Ernie_health + ProtoNet + Supervised-Contrastive Learning实现小样本意图分类与槽位填充
一、初始化模型
采用Ernie_health预训练语言模型,后接BiLSTM,提取样本特征
ModelManager((_ModelManager__encoder): ErnieEncoder((ernie): ErnieModel((embeddings): ErnieEmbeddings((word_embeddings): Embedding(22608, 768, padding_idx=0)(position_embeddings): Embedding(512, 768)(token_type_embeddings): Embedding(2, 768)(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False))(encoder): ErnieEncoder((layer): ModuleList((0): ErnieLayer((attention): ErnieAttention((self): ErnieSelfAttention((query): Linear(in_features=768, out_features=768, bias=True)(key): Linear(in_features=768, out_features=768, bias=True)(value): Linear(in_features=768, out_features=768, bias=True)(dropout): Dropout(p=0.1, inplace=False))(output): ErnieSelfOutput((dense): Linear(in_features=768, out_features=768, bias=True)(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False)))(intermediate): ErnieIntermediate((dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation())(output): ErnieOutput((dense): Linear(in_features=3072, out_features=768, bias=True)(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False)))# ………………………… 0~11共12层(11): ErnieLayer((attention): ErnieAttention((self): ErnieSelfAttention((query): Linear(in_features=768, out_features=768, bias=True)(key): Linear(in_features=768, out_features=768, bias=True)(value): Linear(in_features=768, out_features=768, bias=True)(dropout): Dropout(p=0.1, inplace=False))(output): ErnieSelfOutput((dense): Linear(in_features=768, out_features=768, bias=True)(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False)))(intermediate): ErnieIntermediate((dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation())(output): ErnieOutput((dense): Linear(in_features=3072, out_features=768, bias=True)(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False)))))(pooler): ErniePooler((dense): Linear(in_features=768, out_features=768, bias=True)(activation): Tanh()))(bi_lstm): LSTMEncoder((_LSTMEncoder__dropout_layer): Dropout(p=0.1, inplace=False)(_LSTMEncoder__lstm_layer): LSTM(768, 768, batch_first=True, dropout=0.1, bidirectional=True)))(_ModelManager__slot__extractor): Extractor((_Extractor__dropout_layer): Dropout(p=0.1, inplace=False)(_Extractor__relu): ReLU(inplace=True))(_ModelManager__intent_extractor): Extractor((_Extractor__dropout_layer): Dropout(p=0.1, inplace=False)(_Extractor__relu): ReLU(inplace=True))(_ModelManager__slot_encoder): Encoder((_Encoder__dropout_layer): Dropout(p=0.1, inplace=False))(_ModelManager__intent_encoder): Encoder((_Encoder__dropout_layer): Dropout(p=0.1, inplace=False))
)
二、数据加载器
1.获得意图信息
主要是以下四个
(1)class_names:vocab中出现的不重复意图,存放在一个字典中{0: '定义', 1: '预防', 2: '饮食', 3: '推荐医院', ……}
(2)examples_per_class:字典键表示意图编号,值表示该类意图的样本数量{0: 37, 1: 38, 2: 292,……}
(3)examples:将同一类意图的样本放在同一个列表内 '定义': [{'text_u': '高血压有什么症状', 'intent': '定义', 'slots': 'B-定义 illness I-定义 illness I-定义 illness, O, O, O, O, O'},{},……,{}]
(4)class_names_to_ids:与class_names字典相反,键为意图,值为编号
代码实现:
def get_classes_infomation(vocabPath, filePath):classes = []# 构建一个默认value为list的字典examples = defaultdict(list)class_names_to_ids = {}with open(vocabPath, 'r') as src:for line in src:classes.append(line.split('\n')[0])datas = get_data(filePath)for line in datas:examples[line["intent"]].append(line)# 将同一类意图的样本放在同一个列表内# print('examples', examples)class_names = {}examples_per_class = {}for i in range(len(classes)): # len(classes) = 7class_names[i] = classes[i]examples_per_class[i] = len(examples[classes[i]])if (len(classes) != len(examples.keys())):print("Wrong vocab")for key in class_names.keys():class_names_to_ids[class_names[key]] = key# print('class_names_to_ids', class_names_to_ids)return class_names, examples_per_class, examples, class_names_to_ids
2.定义数据集规范
self.dataset_spec = DatasetSpecification(name=None,images_per_class=self.examples_per_class,class_names=self.class_names,path=None,file_pattern='{}.tfrecords')
输出
DatasetSpecification(name=None, images_per_class={0: 37, 1: 38, 2: 292, 3: 180, 4: 55, 5: 30, 6: 197},
class_names={0: 'capacity', 1: 'airport', 2: 'ground_service', 3: 'abbreviation', 4: 'flight_time', 5: 'distance', 6: 'airline'},
path=None, file_pattern='{}.tfrecords')
images_per_class字典与examples_per_class字典相同,class_names字典与上述相同。分别构建训练集、验证集与测试集的DatasetSpecification
3.构建Episode
在一般情况下,可以选择3-shot、5-shot、随机构建的模式。随机构建模式能够模拟在实际应用场景中数据不平衡的问题。
self.config = EpisodeDescriptionConfig(num_ways=None, # 每个episode中的意图类数量, None表示以可变的方式num_support=None, # 由两个整数组成的元组 1.支持集中,每种意图类的样本数量;2.对支持集中每个类的样本数量进行抽样的范围。3.若为None,则表示随机数量 5num_query=None, # 查询集中每个意图类的样本数量 2min_ways=3, # 采样方式的最小值 意图种类数的范围 8 3 1max_ways_upper_bound=10, # 采样方式的最大值 8 10 3max_num_query=20, # 查询集中每类样本的最大数量 2 10max_support_set_size=100, # 支持集的最大数量max_support_size_contrib_per_class=20, # 任何给定类对支持集大小的最大贡献min_log_weight=-0.69314718055994529, # np.log(0.5), 在确定每个类的支持样本数量时,给予任何特定类的最小对数权重max_log_weight=0.69314718055994529, # np.log(2), 最大对数权重min_examples_in_class=2 # 每个类样本的最小数量,低于则将该类忽略)
三、模型训练
results = train(args = args,tr_dataloader=tr_dataloader,val_dataloader=val_dataloader,model=model,optim=optim,lr_scheduler=lr_scheduler)
构建text_list,将support_text 与query_text进行拼接得到text_list
text_list = support_text + query_textmodel_outputs = model(text_list, intent_description, slots_description)loss, acc, f1 = loss_fn(model_outputs,num_classes=num_classes,class_ids=class_ids,num_support=num_support,num_query=num_query,support_labels=support_labels,query_labels=query_labels,slots=slots)loss.backward()optim.step()lr_scheduler.step()train_loss.append(loss.item())train_acc.append(acc.item())train_f1.append(f1)avg_loss = np.mean(train_loss[-args.num_episode_per_epoch:])
avg_acc = np.mean(train_acc[-args.num_episode_per_epoch:])
avg_f1 = np.mean(train_f1[-args.num_episode_per_epoch:])
print('Avg Train Loss: {}, Avg Train Acc: {}, Avg Train F1: {}'.format(avg_loss, avg_acc, avg_f1))
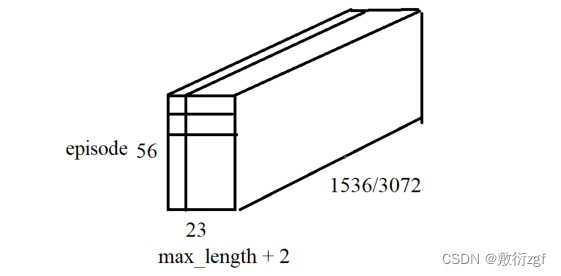
model_outputs 包含三个三维张量:
(1)word_tensor【56,23,1536】
(2)intent_outputs【56,23,3072】
(3)slot_outputs【56,23,3072】
第一个维度表示一个episode中的样本数量,例如支持集由随机的8个意图种类,每种意图5个样本(8-way 5-shot)组成,查询集由与支持集相同的8个意图种类,每种意图2个样本组成。共计 58+28 =56;
第二个维度由这个episode中样本的最长序列 + 2计算得到(+2表示[CLS]、[SEP]);
第三个维度表示每个token被映射到长为1536或3072的向量。
1.intent_prototype_loss
