【第二十一周】机器学习周报
目录
- 摘要
- Abstract
- 一、决策树模型
- 二、学习过程
- 1、关键决策
- 1.1、第一个关键
- 1.2、第二个关键
- 三、选择拆分信息增益
- 四、整合
- 五、使用分类特征的一种独热编码(One - Hot)
- 六、连续的有价值特征
- 七、回归树
- 总结
摘要
这周系统学习了决策树这一重要的机器学习算法。通过猫分类的例子,我理解了决策树如何通过一系列特征判断来做出分类决策,包括根节点、决策节点和叶节点的概念。学习了构建决策树的关键步骤:选择分裂特征时使用信息增益最大化原则,通过计算熵减少量来确定最佳特征;掌握了处理多值特征的独热编码技术和连续值特征的阈值选择方法。最后还了解了决策树在回归问题中的应用,使用方差减少代替信息增益来构建回归树。
Abstract
This week’s study comprehensively covered decision tree algorithms in machine learning. Using a cat classification example, I learned the tree structure with root nodes, decision nodes, and leaf nodes. The key aspects included feature selection using information gain maximization through entropy reduction calculations, handling multi-value features with one-hot encoding, and processing continuous features via optimal threshold selection. The course also extended to regression trees where variance reduction replaces information gain for numerical predictions.
一、决策树模型
有一种强大的学习算法,广泛应用于许多应用当中,也被许多人用来赢得机器人学习比赛,就是决策树和树集成。
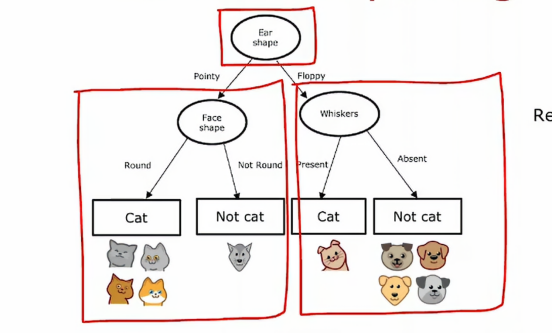
为了解决决策树的工作原理,我们会持续研究一个例子,一个猫分类的例子,假设我们开了一家猫咪收养中心,通过一些特征,我们想要训练一个分类器快速告诉我们一只动物是否是猫
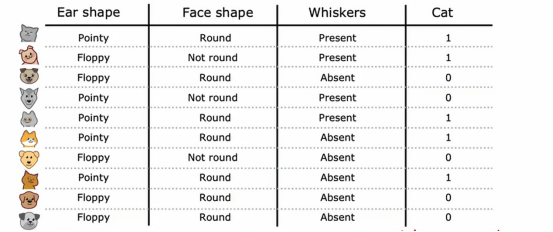
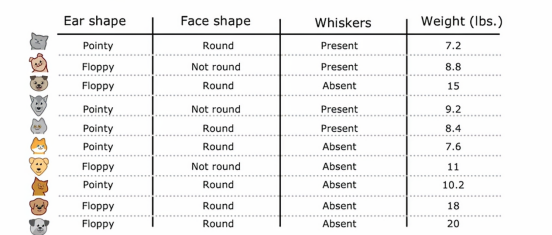
现在我们有一个10个关于判别是否为猫的例子,我们看到我们的判别依据有,耳形、脸形、是否有胡须,来看前两个例子,第一个我们观察到,耳朵形状为尖耳,脸型为圆形,是有胡须的,我们判别为猫;第二个例子,耳朵是垂耳,脸不是圆的,有胡须,我们判别为猫,接下来几个例子也是这样,这里不多赘述。
我们注意到,输出特征x是前三列,我们想预测的目标输出,y是最后一列的是不是猫,在这个例子中,特征x是分类值,换句话说,这些特征只取几个离散值,耳朵形状是尖的还是下垂的,脸型是圆的还是不圆的,胡须是有还是没有,这其实是几个二元分类问题,因为标签总是1或0,目前来看,x1、x2、x3只有2个取值,我们之后会讨论有更多的情况,那么,什么是决策树呢?
