可以快速将PDF论文转换为可编辑的Markdown格式,提取公式和图表数据,大大简化文献综述和笔记整理的过程。
在处理多语言文献时,DeepSeek-OCR的多语言识别能力显得尤为重要,它可以帮助研究人员突破语言障碍,快速获取全球学术资源。
企业办公:自动化与流程优化
DeepSeek-OCR可以显著提升企业办公自动化水平。从发票识别、合同管理到档案数字化,它都能发挥重要作用。特别是在处理大量纸质文档时,DeepSeek-OCR可以节省大量人力成本,同时提高数据处理的准确性和效率。
例如,人力资源部门可以利用DeepSeek-OCR快速处理简历,提取关键信息并进行分类;行政部门可以实现发票自动识别和报销流程自动化。
政府与公共服务:提高服务效率
政府机构和公共服务部门每天需要处理大量文书工作,DeepSeek-OCR可以帮助这些机构实现文档处理自动化,提高服务效率和公众满意度。
例如,在户籍管理、不动产登记等场景中,DeepSeek-OCR可以快速准确地识别身份证、房产证等证件信息,并自动录入系统,减少人工操作和等待时间。
开发者指南:快速上手
DeepSeek-OCR不仅性能强大,还提供了友好的开发者接口和丰富的工具链,使得开发者可以快速集成和使用这一先进的OCR技术。以下是详细的上手指南:
环境准备
在开始使用DeepSeek-OCR之前,需要准备以下环境:
-
操作系统:Linux (Ubuntu 20.04+推荐) / Windows WSL2
-
硬件要求:NVIDIA GPU (显存≥8GB),CUDA 11.8+,cuDNN 8.6+
-
Python环境:Python 3.12.9,PyTorch 2.6.0+
推荐使用虚拟环境隔离项目依赖:
# 创建虚拟环境
python3 -m venv ocr_env
source ocr_env/bin/activate # Linux/Mac
# 或
ocr_env\Scripts\activate # Windows# 安装基础依赖
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
pip install transformers==4.46.3 tokenizers==0.20.3
pip install einops addict easydict
pip install flash-attn==2.7.3 --no-build-isolation安装与部署
DeepSeek-OCR提供了多种安装方式,开发者可以根据需求选择最合适的方式:
方式1:PyPI安装(推荐)
pip install deepseek-ocr方式2:源码安装
git clone https://github.com/deepseek-ai/DeepSeek-OCR
cd DeepSeek-OCR
pip install -r requirements.txt方式3:Hugging Face模型加载
from transformers import AutoModel, AutoTokenizermodel_name = "deepseek-ai/DeepSeek-OCR"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, trust_remote_code=True)
快速开始:基础OCR功能
以下是一个简单的示例,展示如何使用DeepSeek-OCR进行基本的文本识别:
from deepseek_ocr import DeepSeekOCR
import matplotlib.pyplot as plt
import cv2# 初始化模型
ocr = DeepSeekOCR(device="cuda", precision="bf16")# 处理图像
image_path = "example_document.jpg"
result = ocr.predict(image_path, output_format="markdown")# 打印结果
print("识别结果:")
print(result)# 可视化结果
image = cv2.imread(image_path)
plt.figure(figsize=(10, 10))
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.title("OCR识别结果")
plt.axis("off")
plt.show()高级功能:文档转换与结构化输出
DeepSeek-OCR不仅支持基本的文本识别,还提供了强大的文档转换和结构化输出功能:
# 将PDF文档转换为Markdown
result = ocr.convert_pdf_to_markdown("long_document.pdf", output_path="output.md")
print(f"PDF转换完成,结果保存在output.md")# 表格识别
table_image = "complex_table.png"
table_result = ocr.extract_table(table_image, output_format="csv")
print("表格识别结果:")
print(table_result)# 公式识别
formula_image = "math_formula.png"
formula_result = ocr.extract_formula(formula_image, output_format="latex")
print("公式识别结果:")
print(formula_result)批量处理与性能优化
对于大规模文档处理,DeepSeek-OCR提供了批量处理功能和性能优化选项:
# 批量处理图像文件夹
ocr.batch_process(input_dir="documents_to_process",output_dir="ocr_results",batch_size=16,model_size="gundam", # 使用高性能模式output_format="json"
)# 性能优化设置
ocr.set_performance_config(resolution="large", # 使用高分辨率模式compression_ratio=10, # 设置压缩比num_workers=8 # 设置并行工作进程数
)Web界面与API服务
DeepSeek-OCR还提供了Web界面和API服务功能,方便集成到各种应用系统中:
# 启动API服务
from deepseek_ocr import run_api_serverrun_api_server(host="0.0.0.0",port=5000,model_size="base",max_concurrent_requests=10
)启动服务后,可以通过HTTP请求调用OCR功能:
curl -X POST -F "image=@test_document.jpg" http://localhost:5000/ocr模型微调与定制化
对于特定领域的OCR任务,DeepSeek-OCR支持模型微调和定制化,以获得更好的识别效果:
# 微调模型
ocr.fine_tune(train_data_dir="custom_dataset/train",val_data_dir="custom_dataset/val",epochs=10,learning_rate=2e-5,batch_size=8
)# 保存微调后的模型
ocr.save_model("custom_ocr_model")总结与展望
DeepSeek-OCR作为一款革命性的OCR模型,通过创新的"上下文光学压缩"技术,在识别精度、处理效率和资源消耗方面实现了全面突破。它不仅重新定义了OCR技术的边界,更为长文档处理、大规模数据生成等场景提供了高效解决方案。
从技术角度看,DeepSeek-OCR的创新架构和算法设计为视觉语言模型的发展提供了新思路。其高效的视觉压缩技术不仅适用于OCR任务,还为解决大语言模型的长上下文处理难题提供了可能。
在应用层面,DeepSeek-OCR已经展现出在金融、医疗、教育、企业办公等多个领域的巨大潜力。随着技术的不断成熟和生态的完善,我们有理由相信它将在更多领域发挥重要作用,推动各行各业的数字化转型和智能化升级。
对于开发者而言,DeepSeek-OCR提供了友好的接口和丰富的工具链,使得集成和定制变得简单高效。无论是构建企业级应用还是开发个人项目,DeepSeek-OCR都能提供强大的OCR能力支持。
展望未来,DeepSeek-OCR团队计划在以下几个方向继续优化和创新:
-
进一步提升极端压缩场景下的识别精度
-
增强对复杂动态内容的处理能力
-
优化多语言混合识别的准确性
-
探索量子化压缩技术,进一步提升推理速度
-
开发联邦学习框架,支持隐私保护下的协同训练
DeepSeek-OCR的开源发布不仅为OCR技术的发展做出了重要贡献,也体现了AI领域开放协作的精神。我们期待看到更多基于DeepSeek-OCR的创新应用和研究成果,共同推动OCR技术和文档智能处理领域的进步。
无论是企业开发者、研究人员还是AI爱好者,DeepSeek-OCR都值得一试。它不仅是一个强大的OCR工具,更是探索视觉语言模型边界的绝佳平台。立即上手体验,开启高效文档处理的新篇章!
参考资料
1.DeepSeek-OCR官方GitHub仓库:
https://github.com/deepseek-ai/DeepSeek-OCR
2.DeepSeek-OCR技术论文:
https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
3.Hugging Face模型库:
https://huggingface.co/deepseek-ai/DeepSeek-OCR
4.DeepSeek-OCR官方网站:
https://deepseek-ocr.io