def intent_prototype_loss(model_outputs, num_classes, num_support, num_query):# 按照与列垂直的方向拍扁长方体outputs = model_outputs.mean(dim=1) # 将模型的输出按照第一个维度(矩阵的行)求均值 若dim = 0 表示按照矩阵的列求均值support_size = int(num_support.sum()) # 计算支持集的样本数# 根据每个类别支持集的样本数量,将outputs划分为支持集和查询集intent_support_tensor = outputs[:support_size][:] # 支持集中包含用于计算原型的样本intent_query_tensor = outputs[support_size:][:] # 查询集中包含用于计算距离的样本start = 0support_prototype = None# 遍历每个类别的支持集样本,计算每个类别的原型,取均值for i, num_support_per_class in enumerate(num_support):support_tensors_per_intent = intent_support_tensor[start: start + num_support_per_class]if support_prototype is None:support_prototype = support_tensors_per_intent.mean(dim=0)else:support_prototype = torch.cat([support_prototype, support_tensors_per_intent.mean(dim=0)], 0)start = start + num_support_per_class# 将所有类别的原型连接,得到一个形状为(num_classes, model_outputs.shape[2])的张量support_prototypesupport_prototype = support_prototype.view(num_classes, model_outputs.shape[2])# 使用欧氏距离计算查询样本与原型之间的距离dists = euclidean_dist(intent_query_tensor, support_prototype)# 对距离进行log_softmax操作,得到形状为(num_classes, num_query, -1)的张量log_p_ylog_p_y = F.log_softmax(-dists, dim=1).view(num_classes, num_query, -1)# 创建一个形状为(num_classes, num_query, 1)的张量target_inds,用于在log_p_y中选择正确的预测target_inds = torch.arange(0, num_classes)target_inds = target_inds.view(num_classes, 1, 1)target_inds = target_inds.expand(num_classes, num_query, 1).long()target_inds = target_inds.cuda()# 计算原型损失loss_pn,即在-log_p_y中目标索引处的均值loss_pn = -log_p_y.gather(2, target_inds).squeeze().view(-1).mean()# 在log_p_y的第2个维度上找到最大值,并返回预测结果y_hat_, y_hat = log_p_y.max(2)# 计算准确率acc_pnacc_pn = y_hat.eq(target_inds.squeeze()).float().mean()return loss_pn, acc_pn, y_hat
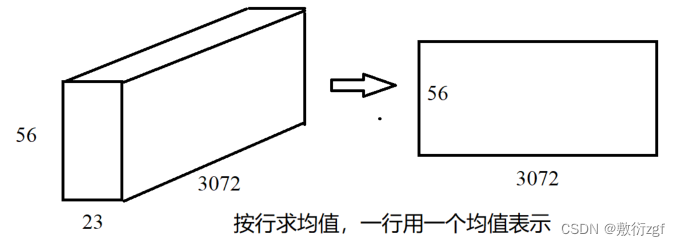
传入的model_outputs 即为intent_outputs,维度【56,23,3072】
outputs = model_outputs.mean(dim=1),维度【56,3072】,将维度为[56,23,3072]的矩阵按照与行方向拍扁。(将模型的输出按照第一个维度(矩阵的行)求均值 若dim = 0 表示按照矩阵的列求均值)
intent_support_tensor【40,3072】
intent_query_tensor【16,3072】
support_tensors_per_intent【5,3072】
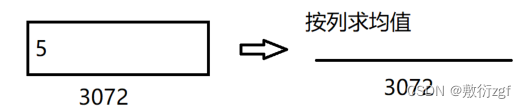
if support_prototype is None:support_prototype = support_tensors_per_intent.mean(dim=0)
support_prototype 【3072,】按照列方向拍扁
else:support_prototype = torch.cat([support_prototype, support_tensors_per_intent.mean(dim=0)], 0)
support_prototype 【6144,】,将第二轮support_tensors_per_intent.mean(dim=0)在后面进行拼接。
经过8次for循环后support_prototype 【24576,】(3072*8)
support_prototype = support_prototype.view(num_classes, model_outputs.shape[2])
view()方法相当于reshape、resize,重新调整Tensor的形状 将所有类别的原型连接,得到一个形状为(num_classes, model_outputs.shape[2])的张量support_prototype
将support_prototype形状修改为【8,3072】
2.计算支持集与查询及意图之间的欧式距离
dists = euclidean_dist(intent_query_tensor, support_prototype)
intent_query_tensor【16,3072】
def euclidean_dist(x, y):'''Compute euclidean distance between two tensors'''# x: N x D 16 * 3072# y: M x D 8 * 3072n = x.size(0)m = y.size(0)d = x.size(1)if d != y.size(1):raise Exceptionx = x.unsqueeze(1).expand(n, m, d)y = y.unsqueeze(0).expand(n, m, d)dist = torch.pow(x - y, 2).sum(2)return dist
unsqueeze将x的维度扩展为(n,1,d),expand将x的维度扩展为(n,m,d) ;unsqueeze将y的维度扩展为(1,m,d),expand将x的维度扩展为(n,m,d)
x = x.unsqueeze(1).expand(n, m, d) # 【16,8,3072】y = y.unsqueeze(0).expand(n, m, d) # 【16,8,3072】dist = torch.pow(x - y, 2).sum(2) # 【16,8】
使用 sum 函数将平方差沿着最后一个维度求和,得到欧氏距离的平方。相当于按照宽的方向将矩形拍扁。
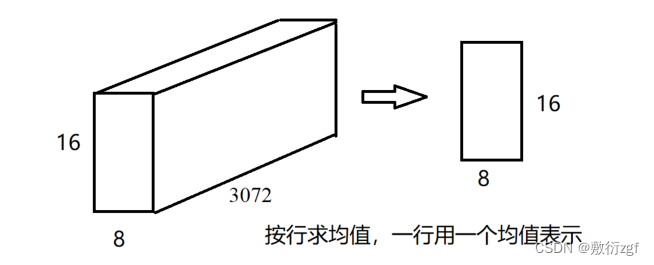
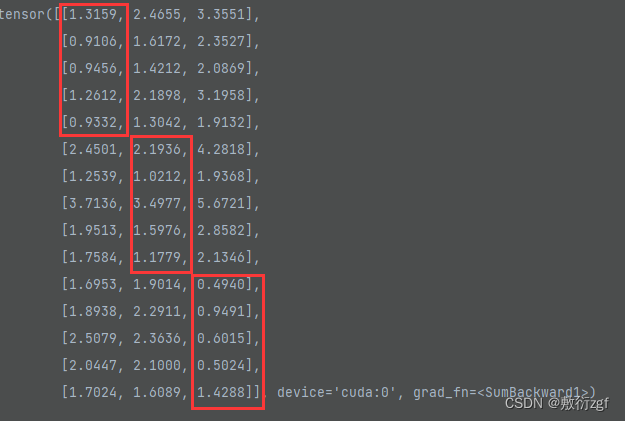
二维矩阵的每一行表示查询集中一行样本与num_classes个支持集原型的距离,一定有一个最小值。
log_p_y = F.log_softmax(-dists, dim=1).view(num_classes, num_query, -1) # 【8,2,8】
F.softmax作用是按照行或者列来做归一化的,0表示对列作归一化,1表示对行作归一化。
F.log_softmax在softmax的结果上再做多一次log运算。
F.log_softmax(-dists, dim=1)维度为【16,8】并将最终结果的形状转化为【num_classes, num_query, -1】【8,2,8】
创建一个形状为(num_classes, num_query, 1)的张量target_inds,用于在log_p_y中选择正确的预测