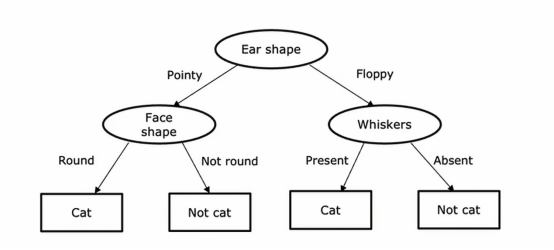
这是一个模型示例,我们可能在使用决策树学习算法对数据集 进行训练后得到该模型,学习算法输出的模型看起来像一棵树,而这样的图像,就是计算机科学家称之为的树,这些椭圆或矩形中的每一个点都称为树中的节点,树的根在顶部、叶在底部
这个模型的工作方式是 如果我们有一个新的测试样本,假如这里有一个耳朵形状尖尖的猫,脸型是圆的,并且有胡须,这个模型查看这个样本并做出分类决策的方式是,我们将从树的最顶端节点开始这个样本,我们会查看写在里面的特征,即耳朵的形状,基于这个样本的耳朵形状的值,我们可以选择向左走还是向右走,这个样本的耳朵形状是尖的,所以我们沿着这个树的左边分支向下走,然后我们查看这个样本的脸型,发现是圆脸,所以我们会沿着这个箭头往左走,算法将会推断认为这个是只猫,我们引入几个概念,首先是椭圆的我们统称为决策节点,并且最上面的决策节点我们也称为根节点,之所以叫它们决策节点是因为它们查看某个特定的特征,然后根据特征的值,决定向左走还是向右走,最后这些底部的节点,这些矩形框,我们称之为叶节点,它们负责进行预测
其实决策树它并不是唯一的,我们可以根据现实情况合理调整,这是四个不同情况下,我们判断是否为猫的决策树,在这些不同的决策树中,有些实是在训练集或交叉验证集和测试集上表现会更好,有些会更差
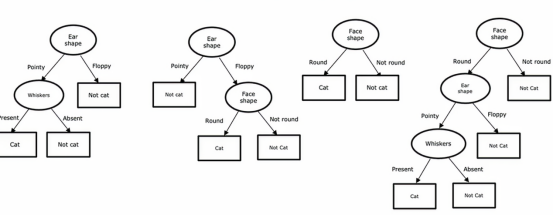
从所有可能的决策时中,试图选出一个在训练集上表现良好的,并且理想情况下能够很好地泛化到新数据,如交叉验证集和测试集,所以看起来对于给定的应用,可以构建很多不同的决策树,如何让算法根据训练集学习一个特定的决策树呢,这就是我们要引出的第二个内容
二、学习过程
构建决策树的过程,给定一个数据集,有几个步骤,在本节中,我们来看看构建决策树的整体过程,给定一个包含10个猫和狗实例的训练集,就像上一节我们看到的那样,决策树学习的第一步是我们必须决定在根节点使用什么特征,这就是第一个节点,在决策树最顶部的位置,假设我们决定选择耳朵形状特征作为根节点的特征,这意味着我们将决定查看所有训练实例,这里显示的所有10个训练实例,并根据耳朵形状特征的值将它们分开,具体而言,我们挑选五个尖耳朵放到左边,然后挑选出五个垂耳朵的例子,把它们移到右边
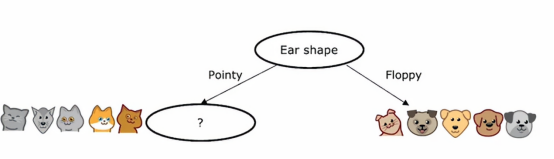
第二步是只关注左边部分,有时被称为是决策树的左分支,具体来说,我们应该选择一个特征去区分左边部分,我们将其选为面部特征
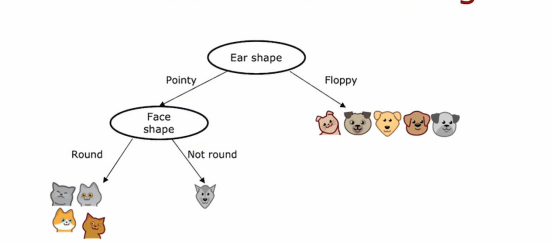
这样我们将圆脸放到左边,将不是圆脸放到右边,最后我们注意到左边的所有例子都为猫,因此不用继续区分,所以我们创建一个叶节点,该节点下全被判别为猫
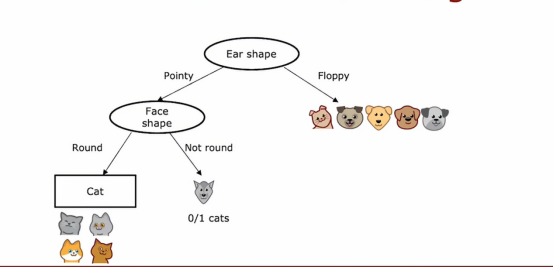
