【STL源码剖析】从源码看 heap:元素的 “下沉” 与 “上浮”

文章目录
- 前言
- heap 的相关接口
- `push_heap`
- `pop_heap`
- `sort_heap`
- `make_heap`
本文并不适合STL初学者。对于那些熟练掌握 C++ 模板和 STL 的日常使用,理解内存分配与对象生命周期,并且有扎实的数据结构基础,希望深刻了解STL实现细节,从而得以提升对STL的扩充能力,或是希望藉由观察STL源代码,学习世界一流程序员身手,并藉此彻底了解各种被广泛运用之数据结构和算法的人,本文可能更适合你。
前言
heap并不属于STL的容器,但是它是priority_queue的幕后主谋,所以在阅读priority_queue的源码之前一定要先看看heap相关的接口。
binary heap就是一个完全二叉树,这棵树除最后一层外每一层都是满足,并且最后一成也是由左至右排列的,这就让我们可以使用数组来存储所有节点,而不需要我们维护树的左支和右支位置,通过一定的计算就可以快速知道每个位置节点的左右子树以及父节点。
heap分为两类max-heap和min-heap,前者是每个节点都大于等于子节点,后者是每个节点都小于等于子节点;STL中供应的是max-heap,因此一下介绍的都是max-heap大堆。
本文的源码主要来自 SGI STL(Silicon Graphics, Inc. 实现的 STL 版本);
关于源码可以到在线网站查看:源码网站,也可以下载源码压缩包:压缩包
heap 的相关接口
push_heap
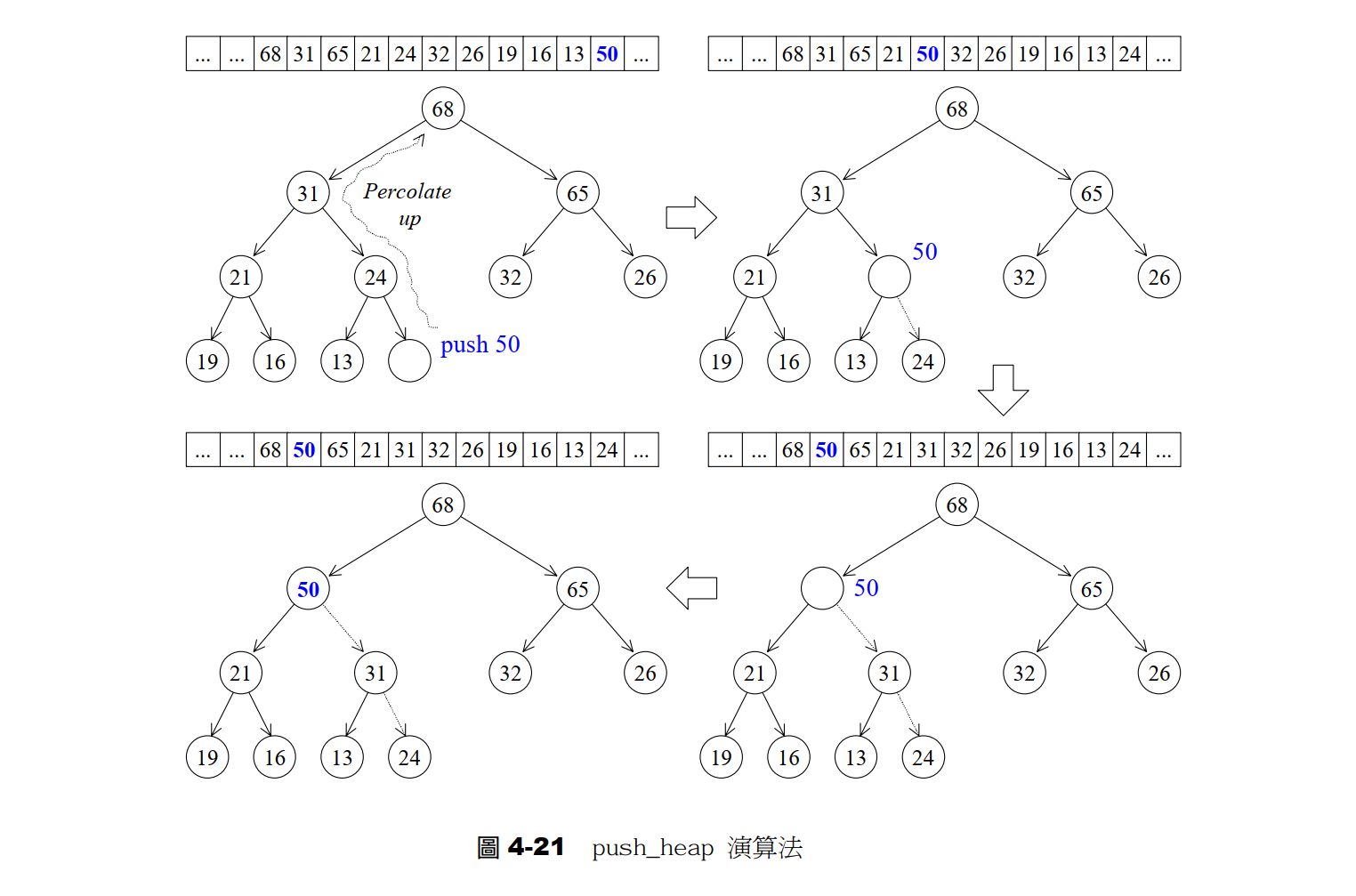
向堆中插入元素,接口void push_back(RandomAcceessIterator first , RandomAcceessIterator last),要求新元素已经插入到[first , last)中了,并且放在该区间的尾部位置即 last-1位置。