target_inds = torch.arange(0, num_classes) # tensor([0, 1, 2, 3, 4, 5, 6, 7])
target_inds = target_inds.view(num_classes, 1, 1)

target_inds = target_inds.expand(num_classes, num_query, 1).long()
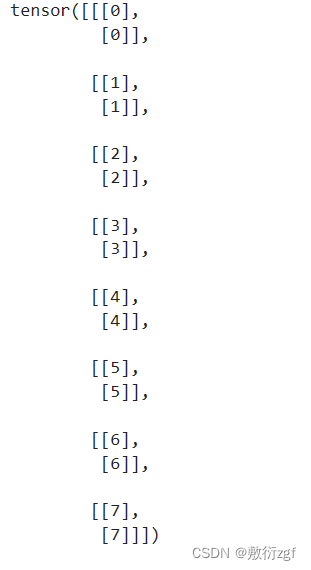
target_inds 【8,2,1】
计算损失,先在第2+1个维度上寻找对应标签的距离,例如类1的样本2标签是5,取出它距离原型1的距离,这就是这个样本的产生的loss,然后对所有样本求平均loss
loss_pn = -log_p_y.gather(2, target_inds).squeeze().view(-1).mean()
_, y_hat = log_p_y.max(2)
acc_pn = y_hat.eq(target_inds.squeeze()).float().mean()
tensor.gather():从原tensor中获取指定dim和指定index的数据。
首先使用 gather 函数根据 target_inds 中的索引从 log_p_y 中选择对应的概率值。然后,使用 squeeze 函数去除多余的维度,并使用 view(-1) 将张量展平为一维。最后,使用 mean 函数计算平均损失值,并将结果保存在 loss_pn 中。
对于准确率,通过使用 max 函数获取每个样本在 log_p_y 中概率最高的类别索引y_hat。y_hat【8,2】
然后,使用 eq 函数将预测的类别索引和真实类别索引进行比较,生成一个布尔型张量。接着,使用 float 函数将布尔型张量转换为浮点型,并使用 mean 函数计算平均准确率,并将结果保存在 acc_pn 中。
3.intent_scl_loss
# 意图分类的对比损失函数
def intent_scl_loss(model_outputs, num_classes, num_support, num_query, temperature=0.07):outputs = model_outputs.mean(dim=1)# 归一化函数,对输出进行归一化outputs = F.normalize(outputs, p=2, dim=1)support_size = int(num_support.sum())# k_s X 768intent_support_tensor = outputs[:support_size][:] # 用于计算对比损失的样本intent_query_tensor = outputs[support_size:][:] # 用于计算相似度的样本# 使用内积计算查询样本与支持样本之间的相似度,将结果除以温度参数以减小相似度的变化范围anchor_dot_contrast = torch.div(torch.matmul(intent_query_tensor, intent_support_tensor.T),temperature)# for numerical stability, 为了提高计算的数值稳定性,使用torch.max函数找到每个查询样本的最大相似度,并将其作为对比结果的偏置logits_max, _ = torch.max(anchor_dot_contrast, dim=1, keepdim=True)logits = anchor_dot_contrast - logits_max.detach()# 根据支持样本的数量创建一个掩码矩阵,用于选择正确的对比结果,掩码矩阵形状(num_classes*num_query, total_support)mask = torch.zeros(num_classes * num_query, num_support.sum())mask = mask.cuda()start = 0for i, num in enumerate(num_support):tmp = torch.zeros(1, num_support.sum())tmp[0][start:start + num] = 1mask[i * num_query:(i + 1) * num_query] = tmpstart = start + numexp_logits = torch.exp(logits)# 使用指数函数对对比结果进行转换,并计算对数概率。log_prob = logits - torch.log(exp_logits.sum(1, keepdim=True))if torch.any(torch.isnan(log_prob)):# log_prob = np.nan_to_num(log_prob.cpu())# log_prob = log_prob.cuda()log_prob = logits# raise ValueError("Log_prob has nan!")# 对每个查询样本计算平均的正例对数概率。通过掩码矩阵进行加权平均,然后除以掩码矩阵的和以标准化。mean_log_prob_pos = (mask * log_prob).sum(1) / (mask.sum(1))# 计算均值的负对数概率,取负作为损失loss = - mean_log_prob_pos.mean()return loss
传入model_outputs = word_tensor【56,23,1536】,
num_classes = 8,
num_support = [5,5,5,5,5,5,5,5],
num_query = 2,
temperature=0.07
outputs = model_outputs.mean(dim=1) 按照行方向拍扁【56,1536】
归一化函数,对输出进行归一化 按照行除以对应的2范数 每行都除以该行下所有元素平方和的开方outputs = F.normalize(outputs, p=2, dim=1)
intent_support_tensor 【40,1536】
intent_query_tensor 【16,1536】
anchor_dot_contrast = torch.div(torch.matmul(intent_query_tensor, intent_support_tensor.T),temperature)
torch.matmul()计算两个矩阵的内积,【16,1536】* 【40,1536】T = 【16,40】
torch.div()计算点除,除以温度系数减小相似度变化范围。
anchor_dot_contrast 【16,40】anchor_dot_contrast 中的每个值就相当于一个查询集样本与一个支持集样本之间的相似度
logits_max, _ = torch.max(anchor_dot_contrast, dim=1, keepdim=True)为了提高计算的数值稳定性,使用torch.max函数找到每个查询样本的最大相似度。keepdim=True保持原维度大小输出,
logits_max 【16,1】, _【16,1】表示对应的索引,就相当于找到每行的最大值,即找到与查询集样本最接近的支持集样本。
logits = anchor_dot_contrast - logits_max.detach()
当两个张量的维度不完全一致时,PyTorch 会进行自动广播(broadcasting)来使得维度匹配。在这里,logits_max 会自动广播为维度为 [16, 40] 的张量,其中每一行都是 logits_max 相应行的值。然后,anchor_dot_contrast 和广播后的 logits_max 的对应元素会相减。logits 【16,40】