在这里我们发现右边没有一个猫,全是狗,所以我们在这里创建一个叶节点,预测为非猫,现在,我们算是完成了根节点左侧的所有工作,现在让我们把目光聚焦于右边,在这五个例子上,包含一个猫四个狗,我们同样需要一个特征来进一步地划分这五个例子,如果我们选择胡须作为特征
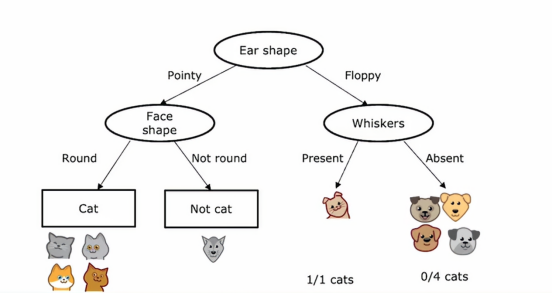
我们会发现左侧的全是猫,所以这每个节点是完全纯净的,要么全是猫,要么全不是猫,因此我们也会创建一些叶节点,在左边做出猫的预测,在右边做出非猫的预测
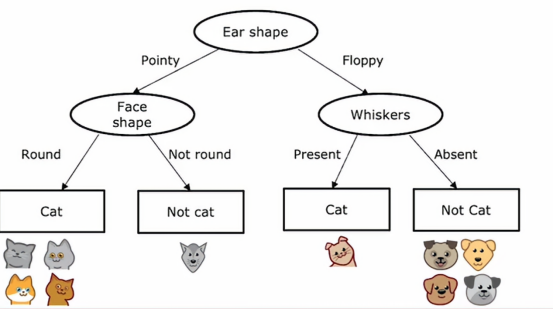
所以这就是构建决策树的过程,通过这个过程,在算法的不同步骤中有几个关键决策需要我们做出,我们来讨论一下关键决策
1、关键决策
1.1、第一个关键
首先我们需要思考的是,如何选择在每个节点上使用哪个特征进行划分,在根节点上,以及在决策树的左分支和右分支上,我们需要决定如果该节点有一些例子是猫和狗的混合,我们是要用耳朵特征划分、还是脸型特征、或者用胡须特征,我们会在之后的学习中会知道决策树将选择哪个特征进行划分,以尽量最大化纯度,所谓纯度,是指我们希望获得尽可能接近全部是猫或全部是狗的子集,例如,我们有一个特征是,该动物是否有猫的DNA,实际上我们并没有这个特征,但如果我们有,我们可以在根节点上使用这个特征进行划分,这样左分支中会得到五只猫,右分支没有猫
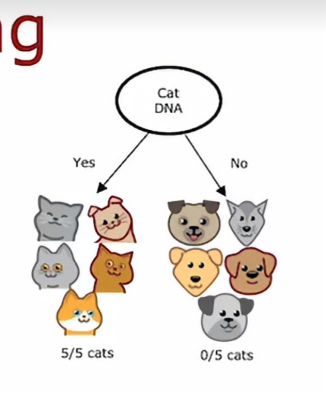
这样左右两个子集数据都是完全纯净的,这意味只有一个类别,要么只有猫,要么不是猫,在这些左右两个子分支都是如此,这就是为什么猫的DNA特征将是一个很好的特征,但按照我们常识肉眼观察的话,我们不得不决定是否在耳朵形状上进行划分
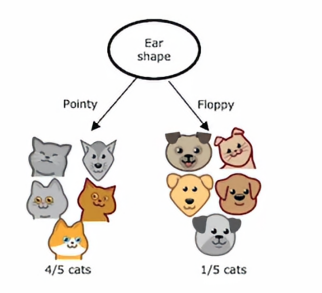
那我们会得到4个猫和1个狗在左边这个分支,1个猫个4个狗在右边这个分支
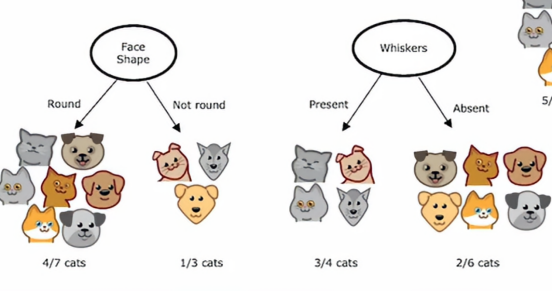
抑或是脸型和胡须之间做出选择,现在我们有一个问题,就是这么多分类的方法,我们怎样选择,决策树的效率会最高呢,答案是选择纯度最高的一个,我们看第一种方法,即按照耳朵形状进行区分,有4/5的猫被区分出来,第二种方法,有4/7的猫被区分出来,第三种方法,有3/4的猫被区分出来,相比后两者,第一种方法区分出来的猫的比例是最多的,所以我们可以选择第一个作为决策条件,即第一个条件是纯度最高的
所以在学习决策树时,我们必须做出第一个决定是如何选择在每个节点进行划分的特征
1.2、第二个关键
构建决策树的第二个关键是何时停止划分,我们刚才使用的标准是直到一个节点100%全是猫或者100%全是狗或不是猫,另外,我们也可以决定在进一步划分节点会导致树超过某个限制时停止划分,在我们允许树生长到最大深度是我们可以决定的参数,在决策树中,节点的深度定义为从根节点到达该节点所需的跳数,就是最顶端的节点到特定节点,所以根节点自身无需跳转,处于深度0,它下面的节点处于深度1,再往下面的节点属于深度2