新插入的元素不一定满足大堆的要求(每个节点的值都比子节点大),所以要进行向上调整,也被称为percolate up上溯程序,即向上为新插入的元素找合适的位置:
- 如果该元素的值比父节点的大,就将父节点的值赋值给子节点,让父节点下放;
- 继续拿着值,向上比,一直与父节点比较,如果父节点小就交换;
- 直到更新到根节点或父节点大时,当前位置就是新插入元素的目标位置,给该位置赋值。
示意图如下:
看源码:
template <class RandomAccessIterator>
inline void push_heap(RandomAccessIterator first, RandomAccessIterator last) {__push_heap_aux(first, last, distance_type(first), value_type(first));
}
调用另一个接口__push_heap_aux()其中通过value_type()和distance_type()将迭代器所指向的类型和迭代器之间的距离。
template <class RandomAccessIterator, class Distance, class T>
inline void __push_heap_aux(RandomAccessIterator first,RandomAccessIterator last, Distance*, T*) {__push_heap(first, Distance((last - first) - 1), Distance(0), T(*(last - 1)));
}
依旧是向下调用,其中用first表示处理区间的起始地址,Distance((last - first) - 1)表示区间的最大有效索引的位置即开始向上调整的位置b, Distance(0)表示第一个有效索引位置,T(*(last - 1)))表示要查找位置的值,即最后一个值。
下面才是真正进行排序的函数:
template <class RandomAccessIterator, class Distance, class T>
void __push_heap(RandomAccessIterator first, Distance holeIndex,Distance topIndex, T value) {Distance parent = (holeIndex - 1) / 2; // 当前位置父节点的索引while (holeIndex > topIndex && *(first + parent) < value) { // 循环向上比较*(first + holeIndex) = *(first + parent); // 让父节点的值下移到子节点位置holeIndex = parent; // 向上走,继续向上找合适位置parent = (holeIndex - 1) / 2;} *(first + holeIndex) = value; // 找到目标位置了
}
pop_heap
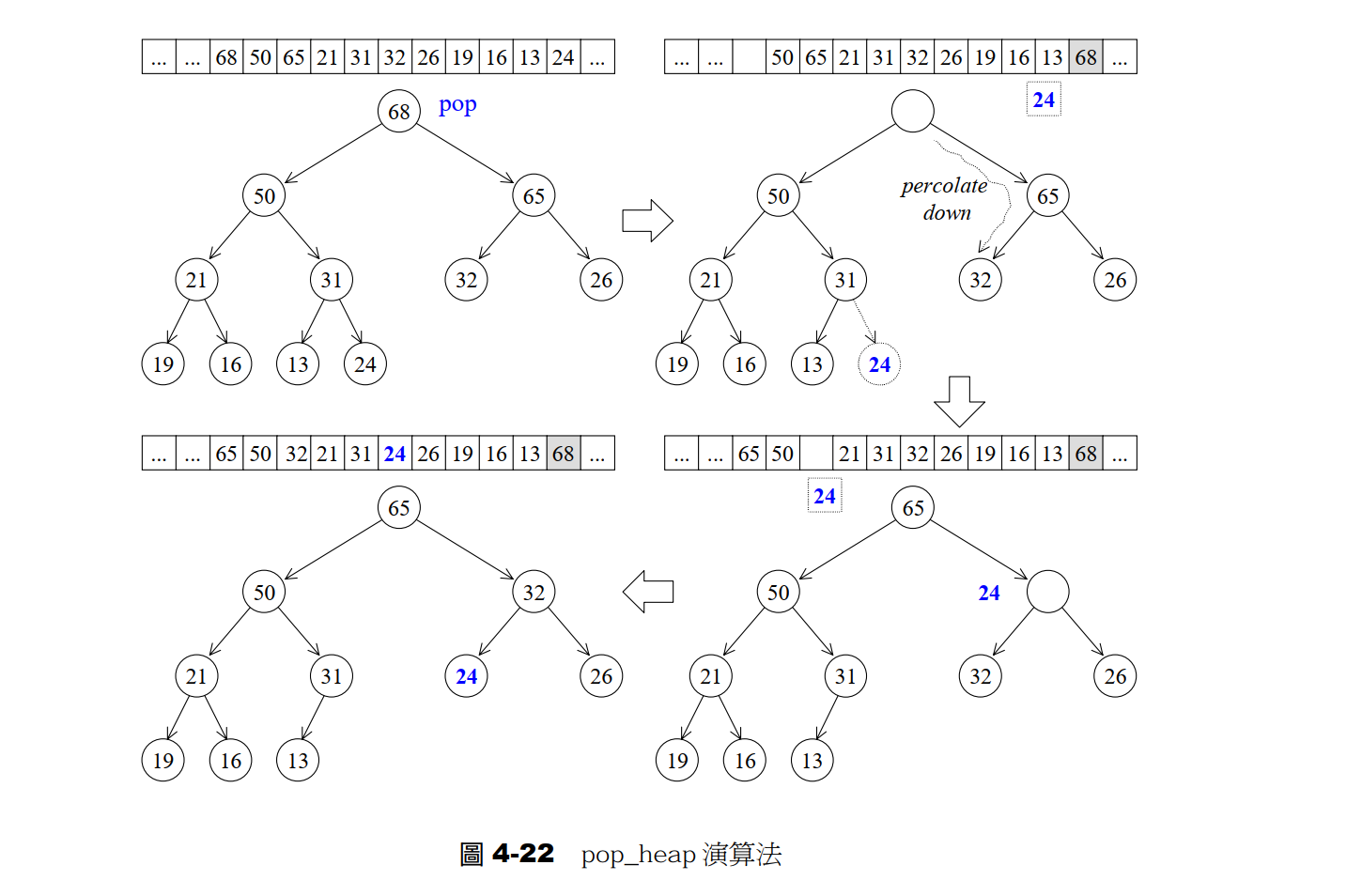
void pop_back(RandomAcceessIterator first , RandomAcceessIterator last)将顶部的元素删除即最大值,并且依旧满足大堆。
核心思想就是:
- 将根节点与最后一个节点对调,将最后一个节点pop即
pop_back; - 此时根节点并不一定满足大堆的条件,所以要进行
percolate down下溯程序,即向下调整。
向下调整:
- 取左右节点中的较大值,交换,将子节点的值上移,将当前值下移;
- 重复1操作;
- 当到达叶子节点停止,但是当前叶子可能并不满足大堆的要求,所以再从当前叶子节点向上再调整依次,即调用
percolate up上溯程序。
示意图如下:
问题:为什么不让调整的值与每一个位置的左右子节点进行比较,如果比左右子节点都大,不就是目标位置嘛,何必再从子节点向上进行调整???