mask = torch.zeros(num_classes * num_query, num_support.sum())
mask = mask.cuda()
mask 【16,40】全0张量
for i, num in enumerate(num_support):tmp = torch.zeros(1, num_support.sum())tmp[0][start:start + num] = 1mask[i * num_query:(i + 1) * num_query] = tmpstart = start + num
遍历每类意图的支持集样本;
创建全零张量tmp作为临时变量;
将临时变量tmp的前num个元素设置为1;
将掩码mask的第i*num_query到(i + 1)*num_query个元素设置为tmp
exp_logits = torch.exp(logits)
对输入input逐元素进行以自然数e为底指数运算。exp_logits 【16,40】
log_prob = logits - torch.log(exp_logits.sum(1, keepdim=True))
log_prob 【16,40】
mean_log_prob_pos = (mask * log_prob).sum(1) / (mask.sum(1))
loss = - mean_log_prob_pos.mean()
对每个查询样本计算正例的平均对数概率。通过掩码矩阵进行加权平均,然后除以掩码矩阵的和以标准化。mean_log_prob_pos 【16,】计算均值的负对数概率,取负作为损失。
4.slot_prototype_loss
def slot_prototype_loss(model_outputs, num_classes, num_support, num_query, slots, window= 2):slot_dict, slot_query_labels_ids, slot_query_tensor_cat, ids_to_slot, seq_lens = get_slot_information(model_outputs,num_classes,num_support,num_query,slots, window)slot_prototypes = []for i, key in enumerate(slot_dict.keys()):# 将slot_dict中键key对应的值组成的列表进行堆叠操作,并计算每个维度上的平均值slot_prototype_per_class = torch.stack(slot_dict[key]).mean(0)slot_prototypes.append(slot_prototype_per_class)matrix_slot_prototypes = torch.stack(slot_prototypes).squeeze(1)if len(slot_query_labels_ids) != slot_query_tensor_cat.shape[0]:raise ValueError("The number of labels of slots is wrong.")dists = euclidean_dist(slot_query_tensor_cat, matrix_slot_prototypes)log_p_y = F.log_softmax(-dists, dim=1)target_inds = torch.tensor(slot_query_labels_ids).unsqueeze(1)target_inds = target_inds.cuda()loss_pn = -log_p_y.gather(1, target_inds).squeeze().view(-1).mean()_, y_hat = log_p_y.max(1)target_inds = target_inds.squeeze()y_true = []y_pred = []start = 0for seq_len in seq_lens:target_slots = []predict_slots = []for i in range(seq_len):if start + i < len(target_inds) and start + i < len(y_hat):target_slots.append(ids_to_slot[target_inds[start + i].item()])predict_slots.append(ids_to_slot[y_hat[start + i].item()])y_true.append(target_slots)y_pred.append(predict_slots)start = start + seq_lenf1 = f1_score(y_true, y_pred)acc = accuracy_score(y_true, y_pred)return loss_pn, acc, f1
传入model_outputs = slot_outputs【56,23,3072】,num_classes=8,num_support = [5,5,5,5,5,5,5,5],num_query = 2,slots中包含56个槽位序列,window= 2
slot_dict, slot_query_labels_ids, slot_query_tensor_cat, ids_to_slot, seq_lens = get_slot_information(model_outputs,num_classes,num_support,num_query,slots, window)
5.get_slot_information
# 获取槽位slot的相关信息
def get_slot_information(model_outputs, num_classes, num_support, num_query, slots, window = 2):# support_size = 98support_size = int(num_support.sum())# 从模型输出中获取支持集和查询集张量slot_support_tensor = model_outputs[:support_size][:][:] # model_outputs.shape[60,86,3072] slot_support_tensor.shape[30,86,3072]slot_query_tensor = model_outputs[support_size:][:][:] # [30,86,3072]# print('model_outputs', model_outputs.shape)# seq_index = model_outputs.shape[1]# support_set的槽位标签集合slot_support_labels = slots[:support_size]# query_set的槽位标签集合slot_query_labels = slots[support_size:]#query_slot_set = [] # 存储不重复的查询槽位集合for slots_per_example in slot_query_labels:for each_slot in slots_per_example:if each_slot not in query_slot_set:query_slot_set.append(each_slot)# slot_dict存储每个槽位的支持张量slot_dict = defaultdict(list)for i in range(support_size):slots_per_example = slot_support_labels[i] # 获取当前样本的槽位标签seq_len = len(slots_per_example) # 计算槽标签序列长度for index, each_slot in enumerate(slots_per_example): # 遍历当前样本的槽位标签序列# 如果槽位不是"F"且存在于查询槽位集合中,将支持张量的窗口范围内的值取平均并添加到slot_dict中。