所以,如果我们决定将决策树的最大深度设为2,那么我们会决定不再划分低于这个层次的任何节点,这样树的深度永远不会达到3,我们这么做的原因就是我们需要限制决策树深度的一个原因是首先确保树不会变的太大和难以管理,其次,通过保持树的规模较小,使其不容易过拟合
我们可能使用的另一个决定停止划分的标准是纯的得分的改进,我们会在后面具体学到,低于某个阈值,所以如果划分一个节点仅带来最低的纯度改进或者我们后面看到它实际上降低了纯度,但如果收益太小,那么我们可能不会这么做,同样,为了保持树的规模较小并减少过拟合的风险,最后如果一个节点上的示例数量低于某个阈值,那么我们也可能停止划分,比如说,如果在根节点我们按照面部形状特征进行划分,那么右侧分支将只有三个训练示例其中一个是猫,两个是狗
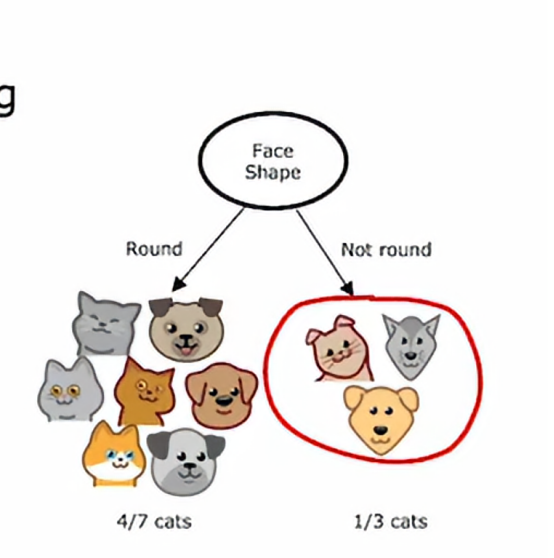
而不是进一步划分为更小的子集,如果我们决定不再划分仅有三个或更少示例的集合,那么我们只需要创建一个决策节点,这个右边这个节点就被预测为不是猫
我们不再决定划分的一个原因是保持树的规模较小并避免过拟合
三、选择拆分信息增益
建立决策树时,我们将在节点上如何决定分裂特征的方法将基于哪种特征选择能够最大程度地减少熵最多,减少熵或者减少杂质在决策树模型中,熵的减少被称为是信息增益,让我来看看如何计算信息增益,从而选择在决策树的每个节点使用哪个特征进行分裂
让我们用刚才构建的决策树的根节点为例来决定使用哪个特征辨别是否为猫
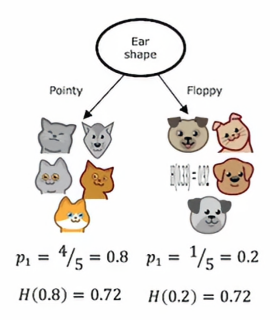
如果我们在根节点分裂时使用耳朵形状作为特征,左边有五个例子,右边有五个例子,在左边我们五个中有四个猫,所以p1=4/5,右边是五个中有一个是猫,所以p2=1/5,如果我们将昨天的熵公式应用到左边的数据子集以及右边的数据子集,我们发现左边的不纯度是0.8的熵,大约是0.72,而右边的熵也为0.72,所以如果我们在耳朵形状上分裂,这将是左右分支的熵
另一种选择是根据面部形状特征分裂
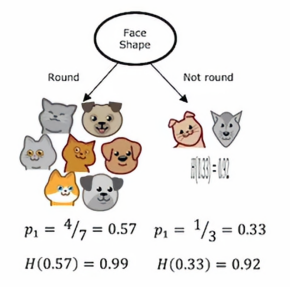
如果我们这样做,那么在左边,七个动物中有四个是猫,右边三分之一是猫,4/7和1/3的熵分别为0.99和0.92,所以左右的不纯度显得更高,直观上就是看着显得更乱
最后,作为根节点的第三个备选特征是胡须特征
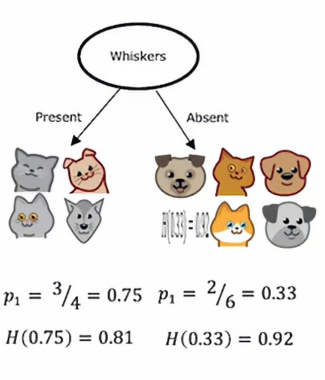
在这种情况下,我们根据是否有胡须来分裂,左边的p1 = 3/4 ,右边的p2 = 2/6=1/3,故它们的熵分别为0.81和0.92