实际上在进行交换的时候本来交换到根位置的值就比较小,调整后一定是比较靠近叶子节点的,所以也不会向上调整几层,但是通过这种方式可以避免每一次循环都将当前位置与左右子节点比较的消耗。
下面看源码:
template <class RandomAccessIterator>
inline void pop_heap(RandomAccessIterator first, RandomAccessIterator last) {__pop_heap_aux(first, last, value_type(first));
}template <class RandomAccessIterator, class T>
inline void __pop_heap_aux(RandomAccessIterator first,RandomAccessIterator last, T*) {__pop_heap(first, last - 1, last - 1, T(*(last - 1)), distance_type(first));
}template <class RandomAccessIterator, class T, class Distance>
inline void __pop_heap(RandomAccessIterator first, RandomAccessIterator last,RandomAccessIterator result, T value, Distance*) {*result = *first;__adjust_heap(first, Distance(0), Distance(last - first), value);
}
与push_heap()一样,pop_heap也进行了包装,其中Distance(last - first)表示第一个无效索引即结束位置,其他的参数就不再赘述了,下面直接看核心代码:
template <class RandomAccessIterator, class Distance, class T>
void __adjust_heap(RandomAccessIterator first, Distance holeIndex,Distance len, T value) {Distance topIndex = holeIndex; Distance secondChild = 2 * holeIndex + 2; // 找右子树的位置while (secondChild < len) {if (*(first + secondChild) < *(first + (secondChild - 1))) // 比较左右子树的值secondChild--;*(first + holeIndex) = *(first + secondChild); // 子树的值向上移holeIndex = secondChild; // holeIndex下移secondChild = 2 * (secondChild + 1); // 新右子树的位置}if (secondChild == len) { // 没有右子树了*(first + holeIndex) = *(first + (secondChild - 1)); // 直接与左子树交换holeIndex = secondChild - 1;}__push_heap(first, holeIndex, topIndex, value); // 向上调整
}
上面代码中并没有删除最后一个位置,需要再调用完pop_heap()后再处理。
sort_heap
堆排序在上面的pop_heap中不难发现每一次调用之后当前区间中的最大值都会被放置到区间末尾,通过这一特性就可以实现对该空间内的值进行排序:
- 通过每一次将最大值交换到末尾,来实现对最大值的查找;
- 每一次循环后将区间缩小来查找未排序区间的最大值;
- 重复上面两个操作。
逻辑示意图如下:
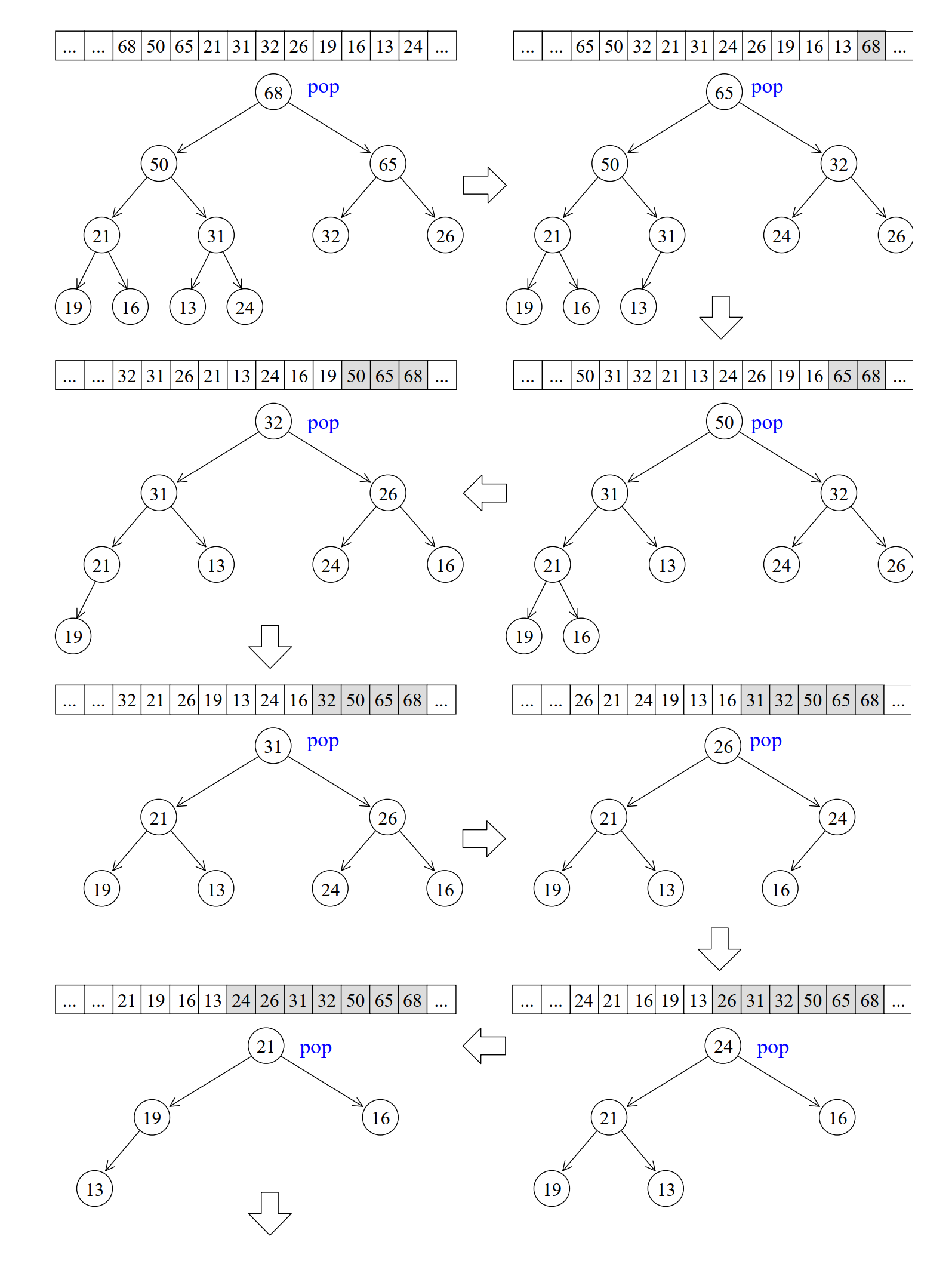
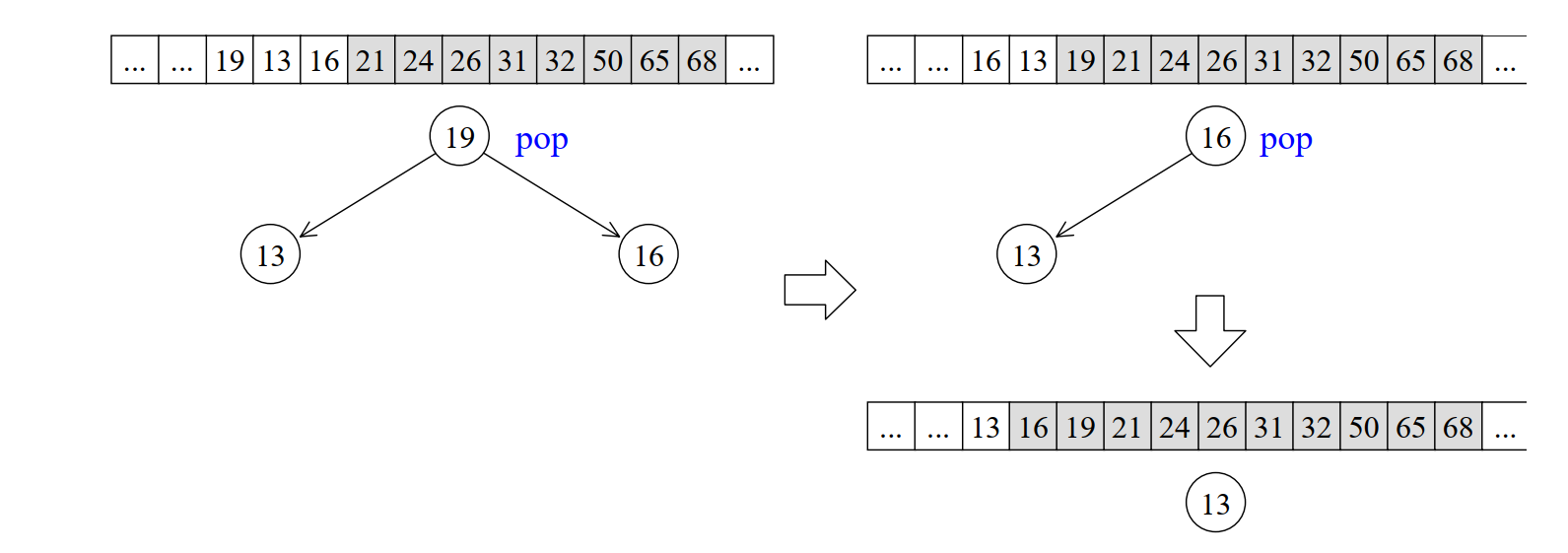
看源码:
template <class RandomAccessIterator>
void sort_heap(RandomAccessIterator first, RandomAccessIterator last) {while (last - first > 1) pop_heap(first, last--);
}
make_heap