if each_slot == 'F' or each_slot not in query_slot_set: # 若槽值为F可能表示缺失槽或不在query_slot_set中(不需要考虑的槽)continue# 计算出左边界 右边界,分别为当前槽标签的索引前后window个槽的位置,确保左边界不小于1,右边界不大于序列长度left = (index + 1 - window) if (index + 1 - window) > 1 else 1right = (index + 1 + window) if (index + window) < seq_len else seq_len# 从支持集中提取包含当前槽位置及其前后window个槽的张量slot_tensor = slot_support_tensor[i][left:right + 1][:]# 计算槽张量的平均值,并在维度0上添加一个维度slot_tensor = slot_tensor.mean(dim=0).unsqueeze(0)slot_dict[each_slot].append(slot_tensor)# 用于将槽位名称转换为对应的索引和将索引转换为槽位名称slot_to_ids = defaultdict(int)ids_to_slot = defaultdict(str)# 遍历查询集的标签,将非查询槽位集合中的槽位排除,并将查询槽位转换为对应的索引。同时记录每个查询样本的槽位序列长度。for i, key in enumerate(slot_dict.keys()):slot_to_ids[key] = iids_to_slot[i] = keyslot_query_labels_ids = []seq_lens = []slot_query_tensor_list = []# 这段出错的原因是slot_query_labels列表中部分标签slots_per_query的长度超过model_outputs.shape[1] seq,想扩大model_outputs.shape[1],但不知道代码中model_outputs.shape[1]如何计算得来的# 找到原因:在数据集中进行BIO标记采用的是token级别,例如89.6 的BIO标记为'O,O,O,O'长度为4,但是Ernie在分词时将89划分为一个词,所以89.6长度为3,这导致了slot序列长度与编码后的长度不一致for i, slots_per_query in enumerate(slot_query_labels):k = 0# if len(slots_per_query) > seq_index:# print('slots_per_query', slots_per_query)# slots_per_query = slots_per_query[:seq_index]for j, each_query_slot in enumerate(slots_per_query):if each_query_slot not in slot_dict.keys():k += 1continue# if j + 1 == len(slot_query_tensor[i]):# print(slots_per_query)# # print('我要跳过了')# breakslot_query_labels_ids.append(slot_to_ids[each_query_slot])slot_query_tensor_list.append(slot_query_tensor[i][j][:])# print(f'slot_query_tensor[{i},{j}]')seq_lens.append(len(slots_per_query) - k)# 将查询集的张量列表拼接成一个张量slot_query_tensor_catslot_query_tensor_cat = torch.stack(slot_query_tensor_list)return slot_dict, slot_query_labels_ids, slot_query_tensor_cat, ids_to_slot, seq_lens
slot_support_tensor【40,23,3072】
slot_query_tensor【16,23,3072】
slot_support_labels支持集40条槽位标签集合
slot_query_labels查询集16条槽位标签集合
for slots_per_example in slot_query_labels:for each_slot in slots_per_example:if each_slot not in query_slot_set:query_slot_set.append(each_slot)
双重for循环遍历的目的是为了在16条查询集槽位标签集合中,遍历出所有出现的槽位 ,将不重复的槽位添加到query_slot_set列表中。
for i in range(support_size):slots_per_example = slot_support_labels[i] # 获取当前样本的槽位标签seq_len = len(slots_per_example) # 计算槽标签序列长度for index, each_slot in enumerate(slots_per_example): # 遍历当前样本的槽位标签序列# 如果槽位不是"F"且存在于查询槽位集合中,将支持张量的窗口范围内的值取平均并添加到slot_dict中。if each_slot == 'F' or each_slot not in query_slot_set: # 若槽值为F可能表示缺失槽或不在query_slot_set中(不需要考虑的槽)continue# 计算出左边界 右边界,分别为当前槽标签的索引前后window个槽的位置,确保左边界不小于1,右边界不大于序列长度left = (index + 1 - window) if (index + 1 - window) > 1 else 1right = (index + 1 + window) if (index + window) < seq_len else seq_len# 从支持集中提取包含当前槽位置及其前后window个槽的张量slot_tensor = slot_support_tensor[i][left:right + 1][:]# 计算槽张量的平均值,并在维度0上添加一个维度slot_tensor = slot_tensor.mean(dim=0).unsqueeze(0)slot_dict[each_slot].append(slot_tensor)
这个双重for循环的目的是为了遍历40条支持集槽位标签中的所有槽位,
作者在论文中描述:
we use the window strategy to take the contextual words into account simultaneously, which
seems more reasonable.