所以,我们回到我们最初的问题,在这三个例子中,哪个是最佳选择,事实证明,与其比较这些熵数值,不如取它们的加权平均值来分析更有用,如果一个节点中很多示例,但它的熵很高,这似乎比一个只有少量示例但同样熵值很高的节点要差,因为如果数据集非常大且不纯,作为纯度测量的熵更差,相比之下,树的一个分支中只有少量示例时,即使非常不纯,其熵值也比较低,所以关键决策是,在这三个可用作根节点的特征中,我们通过加权平均来合并两个数字,因为低熵是多么重要,比如左子分支或右子分支也取决进入左子分支或右子分支的实例数量,因为如果在其中有很多实例,比如左子分支,那么确保左子分支的熵值较低就显得很重要了,在这个示例中,我们有十个示例,其中有五个示例进入了左子分支,所以我们可以计算加权平均值

因此,我们选择分裂的方法是计算这三个数字并选择最小的那个,因为那样会给我们带来平均加权熵值最低的左子分支和右子分支,在构建决策树的过程中,我们实际上会对这些公式进行一个改动,以符合决策树构建的惯例,就是我们不会计算加权平均熵值,而是计算没有分裂时相比的熵值减少量,所以我们到根节点,记住根节点上,我们一开始有根节点上的所有十个示例,有五只猫五只狗,所以在根节点上,我们有p1 = 0.5,H = 1,这是最大的不纯度,因为有五只猫和五只狗在同一层,所以我们实际用来选择分裂的公式不是左右两侧的加权熵值子分支,相反,它将是根节点的熵,即0.5的熵,然后减去这个公式,在这个例子中,如果我们计算一下数学公式,结果是0.28,对于脸型,我们计算为0.03,对于胡须,我们计算为0.12
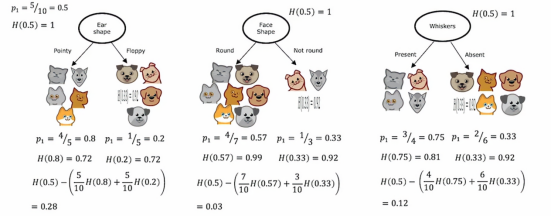
这些我们刚才计算的数字,我们称之为信息增益,它衡量的是我们在树中获得的熵减少,来自分裂所得到,因为根节点的熵原本是1,通过进行分裂,我们最终得到了更低的熵值,这两个值之间的差异就是熵的减少
那么为什么我们要计算熵的减少,而不是直接计算左右子分支的熵呢,事实证明,决定是否不再继续分裂的停止标准之一是看熵的减少程度,如果熵减少的太小,在这种情况下,我们可能会决定只是为了不必要地增加树的大小而冒着过拟合的风险并决定如果熵减少的太小,低于一个阈值,就不再分裂,在上面这个例子中,耳朵的减少量是最多的,所以我们可以选择耳朵形状来作为分类特征

上面这张图就是信息增益在数学上的定义,并且给定了具体的计算公式
所以总的来说,通过计算这些信息增益,我们可以判别几个特征中熵减少最多的特征,把它作为分类特征,这样我们可以得到最优的分类。
四、整合
信息增益标准让我们决定如何选择一个特征在一个节点进行分裂,让我们在决策树多个位置使用它,以确定如何构建一个大型的具有多个节点的决策树
这是构建决策树的总体过程,从树的根节点开始,包含所有训练示例,并计算所有的可能的信息增益特征,选择提供最高信息增益的特征进行分裂,当我们确定了分类的特征后,我们根据选定的特征把数据集分成两个子集,并创建左分支和右分支的树,并将训练示例发送到左分支和右分支,之后,我们继续重复在树上的左分支进行分裂,在右分支上的分裂,以此类推,一直这样做,直到满足标准,停止的标准是一个分类达到100%的纯度或者树的深度超过了我们设置的最大深度抑或是额外分裂的信息增益小于一个阈值,或者节点中示例数量低于阈值