根据迭代器区间构建一个大堆。
核心思路:
- 从下往上,遍历每一个父节点;
- 让每一个父节点都进行向下调整,一直遍历到0位置即可。
看源码:
template <class RandomAccessIterator>
inline void make_heap(RandomAccessIterator first, RandomAccessIterator last) {__make_heap(first, last, value_type(first), distance_type(first));
}template <class RandomAccessIterator, class T, class Distance>
void __make_heap(RandomAccessIterator first, RandomAccessIterator last, T*,Distance*) {if (last - first < 2) return; // 区间数量小于2Distance len = last - first; // 区间总长度Distance parent = (len - 2)/2; // 最后一个节点的父节点,即最下面的最后一个父节点while (true) {__adjust_heap(first, parent, len, T(*(first + parent))); // 开始向下调整if (parent == 0) return; // 调整完了,停止parent--; // 走到上一个节点位置}
}
思考,如果设置一个空堆,让区间中的每一个节点依次入堆,时间与该时间相比会如何???
如果采用入堆的方式即每一个节点都是向下调整的话,最多调整logN层一共有N个节点,时间复杂度是O(logN),如果采用从父结点向上调整的话最多调整logN层一共有N个节点,时间复杂度也是O(logN),量级都是一样的。
- 但是因为向下调整时,最后一行和倒数第二行叶子节点不需要进行操作,有因为每一层节点个数是 2 i 2^i 2i所以就直接省去了一半数据不需要进行调整;
- 并且采用向下调整的话下面的元素多并且靠近底层,调整次数少;而使用向上调整,插入到最后几层时元素多并且上移层数也多。
所以综上所述,采取向下调整的方法效率更高。