因此设计window = 2,每次取当前槽位的left和right范围内的张量slot_tensor【1,3072】
计算槽张量的平均值slot_tensor = slot_tensor.mean(dim=0).unsqueeze(0),将当前槽位,当前槽位前后windows个长度的槽位张量取均值作为该槽位的张量。
双重for循环遍历完成后slot_dict中存放18个不重复槽位对应的所有张量。每个槽位列表的长度,表示该槽位在此批次支持集中出现的次数。
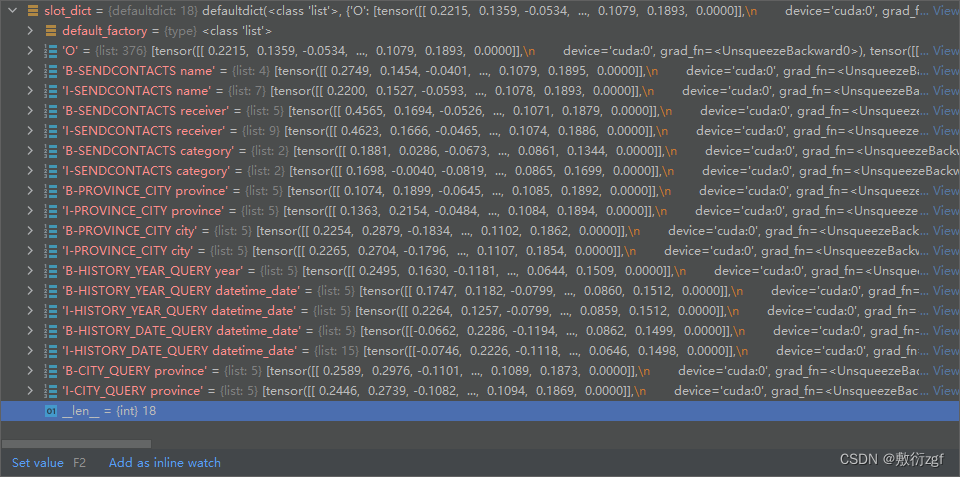
slot_to_ids = defaultdict(int)
ids_to_slot = defaultdict(str)
# 遍历查询集的标签,将非查询槽位集合中的槽位排除,并将查询槽位转换为对应的索引。同时记录每个查询样本的槽位序列长度。
for i, key in enumerate(slot_dict.keys()):slot_to_ids[key] = iids_to_slot[i] = key
为18个不重复槽位添加索引
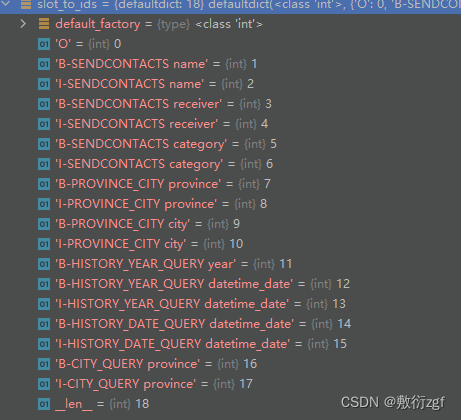
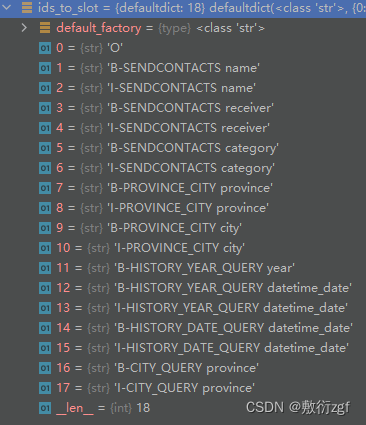
for i, slots_per_query in enumerate(slot_query_labels):k = 0for j, each_query_slot in enumerate(slots_per_query):if each_query_slot not in slot_dict.keys():k += 1continue
slot_query_labels_ids.append(slot_to_ids[each_query_slot])slot_query_tensor_list.append(slot_query_tensor[i][j][:])seq_lens.append(len(slots_per_query) - k)slot_query_tensor_cat = torch.stack(slot_query_tensor_list)
slot_query_labels_ids【184,】存放16条查询集样本(总长度为184)的所有槽位对应在[0~17]的id
slot_query_tensor_list【184,】存放16条查询集样本(总长度为184)的所有槽位对应的张量
最后返回 slot_dict(18个不重复槽位对应的所有张量,键表示槽位,值用列表表示,列表的长度为该槽位出现的次数)、slot_query_labels_ids、slot_query_tensor_cat(将slot_query_tensor_list拼接成一个【184,3072】的张量)ids_to_slot(id对应的槽位【0~17】)seq_lens(16条查询集样本槽位的长度)
for i, key in enumerate(slot_dict.keys()):# 将slot_dict中键key对应的值组成的列表进行堆叠操作,并计算每个维度上的平均值slot_prototype_per_class = torch.stack(slot_dict[key]).mean(0)slot_prototypes.append(slot_prototype_per_class)
slot_dict.keys()键为槽位,值为长度为序列长度的张量。每个张量【槽位出现的次数,3072】
通过取均值,除以槽位出现的次数,得到【1,3072】维张量,替代这个槽位
slot_prototype_per_class 【1,3072】
slot_prototypes为每个都是【1,3072】的列表;matrix_slot_prototypes【18,3072】
dists = euclidean_dist(slot_query_tensor_cat, matrix_slot_prototypes)
slot_query_tensor_cat【184,3072】,matrix_slot_prototypes【18,3072】得到dists 【184,18】
log_p_y 【184,18】
计算槽位原型损失时,方式与意图损失差异较大,输入到欧氏距离函数中的两个张量分别为slot_query_tensor_cat与matrix_slot_prototypes,
其中slot_query_tensor_cat【这一批查询集中所有槽位序列之和,3072】二维张量中的每一行代表一个槽位的嵌入,将这一批查询集样本的槽位无缝拼接。
matrix_slot_prototypes【支持集中不重复槽位的长度,3072】每一行表示一个槽位的嵌入,是之前用当前槽位前后windows个槽位的均值计算得到。
for seq_len in seq_lens:target_slots = []predict_slots = []for i in range(seq_len):if start + i < len(target_inds) and start + i < len(y_hat):target_slots.append(ids_to_slot[target_inds[start + i].item()])predict_slots.append(ids_to_slot[y_hat[start + i].item()])y_true.append(target_slots)y_pred.append(predict_slots)start = start + seq_lenf1 = f1_score(y_true, y_pred)