我们来看一个实例操作
首先根节点上,我们发现耳朵形状是信息增益最好的情况,所以我们选择耳朵形状作为我们的分类特征,然后我们衍生出2个子树,我们先把眼光放到左子树上,通过计算,我们发现脸型的分类表现是最好的,所以我们选择脸型作为分类特征,然后我们发现,左边的猫纯度达到了100%,这达到了我们的停止条件,所以我们把左子树的两个叶节点划定为猫和非猫,然后我们将视角看到右子树,同样的,经过计算,我们将胡须作为我们的分类特征,经过分类之后,我们发现左边的猫特征纯度已经达到100%,右边非猫的纯度也达到了100%,所以我们判定这个分类过程结束,一个决策树就这样被建立起来了
五、使用分类特征的一种独热编码(One - Hot)
目前我们的举得例子,每个特征只能取两个可能值之一,脸的形状圆或不圆,胡须或有或无,但是如果我们有特征可以取多于两个离散值,我们该怎么办呢,在本节中,我们将看看如何使用热编码来解决这样的问题
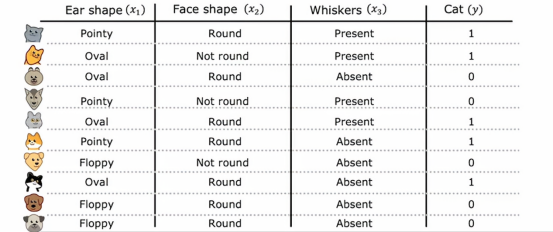
这是我们的宠物领养中心应用程序的新训练集,所有的数据都相同,除了耳朵形状特征耳朵的形状不仅仅是尖或垂,现在还可以是椭圆形,因此耳朵形状特征仍然是一个分类值特征,但它可以取三个可能的值,而不是只有两个,这意味着,当我们在这个特征上分裂数据时,我们会创建三个数据子集并最终为这棵树创建三个子分支,但在本节中,我们想学习的是一种不同的解决多值特征的方法,就是使用独热编码
具体来说,与其使用一个可以取三个可能值的耳朵形状特征,我们将创建三个新特征,其中一个特征是,这个动物是否有尖耳朵,第二个特征是是否有垂耳,第三个特征是是否有椭圆耳
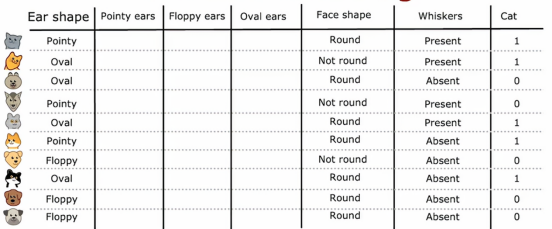
就拿第一个例子来看,我们可以看到这个猫的耳朵是尖耳,那么我们在尖耳的地方将其设置为1,然后再将垂耳和椭圆耳设置为0下面的例子也是同理
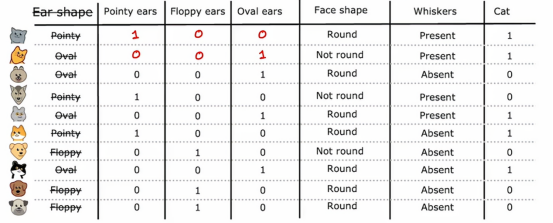
原来的情况是一个特征有3种情况,如果我们不好设计3棵子树,那么我们可以将其拆分为多个二元分类的特征,这样我们判断的范围依旧是0和1
广义来说,如果一个分类特征有K种可能值,在我们上面那个那个例子,k=3,那么这样我们就会创建k个二元特征来替换它,这些特征只能取0或1的值,我们可能会注意到这三个特征中,在任何一行里,都是恰好只有一个值等于1,这就是这种特征被称为独特编码的原因,因为这里分裂的特征中只会有一个是为1,因此得名独热编码,有了这种处理方法,我们就可以将复杂、多值的特征转变到每个只取两个可能值的简单特征,因此,我们以前见过的决策树学习算法可以直接应用到这些数据上,不需要进一步修改,顺便提一嘴,尽管我们的材料都集中在训练决策树模型上,使用独热编码来编码类别特征的想法同样适用于训练神经网络,特别是,如果我们将脸型特征中的圆形和非圆形用1和0替换,非圆形作为0,圆形作为1,把胡须也改成0和1的特征,现在这5个特征列表就可以输入到神经网络或逻辑回归中,尝试训练猫分类器,所以独热编码是一种不仅适用于决策树学习的技术,也让我们用1和0编码类别特征,这样也可以作为输入用于神经网络
就是这样通过独热编码,我们可以让决策树处理拥有超过两个离散值的特征,我们也可以将这种方法应用于神经网络,线性回归或逻辑回归,但是对于那种连续取值的数值特征呢,显然我们这节提到的方法就无法转化它们,这就引入我们下一个节的内容–连续的有价值特征
六、连续的有价值特征
让我们来看一下如何修改决策树以便处理不仅是离散值而是连续值的特征即那些可以取任意数值的特征
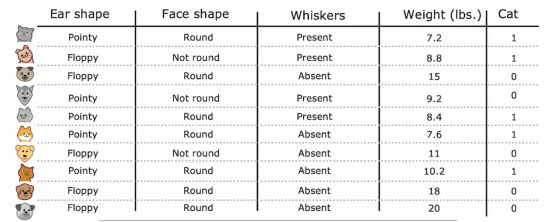
我们已经修改了猫咪收养中心的数据集,增加了一个特征,即动物的体重,平均而言,猫和狗之间,猫比狗轻一些,虽然有些猫比狗重一点,但是体重特征仍然可以决定它是否是猫的一个有用特征,那么如何让决策树使用这些特征呢决策树学习算法像之前一样进行,除了要考虑吧根据耳朵形状、脸型、胡须进行划分以外,还要考虑根据耳朵形状、脸型、胡须或体重进行划分,如果根据体重特征划分比其他选项提供更好的信息增益,那么你将根据体重特征进行划分,但我们如何决定如何根据体重特征划分呢,让我们来看一下,这是根节点数据的图示,我们口语在水平轴上绘制了动物的体重,垂直轴上方是猫,下方不是猫
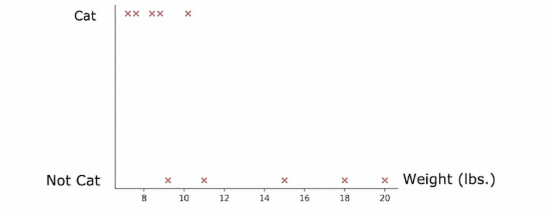
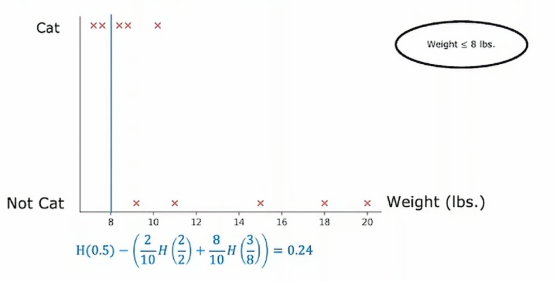
所以垂直轴表示标签y为1或者0,我们根据体重特征划分的方法是根据体重是否小于或等于某个值进行划分,比如说8或其他值,当考虑体重特征划分时,我们应该考虑许多不同的阈值,然后选择最优的那个,最优的意思是,产生最大信息增益的那个,特别地,如果我们考虑根据体重大小或小于等于8来划分
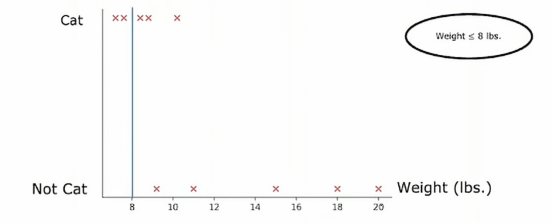
那么我们就将数据集划分为两个子集,左侧子集只有两个猫,右侧子集有三个猫和五只狗,所以如果我们计算通常的信息增益,我们将计算根节点的熵值
那么如果我们将阈值定为9呢,那么结果就是这样,顺便我们计算一下它的熵值
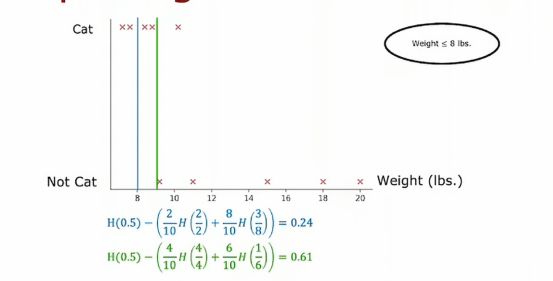
从数据上的表现来看,绿色比蓝色要好,那我们如果选择13当阈值呢,其结果如下
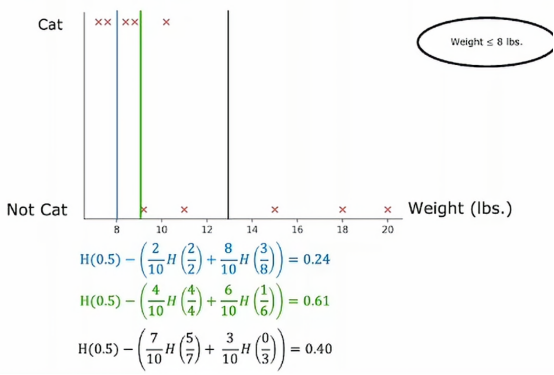
在更一般的情况下,我们肯定不只尝试3个值,而是沿着x轴尝试多个值,一种惯例是根据权重对所有样本进行排序,或者根据这个特征的值并取排序后训练样本中所有值的中点作为其值,然后尝试选择一个能给我们带来最大信息增益的值,用上面这个例子就是0.61,所以我们最终会根据动物的重量是否小于或等于9来分割数据集,这样我们就得到了这两个数据子集,然后我们可以递归地使用这两个数据子集构建额外的决策树来完成剩余的部分