acc = accuracy_score(y_true, y_pred)
target_inds真实标签,y_hat预测标签
target_slots真实槽位标签,predict_slots预测槽位标签
最后计算真实值与预测值之间的f1值与准确率
6.slot_scl_loss
def slot_scl_loss(model_outputs, num_classes, num_support, num_query, slots, window= 2, temperature=0.07):slot_dict, slot_query_labels_ids, slot_query_tensor_cat, _, _ = get_slot_information(model_outputs, num_classes,num_support, num_query, slots,window)total_support_list, num_support_slot = [], []support_ids_interval = defaultdict(list)start = 0for i, key in enumerate(slot_dict.keys()):total_support_list.extend(slot_dict[key])num_support_slot.append(len(slot_dict[key]))support_ids_interval[i] = [start, start + len(slot_dict[key])]start = start + len(slot_dict[key])total_support_tensor = torch.stack(total_support_list).squeeze(dim=1)# normalize the featurestotal_support_tensor = F.normalize(total_support_tensor, p=2, dim=1)slot_query_tensor_cat = F.normalize(slot_query_tensor_cat, p=2, dim=1)anchor_dot_contrast = torch.div(torch.matmul(slot_query_tensor_cat, total_support_tensor.T),temperature)# for numerical stabilitylogits_max, _ = torch.max(anchor_dot_contrast, dim=1, keepdim=True)logits = anchor_dot_contrast - logits_max.detach()mask = torch.zeros(logits.shape[0], logits.shape[1])mask = mask.cuda()for i, ids in enumerate(slot_query_labels_ids):left, right = support_ids_interval[ids]mask[i][left:right] = 1exp_logits = torch.exp(logits)# sum(1, keepdim=True) 求矩阵每一行的和并保持原数组维度log_prob = logits - torch.log(exp_logits.sum(1, keepdim=True))# torch.isnan()判断输入张量每个元素是否为NAN(返回与输入张量大小相同的张量),是NAN则为True,否则为Flase。if torch.any(torch.isnan(log_prob)):# log_prob = np.nan_to_num(log_prob.cpu())# log_prob = log_prob.cuda()log_prob = logits# raise ValueError("Log_prob has nan!")mean_log_prob_pos = (mask * log_prob).sum(1) / (mask.sum(1))loss_scl = - mean_log_prob_pos.mean()return loss_scl
传入model_outputs = word_tensor【56,23,1536】,slot_dict存储每个不重复槽位的支持张量;
for i, key in enumerate(slot_dict.keys()):total_support_list.extend(slot_dict[key])num_support_slot.append(len(slot_dict[key]))support_ids_interval[i] = [start, start + len(slot_dict[key])]start = start + len(slot_dict[key])
循环结束后,total_support_list列表长度是序列长度之和,每一项是【1,3072】的张量;num_support_slot是长度为18(18种不重复槽位)的列表,每一项的值为该槽位出现的次数。
后续操作与intent_scl_loss类似
最终返回对比损失
四、损失函数构造
loss = intent_loss_pn + self.lamda1 * slot_loss_pn + self.lamda2 * intent_loss_scl + self.lamda3 * slot_loss_scl
lamda1 = lamda2 =lamda3 = 0.1