七、回归树
到目前位置,我们只讨论了决策树作为分类算法的情况,在本节中,我们将把决策树泛化为回归算法,以便它们可以预测数值
我们将在此视频中使用的例子是使用我们之前的离散值特征,我们需要明确的是,这里的重量不再是一个输入特征,而是一个输出标签y,而不是之前我们要预测的是否为猫这个目的,这是一个回归问题,因为我们想要预测一个数值y,让我们看看回归树会是什么样子
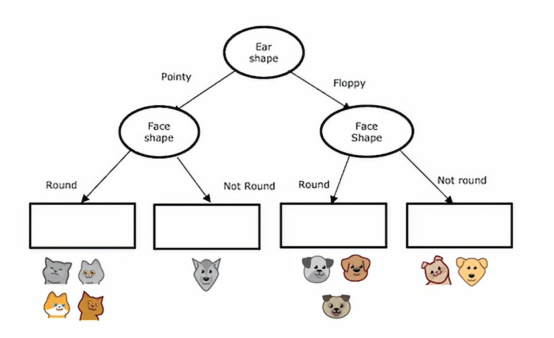
然后左子树和右子树依据脸型进行分裂,决策树在左右两边都选择同一特征进行分裂是没有问题的子树,如果在训练过程中,我们决定了那些分裂,那么这个节点下面就会有这些动物,它们的质量在下图
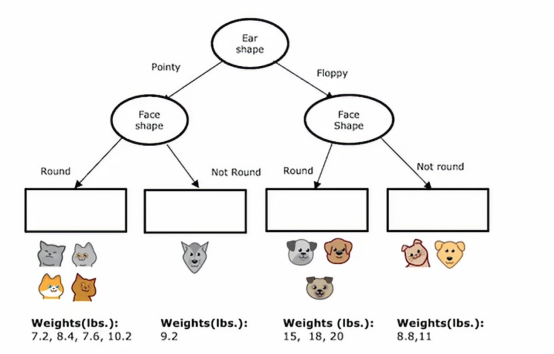
所以我们要为这决策树填写最后一件事是,如果有一个测试样本落到了这个节点,我们应该预测一个耳朵尖尖且脸圆的动物的重量是多少,决策树将基于这些训练样本中的权重平均值进行预测
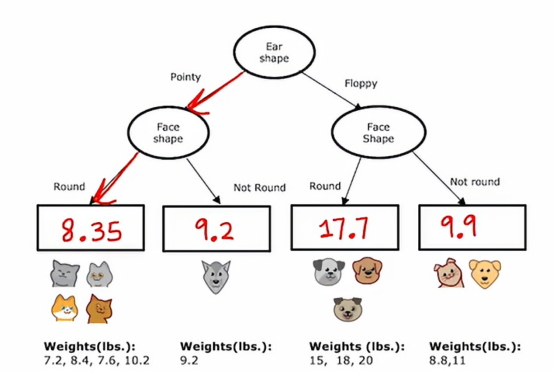
如果我们来个新的样本,按照惯例跟随决策节点直到下一个叶节点,然后在叶节点预测该值,这是我们通过计算这些动物体重的平均值得出的,在训练期间,到达同一个叶节点,如果我们从头构建一棵决策树,使用这个数据集来预测重量
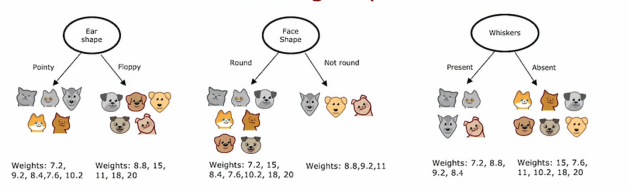
根我们之前的操作很类似,但是我们评判的标准变成了体重而已,在构建回归树时,我们不是试图减少熵,而是试图减少每个子集数据中的y值的体重方差
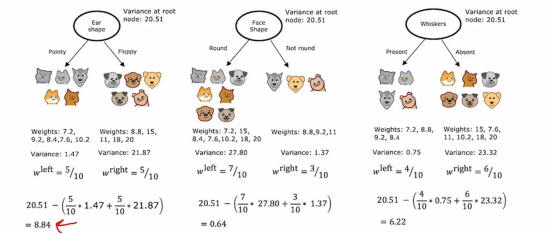
我们先计算每个分支的偏差,就如最左边的那棵来说,我们分别计算节点两边各自的方差,然后我们根据样本分布计算它们的权重然后再加起来,这样得到的平均方差是比较准确的,那么中间和右边也是同理
然后我们再计算根节点的方差,因为数据一开始是未分类的,所以我们得到的方差是一个数值,都是20.51,然后我们拿根节点的方差减去我们之前计算的平均方差,这样得出来的差值,意味着优化的程度,差值越大,优化效果越好,所以我们就可以选择左边的那个分类方法去构造回归树。
总结
这周对决策树的深入学习让我掌握了这种直观而强大的机器学习方法。从最基本的猫分类例子开始,我明白了决策树就像一套"如果…那么…"的判断规则体系。最重要的收获是理解了信息增益的计算原理——通过比较分裂前后的熵值减少量来选择最佳特征,这比凭直觉选择更科学可靠。独热编码的技巧很实用,能把复杂的多值特征转化为多个二元特征,不仅适用于决策树,也能用于神经网络。连续特征的处理方法也很有启发,通过寻找最佳分割阈值来划分数据。最后回归树的学习让我看到决策树的灵活性,用方差减少代替信息增益,在叶节点预测平均值。这些知识构成了一个完整的决策树知识体系,让我对这种算法的原理和应用有了全面认识。